平成
19
年度
学士学位論文
形式概念分析を用いたテキスト分類の検討
A Proposal of Text Classification
using Formal Concept Analysis
1080418
森木 彰規
指導教員
吉田 真一
2008
年
3
月
7
日 提出
要 旨
形式概念分析を用いたテキスト分類の検討
森木 彰規
形式概念分析は束論をもとにして提唱されているデータ分析手法である.この手法では分 析対象(オブジェクト),対象の属性を概念表に表し,そこからHasse図を作成し,概念間の 半順序関係を表す.そのため数値データで表現することなく視覚的にオブジェクト間の関連 性を調査することができる.本研究では,大量のリンクや文書が無秩序に配置されたWeb ページに対して,形式概念分析を用いてテキスト分類を行うことで,テキストを階層構造に 整理し,テキストの要約や主題の推定への応用を検討する.本論文では,英文テキストに対 して形式概念分析を実行し,テキスト分類の実験を行う.テキストには英文のニュース記事 データベースReuters–21578を採用し,各記事をテキストファイルに保存したものを用い る.各テキストファイルをオブジェクト,各テキストの単語を属性としたコンテクストを作 成し,形式概念分析支援ソフト「Concept Explorer」を利用して概念束に表す.表示された 概念束を調査した結果,英文では必然的に使用される前置詞や冠詞というテキスト内容を示 さない単語が概念束の上位層に位置し,多くのテキストで共用されていた.逆にテキスト内 容に関わる名詞や一般動詞は概念束の下位層に位置し,2∼4のテキストで共通していた.ま た今回の実験では,“said”が概念束の上位に位置したが,これは英文のニュース記事では発 言者名を記事中に必ず明記するためと考えられ,このことから,概念束の上位に名詞や一般 動詞といった重要単語が表れた場合,その単語はテキスト全体の分野やジャンルといった傾 向を表すもので,また概念束の下位の重要単語はテキスト間のより詳細な関連性を表すとい うことを確認している. キーワード 形式概念分析,テキスト分類,概念束Abstract
A Proposal of Text Classification
using Formal Concept Analysis
Akinori Moriki
Formal concept analysis, visualizing relations among objects by partial order rela-tion, is a data analysis method based on lattice theory. The method is used Hasse’s diagram which is generated by a 2–dimensional table consisted of objects and attributes. In this thesis, formal concept analysis is applied to articles included in Reuters–21578 for obtaining main subjects and summarization of the articles. Objects are the news articles, and attributes are words included in all of the article. Concept lattice is con-structed with Concept Explorer, the software for formal concept analysis. In the result, prepositions and articles, such as “a”, “an”, and “the”, are located on high layer of the concept lattice. This situation indicates that prepositions and articles are common words for many news articles. They are, however, not suggestive for news contents, since those words are not meaningful. On the other hand, nouns and verbs are gen-erally meaningful words, and they are suggestive for news contents. Those words are located on low layers of the concept lattice, and are common for 2 to 4 articles. However, “said” appears on high layer of the concept lattice. This causes by the name of speaker in news. Therefore, nouns and verbs appeared on high layer are indicate tendencies of all articles, and nouns and verbs appeared on low layer indicate relation and association among texts.
