DEIM Forum 2016 C8-6
CRF による参考文献書誌情報抽出のための辞書素性の拡充
松岡
大樹
†太田
学
††高須 淳宏
†††安達
淳
†††† 岡山大学工学部情報系学科 〒 700–8530 岡山市北区津島中 3 丁目 1 番 1 号
†† 岡山大学大学院自然科学研究科 〒 700–8530 岡山市北区津島中 3 丁目 1 番 1 号
††† 国立情報学研究所 〒 101–8430 東京都千代田区一ツ橋 2-1-2
E-mail:
†[email protected], ††[email protected], †††{takasu, adachi}@nii.ac.jp
あらまし 膨大な文書が格納されている電子図書館を運用するためには,書誌情報データベースの整備が必要である.
特に,学術論文の参考文献欄には,タイトルや著者名などの有用な書誌情報が集約されている.本研究では Conditional
Random Field を用いて参考文献文字列から書誌情報を自動抽出するが,その際,利用する素性が抽出精度を決定する.
これまでの研究により,辞書素性の有効性が確認されているため,本研究では,正解データを利用して参考文献文字
列の全てのトークンに対応する文字列をエントリに持つ完全書誌要素対応辞書を作成し,辞書エントリの拡充により
見込める抽出精度を評価した.さらに,その知見に基づいて,実際に使用する辞書エントリの拡充について考察する.
キーワード
情報抽出,Conditional Random Feild,参考文献文字列,辞書素性
1.
は じ め に
多数の学術論文を蓄積している電子図書館のサービスでは, 検索やソート,文書間リンク等の機能は必須といえる.しかし, そのための書誌情報を人手でデータベースに登録するコストは 膨大なため,その作業を可能な限り自動化する文書解析技術が 求められている.特に学術論文の参考文献欄には,関連する文 献の情報が集約されており,タイトルや著者名などの書誌情報 は有用である. 本研究では川上ら[1]と同様の方法で,Conditional Random Field (CRF) [2]を用いて,参考文献文字列から書誌情報を自動 抽出する.CRFを用いた参考文献書誌情報抽出においては,利 用する素性が書誌情報の抽出精度を決定する.我々は,どのよ うな素性が書誌情報の高精度抽出に有効であるのか検討し,辞 書素性が有効であることを確認した[3].そこで本研究では,正 解データを利用して,参考文献文字列の全てのトークンに対応 する文字列をエントリに持つ完全書誌要素対応辞書を作成し, 辞書エントリの拡充により見込める抽出精度を評価する.そし て,完全書誌要素対応辞書を用いた実験の結果等に基づいて辞 書エントリの拡充に関して考察する. 本稿の構成は次の通りである.2節で学術論文からの書誌情 報抽出に関する研究を紹介し,続く3節で本研究で行うCRF による参考文献書誌情報の自動抽出について説明する.4節で 完全書誌要素対応辞書について述べ,5節で実験による評価を 行う.そして6節で辞書エントリの拡充に関して考察し,最後 に7節で本稿をまとめる.2.
関 連 研 究
多数の学術論文を格納する電子図書館において,書誌情報の 管理は必須であるが,学術論文からの書誌情報抽出では,ルー ルや機械学習がよく用いられる.ルールを用いて論文の,例え ば参考文献文字列から書誌情報を抽出する場合,図1のように, 図 1 学術論文誌による参考文献文字列の書式の違い 著者名,タイトル,発行年などの書式が異なる論文誌ごとに抽 出のためのルールを設定する必要がある.しかし,近年では学 術論文の数が増大し,論文誌ごとにルールを設定し,管理する ことが困難になりつつある.そのため,学習データを準備すれ ば,どの学術論文にも対応することのできる機械学習が注目さ れている. 機 械 学 習 に よ る 書 誌 情 報 抽 出 に は ,阿 辺 川 ら[4],Okada ら[5],Peng ら[6]や Councillら[7]の 研 究 が あ る .本 研 究 で は ,CRF [2] を 用 い て 書 誌 情 報 を 抽 出 す る が ,阿 辺 川 ら[4],Okadaら[5]はSupport Vector Machine(SVM) [8]やHidden
Marlov Model(HMM) [9]を利用して書誌情報を抽出した.阿辺 川らは,pdftohtml(注 1)を用いて学術論文のPDFファイルから, 位置やフォント情報を抽出した.次に,“ はじめに ”や“ Intro-duction”などを手がかり語として,論文の本文が開始される前 までをテキストとして切り出した.また,ファイル末尾の“ 参 考文献 ”,“Reference”などの語を手がかり語として,参考文献 文字列をテキストとして切り出した.論文の1ページ目の本文 が開始されるまでのテキストに対しては,SVMを用いて書誌 情報を抽出した.このとき,ページ上部からの距離や,フォン (注1):http://pdftohtml.sourceforge.net
