メルケプストラムを加工した音声の音質を計測する知覚モデルの開 発と評価 *
小川 樹
†a)森勢 将雅
††b)Development and Evaluation of Perceptual Model for Measuring Sound Quality of Mel-Cepstrum-Modified Speech
∗Itsuki OGAWA
†a)and Masanori MORISE
††b)あらまし 音声合成や声質変換に関する技術は幅広く提案され,既にいくつもの製品が多岐にわたって利用さ れるようになった.声質変換技術の普及により,音声の加工も誰でも手軽に行えるようになった.音声の加工に は,音の3要素と呼ばれる「大きさ」,「高さ」,「音色」をそれぞれ加工する方法が広く用いられている.大きさや 高さは,音圧レベルや基本周波数を加工するため,加工の結果の予測が容易である.しかし,音色の加工は,加 工に伴う劣化の予測が困難という問題点がある.本研究では,音声の音色加工に伴う劣化を計測する知覚モデル によりこの問題の解決を図る.様々なスペクトル尺度と距離関数の組み合わせと音質の関係を調査し,その結果 を用いて知覚モデルを開発した.主観評価実験を実施し,従来法と開発した知覚モデルの間に,主観評価結果と の相関係数の有意差があるかの検定を行った.検定の結果,p <0.001で有意な差があり,従来法より開発した 知覚モデルが優れていることを示した.
キーワード 音声分析,音声知覚,音質評価,知覚モデル,メルケプストラム
1.
ま え が き音声は,人間が意思や感情などの情報を伝達するた めの基礎的な手段の一つであり,計算機による音声生 成は,テキストの読み上げやスマートスピーカなどで 利用される大変身近な技術になっている.この際,生 成される音声は多様であり,利用者の好みに応じた音 声を創る技術に注目が高まっている.音声を加工する 機械やソフトウェアはボイスチェンジャーと呼ばれ,
ロボットを想像させる声や特定の芸能人に似た声など,
さまざまな声に加工をすることができる.とりわけ,
†山梨大学大学院医工農学総合教育部,甲府市
Integrated Graduate School of Medicine, Engineering, and Agricultural Sciences, University of Yamanashi, 4–3–11 Takeda, Kofu-shi, 400–8511 Japan
††明治大学総合数理学部,東京都
School of Interdisciplinary Mathematical Sciences, Meiji University, 4–21–1 Nakano, Nakano-ku, Tokyo, 164–8525 Japan
a) E-mail: [email protected] b) E-mail: [email protected]
*本論文は学生論文特集秀逸論文である.
DOI:10.14923/transinfj.2019PDP0005
高品質な音声加工を実施する基盤として,音の
3
要素 と呼ばれる「大きさ」,「高さ」,「音色」をそれぞれ加工 する音声分析合成方式が広く用いられている.しかし,音色の加工は,大きさや高さの加工に対して直感的な 加工が困難という問題点がある.
この問題の原因は,大きさや高さが,
1
時刻あたり1
次元の時系列である一方,音色は,加工するパラメー タが1
時刻あたり多次元なスペクトル包絡というス ペクトル情報で表現されるためである.また,わずか な加工で音質が悪化するなど,加工の程度と音質との 関係性が直感的ではなく,情報量の多さから音質に与 える影響の原因を特定することは困難である.そのた め,目的の加工音声を作成するためには,人間が直接 音声を聴取して音質を確認し,得られた結果を用いて 満足のいく品質となるまで加工する作業を繰り返し 行う必要がある.この評価には,主観評価を行うこと が最も正確であるが,大量の加工音声に対して行う場 合,多くの時間を費やす必要があり,効率が悪い.そ こで,主観評価の結果を推定する客観評価法が提案さ れ,利用されている.PESQ
(perceptual evaluation
of speech quality
)[1]
とPOLQA
(perceptual objec- tive listening quality assessment
)[2]
は,広く用いら れている客観評価法である.しかし,PESQ
は,電話 帯域の音声を対象としており,POLQA
は,音声の長 さなどに制約があるため,任意の音声での評価は困難 である.このことから,任意の音声に対しても,音色 の加工を行った音声を評価することができる知覚モデ ルの構築は,膨大な音声を自動で評価する領域で役に 立つことが期待される.本研究では,音声の音色の加工に伴う劣化の予測が 困難という問題点を解決するため,音色の加工後に起 こる音質劣化に特化した知覚モデルを開発する.既存 の音声の客観評価法と音色を表す音響特徴量の関係を 調査する.調査した結果より,複数の知覚モデルを開 発する.これらの知覚モデルから最適な知覚モデルを 選択するため,主観評価実験を実施し,提案した知覚 モデルが既存の評価法よりも優れているかを明らかに する.
本章では,序論として本研究の背景及び目的につい て述べた.
2.
では,音声の評価法について関連研究を 説明し,3.
では,提案法の概要について述べる.4.
で は,知覚モデルの選定のために実施した予備実験を示 す.5.
では,4.
の結果を基にした知覚モデルの開発を 述べる.6.
では,主観評価実験について述べ,7.
で は,6.
までに得られた結果から構築した知覚モデルの 有効性について論じる.8.
では,本論文の結論及び今 後の課題を述べる.2.
