聴衆のプレゼンテーション理解を促進するロボット
の非言語動作の検証
Evaluating Nonverbal Behavior of Presentation Robot for Promoting Audiences’
Understanding
後藤 充裕
1*石野 達也
2稲澤 佳祐
2松村 成宗
1布引 純史
1柏原 昭博
2Mitsuhiro Goto
1*, Tatsuya Ishino
2, Keisuke Inazawa
2, Narimune Matsumura
1,
Tadashi Nunobiki
1,
and Akihiro Kashihara
21
NTT サービスエボリューション研究所
1NTT Service Evolution Laboratories
2電気通信大学 大学院情報理工学研究科
2
Graduate School of Informatics and Engineering, The University of Electro-Communications
Abstract: In presentations, nonverbal behavior of presentation robots such as gaze and gesture are so important for inducing the audiences to direct their attention to the contents presented and promoting audiences' understanding. However, the effects of these nonverbal behavior to the audiences that has not been clarified. This paper proposes a presentation recomposition method, which sets appropriate non-verbal behavior for robots in presentation. We also reports the diffrence of effects of the robots’ and virtual agents' nonverbal behavior in presentation to the audiences.
1. はじめに
近年,ビジネスにおける企画説明や商品紹介,大 学における講義や e-Learning など様々な場面にお いてプレゼンテーションを実施する機会が増加して いる.一般に,プレゼンテーションとは,プレゼン タが事前に作成したスライド(以下,スライドコン テンツ)を投影し,口頭での説明(以下,オーラル コンテンツ)を通して,聴衆の理解・納得を得るた めの情報伝達手段の1 つである.このようなプレゼ ンテーションを分かりやすく実施するためには,上 述した2 種類のコンテンツを提示するだけではなく, 聴衆の注意をプレゼンタが意図しているコンテンツ に集め,コンテンツ内の情報の重要度や論理展開な どの情報の関係性を正しく伝えることが重要となる. これらを効果的に実施するには,プレゼンタがアイ コンタクトやジェスチャといった非言語動作を活用 して,意図しているコンテンツへ聴衆の注意を誘導 したり,重要性や関係性といった説明しようとして いる情報の特徴を伝達する必要がある.しかしなが ら,プレゼンテーション中にこれらの非言語動作を 適切に用いることは学生や新入社員といった経験の 浅いプレゼンタだけではなく,大学講師や企業の管 理職といったある程度経験を持ったプレゼンタにと っても難しい.その結果,聴衆への情報伝達が不十 分なまま,プレゼンテーションを終えてしまうこと が多々ある. そこで,筆者ら[1]は,プレゼンタの代わりにロボ ットが内容理解を促進する非言語動作を伴わせてプ レゼンテーションを実施するプレゼンテーション代 行ロボットについて研究を進めている.これらの研 究では,プレゼンタがどのような意図(以下,動作意 図)を持って非言語動作を行い,ロボットがプレゼン テーションで利用可能な各種動作の表現要素(以下, 基本構成要素)を組み合わせて,プレゼンテーション 中に実施すべき動作を導き出すための「プレゼンテ ーション動作モデル」をデザインしてきた.そして, このモデルに基づき,プレゼンタによる非言語動作 が適切に用いられているかを診断し,不十分・不適 切な動作が存在する場合にはプレゼンテーションを 再構成し,ロボットに代行させるプレゼンテーショ ンシステムの開発を進めている. 本稿では,プレゼンテーションにおける非言語動 作活用の必要性と問題点を整理し,モデルに基づく プレゼンテーション再構成について述べる.さらに, *連絡先: NTT サービスエボリューション研究所 人工知能学会研究会資料 SIG-ALST-B509-03プレゼンテーション代行における注意誘導や重要点 理解を促進する非言語動作が聴衆に与える影響を調 査することを目的に,プレゼンテーションロボット とバーチャルエージェント(以下,VA)による非言 語動作を比較するケーススタディを行い,ロボット がVA に比べて,プレゼンタとして分かりやすい印 象を聴衆に与えることを確認した.
