Hadoop を利用した新聞記事群の関係抽出に関する研究
Hadoop Based Analyzing for Relations Among Articles of
Newspaper
金正福
† ‡川村秀憲
†鈴木恵二
†Abstract: 新聞記事は, 社会の動向を詳細に知ることができる, 重要な情報ソースである. 多様な形 態の新聞記事が蓄積され, その有効利用に向けて様々な工夫がなされている. 豊富な情報資源である 新聞記事からの知識発見に向けた, 有効な情報抽出法の獲得が望まれており, 本稿ではそのアプロー チの一つとして, 関連性に基づいた新聞記事ネットワークを構築, 分析を行い, その結果得られたいく つかの知見と今後の課題について論ずる.
1 序論
1.1 背景
新聞記事は, さまざまな分野の活動や社会情勢を伝え る情報の基礎資料となっている. 毎日の新聞記事から 過去の記事まで, 全国紙から地方紙, そして業界紙など の多様な新聞には, 膨大な情報が蓄積されている. これ らの膨大な情報を活用するためには, 新聞記事情報の検 索環境や資料の保存形態を理解した効果的な活用を図 ることが重要である. 現在は, データベースによる記事 検索やWeb 利用が可能となっているなど, より効果的 な利用環境の整備が図られている.
「ニュースは社会の鏡」と良く言われるが, 実際には この表現がそのまま当てはまらない場合も多い. 新聞 やテレビのニュースには, 制作者の考え方やメディアの 産業構造, メディアの特性などが深く影響しているもの だからである. とはいえ, 新聞はその時代の社会的な争 点や世論を色濃く映し出しているのも確かであり, その ために, 新聞記事は学術な調査・研究でも広く用いられ ている.
1.2 問題提起
計算機の発達に伴い, 大量の記事データを高速に取得 できるようになった. それにより, 従来人手で新聞記事 を解析せざるを得なかった分野においても計算機を用 いた解析などは一般的になり, 様々な分野に関する研究 が行われるようになった. しかし, 一つ一つの研究に関 しては, 新聞記事の特定の分野にとどまった解析が主と
†
連絡先:北海道大学工学部 情報エレクトロニクス学科 複雑系工学講座 調和系工学研究室
〒060-0014 北海道札幌市北区北 14 条西 9 丁目
‡E-mail: kin@complex.ist.hokudai.ac.jp
なっており, 新聞記事を単一の文書形態とみなして解 析を試みた研究はいまだ多くない. 社会の動向を伝え, 日々幅広い分野の話題を取り上げる, 新聞記事の特性を 活かした情報抽出法の確立が望まれる.
1.3 研究目的
以上から, 本研究では新聞記事の全紙面を対象とした 解析を行い, 有用な知見の創出に向けた情報の取得法の 獲得を目指す. その際には, あらかじめ問題を設定する ことなく, 社会における様々な課題や対策の相互関係, または傾向について分析する, 俯瞰的アプローチ [1][2] をとる. これにより, 従来の手法では見落としてしまう ような, 特殊な傾向や性質の発見を実現できる可能性が ある.
1.4 本稿の構成
本稿では, まず第 2 章で, 新聞データベースを用いた 関連研究として, 従来新聞記事データがどのように用い られてきたかを紹介し, 現状の問題点を明らかにする.
第3 章では, 既存の問題点を解消するために今回適用 したアプローチに関する説明を行う.
第4 章では, 今回実験に使用した分散処理技術である Hadoop の概要を, 基となった Google の技術と比較し ながら説明する.
第5 章において, 今回の実験で対象とした記事データ と, 実験方法及び調査方法について述べ, 第 6 章で得ら れた実験結果についての考察と現状で課題となる点を 説明する.
最後に, 第 7 章で今後の改善点を述べ, 本稿を締めく くりたい.
2 新聞データベースの解析
2.1 従来のテキストマイニングの対象
計算機の発達や自然言語処理技術の進歩に伴い, テキ ストデータの処理に関する様々な手法が提案されてい る. 従来では人手で処理しきれなかったようなデータ に対しても, テキストマイニングを適用することによ り, 有用な知見の創出につながるという期待が高まって いる[3].
例えば, コールセンターにおける顧客とのやりとりを 解析し, 商品に対する問い合わせや苦情, 要望などを自 動的に分類することで,「商品 X の仕様に関する問い合 わせが多い」,「この時期は商品 Y に関する問い合わせ が増加する」などといった傾向の分析に役立てること が出来る.