目次
第1章 はじめに 1 第2章 形式概念分析 3 2.1 形式概念分析の基礎概念 . . . 3 形式概念分析の例題 . . . 6 2.2 形式概念分析の応用例 . . . 8 第3章 形式概念分析を用いた英文テキストの分析 10 3.1 実験に用いる英文テキスト . . . 10 3.2 コンテクスト表の作成 . . . 11 3.2.1 英文テキストからの単語の抽出 . . . 11 3.2.2 コンテクストデータのCSVファイルの作成 . . . 11 3.3 概念束図の表示 . . . 12 概念束表示までの手順 . . . 13 第4章 実験 14 4.1 実験結果と考察 . . . 14 4.1.1 実験結果 . . . 14 概念束 . . . 14 概念束描画の処理時間 . . . 15 4.1.2 考察 . . . 16 第5章 おわりに 24 謝辞 26目次
図目次
2.1 表2.1より得られる概念束(concept lattice) . . . 4 2.2 概念(concept)の構成[5] . . . 5 2.3 表2.2の概念束 . . . 8 3.1 手法全体の流れ . . . 13 4.1 テキスト10個の概念束 . . . 16 4.2 テキスト15個の概念束 . . . 17 4.3 テキスト20個の概念束 . . . 18 4.4 テキスト25個の概念束 . . . 19 4.5 テキスト30個の概念束 . . . 20 4.6 テキスト35個の概念束 . . . 21 4.7 テキスト40個の概念束 . . . 22 4.8 テキスト45個の概念束 . . . 23 4.9 テキスト50個の概念束 . . . 23表目次
2.1 コンテクスト表の例 . . . 4 2.2 コンテクスト表(例題) . . . 7 3.1 CSVファイルの内容の例 . . . 12 4.1 テキスト数ごとの概念束表示に要した時間 . . . 15 4.2 計算量の増大 . . . 15第
1
章
はじめに
掲示板サイトのスレッド一覧などのWebページでは,大量の文章やリンクがあるため, 必要な情報をすぐに取り出すことができない.そのようなWebページで,必要な情報のみ を表示し,不要な情報は見えなくすることで文章やリンクの量を削減し,さらにその情報を 階層的に整理することできれば,ユーザはより効率的に大量の文書から情報を取得できるよ うになる.そこで,ユーザに表示する情報を取捨選択し,情報を整理する必要がある.大量 の文章やリンクのあるWebページでは,内容がほとんど同じであるような文章やリンクが 存在する場合がある.そのような類似した文書が複数存在する場合に冗長な部分を省くこと で,情報整理を行うが,文書間の類似度を判定する方法として,文書を特徴ベクトルで表 し,そのベクトル間の距離に基づく方法があり,広く用いられている.しかし,この方法で は,文書を数値化する必要があり,表現の個人差などによりそれが困難な場合もある.一方, 形式概念分析とは,1981年にドイツのDarmstadt工科大学のRudolf Wille教授により提 唱された手法である.これは,既存の類似度判定である距離判定のように特徴ベクトルを必 要とせず,分析対象を行,対象の性質を列においた2次元の表の内容で表される包含関係の 半順序構造を Hasse図で表したものに基づいて類似性を調査する手法である.形式概念分 析では,この2次元表をコンテクスト表と呼び,また表における行の分析対象をオブジェク ト,列の対象の性質を属性と呼ぶ. 本研究では,この形式概念分析を用いてテキスト分類を行う.形式概念分析を行うには, 文書の数値化は必要ないが,文書について多くの属性を定義し,それぞれの文書にその属性 があるか否かを決める必要がある.本研究では,この属性を「単語」とし,各文書がその単 語を含むか否かにより,属性を定義する.このようにして各文書間の半順序関係を明らかする.その適用対象として,本論文では英文のニュース記事 [2]を分析対象すなわちオブジェ クトとする.その対象とする記事から使用されているすべての単語を取り出し,属性とす る.そしてオブジェクトを行,属性を列として形式概念分析に必要なコンテクスト表のもと になるデータを作成し,形式概念分析の支援ソフトConcept Explorer[3]で,コンテクスト 表を作成する.続いてこのソフトウェア上で表したコンテクスト表の各セルの内容の半順序 関係をHasse図上に表す.このとき,表示されるHasse図を概念束と呼ぶ.この概念束を調 査し,テキスト分類へ応用できる点を考察する.英文のニュース記事を分析対象とする記事 に含まれる単語を属性として,形式概念分析を行い,表示された概念束を調査し,上位層に 現れる単語の傾向,下位層に現れる単語の傾向を調べ,上位層には冠詞や前置詞といった意 味を持たない単語が,また下位層には,文書の意味を示す重要な単語が現れることを示す. 本論文の構成として第2章で形式概念分析の基礎概念と応用例について述べ,第3章では 英語の文書からの単語の抽出方法など,形式概念分析による英語の文書の分析を行うための 手順について述べる.第4章では,第3章で記述した手順の分析を実験用のテキストデータ を用いて実際を行い,それから得られた結果や事実よりテキスト分類への応用に関して考察 を行う.そして最後に,第5章で本論文の内容をまとめ,今後の課題と将来の展望を示す.
