知識集約型データベース検索システムの構築
服 部 忍
Construction of knowledge intensiveness type data base exploration system
Shinobu HATTORI
Inthispaper,theknowiedgeintensivenesstypeda
t
abaseexplorationsystem ishandled.The proposeddatabaseexplorationSystemCOnStruCtSitaSaSearchsystemcorre印Ondingtothedatabase thatthecom onbackgroundknowiedgeexistsbetweenthedatabaseconstructionpersonandthe databaseretrieval per8 0
n.ThisSearch system assumestlSeSuchasTLO (technology licensing organkatioh)asthe血isonSupportSyst e
m Inthisresearch,themethodofconsolidatingthekn wledge ofthedatabaseregiBtrantanduseisexaznined,anditproposestheknowledgeintensivenes8typedata basee葺plorationmodelthatcanberetrievedeuectivelyandefficientlyinaSPeCiBcgroup.キーワー ド:キー ワー ド検索,置換え可能語,一致率,知識集約型,TLO
1
.は じ め に
データベースの情報検索において,様々な検索モ デルが用い られている.データベースの情報検索で は.必要な情報 を有する情報源 を対象 とす るデー タ ベースか ら,いかに漏れ を無 くし網羅的に検索す る か,また,無駄 な情報をいかに少な くす るかが最 も 重要な事柄 となる.このことが検索の信頼性や効率 化に大きく影響 し, 効果的な検索の実現 を左右す る,
しか しながら,現在用い られている検索モデル の ほとん どは,利用者 を十分 に満足 させているわけで はない.実用的な検索モデルである全文検索モデル とキー ワー ド検索モデルにおいても,必ず しも検索 者の意図す る検索ができるとは限 らない.検索の結 果に満足できず に,異なる検索語 ( 検索す る語句) を用いて複数回検索を実行 しても,望む結果が得 ら れないことも多い.
本研究では,デー タベース登録者の知識 を集約 し て利用す る方法について検討 し,特定集団において 有効かつ効率的に検索できる知識集約型データベー ス検索モデルを提案する.
★電子制御 工学科助教授 原稿受付
2002年5月17日2.各種検索法 とその課題
現在,代表的な情報検索システムのモデルは,全 文検索モデル とキー ワー ド検索モデル
(Booleanモ デル)である.また,最近,実用化 されたベ ク トル 空間モデル も有力な検索モデルである.
2 ‑1
全文検索モデル
全文検索モデルでは,テキス トそのものを検索対 象 としている.検索では,複数の検索語 を論理演算
千 (ANDや
ORな ど)で関係づけて入力 とし,検 索結果は検索語を含むテキス トの集合 として出力 さ れ る.テキス トは計算機 内の情報表現であるため, 検索用の特別な前処理が不要である,そのため小規 模 なシステム処理系で実現でき,維持費等において
も低 コス トで済む大 きな利点がある.
一方,この全文検索 システムの裸題 としては,検
索適合率が低いことが挙げ られ る.全文検索システ
ムでは,検索 したい語句 を文字列 として扱い,検索
キー としている.そのため意味をなさない文字列 と
も照合す る結果,無駄 な照合 が生 じる.この対策 と
しては,全文検索の結果を言語解析す る方法が採 ら
れてい る.また,検索語 と一致す る文字列がテキス
60
服 部
トに現れない と検索できないため再現率 も低いため, その対策 として, シソーラスを用いた同義語等によ って照合す る方法が行われている.さらに,全文検 索は文字列の一致のみで検索す るため主題 と関係 の 無い部分 も検索 されて しま う場合 が多い とい う欠点 も有す る.それぞれの課題 に対す る改善策 も検討 さ れ実施 されているが,そのために,全文検索の利点 である小規模なシステム処理系での実現や維持費等 の低 コス トが損なわれている事は否定できない.
2‑2
キー ワー ド検索モデル
キー ワー ド検索モデルは,テキス ト内容 を代表す るキー ワー ドをキー として検索を行 うモデルで,情 報検索 システムで従来か ら多 く用 い られている.検 索語 を入力す る方法は全文検索 と同じであるが,検 索結果 はキー ワー ドが付与 されたテキス トの集合で ある.キー ワー ド検索モデルは,キー ワー ドごとに そのキー ワー ドが出現 したテキス トを記録す る転置 ファイル を作る方式を用いているため,高速検索が 可能である,また,キー ワー ド設定時にテ キス ト内 容 に適 したキー ワー ドを人手あるいは自動的に言語 解析やテーマ解析 で設定できるため,高い検索精度 が得 られ る.
