Web 情報探索行動時の視線情報に基づくユーザー属
性の推定
著者
今田 真平
学位授与機関
Tohoku University
指導教員(主査)
:和田裕一 准教授
Web
情報探索行動時の視線情報に基づく
ユーザー属性の推定
東北大学大学院 情報科学研究科
人間社会情報科学専攻 認知心理情報学分野
今田真平
2020
年
2
月
10
日
概要
本研究の目的は,Web情報探索行動時の視線情報のみからユーザーの属性を直接推定することが可能かど
うかを検証することである.推定するユーザー属性としてSimulated Work Task Situationsの3種類のタス
ク(Factual, Interpretive, Exploratory)とBIG5パーソナリティ(Neuroticism, Extraversion, Openness,
Agreeableness, Conscientiousness)を設定した.実験では学部生,大学院生合わせて72名を対象に3種類 の情報探索タスクを遂行してもらい,その際の視線行動を記録した.各タスク中の視線データの代表値を用い たデータセットに対して多項ロジスティック回帰で分析した結果,パーソナリティに対して一定の予測力を持 つモデルを作成できることが示された.また,分割窓を設定して細かい時間で分割した視線データセットを用 いてRandom Forest識別器で分析を行った結果,タスクに対して高い予測力を示した.本研究の結果はユー ザー属性をWeb情報探索時の視線行動から推定することが可能であることを示すと同時に,特定の時間情報 を考慮する必要があることを示唆する.
目次
第1章 序論 3 1.1 本研究の目的 . . . 3 1.2 問題の背景 . . . 3 1.3 本論文の構成 . . . 4 第2章 先行研究 5 2.1 情報探索行動 . . . 5 2.1.1 Web情報探索行動と視線 . . . 5 2.1.2 情報探索行動とタスク . . . 7 2.1.3 従来の情報探索行動の問題点 . . . 9 2.2 ユーザー属性推定 . . . 9 2.2.1 ユーザー属性推定研究 . . . 9 2.2.2 視線情報によるユーザー属性推定 . . . 11 第3章 本研究 14 3.1 本研究の位置づけ . . . 14 3.2 実験概要 . . . 14 3.2.1 被験者 . . . 14 3.2.2 実験器具 . . . 15 3.2.3 実験手順 . . . 16 3.3 データ分析 . . . 18 3.3.1 データの分布. . . 18 3.3.2 各データの関連性 . . . 22 3.4 機械学習モデル. . . 26 3.4.1 特徴量の抽出. . . 26 3.4.2 モデル構築 . . . 30 第4章 推定結果 34 4.1 タスク推定 . . . 34 4.1.1 多項ロジスティック回帰分析 . . . 34 4.1.2 機械学習 . . . 354.2.1 多項ロジスティック回帰分析 . . . 38 4.2.2 機械学習 . . . 41 4.2.3 考察 . . . 49 4.3 全体結果 . . . 50 第5章 結論 52 引用文献 54 謝辞 58
第
1
章
序論
1.1
本研究の目的
本研究の目的はWeb情報探索時の視線情報のみから,ユーザーの属性を推定することが可能かどうかを検 証することである.タスクとBIG5パーソナリティをユーザー属性として設定し,これらの属性を視線情報か ら推定する.この目的を達成するために,注視回数などに着目したデータセットに対して多項ロジスティック 回帰を用いる分析に加え,分析窓を設定して特定の時間で分割したデータセットに対しRandom Forest識別 器を使って分析を行う2種類のアプローチで推定を行う.1.2
問題の背景
1990年代後半から続くインターネットの肥大化に伴い,World Wide Web(以下Web)上のデータ量は爆
発的に増え続けている.平成29年度の総務省の発表によれば,日本国内におけるWeb上のデータトラフィッ
クは2014年以降,指数関数的な上昇を見せている.あらゆる情報がWebにアップロードされ,スマートフォ
ンやPCを使っていつでも,どこからでもインターネットを介して情報にアクセスできるようになってきてい
る.そうして,我々の情報収集の場が図書館などの物理的な環境から,Webというデジタルな環境に徐々に
シフトしている中,InternetLiveStats,SoftwareFindrで公表されている情報によると,今やWeb上に存在
するアクセス可能なWebページの数は2019年時点で約17億ページ,Wikipediaなどのウェブログ*1の数だ けでも2018年には5億ページを超え,今なおその数は増え続けている.また,米国のインターネットメディ アによると世界中でGoogle検索エンジンを利用した検索回数は少なくとも年間2兆回も行われているとされ ている.単純に計算して,1日に55億回以上,世界のどこかでGoogle検索,すなわち情報探索行動が行われ ているということになる. Web上の情報の増加に伴い,明日の天気から経営戦略上の意思決定の材料まで,我々ユーザーの情報要求も 幅広く,我々の日常にとって,Webの存在感は日に日に大きなものとなってきている.そうして多様化,複雑 化するユーザーの情報要求の中で,我々がWeb上の情報をどのように取捨選択して,求める情報を獲得する かという,Web情報探索行動のメカニズムを解明しようとする研究が盛んに行われている.こうした研究の 知見が積み重なるにつれて,Web情報探索行動には探索背景となる情報要求(タスク)やパーソナリティなど の個々のユーザーに関係する属性が,探索の方略に大小さまざまな影響を与えていることが明らかとなってい
る.一方,我々ユーザーの探索行動に着目すると,Web上の情報の信頼性の問題を示す研究(Wathen et al.,
2002)や,大半のユーザーの探索過程では情報源の評価が欠落しているということを示す調査研究(Graham
& Metaxas, 2003)も存在している.そのため,Marzhoukou et al.(2015)が指摘しているように,増え続け
る情報量とユーザーの情報要求の多様化に沿って,そうした個々のユーザーの探索背景や属性を的確に捉え, それらを元に各ユーザーに合った情報探索や評価支援を行っていくことがこれからのユビキタスな社会におい て,より重要となってくるだろう.しかしながら,これまでのWeb情報探索行動から直接ユーザーの属性を 推定しようとする試みは数は非常に少なく,知見が十分とは言えないのが現状である.そのため,ユーザーの 探索行動から属性を推定する方法を探る研究には大きな意義があると言えるだろう. また,こうしたユーザー属性を推定する上では,可能な限り簡便な方法でデータを収集することもまた,重 要となるだろう.本研究では視線情報を指標として,探索中の視線の動きからユーザーの属性を推定する方法 を探る.視線はその人の意図や興味などの内的な状態を反映しているとされ,視線トラッキング技術の向上や 高性能なカメラの大衆化に伴って,視線を指標として情報探索行動のメカニズムを探る研究も多く行われるよ うになってきている.最近では特別な装置を必要とせず,ブラウザやアプリケーションベースで視線の追跡を 可能にするプラグインやソフトウェアも開発されている.情報探索支援を目的として,視線を用いた情報探索 行動研究はこれからも多くなされていくことが予想され,本研究もそうした研究の一助となることが期待さ れる.