2. プレゼンにおける非言語動作
本章では,プレゼンテーションにおける非言語動 作の必要性や問題点,内容理解を促す非言語動作例 を詳述する.2.1 非言語動作の必要性
通常,プレゼンテーションの実施には,プレゼン タが聴衆に伝えたい情報を,キーワードや図表など で端的に表現したスライドコンテンツと,そのスラ イドコンテンツを補足説明するオーラルコンテンツ を用いる.プレゼンタは「説明している情報の重要 性」や「複数の情報間の関連性」などを聴衆に認識 してもらうために,アニメーションやテキスト効果 によりスライド中の一部を強調表現することが多い. しかしながら,プレゼンタがこれらのコンテンツ内 で意図的に強調したプレゼンテーションを実施して も,聴衆がその強調に気付けないことがある.その 結果,聴衆に情報伝達が不十分なままプレゼンテー ションを終えてしまうことになる.また,聴衆がプ レゼンタによる表現の強調に気付いた場合にも,「ど の程度重要であるのか」や「どういった関係性があ るのか」といったように,プレゼンタの意図の詳細 を理解する情報がスライドコンテンツやオーラルコ ンテンツに陽に表現されていない場合には,情報の 理解が十分に進まないことがある. そこで,プレゼンタは,アイコンタクトやジェス チャなどの非言語動作を用いて,プレゼンタの意図 したコンテンツに注意誘導を行うことで,「オーラル に注意を向けて情報を聞いて欲しい」などの動作意 図を伝えようとする.この点は,有馬[2]による研究 においても示唆されている.有馬によると初任教師 と熟練教師の授業中での視線行動と思考について比 較しており,熟練教師は意図的な視線行動を多く実 施すると分析されている. また,聴衆に提示してい る情報の重要性をポインティング動作によるジェス チャで表現することで,「今,説明している情報が重 要である」といった動作の意図の詳細を伝えたプレ ゼンテーションを行うことが多い.このように分か りやすいプレゼンテーションには非言語動作の活用 が必要であると言える.2.2 問題点
しかしながら,多くのプレゼンタにとって,プレ ゼンテーション中に非言語動作を適切に行うことは 難しい.例えば,学生や新入社員といったプレゼン テーションの経験が浅いプレゼンタは,オーラルコ ンテンツを正確に話すことに終始してしまい,非言 語動作を伴いながらプレゼンテーションを実施する 余裕がないことが多い.大学講師や企業の管理職と いったある一定のプレゼンテーション実施機会があ り,経験を持ったプレゼンタにおいては,非言語動 作を伴ったプレゼンテーションを行うことができる が,アイコンタクト時の顔向きやジェスチャ実施時 の腕の角度が不十分となり,聴衆に動作意図を伝え ることのできる動作までに至らないことが多い.ま た,手元のPC や投影しているスクリーンを凝視し, 聴衆へのアイコンタクトなどの非言語動作がおろそ かとなってしまうこともあり.この結果,聴衆への 情報伝達が不十分なままプレゼンテーションを終え てしまうケースが発生する. さらに,これらの非言語動作を過剰に用いること も問題となる.例えば,1 枚のスライドコンテンツ の説明の中で,プレゼンタが重要点を指し示すため のジェスチャ動作を多用してしまうと,そのスライ ド中で一番重要な箇所が伝わらず,聴衆の理解を阻 害してしまうことに繋がる.従って,プレゼンテー ション中の非言語動作は,適切な箇所で適切な頻度 で利用する必要がある.2.3 動作意図を伝える非言語動作
前節で述べた問題の解決に向けて,プレゼンタの 動作意図を伝えるための非言語動作について整理す る.本研究では,図 1 に示した通り,プレゼン中の 動作意図は,以下の 3 つに大別でき聴衆の状態に応 じて変化と考えている. 意図 1(状態 1→状態 2 の変化を促す): 聴衆にプレゼンテーション自体への興味を 持たせる. 意図 2(状態 2→状態 3 の変化を促す): プレゼンタの伝えたいコンテンツへ聴衆の の注意を向けさせる 意図 3(状態 3→状態 4 の変化を促す): 聴衆にコンテンツを詳細に理解させる. そして,本研究では,プレゼンタが動作意図の切 替えを考える機会として,(1)プレゼンテーションの 準備中と,(2) プレゼンテーションの実施中がある と考えている.本研究で主な対象とする(1)の機会で は,プレゼンタが発表内容や発表場所,対象となる聴衆の属性などを基に,聴衆の状態変化を仮定して, 動作意図の切替えを検討していく.特に学会発表の ようなモチベーションの高い聴衆では状態3 以降が 多くなると仮定して,より情報の詳細を理解しても らうような伝達意図の切替えを行うことが多い.