しかし, 新聞記事を対象とした研究は, 検索の支援や 記事推薦など, 効率的な情報取得に向けた研究が主流と なっており[4][5], 有用な知識発見に向けた研究は多く ない. 多様な分野の話題を取り上げる新聞から, 目的に 沿った記事を効率的に見つけ出す方法の確立が望まれ るのは必然であるとは言えるが, しかし同時に, 社会の 様々な活動を取り上げる新聞の蓄積から, 新しい発見を 求める研究も重要であると考えられる.
2.2 新聞記事のテキストマイニング
内海らの研究[1] では従来の情報検索について, キー ワード検索では物事の多面的な把握が十分に出来ない と指摘したうえで, 文書集合全体を鳥瞰できるような
「俯瞰的アプローチ」に基づく情報取得法を提案してい る. 具体的には, 医療に関連する記事を対象としたクラ スタリングを行い, がんや生活習慣病などの「医療課 題」と, 医薬品や手術器具名などの, 医療課題解決に結 びつく対策用語の抽出を目的とした研究を行っている. この研究では, 対象となる記事数が 8890 件と, 一般 的な新聞データベース上で利用可能な記事数と比較し ても, それほど大規模なデータ量とは言えない. 今後さ らに対象記事数を拡大したときに, 同様の手法が成立す るのかを慎重に検討する必要があると考えられる. こ の論文では結論として, 今後医療だけでなく, より幅広 い分野の記事を対象とした手法の開発を目指すと述べ ている.
このように, 新聞記事の, 情報量の豊富さや網羅性を 生かした情報抽出に関する研究は未だ行われていない. 本稿では, 情報資源としての新聞の利用価値を更に高め るために, 新聞記事データの全期間, 全紙面を対象とし た情報抽出技術の獲得を目的とする. そのためには, 解 析対象となる記事一つ一つに注目するのではなく, 何ら かの指標を以て記事間の関連性を定義し, ネットワーク
を構築, 解析することで, 特定分野に限定されない幅広 い知識の獲得を可能にする方法について検証を行った.
3 新聞記事ネットワーク
3.1 文書とネットワーク
知識獲得に向け, 関連するテキストでネットワークを 張るという研究は既にいくつか行われている. また, そ の際に問題となる, 文書間の関連性の指標についても 様々な議論がなされている.
若月らの研究[6] では,2 つの新聞記事間の意味的な関 連の強さを数値化する手法について提案している. 関 連性の強さの数値化には, 概念ベースと, 概念間の関連 性を判断する関連度計算を利用している.
概念ベースとは, 語の意味を, その語の特徴を表す属 性と, 属性の重要性を示す重みの対の集合で定義した知 識ベースで, 言語コーパスや辞書等からの自動的な獲得 によって構築される. 概念ベースは,
1. 概念
2. 概念の意味を表す属性 3. 属性の重要度を表す重み
の3 つで構成されており, これらは概念の関連度計算を する際に用いられる. 若月らの研究では, 概念ベースを 利用することで語の共有や共起などの表層的な情報以 外の要素を記事の関連性の計算に利用し, 従来のテキス ト分類で得られなかった, 意味的な関連性に基づいた文 書分類に成功している.
また, 佐藤ら [7] は, 文書間の関連性について, 同じ語 を共有するか否かで文書ネットワークを構築している. 従来の研究が, 完成したネットワークの解析法に関する 検証を主としており, そもそもネットワークを構築する 方法が各研究者によって恣意的に定められていると述 べたうえで, ネットワークを構築する段階での方法につ いて議論し, 妥当性について十分に検討する必要がある と述べている.
この論文では実際の応用例として, 関連する文書で構 成されたネットワークを用いて, web 上の文書に見られ る同姓同名人物の分離という課題に対し適用し, その結 果について考察を行っている.
この論文では, 文書の関連性を決定する指標として 1. 一般語
2. 人名
を用いている. 一般語とは, 地名や組織名などの固有名 詞を除いた名詞全般をいう.
まず, 一般語と人名それぞれについて tfidf 値を計算 する. tfidf 値が高い語を上位語とし, これらを用いて文 書ネットワークを構築する. 上位語として用いる語数 を変化させ, さらにグラフの稠密性, 連結性の二つの指 標を課題に適用した結果と, 構築されたネットワークの 性質との関連性について考察している. ネットワーク の性質として用いられたのは, 主に次数とクラスタ係数 で, これらに強い負の相関が見られた場合に同姓同名人 物の同定が正確に行えることを報告している.