1.3
本論文の構成
本論文の構成は以下のとおりである. まず第1章において,本研究の目的と問題の背景について,本研究で用いるアプローチを含めて述べた.続 く第2章では,先行するWeb情報探索行動およびユーザー属性推定に関する研究知見を概観した.第3章で, 本研究における実験方法および収集したデータの内容についての分析結果を紹介し,第4章にて実験で得られ たデータから,統計的,機械学習的なアプローチによるユーザー属性の推定結果を掲載した.最後,第5章に おいて,研究結果に対する議論と本研究の結論および今後の課題について述べた.第
2
章
先行研究
顧客マーケティングや商品レコメンデーションエンジン,ECなどを中心として,従来の画一的( one-size-fits-all)なサービスの提供の仕方から,各ユーザーにパーソナライズされたサービスの提供(personalization) へと移行する動きが活発化している(市川・小林, 2011). そのような背景から,ユーザー属性を推定しようとする試みはこれまでに数多く行われてきた.ユーザー 属性にはユーザーの内部状態に関するものや,外部環境に関するものなど様々なものがある(松尾ら, 2007). これまで,ユーザーの属性として考慮されてきたのは主に年齢や性別などのデモグラフィックな属性であった が,ユーザーの価値観が多様化してきたことで,デモグラフィックな属性だけではユーザーの実態をとらえる ことが難しくなってきたため,興味やパーソナリティなどのサイコグラフィックな属性を用いてユーザーを細 分化し,パーソナライズを実現しようという応用研究が盛んである.また,推定に用いられる情報源も様々で あり,SNSの投稿情報やセンサーから得られた位置情報,視線情報など多様な情報源が使われている.2.1
情報探索行動
近年のWebの急速な発展により,個人が世界中のあらゆる情報にWebを介して簡単触れることができ,一 般の人にとっての情報探索の場は,図書館など物理的な環境から検索エンジンを介したWeb環境にシフトし ている.Webが一般の生活に広く浸透していく中で,世界中に存在するWebページの数は2017年には15 億を突破し,その数は指数関数的に今も増加し続けている.ユーザーはWeb上に存在する大量の情報の中か ら求める情報を探索する必要があり,検索エンジンの性能向上と並行してユーザーの探索行動を支援していくことが強く求められている(Marzhoukou et al., 2015;Takaku et al.,2010).
そのため,情報探索行動という概念にも多くの関心が寄せられており,人はいかにして必要な情報を獲得し ているのかという基盤的な研究から,どのような探索支援を行うべきかといった応用的な領域に対しても,研 究者だけでなく民間の企業も力点を置いて研究を進めている.
2.1.1
Web
情報探索行動と視線
目は心の窓という言葉があるように,目,すなわち視線情報はその人の興味や嗜好など,その人の意思を強 く反映しているとされる.何に注目しているのか,次に何をしようとしているのかといった情報までも,視線の研究で視線情報が用いられている(vanGog el al., 2005; Terai. & Miwa, 2006).また,Webサイトにお けるユーザーインタラクションの改良を目的とした研究でも,視線情報は主要な指標の一つとして活用されて
いる(Nielsen & Jakob, 2009;松延, 2014).このように視線情報というのは様々な研究領域においても有用
な指標として用いられており,情報探索行動研究においても視線は最も精緻なデータの1つとして注目されて
いる(Takaku et al., 2010).
Busher et al.(2012)は検索結果ページ(図2.1)における視線情報,マウス操作およびクエリ情報を利用
してユーザーの行動を調査している.Busher et al.は実験から得られたデータをクラスタリングし,徹底-活
動的(Exhaustive-Active),徹底-受動的(Exhaustive-Passive),経済的(Economic)の3タイプの行動に分
類できることを報告している.また,Granka et al.(2004)も検索結果ページ閲覧中の視線データを分析し,
ユーザーは検索結果順位1位と2位は同程度の時間眺めるが,それ以降順位が下がっていくにつれて,線形に
眺める時間が短くなることを明らかにしている.さらに,Guan & Cutrell(2007)は検索結果の表示順位が
変動することによるユーザーの探索行動への影響を視線情報から調査している.提示された課題の答えが掲載 されているページの順位を段階的に下げてユーザーに提示し,その時の正解ページを発見するまでの時間や視 線の滞留時間を分析したところ,正解ページの順位が下がると課題の遂行時間がより長くなり,正解ページを 発見できる確率も下がるとしている.また視線データからは正解ページの表示順位があがると,注視時間と注 視率が共に上昇することを報告している. 図2.1 Busher et al.(2012)より引用 視線情報を使った情報探索研究では,図2.1のような関心領域(Area of Interest)を設定し,その領域内に どれだけ視線を向けたか等の情報を活用して分析するのが主流である.反対に,関心領域を設定しない実験で は通常,全体としての注視時間や注視回数といった限られた特徴しか分析に使うことができない.そのため情
報探索研究ではその多くが,単一のWebページあるいは上に紹介したような検索結果ページにおける,ペー ジ内の各オブジェクトに関心領域を設定して視線情報を取得する方法がとられている.
2.1.2
情報探索行動とタスク
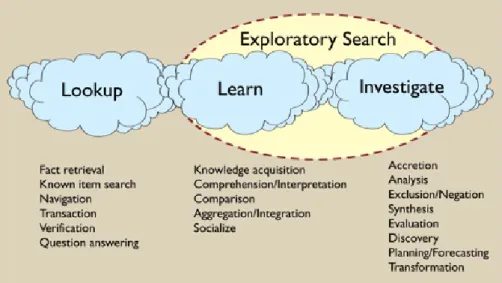
情報探索行動はその目的や志向性などの違いによって,探索時に用いる方略が異なることが知られている (Marchionini, 2006; Kim, 2008;齋藤ら, 2008).うした情報探索の背景のことを情報探索タスク,あるいは 単にタスクと呼ぶ.Marchionini(2006)はWebの発達とともにユーザーの検索エンジンに対する要求も多 様化したことで,情報の探索の仕方が目的によって異なると述べている.雨が降るかどうかといった天気予 報を調べるような,単純に答えを探すだけ(Lookup)のタスクから,引退後のポートフォリオを作成する ため株価や債権に関する情報を収集するなどの複雑(Learn)なタスク,さらには自分のキャリアパスを描 くための情報を探すといった,暗黙的な情報を探索する(Investigate)なタスクの3種類に分類できると述べ,LearnタスクとInvestigateはExploratoty SearchとしてLookupタスクと二分化できるとしている(図
2.2).Marchioniniは,これまでの情報探索行動に関する研究ではLookupタスクのような単純なタスクに焦
点が当てられているが,Web情報探索行動のメカニズムを解明する上では,Exploratoryタスクのような複
雑なタスクを十分に考慮する必要があると述べている.
図2.2 探索タスクの分類(Marchionini,2006より引用)
また,Kellar el al.(2007)は情報探索行動を,事実発見(Fact Finding),情報収集(Information Gathering),
ブラウジング(Browsing),トランザクション(Transaction),その他(Others)の5つに分類し,それぞれ
の情報探索タスクの質的違いにより,探索時間や閲覧ページ数に差異が生じることを明らかにしている. 同じ性質のタスクであっても,その難易度によって視線の動き方が変わってくるという研究報告もある.
Zhou(2017)は同じ性質(答えがWeb上に明示的に存在する)で難易度の異なるタスクを探索中の視線行動
から注視回数や注視時間,最初の検索語を入力するまでの時間などを計測したところ,高難易度のタスクの方 が注視回数や注視時間,入力までの時間が有意に少なく,短くなっていたと報告している.
類の課題(レポート作成のために情報を収集するInformational課題,国内旅行の計画を立てるTransactional
課題)を行わせ,その際の発話内容,トランザクションログ,視線行動といった複数の指標を用いて,課題 の志向性と検索経験の違いが探索行動に与える影響を調べる研究を行っている.その結果,トランザクショ ンログから検索経験の多い大学院生はブラウザのタブを多用する傾向があること,視線行動からは学部生は
Informational課題において1つのページの閲覧時間が長いなど,課題の志向性と経験によって探索行動に
違いがあることを明らかにしている.さらに,Kim(2008)はSimulated Work Task Situationsと呼ばれる3
種類の情報探索タスクを設定し,それぞれのタスクごとの探索方略の違いを調査している.Simulated Work
Task SituationsはFactual,Interpretive,Exploratoryの3種類で構成されており, それぞれ以下のような
定義となっている(表2.1). Factual: 明確な事実に関する情報を見つける Interpretive: 結論が与えられている中で,それを支持する複数の根拠を集める Exploratory: 様々な情報を探索しながら,自ら結論を導き出す これら3つの定義に沿って作成されたタスクを被験者に行わせた結果,検索結果ページの閲覧回数やブック マーク数,検索クエリの修正回数がタスクごとに有意に異なることを報告している. 心理学的なパーソナリティとの関連性を示す研究もある.Heinstr¨om(2003)は298人の大学生を対象に, 自身の研究に関する情報を調べる際の探索行動に関して,批判的に情報を捉えられるか(Critical information
judgement),複数の情報を有機的に繋げられるか(Relavance difficulties),新たな考えを生み出す情報では
なく自分の考えを支持する情報を好むか(Confirmation of previous knowledge),時間に限りがある場合で
も十分に探索ができると思うか(Time pressure as a barrier to information),他の情報に惑わされずに必要
な情報を探索できるか(Aiming to acquire new ideas from retrieved information),どれくらい探索行動に
力を入れるか(Effort),の6つのサブカテゴリ,計70項目からなる独自の質問紙を作成し,BIG5因子を測
定するNEO FFIと合わせて質問紙調査を行い,パーソナリティと情報探索行動が密接に関連していることを
明らかにしている.Heinstr¨omは,情報探索行動に影響を与える要因はパーソナリティだけに限らないと述べ
たうえで,いくつかのパーソナリティは他の要因よりも探索行動に強く作用している可能性について言及して いる.