音声評価に関する関連研究音声の加工は,入力された音声パラメータを,設定 された目的のパラメータへと変換することにより実施 される.その際,定常的に起きるノイズや,局所的に 生じる振幅のピークなどの劣化が生じることがある.
したがって,目的とする音色であるかを評価するため の方法があり,特に主観評価法が広く利用されている.
MOS
(mean opinion score
)評価は代表的な主観評 価法であり,音質について「非常に良い」から「非常 に悪い」までの5
段階で評価する方法である.しかし,評価者や評価音声の準備にコストがかかるという問題 点がある.具体的には,まず正常な聴力をもつ被験者 を多数集める必要がある.評価環境は,専用の無響室 や防音室などの評価施設で行い,騒音や音圧レベルな どの条件を揃えたり,評価音声の順序を毎回変化させ たりするなど,評価に対するばらつきを抑えなければ
ならない.この問題点を解決し,
MOS
評価と同等の 評価値を推定する方法として,PESQ
とPOLQA
や,AutoMOS [3]
などの客観評価法が提案されている.PESQ
とPOLQA
は,参照音声と評価音声を比較 し,知覚・認知モデルのそれぞれの処理から,評価 値を推定する方法である.PESQ
は電話帯域の音声 を対象としており,POLQA
はPESQ
を拡張し,性 能の向上に加え,より広帯域な音声も対象としてい る.PESQ
とPOLQA
は,共に国際規格となってい る.しかし,PESQ
はサンプリング周波数が16 kHz
を上回る音声に対応しておらず,POLQA
は使用する 音声への制約,特に時間に関する制約が多い.サン プリング周波数48 kHz
に対応させたPESQ
の拡張 版であるEW-PESQ [4]
も提案されているが,音色の 加工を行った音声の評価法としての検討が十分であ るとは言い難い.近年では,AutoMOS
と呼ばれる,ニューラルネットワークを用いた客観評価法も提案さ れている.
AutoMOS
は,スペクトルとその動的特徴 量を入力として,評価値を出力するように学習を行う.text-to-speech
システムなどで合成された音声や,評 価音声しか用意できない環境に対しても利用すること ができ,その利用範囲は広い.しかし,学習を行うた めのデータセットが,文献中では約17
万音声と非常 に多く,どのような音声で構成されているかが不明で あるため,同じ性能を達成するデータセットの構築が 課題となる.3.
提 案 法3. 1
本研究の位置づけ本研究の目的は,音色変化による劣化の計測である ため,スペクトル包絡のみを評価する指標として,ス ペクトル距離に着目する.スペクトル距離は,参照音 声と評価音声のそれぞれのスペクトル包絡を,適当な 距離関数を用いて得られた誤差の尺度である.
本研究では,
2.
で述べたPESQ
とEW-PESQ
を従 来法とする.4.
以降で利用する親密度別単語了解度 試験用音声データセット2007
(familiarity-controlled wordlists 2007: FW07
)[5]
の発話内容が4
モーラの 単語と短いため,発話時間に制約のあるPOLQA
は 今回比較する従来法から除外した.また,AutoMOS
も,学習するためのデータセットに結果が依存し,再 現性を担保することができないため除外した.音色の みを加工した音声の音質劣化の推定を目的とするため,音色のみの加工を行った音声を評価音声とし,加工を
図1 メルケプストラムを用いた音声変換のフロー図
行う前の音声を参照音声として,二つの音声を比較す る評価法とする.サンプリング周波数が
40 kHz
以上 のフルバンド音声を対象とし,信号処理のみを用いて 評価値を推定する.評価値は,MOS
値と同じ1
から5
の範囲で推定する.3. 2
メルケプストラムを用いた音声変換音声変換のフロー図を図
1
に示す.音色のみの加工 を行うため,音声から音色を表す音響特徴量を抽出す る.音響特徴量の抽出には,音声分析合成システムで あるWORLD [6]
(D4C edition [7]
)を利用した.また,
WORLD
の構成モジュールは複数あるため,基本周波数推定には
Harvest [8]
,スペクトル包絡推定に はCheapTrick [9], [10]
を用いた.WORLD
は,高品 質な音声の分析合成システムであり,声の高さを表す 基本周波数,声の音色を表すスペクトル包絡,声のか すれ具合を表す非周期性指標の三つのパラメータを用 いたVocoder
の機構を採用している.同じ音声デー タセットを用いて,声質変換[11]
の精度を競うVoice Conversion Challenge 2016 [12]
では,参加した17
チームのうち,13
チームでメルケプストラム[13]
を 用いたシステムを開発している.性能の面でもメルケ プストラムを用いたシステムが上位に多いこと[14]
か ら,本研究ではメルケプストラムを用いた音声変換を 行う.音色の加工方法は,メルケプストラム次数の1
からN
次までの1
刻みのうち,一つの次元のみを− 8
から10
まで1
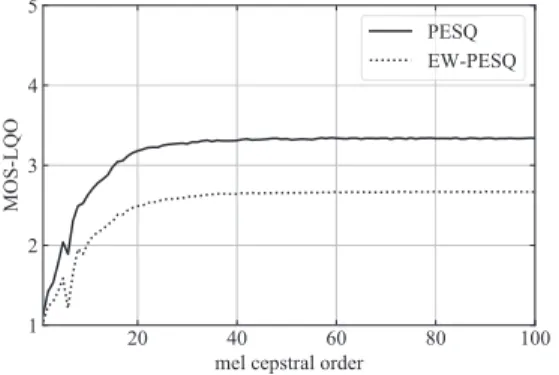