3.2 本研究でのアプローチ
本実験では, 記事間の関連性に基づいた記事ネット ワークを構築し, 完成したネットワークの構造から知見 を発見しようとするアプローチをとる.
新聞記事の関連性の指標としては, 私見ではあるが以 下のようなものが挙げられる.
1. 日付
2. 掲載紙面(掲載ページ) 3. 文字数および段落数 4. 執筆者
5. 単語
これらの指標のうち,(1)∼(4) は記事の内容にまで関 わっているとは考えづらく, 基となる指標に付加するこ とで一定の効果が表れるような, 補完的な役割を持つと 考えられる. そこで今回は, 記事の見出しおよび本文に 含まれる名詞が最も記事の性質を良く表していると仮 定し, 名詞を記事間の関連性の指標に用いることにした. 記事中に含まれる名詞一般を「キーワード」と定義し, これらのキーワードを記事間で共通して保持している 記事群の特徴を調べた. 他に挙げた指標については, 今 後の課題として検討していく予定である.
3.3 ネットワークの構築法
どのようなルールで記事間に関連性を見出し, ネット ワークを構築したかを以下に記述する.
まず適当な記事を一つ選び, その記事をルート記事 arootとしてネットワークの始点とする. arootの単語集 合 w(root) と aiの単語集合 w(i) を比較し, 最も重複数 が多い記事を a1とする. 次に,w(1) のうち arootと a1
で重複する単語を除いた単語集合 w(r) \ w(1) と最も 重複数が多い記事を a2とする. 以下順に, a3,a4,· · ·,an とする.
a1= max
i {w (aroot) ∩ w (ai)}
(root = 0) (1)
ak = max
j ({w (aj−2) \w (aj−1)} ∩ w (ai))
(k ≥ 2) (2) 今回は, 以上のような条件で記事ネットワークを構築 した. なお, これらの計算を行う際, 大量の記事データ の中から条件に合致した記事を一つ一つ見つけ出すに は, 多大な計算コストがかかると予想される. そこで本 研究では, 複数の計算機を用いた並列分散処理技術を用 いることで, この問題の解決を試みた.
4 Hadoop
今回は並列処理技術であるHadop[8] を用いて実験 を行った. Hadoop は, 大量の大規模データを分散処 理することを目的とした, オープンソースのプラット フォー ム で あ る. Google が開発した分散データファ イルシステムである「Google File System」(GFS) と 分散処理フレームワークである「MapReduce」を基に した, 「Hadoop Distributed File System」(HDFS) と
「Hadoop MapReduce」, さらに, 分散データベース「Big Table」を模した「HBase」で構成される.
並列処理技術に関しては, メッセージ通信による複 数の計算機の協調動作を可能にしたMPI や, 複数コア による共有メモリ型並列計算機であるOpenMP など が他に挙げられる. Hadoop は, 処理機能としての計算 ノードに関しても, 分散してデータを保存するファイル システムに関しても, 必要な時に必要なだけ容易に追加 できるという拡張性の高さがある. 新聞記事のような 日々データが増大する対象に対して,Hadoop の持つこ のようなスケーラビリティの高さが有効であると考え られる.
5 実験
5.1 本実験でのクラスタの構成
今回の実験では4 台の Hadoop クラスタ PC を用い て記事ネットワークを構築した.
各ノードの計算処理を監視するマスターノード1 台 と, データを保持し計算処理を行うスレーブノード 3 台 に分かれて動作する. 以下, 各計算ノードを n1∼n4と
する. マスターノードを n1, スレーブノードを n2∼n4
として割り当てる.
札幌 函館 釧路 旭川 帯広 十勝 苫小牧 小樽 室蘭 北見 網走 根室 岩見沢 江別 留萌 胆振 空知 千歳 稚内 日高 石狩 後志 富良野 上川
表 1: 掲載数の多い北海道地名
まず, 実行するプログラムファイルが n1から各スレー
ブノードに配布される. プログラム実行の際, 各スレー ブノードは入力として,
1. 現時点での記事ネットワークの末端記事 ID 2. 重複数としてカウントされるキーワードリスト 3. 重複から除外する(含んではいけない)キーワー
ドリスト
を同時に読み込む. 各スレーブノードは,n2∼n4で構成
されたHDFS 上に保存されている全記事データから, 各ノードで分散して該当する記事を探し出す. 入力に 対する結果として, 各スレーブノードは, 各記事の
1. 記事 ID
2. キーワードの重複数 3. 重複したキーワードリスト
をマスターノードに出力する. 以上が Map 処理にあた る部分である.