2.3.1 意図 1:聴衆の興味を促す非言語動作
聴衆がプレゼンテーションへ興味を持ち,耳を傾 けてもらうためには,プレゼンタが聴衆に対して語 りかけているような印象や何か面白そうだとインパ クトを与える必要がある.これらを実現するには, 聴衆の頷きに合わせて発話タイミングやジェスチャ の開始タイミングを合わせたり,ビデオや音楽とい ったマルチメディアの利用,大げさなジェスチャに よるオーバーアクションを用いて,聴衆にプレゼン テーションへの興味を持ってもらうことが考えられ る.2.3.2 意図 2:注意を誘導する非言語動作
聴衆がプレゼンテーションを聞きながら,プレゼ ンタが伝達したい箇所に注意を向けさせるためには, プレゼンタがある時点で,スライドコンテンツとオ ーラルコンテンツのうち,どちらのコンテンツに注 力して説明をしているかを聴衆に伝える必要がある. Kamide ら[3]の研究では,ロボットプレゼンタの顔 や視線方向の制御により聴衆の注意をスライドコン テンツへ誘導可能なことを示唆している.これを踏 まえて,本研究ではプレゼンタの顔や視線の向きを 活用した聴衆の注意誘導を実現する.つまり,プレ ゼンテーション実施時にプレゼンタがスライド方向 へ顔向きや視線を移すことにより,聴衆の注意をス ライドコンテンツに誘導する.これにより,聴衆の 視線はスライドに向けられることが期待できる.逆 に,プレゼンタが聴衆方向へ顔の向きや視線を移す ことにより,聴衆の視線はスライドから外れ,聴衆 の注意をプレゼンタに誘導する.これにより,プレ ゼンタの発話しているオーラルコンテンツに対して 注意を向けさせることができる.2.3.3 意図 3:理解を促進する非言語動作
プレゼンタが特に伝達したい箇所の詳細を聴衆に 理解させるためには,プレゼンタの説明を補足する 情報を伝える必要がある.McNeill[4]は,非言語動 作が人同士のコミュニケーションを円滑にすること を明らかにし,実際にコミュニケーションで用いら れる身振り・手振りのジェスチャ動作の形態や機能 をもとにした分類観点を提案している.本研究では McNeill の分類した 3 タイプのジェスチャを補足し たい情報に合わせて使い分けていく. (a)Deictic: 重要箇所など注目して欲しい対象を指定 する,指差しなどのポインティングジェスチャ (b)Iconic: 説明している情報の大きさや長さを 手の動きで表現するジェスチャ (c)Metaphoric: 説明している複数の情報の間にある 順序関係を立てた指の数で表現したり,大小関係 を手の動きにより表現するジェスチャ これらのジェスチャは,プレゼンタの説明してい る情報の重要性や関係性,内容の具体化などの詳細 を聴衆に伝え,内容理解の促進に寄与すると考えら れる.3. ロボットによるプレゼン代行
本章では,前章で述べたプレゼンタの動作意図と その意図を正しく聴衆に伝える非言語動作との対応 関係をデザインしたプレゼンテーション動作モデル と本モデルに基づく再構成手法について述べる.3.1 プレゼンテーション動作モデル
本モデルは,動作意図と動作カテゴリ,プレゼン テーションの基本構成要素の 3 層で構成され,これ らの対応関係でプレゼンテーション時の非言語動作 の組み合わせを決定するモデルである(図 2).具体 的には,プレゼンタの思い描く「動作意図」と,ロ ボットが利用可能な「基本構成要素」を入力として, ロボットが分かりやすいプレゼンテーションを実施 する上で,必要となる非言語動作の組み合わせを「動 図 1 聴衆の状態に応じたプレゼンタの伝達意図 図 2 プレゼンテーション動作モデル作カテゴリ」として出力し,ロボットによるプレゼ ンテ−ション代行時に適切な非言語動作を用いてプ レゼンテーションを実施可能になる.