Kim & Allen(2002)は,被験者の認知スタイルおよび課題解決スタイルをGroup Embedded Figure Test
(GEFT)とProblem-Solving Inventory(PSI)の2種類の質問紙を用いて得点化し,性質の異なる2つの探
索タスク(唯一の答えが存在するか否か)との関連性を検証した.結果,両者の交互作用が一部見られ,コン テクストなど外的要因に影響を受けにくい認知スタイルを持つ被験者の中で,自身の課題解決能力を低く見積
もった人物はWebページにある埋め込みリンクをより頻繁にクリックする傾向がみられたことなどを報告し
ている.
このように,タスクやパーソナリティといったユーザー属性の違いは情報探索行動に大小様々な影響を与え
ることが示されている.特にMarzhoukou(2015)が指摘しているが,従来のWeb探索行動研究ではLookup
タスクをはじめとした比較的単純なタスクのみを対象とした研究が多く,それでは情報探索行動の複雑な側面 を捉えることはできない.また,多くの研究が,探索行動がタスクによってどのように影響を受けるのかを明 らかにしようとしているのに対し,ユーザーが現在どのタスクを行っているのかについて直接推定しようとし た研究はまだない.
表2.1 Simulated Work Task Situations (Kim’s(2008) version)
Type Content
Factual You plan to visit San Francisco next week. One of your friends who has been there
suggests that you visit the oldest seafood restaurant in town. You want to know the name of the restaurant.
Interpretive Your cousin, a typical teenage girl, said that one of her friends had started to smoke. You fear your cousin might begin smoking in the near future and decide to educate her, so you have to find some information on what could happen if she starts smoking.
Exploratory You have recently moved to Boston and you are interested in buying a home. You
have heard that most homes built before 1978 have some lead paint, but that their paint status is often reported as ”unknown.” You think you should learn about lead paint and housing. The Web seems linke a good place to locate this information.
2.1.3
従来の情報探索行動の問題点
以上のように,情報探索行動と視線との関連を見た研究はこれまでに数多く行われていきているが,そのほ とんどが,検索結果ページや特定のWebページに依拠した視線行動を対象としたものである.しかしながら, 齋藤ら(2008)が指摘する通り,情報探索行動というのは検索語を入力し,検索結果画面を眺めた上で,そこ からWebページを開いて情報を探すというプロセスを何度も繰り返し行う過程である.また,実際の探索行 動においては,探索背景となるタスクが異なる場合がほとんであり,仮に同じタスク,同じ情報を探す場合で あっても,人ごとに見るページが異なるのが普通であろう.情報探索行動の全容を明らかにする上では,特定 のページデザインに依拠した視線行動を分析するのでは不十分であると考えられる.また,そのため,特定の 環境に依存しない状況下での,Web情報探索行動と視線情報との関連を調査する必要があると考えられる.2.2
ユーザー属性推定
2.2.1
ユーザー属性推定研究
ユビキタスな情報環境が広がるにつれて,ユーザーの属性を把握し,各ユーザーに応じた情報の提案やサー ビスの提供を目指す動きは情報社会における中心的な課題の一つとなっている(松尾ら, 2007).例えば,Web サイトやブログでよく見る商品広告はユーザーの閲覧履歴や行動履歴から興味のありそうな商品を推測する ことで,各人のニーズに沿った広告が優先的に出現するようになっている.また,センサーを用いてお年寄 りの家の中での移動パターンを把握し,適切な行動支援を行うことを目指した研究も行われている(Mori & Kougo, 2017).現代,ひいては近未来の社会においては,最大公約数的な不特定多数をターゲットとした商 品やサービス,情報支援ではなく,各人の属性,個性に沿って「パーソナライズ」されたサービスが我々の日 常の根幹を支えるようになってくるだろう.機械学習の目覚ましい発達により,ビッグデータと呼ばれる巨大なデータを比較的容易にかつ効果的に取り扱 うことが可能となっており,こういった手法の発展も研究の流れを後押ししていると考えられる.機械学習と は多量のデータの中からパターンを半自動的に学習して,未知のデータを推測する分析手法であり,特徴量と 呼ばれる,データの表現を工夫することでかなりの程度,高い予測精度を出すことも可能であり,近年大いに 注目されている. この流れの中,対象となるユーザー属性も,ユーザーの位置やリソースの使用状況など外部環境に関するも の(Nishiguchi et al. 2009),意図や目的,持っているものといった状態に関するもの,興味や嗜好,性格な
ど性質に関するもの(Al-Samarraie et al., 2016; Hoppe et al., 2018; Seo & Zhang, 2000; You et al., 2016;
Zhuang et al., 2017;天野, 2018; Rew et al., 2018),年齢や性別,職業などのグラフィックな属性に関するも
の(Rao et al., 2010;松尾ら, 2007;佐伯ら,2015)など,多様な属性がフォーカスされている.
Rao et al.(2010)は,Twitterの投稿内容を単語に分解し,出現する語の頻度や意味情報を利用し,ユー
ザーの年齢,性別,出身地,政治的イデオロギーを推定する研究を行っている.Zhuang et al.(2017)の研究
では,FacebookなどのSNSの登録情報および投稿内容から,ユーザーが特定の都市の地理にどれだけ精通し
ているか(location authority)について,social-networkingモデル,time-drivenモデル,location-driven
モデルの3種類の数理モデルを考案し,それらのモデルを用いて推定を行っている.佐伯ら(2015)は訪日観 光客のTwitterの投稿頻度を分析し,特定期間に一定以上の日本国内でツイートを行ったユーザーは在日の外 国人,一定以下なら観光目的で訪日した外国人と識別する手法を提案している. SNSを対象としてユーザー属性を推定する研究の主な目的は,タイムラインなどに表示する広告やユーザー レコメンドエンジン*1の最適化であろう(天野, 2018; Zhuang et al., 2017).近年までのSNSを対象とした 属性推定は,プロフィール情報や投稿地点のログ情報を利用した比較的単純なものが多かったが,自然言語処 理分野の解析技術の発展により,投稿内容からも精度の高い推定が可能となってきている.中でも,最近の SNSではInstagramを中心として,文章だけなく画像や動画を投稿するユーザーも増えてきており,こうし
たマルチメディアを素材とした研究も行われている.Rew et al.(2016)はTwitter,Facebook,Instagram
から収集したユーザーの投稿内容に含まれている数種類のキーワード群(食事:「サンドイッチ」「ハンバー ガー」,活動:「ピクニック」「アウトドア」,睡眠:「就寝」など)とツイート投稿時の投稿地点の天候,投稿内 容に含まれる画像から,そのユーザーが摂取したカロリー,睡眠時間,喫煙者かどうかといった情報を算出し, それらを用いてユーザーの生活パターンと肌の健康状態を分類,推定している.さらに,You et al.(2016) は画像投稿型SNSであるPinterestから,ユーザーが投稿した画像をクローリングし,畳み込みニューラル ネットなど複数の数理モデルを使用して,取得した画像の画像特徴量のみから,ユーザーがその画像をピン*2 するかどうかを推定する研究を行っている. SNSの投稿内容やアカウント情報を用いて,ユーザーが公表していない何らかの属性を推定しようとする 研究は上で挙げた他にも数多く存在する.その背景には,SNSが社会のいわばインフラとしての地位を確立し ていっており,SNSを用いた集客,広告もWebマーケティングの一手法として多くの企業が積極的に活用 しているためである(天野, 2018).そういったマーケティングの手法としてのSNSの利活用において,ユー ザーの属性を明らかにすることは企業にとって大きな関心事の一つとなっている. 一方で,ユーザー属性を推定することはマーケティングにのみ効果があるわけではない.情報支援などを目 的として,SNS以外の情報を用いてユーザーの属性を推定している研究も多く存在する. *1フォローさせることを目的として,自分以外のアカウントを「知り合いかも」「おすすめユーザー」といった形で推薦するシステム *2ユーザーが興味を持った画像を自身のコレクションに追加する操作
松尾ら(2007)はカード型CoBITと呼ばれる小型のカメラ付きセンサーを使い,オフィス内にいる人の位 置情報履歴を計測し,記録した位置情報からその人の年齢や居室,喫煙者か否かといった属性をサポートペク
タマシン(Support Vector Machine: SVM)と呼ばれる機械学習の手法を用いて推定する研究を行っている.