刻みで定数倍する.加工したメルケプ ストラムをスペクトル包絡に復元し,元音声から推定図2 メルケプストラム次数の変化によるPESQとEW- PESQの評価値
した基本周波数と非周期性指標を用いて
WORLD
で 合成することにより音声変換を行う.メ ル ケ プ ス ト ラ ム 次 数
N
を 決 め る た め に ,メ ル ケ プ ス ト ラ ム 次 数 を1
か ら100
次 に し た 際 の ,PESQ
またはEW-PESQ
の評価値の変化について 予備調査を行った.使用音声は,JSUT
(Japanese speech corpus of Saruwatari laboratory, the Uni- versity of Tokyo
)[15]
から女性話者の10
音声,HTS- demo NIT-ATR503-M001 [16]
から男性話者の10
音 声,計20
音声を用いた.調査結果を,図2
に示す.縦 軸はPESQ
またはEW-PESQ
の評価値であるMOS- LQO
(MOS-listening quality objective
),横軸はメ ルケプストラム次数を表す.図2
より,28
次以上でど ちらの評価値も変動がおおむね飽和したため,28
次を 音声変換に用いるメルケプストラム次数と決定した.3. 3
スペクトルの種類調査するスペクトルとして,
WORLD
で推定した スペクトル包絡に加え,以下の項で述べる5
種類のス ペクトルを用いる.3. 3. 1
メ ル 尺 度メル尺度(
mel
)[17]
は,音の高さの知覚的尺度であ る.低域の周波数差には敏感だが,高域の周波数差に は鈍感という聴覚特性を基に作成された.周波数から メル尺度への変換は,文献[18]
から,式(1)
を用いる.mel( f ) = 1127 . 01048 log f
700 + 1
, (1)
f
はHz
を単位とする周波数を表す.式(1)
以外にも幾 つかの変換式が提案されているが,どの変換式も低域 では線形,高域では対数関数で近似されている.本研 究では,WORLD
で得られたスペクトル包絡に,100
次のメルフィルタバンクをかけたものをメルスペクトルとして用いる.本実験では,フィルタバンクの上限・
下限周波数をそれぞれ
24000 Hz
,20 Hz
にした.こ の上下限は以下に示す他の尺度でも同一である.3. 3. 2
バーク尺度バーク尺度(
Bark
)[19]
は,臨界帯域幅測定法を用 いた心理学実験を基に作成された音響心理学的尺度で ある.周波数f
からバーク尺度への変換は,文献[20]
から,式
(2)
を用いる.Bark( f ) = 26 . 81 f
1960 + f − 0 . 53 . (2)
本研究では,WORLD
で得られたスペクトル包絡に,100
次のバークフィルタバンクをかけたものをバーク スペクトルとして用いる.3. 3. 3 ERB
尺度ERB
(equivalent rectangular bandwidth
)尺 度[21]
は,バーク尺度で利用されていた臨界帯域幅測 定法を改良した,ノッチ雑音マスキング法を用いた心 理学実験を基に作成された音響心理学的尺度である.周波数
f
からERB
尺度への変換は,文献[22]
から,式
(3)
を用いる.ERB( f ) = 21 . 4 log
104 . 37 f
1000 + 1
. (3)
本研究では,音声波形から得られた
100
次のERB
ス ペクトルを用いる.3. 3. 4
ガンマチャープガンマチャープ
[23]
は,音圧のレベル依存性や圧 縮特性といった聴覚末梢系の非線形性や,時間変化に よる動的な特性をモデル化した聴覚フィルタである.ガンマチャープには,線形で時不変なガンマチャープ
(
gammachirp: GC
),非線形で時不変な圧縮型ガンマ チャープ(compressive gammachirp: cGC
),非線形 で時変な動的圧縮型ガンマチャープの3
種類がある.聴覚特性を最もよく表現しているフィルタは,動的圧 縮型ガンマチャープであるが,非線形性があるため波 形に対する音圧レベルという他の尺度には存在しない パラメータが必要であること,及び時変性を取り入れ るため計算に時間がかかることから,本研究では
GC
とcGC
のみを用いる.3. 4
距離関数の種類調査する距離関数として,式
(4)–(7), (9)
で述べる5
種類の距離関数と,それらの対数で表現する距離関 数を加えた計10
種類を用いる.代表的な距離関数であるユークリッド距離は,式
(4)
で表される.D
EU= 1 T
T0
1 f
N fN0
D
EU( t, f ) df dt, (4) D
EU( t, f ) =
P ( t, f ) − P ˆ ( t, f )
2,
P ( t, f )
は,真値のスペクトル包絡の時間周波数表現 であり,P ˆ ( t, f )
は,加工したスペクトル包絡の時間周 波数表現である.T
は信号長に相当し,t
は分析時刻,f
Nはナイキスト周波数であり,f
は周波数を示す.こ の距離関数は,誤差の正負にかかわらず対称である.式
(5)
は,対数スペクトル距離である.D
LS= 1 T
T0
1 f
N fN0
D
LS( t, f ) df dt, (5)
D
LS( t, f ) =
10 log
10P ( t, f ) P ˆ ( t, f )
2
.