3.2 プレゼンテーション再構成手法
本研究ではロボットによるプレゼンテーションと して,プレゼンタの動作を忠実に再現するのではな く,プレゼンテーション動作モデルと照合しながら, 不十分・不適切な動作を診断・再構成し,必要に応 じてプレゼンタ自身による非言語動作の再修正を行 いながら,プレゼンテーションを代行する. 本手法の特徴として、プレゼンタ個人の癖や個性 を残しつつ,内容理解を促す非言語動作を再構成し たプレゼンテーション代行を行う点がある.従来研 究では,Chien-Ming ら[5]により動的ベイジアンネッ トワークを用いたロボットの発話するオーラルに合 わ せ て 自 動 的 に 非 言 語 動 作 を 付 与 す る 手 法 や Hanani[6]により SVM や Random Forest を用いてプレ ゼンテーションの上手さを判定する手法が提案され ている.これらの研究では,機械学習により,事前 学習したデータを基に非言語動作の自動付与やスキ ル判定を実現しているが,学習データに依存する点 が多く,学習結果を用いて全てのプレゼンテーショ ンに適用することは難しい.プレゼンテーションは, 発表する文脈や場所に応じて的確な振る舞いは異な り,その的確さを一意に定義することができない. そこで,本研究では,プレゼンタの動作をより効果 的に代行するために再構成を行うアプローチを採る. 本手法は3 つのステップで再構成を行う. ステップ1:動作意図の推定 ステップ2:モデル照合による診断・再構成 ステップ3:再構成結果のフィードバック ステップ1では,プレゼンタが聴衆を前にせずに 実施したプレゼンテーションのみを入力として,プ レゼンタがどのような動作意図を持っているかを推 定する.現状では,プレゼンタの実施した動作やス ライドコンテンツ,オーラルコンテンツ内のキーワ ードを分析して伝達意図の推定を行っている.その ため,推定できる伝達意図は「プレゼンタの伝えた いコンテンツへの集中」と「コンテンツの詳細を理 解(重要点の強調)」となっている. ステップ2では,推定した伝達意図をプレゼンテ ーション動作モデルと照合しながら,不十分・不適 切な動作を診断・修正する.「プレゼンタの伝えたい コンテンツへの集中」の意図では,プレゼンタの意 図した方向にしっかりと顔や視線を向けているかを 診断し,向きが不十分な場合には,それらを再構成 する.「コンテンツの詳細を理解(重要点の強調)」 の意図では,プレゼンタが意図している情報をしっ かりとポインティングしているかを診断し,ポイン ティング時の腕の角度や顔向きが不十分な場合には, それらを再構成する. ステップ 3 では,ステップ 2 での動作の再構成結 果をプレゼンタへフィードバックし,不適切な修正 があれば,プレゼンタ自身で再度修正を行い,最終 的なプレゼンテーション動作を決定する.プレゼン タが全く意図していない方向へ顔や視線を向けるよ うな不適切な修正がされている場合には,それらを プレゼンタが手動で修正して,ロボットによるプレ ゼンテーション代行を実施する.本手法ではこれら ステップを経て,プレゼンテーションの再構成を実 現する.4. ケーススタディ
ケーススタディとして,プレゼンテーション代行 において,注意誘導や重要点を強調する非言語動作 が聴衆へ与える印象やプレゼンテーション内容理解 への影響について,10-60 代の男女 20 名(男性:11 名,女性:9 名)を実験参加者として調査した.4.1 ケーススタディ環境・条件
図3 に示す通り,プレゼンタとして,プレゼンテ ーションロボット(Sota[7])と Unity[8]上で動作する バーチャルエージェント(VA)の 2 種類を用意した. これらプレゼンタはR-env[9]経由で制御され,スラ イドの表示タイミングや非言語動作のタイミング, 発話内容などを統一している.プレゼンテーション 中のプレゼンタの大きさや位置が極力同じになるよ うに,Sota を台に設置したり,VA の表示サイズを 調整している.また,スライドの表示位置やサイズ についても,両プレゼンタで同様となるようにして いる.そして,ケーススタディは図3 下部の実施イ メージに示す通り,実験参加者1 名に対して各プレ 図 3 ケーススタディで利用した各プレゼンタゼンタがプレゼンテーションを実施する形態を取っ た.各プレゼンタが実施する非言語動作は,M1:顔 向きによる注意誘導とM2:ポインティング動作によ る重要点の強調であり,強調時には,スライド上部, 中部,下部をそれぞれ指すようになっている.また, プレゼンテーションに用いるスライドコンテンツは, C1: 環境問題と C2: 電力問題に関するものであり, 各スライドの構成や記述量などを出来るだけ統一し て,筆者らが作成した.そして,C1 のプレゼン時に は,M1: 顔向きによる注意誘導,C2 のプレゼン時 には,M2: ポインティング動作による重要点の強調 を行うことにした.
