数値計算ライブラリを対象とした ソフトウェア自動チューニングにおける
性能パラメタ推定法に関する研究
田 中 輝 雄
電気通信大学 大学院情報システム学研究科 博士 ( 工学 ) の学位申請論文
2007 年 3 月
数値計算ライブラリを対象とした ソフトウェア自動チューニングにおける
性能パラメタ推定法に関する研究
博士論文審査委員会
主査 弓 場 敏 嗣 教授
委員 伊 藤 秀 一 教授
委員 曽 和 将 容 教授
委員 吉 永 努 助教授
委員 本 多 弘 樹 助教授
著作権所有者
田 中 輝 雄
2007 年
An Incremental Performance Parameter Estimation Method Applied to Software Automated Performance Tuning
for Numerical Libraries Teruo Tanaka
Abstract
Software automated performance tuning is an optimization of performance parame- ters suitable for a certain computational environment in ordinary numerical libraries.
One of the important issues for the automated performance tuning is reduction of ex- ecution time required for tuning of performance parameters. In consideration of the issue, this dissertation proposes a new method to estimate optimal performance pa- rameters by incrementing suitable sampling points referring to computational results of a cost definition function. The new method is named Incremental Performance Parameter Estimation method. The method is effectuated by a newly defined cost definition function d-Spline, which has high flexibility to adapt given data and can be easily calculated. The characteristics of the Incremental Performance Parameter Estimation method are:
1) estimates the optimal performance parameters using dynamically incremented sampling points,
2) achieves high accuracy with a relatively small estimation time, otherwise, find the parameter values near optimal performance,
3) makes an efficient combination withd-Spline as well as the complexity of solving d-Spline can be neglected,
4) does not require the user’s knowledge and is applicable to every mathematical library.
There are two phases to execute automated performance tuning: (a) at install-time and (b) at run-time. For evaluation, the new method is applied to eigenvalue analysis programs at install-time. The results of the evaluation showed that the method achieves to reduce execution time by 49.0% at the best and by 19.0% in average compared with conventional methods. The new method is also evaluated by sparse matrix-vector multiplication at run-time. The results of the evaluation showed that the execution time required for the optimization can be neglected.
数値計算ライブラリを対象とした ソフトウェア自動チューニングにおける
性能パラメタ推定法に関する研究 田 中 輝 雄
要 旨
大規模行列計算等で利用されている数値計算ライブラリを,使用する計算機環境および ユーザが解きたい問題に対して,実行性能が最大になるように自動的に最適化する「ソフ トウェア自動チューニング」の研究が進められている.ソフトウェア自動チューニングで は,数値計算ライブラリのループ構造のアンローリング段数などの性能チューニング項目 をパラメタ化する.この性能パラメタのとり得る値から複数の値を標本点として選択し,
標本点ごとに数値計算ライブラリの実行時間を測定する.標本点ごとの実行時間(=コス ト)をコスト定義関数であらわす.このコスト定義関数を用いて,数値計算ライブラリの 実行時間を最小にする性能パラメタの最適値を推定する.この数値計算ライブラリの最適 化は,複数の性能パラメタに対して,かつ,多くの問題規模(行列サイズ)に対して,実行 する必要があり,性能パラメタ推定の時間短縮が大きな課題となっている.
本論文では,コスト定義関数による推定に必要とする最低限の数の標本点から始めて,
新たに標本点を選択し追加しながらコスト定義関数を順次更新し,最適な性能パラメタの 値を推定する「標本点逐次追加型性能パラメタ推定法」を提案する.この新しい性能パラ メタ推定法では,標本点を追加するか否かの終了判定条件に,何回連続して同じ性能パラ メタ値を選択したかという同一判定連続回数を用いる.また,コスト定義関数として,標 本値を追加したときの実測データ間の形状の変化に柔軟に追随し,かつ計算量の少ない d-Splineを適用する.
標本点逐次追加型性能パラメタ推定法は,次のような特徴を持つ.
a) 事前に与えられた固定数の標本点をもとに推定を行なう従来の方式に対して,必要 に応じて使用する標本点の数を調整する柔軟性を実現した.
b) 高い正答率(最適な性能パラメタ値を選択する割合)を実現した.もし正しい最 適値を選択できなかった場合も,最適値に近い実行時間の性能パラメタ値を選択 する.
c) コスト定義関数d-Splineは,提案する性能パラメタ推定法との整合性が良く,数 値計算ライブラリ自体の実行時間に比べて,無視できるほど少ない演算量で実行で きる.
d) ユーザからの事前情報は一切使用しないので,ユーザが解きたいどのような問題に も対応することが可能である.また,対象とする数値計算ライブラリに対しても制 限はない.
これらの特徴から,提案した性能パラメタ推定法はソフトウェア自動チューニングにお いて実用性の高い方式といえる.