第
2
章
形式概念分析
本章では形式概念分析の基礎概念について説明する.形式概念分析は表2.1に示したコン テクスト表と呼ばれる表の内容に基づいて,図2.1に示した概念束と呼ばれるHasse図に表 し,分析する手法である.これによって,コンテクスト表の各セルにおける状況を半順序関 係で視覚的に確認することができる.2.1
形式概念分析の基礎概念
形式概念分析はコンテクスト表を作成することから始まる.コンテクスト表とは,行に分 析の対象,列に対象の特性を表した表である.行に表示される分析対象をオブジェクト,列 に表示される対象の特性を属性と呼ぶ.表の各セルにおいてセルの行に対応するオブジェク トがセルの列に対応する属性をもつ場合,そのセルに×
が記入される.各オブジェクト または各属性の持つ×
の包含関係をHasse図のノードに半順序関係で表したものが概念 束である.この包含関係は,オブジェクトに着目した場合,そのオブジェクトがもつ属性の 包含関係であり,属性に着目した場合,その属性をもつオブジェクトの包含関係である.次 にこの概念束に関して説明していく.概念束はコンテクスト表のオブジェクトと属性のそれ ぞれの視点からの×
の配置状況をオブジェクト集合と属性集合の組で表し,それをHasse 図の各ノードに配置したものである.概念束に表すことによってデータ間の半順序関係を可 視化することができる. 次に,図2.1を例に概念束の見方を説明する.上端と下端のノー ドではオブジェクト集合と属性集合のうちの片方の集合が空集合であり,もう片方の集合が すべての要素を含む全体集合である.概念束ではオブジェクト集合は最下端で空集合とな2.1 形式概念分析の基礎概念 a b c d 1
× ×
2× ×
3×
4×
×
表2.1 コンテクスト表の例: node(concept)
({1,2,3,4}, empty)
({2,3}, {c})
({2,4}, {d})
({1,4}, {b})
({2}, {c,d})
({4}, {b,d})
({1}, {a,b})
(empty, {a,b,c,d})
図2.1 表2.1より得られる概念束(concept lattice) り,下方から上方にかけて要素が加えられていき,逆に属性集合は上方から下方にかけて要 素が加えられ,最後に図の上下端のような集合の組ができる.図2.1の例では上端のノード ではすべてのオブジェクトのもつ属性はないことを表し,下端のノードではすべての要素を もつオブジェクトはないことを表す.次にノード ({2}, {c,d})とノード ({4}, {b,d})に着 目する.ノード({2}, {c,d})はオブジェクト{2}は属性{c,d}をもち,ノード({4}, {b,d}) はオブジェクト {4}は属性{b,d}をもつことを表す.この2つのノードの上位にはノード2.1 形式概念分析の基礎概念
concept
A
B
Object
Attribute
Extent
Intent
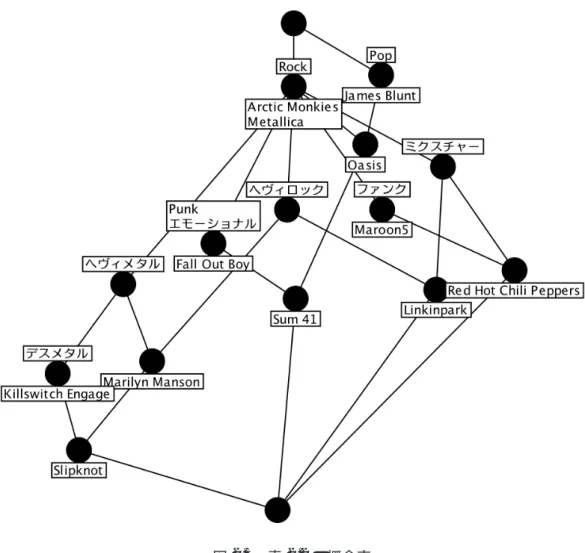
図2.2 概念(concept)の構成[5] ({2,3}, {c})とノード({2,4}, {d})がある.この2つのノードは,オブジェクト{2,3}は属 性{c}をもつこと,オブジェクト{2,4}は属性 {d}をもつことをそれぞれ表すが,ノード ({2,3}, {c})は下位に位置するノード({2}, {c,d})の要素を含み,ノード({2,4}, {d})は ノード ({2}, {c,d})と({4}, {b,d})の要素を含む.このことから上位に位置するノードは 下位に結合するノードの要素で共通していることが分かる.すなわち,概念束では上方に向 かうにつれてより多くのオブジェクトで共通する属性が分かり,逆に下方に向かうにつれて より多くの属性をもつオブジェクトが分かる.今回,図2.1では各ノードに含まれるすべて のオブジェクト集合と属性集合を示したが,一般的にはその要素の加えられたノードのみ に記される.そのため,オブジェクトの要素は上方に向かって,属性の要素は下方に向かっ て加えられていくことを考慮に入れると,例えばノード ({2,3}, {c})の場合では,下位に ノード({2}, {c,d})が位置し,すでにオブジェクト{2}が加えられていることから,ノード ({2,3}, {c})は一般には({3}, {c})と示される.ノード({2,4}, {d})は下位にてオブジェ クト{2}{4}がすでに加えられているため,このノードでは属性{d}のみ示される.反対 にノード ({2}, {c,d})では上位のノード({2,3}, {c})とノード({2,4}, {d}) ですでに属性 {c}{d}が加えられているため,ここではオブジェクト{2}のみが示される.形式概念分析2.1 形式概念分析の基礎概念 では,概念束のHasse 図上のノードを概念と呼ぶ.この概念は,外延と内包の組で構成さ れる(図2.2).外延はHasse図の各ノードにおけるオブジェクト集合を示し,内包は同様の 属性集合を示す.例えば,ノード({2,3}, {c})はオブジェクト集合{2,3}を外延,属性集合 {c}を内包とした1つの概念であるといえる. 形式概念分析の例題 12のアーティストをオブジェクト,9の音楽ジャンルを属性として形式概念分析を行った 場合を例に挙げ,そのコンテクスト表や概念束に関して説明する.表2.2にコンテクスト表 を表示する.各セルの
