分散共有メモリ型組込みシステムにおける遅延性能確保とコア割付け自由化に関する一手法
2
0
0
全文
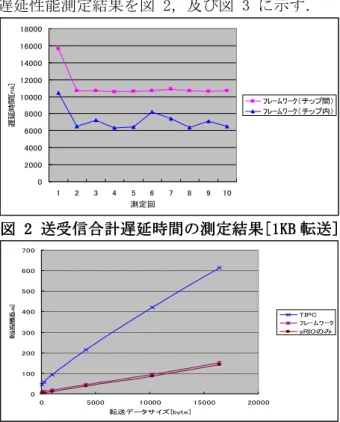
(2) 情報処理学会第 74 回全国大会. 場合,再度自動生成すると受信バッファは CPU#2 のメモリ上 B’の位置へ移動し,CPU#0 のタスク A が call する API の内部はそれまでのチップ内通 信から,宛先 CPU#2 の B’へのチップ間通信へ変 更される.ここでタスク B のコア割付け変更に 際して,タスク A,B 共にコードを修正する必要 は無くなった.. sRIO ドライバ単体での遅延時間に比べ,フレー ムワークを適用した遅延時間はいずれのデータ 長においても一定の数 us のオーバヘッドしか観 測されなかった.TIPC の遅延時間と比べると約 1/4~1/5 の値であった.. 5. 考察. 遅延性能の測定結果は,ほぼ期待通りの低遅 延を実現できた.測定は全て 1 回のデータ転送 によるものであり,CPU#2 で受信データを返送す 遅延性能測定の構成について述べる.チップ間 の測定では2つの CPU#1/#2 間を sRIO で接続し, る際コアによるコピーが発生しない為,全デー タ長で同様のオーバヘッドになったのは予想通 CPU#1 から送信したデータを CPU#2 で折り返しそ りである.sRIO はハードによる送達確認機構を のまま CPU#1 へ返送する構成において,CPU#1 で 持つ等 GbE に比べ元々遅延性能に優れる[2]為, データ送信前から返送データ受信後までの所要 TIPC より結果が良いのは想定済である.初回の サイクル数を測定し時間に換算し 1/2 にした. チップ内の測定は同様の事をコア間で実施した. 測定結果が悪い結果になっているのは API がキ ャッシュミスした為と思われる.自動生成によ 評価環境にはチップ内・チップ間の DMA を複数 り経路毎個別の API を生成している為, 1 箇所 チャネル具備するマルチコア CPU を OS 無しで使 のドライバコードで全経路分を処理する場合に 用した.尚,参考の為に TIPC について,同程度 比べ,i キャッシュはミスする確率が高い.生成 の処理能力の CPU に Linux を載せ GbE で 2 台対 するコードのバイナリを極力 1 キャッシュライ 向させて同様の測定を実施した.尚,チップ間 ンに収める工夫を行ってはいるが,使用におい sRIO は実運用より遅い 1.25GHz×1 レーンで使用 ては無闇に 1 コアが扱う転送経路数を増やしす し,比較対象の TIPC で使用した GbE と物理的に ぎない様,アプリ設計に注意が必要であろう. 同条件にした. 一方,コア割付け変更の容易性については, 目的は達成されたが,弊害も出た.コア割付け 4. 性能評価結果 変更やバッファサイズ・数変更により,割付変 遅延性能測定結果を図 2,及び図 3 に示す. 更当事者でないコアについても受信バッファの 18000 16000 アドレスが変わり,その都度全 CPU で再ビルド 14000 が必要となった.これについては自動生成ツー 12000 ルのバッファ割付アルゴリズムを修正すること 10000 フレームワーク(チップ間) である程度軽減することができたが,フルメッ フレームワーク(チップ内) 8000 シュのトポロジを許容する仕組みである以上, 6000 4000 完全に避ける事はできない問題である. 遅延時間[ns]. 3. 性能評価方法. 2000 0 1. 2. 3. 4. 5 6 測定回. 7. 8. 9. 6. 結論. 10. 図 2 送受信合計遅延時間の 送受信合計遅延時間の測定結果[1KB 測定結果[1KB 転送] 転送] 700 600. 本稿のフレームワークを開発したことにより, 遅延性能目標とタスクのコア割付け変更の容易 化を両立させる事ができ,開発効率化に効果が あった.. 転送遅延[us]. 500 400. 7. 参考文献. TIPC フレームワーク sRIOのみ. 300. [1] “TIPC Home Page”, http://tipc.sourceforge.net/ [2] “Serial RapidIO vs 10Gigabit Ether” http://www.idt.com/content/facn_idt_feb2011 _Print.pdf. 200 100 0 0. 5000. 10000. 15000. 20000. 転送データサイズ[byte]. 図 3 TIPC とのチップ とのチップ間転送遅延比較 チップ間転送遅延比較. 1-26. Copyright 2012 Information Processing Society of Japan. All Rights Reserved..
(3)
図
関連したドキュメント
および皮膚性状の変化がみられる患者においては,コ.. 動性クリーゼ補助診断に利用できると述べている。本 症 例 に お け る ChE/Alb 比 は 入 院 時 に 2.4 と 低 値
耐震性及び津波対策 作業性を確保するうえで必要な耐震機能を有するとともに,津波の遡上高さを
層の項目 MaaS 提供にあたっての目的 データ連携を行う上でのルール MaaS に関連するプレイヤー ビジネスとしての MaaS MaaS
補助 83 号線、補助 85 号線の整備を進めるとともに、沿道建築物の不燃化を促進
本案における複数の放送対象地域における放送番組の
据付確認 ※1 装置の据付位置を確認する。 実施計画のとおりである こと。. 性能 性能校正
⼝部における線量率の実測値は11 mSv/h程度であることから、25 mSv/h 程度まで上昇する可能性
定的に定まり具体化されたのは︑
