仮想リオーダ・バッファ方式における選択的先行実行による低消費電力化
8
0
0
全文
(2) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report. を行い,6 節で本論文をまとめる.. 4 issue queue for pre-execution (FIFOs). 2. 関 連 研 究. 3 notify availability of ROB entry. 2.1 先 行 実 行 本論文で用いる VROB 方式は,先行実行に基づくものであるが,これまでにも多くの先. PC. 行実行を利用したプリフェッチ手法が提案されている2),9) .しかし,これらの手法の多くは. 1. 別スレッドを生成して先行実行するというもので,マルチスレッド環境を必要とする.. RPC. 単一スレッド環境において先行実行を行う手法として,Mutlu らは runahead 実行を提. L1 I-cache. rename allocate dispatch. 2 initiate or terminate instruction refetch. 8). 案した .この手法は L2 キャッシュ・ミスが生じると,プロセッサ状態をチェックポイント し,ミスが解決するまで runahead モードと呼ぶ特別のモードに移る.このモードでは,ミ. main issue queue. physical registers. functional units. ROB. L1 D-cache. LSQ. 図 1 VROB プロセッサの構成 Fig. 1 Organization of processor with VROB.. スした命令に依存していない命令を実行する.この時,ロードがキャッシュ・ミスを起こせ ば,データがプリフェッチされる.この手法の欠点は,runahead 実行中にはプロセッサ状 態を更新する本来の命令実行を並行して行えないという点である.. FQ. 2.2 先行実行方式における省電力化. PC. 先行実行を行う場合での電力の高効率化について,Mutlu らは runahead 実行方式にお. rename allocate. I-cache. 7). ける省電力化手法を提案している .これは過去の runahead 実行を学習し,効果の小さい. RPC. 命令の先行実行を抑制することで全体の実行命令数を削減する.. RFQ. 3. 仮想リオーダ・バッファ方式による命令の先行実行. 図 2 命令フェッチの構成 Fig. 2 Organization of instruction fetch.. 1再 図 1 に VROB 方式を実装したプロセッサの構成を示す.通常の構成要素に加え, 2 ディスパッチ・ステージから RPC へ再フェッチ フェッチ用 PC(RPC: refetch PC), 3 ROB から先行実行用発行キューへ ROB に空きエントリ の開始・停止を指示する信号,. ワーディング・バッファ(FB: forwarding buffer)1) を用いる.FB はオペランド・タグで. 4 先行実行用の FIFO 発行キューが追加されている. が生じたことを伝える信号,及び. 連想検索可能な小さなバッファであり,最近の先行実行の結果を保持している.バイパス論. 3.1 先行実行・本実行. 理による実行結果の受け渡しに失敗した場合でも,FB にその結果があれば,後続の依存命. 従来のプロセッサでは,命令に ROB を割り当てることができない場合,命令はストール. 令を先行実行できる.FB からも結果値を得られなかった場合は,これらの命令は発行でき. する.これに対し,VROB 方式では ROB が不足している場合には,ROB 及び物理レジス. 3 によって発行キューから削除される(3.2 節で詳述). ず,後に本節の冒頭で示した信号. 命令の先行ディスパッチを開始したら,直ちにそれらの命令の再フェッチを開始し,本実. タを割り当てないまま命令を発行キューへ挿入する.これを先行ディスパッチと呼ぶ.先行. 2 に示すと 行に備える.再フェッチは,再フェッチ用の PC である RPC を用いて行う.図 1. ディスパッチされた命令は,ソース・オペランドが揃えば発行され,先行実行を行う. 先行実行は物理レジスタを割り当てられていないため,結果を保持することはできない. おり,RPC は先行ディスパッチを開始した際に,その最初の先行ディスパッチ命令の PC で. が,バイパス論理を経由して後続命令に受け渡すことはできる.ただし,バイパス論理に. 初期化する.再フェッチした命令は,図 2 に示すとおり再フェッチ・キュー(RFQ: refetch. よる結果の受け渡しは実行後1サイクルしか有効でない.この制約を緩和するために,フォ. queue)と呼ぶ一時バッファへ格納する.一方,PC によってフェッチされた命令は,フェッ. 2. c 2011 Information Processing Society of Japan.
