潜在的ディリクレ配分法における
確率分布の共役性の可視化
Visualization of Conjugate Distributions
in Latent Dirichlet Allocation Method
白田 由香利
1*†Yukari Shirota
11
学習院大学経済学部経営学科
1
Gakushuin University, Faculty of Economics, Department of Management
Abstract: In Bayesian probability theory, if the posterior distributions p(θ|x) are in the same family as the prior probability distribution p(θ), the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood function. In the Latent Dirichlet Allocation model, the likelihood function is Multinomial and the prior function is Dirichlet. There the Dirichlet distribution is a conjugate prior and then the posterior function becomes also Dirichlet. The posterior function is a parameter mixture distribution where the parameter of the likelihood function is distributed according to the given Dirichlet function. Because the process is complicated, it is hard to understand the process. The paper visualizes the parameter mixture distribution. The visualization is helpful to understand the algorithm of the Latent Dirichlet Allocation method.1 始めに
パラメータによって確率分布の形状が決定される 確率分布を,パラメトリックであると言う. 例えば, 正規分布は,平均と分散という 2 つのパラメータの みで形状が決定される.実際的な応用の事例におい ては,このパラメータは不明であることが多く,我々 はそれを何らかの方法を用いて,適切なパラメータ 値を得ようとする.ベイズ主義の立場では,パラメ ータに事前分布を導入し,観測データが与えられた ときのパラメータの事後分布を,ベイズの定理を用 いて計算する.事前分布として,共役事前分布を用 いると,事後分布の関数の形が事前分布と同じにな り,ベイズ解析が非常に簡単になる[1]. パラメータを固定値にした場合に比較して,パラ メータに確率分布(重み分布)を設定する場合,結果 の分布形状は複雑になり,その形状をイメージする ことは困難になる.昨今,潜在的ディリクレ配分法 (LDA: Latent Dirichlet Allocation)によるトピ * 連絡先:学習院大学経済学部経営学科 〒171-8588 東京都豊島区目白 1-5-1 E-mail: [email protected] ック分析などが盛んに行われている.LDA 手法は多 項分布とディリクレ分布を用いたベイズ解析手法で ある[2].LDA のプログラムやツールは簡単に入手で き簡単に分析を行えるため,モデルを理解しないで も使えてしまう.これは問題であり,モデルの教育 を行った上で,LDA 分析を行わせるべきと,著者は考 える.そこで,本稿では,3 次元で表現できる範囲 で,LDA で用いる関数形状の可視化を行う.ディリク レ分布の可視化については WEB やテキストに載って いるが[1, 3],多項分布のパラメータにディリクレ 分布という重みをつけた結果の混合分布の可視化は 行っていない.本稿では,このパラメータ混合分布 の可視化を行う. 第 2 節は確率分布の共役性の可視化例を示す.第 3 節は,可視化により LDA モデルを説明する.第 4 節 はまとめである. 人工知能学会研究会資料 SIG-FPAI-B402-052 パラメータの混合分布可視化例
本節では,パラメータの混合分布可視化事例を示 す.共役事前分布の例も含む. 図 1:確率変数 𝑥(5 − 𝜇 ≤ 𝑥 ≤ 5 + 𝜇) において,μ =0の一様分布に対して,𝜇 を正規分布 𝑁(0 , 1) に した場合の混合関数. 図 2:正規分布で,𝜇 を正規分布 𝑁(0 , 1) にした混合 関数(上図).データ数10000 .標準正規分布(下図) に比較して分散が大きい正規分布となる. 図 3:上図がベルヌーイ分布の例𝐵𝑒𝑟𝑛(𝑥|0.5). 下図がベータ分布の例 𝐵𝑒𝑡𝑎(2,2). 図 4:ベルヌーイ分布のパラメータをベータ分布 𝐵𝑒𝑡𝑎(2,2) にした混合分布2.1 正規分布の平均についての正規分布
まず,パラメータ化した混合関数の例として,一 様分布のパラメータ化の例を示す.一様分布の確率 変数 𝑥(5 − 𝜇 ≤ 𝑥 ≤ 5 + 𝜇) において,𝜇 を標準正 規分布としたグラフィクスを図 1 に示す.これは, 共役性はもたない. グラフは,混合関数を確率分布として,確率変数 の値をランダムに生成し,そのデータの数をカウン トして,確率分布を疑似的に求めて,ヒストグラム を描いている.図 1 の例は生成データ数が 10000 と 小さいので,関数形状が滑らかではない.データ数 を増やせば,滑らかになる. 次に正規分布の平均を標準正規分布にした場合の 10 5 5 10 0.02 0.04 0.06 0.08 0.10 4 2 2 4 0.05 0.10 0.15 0.20 0.25 0.5 1.0 0.5 1.0 1.5確率密度分布を示す(図 2 参照).