トサイズの差などの視覚的素性と,“ はじめに ”や“ 参考文献 ” などのキーワードや文字クラスなどの言語的素性を利用した. そして,参考文献文字列からはHMMとSVMのそれぞれを用 いて書誌情報を抽出した.その際,日本語と英語では学習のモ デルが異なると考え,参考文献文字列を和文と英文に分類して 実験を行っている.HMMを用いた手法においては,文字クラ スを入力とし,状態遷移モデルを用いて書誌情報を抽出した. また,SVMを用いた手法においては,文字そのものを素性と し,状態遷移モデルを用いて書誌情報を抽出した.実験の結果, タイトルページからの書誌情報抽出精度が論文単位で69.2%, 参考文献文字列からの書誌情報抽出精度が,和文で74.8%,英 文で81.6%であった.Okadaらは,カンマや“vol.”,“no.”,
“pp.”,“ed.”といった特定の文字列をデリミタとして参考文 献文字列をトークンに変換し,SVMとHMMを用いて各トー クンに書誌要素ラベルを付与した.実験では,電子情報通信学 会論文誌Vol.J83-DIIのNo.1からNo.12に掲載されている論文
の参考文献文字列を対象にし,97.6%の精度で書誌情報を抽出 した. Pengら[6]やCouncillら[7]はHMMやCRFを用いて書誌 情報を抽出した.Pengらはタイトルページと参考文献欄の単語 ごとに書誌要素ラベルを付与した.タイトルページにおける書 誌情報抽出では,英語論文935件を対象に,500件を学習デー タ,435件をテストデータとして実験を行った.著者名やタイ トル,所属など13項目の書誌情報を抽出し,そのF値の平均 は0.939であった.一方,参考文献欄からの書誌情報抽出にお いては,英語論文500件を対象に,350件を学習データ,150件 をテストデータとして実験を行った.著者名や論文誌名,日付 など13項目の書誌情報を抽出し,そのF値の平均は0.915で あった.また,Councillらは,参考文献文字列から書誌情報を 抽出する,CRFに基づく書誌情報抽出ツールであるParsCitを 開発した.ParsCitでは,空白文字をデリミタとして英文の参考 文献文字列をトークン列に変換し,そのトークン列に書誌要素 ラベルを付与する.彼らの実験は,Coraデータセット[10]を対 象に,著者名やタイトルなど13項目の書誌情報を抽出し,そ のF値の平均は0.950であった. Ohtaら[11]は,書誌情報抽出における学習データ生成コス トの削減に関する研究を行った.Ohtaらは,CRFにより書誌 情報を抽出する際に,能動サンプリングにより学習データを削 減する方法を提案した.能動サンプリングは,CRFの学習の際 に有効なデータを効率よく選択する方法である.具体的には, 書誌情報抽出結果に確信度を定義し,ある時点の学習モデルに おいて,書誌情報抽出が困難な学習データを次回の学習データ とする方法である.Ohtaらの書誌情報抽出では,文書画像の 学術論文のタイトルページに対して,OCRによりレイアウト 解析と文字認識を行い,CRFを用いて矩形テキスト領域に対し て書誌要素ラベルを付与する.能動サンプリングを用いた実験 の結果では,書誌情報抽出精度を維持したまま,学習データ量 を三分の一以下に削減できたと報告している.さらにOhtaら は[12]において,論文タイトルページからCRFにより抽出し た書誌情報の誤り検出を確信度に基づいて行うことで,人手に 図 2 参考文献書誌情報抽出の例 表 1 抽出する書誌情報 [1] 書誌要素 書誌要素ラベル Author RA Editor RE Translator RTR
Author Other RAOT
Title RT Booktitle RBT Journal RW Conference RC Volume RV Number RN Page RPP Publisher RP Day RD Month RM Year RY Location RL URL RURL Other ROT よる後処理のコストを抑えながら,高品質な書誌情報が得られ ることを示した.これらの研究はいずれも論文タイトルページ からの書誌情報抽出であるが,本研究では川上ら[1]の研究を もとに,レイアウト情報を持たない参考文献文字列から書誌情 報を抽出する.