(3) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report. チ・キュー(FQ)と呼ぶ別のバッファへ格納される.. tail. 再フェッチは,先行ディスパッチされた命令を全て本実行するまで継続する.再フェッチ. r-tail. 4N-1. 3N. 2N. N-1. 0. 0. head 0. N. を終了するタイミングを検出するため,先行ディスパッチ・カウンタと呼ぶカウンタを用意 する.このカウンタは本実行されるべき命令数を表し,命令を先行ディスパッチした際にイ ンクリメントする.一方,再フェッチした命令を発行キューへ挿入した際にデクリメントす. k-1. 0. k. real ROB. る.カウンタ値が 0 となった場合,必要な本実行は全て行われることが確定するため,再. 0. virtual entry number physical entry number. virtual ROB. フェッチを終了し,RFQ をフラッシュする.. 図 3 仮想 ROB(M = 4) Fig. 3 Virtual reorder buffer(M = 4).. 命令フェッチ及び再フェッチは時分割で行う.再フェッチを優先して行い,RFQ が満杯と なった場合に PC によるフェッチを行う.これは本実行のスループットの方が,先行実行よ りも性能において重要となるからである.また,リネーム・ステージにおける FQ または. られる.この場合においては本来,命令は先行実行結果の受け渡しに失敗した時点で削除さ. RFQ からの読み出しも,同様に時分割で行う.まず RFQ の先頭の命令について,資源割. れるべきである.しかし,実際には結果受け渡しの成功率は非常に高く, (2)の状態が生じ. り当てが可能かを確認し,可能であれば RFQ から命令を読み出す.不可能であれば FQ か. ることは稀である.従って,これによる性能への影響は小さい.. ら読み出す.. 3.3 ROB の利用可能性の伝達. 3.2 先行ディスパッチ命令の削除 3.2.1 概. リネーム時に ROB が満杯でエントリを割り当てることができなけば,もしも空いていた. 要. とするなら割り当てられたはずの ROB のエントリを命令に割り当てる.これを先行割り当. 先行ディスパッチされた命令は,以下の場合においては発行される前に発行キューから削. てと呼ぶ.これは概念的には ROB を仮想的に拡大したことに相当し,ROB に関する資源. 除されなければならない.. (1) (2). 制約を緩和し先行実行を可能とする.. 先行実行する前に,本実行に必要な資源が利用可能となった場合.この場合,命令は. 図 3 に仮想的に拡大された ROB の概念図を示す.この図では,実エントリ数 N の ROB. 本実行可能となるため,もはや先行実行を行う必要はない.. を M = 4 倍に拡大した場合を例示している.図において,ROB の上部の数字は仮想的に. バイパス論理及び FB による先行実行結果の受け渡しに失敗した場合.この場合,後. 拡大された ROB 全体の仮想エントリ番号を表し,下部の数字は ROB を循環バッファで実. 続の依存命令は発行不能となり,発行キューに取り残される.. 装した時の物理エントリ番号を表している. (仮想エントリ番号 mod N )が物理エントリ番. (1)の場合に対応するため,次のようにして資源の利用可能性を発行キュー内の命令に. 号となる.従って,1 つの物理エントリには 1 つの実エントリと (M − 1) 個の仮想エント. 伝達する.ROB から命令がコミットされ空きエントリが生じたら,そのエントリの ID 番. リがマッピングされる.以後,仮想的に拡大された ROB 全体を仮想 ROB,実在の ROB. 号(3.3 節で述べる仮想エントリ番号)を発行キューへ放送する.発行キューでは,先行ディ. を実 ROB と呼ぶ.. スパッチされた命令について,そのエントリが,もし ROB に空きがあれば自身が割り当て. 仮想 ROB の先頭と末尾を,それぞれ head,tail ポインタが指す.一方,実 ROB の先頭. られたはずのエントリかどうかを判断する.もしそうであれば,その命令を発行キューから. は仮想 ROB と同一であり head ポインタが指すが,末尾は別途 r-tail(real tail)と呼ぶ. 削除する.削除された命令は必要な資源を割り当てられた上で,RFQ から発行キューへ再. ポインタが指す(これらのポインタは全て仮想エントリ番号を持つ).リネーム・ステージ. ディスパッチされる.なお,厳密には ROB が利用可能であっても,その他の資源が割り当. において ROB が満杯の場合,命令には仮想エントリを割り当て,tail ポインタのみを更新. て可能であるとは限らず,直ちに再ディスパッチ可能であることは保証されない.しかし,. する.これが前述した先行割り当てである.. すべての資源のバランスがとれた設計においては,ほぼ良い近似を示すと考えられる.. 図 4 に,先行ディスパッチされる命令の発行キューへの挿入及び削除の様子を表す.命令. この方法の欠点としては, (2)の場合の命令の削除としてはタイミングが遅いことが挙げ. は,先行割り当てされた ROB エントリの仮想エントリ番号と共に発行キューへ挿入される. 3. c 2011 Information Processing Society of Japan.