�4.2 ケーススタディ手順
上述した環境を用いて,表1 に示す通り,プレゼ ンタと非言語動作のカウンタバランスを考慮して, 被験者を4 グループに分け,調査を行った.実験開 始前に,被験者に対して「ロボットと VA によるプ レゼンを見て,その印象に関するアンケート回答を 行う.また,プレゼンテーション終了後に,各スラ イドで印象が強かったり,重要だと思ったキーワー ドを書き下す作業を行ってもらう」という指示を与 えた.印象評価アンケートは,ロボットと VA で同 一の非言語動作によるプレゼンを見た後(試行2 回 目終了時と試行4 回目終了時)に実施した.印象評 価アンケートの質問項目は以下に示す通りである. � Q1:全体的にプレゼンテーション内容が分かりやす いと感じたプレゼンタはどちらでしたか? Q2:スライドに注意を向けるタイミングが分かりや すいと感じたプレゼンタはどちらでしたか? Q3:スライド中の注目すべき箇所が分かりやすいと 感じたプレゼンタはどちらでしたか? Q4:スライド中の重要な箇所が分かりやすいと感じ たプレゼンタはどちらでしたか? Q5:集中してプレゼンテーションを聞きやすいと感 じたプレゼンタはどちらでしたか? Q6:自分自身に語りかけているように感じた プレゼンタはどちらでしたか? Q7:顔向きや手の動きがプレゼンを聞く妨げになら なかったプレゼンタはどちらでしたか? Q8:プレゼン中に視線が合っていると感じた プレゼンタはどちらでしたか? Q9:プレゼンを聞き続けることができると感じた プレゼンタはどちらでしたか? 参加者には,各質問項目に対して6 段階(極めて ロボット,かなりロボット,どちらかと言えばロボット,どちらかと言えばVA,かなり VA,極めて VA)
での回答を求めた.また,自由記述による回答も許 可した.また,プレゼン終了後に行う各スライドの キーワードの書き下し作業は,実験参加者に対して, 各プレゼンタ条件でのプレゼンを十分に聞いてもら うために与えたタスクである.
4.3 ケーススタディ結果・考察
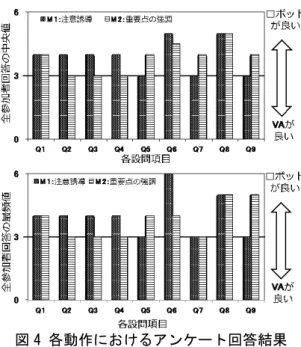
全実験参加者によるM1 と M2 の各質問への回答 結果に対して,「極めてロボット」を6 として,1 つ ずつスコアを減らしていき,「極めてVA」を 1 とし て集計して,各質問項目の結果の中央値と最頻値を グラフ化した結果を図4 に示す.スコアが 4 以上の 場合,ロボットの方が良く,3 以下の場合,VA の方 が良いという印象を参加者に与えていることになる. また,キーワードを書き下す作業結果より,全参加 者が各プレゼンタ条件で十分にプレゼンを聞いた上 で,アンケートに回答していることを確認した. 図4 に示した結果から M1 と M2 のどちらの非言 語動作においても,Q1, Q6, Q8 といった項目につい ては,それぞれスコアが4 以上となり,ロボットが 良い傾向にあることが分かる.「VA がスライドと同 一のバーチャル空間に居て,プレゼンタというより, スライドの背景という印象を持った」という自由記 述の回答もあり,スライドとは別空間にいるロボッ トの方が実際のプレゼンタという認識を持って,聴 衆がプレゼンを聞けることを示唆している. 一方で,非言語動作の違いにより回答結果が異な る傾向が見受けられた.「Q2〜Q4」について M1 で はロボットが良い印象,M2 では VA が良い印象を与 える傾向を得た.スライドに注意を向けるタイミン グや注目すべき箇所を聴衆に伝える上で,M1 の動 作では,動きが大きく顔向きの変化が分かりやすい ロボットが好まれた.自由記述回答でも「VA に比べ て,ロボットは顔向きを変える際の動きが大きく感 じられた」,「顔向きを変えることで視線が外れたの がはっきり分かった」といった回答を得ている.逆 にM2 の動作では,ロボットよりも重要点を細かく ポインティングできる VA が好まれた.自由記述回 答でも「ロボットに比べて,スライド中のどの箇所 を見るのかがきちんと指し示されていた」,「ポイン ティング時にスライドの上部,中部,下部がはっき りと区別できた」といった回答があった.ロボット 条件では,VA に比べて腕が短かったこともあり,ポ 表 1 各グループにおけるケーススタディ条件インティング動作がどこを指し示しているのが分か り辛かったことが要因となったと考えられる. ` 「Q5, Q9」について考えると,M1 では VA の方 が良い印象,M2 ではロボットの方が良い印象を与 える傾向となった.集中してプレゼンを聞いたり, プレゼンを継続的に聞くことを考えた場合に,M1 の動作では,動きが小さくスライドから注意を逸ら しにくいVA が好まれた.