しか しキー ワー ドを付与す るために,人手の場合 は膨大な労力が必要であ り,キー ワー ド自動抽出シ ステムを利用 した 自動化の場合はシステムに言語解 析系 を組み込む必要がある.高精度な言語解析系 シ ステムの構築には多 くの困難が伴 っている.いずれ に して もメンテナ ンスや運用維持費で高 コス トにな
りやすい欠点がある.
また,キー ワー ド検索モデル を改良 した ものに, 検索語 に重要度 を付加する拡張キー ワー ド検索モデ ル がある.このモデルは,検索の一致度や重要度 な どの付加価値 を加 えたもので,システムの利便性 を 大幅に向上 させ ることができる.
2 ‑3 ベク トル空間モデル
ベ ク トル空間モデルは,テキス トを単語や概念 の ベ ク トル として表現す るもので,設定された単語 ( キ ー ワー ド)等に重要度等の情報を割 り当てて,よ り 高い精度の検索 を実現 しようとす る検索 システムで ある.検索語の入力は 自然言語入力でベ ク トルに変 換 され ,検索結果 は登録テキス トの入力検索語に対 す る● 一致度 ( 類似度) 順の リス トとして出力 される.
このモデルでは,キー ワー ドの重要度を どのよ うに 設定す るかがポイ ン トになる.代表的な設定法は, あるテキス トにお けるキー ワー ドの重要度 を,その
忍
キー ワー ドがテキス ト中に出現す る頻度 と全テキス トにおける頻度の逆数 とす る方法である.
このモデルの問題点は,精度や効率の面を考慮 し てベ ク トル表現に用いる基底単語 ( 概念)の次元や 単語等を最適に選択す ることの難 しさにある.また, テキス トごとに単語の重要度 を保持 しなけれ ばな ら ないため,索引ファイルが大きくなる欠点がある.
3.本データベース検索 システム の基本構造
本研究で提案す るデー タベース検索システムは, デー タベース構築者 とデータベース利用者 との間に 共通の背景知識が存在す るよ うなデータベースに対 応する検索システム として構築す る.本検索 システ ムは
TLO( 技術移転機 関)等における リエ ゾン支 援 システムとしての利用 を想定 している.
3 ‑1
基本 コンセ プ ト
本 システムは,次の基本 コンセプ トに基づ き構築 されている.
①高い検索精度 を有す ること. .
②利便性 の高いシステムであること.
③システム構築や維持 のコス トが低いこと.
④利用が簡単であること.
⑤システムの更新等が 自動化できること.
これ らの基本 コンセプ トに基づいて本検索 システ ムのア ウ トライ ンを策定す る.
前節 の検索モデルの特徴 を考慮 して, これ らの基 本 コンセプ トを満足す るシステムを構築 していく.
まず①お よび② より, 本システムの基本構造 として, 一致度のよ うな付加情報 を持つ拡張キー ワー ド検索 モデル を基本 として採用す る.そ してそれぞれの登 録情報 ごとにモジュール構造 として構築する,
また,通常ではデー タベースの作成には莫大な時 間 と労力を必要 とす るが,本システムでは,デー タ ベース作成 に,ほとん ど労力は必要 とな らない.そ れ は本 システムでは,デー タベースにおける情報の 蓄積は基本的には情報登録者が行 う.そ して情報登 録者が行 う作業 も,情報の提供 とそれに付与するキ ー ワー ドお よびキー ワー ドの置換可能語の登録だけ とする.このよ うにす ることで,システム構築や維 持 のコス トを低 く抑えることができる.また,デー タベース管理者 に専門的知識 を特に必要 としないシ ステム とす ることができる,こ うしてコンセプ ト③ お よび( 参は満足 され る.
情報登録者 の拡大や,情報量の増加や更新があっ
キーワー ド用データベース メイ ン用デー タベース
+ +
… ‑日 用
書目
壬 妻I7 l ・̲テキス ト③ テキス ト(
E,Gキーワード キーワード
A,B,C,H 》
,.
Ⅰ D,E,FB,どテキス ト( テ キス ト④ キーワード キーワード ,H, 9
S
一致率算 出部
一致率算出部
て も,モジュール構造であるため追加や変更などの 更新が容易である.また, 自動更新システム として 構成 し,コンセプ ト⑤の要求を満たす設計 とする.
3 ・2
基本構造
本デー タベー ス検索 システムの基本構造 を図
1に示す・ 本システムの基本構造は,主要部分 として, メイン用デー タベース と,キー ワー ド用デー タベー ス と,キー ワー ド用データベースを基に一致率を算 出す る一致率算出部 と,の
3つを有 して構成 され て いる.