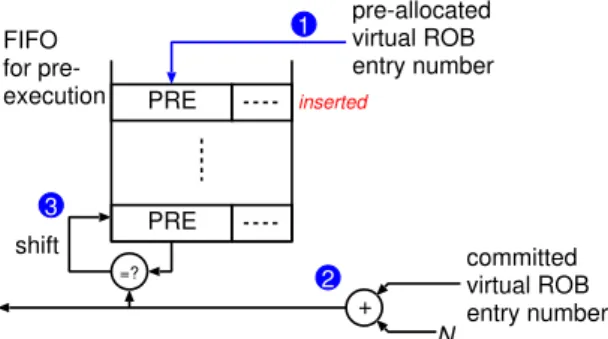
(4) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report. PRE. は,以下の内容を保持する:. pre-allocated virtual ROB entry number. 1. FIFO for preexecution. • 有効ビット(V フラグ) • L2 キャッシュ・ミス回数を数えるカウンタ. inserted. • ロード命令の PC の一部(タグ) • 4.2 節で述べる TP 探索がすでに行われたかどうかを示すビット(C フラグ). 3. L2 キャッシュ・ミスを起したロードはコミットされる際,MCT の対応するエントリを参. PRE. shift =?. committed virtual ROB entry number. 2 +. 照する.エントリにヒットしたら,そのエントリのカウンタをアップする.ミスの場合,カ ウンタを 1 にセットし,C フラグをリセットする.L2 キャッシュ・ミスの頻度を測るため. N. に,一定間隔で全有効ビットをクリアし,MCT をリセットする.ロードがカウンタを増加. 図 4 発行キューへの挿入及び削除(N は実 ROB サイズ) Fig. 4 Insert and removal of instructions in issue queue.. させる際,カウンタ値があらかじめ定めた閾値に到達し,C フラグがセットされていなけれ ば,そのロードを delinquent と判定する.delinquent ロードは,次回実行時に,4.2 節で. 1 ).仮想エントリ番号を保持するために,発行キューの各エントリに PRE(pre-allocated (. 述べる TP 探索を起動する.TP 探索が終了したら,C フラグをセットし,以後,現在のイ. ROB entry)フィールドを追加する.資源の利用可能性を伝達するため,ROB から命令が. ンターバルにおいては,再び TP 探索しないよう制御する.. コミットされたら,その ((仮想エントリ番号 + N ) mod (N × M )) が発行キューへ放送さ. 4.2 TP 命令の動的探索. 2 ,図 1 3 も参照).この値は,解放された物理エントリが次に割り当てられる仮想 れる(. delinquent ロードの TP 命令の探索のため,delinquent ロードに先行して実行される命令. エントリの番号を表している.発行キューでは,先行ディスパッチされた命令について,そ. を解析する.そのため,コミットされた命令を順に蓄える RIB(retired instruction buffer). の PRE フィールドが保持している仮想エントリ番号と放送されてきたエントリ番号とを比. と呼ぶ FIFO のバッファを用意する.RIB には,命令の PC と論理デスティネーション・. 較する.一致すれば,そのエントリに割り当てられた命令に先行割り当てされた ROB のエ. レジスタ番号および論理ソース・レジスタ番号を保持する.RIB はコミットされた順に命. ントリが利用可能となったことを意味する.この場合,その命令を発行キューから削除する. 令を保持するため,プログラム順で命令が並ぶ.. 3 ).なお,3.1 節で述べたように,先行ディスパッチされた命令は即座に再フェッチされ (. TP 命令の探索は 2 段階で行われる.第 1 段階は,RIB を起動し,コミットされた命令. るため,削除された命令は多くの場合,すでに RFQ の先頭で待ち合わせている.. を格納する段階である.RIB は,通常,低電力モード(電源電圧降下もしくは電源供給停 止)にあり,トリガ信号により起動し,コミットされた命令を格納していく.そして,第 2. 4. 先行実行命令候補の抽出. 段階の TP 命令抽出が終了したら低電力モードに遷移する.このように必要に応じて起動. 本節では,先行実行命令候補の抽出方法6) について説明する.