SVMは,予測に必要となる最小限のデータ(サポートベクタ)から,それらの距離を最大化する「マージン 最大化」という考え方に基づいて,異なるクラス同士の間に境界線を引いて予測を行う,ポピュラーな機械学 習アルゴリズムの一つである.そうしたSVMを用いた分析の結果,居室は高い精度で推定ができたと松尾ら は報告しているが,一方で,居室と同様に位置情報から比較的推定しやすいと思われる,喫煙者か否かといっ た情報がそれほど良い精度での推定が出来なかったと報告している. ユーザー属性を推定する試みは多くの領域,分野で行われており,特に近年の統計学や人工知能,さらには IoT分野の隆盛により,より高精度で信頼性の高い推定が可能となってきていることも,この流れを後押しす る要因となっていると思われる. 推定される属性もその目的によって多様であり,より簡便な方法で属性の推定を可能にする手法を提案する ことも価値があると言えるだろう.その中で,近年注目を浴びている指標として,視線情報が挙げられる.次 節では視線情報を使ってユーザーの属性を推定する試みを行っている研究を紹介する.
2.2.2
視線情報によるユーザー属性推定
2.1.1節の冒頭で述べたように,その人がどこを見ているのかといった情報はその背後に潜むその人の興味 や意思を反映しているとされる.こうした視線情報を活用して,ユーザーの属性を推定しようとする研究が, 技術の進展によるカメラの高性能化,安価化,さらには人工知能や機械学習技術の発展に伴って,近年盛んに なってきている. 機械学習による推定とは,基本的にはカテゴリ変数を推定することを表す.カテゴリカルな変数を目的変数 として,入力したデータがどのカテゴリに属するのかを,その入力したデータのみから推定を行う(図2.3). 推定を行うモデルは,機械学習の文脈では「識別器」と呼ばれ,より正確な推定を行うことができるように大 図2.3 機械学習の概要 量のデータを識別器に入力し,識別器を学習させていく.Lall´e et al.(2016)はデータグラフを見た際のユーいった異なる内容の課題を与え,被験者が課題の遂行に際して困惑を感じたら図の右上の「I am confused」
ボタンを押すよう指示した.ボタンが押された課題の視線情報にconfusionラベル,押されなかった場合に
non-confusionラベルを付与して,オーバーサンプリングを施した上で2値分類としてRandom Forest識別
器を用いて推定を行った.Random Forest識別器は多量の決定木*3と呼ばれる識別器を生成し,それらの推定 結果の調和平均から最終的な予測精度を算出する,多くの研究で用いられている識別器である.そのRandom Forest識別器を使用して分析した結果,60%を超える感度*4を算出している. 調理時の動作を視線情報から推定する手法もInoue et al.(2016)らによって提案されている.調理動作を 切る,混ぜる,剥く,潰す,待機の5つに分類し,5値問題としてRandom Forest識別器を使って推定を行っ ている.Inoueらは連続する視線データに対して,移動量,方向および瞬きに応じた大小のアルファベット (右上方向に大きく移動: ’B’,左下方向に小さく移動: ’j’,など)の記号を付与し,それらの記号列を1 4つ ずつ連結させてヒストグラムパターンとして量子化を行い,それらを特徴量とした特徴ベクトルを抽出してい る.推定の結果,ほぼ全ての調理動作を90%前後の高い精度で推定することができたと報告している. 他にも,Al-Samarraie et al.(2016)は情報探索タスク遂行時の視線を計測し,事前に測定した被験者
のBIG5パーソナリティを,機械学習の手法を用いて推定する研究を行っている.Al-SamarraieらはKim
(2008)の定義したSimulated Work Task Situationsの3つのタスクを73名の被験者に課し,得られた視線
データをタスクごとに平均注視回数,平均注視時間,平均サッケード振幅,平均サッケード時間,平均瞳孔サ
イズの5つの特徴量に分解し,パーソナリティとの相関関係を算出している.結果,全てのタスクにおいて平
均注視回数,注視時間,平均瞳孔サイズが5因子それぞれに有意な相関関係があったと報告している.また,
それぞれの被験者を高Extraversion群,高Agreeableness群,高Conscientiousness群に分け,それらを目
的変数として,推定を行っている.距離が近いデータ同士を同一のクラスとして推定する最近傍アルゴリズム
を用いて視線データからパーソナリティの推定を行い,結果,70%という高い推定精度でそれぞれのクラスを
推定することが可能であったことを報告している.
また,Hoppe et al.(2018)は実験室環境ではなく,日常場面での視線行動からパーソナリティを推定し
ている.事前にNEO Five Factor Inventoryで被験者のBIG5パーソナリティを算出し,その後,メガネ型
のアイトラッキング装置を装着させ,キャンパスの周囲を約10分間被験者に散歩させた.その際の視線情報
を,時系列情報を保った形でサンプリングするために分析窓で分割して,それぞれの窓サイズのデータに対し
Random Forest識別器を用いて推定を行っている.各被験者のBIG5パーソナリティを,得点分布の33%点
および66%点を閾値として,Low,Mid,Highのクラスにそれぞれ割り当て,これらの目的変数とし,各窓
サイズで最も良い識別精度を算出した結果,Agreeableness,ExtraversionおよびConscienciousnessの推定
精度が数種類のベースラインより高く,50%前後の値を出していた.
機械学習の技術を応用した視線追跡技術も著しい発展を見せており,特別な装置を必要とせず,スマート
フォンやPCに搭載されたフロントカメラ,Webカメラのみで精度の高い視線追跡の実現を目指した研究も
盛んである(Zemblys et al., 2018; Kar & Corcoran, 2017).また,特別なソフトウェアやアプリケーション
を必要としないWebブラウザベースの視線計測ツールも提案されている(Papoutsaki et al., 2017).今後,
より手軽に視線を計測できる装置が開発されてくるだろう. 以上のように,視線を使ったユーザー属性の推定はその領域や目的に関係なく,いくつもの関連研究が行わ れてきている.視線はその人の興味の対象を反映し,内的な状態を表しているため,ユーザーの属性を推定す *3各特徴量の値が閾値よりも大きいか小さいかといった指標を用いてデータを段階的に 2 つに分割していくことで,最終的な予測ク ラスを決定する分析手法 *4目的とするラベルクラスを正確に推定できた割合を示す指標.再現率に同じ
る上で非常に有用な指標として期待されている.また,機械学習は,そうしたユーザー属性の推定を行うため に有効な手法であると考えられる.