対数スペクトル距離は,ユークリッド距離を対数軸上 で評価した距離関数となる.
音声評価で利用される板倉斉藤距離
[24]
を式(6)
に 示す.D
IS= 1 T
T0
1 f
N fN 0
D
IS( t, f ) df dt, (6)
D
IS( t, f ) = P ( t, f ) P ˆ ( t, f ) − log
P ( t, f ) P ˆ ( t, f ) − 1 .
ユークリッド距離では対称であった正負に対して,負 方向には大きく,正方向には小さく距離を取る,非対 称性をもつ.スペクトル包絡のピークが弱まるより強 まる加工が音声として自然なため,この距離関数は音 声に適していると言える.式
(7)
に示す距離関数は,文献[25]
で提案された,重み付き板倉斎藤距離である.
D
WIS= 1 T
T0
1
0 . 45 f
s− 2 f
0D
WIS( t ) dt, (7) D
WIS( t ) =
0.45fs2f0
D
WIS( t, f ) u ( f ) df,
D
WIS( t, f ) = P ( t, f ) P ˆ ( t, f ) − log
P ( t, f ) P ˆ ( t, f ) − 1 , u ( f ) = 9 . 294
0 . 00437 f + 1 , (8)
f
sはサンプリング周波数を,f
0は基本周波数を示す.板倉斎藤距離に,低域ほど大きく,高域ほど小さい周 波数重みをかけ合わせたもので,周波数重みは,式
(3)
の導関数として,式(8)
で表される.積分範囲は,低 域は重みが大きくなりすぎるため,高域は折り返しの 影響を除くために狭くしている.最後に,式
(9)
は,文献[26]
で提案された距離関数 である.D
dB=
1 T
T0
1 f
N fN0
D
dB( t, f ) df dt, (9) D
dB( t, f )
=
10 log
10P ( t, f ) P ¯ ( t )
− 10 log
10P ˆ ( t, f )
¯ ˆ P ( t )
2
, P ¯ ( t )
は,真値のスペクトル包絡の周波数の平均値であ り,P ¯ ˆ ( t )
は,加工したスペクトル包絡の周波数の平均 値である.文献中では,ガンマチャープを用いた声道 長の推定のために用いられている.4.
従来法と提案法の比較4. 1
実 験 条 件知覚モデルを開発するための予備実験として,知覚 モデルの選定に利用することを目的とした従来法と提 案法の比較実験を行い,従来法と提案法の相関につい て調査する.実験条件を表
1
に,提案法で使用する スペクトル及び距離関数を表2
に示す.使用音声はFW07
を用いた.FW07
は,4
モーラの単語で構成さ れた発話時間の短い音声で構成されているデータセッ トである.本章以降での実験には主観評価を含むため,3. 2
のメルケプストラム次数の決定の実験で使用したJSUT
やHTS-demo NIT-ATR503-M001
のような発 話時間の長い音声では,発話の局所的な劣化を評価す ることが困難となる.そのため,本論文では,発話時 間が短く固定されたFW07
を使用した.FW07
は,サ ンプリング周波数が48 kHz
であるため,16 kHz
まで の音声にしか対応していないPESQ
では評価できな い.そのため,PESQ
で評価を行う際は,音声を16 kHz
にダウンサンプリングする.4. 2
実 験 結 果まず,
PESQ
またはEW-PESQ
と提案法の距離と の相関係数のうち,それぞれ上位五つについて表3
に示す.表中において,例えば,ERB-log ( D
dB)
は,ERB
尺度のスペクトルを用いた式(9)
の対数距離で表1 従来法と提案法の比較実験の実験条件 メルケプストラム次数 28次
変化量 1刻みで−8から10倍の19通り
使用音声 FW07
音源 全40音声(男女各2名×10文章)
加工種類 全532種類(28次×19通り)
従来法 PESQ,EW-PESQ
提案法
全60種類
(スペクトル6種類
×距離関数10種類)
表2 実験に用いるスペクトルと距離関数.6種類のスペ クトルと10種類の距離関数を組み合わせた60種 類の指標が存在する.
スペクトル 距離関数 WORLD DEU
mel DLS
Bark DIS
ERB DWIS
GC DdB
cGC log (DEU) log (DLS) log (DIS) log (DWIS) log (DdB)
表3 従来法と提案法の距離との相関係数 従来法 提案法 相関係数
PESQ
ERB-log (DdB) −0.814 GC-log (DLS) −0.801 Bark-log (DdB) −0.792 ERB-log (DLS) −0.785 mel-log (DdB) −0.781
EW-PESQ
ERB-log (DdB) −0.753 GC-log (DLS) −0.746 GC-log (DdB) −0.724 ERB-log (DLS) −0.721 Bark-log (DdB) −0.708
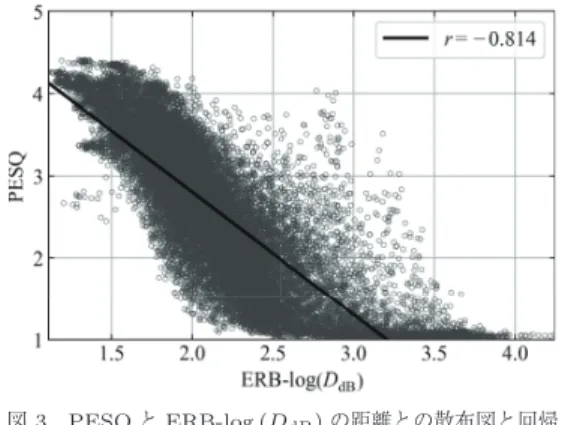
あることを示す.次に,従来法のそれぞれで最も相関 係数が高かった組み合わせについて,散布図と回帰直 線を図
3, 4
に示す.縦軸はPESQ
またはEW-PESQ
の評価値,横軸は提案法の距離を表し,右上に相関係 数を示す.距離関数では,対数軸上で比較する
log ( D
LS)
やlog ( D
dB)
を用いた提案法が,従来法との相関が強い という結果が得られた.すなわち,従来法の距離関数 も対数関数に近い特性を有する可能性が示唆される.また,従来法と提案法の間に非線形性があることも確 認できる.