ソフトウェア自動チューニングによる最適化のフェーズとして,次の2つがある.
a) インストール時ソフトウェア自動チューニング:数値計算ライブラリを計算機にイ ンストールする時
b) 実行時ソフトウェア自動チューニング:問題を解くために,数値計算ライブラリを 用いてアプリケーションプログラムを実行する時
提案手法の有効性を検証するために,それぞれのフェーズに対して,実証実験を行 なった.
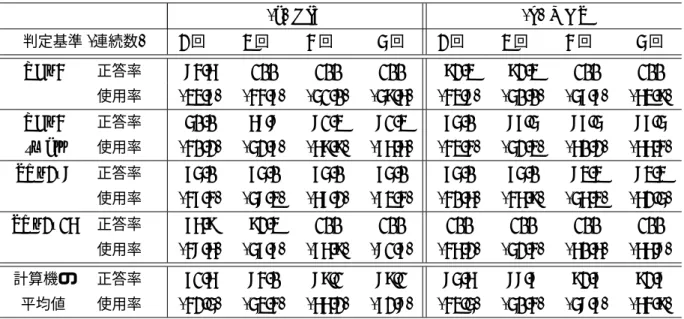
インストール時ソフトウェア自動チューニングでは,ユーザプログラムが対象とする行 列サイズが特定できないため,多くの行列サイズに対して数値計算ライブラリを実行さ せる必要がある.ここでは,密行列演算の固有値計算ライブラリを用いた.4種の計算機 環境ならびに4種のベンチマークに対して,それぞれ16種の行列サイズで実験を行なっ た.その結果,全体での平均では,終了判定基準を4回連続同一性能パラメタ値の選択と した場合,性能パラメタのとり得る値全数に対する使用した標本点の割合である利用率
68.3%で,正答率87.3%を実現した.ランダムに標本点を選択した場合は,同じ正答率 を得るためには確率的に利用率が87.3%となるので,利用率に関し19.0ポイントの効果 があったと言える.同様に,最大では51.0%の利用率で100%の正答率を得ており,49.0 ポイントの効果を実現した.
実行時ソフトウェア自動チューニングでは,実行時間にほとんど影響を与えないよう に,性能パラメタ推定時間を抑える必要がある.ここでは,疎行列の行列積を取り上げ た.疎行列の非零要素の位置は実行時にしか決まらないため,自動チューニングは実行時 にしか行なうことができない.今回の実験では,疎行列の行列積の計算時間の1%以下で 性能パラメタ推定処理を実行することができ,自動チューニングに要する時間を無視でき ることを示した.このとき,インストール時の場合と同様に,ランダムに標本点を選択し た場合に比べて,同じ標本点の利用率で正答率を平均で55.0%から75.9%に20.9ポイン トの向上を実現した.
今後は,ソフトウェア自動チューニングのフレームワークの中に,提案した性能パラメ タ推定法を組み込み実用化をはかる.それとともに,事前に全数取得することが難しい行 列サイズ間の性能パラメタ最適値の補間,複数性能パラメタの同時推定など,提案した性 能パラメタ推定法の改善,適用拡大に取り組んでいく.
目次
1 緒 言 1
1.1 本研究の背景と目的 . . . 1
1.2 コンパイラとの関係 . . . 7
1.3 本論文の構成 . . . 8
2 ソフトウェア自動チューニングにおける性能パラメタ推定の位置付け 10 2.1 ソフトウェア自動チューニングを実行するタイミング . . . 10
2.2 ソフトウェア自動チューニングの研究課題 . . . 12
2.3 性能パラメタ推定の関連研究 . . . 13
2.4 本章のまとめ . . . 16
3 標本点逐次追加型性能パラメタ推定法の提案 18 3.1 新しい性能パラメタ推定法の検討方針. . . 18
3.2 コスト定義関数d-Spline . . . 20