3.
CRF
による書誌情報抽出
3. 1 書誌情報抽出 本研究では,学術論文の参考文献文字列から書誌情報を自動 抽出する.具体的には図2のように参考文献文字列をまずトー クン列に変換し,その後トークン列から著者名やタイトルと いった主要な書誌情報を抽出する.参考文献文字列から抽出す る書誌情報の一覧とそれに対応する書誌要素ラベルを表1にま とめる[1].表1のOtherは他のどの書誌要素にも分類されない 書誌要素であり,具体的には所属機関などが含まれる.本研究 では図2に示すように,トークン列の各トークンに対してRA やRTなどの書誌要素ラベル,またはDCなどのデリミタラベルを付与する.なお,図2でDから始まるラベルはデリミタラ ベルを表し,DC(カンマ+空白)などが定義されている[1]. 3. 2 CRF 本研究の書誌情報抽出では,標準的なチェーンモデルの CRF [2]の定義を用いて,参考文献文字列をトークン列に変換 し,そのトークン列に書誌要素ラベルを付与する.またCRFで は,入力系列x= x1, . . . , xnが与えられたとき,出力ラベル系列 がy= y1, . . . , ynとなる条件付き確率を以下のように与える. P (y|x) = 1 Zx exp n ∑ i=1 ∑ k λkfk(yi−1, yi, x) (1) ただし、Zxは,全てのラベル系列を考慮したときに確率の和が 1となるための正規化項で, Zx= ∑ y′∈Y(x) exp n ∑ i=1 ∑ k λkfk ( y′i−1, y′i, x ) (2) である.ここで,fk(yi−1, yi, x)は(i− 1)番目とi番目の出力ラ ベルと入力系列xに依存する任意の素性関数である.λkは素 性関数 fkの重みを表すパラメータで学習により定める.また, Y (x)は入力系列xに対する出力ラベル系列の集合である.そし て,入力系列xに対する最適な出力ラベル系列y∗は次式で与 えられる. y∗= arg max y∈Y(x) P(y|x) (3) 本研究の書誌情報抽出では,ラベル付与の対象である入力xi は,参考文献文字列をトークン化して得られるトークンであり, 一方,ラベルyiは,書誌要素またはデリミタのラベルである. 本稿の実験では,書誌要素ラベル付与の精度を評価するため, トークン化は人手で行った. 3. 3 素性テンプレート 本研究では工藤が作成したCRF++(注 2)を利用して書誌情報 を抽出する.CRF++で用いる素性テンプレートは川上らの素性 テンプレート[1]を拡充したもの使用する[3].これを表2にま とめる.素性テンプレートについて説明する.この素性テンプ レートは56種類のUnigram素性と1種類のBigram素性の合計 57種類の素性で構成されている.これらは全て言語的な素性で, レイアウトに関する素性はない.Unigram素性には,トークン のトークン列における出現位置や文字数,トークンを構成する 文字種とその割合,トークンの先頭・末尾から四文字目までの 文字列,大文字などの特定の文字や特徴的な文字列,各種辞書 のエントリの有無などを用いている.また,<dictionary(i)>に おける辞書としては,人名(注 3),月名,地名(注 4),出版社名(注5), 論文誌名(注 6),会議名(注 7)の辞書と,学会誌名や新聞紙名など の分類困難なものをまとめた辞書の7種類の辞書を使用する. (注2):http://taku910.github.io/crfpp/ (注3):http://www.census.gov/genealogy/names/など (注4):http://www.fallingrain.com/world/index.html など (注5):http://www.narosa.com/nbd/PublisherDistributed.asp など (注6):http://science.thomsonreuters.com など (注7):http://www.allconferences.com/など 表 2 素性テンプレート [3] 種類 素性 数 内容