メイ ン用データベースは,図
1に示す よ うに,情 報登録者が登録 した情報 とそれ に付与 された複数の キー ワー ドとか らなるモジュール構造である. ・情報 登録者 は,情報本体 と,その内容 を的確 に表す数個 のキー ワー ドと,そのキー ワー ドごとに対応 させた 置換可能語があれば併せてキー ワー ドとともに登録 する.このよ うに,登録情報は,情報 内容 ごとのモ ジュール構造 となってメイン用データベースに蓄積 され る.
キー ワー ド用データベースは,情報登録者が登録 した情熱 こ付与 されたキー ワー ドとそのキー ワー ド と置換可能語 を抽出 して,配置変更 して再構成 した 後,デー タベースが作成 され る.キー ワー ド用デー タベースの構造を図
2に示す.図
2に示す よ うに, キー ワー ド用デー タベースは,行列形式の構造を持 っている.まず,メイン用データベースに格納 され
た内容の うち,キー ワー ドと,それに付与 された置 換可能語 を抽 出す る.そ して抽 出 した語 をソー トし て,行 と列に配列す る.次に行 をキー ワー ド,列 を そのキー ワー ドに対応する置換可能語 とみな し,キ ー ワー ドに付与 された置換可能語の個数 をカ ウン ト す る.多数の情報登録があるため,当然 キー ワー ド が重複す る場合が生 じるが,その場合は重複 した頻 度 をキー ワー ドの情報 として記録 してお く.行 のキ ー ワー ドと,列の置換可能語 とのマ トリックスの交 点の借は置換可能 として登録 された数 ( 以後,置換 頻度数 とい う) となっている.
一致率算 出部は,情報検索者が検索語 として入力 したキー ワー ドに対 し,デー タベースに登録 された 情報に付与 されたキー ワー ドとめ一致の度合いを算 出す るもので,情報登録者がキー ワー ドに対す る置 換可能語 として登録 した語句 も考慮 して算 出す る.
算 出された一致率は,キー ワー ド用デー タベース上 に併せて登録 され る.そのため,利用者 が検索 を行 った場合には,即座 に対応す るキーワー ド同士の一 致率 を取 り出す ことができ, トー タルの検索一致率 の算出に利用 され る.
4.
一 致 率 の 算 出 方 法
デー タベースの登録状態が表
1に示す よ うになっ
てい る場合 の,一致率算出方法について述べ る.な
お,一致率の計算では,キー ワー ドと置換可能語 と
62
服 部
忍表
1キーワー ド用データベースのマ トリックス配列
置換可能語
キーワード重複数 A
B C D E ど G Hi
J K」 ■ ●
A
4 2 1 3 1 1 1 2 1B 2 1 1 1 2 1
C 1 1 1 1
D 2 1 2 1 1
E 1 1 1 1
ど 1 1 1 1 1
G 2 1 1. 1 1 1
H 1 1 1 1
Ⅰ
1 1 1 1● ■
■ ■
揺,相互参照 の関係 にあるもの として取 り扱 う.
4 ・1 一致率の考え方
キー ワー ド
Aとキー ワー ド
Bとの一致度は,次の よ うに算出される.
表 1において,Aの行 とBの列 との交点の値 を見 ると置換頻度数は
2, このときのキー ワー ド
Aの重 複度 は4である.また.置換可能語 としてAを見 る と,キー ワー ドBとの交点の置換頻度敦は 1であ り, その ときの重複度は 2 . である.キー ワー ドAとキー
ワー ド
Bとの相互の一致率を
α (A :B)で表す と,
α (A :B)
‑0. 5(2/4+ 1/2)‑ 0. 5として計算 され,キー ワー ド
Aとキー ワー ド
Bとの 一致率は
50%である.
また
, α (A :C)は同様 に,
α (A :C)‑0. 5 (ユ/4+0/1)‑0.125
と計算 され,一致率は
12. 5%である,一致率算 出部は,この ような計算のもと,すべての場合 の一 致率 を算出す る.
例 えば,検索語 としてAを入力 した場合に, キー ワー ドとして
,Aが無 く
Bと
Cが付与 されてい る情 報に対 して札 一致率はそれぞれの一致率の和
, 62・ 5%
とな り,この情報を一致率
62. 5%の情 報 として検索 されるこ とになる.
4 ‑2 一致率の一般的算出方法
キー ワー ド用データベースが表
1のよ うに表 され ている場合,キー ワー ドiとキー ワー ド
jとの置換 頻度数 を,行列
M(
i,j)と表す.また,キー ワ ー ドiの重複度 を,ベ ク トル
m( i )と表す と,
‑致率
(i:j)は,
α
(i:j,‑喜〔警 十% )‑
(1,と,表 され る.