本手法における先行実行命令. することにより RIB による無駄な電力消費を抑える.. は,delinquent ロードとそれが直接,あるいは間接的に依存する命令(TP 命令: transitive. まず,MCT によって delinquent ロードが検出されたら,その命令をトリガとしてマー. producer)のみとする.それぞれの抽出の方式について順に説明する.. クする.これは,命令キャッシュにフラグ(TG フラグ)を用意して記憶する.その後,ト. 4.1 delinquent ロードの検出. リガ命令がフェッチされたら MCT を参照する.C フラグがセットされていなければ,TP. 第 1 節で述べたとおり,delinquent ロードとは,頻繁に L2 キャッシュ・ミスを起すロード. 探索は行われていない.トリガ命令のデコード時に RIB を起動し,以後,トリガ命令がコ. である.そのため,ロードが delinquent かどうかを判断するには,一定期間での L2 キャッ. ミットされるまで,先行してコミットされる命令を RIB に書き込む.. シュ・ミス回数を計測すればよい.delinquent ロード検出のため,ロードの命令アドレス. 第 2 段階は,トリガ命令がコミットされるタイミングで開始される.この段階では,RIB. をインデクスとする MCT(miss count table)と呼ぶ表を用意する.この表の各エントリ. を末尾から先頭に向かって読み出し,データフロー解析を行い,TP 命令を抽出する.この. 4. c 2011 Information Processing Society of Japan.
(5) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report. 1:. LIV E := sreg of delinquent load;. 3 に示すようにその命令を TP として ン・レジスタ(dreg)が LIVE に属しているなら,. 2:. foreach inst ∈ RIB (from tail to head) {. 5 に示すように sreg を マークする(5 行目).そして,LIVE から dreg を除き(6 行目),. 3:. if (LIV E = φ) break;. 4:. if (dreg o inst ∈ LIV E) {. LIVE に加える(7 行目). 集合 LIVE はビット・ベクタで表す.つまり,レジスタ i が LIVE に属していれば,第 i. 5:. mark inst as “TP”;. 番目のビットを 1 とする.こうすれば,集合演算はビット毎の論理演算という単純なハー. 6:. LIV E := LIV E − dreg of inst;. ドウェアで行うことができる.また,TP としてのマークは,命令キャッシュにそれを保持. 7:. LIV E := LIV E ∪ sreg(s) of inst;. するビット(TP フラグ)を用意して記憶する.以上の TP 探索が終了すると,MCT の C. }. 8: 9:. ビットをセットする.また,RIB を低電力モードとし電力消費を抑える.. }. 以後,フェッチされた命令が TG 命令または TP 命令とマークされている場合,それらの 図 5 TP 命令抽出アルゴリズム Fig. 5 TP instruction extraction lgorithm.. 命令は先行実行の対象となる.ROB が不足し,先行実行を行う状態になったら,TG また は TP 命令のみを先行ディスパッチする. ある delinquent ロードが RIB を起動した後で,他の delinquent ロード(まだ TP 探索. PC. ..... ..... 0x5. 4. 1. 5. ..... 3. ..... 2. ..... 1. ..... 0x1. .... 3. RIB dreg sreg1 sreg2. ..... TP. されていないもの)がフェッチされた場合,RIB は既に稼働中である.TP 探索は,RIB を. 0x8. 7. 4. 起動させた delinquent ロードが行わなければならないので,後者の delinquent ロードは. LIVE 2,3,5 4 2 1. RIB を起動することができない.