Unigram <token ab pos(0)> 1 トークン列における絶対的な出現位置 <token re pos(0)> 1 トークン列における相対的な出現位置 <num char(0)> 1 トークンの文字数 <num word(0)> 4 トークン内の単語数 <num period(0)> 4 トークン内のピリオド数 <f kanji(0)> 1 トークン内の漢字数の割合 <f hiragana(0)> 1 トークン内のひらがな数の割合 <f katakana(0)> 1 トークン内のカタカナ数の割合 <f alphabet(0)> 1 トークン内の全角アルファベット数の割合 <f digit(0)> 1 トークン内の全角数字数の割合 <h alphabet(0)> 1 トークン内の半角アルファベット数の割合 <h digit(0)> 1 トークン内の半角数字数の割合 <h symbol(0)> 1 トークン内の記号数の割合 <first 1-4 string(0)> 4 トークンの先頭から四文字目までの文字列 <last 1-4 string(0)> 4 トークンの末尾から四文字目までの文字列 <token(0)> 1 トークン自身 <last char(i)> 1 トークンの最後の文字種 <token lc(i)> 1 トークンを小文字にした文字列 <capital(i)> 1 トークン中の大文字の有無 <digit(i)> 1 トークン中の数字の有無 <symbol(i)> 2 トークン中の記号の有無 <keyword(i)> 4 トークン中の特徴的な文字列の有無 <dictionary(i)> 15 辞書的素性 <num token(0)> 1 参考文献文字列のトークン数 <editor(0)> 1 参考文献文字列中の Editor に関する記述の有無 <URL(0)> 1 参考文献文字列中の URL に関する記述の有無
Bigram < y(-1), y(0)> 1 ラベルの遷移
また,辞書素性には,どの辞書のエントリに一致したかを示す Dictという素性があり,この素性はヒットしたエントリを持つ 辞書のビットを1とし,2進表現したものを10進数に直した素 性である.例えば,“July”という文字列が人名,月名の2つの 辞書にヒットすると,Dictの値は3となる. また,[3]において拡充した素性は,<keyword(i)>に含まれる 日本語姓辞書の素性と,<dictionary(i)>に含まれる7種類の辞 書素性である.川上ら[1]は,<keyword(i)>に含まれる日本語 姓辞書においては完全一致,前方一致,後方一致,部分一致,不 一致の5段階の照合判定を用いた.一方,<dictionary(i)>に含 まれる7種類の辞書においては,各辞書のエントリに一致した か一致してないかの2段階の照合判定を用いた.これを[3]で, どの辞書においても2段階と5段階のどちらの照合判定も可能 にした.よって追加した素性は,日本語姓辞書と2段階の照合 判定を行った素性が1種類と,それ以外の辞書と5段階の照合 判定を行った素性が7種類である.表2の各素性の括弧内の数 字はトークンの相対位置を表し,0が現在のトークンである.ま たi∈ {−4, −3, −2, −1, 0, 1, 2, 3, 4}である.なお,表2で,“ 数 ” はその素性に関する要素数を表し,例えば,<first 1-4 string(0)> の場合,トークンの先頭の文字,先頭から二文字目までの文字, 先頭から三文字目までの文字,先頭から四文字目までの文字と いう4つの要素を持つ.また,書誌要素ラベルの遷移を考慮す るためBigram素性を用いる.この素性は付与される書誌要素 ラベルの連接に関する情報を表し,これにより,例えば,著者 名の後にタイトルがくるといった書誌要素の出現順に関する制 約を考慮することができる.
4.
完全書誌要素対応辞書
本研究では,正解データを利用して全てのトークンに対応す る文字列をエントリに持つ完全書誌要素対応辞書を作成し,そ表 3 書誌要素ラベルの再分類 [1]
書誌要素ラベル 分類名
RA, RE, RTR, RAOT AUTHOR
RT, RBT TITLE RW, RC JOURNAL RV, RN, RPP VOLUME RP PUBLISHER RD DAY RM MONTH RY YEAR
RL, RURL, ROT OTHER
表 4 作成した辞書
辞書 IEICE-J IEICE-E IPSJ 3journal
AUTHOR 7,210 6,272 6,730 19,391 TITLE 4,409 4,289 4,308 12,835 JOURNAL 1,551 1,747 2,026 5,004 VOLUME 2,221 2,181 1,763 3,441 PUBLISHER 274 336 400 842 DAY 9 54 11 67 MONTH 23 31 32 58 YEAR 60 59 52 78 OTHER 224 432 618 1,107 れを用いて書誌情報抽出精度を評価する.本研究においては, 表1に示した書誌情報を先行研究[1]に倣って表3のように集約 して正解判定を行うため,これに対応する辞書を作成した.よっ て,AUTHOR,TITLE,JOURNAL,VOLUME,PUBLISHER,
DAY,MONTH,YEAR,OTHERの9種類の辞書を作成した.