4 ‑3
‑故事表の作成
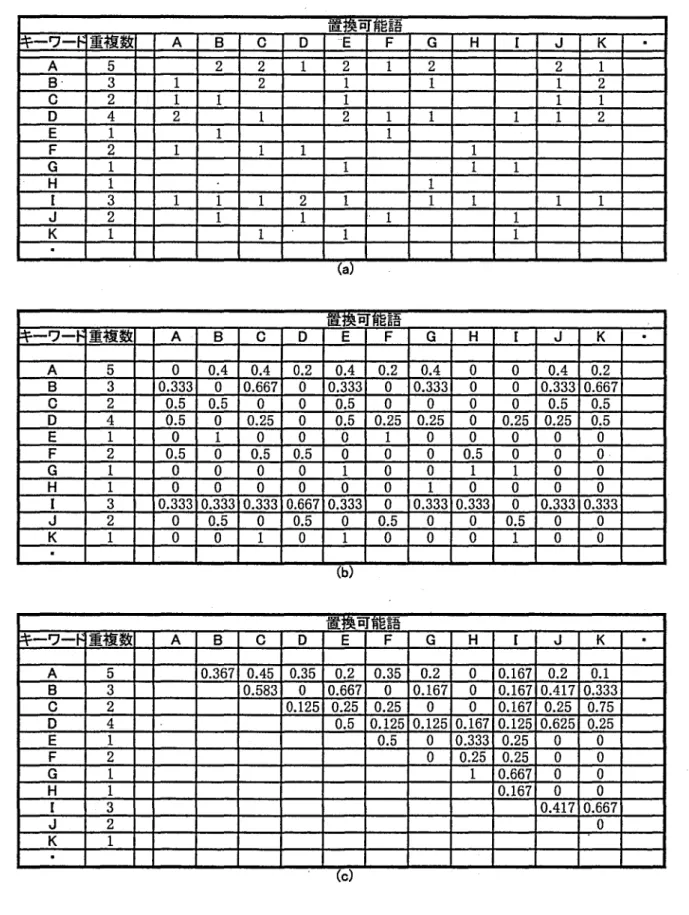
キー ワー ドの一致率の計算例 として,キー ワー ド 用デー タベースの頻度表が表
2の
(a)の場合 につい て,以下のよ うに計算 され る.
キー ワー ドに対する置換可能 と判断す る頻度の割 合 を,すべてのキー ワー ドについて計算する と,表 2の( b) のよ うに計算 され る. 本システムではキー ワ ー ドと置換可能語は相互参照の関係にあるとして, 一致率の計算 においては区別 していない.そ こで, 式 (1)に従 って,一致率を計算する と,表
2の
(C)のようにキー ワー ド間の一敦率表が作成 され る.
4 ‑4
検索一致率の算出
次に, 模索時の検索一致率の算 出について述べ る.
ここでは,検索語が複数の
p個ある場合めキー ワー
ドの一致率を求める.
表
2キーワー ド相互間の一致率計算表
置換可 能言 吾
‑ ワ‑
'重複 数 A B C D ■E FG
HI J K
A 5 2 2 1 2 1 2 2 1
ら. 3 1 2 1 1 1 2
C 2 1 1 1 1 1
D 4 2 1 2 1 1 1 1 2
E 1 1 1
F 2 1 1 1 1
G
1 1 1 1H 1 1
I 3 1 1 1 2 1 1 1 1 1
J
2 1 1 1 1K
1 1 1 11
置換 可能 語
A 5 0 0.4 0.4 0.2 0.4 0.2 0.4 0 0 0.4 0.2 B 3 0.333 0 0.667 0 0.333 0 0.333 0 0 0.3330.667
C 2 0.5 0.5 0 0 0.5
0
00
0 0.5 0.5D
4 0.5 0 0.25 0 0.5 0.25 0.25 0 0.25 0.25 0.5E 1 0 1 0 0 0 1
0
0 000
F 2 0.5 0 0.5 0.5
00
0 0.50
0 0.G
10
00
0 100
1 1 00
H 1 0 0 0 0 0
0
1 0 0 00
I 3 0.3330.3330.3330.6670.333 0 0.3330.333 0 0.3330.333 J 2 0 0.5 0 0.5 0 0.5 0 0 0.5 0
0
K 1 0
0
10
1 00
0 100
(b)
置換 可能 語
‑ ワ‑
重複 数 A a C D E ドG
H I JK
A 5 0.367 0.45 0.35 0.2 0.35 0.2 0 0.167 0.2 0.1 B 3 0.583 0 0.667 0 0.167 0 0.1670.4170.333C 2 0.125 0.25 0.25
0
0 0.167 0.25 0.75D 4 0.5 0.1250.1250.1670.1250.625 0.25 E 1 0.5 0 0.333 0.25 0 0
F 2 0 0.25 0.25 0 0
G
1 1 0.667 0 0H 1 0.167
0
0[ 3 0.4170.667
J 2 0
K
1(G)
64
服 部 まず
, p個の検索語が,キー ワー ド用データベー ス上の何番 目のキー ワー ドにあたるのかが調べ られ, 対応ベ ク ト
ル qが作成 され る.