×
は,各オブジェクトにおけるそのアーティストに当てはまると考 えられる属性のセルに記入している.表 2.2のコンテクスト表をもとに表した概念束を図 2.3 に示す.概念束の上位に ({Arctic Monkeys,Metallica}, {Rock})と({James Blunt},{Pop})の2つのノードが存在する.ノード({Arctic Monkeys,Metallica}, {Rock})の下 位に結合するノードはすべて属性集合 {Rock}で共通し,ノード({James Blunt}, {Pop}) の下位に結合するノードは属性集合 {Pop}で共通する.その下方のノードも下位のノード に対して同様のことがいえる.概念束では,各ノードは下位に結合するすべてのノードで共 通する属性集合とすべてのノードで含まれるオブジェクトをもつ.また同時に,上位に結合 するすべてのノードに含まれる属性集合も有する.このことから,概念束を通して音楽ジャ ンルにおけるアーティストの特性をうかがうことができる.例えば,概念束の上方にノード ({Arctic Monkeys,Metallica}, {Rock})とノード ({James Blunt}, {Pop})が存在するこ とからオブジェクトの各アーティストの音楽ジャンルはRockとPopに大きく分けられるこ とが分かる.またノード ({Arctic Monkeys,Metallica}, {Rock})の下位に位置するノード に含まれる属性集合{デスメタル},{ヘヴィメタル},{Punk,エモーショナル},{ヘヴィ ロック},{ファンク},{ミクスチャー}はRockのサブジャンルとなる.そしてオブジェ クトの各アーティストは,上位のノードで加えられている属性集合の音楽ジャンルをもつ. 例えば,ノード({Slipknot})では上位に属性{Rock},{デスメタル},{ヘヴィメタル},
2.1 形式概念分析の基礎概念 Po p Ro ck へヴィメタル Punk ミクスチャー ファンク デスメタル ヘヴィロック エモーショナル Sum 41 × × × ×
Red Hot Chili Peppers × × ×
Oasis × ×
Linkinpark × × ×
Killswitch Engage × × ×
Fall Out Boy × × ×
Slipknot × × × × Marilyn Manson × × × Arctic Monkeys × Maroon5 × × Metallica × James Blunt × 表2.2 コンテクスト表(例題) {ヘヴィロック}が含まれている.これは,SlipknotはRockを主体にヘヴィメタル,デス メタル,ヘヴィロックというジャンルに属することを意味する.また,ノード ({Sum 41}) では上位に属性{Rock},{Punk,エモーショナル},{Pop}が存在することから,Sum 41 はPunk・エモーショナルといったジャンルを扱い,Popの要素を併せ持った楽曲を得意と するRockアーティストであることが推測できる.
2.2 形式概念分析の応用例
図2.3 表2.2の概念束
2.2
形式概念分析の応用例
形式概念分析はテキストマイニング,心理学,教育学などの様々な分野に対して応用され ている.その中で実際にシステムとして稼働している例としてテキストマイニングへの応 用事例であるCREDO[4]というシステムが存在する.これはClaudio CarpinetとGianni Romano の2人によって開発された Web検索システムである.このシステムでは,検索 結果の文書の内容を概念クラスタの束によって分類を行う.この分類処理に適用される形 式概念分析は,検索結果の文書をオブジェクト,検索キーワードを属性として行われる. Web検索には現時点で試行されているバージョンではYahoo!が用いられている.このため, CREDOによって検索が行われた場合,それぞれの Web検索結果が類似するWebページ
2.2 形式概念分析の応用例
Googleなどの一般の検索システムよりも検索キーワードを反映したWeb検索ができ,目的 の文書の記載されたWebページを探索することがより容易となる.