Reduce 処理にあたる部分では, 各スレーブノードか らMap 処理で出力された結果をマスターノードに集約 する. 全ての結果から最も重複数の多い記事 ID を最終 的な出力とする.
5.2 対象データ
本実験では, 北海道新聞データベース [9] 上で提供さ れている新聞記事270 万件を対象とした. 対象期間は 1988 年∼2007 年の約 19 年間である. これらの記事の 見出しと本文全てについて,Mecab[10] を用いて形態素 解析を行った. 形態素解析の結果, 固有名詞と判定され た形態素のうち, 重複を除外した全異なり語は約 18 万 となった. これらの固有名詞について, 掲載記事数上位 100 語を抜き出したところ, そのうちの 24 語が北海道 の地名となっており, 各地域の話題を幅広く取り扱う, 地方紙の特性を示す何らかの傾向がみられることが期 待できる(表1).
図1: 記事ネットワークのルート記事
5.3 記事ネットワーク
今回の実験で用いたルート記事の見出し, 日付を図 1 に示す. ルート記事を始点として,Hadoop を用いた計 算処理を a100が求まるまで繰り返し行い, 記事ネット ワークを生成した. このネットワーク内の記事一つ一 つについて, 見出しの内容に則した「政治」,「観光」,
「スポーツ」などのラベル付けを独自に行った(表 2). 記事ネットワークのラベルと見出しの一覧の一部を表 3 に示す. ここで, 表 3 から,a11と a12(「汚職」),a16
と a17(「選挙」),a18と a19(「政治」)のように同一 のラベルが連続しているものを「自己ループ」とし,a10
(「スポーツ」),a11(「汚職」)のように, 接続されたラ ベル同士が異なる組み合わせと区別する. 実験結果か ら, まず, ネットワークの前後の接続関係からみられる 事例をいくつか確認した(調査 1). また, 同一のラベル でグループ化したネットワーク構造を俯瞰すると,「選 挙」,「国際」,「地方」,「経済」をラベルに持つノード が, 他のラベルを持つ多数のノードとつながっており, ハブのような特徴を持っていることがわかった(調査 2).
選挙 国際 経済 地方 政治 医療 自治 スポーツ 予算 観光 犯罪 外交 防災 少子化 汚職 データ 人事 災害 法律 社会保障 社説 年金 憲法
表2: 見出しラベル
以降で, 本実験で確認された事例について説明する.
6 考察
6.1 調査 1:記事ネットワークの接続関係
生成されたネットワークの性質としては, ネットワー クの始点と終点である arootと a100を除いて, 他の記事 は全て出次数, 入次数ともに 1 となっている. また, 第 3 章の式(1),(2) より,ai−1と aiでキーワードの重複数が 多い場合, ai+1として候補に挙がる記事は, 基本的に ai とキーワードの重複が少なくなる. 逆も同様で,ai−1と aiでキーワードの重複数が少ない場合には,ai+1 は ai とのキーワードの重複が多くなる. 一般的に, キーワー ドの重複が多い記事同士ほど内容も関連度が高く, 重複
記事ID 日付 ラベル 見出し
a10 2001/11/04 スポーツ 札幌J1残留*今季の札幌*「堅守からの速攻」定着
a11 2004/03/02 汚職 道警報償費疑惑*元弟子屈署次長の証言(要旨)
a12 2004/11/21 汚職 どこまで開示 道警裏金全容*あす内部調査最終報告*「私的流用なし」固持
a13 2004/03/28 選挙
参院選出馬予定者アンケート*消費増税「不可避」 自・民の過半数* 早期改憲に「賛成」 全体の4割に
a14 1999/09/30 政治
自自公協議 大筋で合意*多国籍軍* 後方支援,法整備へ*定住外国人*地方参政権付与も a15 1998/04/12 外交
18日から日ロ首相会談*大統領決断にかける日本* 信頼関係をてこに*共同経済活動も前向き
a16 2001/02/19 選挙 4氏が対決,清水町長選を振り返って*公約に違い少なく 欠けた盛り上がり