図3 PESQとERB-log (DdB)の距離との散布図と回帰 直線
図4 EW-PESQとERB-log (DdB)の距離との散布図 と回帰直線
5.
知覚モデルの開発5. 1
非線形モデルの推定スペクトル距離から評価値を推定する知覚モデルを 開発する.知覚モデルには,
4. 2
より従来法の評価値 と提案法の距離との間に非線形性があったため,非線 形モデルを使用する.非線形モデルとして,式(10)–
(12) [27]
を用いる.Exp y = a e
bx+ c, (10)
Shah y = a + bx + cd
x, (11) Stirling y = a + b e
cx− 1
c , (12)
x
はスペクトル距離,y
は評価値,a, b, c, d
は各非線 形モデルのパラメータである.パラメータは,4. 2
の データを基に,レーベンバーグ・マーカート法[28]
に よって求める.5. 2
開発した知覚モデルと従来法の比較開発した
360
種類の知覚モデルと従来法の比較を行表4 知覚モデルに用いる従来法,スペクトル,距離関数 及び非線形モデル.2種類の従来法,6種類のスペ クトル,10種類の距離関数と3種類の非線形モデル を組み合わせた360種類の知覚モデルが存在する.
従来法 スペクトル 距離関数 モデル
PESQ WORLD DEU Exp
EW-PESQ mel DLS Shah
Bark DIS Stirling
ERB DWIS
GC DdB
cGC log (DEU) log (DLS) log (DIS) log (DWIS) log (DdB)
表5 従来法と知覚モデルの評価値との相関係数
従来法 提案法 相関係数
PESQ
WORLD-log (DIS)-Shah 0.851
ERB-DdB-Shah 0.848
ERB-DdB-Exp 0.848
ERB-DdB-Stirling 0.848 WORLD-log (DIS)-Exp 0.846
EW-PESQ
ERB-DdB-Shah 0.814
ERB-DdB-Exp 0.814
ERB-DdB-Stirling 0.814 ERB-log (DdB)-Shah 0.811 ERB-log (DdB)-Exp 0.806
図5 PESQとPESQ-WORLD-log (DIS)-Shahの評価 値との散布図と回帰直線
う.
360
種類の知覚モデルで使用したスペクトル,距 離関数,非線形モデルを表4
に示す.PESQ
またはEW-PESQ
と開発した知覚モデルとの相関係数のうち,それぞれ上位五つについて表
5
に示す.表中におい て,例えば,WORLD-log ( D
IS)-Shah
は,WORLD
で推定したスペクトルを用いた式(6)
の対数距離を基 に,Shah
のモデルで推定した知覚モデルであること を示す.次に,従来法のそれぞれで最も相関係数が高図6 EW-PESQとEW-PESQ-ERB-DdB-Shahの評 価値との散布図と回帰直線
かった組み合わせについて,散布図と回帰直線を図
5, 6
に示す.縦軸はPESQ
またはEW-PESQ
の評価値,横軸は提案法の評価値を表し,左上に相関係数を示す.
PESQ
では,ERB- D
dB やWORLD-log ( D
IS)
の 組み合わせが,EW-PESQ
では,ERB- D
dBやERB- log ( D
dB)
の組み合わせが,従来法と相関の強い知覚 モデルとなった.また,非線形モデルの種類について は,大きな差は見られなかったが,Stirling
のモデル は,幾つかの知覚モデルに対して,パラメータは収 束しているが曲線の当てはめに失敗していることが あった.6.
主観評価実験6. 1
実 験 条 件実験条件を,表
6
に示す.音声の加工種類について は,PESQ
の評価値が,1.0
から1.5
になる音声を5
種類,1.5
から2.0
になる音声を7
種類,2.0
から2.5
になる音声を8
種類,2.5
から3.0
になる音声を8
種 類,3.0
から3.5
になる音声を7
種類,3.5
から4.0
に なる音声を5
種類の計40
種類を使用した.6. 2
実 験 結 果MOS
と5.