例 えば, 3 個の検索語で検索す る場合,それぞれ の検索語が,キー ワー ド用データベース上で,何番
日のキー ワー ドに相当するのかが調べ られ る.
ここでは,次のよ うに表 された とす る.
1
番 目の検索語は, 5 番 目のキー ワー ド
.2番 目の検索語は
, 13番 目のキー ワー ド
3
番 目の検索度は
, 16番 目のキー ワー ド 対応ベ ク トル を q ( i )で表す と,
(1)
となる.
メイ ン用データベースの各情報に付与 されたキー ワー ドとそれぞれ の検索語 との一致率が抽出される.
この例の場合は,各情報に付与 されたキー ワー ドと
3つの検索語 との間の一致率が抽出され,すべての 検索度 について合算 される.
p
個の検索語を使った検索では, 検索一致率
Eは, 次のよ うに求められ る.
E(q(L)持
主 よ こ l
皇 αJ
=1〈q(i),j)・I
'2'となる.
ただ し
,nはキーワー ド用データベースでのキー ワー ドの総数, αはキーワー ドの一致率である.
5.本 システムの動作説明
本 システムの動作例 を,デー タベースの作成 から 順 を追って説明す ると,次のよ うになる.
5・1
データベースの作成
デー タベースの作成 では.情報登録者が情報内容 と,内容 を的確 に表す数個のキー ワー ド,およびキ ー ワー ドごとの置換可能語 を一括 して,メイン用デ ー タベースに登録す る.す るとシステムは,図
2(a)に示す ように,キー ワー ド用デー タベースを生成 し, 登録情報がある場合は 自動的に更新 される.
例 えば,情報登録者①が情報① を登録す ると,そ の情報①に付与 されているキー ワー ド
,A,B,C,忍
お よび,キー ワー ドAの置換可能語,D,E, F, キー ワー ド
Bの置換可能語
G,H,キー ワー ド
Cの 置換可能語 Ⅰ
,J,Kが抽 出され,ソー トの後,キー ワー ド用データベースに配列 される.
次に,情報登録者②が情報② を登録す ると,その 情報② に付与 され てい るキー ワー ド
,F,Ⅰ,およ び,キー ワー ドFの置換可能語,A,K,M,キー ワー ドⅠの置換可能語
N,0,が抽出され, ソー ト の後,キー ワー ド用データベースに配列 される.
同様 に,情報登録者 が登録作業を行 う毎に, 自動 的に上述の作業が行われ る.そ して,メイン用デー タベースに情報が蓄積 され ると同時に,キーワー ド 用デー タベースの更新が自動的に行われ る.
5.2
一致率の算出
キー ワー ド用データベル が作成 され,奉るいは更 新 された時に臥 キー ワー ド等の相互間の一致率が 計算,あるいは再計算 され る.それ らの計算は図
2(b)
に示す よ うに,キー ワー ド用のデータベース上に 併せて記録 され, 利用者 が検索 をした際に利用 され, 時間の短縮に役立っている.
6.
お わ り に
本データベース検索 システムは,情報登録者がキ ー ワー ド付与や置換可能語 を登録する際,この情報 登録者の知識 を集約す る形で利用す る.個々の情報 登録者 にとっては別段 ,検索に関す る知識 を提供 し ている認識はほとん ど無い と思われ るが,キー ワー
ドとその置換可能語に対す る認識等が情報登録者全 体で集約 され ると,強力な検索ツール となる.これ を利用す ることで,検索精度の向上や,システムの 小規模化や,システム管理者 の負担が軽減 されるな ど大きな効果 を有 している.それ故,本 システムは 知識集約型データベース検索システム と称 している.
本検索システムは
,TLO用の リエ ゾン支援 シス テム‑の適用に適 していると考えられ,この方面で 広 く活用 され ることを期待す る.
参 考 文 献
1)