a17 2001/11/30 選挙 <2001浦河町長選>町議補選も熱い戦い*欠員2,議会運営を左右
a18 1990/10/14 政治
<激突「中東」国会> 中 自民内の亀裂−協力法で賛否両論. ポスト海部をにらむ動きも
a19 1990/10/19 政治
「自衛隊の国連軍参加は憲法上問題」,衆院予算委で法制局長官−「防衛の範囲逸脱」. 首相,加盟時の留保を否定
表3: 記事ネットワークの見出し一覧(一部抜粋)
記事ID:a92
✓ ✏
<視角触角>菅・民主代表が辞任*党再生「切り札」不在*「小沢不信」根強く*参院選へ増す不安 国民年金未加入問題の責任を取り民主党の菅直人代表が十日辞任を表明したことで, 今後の焦点は「ポスト 菅」に移った. 自らの退陣と引き換えに, 年金制度改革関連法案に関する三党合意の党内了承にこだわったの は, 三党合意反対の急先鋒(せんぽう)だった小沢一郎代表代行に「党を乗っ取られかねない」(菅氏周辺)と の危機感があったからだ. 菅氏の思惑通り「小沢代表」の可能性はしぼみつつあるが, 後任人事の難航は必至. 代表の未加入問題と辞任で傷ついた党のイメージ回復を担う「切り札」は, 容易に見つかりそうにない.
(東京政経部 坂東和之, 山本武史)
(以下省略)
(2004/05/11, 北海道新聞朝刊全道, 3 ページ, 1404 文字)
✒ ✑
記事ID:a93
✓ ✏
民主代表 小沢氏受諾*「剛腕」に期待と警戒*党イメージ 変質の懸念
民主党の新代表選びは十四日, 小沢一郎代表代行の就任で決着した. 党の「顔」として知名度と手腕に期待 が集まる一方, トップダウン式の強権的な「小沢流」には党内に警戒感がくすぶる. 小沢氏の代表就任で「若 さと透明性」を売りにしてきた党のイメージが変質する可能性もあり, 参院選を前に, 民主党は大きなかけに 出たといえる.
「菅直人代表は(党内の)会議に出席していたが, 私は出られない場合もある. それでもいいか」. 同日午 後の岡田克也幹事長との会談で, 代表受諾を伝えた小沢氏は, 自らの政治スタイルを変えないことへの了承を 求めた.
民主党は一九九六年の結党以来, 鳩山由紀夫前代表と菅氏が交代で代表を務め, どんな小さなことも話し合 いで決めてきた. 一方の小沢氏は, 自民党時代「数は力」で多数派を形成して力を誇示, 自らの言葉での説明 を嫌うなど民主党のイメージとは相いれない面を持つ.
(以下省略)
(2004/05/15, 北海道新聞朝刊全道, 3 ページ, 1004 文字)
✒ ✑
図 2: 記事ネットワークの一例(太字は重複キーワード)
が少ないほど関連度は薄れると考えられる. このこと から, 今回の手法で生成される記事ネットワークは, 重 複数が多い組合せと少ない組合せが繰り返し繋がる構 造となると考えられる. すなわち, 関連性の高い, 取り 上げられる話題や内容が似たような記事対と, そうでな い記事対が繰り返し現れると予想される. また, 今回は キーワード毎に重みづけを行わず, 出現頻度も考慮して いないため, 重複するキーワードの組合せ次第では意外 な記事が繋がる, もしくは全く関係のない記事同士が繋 がってしまう可能性も考慮しなければならない.
このようなネットワークの性質を考慮しつつ, 本章で はネットワークの前後の接続関係を調査し, 確認できた 事例について説明する.
6.2 事例 1
まず一つ目の事例として, ネットワーク内で, 民主党 代表の辞任を報じた記事(a92) と, 次期代表の就任を報 じた記事(a93) が連続している部分が確認できた(表 4). 日付はいずれも 2004 年 5 月付となっている. a92
が掲載された後の日付では, 新代表候補に関する記事が 数日間にわたって多数掲載されていた. これらの記事 でも a92と同じ話題が取り上げられており, キーワード が多数重複していると考えられる. しかし, これらの記 事に比べ日付が離れた a93が直接繋がり, ある出来ごと の発端と結末についての記事が連鎖している例が確認 できた.