第
3
章
本研究
3.1
本研究の位置づけ
本研究では,3種類のタスクに基づくWeb情報探索行動時の視線情報からユーザー属性の推定を行う. 前章でも述べたように,Web情報探索時の視線情報を分析した研究はいくつかある.しかし一方で,単一 のページだけでなく,探索行動のプロセス全体を対象として視線情報を分析している研究はまだ少ない.通常 のWeb情報探索行動は,検索エンジン上で検索クエリを生成し,検索結果ページに表示されるリンクおよび 概要を閲覧し,求める情報がありそうなページを順にブラウジングしていくという一連の流れを再帰的に繰り 返すプロセスである.そのため,単一のページや検索結果ページのみを対象とした研究では情報探索行動の全 容を明らかにする上で不十分であると考えられる.そのため本研究ではユーザーの探索行動の全プロセスを対象として視線を計測し,分析を行っていく.また,Hoppe et al.(2018)やAl-Samarraie et al.(2016)が示
したように,機械学習はユーザーの属性を推定する上で有効な手法であると考えられる.しかしながら,これ までのWeb情報探索行動研究を見てきても,機械学習を用いて直接タスクの推定を行っている研究はまだな い.2章1.2節で見てきたように,タスクやパーソナリティが情報探索行動に大きな影響を与えていることが 先行研究により示されている.そのため,視線情報から現在探索しているタスクやユーザーのパーソナリティ を推定することができれば,適切な情報探索支援に応用が可能であり,また,より高精度にパーソナライズさ れた情報をユーザーに提供する検索エンジンの開発など,応用範囲は非常に広いと考えられる.したがって, Web情報探索時の視線情報からタスクおよびパーソナリティの推定を試みることは意義のあることと言える. 以上より,本研究では3種類の質的に異なる探索タスクを行っている際の,特定のページに依拠しない,探 索行動全プロセスを対象として視線計測を行い,タスクとBIG5パーソナリティという2種類のユーザー属性 の推定を行う.
3.2
実験概要
3.2.1
被験者
参加した被験者の内訳を表3.1に示す.国立大学法人東北大学の学生,合計75名の被験者に対して実験を 行い,性別の内訳は男性47名,女性28名であった.日本語話者であり,矯正視力に異常がない学生を被験者 とした.表3.1 被験者内訳
Sex Age(Average) Number
Men 21 40 Women 20 35 Total 75 行い,用意されたタイムスロットを選択する形で実験日程を選択した.実際に実験に参加する日にちまでにシ ステム上から,用意されたパーソナリティ質問項目に回答した.
3.2.2
実験器具
実験に使用した視線計測装置の詳細を図3.1および表3.2に示す. 図3.1 視線計測装置 表3.2 視線計測装置の仕様 Device SpecTobii TX300(Tobii Studio Version: 3.4.8) Resolution: 1920[px]× 1080[px] Sampling Rate: 250Hz
3.2.3
実験手順
本実験の流れは以下の通りとなる.
被験者の頭部の運動を固定するため,視線計測中は被験者の頭部を顎台に乗せて計測を行った.ディスプレ
イと顎台との距離を約60cm(キャリブレーションの結果次第で数cmの誤差が生じた)に固定した.
各タスクの内容を表3.4に示す.それぞれの内容はKim(2008)のSimulated Work Task Situationsの定
義を用いて,Factual,Interpretive,Exprolatoryの計3種類のタスクを,日本人大学生にも興味が湧く内容
となるよう筆者が内容を変更したものを使用した(表3.4). 実験の手順を図3.2に示す. 図3.2 実験フロー まず実験全体の説明を行い,その後準備が整い次第,被験者はディスプレイから60cmほど離れたところに 置かれた顎台に頭を乗せ,視線のベースラインを計測するためにキャリブレーションを行った.キャリブレー ションに問題がなければ,一度顎台から頭を外し,最初のタスクの説明が行われた.その際,オーダーバイア スの影響を抑えるために,被験者ごとのタスクの順番はランダム化し,カウンターバランスを取った. タスクの説明を行った後,Kim(2008)の方法に倣い作成したタスク関連項目に1-5の5段階評価で回答し てもらった.タスク関連項目の内容を表3.3に示す.全ての準部が整い次第,タスクが開始された. タスクが開始されると,中心に白い十字が配置された,背景が黒の画面が提示された.その画面でマウスを 左クリックすると,図3.3のようなGoogle検索のトップページが表示され,被験者はページ中央のテキスト ボックスに最初の検索語を入力して自由に探索を初めた(視線計測中,文字を入力するためにキーボードに目 線を落とす等も許容).探索中はWebページに限らず,Webブラウザからアクセス,起動可能なものであれ ばWebブラウザに限らず,外部のpdfビューワーなど,自由に閲覧可能とした.また,被験者は回答作成の ためのメモ代わりとして,回答作成に役立つと思われるWebページを好きな数だけブックマークしながら探 索を行った. 各タスクには7分間の制限時間があり,探索課題遂行中は被験者に対して経過時間を知らせず,タスクが開 始されてから7分間が過ぎた時点でブラウザが強制的に閉じて,そこで1つのタスクが終了となった. タスクが終了したら再度,タスク関連項目に口頭で回答してもらった.その後,もう一度ブラウザを立ち上
げ,探索中にブックマークしたページを自由に見返しながら,口頭で回答を行った.回答作成の時間は分析対 象外とし,視線の計測は行っていない. 以上の流れを各タスク1回ずつ,計3回繰り返し行い,それぞれの探索時の視線情報を記録した.実験時間 は全て合わせて1時間程度であった. 表3.3 タスク関連項目 Before Task どれぐらいこのタスクは難しそうか(Pre-task Difficulty) (1. とても簡単そう 5. とても難しそう) 今現在,タスクの内容に関する知識はどれくらい持っていると思うか(Prior Knowledge) (1. 全く何も知らないと思う 5. 何でも知っていると思う) After Task 実際どれくらい難しかったか(Post-task Difficulty) (1. とても簡単だった 5. とても難しかった) 達成感はどれくらいあるか(Achievement) (1. 全く達成感がない 5. かなり達成感がある)
表3.4 改変Simulated Work Task Situations
Task Type Content
Factual あなたは1学期の授業が終わった夏休みに,サークルの友人と名古屋に旅行に行くこと になりました.そこで,名古屋の有名な食べ物屋さんを調べていると「モーニング」と いう文化が名古屋の喫茶店には根付いていることを知り,その文化に興味を持ちまし た.あなたは,どうせなら今度のサークル旅行の際には名古屋で最も古くからモーニン グの提供を行っているお店に行ってみようと考え,WEBでそのお店の名前を調べてみ ることにしました Interpretive まだ10代半ばのあなたの従姉妹が,「私の友達がタバコを吸い始めたの」と言い出しま した.あなたは近い将来,あなたの従姉妹もタバコを吸い始めてしまうのではないかと 不安になり、タバコを吸うと身体へどのような影響があるのかを従姉妹に詳細に伝えよ うと情報を集めることにしました Exprolatery 心地よく晴れた日曜日.あなたは小学生の頃にいつも遊んでいた近所の公園にふと行っ てみることにしました.公園についたあなたは不思議な違和感を覚え,公園内を見回す と,当時使っていたいくつかの遊具が無くなっていることに気づきました.家族にその ことを話すと,どうやらその公園だけでなく全国的に公園からどんどん遊具が撤去され ている動きがあるらしいという話になりました.あなたは,このことについて自分はど う思うのか,自分の意見を明確にしようとまずはWebで情報を検索してみることにし ました
図3.3 Google検索のトップページ
3.3
データ分析
3.3.1
データの分布
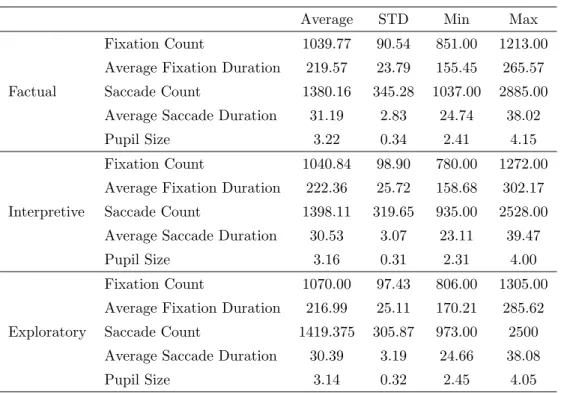
この3.3.1節では視線データ,パーソナリティ得点およびタスク関連変数について,記述統計量を算出し, 各変数の分布をみていく. 視線データ 実験により得られた75名のデータの内,実験器具の不具合により正常に計測ができていなかったデータ, およびTIPI-J質問紙の回答に不備があった被験者のデータを以降の操作から除外した.したがって,分析に 使用した被験者数は72名であった.各タスクの代表値として,注視回数(Fixation Count),平均注視時間(Average Fixation Duration),サッ
ケード回数(Saccade Count),平均サッケード時間(Average Saccade Duration),瞳孔サイズ(Pupil Size)
を抽出し,それらの記述統計量を以下の表3.3.1に示す.