そのような場合には TP 探索は行わず,次回の実行以降 に延期される.. LIVE 1,5. グラムの実行のフェーズ移行に追従するためである.追従しなければ,TP 命令集合が不必. LIVE. 要に大きくなり,不要な先行実行が生じる.また,これらのフラグは,命令キャッシュに保. 4. 持するため,キャッシュが書き換えられる際に消去されるが,命令キャッシュ・ミスが起こ. TP フラグおよび TG フラグは,MCT リセットの際に,全てクリアする.これは,プロ. ることは稀であり,消去された後に再度必要となる可能性は低いものと考えられる.. 4.3 選択的先行実行の VROB 方式への適応. 図 6 TP 命令抽出時の動作 Fig. 6 Example of TP instruction extraction.. VROB 方式では ROB が不足していた場合,ROB 及び物理レジスタを割り当てないま ま,命令を先行ディスパッチする.この先行ディスパッチされる命令を,TP 探索によって. 解析では,データフロー・グラフを delinquent ロード(トリガ命令)を始点としてエッジ. TP フラグがセットされた命令のみに限定することで,選択的先行実行を VROB 方式に適. を逆方向に遡り,至ったノードに対応する命令を TP 命令としてマークする.具体的には,. 応する.ただし,TP フラグがセットされておらず,先行ディスパッチがスキップされた命. 図 5 に示すアルゴリズムで実現する.また,この時の動作を図 6 に示す.. 令についても,後に RFQ から再フェッチされ,本実行される必要がある.. RIB を起動するタイミングは,delinquent ロードを本実行ディスパッチするタイミング 1 に示すように delinquent ロードのソース・レジスタ(sreg)を集合 LIVE の まず,図 6 の. とする.ここで本実行ディスパッチとは,命令に ROB や物理レジスタなどを割り当てた後,. 初期値とする(図 5,1 行目).次に,RIB を末尾から先頭に向かって順番に読み出し,LIVE. 本実行を行うためにディスパッチすることを表す.この場合,TP 探索を行う命令数は,最. 2 に示すように読み出した命令のデスティネーショ が空になるまで,以下の動作を行う.. 大でも実 ROB のエントリ数と同数の命令のみとなる.. 5. c 2011 Information Processing Society of Japan.
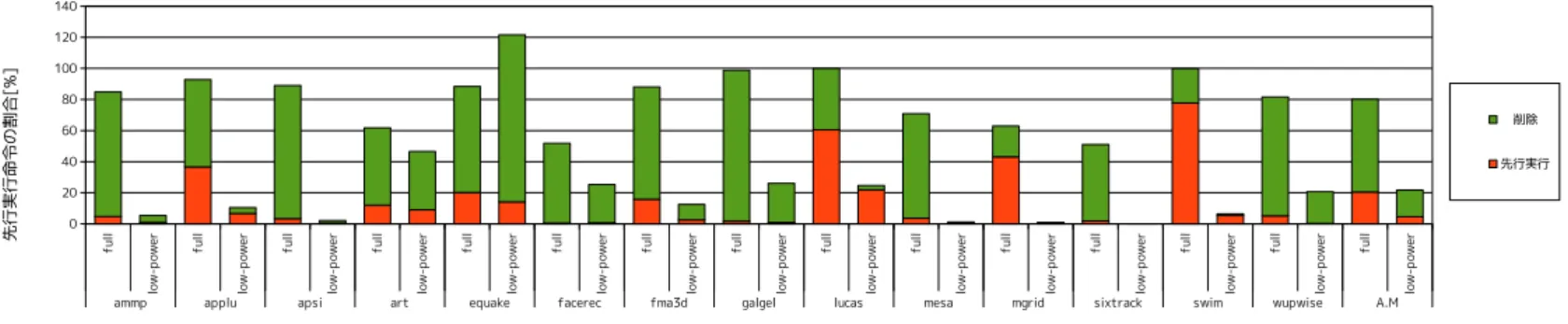
(6) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report 表 1 キャッシュの MPKI 及びメモリ・アクセス率 Table 1 Statistics of cache and memory accesses.. program ammp applu apsi art equake facerec fma3d galgel lucas mesa mgrid sixtrack swim wupwise. MPKI L1 data L2 21.8 0.7 24.0 17.0 4.0 1.0 108.3 10.1 70.1 26.4 3.8 1.6 15.6 12.1 19.0 1.1 26.3 21.9 1.3 0.6 19.4 6.6 0.9 0.3 39.7 20.1 4.6 2.3. memory access rate 0.3 6.1 0.4 5.1 6.4 0.7 4.3 0.3 9.4 0.2 2.1 0.2 9.4 1.2. 表 2 ベース・プロセッサの構成 Table 2 Configration of base processor.. Pipeline width. memory intensive? no yes no yes yes no yes no yes no moderately no yes moderately. Real ROB Fetch queue Issue queue LSQ Physical regsiter Function unit L1 I-cache L1 D-cache L2 cache Main memory Branch prediction. 