辞書は,実験で使用する3つの論文誌である,電子情報通信学会 和文論文誌(IEICE-J),電子情報通信学会英文論文誌(IEICE-E), 情報処理学会論文誌(IPSJ)の正解データから,表1に示した書 誌要素ごとにトークンを抽出し,それを表3のように集約して, 重複を除いて作成する.つまり,作成した辞書は正解データの 全てのトークンの文字列を含んでいる.このようにして作成し た辞書のエントリ数を表4に示す.表4には論文誌ごとに作成 した辞書のエントリ数と,全ての論文誌をまとめて作成した辞 書のエントリ数があるが,実験は全ての論文誌をまとめて作成 した辞書である3journalを使用する.なお,辞書3journalにお いても作成の際に重複を削除している. CRFにより書誌要素ラベルを付与する際は,作成した9種 類の辞書を表2の<dictionary(i)>に含まれる人名辞書,月名辞 書,地名辞書,出版社名辞書,論文誌名辞書,会議名辞書,分 類困難なものをまとめた辞書と入れ替える.また,Dictはこの 辞書の入れ替えに伴い,図3のようにする.図3では,ある
トークンがVOLUME,DAY,MONTHの3つの辞書のエント リに一致した場合を示しており,このときDictの値は104にな る.この結果辞書素性は,Dict素性が1種類と各辞書における 2段階の照合判定を用いた素性と5段階の照合判定を用いた素 性の18種類があり,合計19種類となる.よって,作成した辞 書を用いた実験は,60種類のUnigram素性と1種類のBigram 素性の合計61種類の素性を用いて行う. 図 3 変更後の Dict 素性 表 5 完全書誌要素対応辞書を用いたときの抽出精度 論文誌 川上ら [1] の辞書 完全書誌要素対応辞書 IEICE-J 0.9662 0.9887 IEICE-E 0.9709 0.9895 IPSJ 0.9646 0.9906
5.
評 価 実 験
5. 1 実 験 概 要 4節に示した完全書誌要素対応辞書を用いて書誌情報抽出精 度を算出する.実験データとして,以下の参考文献文字列コー パスを利用する. IEICE-J 2000年の電子情報通信学会和文論文誌に含まれる参 考文献文字列4,787件(内,和文2,193件) IEICE-E 2000年の電子情報通信学会英文論文誌に含まれる参 考文献文字列4,497件(内,和文0件) IPSJ 2000年の情報処理学会論文誌に含まれる参考文献文字列 4,574件(内,和文1,537件) 参考文献文字列に含まれる書誌要素が過不足なく抽出された 参考文献文字列数を,全参考文献文字列数で割ったものを書誌 情報抽出精度と定め,評価指標とする.また,この精度は5分 割交差検定を用いて算出する.ただし,書誌要素ラベル付与に おいては,表1を先行研究[1]に倣って表3のように集約し, 表3において同じ分類のものは正解判定において区別しない. そして,表3の分類に基づいて,CRFが全てのトークンに正し い書誌要素ラベルを付与した場合を成功とみなす.また,デリ ミタの種類の誤りは無視する.実験において,CRF++の学習パ ラメータはデフォルトの値を利用した. 5. 2 完全書誌要素対応辞書の効果 4節に示した完全書誌要素対応辞書を用いて実験を行い,書 誌情報抽出精度を算出した.結果を表5に示す.完全書誌要素 対応辞書を用いた結果,川上ら[1]の辞書に比べ,IEICE-Jにお いて2.25ポイント,IEICE-Eにおいて1.86ポイント,IPSJに おいて2.6ポイント抽出精度が向上した.この結果から,辞書 を拡充し,照合するエントリが増えれば抽出精度の向上が期待 できることがわかる. また,Dictと9種類の辞書の中でどの素性が有効であるか確 かめるため,それぞれの辞書素性を1種類ずつを除いて比較 実験を行った.なお,各辞書の素性を除いて比較するときには(a) IEICE-J (b) IEICE-E (c) IPSJ 図 4 完全書誌要素対応辞書による比較実験 Dict素性は常に使用しない.素性を除いて実験を行っているた め,精度が大きく低下した素性ほど書誌情報抽出精度への寄与 が大きいといえる.実験の結果を図4に示す.図4の(a)より,