各タスク同士で視線データの平均値を取り,そのデータの相関行列を以下に示す(図3.3.1).
AverageFixationDurationとSaccadeCountの間に-0.78の強い相関がみられ,AverageFixationDuration
とFixationCountの間に-0.45のやや強い相関がみられた.
パーソナリティ得点
小塩ら(2012)の作成した日本語版Ten Item Personality Inventory(TIPI-J)を用いて,被験者のBIG5
因子得点を測定した.TIPI-Jは10項目の質問で構成されており,協調性(Agreeableness)のみ再検査信
頼性が多少低いものの,その他の下位尺度では十分な信頼性,妥当性を示している(小塩ら, 2012).本研
究において測定した,回答に不備のあった被験者のデータを除いた72 名分のTIPI-Jから算出した,神
経症傾向(Neuroticism),外向性(Extraversion),開放性(Openness),協調性(Agreeableness),誠実性
(Conscientiousness)の記述統計量を表3.6,図3.5,図3.6に示す.
図3.5では,中心点である4点の部分が薄く,中心点の周囲に分布する傾向が見られた.また,Agreeableness
表3.5 視線データ統計量
Average STD Min Max
Factual
Fixation Count 1039.77 90.54 851.00 1213.00
Average Fixation Duration 219.57 23.79 155.45 265.57
Saccade Count 1380.16 345.28 1037.00 2885.00
Average Saccade Duration 31.19 2.83 24.74 38.02
Pupil Size 3.22 0.34 2.41 4.15
Interpretive
Fixation Count 1040.84 98.90 780.00 1272.00
Average Fixation Duration 222.36 25.72 158.68 302.17
Saccade Count 1398.11 319.65 935.00 2528.00
Average Saccade Duration 30.53 3.07 23.11 39.47
Pupil Size 3.16 0.31 2.31 4.00
Exploratory
Fixation Count 1070.00 97.43 806.00 1305.00
Average Fixation Duration 216.99 25.11 170.21 285.62
Saccade Count 1419.375 305.87 973.00 2500
Average Saccade Duration 30.39 3.19 24.66 38.08
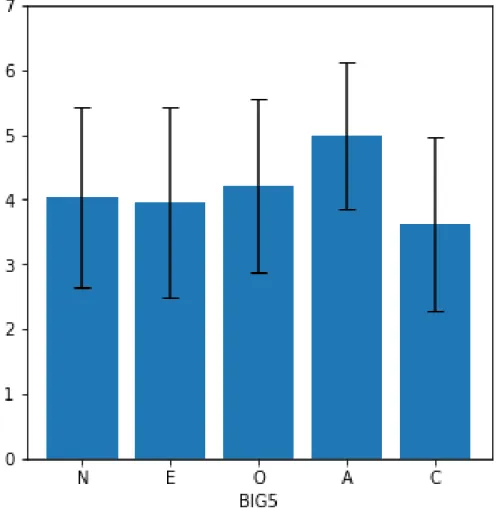
表3.6 TIPI-J記述統計量
Average STD Min Max
Neuroticism 4.06 1.40 1.5 6.50 Extraversion 3.98 1.48 1.50 7.00 Openness 4.18 1.36 1.50 7.00 Agreeableness 4.95 1.16 2.00 7.00 Conscientiousness 3.66 1.39 1.00 6.50 N=72 図3.5 TIPI-J度数分布 それぞれのパーソナリティ得点の相関行列を図3.7に示す.それぞれのパーソナリティ同士に大きな相関は 見られなかった.
次に,それぞれのパーソナリティ得点について,33≤ score,33<score<66,score≤ 66の範囲の得点を
示した被験者をそれぞれLow,Mid,Highの3つのカテゴリクラスに分類した.
分類した結果を図3.8に示す.Neuroticism, Extraversion, Openness, Agreeableness, Conscientiousness
の因子にそれぞれ, Low: 21, 20, 23, 22, 23 Mid: 29, 35, 32, 28, 26 High: 23, 18, 18, 23, 24 人ずつ割り当てられた.各カテゴリの被験者数に特筆すべき偏りはなく,妥当な数だけ割り当てられたと考 えられる.本研究におけるBIG5因子の推定ではこの3カテゴリクラスの推定を行う.
図3.6 TIPI-Jバイオリン図 図3.7 TIPI-J相関行列 タスク関連変数 Kim(2008)の用いた手法に倣い,タスク関連変数および被験者の保存したブックマーク数の統計量を表 3.7に示す. 表3.7 タスク関連変数統計量
Pre-task Difficulty Post-task Difficulty Prior Knowledge Achievement Number of Bookmarks average std median average std median average std median average std median average std median Factual 2.50 1.06 2.00 3.86 1.03 4.00 1.77 1.02 1.00 2.86 0.90 3.00 2.29 1.76 2.00 Interpretive 2.15 0.83 2.00 2.13 0.96 2.00 3.06 0.63 3.00 3.65 0.73 4.00 3.61 1.81 3.00 Exploratory 3.13 0.87 3.00 2.97 1.02 3.00 2.05 0.88 2.00 3.23 0.79 3.00 2.88 1.90 3.00
図3.8 BIG5カテゴリ度数
3.3.2
各データの関連性
この節では,視線データ,パーソナリティ得点,タスク関連変数について分散分析および相関分析を行い, 各タスク遂行時の視線情報とパーソナリティとの関連について見ていく. 視線データ 視線データに関して,各タスクごとに平均値が異なるかどうかを確かめるために,各変数について一元配置 3水準の分散分析を行った.結果を表3.8に示す. 表3.8 視線データ 分散分析結果 Fixation Count F(2, 142)=7.037, p<.001 **Average Fixation Duration F(2, 142)=4.375, p<.05 *
Saccade Count F(2, 142)=2.020, p>.05 n.s.
Average Saccade Duration F(2, 142)=7.657, p<.001 **
Pupil Size F(2, 142)=18.089, p<.001 **
** : p<.01 * : p<.05
Fixation Count(F (2, 142)=7.037, p<.001),Average Saccade Duration(F (2, 142)=7.657, p<.001),
Pupil Size(F (2, 142)=18.089, p<.001)が1%水準,Average Fixation Duration(F (2, 142)=4.375, p<.05)
に5%水準で,タスクごとの平均値に有意な差が見られた.Saccade Count(F (2, 142)=2.020)には有意な差
は見られなかった.
有意差が見られたFixation Count,Average Fixation Duration,Average Saccade Duration,Pupil
Sizeに対し,Holm法で多重比較を行った(図3.9).その結果,Fixation CountのFactual-Exploratory,
られなかった.Average Fixation DurationではInterpretive-Exploratory間に1%水準で有意な差が見
られ,Factual-Interpretive,Factual-Exploratory間には差がなかった.Average Saccade Durationでは
Factual-Interpretive,Factual-Exploratory間に1%水準で有意な差があり,Interpretive-Exploratoryには
差がなかった.Pupil SizeはFactual-Interpretive,Factual-Exploratory間に1%水準で有意な差が見られ,
Interpretive-Exploratory間には有意な差は見られなかった.
図3.9 視線データ バープロット
次に,パーソナリティ得点との相関を見ていく.以下に視線データとパーソナリティ得点との相関表を示す
(表3.9).
表3.9 視線とパーソナリティの相関表
Neuroticism Extraversion Openness Agreeableness Conscientiousness Factual
Fixation Count r=.123, p>.05 n.s. r=.068, p>.05 n.s. r=-.261, p<.01 ** r=-.176, p>.05 n.s. r=.112, p>.05 n.s.
Average Fixation Duration r=.048, p>.05 n.s. r=-.176, p>.05 n.s. r=.083, p>.05 n.s. r=.126, p>.05 n.s. r=-.039, p>.05 n.s.