で開発した知覚モデルの評価値との相関 係数のうち,それぞれ上位五つについて表7
に示す.表中において,例えば,
PESQ-WORLD-log ( D
WIS)- Shah
は,PESQ
の結果とWORLD
で推定したスペ クトルを用いた式(6)
の対数距離を基に,Shah
のモデ ルで推定した知覚モデルであることを示す.次に,従 来法のそれぞれで最も相関係数が高かった知覚モデル と従来法について,散布図と回帰直線を図7–10
に示 す.縦軸はMOS
,横軸は提案法の評価値を表し,左 上に相関係数を示す.最も相関が強くなった知覚モデ表6 主観評価実験の実験条件 使用音声 FW07
音声数 全160音声
(男女各1名×2文章×加工40種)
サンプリング 48 kHz / 16 bit
実験環境 防音室(A-weighted SPL 17 dB)
再生機材 Roland QUAD-CAPTURE
SENNHEISER HD 650 被験者 20代15名
評価法 MOS評価
表7 MOSと知覚モデルの評価値との相関係数
提案法 相関係数
PESQ-WORLD-log (DWIS)-Shah 0.949 PESQ-WORLD-log (DWIS)-Exp 0.948 PESQ-WORLD-log (DWIS)-Stirling 0.948 PESQ-Mel-log (DWIS)-Shah 0.946 PESQ-Mel-log (DWIS)-Stirling 0.945 EW-PESQ-WORLD-log (DWIS)-Stirling 0.948 EW-PESQ-WORLD-log (DWIS)-Exp 0.948 EW-PESQ-WORLD-log (DWIS)-Shah 0.948 EW-PESQ-Mel-log (DWIS)-Stirling 0.945 EW-PESQ-Mel-log (DWIS)-Exp 0.945
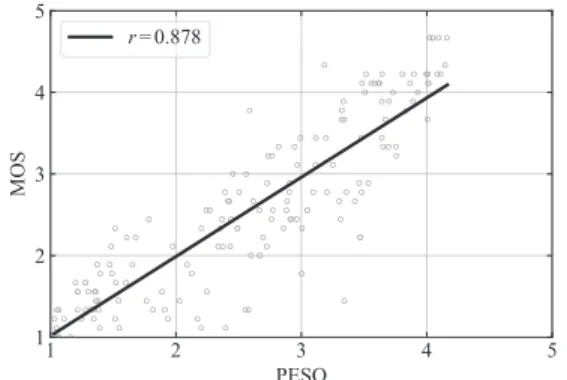
図7 MOSとPESQ-WORLD-log (DWIS)-Shahの評 価値との散布図と回帰直線
図8 MOSとEW-PESQ-WORLD-log(DWIS)-Stirling の評価値との散布図と回帰直線
図9 MOSとPESQの評価値との散布図と回帰直線
図10 MOSとEW-PESQの評価値との散布図と回帰
直線
図11 MOSとPESQ,EW-PESQ及びPESQ- WORLD-log (DWIS)-Shahとの相関係数
ルは,
PESQ-WORLD-log ( D
WIS)-Shah
となった.最適な知覚モデルを
PESQ-WORLD-log ( D
WIS)- Shah
と定義し,この知覚モデルについて,PESQ
とEW-PESQ
よりも有意であるかを調べるため,文献[29]
を参考に検定を行った.図11
は,MOS
とPESQ
,EW-PESQ
及 びPESQ-WORLD-log ( D
WIS)-Shah
との相関係数を表す.検定の結果,PESQ
とEW-
PESQ
そ れ ぞ れ に つ い て 開 発 し た 知 覚 モ デ ル が ,p < 0 . 001
と な り 有 意 差 が 認 め ら れ た .PESQ- WORLD-log ( D
WIS)-Shah
の モ デ ル を ,式(13)
に 示す.y = 1 . 507896 − 0 . 012978 x
+ 1 . 013483 × 0 . 643603
x. (13)
7.
考 察まず,本研究では,相関係数に基づいて知覚モデ ルを開発した.提案法同士や提案法と従来法を,相 関係数の値で直接比較することはできないが,二つ の相関係数の有意差を判定する検定を用いて比較を 行った.最適な知覚モデルとして,
360
種類の中からPESQ-WORLD-log ( D
WIS)-Shah
を選択した.この 最適な知覚モデルの相関係数とp > 0 . 001
で有意な差 がない知覚モデルは,360
種類中18
種類あった.こ の18
種類の知覚モデルは,従来法のどちらの相関係 数ともp < 0 . 001
で有意な差があった.このことか ら,提案法に基づく知覚モデルは,従来法のPESQ
やEW-PESQ
と比較して優れているといえる.次に,本研究では,非線形モデルとして
3
種類のみ を用いた.この3
種類以外の非線形モデルや線形モデ ルも使用して知覚モデルの推定を行ったが,その中で 首尾よく当てはめが行えた3
種類のみを選定した.ま た,線形モデルより非線形モデルが適している点につ いては,図3, 4
から分かるとおり,従来法と提案法 の距離の間に,非線形な関係性があることが確認でき る.そのため,複数の非線形モデルを対象とした知覚 モデルを作成し,より相関が高くなるように構築した 効果が認められたといえる.本来,知覚モデルは主観評価実験に基づいて開発す べきである.一方,今回のように多数のパラメータか ら構成される膨大な音声の評価を行うことは現実的 ではないといえる.例えば,今回,知覚モデルを開発 するためのデータとなった
4.