「ロボットはモーター音が 気になり,説明の声が聞きにくかった」,「ロボット の向きが動くたびに,スライドからロボットに目を 向けてしまうことがあった」という回答からもロボ ットの動きが目立つことにより,聴衆の集中に影響 したことが示唆される.逆にM2 の動作では,視覚 的にスライドと重なりにくく,プレゼンタとスライ ドのどちらに目を向けるかを聴衆がコントロールし やすいロボットが好まれた.「スライドを見ていて, VA の手の動きに集中をしてしまった」といった回答 もあり,スライドを見ている際の VA の動きが聴衆 の集中に影響したと考えられる.以上をまとめると, プレゼンテーションを代行するプレゼンタとして, 実空間上で存在感のあるロボットは VA に比べて分 かりやすく聴衆に語りかけているような良い印象を 与えることができる傾向にあった.非言語動作の観 点では,視覚的や聴覚的な存在感が高まるほど,ス ライドへの注意誘導や注目すべき箇所を聴衆に伝え ながらプレゼンを代行できるが,これらの存在感が 高まり過ぎると逆にノイズとなってしまうことにな り,聴衆のプレゼンへの継続的な集中に対して影響 が生じることが示唆された.これらのことから,プ レゼン代行における適切な非言語動作の再構成には, 視覚的・聴覚的なノイズとならない範囲を見極めな がら動作を設定していく必要がある.
5. まとめ
本稿では,プレゼンテーションにおける非言語動 作活用の必要性と問題点を整理し,プレゼンタの動 作意図とロボットが利用可能な基本構成要素の対応 関係から定義したプレゼンテーション動作モデルに よるプレゼンテーション再構成手法について述べた. さらに,プレゼンテーション代行における注意誘導 や重要点理解を促進する非言語動作が聴衆に与える 影響を調査することを目的に,ロボットとVA の非 言語動作が聴衆に与える影響についてケーススタデ ィについて述べた.ケーススタディの結果から,ロ ボットが聴衆にとって分かりやすく,よりプレゼン テーションを聞いているという印象を得ることので きるプレゼンタであることが明らかになった.一方 で,非言語動作の観点では,視覚的や聴覚的な存在 感が適切な場合には注意誘導や重要点の強調に寄与 するが,これら存在感が高まり過ぎると聴衆のプレ ゼンへの集中に対してノイズとなってしまうことが 分かった.今後の課題は,開発したシステムによる プレゼンテーション再構成に関する評価や重要点の 強調以外の非言語動作の表現方法の考案がある.参考文献
[1] 後藤充裕.: プレゼンタ動作を再現・再構成するロボ ットプレゼンテーションシステム, JSiSE 2017 年度 第 5 回研究会,Vol.32, No.5 pp.121-128 (2018). [2] 有馬 道久.: 授業過程における教師の視線行動と反 省的思考に関する研究, 広島大学大学院教育学研究 科紀要, Vol.63, pp. 9-17(2014).[3] Kamide, H.et al.:Nonverbal behaviors toward an audience and a screen for a presentation by a humanoid robot, Artificial Intelligence Research, Vol. 3, No. 2, pp. 57-66(2014).
[4] McNeill, D.: Hand and Mind. The University of Chicago Press(1992).
[5] Chien-Ming, H. et.al .: Learning-based modeling of multimodal behaviors for humanlike robots, Proc of HRI 2014, pp. 57-64 (2014).
[6] Hanani, A. et.al.: Automatic Estimation of Presentation Skills Using Speech, Slides and Gestures, Proc of SEPCOM 2017, pp. 181-192 (2017).
[7] VStone.: Sota, https://sota.vstone.co.jp/home/.
[8] Unity Technologies.: Unity - Game engine, tools and multiplatform. https://unity3d.com/jp/unity.
[9] 松元崇裕ら.: 「R-env:連舞 TM」クラウド対応型イン
タラクション制御技術, 2017 年度人工知能学会全国 大会予稿集(2017).