Saccade Count r=-.113, p>.05 n.s. r=.103, p>.05 n.s. r=.120, p>.05 n.s. r=-.017, p>.05 n.s. r=-.067, p>.05 n.s.
Average Saccade Duration r=-.111, p>.05 n.s. r=-.188, p>.05 n.s. r=.023, p>.05 n.s. r=-.112, p>.05 n.s. r=-.042, p>.05 n.s.
Pupil Size r=.006, p>.05 n.s. r=.024, p>.05 n.s. r=-.048, p>.05 n.s. r=-.078, p>.05 n.s. r=.106, p>.05 n.s.
Interpretive
Fixation Count r=.129, p>.05 n.s. r=.063, p>.05 n.s. r=-.238, p<.01 ** r=-.345, p<.01 ** r=.127, p>.05 n.s.
Average Fixation Duration r=.000, p>.05 n.s. r=-.188, p>.05 n.s. r=.063, p>.05 n.s. r=.201, p>.05 n.s. r=-.054, p>.05 n.s.
Saccade Count r=-.089, p>.05 n.s. r=.228, p>.05 n.s. r=.145, p>.05 n.s. r=-.099, p>.05 n.s. r=.040, p>.05 n.s.
Average Saccade Duration r=-.055, p>.05 n.s. r=-.212, p>.05 n.s. r=-.042, p>.05 n.s. r=.116, p>.05 n.s. r=-.184, p>.05 n.s.
Pupil Size r=-.009, p>.05 n.s. r=-.016, p>.05 n.s. r=-.014, p>.05 n.s. r=-.074, p>.05 n.s. r=.084, p>.05 n.s.
Exploratory
Fixation Count r=.243, p<.01 ** r=-.081, p>.05 n.s. r=-.274, p<.01 ** r=-.412, p<.001 ** r=.147, p>.05 n.s.
Average Fixation Duration r=-.055, p>.05 n.s. r=-.135, p>.05 n.s. r=.121, p>.05 n.s. r=.364, p<.01 ** r=-.038, p>.05 n.s.
Saccade Count r=-.122, p>.05 n.s. r=.167, p>.05 n.s. r=.125, p>.05 n.s. r=-.174, p>.05 n.s. r=.068, p>.05 n.s.
Average Saccade Duration r=-.060, p>.05 n.s. r=-.193, p>.05 n.s. r=-.048, p>.05 n.s. r=.027, p>.05 n.s. r=-.304, p>.05 **
Pupil Size r=-.036, p>.05 n.s. r=.028, p>.05 n.s. r=-.052, p>.05 n.s. r=-.105, p>.05 n.s. r=.066, p>.05 n.s.
** : p<.01 * : p<.05
すべてのタスクにおいてFixation CountがOpennessとp<.01の中程度の負の相関をみせており,これ
は探索行動中に注視回数が少ない人はOpenness得点が高い傾向にあることを示している.また,Fixation
CountはInterpretiveタスクとExploratoryタスクにおいてAgreeablenessと中程度の負の相関を示してお
り,これもまた注視回数が少ない人はAgreeablenessの得点が高い傾向にあることを示している.
他の視線データはExploratoryタスクにおいてのみ,パーソナリティと有意な相関関係を見せている.
Fixation Count が Neuroticismと中程度の正の相関(r=.243, p<.01),Average Fixation Durationが
Agreeablenessと中程度の正の相関(r=.364, p<.01),Average Saccade DurationがConscientiousnessと
中程度の負の相関(r=-.304, p<.05)であった.
ティごとの平均値の主効果に有意な差がみられた(F(4, 284)=10.024, p<.001)ため,テューキーの方法を用
いて多重比較を行った.各パーソナリティのバープロットを図3.10に示す.
図3.10 パーソナリティ得点 バープロット
多重比較の結果,AgreeablenessとConscientiousnessの間(p<.001),AgreeablenessとExtraversionの 間(p<.001),AgreeablenessとNeuroticismの間(p<.001),AgreeablenessとOpennessの間(p<.01)に それぞれ有意な差がみられたが,他の水準間には有意な差はみられなかった.これは他のパーソナリティと比 較して,Agreeablenessのパーソナリティが相対的に高い被験者が集められたということを示している. タスク関連変数 タスク関連変数について,タスクごとに平均値に差があるかどうかを確かめるために,各変数に対して一元 配置3水準の分散分析を行った.分散分析の結果を表3.10に示す. 全ての変数において1%水準で主効果が有意であったため,テューキーの方法を用いてそれぞれの変数に対 し多重比較を行った(図3.11).
Pre-task DifficultyではExploratory-Factual,Exploratory-Interpretiveの間に1%水準で有意な差がみ
表3.10 タスク関連変数 分散分析結果 Pre-task Difficulty F(2, 142)=23.691, p<.001 ** Post-task Difficulty F(2, 142)=54.228, p<.001 ** Prior Knowledge F(2, 142)=43.451, p<.001 ** Achievement F(2, 142)=16.688, p<.001 ** Number of Bookmarks F(2, 142)=14.133, p<.001 ** ** : p<.01 * : p<.05 Interpretive, Exploratory全ての間にp<.001で有意差がみられた.これはタスクの内容に対して被験者が感
じる難しさは,探索前では,ExploratoryタスクおよびFactualタスクはInterpretiveタスクよりも難しそう
に感じられ,探索後でも同様にInterpretiveタスクが最も簡単に感じられたが,実際に探索を行ってみると
FactualタスクがExploratoryタスクよりも難しく感じられたということを示している.
Prior KnowledgeはFactual-Interpretive,Interpretive-Exploratoryの間に有意差がみられた(
Factual-Interpretive: p<.001, Interpretive-Exploratory: p<.001).これは被験者がInterpretiveタスクに対する事
前知識を他のタスクと比べて多く持っていることを示している.
AchievementではFactual-Exploratoryの間がp<.05,Interpretive-Exploratory,Factual-Interpretive
の間がp<.001の有意差であった.Interpretive タスクが最も達成感があり,それに続いてExploratory,
Factualの順に達成感が感じられるという結果であった.
Number of BookmarksではFactual-Interpretive,Exploratory-Interpretiveの間に1%水準で有意な差が
みられ,Factual-Exploratoryの間には5%水準で有意な差が見られた.これはブックマークする数がFactual
タスクおよびExploratoryタスクではInterpretiveよりも有意に少なく,FactualタスクとExploratoryタス
クでは,Factualタスクの方が少ない傾向にあることを示している.
図3.11 タスク関連変数 バープロット
次にパーソナリティとの相関を見ていく.以下にタスク関連変数とパーソナリティ得点との相関分析表を示
す(表3.11).