第
3
章
形式概念分析を用いた英文テキスト
の分析
本研究では,英文テキストの単語における半順序関係を形式概念分析により概念束で表 し,その結果からテキスト分類や要約への応用を検討する.そのために,英文テキストに対 して形式概念分析を行う実験を行う.形式概念分析は,英文のテキストファイルをオブジェ クト,テキストで使用されている単語を属性とする.本章では,この実験の手法に関して説 明する.3.1
実験に用いる英文テキスト
実験に用いる英文テキストには,Web上で研究目的に対して無償配給されているニュー ス記事のデータ集 Reuter–21578, Distribution 1.0[2]を使用する.ファイルデータはすべ てSGML形式で記録されているため,本文に記述されている<BODY>· · ·</BODY>の 部分をそれぞれ「*.txt」形式のファイルに保存する.この保存したtxtファイルを実験用の 英文テキストとして使用し,形式概念分析のオブジェクトとする.3.2 コンテクスト表の作成
3.2
コンテクスト表の作成
3.2.1
英文テキストからの単語の抽出
形式概念分析を行うために,単語をオブジェクトの英文テキストから1単語ずつすべて抽 出し,属性とする.まず,オブジェクトとするテキストファイルを選択し,その pathを設 定し,そのファイルの内容を取得する.次に取得したテキストの単語をすべて1つずつ配列 に格納し,重複するものは削除する.この単語の配列を属性として利用する.以後,この配 列を属性配列と呼ぶ.そして,属性配列とは別にテキストファイルの単語を重複するものも 含めすべて配列に格納する.以後,この配列をオブジェクト配列と呼ぶ.3.2.2
コンテクストデータの
CSV
ファイルの作成
コンテクストのデータはCSVによって表す.あらかじめ,空のCSVファイルを作成し, これに書き込む方法を用いる.次から,その手順に関して説明する. 3.2.1にて作成した属性配列とオブジェクト配列を用いて,CSVファイルに書き込むコン テクストKを作成する.このコンテクストも配列で実現する.以後,この配列をコンテク スト配列と呼ぶ.コンテクスト配列の要素はコンテクスト表を表すように格納していく.最 初に属性を表示するために属性配列の要素をまずコンテクスト配列に格納する.それ以降 は,コンテクストKの内容を格納していく.次に,その格納方法を説明する.属性配列の単 語をオブジェクト配列の単語と比較していき.単語が一致すれば1,そうでなければ0を格 納していく.コンテクストの内容の格納方法を行列で表すと,以下のようになる. K = ⎡ ⎢ ⎢ ⎣ w0,0 · · · w0,attr−1 .. . . .. ... wobj−1,0 · · · wobj−1,attr−1 ⎤ ⎥ ⎥ ⎦ (3.1) objはオブジェクトであるテキストファイルの数,attrは属性の数(属性配列の要素数)を表 す.wはコンテクスト表の各セルに入るオブジェクトと属性の間の関係を表す.コンテクス ト内容を格納する際,属性配列とオブジェクト配列を比較する.比較の処理は,各セルにお3.3 概念束図の表示 ,Showers,continued,throughout,· · ·,hotels text 1,1,1,1,· · ·,0 text 2,0,0,0,· · ·,0 text 3,0,0,0,· · ·,0 text 4,0,0,0,· · ·,0 text 5,0,0,0,· · ·,1 表3.1 CSVファイルの内容の例 ける列mの属性の単語を行gのオブジェクトのテキストのすべての単語と比較していくこ とで行う.オブジェクト配列にはオブジェクトのテキストファイルの単語がすべて格納され ているため,各テキストファイルの単語数を算出しておくことで,オブジェクト配列の単語 を各テキストファイルごとに区別する.この属性とオブジェクトの比較処理をwobj-1,attr-1 までそれを行う.格納を終えたコンテクスト配列の要素をセルごとに区切るために,各要素 の間に「,」を挿入する.最後に完成したコンテクスト配列をCSVファイルに書き込む.な お,書き込まれたCSVファイルの内容例を表3.1に示す.
3.3
概念束図の表示
概念束の表示には Web 上でオープンソースとして公開されている Concept Explorer version 1.3[3]を用いる.Concept Explorerはウクライナ工科大学の大学院生Yevtushenko によって開発された形式概念分析の支援ソフトである.Concept Explorerはコンテクスト の編集,編集されたコンテクストからの概念束図の描画を主な機能とする.3.2.2で作成し たCSVファイルをConcept Explorerのコンテクスト表に開き,ソフトその内容を読み込 ませ,概念束を表示させる.
3.3 概念束図の表示
CSV
text 1
text 2
Concept Lattice
. . . .