の実験を主観的に行う 場合,21280
音声を評価する必要がある.そのため,PESQ
のような,国際電気通信連合で既に規格化され ており,信頼できる評価法を使用し,4. 2
でも述べた 非線形性を提案法により解消するというアプローチを 採用した.結果,図9, 10
の従来法より図7, 8
の提 案法はばらつきが抑えられ,図11
に示すように従来 法より性能が向上した.このばらつきは,4. 2
でも述 べた非線形性が影響していると考えられ,この影響が線形になるように変換する提案法により,従来法より ばらつきを抑えることができたと考えられる.
最後に,表
7
で上位の知覚モデルに使用しているス ペクトル包絡や距離関数は,表3
や表5
で上位であっ たとは限らない.4.
の実験では,最適な知覚モデルに 使用されているWORLD
とlog ( D
WIS)
の組み合わせ は,PESQ
とは−0 . 553
,EW-PESQ
とは−0 . 463
の 相関係数であった.一方,5.
の実験では,最適な知覚 モデルに使用されているWORLD
とlog ( D
WIS)
とShah
の組み合わせは,PESQ
とは0 . 835
,EW-PESQ
とは0 . 764
の相関係数であり,どちらも相関が相対的 に高い数値を示した.つまり,非線形性の影響が線形 になるように変換するために使用した非線形モデルに より,主観評価実験の結果と相関が強くなったと考え られる.8.
む す び本研究では,音声の音色加工に伴う劣化を計測する 知覚モデルを開発した.提案法として,音声の音色を 表すスペクトルと,スペクトルを評価する距離関数に 着目し,スペクトルを
6
種類,距離関数を10
種類の 全60
種類について検討した.まず,従来法と提案法 の距離との比較を行い,対数軸上で比較する距離関数 の相関が強くなることを確認した.次に,従来法と提 案法の比較実験の結果を基に,知覚モデルを開発し た.従来法と提案法の距離との間には非線形な関係性 があることが確認できたため,非線形モデルをベース とした.従来法と開発した知覚モデルの性能の評価を 行い,WORLD
のスペクトルやERB
尺度と対数軸 上で比較する距離関数を組み合わせた知覚モデルが,従来法との相関が強い結果となった.最後に,知覚モ デルの性能の評価を行うために,主観評価実験を実施 した.主観評価実験の結果を基に,最適な知覚モデル として,
PESQ-WORLD-log ( D
WIS)-Shah
が,MOS
との相関が最も強いことを示した.今後の課題として,より複雑な音色の加工を行った 音声への性能評価が挙げられる.今回の評価音声の加 工方法は,一つに限定しているため,他の音色加工に よる音声に対しての評価値が,正しく推定できるとは 限らない.そのため,より多様な加工を行った音声に 対しても頑強であるかの評価は必要である.
謝辞 ガンマチャープについて御教授を賜った和歌山 大学システム工学部システム工学科入野俊夫教授に深謝 する.本研究は,科研費
JP16H05899, JP16H01734
,JST
さきがけJPMJPR18J8
の支援を受けた.文 献
[1] ITU-T, “Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone net- works and speech codecs,” Recommendation P.862, International Telecommunication Union, 2001.
[2] ITU-T, “Perceptual objective listening quality pre- diction,” Recommendation P.863, International Telecommunication Union, 2011.
[3] B. Patton, Y. Agiomyrgiannakis, M. Terry, K.
Wilson, R.A. Saurous, and D. Sculley, “AutoMOS:
Learning a non-intrusive assessor of naturalness-of- speech,” NIPS 2016 End-to-end Learning for Speech and Audio Processing Workshop, pp.1–5, 2016.
[4] B.C. Bispo, P.A.A. Esquef, L.W.P. Biscainho, A.A.
de Lima, F.P. Freeland, R.A. de Jesus, A. Said, B.
Lee, R.W. Schafer, and T. Kalker, “EW-PESQ: A quality assessment method for speech signals sam- pled at 48 kHz,” J. Audio Eng. Soc., vol.58, no.4, pp.251–268, 2010.
[5] 近藤公久,天野成昭,坂本修一,鈴木陽一,“親密度別単 語了解度試験用音声データセット2007 (FW07),” NII音 声資源コンソーシアム,2007.
[6] M. Morise, F. Yokomori, and K. Ozawa, “WORLD:
a vocoder-based high-quality speech synthesis sys- tem for real-time applications,” IEICE Trans. Inf.
& Syst., vol.E99-D, no.7, pp.1877–1884, July 2016.
DOI:10.1587/transinf.2015EDP7457
[7] M. Morise, “D4C, a band-aperiodicity estimator for high-quality speech synthesis,” Speech Commun., vol.84, pp.57–65, 2016. DOI:10.1016/j.specom.2016.
09.001
[8] M. Morise, “Harvest: a high-performance fundamen- tal frequency estimator from speech signals,” In- terspeech 2017, pp.2321–2325, 2017. DOI:10.21437/
Interspeech.2017-68
[9] M. Morise, “Cheaptrick, a spectral envelope estima- tor for high-quality speech synthesis,” Speech Com- mun., vol.67, pp.1–7, 2015. DOI:10.1016/j.specom.
2014.09.003
[10] M. Morise, “Error evaluation of an F0-adaptive spec- tral envelope estimator in robustness against the additive noise and F0 error,” IEICE Trans. Inf.