相関分析の結果,ほとんどのデータでパーソナリティとの有意な相関関係は見られなかったが,唯一,
ExploratoryタスクにおいてNumber of BookmarkがConscientiousness得点とr=-.256, p<.01の負の相
表3.11 タスク関連変数とパーソナリティ 相関表
Neuroticism Extraversion Openness Agreeableness Conscientiousness Factual Pre-task Difficulty r=-.017, p>.05 n.s. r=-.017, p>.05 n.s. r=-.052, p>.05 n.s. r=–.049, p>.05 n.s. r=-.010, p>.05 n.s. Post-task Difficulty r=-.098, p>.05 n.s. r=.084, p>.05 n.s. r=-.019, p>.05 n.s. r=.094, p>.05 n.s. r=.112, p>.05 n.s. Prior Knowledge r=.059, p>.05 n.s. r=-.146, p>.05 n.s. r=.127, p>.05 n.s. r=-.062, p>.05 n.s. r=-.076, p>.05 n.s. Achievement r=-.068, p>.05 n.s. r=-.131, p>.05 n.s. r=-.027, p>.05 n.s. r=-.210, p>.05 n.s. r=.014, p>.05 n.s. Number of Bookmarks r=-.201, p>.05 n.s. r=-.063, p>.05 n.s. r=-.074, p>.05 n.s. r=.201, p>.05 n.s. r=.049, p>.05 n.s. Interpretive Pre-task Difficulty r=-.059, p>.05 n.s. r=-.137, p>.05 n.s. r=-.092, p>.05 n.s. r=-.132, p>.05 n.s. r=-.067, p>.05 n.s. Post-task Difficulty r=.105, p>.05 n.s. r=-.016, p>.05 n.s. r=.122, p>.05 n.s. r=.046, p>.05 n.s. r=-.206, p>.05 n.s. Prior Knowledge r=-.003, p>.05 n.s. r=-.042, p>.05 n.s. r=-.083, p>.05 n.s. r=.030, p>.05 n.s. r=.177, p>.05 n.s. Achievement r=-.055, p>.05 n.s. r=-.173, p>.05 n.s. r=-.008, p>.05 n.s. r=-.016, p>.05 n.s. r=.106, p>.05 n.s. Number of Bookmarks r=-.113, p>.05 n.s. r=.070, p>.05 n.s. r=-.069, p>.05 n.s. r=.067, p>.05 n.s. r=-.100, p>.05 n.s. Exploratory Pre-task Difficulty r=.202, p>.05 n.s. r=-.032, p>.05 n.s. r=-.038, p>.05 n.s. r=-.203, p>.05 n.s. r=-.192, p>.05 n.s. Post-task Difficulty r=-.068, p>.05 n.s. r=.080, p>.05 n.s. r=-.052, p>.05 n.s. r=-.115, p>.05 n.s. r=.053, p>.05 n.s. Prior Knowledge r=.072, p>.05 n.s. r=-.090, p>.05 n.s. r=-.010, p>.05 n.s. r=.168, p>.05 n.s. r=.088, p>.05 n.s. Achievement r=.056, p>.05 n.s. r=.061, p>.05 n.s. r=.208, p>.05 n.s. r=-.084, p>.05 n.s. r=-.158, p>.05 n.s. Number of Bookmarks r=-.123, p>.05 n.s. r=.097, p>.05 n.s. r=-.018, p>.05 n.s. r=.016, p>.05 n.s. r=-.256, p<.01 ** ** : p<.01 * : p<.05
3.4
機械学習モデル
3.4.1
特徴量の抽出
また,正常に計測できていた被験者のデータの内,一つでも視線座標の取得率が50%を下回るタスクが存 在した場合,その被験者のデータも以降の操作から除外した. タスク開始から最初の1分間にはタスク開始直後の読み込みの時間のデータが含まれており,また,タスク の内容あるいは難易度の理解がまだ不十分な状態であったと考えられる.さらに,最後の1分間はタスクの答 えがある程度作成し終わり,被験者によっては集中力が切れた状態であった可能性があり,分析に適していな い恐がある.そのため,この開始直後と終了直前の1分間のデータを除外し,計5分間のデータを使って分析 を行った. 60ms以上,視覚半径0.5degの範囲に収まった視線データを注視(Fixation)とみなし,また,注視点から 次の注視点への移動が視覚半径0.5deg,75ms以下に収まっている注視は同一の注視として使用した.注視か ら注視の間は全てサッケード(Saccade)とみなした.さらに,注視でもサッケードでもないデータ(欠損し たデータも含む)は瞬き(Blink)とみなした. 以下では機械学習アプローチにおける分析で使用する特徴量の抽出方法,ならびに説明を行う.視線のxy 座標および瞳孔サイズを用いて特徴量の抽出を行った.使用した特徴量を以下の表3.12に示す.本研究ではHoppe et al.(2018)と同様の方法を用いて,同一の特徴量を抽出し,分析に使用した.以下にHoppe et al.
の研究で用いられた特徴量抽出の説明を行う. また,Bulling et al.(2011)の手法に従い,あらかじめ分析窓を設定して,時系列で並んだ視線データを処 理した.分析窓を設定することで,単純に視線データを平均化してしまうと消失してしまうような,短い時間 でのみ生じる視線行動を拾い上げることができる.また,少ない被験者数でもサンプルの数を大幅に増加さ せ,学習に十分なデータサイズを得ることができる(Bulling et al., 2011).したがって,機械学習による分 析ではこの分析窓で分割したデータセットを用いて,属性の推定を行っていく. それぞれの分析窓は互いに50%ずつ重複させながら,計測時間全体にわたって窓をスライドさせてサンプ リングした(図3.12).各窓内のエラー率(座標や瞳孔が検出できなかった割合)および計測機器のエラーな どにより座標値がディスプレイの外にあると判定された割合が50%を超えた場合,各窓内の正常なサンプル
が2つ未満である場合および各窓内に一度も注視が発生しなかったと判定された場合,そのサンプルを除外 した. 図3.12 分析窓分割の例 分析窓のサイズはそれぞれ5, 15, 30, 45, 60, 75, 90, 105, 120, 135secとし,それぞれの窓内での特徴量を 抽出した結果,合計207個の特徴量が抽出された. 視線データに基づく207個の特徴量は4つのサブカテゴリーに区分される.以下にそれぞれの概説を示す.
注視,サッケードおよび瞬きの統計量(Statistics over fixations, saccades and blinks) : 注視回数やサッケー ド時間,瞬きの回数など,基本的な視線指標の統計量.本研究に限らず,眼球運動を分析する実験で広 く用いられている特徴量(Bulling et al., 2011).本研究においては最小注視時間を60ms,最小注視範 囲を0.5degとみなしている. 注視点ヒートマップ(Heatmap on fixations) : 本研究では被験者ごとに見ているページが異なるため,関心 領域を設定しない(できない)代わりに,ディスプレイ上に8×8の仮想的なグリッドを作成し,それ ぞれのセル上での注視回数を記録したもの(図3.13).グリッドはディスプレイの左上が0,右上を7 として計64個とした.
座標値および瞳孔サイズの統計量(Statistics over raw gaze data) : 観 測 環 境 に 依 存 す る 情 報 の 統 計 量
(Baranes et al.,2015).xy座標値や瞳孔サイズの数値データを直接扱う.本来であればこれを用いる
際は結果の一般性に注意する必要がある.しかしながら,本研究においては被験者に対してある程度の 自由を許容している(例えば,キーボードに文字を打ち込む際に,目線をディスプレイの外に落とす 等)ため,一定以上の一般化は可能であると考えられる.視線情報の一般性に関してはここでは詳しく
議論しない.詳しくはBaranes et al.(2015)を参照してほしい.
注視およびサッケードの時系列情報(Information on the temporal course of saccades and fixations) : 視 線
N-gram 特徴量.連続する視線行動をサッケード量(振幅)およびサッケード方向に基づいて,そ
表3.12: 抽出した特徴量
Features Numbers
Statistics over fixations, saccades and blinks (45)
fixation/saccade rate 2
small/large saccade rate 2
left/right saccade rate 2
saccade to fixation ratio 1
ratio of small/large/right/left saccades to the total number of saccades 4
mean/variance/minimum/maximum saccade amplitude 4
mean/variance/minimum/maximum saccade saccadic peak velocity 4
mean/variance/minimum/maximum of the mean pupil diameter during saccades 4
mean/variance/minimum/maximum of the fixation duration 4
dwelling time 1
mean/variance of the mean of angles between subsequent fixations 2
mean/variance of the variance of angles between subsequent fixations 2
mean of the variance in raw x coordinates during fixations 2
mean of the variance in raw y coordinates during fixations 2
mean/variance of the mean pupil diameter during fixations 2
mean/variance of the variance in pupil diameter during fixations 2
mean/variance/minimum/maximum of blink duration 4
blinks per second 1
Heatmap on fixations (64)
heatmap counts with 8× 8 cells 64
Statistics over raw gaze data (34)
mean of XYD 3
minimum of XYD 3
maximum of XYD 3
range of XYD 3
standard deviation of XYD 3
median of XYD 3
1st quartile of the distribution over XYD 3
3rd quartile of the distribution over XYD 3
inter quartile range of the distribution over XYD 3
absolute value of mean difference between subsequent XYD 3
mean difference between subsequent XYD 3
mean angle between two subsequent raw gaze points 1
Information on the temporal course of saccades and fixations (64)