5. 評. 価. 4-instruction wide for each of fetch, decode, issue, and commit 128 entries 16 entries 128 entries 128 entries 128 for int and fp 4 iALU, 2 iMULT/DIV, 2 Ld/St, 4 fpALU, 2 fpMULT/DIV/SQRT 64KB, 2-way, 32B line 64KB, 2-way, 32B line, 2 ports, 2-cycle hit latency, non-blocking 2MB, 4-way, 64B line, 12-cycle hit latency 300-cycle min. latency, 2B/cycle bandwidth 16-bit history gshare, 64K-entry PHT, 2048-entry 4-way set associative BTB, 10-cycle misprediction penalty. 5.1 評 価 環 境 評価には,SimpleScalar Tool Set Version 3.0a10) をベースに提案手法を実装したシミュ. 用の FIFO 発行キューを本実行用発行キューに統合し,1 つの CAM の発行キューとした.. レータを用いた.命令セットには Compaq Alpha ISA を用いた.ベンチマーク・プログ. 発行キュー及び LSQ は十分に存在すると仮定し,エントリ数を仮想 ROB エントリ数と同. ラムとして,数値計算プログラムからなる SPECfp2000 を使用した.表 1 に使用したベン. 一とした.また,この 2 つのモデルにおいては 8 エントリの FB を用いた.FB の容量を有. チマーク・プログラム及びロードの L1 データ・キャッシュ・ミス率(MPKI: misses per. 効に利用するため,エントリの置換ポリシとして non-bypass caching4) を用いた.このポ. kilo-instructions),L2 キャッシュ・ミス率,主記憶アクセス率を示す.バイナリは,Compaq. リシでは,バイパス経由で読み出されなかった結果のみを FB に置く.2 回以上参照される. C 及び Fortran コンパイラを用いて-fast -O4 のオプションでコンパイルした.入力には ref. オペランドは少ないため,読み出されることのないオペランドによる FB の容量の浪費を抑. 入力を用い,SimPoint5) によって選択した 100M 命令を実行した.評価におけるベース・. 制できる.. プロセッサの構成を表表 2 に示す.. 5.2 先行実行命令削減率. 評価では以下の 2 つモデルについて評価を行った.. 図 7 に,コミット命令数に対する先行ディスパッチ命令数の割合を示す.各棒グラフは 2. • full: M = 8 に仮想 ROB を拡大した VROB 方式において,可能な限りすべての命令. つの部分にわかれている. 「先行実行」は実際に実行された命令であり, 「削除」は先行ディス. の先行実行を行うモデル. パッチされたが,発行キュー内で削除された命令の割合を表している. 「先行実行」と「削. • low-power: M = 8 に仮想 ROB を拡大した VROB 方式において,選択的先行実行. 除」を合わせたものが,コミット命令数に対する先行ディスパッチ命令の割合となる.また. を行うモデル. 図 7 の右端の「A.M.」は,14 本の算術平均である.. full 及び low-power モデル固有のプロセッサ構成を表 3 に示す.本論文では,先行実行. 先行実行による消費電力は,先行ディスパッチされた命令数と先行実行された命令数に. 6. c 2011 Information Processing Society of Japan.