IEICE-Jにおいては,TITLE,JOURNAL,VOLUMEの辞書を それぞれ除いたときに抽出精度が大きく低下していることがわ かる.この結果から,IEICE-Jにおいては,TITLE,JOURNAL,
VOLUMEの3つの辞書が特に有効であるといえる.その中で
もJOURNAL辞書の寄与が1番大きい.また,図4の(b)よ
り,IEICE-Eにおいては,AUTHOR,TITLE,JOURNALの辞 書をそれぞれ除いたときの抽出精度の低下が大きい.この結果 から,IEICE-Eにおいては,AUTHOR,TITLE,JOURNALの
表 6 エントリ追加による書誌情報抽出精度の比較 論文誌 書誌情報抽出精度 エントリ追加後の書誌情報抽出精度 IEICE-J 0.9662 0.9659 IEICE-E 0.9709 0.9702 IPSJ 0.9646 0.9646 3つの辞書が特に有効であることがわかる.IEICE-Eにおいて もIEICE-Jと同様に,JOURNAL辞書の寄与が1番大きい.そ
して,図4の(c)より,IPSJにおいては,TITLE,JOUNRAL
の辞書をそれぞれ除いたときの抽出精度の低下が大きい.こ の結果から,IPSJにおいては,TITLE,JOURNALの2つの辞 書が特に有効であることが確認できる.IPSJにおいても,前 の2雑誌と同様,JOURNAL辞書の寄与が1番大きい.TITLE, JOURNALの2つの辞書はどの雑誌においても書誌情報抽出精 度に大きな寄与を示したが,TITLE辞書の作成は一般には困難 だと考えられる.よって,実用的にはJOURNAL辞書のエント リを拡充させることにより,書誌情報抽出精度の向上が期待で きる.この辞書は表1と表3より論文誌名や会議名の辞書のこ とである.
6.
辞書エントリの拡充に関する考察
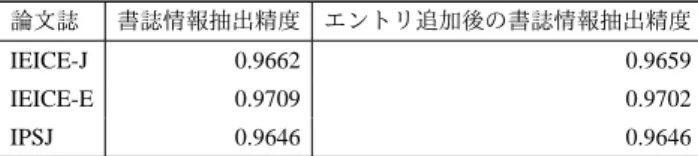
5. 2節の実験より,論文誌名や会議名の辞書のエントリの追 加が書誌情報抽出精度の向上に有効であることがわかった.そ こで,無作為に論文誌名辞書にエントリを追加して実験を行い, 辞書にどのようなエントリを追加すれば書誌情報を高精度に抽 出できるか考察する. 実験では,論文誌名辞書に日本語,および英語のエントリを 追加した.日本語のエントリはNII学術情報ナビゲータ(CiNii) の刊行物ディレクトリ(注 8),および電子情報通信学会の学術雑 誌略語表(注9)より,1,042件追加した.また,英語のエントリ はdblp(注10)のjournalの一覧より,742件追加した.なお,こ れらエントリ数は既存のエントリとの重複を削除した後のエン トリ数である.エントリを追加した論文誌名辞書を用いて実験 を行った結果を表6に示す.表6より,いずれの雑誌において もほとんど差は見られなかった.よって,無作為にエントリを 1,800件程度追加しても,抽出精度への影響はほとんどないこ とがわかる.抽出精度への影響がほとんどない理由としては, 本稿で追加したエントリは無作為に選択したため,実際に実験 データの参考文献にヒットするエントリが少なかったことが挙 げられる.例えば英語のエントリは,全て論文誌名の正式名称 を追加したため,省略して記載されている論文誌名には一致し ない.よって,辞書にエントリを追加する際には,その学術論 文の体裁等からよく使われている論文誌名の見当をつけて,エ ントリに追加することが重要である.また,論文誌名は雑誌に よって省略されて表記されることがあり,それを考慮して省略 名も辞書に加える必要がある.このように辞書にエントリを追 加すれば,ヒットするエントリが増え,抽出精度の向上が期待 (注8):http://ci.nii.ac.jp/journal/society/all ja.html (注9):https://www.ieice.org/jpn/shiori/pdf/furoku e.pdf (注10):http://dblp.uni-trier.de/できる. 今後は,この知見を生かし,有効であると確認できた論文誌 名辞書や会議名辞書のエントリを追加していく予定である.
7.