2.2 ベルヌーイ分布のパラメータをベー
タ分布にした混合分布
ベルヌーイ分布のパラメータをベータ分布にした 可視化事例を示す.ベルヌーイ分布は離散分布であ る.図 3 に例として𝐵𝑒𝑟𝑛(0.5) のグラフを示す.ベ ータ分布は 2 つのパラメータをもち,図 3 右図は 𝐵𝑒𝑡𝑎(2,2) の分布を示している.ベルヌーイ分布で はベータ分布が共役事前分布になる.ベルヌーイ分 布のパラメータをベータ分布 𝐵𝑒𝑡𝑎(2,2) にした分 布の可視化を図 4 に示す.𝐵𝑒𝑡𝑎(2,2) は𝑥 = 0.5 にお いて最大点となる.図4のパラメータ混合関数が最 大値となるのは,𝐵𝑒𝑡𝑎(2,2) が最大値をとる 𝑥 = 0.5 の時である.𝐵𝑒𝑟𝑛(0.5)が 𝑥 = 0, 𝑥 = 1で最大値をも つのと同様に𝑥 = 0, 𝑥 = 1で最大となる. パラメータの混合分布の例を2つ示した.パラメ ータに確率分布を導入することで,関数の形状変化 が確率的に連続値をとることが,上記例から分かっ た.3 LDA 法における共役性の可視
化
図5:LDA 法のグラフィカルモデル 本節では,LDA 法における多項分布とディリクレ分 布の可視化を行い,LDA モデルを説明する.まず, LDA 法を定義する[2, 4, 5]. LDA 法:𝐷 個の文書がある.文書𝑑 について𝑁𝑑個の 単語が観察されるとする.LDA 法では,各文書は𝐾個 のトピックの混合であると仮定する.文書𝑑 の𝑗 番 目の位置の単語𝑤𝑑,𝑗は,あるトピック𝑘に属しており, 文書𝑑は𝐾個のトピックの混合分布𝜃𝑑をもつ.トピッ ク𝑘は,それに対応する単語分布𝜙𝑘をもっており, 𝑤𝑑,𝑗は単語分布𝜙𝑘から生成されたものである.今, 文書の単語集合𝑊 が観測されたとする.𝑊からトピ ック集合𝑍を推定したい. LDA 法における文書の生成モデルのグラフィカル モデルを図 5 に示す.𝛼 は 𝜃 上の事前分布を決める ハイパーパラメータである.𝛽 は𝜃 上の事前分布を 決めるハイパーパラメータである.LDA モデルによ る文書の生成過程は以下のようになっている[5]. (1)トピックは𝐾 個とする.各トピック𝑘 = 1, ⋯ , 𝐾に ついて: (a)各トピックの単語分布はディリクレ分布 𝐷𝑖𝑟(𝛽)に従うと仮定する. 𝜙𝑘 ~ 𝐷𝑖𝑟(𝛽) (2)文書は𝐷個存在する.各文書 𝑑 = 1, ⋯ , 𝐷につい て: (a)各文書のトピック分布はディリクレ分布 𝐷𝑖𝑟(𝛼)に従うと仮定する. 𝜃𝑑 ~ 𝐷𝑖𝑟(𝛼) (b)文書𝑑 は,𝑁𝑑個の単語をもつ.文書𝑑 におけ る各単語 𝑛 = 1, ⋯ , 𝑁𝑑について: (i)その単語,つまり文書𝑑 の 𝑛 番目の単 語の潜在的トピック𝑧𝑑𝑛を生成する.文書𝑑 のトピック分布は𝜃𝑑 であるが,この単語の 潜在的トピック𝑧𝑑𝑛は,𝜃𝑑 をパラメータと する多項分布 𝑀𝑢𝑙𝑡𝑖(𝜃𝑑) に従うと仮定す る.この𝑀𝑢𝑙𝑡𝑖(𝜃𝑑) に従ってトピック𝑧𝑑𝑛を 生成する. (ii)生成されたトピック𝑧𝑑𝑛の単語分布 𝜙𝑧𝑑𝑛 を発生させる.文書𝑑 の 𝑛 番目の単語 は,𝑧𝑑𝑛 をパラメータとする多項分布に従 うと仮定する.この𝑀𝑢𝑙𝑡𝑖(𝜙𝑧𝑑𝑛 )に従って 単語 𝑤𝑑𝑛を生成する. 多項分布を説明する. 