text N
Concept Explorer
context
図3.1 手法全体の流れ 概念束表示までの手順 本章で説明してきたテキスト分析の流れの概要を示す. 1. オブジェクトとするテキストファイルを設定する 2. プログラムを実行し,コンテクストのデータを作成し,指定したCSVファイルにそれ を書き込む 3. Concept Explorerを起動し,作成したCSVファイルを開く 4. 開いたCSVファイルに基づいてコンテクスト表が表示される 5. 概念束表示の機能を使用し,概念束を描画する第
4
章
実験
英文テキストに対して形式概念分析を適用し,概念束を表示しテキスト中の単語における テキストの半順序関係を表し,その結果からテキスト分類や要約への応用を検討する.本章 では,これらの実験とその結果の考察に関して述べる.4.1
実験結果と考察
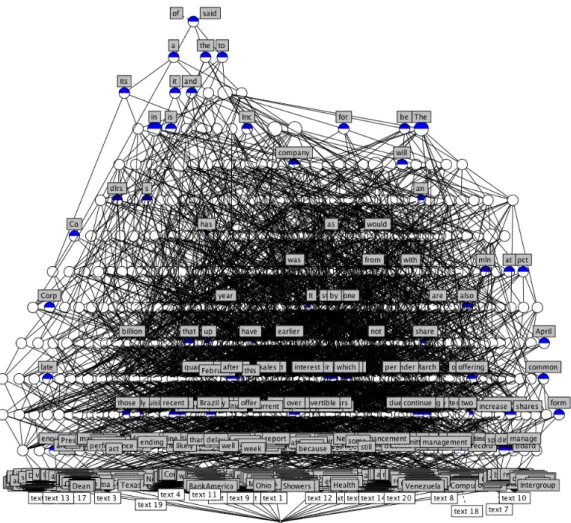
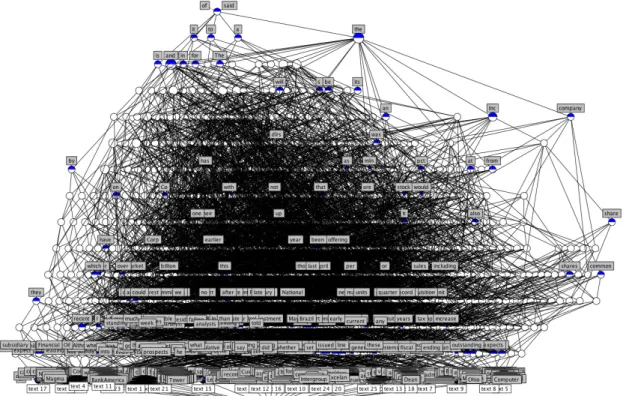
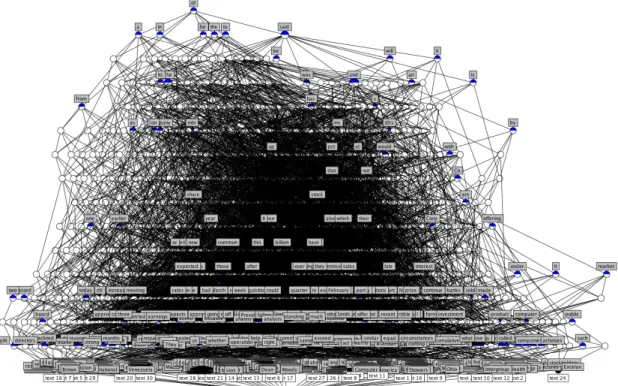
オブジェクトとしてテキストを10個から始め,5個ずつ加えていき50個までに対して形 式概念分析を行い,概念束を描画した.以下にテキストを各個数ごとに形式概念分析にかけ た結果,表示された概念束図を図4.1∼図4.9に示す.4.1.1
実験結果
概念束 分析結果を示した各図より,2つの点が明らかになった.1つは分析を行ったテキストは それぞれ前置詞や冠詞,代名詞の概念で共通している場合がほとんどの割合を占め,束の上 位層に多く見られるということである.またテキストそのものを示す概念はすべて概念束の 最下層から2番目の層に個別に存在し,それより上位の層には現れない.その結果,各テキ ストにおける使用頻度の高い前置詞,冠詞,代名詞などの単語では多くのテキストに共通す るが,テキスト内容を示す単語はそのテキストのみに含まれる場合と,2∼4の記事で共用さ れている場合に集中している.もう1つは,前置詞や冠詞と違い,固有の意味を示す名詞や4.1 実験結果と考察 テキスト数 計算時間 10∼20 3∼5分 30 約40分 40 約4∼5時間 50 約9∼10時間 表4.1 テキスト数ごとの概念束表示に要した時間 コンテクスト表の大きさ(n×n) 1×1 2×2 3×3 · · · n×n 最大ノード数 2 4 8 · · · 2n 表4.2 計算量の増大 に見受けられるという点である.その中でも一般動詞の “said”を含む概念は束の最上位も しくは上位の第2層に位置している. 概念束描画の処理時間 Concept ExplorerでCSVファイルのコンテクストデータから概念束を描画する際,処 理するテキスト数および量が増加するにつれて計算量が増大していき,処理時間が長期化し ていった.テキスト数が10∼20のときは最長5分程度であるが,30を境目に処理時間が急 激に増大する.テキスト数が 30のときは概念束表示までに約 40分,40のときは概念束表 示までに約4∼5時間を要する.テキスト数が50のときに至っては約 9∼10時間を要する. この内容を表 4.1に示す.今回はテキスト50個に形式概念分析を行う場合までの概念束を 表示しているが,形式概念分析はテキスト60個まで行った.概念束そのものはテキスト数 が50のときとほぼ等しい時間で表示される.しかしテキスト数が増加するにつれて,計算 量が増大するため概念束の描画の処理時間の他,概念束の編集,保存といった処理も困難に なった.テキスト 60個のときには,システムのリソースがほぼなくなり,概念束図の保存 ができなかった.