ま と め
本稿では,CRFによる参考文献書誌情報の高精度抽出のた めに完全書誌要素対応辞書を作成し,辞書エントリの拡充によ り見込める抽出精度を評価した.実験の結果,完全書誌要素対 応辞書を使用すれば,川上らの辞書に比べ,IEICE-Jにおいて 2.25ポイント,IEICE-Eにおいて1.86ポイント,IPSJにおいて 2.6ポイント書誌情報抽出精度が向上することを確認した.さ らに,各辞書素性の中でどの辞書が有効であるか実験を行い, IEICE-Jにおいては論文題目名,論文誌名,会議名,ボリュー ム,ページ番号の辞書,IEICE-Eにおいては著者名,論文題目 名,論文誌名,会議名の辞書,IPSJにおいては論文題目名,論 文誌名,会議名の辞書が有効であることを確認した.また,辞 書にどのようなエントリを追加すれば書誌情報を高精度に抽出 できるかについて考察した.今後は,実験結果から得られた知 見をもとに,辞書のエントリを拡充する予定である.謝
辞
本研究の一部は,科学研究費補助金基盤研究(B)(課題番号 15H02789),科学研究費補助金基盤研究(C)(課題番号25330384), および国立情報学研究所公募型共同研究の援助による.ここに 記して深謝する. 文 献 [1] 川上尚慶, 太田学, 高須淳宏, 安達淳, “少量学習データによる参考 文献書誌情報抽出精度の向上”, 情報処理学会論文誌データベー ス, vol. 8, no. 2, pp. 18–29, 2015.[2] J. Lafferty, A. McCallum and F. Pereira, “Conditional Random Fields : Probabilistic Models for Segmenting and Labeling Sequence Data”, In Proc. of 18th International Conference on Machine Learning, pp. 282–289, 2001. [3] 松岡大樹, 太田学, 高須淳宏, 安達淳, “CRF による参考文献書誌 情報抽出のための有効な素性の検討と拡充”, 情報処理学会研究 報告, vol. 2015-DBS-162, no. 3, pp. 1–8, 2015. [4] 阿辺川武, 難波英嗣, 高村大也, 奥村学, “機械学習による科学 技術論文からの書誌情報の自動抽出”, 情報処理学会研究報告, 2003-FI-72/2003-NL-157, pp. 83-90, 2003.
[5] T. Okada, A. Takasu, and J. Adachi, “Bibliographic Component Ex-traction Using Support Vector Machines and Hidden Markov Mod-els”, ECDL 2004, LNCS 3332, pp. 501-512, 2004.
[6] F. Peng, A. McCallum, “Accurate Information Extraction from Re-search Papers Using Conditional Random Fields”, HLT-NAACL 2004, pp. 329–336, 2004.
[7] I.G. Councill, C.L. Giles and M.Y. Kan, “ParsCit: An Open-Source CRF Reference String Parsing Package”, In Proc. of language re-source and evaluation conference, 2008.
[8] C.Cortes and V.Vapnik, “Support-Vector Networks”, Machine Learn-ing, vol.20, no. 3, pp.273-297, 1995.
[9] K.Seymore, A.McCallum and R.Rosenfeld, “Learning hidden Markov model structure for information extraction”, In AAAI 99 Workshop on Machine Learning for Information Extraction, 1999. [10] A. McCallum, K. Nigam, J. Rennie and K. Seymore, “Automating
the Construction of Internet Portals with Machine Learning”, Infor-mation Retrieval, vol. 3, no. 2, pp. 127-163, 2000.
[11] M. Ohta, R. Inoue, A. Takasu, “Empirical Evaluation of Active Sam-pling for CRF-Based Analysis of Pages”, In Proc. of IEEE IRI 2010, pp. 13–18, 2010.
[12] M. Ohta, R. Inoue, A. Takasu, “Empirical Evaluation of CRF-Based Bibliography Extraction from Research Papers”, IADIS International Journal on Computer Science and Information Systems, vol. 7, no. 2, pp. 18–31, 2012.
![表 2 素性テンプレート [3]](https://thumb-ap.123doks.com/thumbv2/123deta/8192566.1277461/3.892.467.791.63.455/表2素性テンプレート3.webp)
![表 3 書誌要素ラベルの再分類 [1]](https://thumb-ap.123doks.com/thumbv2/123deta/8192566.1277461/4.892.497.770.63.273/表3書誌要素ラベルの再分類1.webp)