𝐾 種 類 の 事 象 が 発 生 す る 確 率 を そ れ ぞ れ 𝑝1, 𝑝2, ⋯ , 𝑝𝐾 (Σ 𝑝𝑖= 1)としたとき,𝑁 回の試行に よ り そ れ ぞ れ の 事 象 が𝑚1, 𝑚2, ⋯ , 𝑚𝐾 (Σ 𝑚𝑖= 𝑁) 回おきる確率は次式で表される. 𝑀𝑢𝑙𝑡𝑖(𝑚1, 𝑚2, ⋯ , 𝑚𝐾|𝑝, 𝑁) = (𝑚 𝑁 1𝑚2⋯ 𝑚𝐾) ∏ 𝑝𝑖 𝑚𝑖 𝐾 𝑖=1 この分布を多項分布と呼ぶ. 次にディリクレ分布を説明する[1]. :潜在変数 :観測変数𝛼 = (𝛼1, ⋯ , 𝛼𝐾) をパラメータ,実数ベクトル𝑝 = (𝑝1, ⋯ , 𝑝𝐾)を確率変数とするときの (𝐾 − 1)次ディリクレ分布の確率密度関数は以下の 式で定義される[1]。 𝐷𝑖𝑟(𝑝|𝛼) = Γ(𝛼0) Γ(𝛼1) ⋯ Γ(𝛼𝑘)∏ 𝑝𝑖 𝛼𝑖−1 𝐾 𝑖=1 Γ(𝑥)はガンマ関数,𝛼0= Σ𝛼𝑖 𝑝𝑖≥ 0 ,∑ 𝑝𝑖= 1を満たす。また,𝛼𝑖> 0 である。 LDA 法においては,尤度関数は多項分布であり,事 前分布はディリクレ分布である.多項分布にディリ クレ分布を掛け算すると,事後分布はディリクレ分 布となる.つまり,多項分布のパラメータとしての ディリクレ分布は,共役事前分布となる. 例: あるトピック「スポーツ」に関連する語とし て「勝負」「努力」という 2 種類の語がある.このト ピックの単語分布をディリクレ分布でモデル化した い.ハイパーパラメータ𝛽 = (2 , 2)として 1 次元デ ィリクレ分布を描くと以下のようになる.各語の出 現確率を𝑝1, 𝑝2とする.図 6 の横軸は𝑝1である. 図 6: 𝛽 = (2 , 2)のディリクレ分布.横軸は𝑝1. 図 7: 𝛽 = (2 , 2) のディリクレ分布.𝑥方向に𝑝1, 𝑦 方向に𝑝2をとった.𝑝1+ 𝑝2= 1 図 6 と図 7 は同じディリクレ分布を描いているが, 𝑝2= 1 − 𝑝1 の関係があるので,3 次元で描くと図 7 のようになる. 次に,特定トピックで出現する語の観測数の分布 を多項分布でモデル化する.例えば,トピック「ス ポーツ」に関連する語として,「勝負」「努力」が存 在すると仮定する.単語の出現確率が,(P 勝負, P 努力)=(0.5, 0.5) のように固定の場合,50 回試 行した場合,各語がそれぞれ𝑛1, 𝑛2回出現する確率 分布は,図 8 のような多項分布で与えられる.ここ で単語の出現確率パラメータを,ディリクレ分布の 単語分布によって表すことにする.ディリクレ分布 𝐷𝑖𝑟(𝛽) のパラメータは𝛽 = (2 , 2)とする.その混合 分布は図 9 のようになる. 図 8 :多項分布𝑀𝑢𝑙𝑡𝑖(𝑛|𝜙),試行回数 50 回.𝑃 = (0.5, 0.5)) 0.2 0.4 0.6 0.8 1.0 0.5 1.0 1.5 0.0 0.5 1.0 0.0 0.5 1.0 0.0 0.5 1.0 1.5
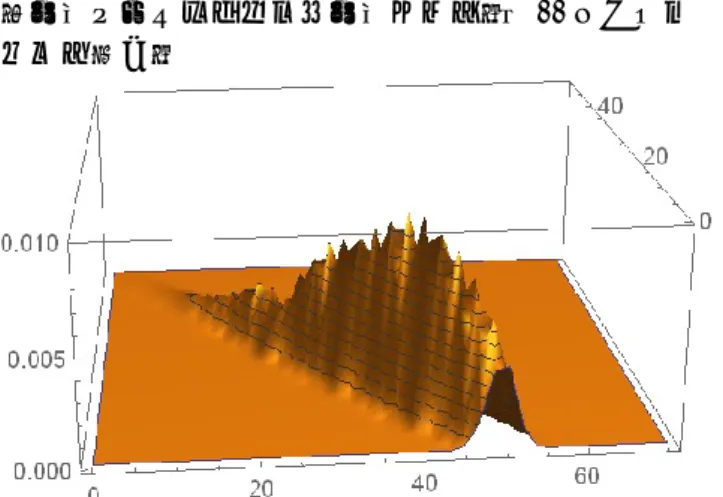
図 9:𝐷𝑖𝑟(𝛽) , 𝛽 = (2 , 2) というパラメータを与え た観測数の多項分布.試行回数 50 回.シミュレーシ ョンのため,関数が滑らかではないが,データ数を 増やすことで滑らかな曲面となる.データ数 10 万の 場合. 図 10 :𝐷𝑖𝑟(𝛽) , 𝛽 = (5 , 2) というパラメータを与 えた観測数の多項分布.試行回数50 回.データ数 10 万の場合. 同様に𝛽 = (5 , 2) の場合のディリクレ分布をパラ メータとする多項分布によって生成された観測数分 布を図 10 に示す.