4.1 実験結果と考察 図4.1 テキスト10個の概念束
4.1.2
考察
前置詞や冠詞,代名詞などの単語は多くのテキストで使用されているが,テキストの内 容を表す固有名詞などの単語は 1∼4のテキストで使用されている場合がほとんどであった. このことから,1つのテキストでのみ使用されている単語は除き,2∼4のテキストで共通し ている単語の含まれる概念をもつ概念束の層に着目することで,テキスト内容を連想させる 固有の意味合いを持つ単語におけるテキスト間の関連性を調査することができ,複数のテキ ストの主題を割り出すことが可能となる.また,一般動詞の“said”が上位第1∼2層に位置 したことについてであるが,これは,今回の実験ではロイターのニュース記事のテキストを 用いたことに起因する.英文ニュースでは発言内容を記述する場合,発言者の名前が明記さ れるためである.今回このような結果が出たことから,テキスト全体がある傾向をもってい4.1 実験結果と考察 図4.2 テキスト15個の概念束 従って,上位層において名詞や一般動詞といった単語を含む概念を探し出し,調べることで テキストを分野ごとに分けることができるものと考える. また概念束描画の際に対象のテキスト数が増えるごとに処理時間が増大していた件に関し て,その要因を調査した.ここでは,コンテクスト表をn×nとした場合のnの値ごとのコ ンテクスト表の大きさにおける概念束のノード数の最大数を計算した.その内容を表 4.2に 示す.その結果,コンテクスト表の大きさ,すなわちnの値が1ずつ増加する度に最大ノー ド数が2n と指数オーダーで増加していくことが分かった.このことから,概念束の元とな るコンテクスト表の大きさが増大することにより,概念束表示における計算量は急激に増大 していくものと考えられ,現時点の形式概念分析における重要な問題点となり,その解決が 急務となる.
4.1 実験結果と考察
4.1 実験結果と考察
4.1 実験結果と考察
4.1 実験結果と考察
4.1 実験結果と考察
4.1 実験結果と考察
図4.8 テキスト45個の概念束
第
5
章
おわりに
本研究では,Webページなどのテキストデータの情報整理を行うために,数値からの類 似度判定ではなく半順序関係からの判定を行う形式概念分析を用いてテキスト分類を行い, テキストの要約や主題の割り出しへの応用を検討している.今回は,英文のニュース記事[2] を実験用のテキストとしている.実験では各記事を分析対象,対象とした記事全体で用いら れている単語を属性とするコンテクスト表を用いている.表示された概念束では,まず,オ ブジェクトである個々のテキストは全て最下層に位置し,そして,概念束の上位層では,前 置詞や冠詞といった英文ではほぼ必ず使用される単語が多く位置する.一方,下位層ではテ キスト内容を連想させる名詞や一般動詞といった単語が位置する.この下位層に位置する単 語は,2∼4のテキストで共通する場合に集中している.しかし,中には,上位層に一般動詞 の“said”が位置するという例外も確認している.これらの結果より,オブジェクトの含ま れる概念層よりも 2∼4階層上位の層に着目すれば,よりテキスト間の関連性を詳細に調査 することができる.すなわち,名詞や一般動詞などの固有な意味合いを持ち,記事内容を連 想させる単語が集中している下位層を重点的に調査することで,テキスト間のより詳細な関 連性が分かる.一方,“said”が上位層に位置するという例外が存在するが,これは用いたテ キストが発言した人物名を必ず明記する英文のニュース記事であることが原因であると考え る.英文の記事では発言を記述する場合,「∼ said」と発言者名を明記するためである.この ことから,概念束の上位層に位置する名詞や一般動詞はオブジェクトとしたテキスト全体の 傾向を表すものであると考えることができる.したがって,概念束の上位層を調べ,名詞や 一般動詞を探し出すことでテキストの分野ごとに分けることが可能となると考える.今後はすることでテキスト間の関連性を階層構造化しテキストの要約や主題の選択などへの応用が 期待できる. 今回の実験結果では,最高50個のテキストを形式概念分析にかけた場合の概念束までを 表示しているが,実際にはテキスト60個の場合まで実験を行っている.しかし,テキスト 60個のときのコンテクスト表の概念束をConcept Explorer[3]において描画する際,概念 束表示の計算量があまりにも膨大となり,最終的にはテキスト60個以降のデータを採取を できない.今回得た概念束を描画する際もテキスト数が増加するとともにデータ採取までの 時間が長くなった.そのため,テキストに形式概念分析を行う際,前置詞,冠詞,代名詞な どテキスト内容の把握に対して期待できない単語は,コンテクストの属性の対象からは除外 することにより,コンテクスト表のデータ量削減を図ることが必要であると考える.また, より大容量のデータ処理が可能なソフトウェアを作成することも必要であると考える.さら に,より良いテキスト分類のためには,コンテクスト作成において,属性に単語だけではな く熟語も取り込み,よりテキスト内容に精通した概念束を描画する必要もある.