& Syst., vol.E98-D, no.7, pp.1405–1408, July 2015.
DOI:10.1587/transinf.2015EDL8015
[11] Y. Stylianou, O. Cappe, and E. Moulines, “Contin- uous probabilistic transform for voice conversion,”
IEEE Trans. Speech Audio Process., vol.6, no.2, pp.131–142, 1998. DOI:10.1109/89.661472
[12] T. Toda, L.-H. Chen, D. Saito, F. Villavicencio, M.
Wester, Z. Wu, and J. Yamagishi, “The voice con- version challenge 2016,” Interspeech 2016, pp.1632–
1636, 2016. DOI:10.21437/Interspeech.2016-1066 [13] T. Fukada, K. Tokuda, T. Kobayashi, and S. Imai,
“An adaptive algorithm for mel-cepstral analysis of speech,” ICASSP-92: 1992 IEEE International Con- ference on Acoustics, Speech and Signal Processing, vol.1, pp.137–140, 1992. DOI:10.1109/ICASSP.1992.
225953
[14] M. Wester, Z. Wu, and J. Yamagishi, “Multidimen- sional scaling of systems in the voice conversion chal- lenge 2016,” 9th ISCA Speech Synthesis Workshop, pp.38–43, 2016. DOI:10.21437/SSW.2016-7 [15] R. Sonobe, S. Takamichi, and H. Saruwatari, “JSUT
corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis,” arXiv preprint, 1711.
00354, 2017.
[16] HTS Working Group, “The NITech Japanese speech database NIT ATR503 M001,” May 29 2019. http://
hts.sp.nitech.ac.jp/archives/2.3/HTS-demo NIT- ATR503-M001.tar.bz2
[17] S.S. Stevens, J. Volkmann, and E.B. Newman, “A scale for the measurement of the psychological magni- tude pitch,” J. Acoust. Soc. Am., vol.8, no.3, pp.185–
190, 1937. DOI:10.1121/1.1915893
[18] S.S. Stevens and J. Volkmann, “The relation of pitch to frequency: a revised scale,” The American Jour- nal of Psychology, vol.53, no.3, pp.329–353, 1940.
DOI:10.2307/1417526
[19] E. Zwicker, “Subdivision of the audible frequency range into critical bands (frequenzgruppen),” J.
Acoust. Soc. Am., vol.33, no.2, p.248, 1961. DOI:10.
1121/1.1908630
[20] H. Traunm¨uller, “Analytical expressions for the tono- topic sensory scale,” J. Acoust. Soc. Am., vol.88, no.1, pp.97–100, 1990. DOI:10.1121/1.399849 [21] B.C.J. Moore and B.R. Glasberg, “Suggested formu-
lae for calculating auditory-filter bandwidths and ex- citation patterns,” J. Acoust. Soc. Am., vol.74, no.3, pp.750–753, 1983. DOI:10.1121/1.389861
[22] B.R. Glasberg and B.C.J. Moore, “Derivation of au- ditory filter shapes from notched-noise data,” Hear- ing Research, vol.47, no.1, pp.103–138, 1990. DOI:10.
1016/0378-5955(90)90170-T
[23] T. Irino and R.D. Patterson, “A dynamic compres- sive gammachirp auditory filterbank,” IEEE Trans.
Audio, Speech, Language Process., vol.14, no.6, pp.2222–2232, 2006. DOI:10.1109/TASL.2006.874669 [24] A.H.-S. Chan and S.-I. Ao, Advances in industrial engineering and operations research, Springer, 2008.
DOI:10.1007/978-0-387-74905-1
[25] 赤桐隼人,森勢将雅,入野俊夫,河原英紀,“スペクトル ピークを強調したF0適応型スペクトル包絡抽出法の最適 化と評価,”信学論(A),vol.J94-A, no.8, pp.557–567, Aug. 2011.
[26] 入野俊夫,河原英紀,R.D. Patterson,“聴覚における スケール分析のための末梢系フィルタバンクのウェーブ レット性と非線形性,”数理解析研究所講究録,vol.1928, pp.27–57, 2014.
[27] LightstoneR, “非線形フィット関数の一覧|データ分析・
グ ラ フ 作 成 Origin|ラ イ ト ス ト ー ン ,” May 29 2019.
https://www.lightstone.co.jp/origin/flist2.html [28] K. Levenberg, “A method for the solution of certain
non-linear problems in least squares,” Quarterly of Applied Mathematics, vol.2, no.2, pp.164–168, 1944.
[29] 池田 央,統計ガイドブック,新曜社,1989.
(2019年5月30日受付,9月30日再受付,
12月16日早期公開)
小川 樹
2019年山梨大学工学部コンピュータ理 工学科を卒業.現在,山梨大学大学院医工 農学総合教育部工学専攻コンピュータ理工 学コースに在籍中.音声の音色加工に伴う 劣化に関する研究に従事.
森勢 将雅 (正員)
2008年和歌山大学大学院システム工学 研究科博士後期課程修了.関西学院大学 博士研究員,立命館大学助教,山梨大学大 学院総合研究部特任助教・准教授を経て,
2019年4月より明治大学総合数理学部先 端メディアサイエンス学科専任准教授.博 士(工学).主に,音声・聴覚情報処理に関する研究に従事.日 本音響学会,情報処理学会各会員.