6.3 事例 2
次の事例(表5)は, サッカーに関する記事 (a10) と 警察の汚職告発についての記事(a11) という, 内容に関 連性が見られない例である. これらは, それぞれ 2001 年,2004 年と日付が離れており, また記事の内容につい ても特に関連が無い. 今回の実験設定が, 記事間での キーワードの重複という, ごく単純な条件であったた め, このような連鎖が見られたと考えられる.
6.4 事例 3
最後に, 人事に関する記事 (a40,a42) や選挙に関する 記事(a41) などの, 人名が多数羅列されていたり, 名簿 リストのようなものが掲載された記事による連鎖の例 を示す(表6). これらの記事は, 新聞記事において紙 面を占める面積が他の記事に比べ著しく大きく, そのた め記事を構成するキーワードが多数検出される結果と なった. 今回の連鎖 a40∼a42では日付や地域などの関 連性は見られなかったが, 日付の近い記事を選びだした り, 記事に記載された地名に重みを付与するなどして,
適切な関連性の定義が出来れば, これらの記事から何ら かの事実を発見できる可能性がある. また, 人名や組織 名などの固有表現を抽出する研究や, 同姓同名人物の特 定に関する研究が広く行われている. これらの手法を 今回の実験に追加して適用することで, 有益な情報の抽 出が期待できる.
6.5 調査 2:記事ネットワークの構造
調査1 ではネットワークの一部を取り出し, その前後 関係からいくつかの事例を確認した. 調査 2 では, 生成 された記事ネットワークの全体を俯瞰し, 個々の記事が ネットワーク内でどのような性質を持つかを調べた.
表2 の見出しラベルから, 同一のラベルを持つ記事群 をネットワークにおける一つのノードと見なし, 個々の ラベルに関するネットワークを構築した(ラベルネッ トワーク). その際, 他のラベルとの接続関係において, 前後関係, すなわちノードからノードへの辺の向きを考 慮せずにリンクを張り, 全体を俯瞰した.
まず, ラベルネットワークを可視化し, 記事数の多い ラベルとそうでないラベルを区分し, それらのリンクの 特徴を調べた. 次に, ネットワークの次数分布やラベル 間の接続関係について調査を行った.
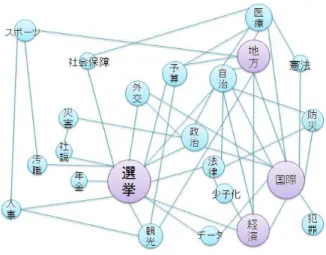
6.6 ネットワークの可視化
図3. は, 先に述べたラベルネットワークを可視化し たものである. 多くの記事によって構成されたラベル ほど, 大きく表示している. 最も記事数の大きいラベル が「選挙」で次数が17, 次いで「国際」が 11,「地方」,
「経済」が8 となっている. 特に記事数が多いこれらの ラベル(大ラベル)が, 記事数が少ない他のラベル(小 ラベル)とどのようにつながっているかを調べた.
まず, 小ラベルは少なくとも一つ以上の大ラベルとつ ながっているのがわかる. 4 つの大ラベルが他の全ての 小ラベルを間接的につなぐ性質を持ち, 結果としてラベ ル間の距離が非常に近いネットワークを形成している のがわかる. さらに, 個々の大ラベルが多数の小ラベル とリンクを持っていることから, 大ラベルとなる記事が 豊富な語彙を持ち, 様々なラベルを持つ記事を網羅でき るほどの多様性があるということがこの結果から考え られる.
大ラベルと小ラベルの関係性に関してもう一つ明ら かになったのが,「自治」のラベルが小ラベルの内で唯 一全ての大ラベルとリンクを持っているという点であ る. 「自治」ラベルは, ネットワーク内の全てのラベル と最大でも2 リンクのみでつながっており, 大ラベルほ どの記事数を持たないものの, 他のラベル同士を結び付 ける性質を持っていることがわかる.