謝辞
本研究にご協力いただいた皆様へ心から感謝の意を表明いたします.御指導していただい た吉田真一先生と岡本一志さん,本当にありがとうございました.粗悪な自分のために最後 まで御二人の手を煩わしてしまいました.誠に申し訳ありませんでした.今回の卒業研究 で,自身が論文を書くことが非常に下手であることが分かりました.特に日本語の表現には かなりの問題があることが判明しました.自分でもなぜ今まで日本人でいられたのか不思議 なくらいです.また,研究も前田君のようには中々はかどらせることもできず,最後まで先 生に頼り切りという状態でした.自身は努力をしていると勘違いをしていただけで,全くの 自惚れであったことが分かり,自分の人間としての質の低さを痛感しています.こうして思 い返してみれば,良いといえるものが1つもなかった私ですが,吉田先生にはあと2年間, ご迷惑をおかけすることになります.本来は自分のような人間には修士に進む資格はないこ とは承知しておりますが,よろしくお願いします.これからは今回の卒業研究で浮き彫りと なった様々な課題を少しでも克服していく所存です.岡本さんにはこの1 年間お世話にな りっぱなしでした.研究室のレイアウト,ネットワーク環境の整備,我々4年生と3年生の 指導など,今年度から始動したこの吉田研究室にとって,岡本さんの存在は非常に大きなも のでした.今この研究室が普通に機能しているのも岡本さんの獅子奮迅あってのものだと思 います.東京工業大学でも頑張って下さい. そして,研究の副査を引き受けていただいた高田喜朗先生と妻鳥貴彦先生,お疲れ様で す.そして,ありがとうございました.ご自分の研究室の学生の研究で忙しい中,私の劣悪 な梗概を読ませてしまい,さぞ御不快な思いをさせてしまったことであると存じます.誠に 申し訳ありません.高田先生には,梗概をお見せした際に,私の研究によってどうすること ができるのかなど,上手に説明できない点を指摘していただき,ありがとうございます.妻 鳥先生にも,ご自身の研究室の学生の卒研で多忙を極めていたにも関わらず,副査を担当し ていただき,本当にありがとうございました.謝辞 研究室で苦楽を共にした前田豊文君と鈴木慎也君にも,色々とお世話になりました.前田 君には自分の研究での愚痴の相手になっていただきました.また,あなたの持ち前の明るさ によって,何かにつけて消極的になりやすい自分を勝手ながら元気づけさせていただきまし た.研究もとてもよく頑張っておられ,その姿勢は非常に自分のよき手本となりました.鈴 木君とは,共に研究が中々はかどらない者同士で,ある意味ではかなり苦労を共にしたよう に感じます.卒研発表の前日は本当に大変でしたね.この苦労が将来何かの形で報われるこ とを祈るばかりです. また,3年生諸君は来年度,とうとう卒業研究の年となります.この1年は今までで最も 時間の流れを早く感じる1年となり,特に8月あたりからは嵐のように時間が過ぎていくこ とでしょう.今年度1 年間を通して我々4 年の卒業研究を見てきた者は分かるでしょうが, 研究は早期に開始した方が本当にいいです.研究の開始に早すぎることは全くありません. 今年の私の有り様のように,3年生の皆さんには同じ轍を踏まないで欲しいです.最後に, 来年もよろしくお願いします.こちらも諸君をしっかり指導できるように頑張っていく所存 です.
参考文献
[1] Bernhard Ganter TU Dresden, Formal Concept Analysis : Methods and Applica-tion in Computer Science, 2002
[2] Reuters-21578 Text Categorization Collection
http://kdd.ics.uci.edu/databases/reuters21578/reuters21578.html [3] Yevtushenko, Concept Explorer version 1.3
http://sourceforge.net/projects/conexp [4] C. Carpinet, G. Romano, CREDO
http://credo.fub.it/
[5] 鈴木治,室伏俊明,“形式概念分析 –入門・支援ソフト・応用–, ”日本知能情報ファジィ 学会誌,vol. 19,no. 2,pp. 103–142,2007.