語「勝負」の出現回数が,語「努 力」の出現回数よりも大きいことが図から分かる. LDA 法では,文書𝑑 の各単語について,多項分布で その語のトピックを生成する.多項分布のパラメー タは,ディリクレ分布(文書𝑑 のトピック分布) θd とする. 例えば,トピックは,「スポーツ」と「政治」の2 つと仮定しよう.ハイパーパラメータ𝛼 = (2 , 2)とす る𝐷𝑖𝑟(𝛼) は,図 6 と同様の分布となる.文書𝑑 に単 語が 50 個あった場合,トピックの出現回数の確率分 布は図 9 のパラメータ混合分布と同じになる.図 9 から,「スポーツ」と「政治」の出現回数が等しく 25 のときの確率が最も大きいことが分かる.図 9 はデ ィリクレ分布であるが,それをパラメータとする多 項分布は再びディリクレ分布となる.図 11 にそのグ ラフを示す. 図 11 :𝐷𝑖𝑟(𝛽) , 𝛽 = (5 , 2) というパラメータを与 えた観測数の多項分布をさらにパラメータとして与 えた多項分布.多項分布の試行回数は,50 回とした. データ数は 1 万.
4 まとめ
本稿では,LDA 法に出てくる,多項分布のパラメー タをディリクレ分布にする,という混合分布の可視 化を行った.LDA 法においては,尤度関数は多項分布 であり,事前分布はディリクレ分布である.多項分 布にディリクレ分布を掛け算すると,事後分布はデ ィリクレ分布となる.つまり,多項分布のパラメー タとしてのディリクレ分布は,共役事前分布となる. LDA の説明においては,トピック数は2,単語数は 2 として,事前分布と,事後分布の可視化を行った. 多項分布のパラメータとしてディリクレ分布を与え てできる混合分布のイメージを 3 次元グラフィクス で示すことは,この共役性を視覚的に確認すること ができるので,LDA 法におけるモデルを理解する上 で有効と考える.今後とも,ベイズ推論に関する関 数の可視化の研究を続ける所存である.謝辞
本研究の一部は,2014 年度 学習院大学計算機セ ンター特別研究プロジェクト「アジア通貨危機時の 経済行動における不確実性の検証」(代表:白田由香 利)による.ここに記して謝意を表します.参考文献
[1] C. M. Bishop, Pattern Recognition and Machine Learning: Springer, 2006.
allocation,” Journal of Machine Learning Research, vol. 3, pp. 993-1022, 2003.
[3] S. Mathur. "Dirichlet and Friends,"
http://suhasmathur.com/2014/01/dirichlet-and-friends/. [4] T. L. Griffiths, and M. Steyvers, “"Finding scientific topics,”
Proceedings of the National Academy of Sciences, vol. 101
(Suppl. 1), pp. 5228–5235, 2004.
[5] 北島理沙, 小林一郎, “文書内の事象を対象にした潜在
的ディリクレ配分法による要約,” DEIM2011(第3回デ
ータ工学と情報マネジメントに関するフォーラム), pp.