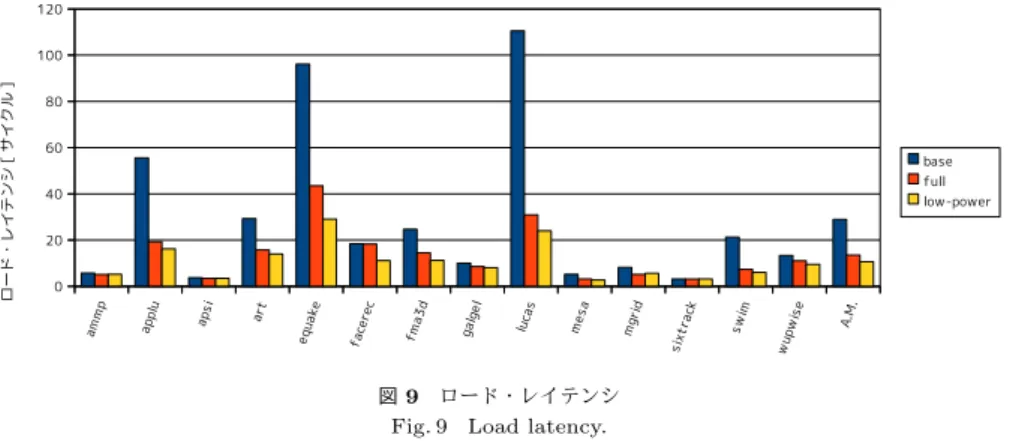
(7) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 7 コミット命令に対する先行ディスパッチ命令の割合 Fig. 7 Ratio of pre-dispatched instructions to commited instructions.. 表 3 full, low-power モデルの構成 Table 3 Configrations of full and low-power models.. common. low-power model. 1024-entry LSQ 1024-entry issue queue 8-entry forwarding buffer, non-bypass caching 1024-entry MCT 128-entry RIB Threshold of miss count to identify load is 8. Reset interval of MCT and TP,TG flags is 1M cycles. TP search penalty is 1 cycle per each RIB entry.. よって変化する.先行ディスパッチされた命令は,発行キューの消費電力を増加させる.ま. 図 8 IPC Fig. 8 IPC.. た先行実行された命令は,機能ユニットやキャッシュの消費電力を増加させる.図からわか るように,選択的先行実行を行うことで,ほとんどのプログラムにおいて,先行ディスパッ. 5.3 性 能 評 価. チ命令数,先行実行命令数を大きく削減することができている.. 図 8 に base モデル,full モデル,low-power モデルの IPC を示す.また,図 9 に,コ. コミット命令数に対する先行ディスパッチ命令数の割合は full モデルでは平均 81%であっ. ミットされたロード命令のレイテンシを示す.. たが,low-power モデルでは平均 22%と大きく削減できた.またコミット命令数に対する先 行実行命令の割合も full モデルでは平均 20%であったが,low-power モデルでは平均 5%と. low-power モデルでは,先行ディスパッチを delinquent ロード,TP 命令に限定している. 大きく削減できた.また,先行ディスパッチ命令と先行実行命令の削減率の平均は,それぞ. ため,full モデルよりもプリフェッチ機会が減少し,一般にレイテンシは若干増加すると予. れ,72%,77%である.. 想された.そのため性能も低下すると予想された.しかし,実際には low-power モデルの レイテンシは full モデルとほぼ同等か,削減されており,平均では,21%削減されている.. 7. c 2011 Information Processing Society of Japan.