重複数 記事ID 日付 ラベル 見出し
48
a92 2004/05/11 政治
<視角触角>菅・民主代表が辞任*党再生「切り札」不在
*「小沢不信」根強く*参院選へ増す不安
a93 2004/05/15 政治
民主代表 小沢氏受諾*「剛腕」に期待と警戒* 党イメージ 変質の懸念
表4: 事例 1 民主党代表辞任及び新代表就任に関する記事
重複数 記事ID 日付 ラベル 見出し
8 a10 2001/11/04 スポーツ 札幌J1残留*今季の札幌*「堅守からの速攻」定着
a11 2004/03/02 汚職 道警報償費疑惑*元弟子屈署次長の証言(要旨)
表5: 事例 2 スポーツと汚職告発に関する記事
重複数 記事ID 日付 ラベル 見出し
64 a10 2007/03/27 選挙
<2007統一地方選>道議選30日告示 4月8日投開票(2の1)* 48選挙区 構図鮮明に*道東,道北
a11 2007/03/23 人事 <公立高,特殊学校の人事>教諭
48 a12 1995/07/24 選挙 <95参院選>道選挙区市町村別投票率(3の2)
表6: 事例 3 人事や選挙に関する記事
図4: ラベル毎の構成記事数
図3: 見出しラベルのネットワーク
6.7 構造上の性質
図4 に各ラベルの構成記事数のグラフを示した. さ らに, ネットワークの前後関係で, 各ラベルの自己ルー プの分布を調べた. その結果, 基本的に構成記事数が多 いラベルほど自己ループも多くなるという傾向が見ら れるものの, 一部のラベルでは自己ループが全くない, すなわち, 接続関係が全て自身を除く他のラベルとの間 に形成されたラベルがいくつか確認出来た. それらの 自己ループが無いラベルの内, 最も構成記事数が多いの が「自治」ラベルでとなっている(構成記事数6). こ のことから, この「自治」ラベルが新聞記事内で複数の 分野に及ぶ多様な語彙を持ち, なおかつ自身のラベルを 特徴づける語をあまり多く持たないという特徴がある ことがわかった.
7 結論
本稿では, 新聞記事の関連性に基づいた情報抽出法の 発見を目的とし, 記事ネットワークを構築する実験を行 い,. その結果についていくつかの事例を確認した実験 の結果, ある特定のラベルが付与された記事群につい ては, 他のラベル同士を結び付けるハブのような役割を 持っていることが発見された. 今回の実験では, 記事間 の関連性について時間の関係を考慮しなかったため, 日 付, 内容ともに関連性の見られない記事の連鎖が多数生 成されるという結果が生じてしまった. 今後の課題と して, 時間の関係を考慮するための有効な指標を定義し ていく必要がある.
謝辞
本研究で使用した新聞記事データは, 株式会社北海道 新聞社様より提供していただきました. この場を借り て厚く御礼申し上げます.
参考文献
[1] 内海和夫,乾孝司,橋本泰一,村上浩司,石川正道.
”社会課題とその解決に結びつく科学技術に関する 有用知識の抽出”,社会技術研究論文集. Vol.6, 187-198,(2009).
[2] 奥田英範,川島晴美,佐藤吉秀,宮原伸二,定方徹.
”俯瞰的アプローチに基づく情報場ナビゲーション 技術”,NTT 技術ジャーナル. 22-25 (2006). [3] 吉田稔,中川裕志. ”テキストマイニングの活用¡特
集¿データマイニングの活用”,社団法人情報科学 技術協会. 情報科学と技術. Vol.60,No.6,(2010). [4] 高野敦子, 平井誠, ”新聞記事検索における観点を 考慮したクエリー拡張手法”. 情報処理学会研究報 告. 自然言語処理研究会報告 Vol.2002, No.104 , pp 107-114, (2002)
[5] 松井くにお, 橋本三奈子, 内野寛治, ”新聞記事の 検索支援システム”. 情報の科学と技術 Vol. 53 , No.11, pp 540-545, (2003)
[6] 若月紀之, 渡部広一, 河岡司. ”概念ベースと関連度 計算を用いた新聞記事の分類(意味 (言語モデル・ 文書分類))”. 情報処理学会研究報告. 自然言語処 理研究会報告Vol.1, pp. 67-72, (2005)
[7] 佐藤進也,福田健介,風間一洋,村上健一郎. ”語の 共有に基づく文書ネットワークの構造的特徴につい て”,情報処理学会論文誌. Vol.47,No.3,(2006). [8] http://hadoop.apache.org/, Apache Hadoop [9] https://t21.nikkei.co.jp/g3/p01/LCMN0F11.do/
doshin/, 北海道新聞データベース [10] http://mecab.sourceforge.net/, Mecab