(8) Vol.2011-ARC-196 No.16 2011/7/28. 情報処理学会研究報告 IPSJ SIG Technical Report. 参. 考. 文. 献. 1) Borch, E., Manne, S., Emer, J. and Tune, E.: Loose Loops Sink Chips, Proceedings of the 8th International Symposium on High-Performance Computer Architecture, pp.299–310 (2002). 2) Collins, J.D., Tullsen, D.M., Wang, H. and Shen, J.P.: Dynamic Speculative Precomputation, Proceedings of the 34th International Symposium on Microarchitecture, pp.306–317 (2001). 3) Collins, J.D., Wang, H., Tullsen, D.M., Hughes, C., Lee, Y.-F., Lavery, D. and Shen, J. P.: Speculative Precomputation: Long-range Prefetching of Delinquent Loads, Proceedings of the 28th Annual International Symposium on Computer Architecture, pp.14–25 (2001). 4) Cruz, J.-L., Gonz´ alez, A., Valero, M. and Topham, N.P.: Multiple-Banked Register File Architectures, Proceedings of the 27th Annual International Symposium on Computer Architecture, pp.316–325 (2000). 5) Hamerly, G., Perelman, E., Lau, J. and Calder, B.: SimPoint 3.0: Faster and More Flexible Program Phase Analysis, Journal of Instruction-Level Parallelism, Vol.7, pp.1–28 (2005). 6) Hyodo, K., Iwamoto, K. and Ando, H.: Energy-Efficient Pre-Execution Techniques in Two-Step Physical Register Deallocation, IEICE Transactions on Information and Systems, Vol.E92-D, No.11, pp.2186–2195 (2009). 7) Mutlu, O., Kim, H. and Patt, Y.N.: Techniques for Efficient Processing in Runahead Execution Engines, Proceedings of the 32nd Annual International Symposium on Computer Architecture, pp.370–381 (2005). 8) Mutlu, O., Stark, J., Wilkerson, C. and Patt, Y.N.: Runahead Execution: An Alternative to Very Large Instruction Windows for Out-of-order Processors, Proceedings of the 9th International Symposium on High-Performance Computer Architecture, pp.129–140 (2003). 9) Roth, A. and Sohi, G.S.: Speculative Data-Driven Multithreading, Proceedings of the 7th International Symposium on High-Performance Computer Architecture, pp. 37–48 (2001). 10) simplescalar: http://www.simplescalar.com/. 11) 市原敬吾,田中雄介,安藤秀樹:仮想化により拡大したリオーダ・バッファによる先行 実行,2011 年先進的計算基盤システムシンポジウム SACSIS 2011,pp.64–71 (2011).. 図 9 ロード・レイテンシ Fig. 9 Load latency.. この結果,性能もすべてのプログラムで同等か上回るようになり,平均で 3%向上している. 理由として次の 2 点があげられる: 1) delinquent ロードがほぼすべての L2 ミスをカバー していると思われる.2) 先行実行する命令を削減したことによって,実行における資源競 合が減少し,発行キューでの待ち合わせ時間が減少し,その結果,プリフェッチのタイミン グが改善されたと思われる.性能が full モデルとほぼ同等で,図 7 に示す通り先行実行命 令が削減できたので,本論文提案の手法は効果的であると言える.. 6. ま と め データ・プリフェッチを実現する方法に命令の先行実行がある.単一スレッド環境において 先行実行を行う手法として,我々はこれまでに仮想 ROB(VROB : virtual reorder buffer) 方式を提案した.しかし従来の VROB 方式では,先行実行が有効でない命令も先行実行し, 無駄な電力を消費していた.そこで本論文では,頻繁にキャッシュ・ミスを起こすロード命 令とそれが直接あるいは間接的に依存する命令のみを先行実行することで,有効な先行実行 のみを行う選択的先行実行方式を VROB 方式に適用し,評価を行った.SPECfp2000 ベン チマークを用いて評価を行った結果,通常の VROB プロセッサをやや上回る性能で,先行 ディスパッチ命令数を 72%削減できることを確認した. 謝辞 本研究の一部は,日本学術振興会 科学研究費補助金基盤研究 (C)(課題番号 22500045) による補助のもとで行われた.. 8. c 2011 Information Processing Society of Japan.
(9)
図



+3
関連したドキュメント
of IEEE 51st Annual Symposium on Foundations of Computer Science (FOCS 2010), pp..
Amount of Remuneration, etc. The Company does not pay to Directors who concurrently serve as Executive Officer the remuneration paid to Directors. Therefore, “Number of Persons”
「普通株式対価取得請求日における時価」は、各普通株式対価取得請求日の直前の 5
①正式の執行権限を消費者に付与することの適切性
②
Proceedings of EMEA 2005 in Kanazawa, 2015 International Symposium on Environmental Monitoring in East Asia ‑Remote Sensing and Forests‑.
Proceedings of EMEA 2005 in Kanazawa, 2016 International Symposium on Environmental Monitoring in East Asia ‑Remote Sensing and Forests‑.
かくして Appleton の言及は, 内に概念的先駆者とし ての自負を滲ませながらも, きわめてそっけない.「隠 れ場」にかかる言説で, Gibson (1979) が