3.2.1 コスト定義関数d-Splineの導入 . . . 20
3.2.2 コスト定義関数d-Splineの計算手順 . . . 22
3.2.3 コスト定義関数d-Splineの計算量 . . . 25
3.3 標本点選択基準と終了判定基準 . . . 26
3.3.1 標本点選択基準 . . . 26
3.3.2 終了判定基準 . . . 27
3.4 実行手順 . . . 29
3.5 適用事例 . . . 30
3.5.1 コスト定義関数d-Splineを用いた近似例 . . . 30
3.5.2 標本点追加型性能パラメタ推定法の適用例 . . . 31
3.6 本章のまとめ . . . 35
4 インストール時ソフトウェア自動チューニングへの
標本点逐次追加型性能パラメタ推定法の適用 37
4.1 インストール時ソフトウェア自動チューニングの特徴 . . . 37
4.2 実験計算機環境と自動チューニングの対象 . . . 40
4.2.1 実験計算機環境 . . . 40
4.2.2 自動チューニングの対象 . . . 40
4.3 実験結果と分析 . . . 42
4.3.1 実験結果 . . . 42
4.3.2 分析1:正答率と利用率 . . . 44
4.3.3 分析2:行列サイズによる特性 . . . 46
4.3.4 分析3:最適値を選択できなかったときの選択値の有効性 . . . 47
4.3.5 分析4:他コスト定義関数との比較 . . . 48
4.4 本章のまとめ . . . 52
5 実行時ソフトウェア自動チューニングへの 標本点逐次追加型性能パラメタ推定法の適用 54 5.1 実行時ソフトウェア自動チューニングの特徴 . . . 54
5.2 実験計算機環境と自動チューニングの対象 . . . 58
5.2.1 疎行列の行列ベクトル積 . . . 58
5.2.2 疎行列のブロック化 . . . 59
5.2.3 実験計算機環境 . . . 61
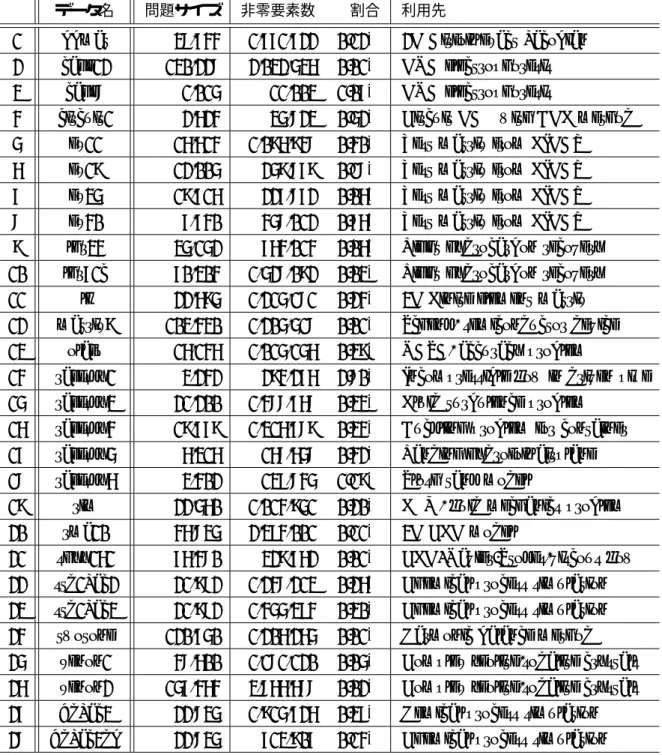
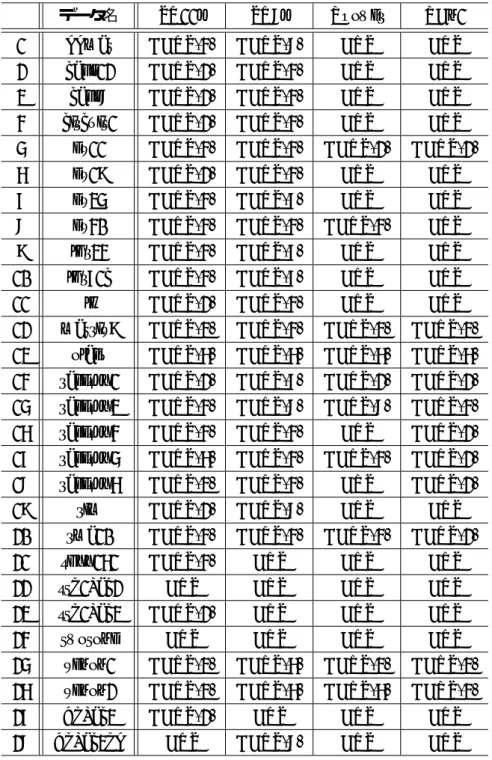
5.2.4 疎行列データ . . . 63
5.3 実験結果と分析 . . . 67
5.3.1 分析1:正答率と利用率 . . . 67
5.3.2 分析2:SR11000での実験結果と分析 . . . 69
5.3.3 分析3:標本点逐次追加型性能パラメタ推定方式の評価尺度 . . . 72
5.3.4 分析4:性能パラメタ推定に要する時間 . . . 75
5.4 本章のまとめ . . . 75
6 今後の課題 77 6.1 今後の課題 . . . 77 6.2 ユーザ知識の活用 . . . 78
7 結 言 81
謝辞 86
参考文献 88
Appendix A 詳細実験結果 98
Appendix B 著者研究業績 111
図目次
1 ソフトウェア自動チューニングにおけるユーザプログラム,計算機環境と
数値計算ライブラリの関係 . . . 3
2 数値計算ライブラリを用いたユーザプログラムの実行手順とソフトウェア 自動チューニングの実行タイミング . . . 11
3 性能パラメタ最適値導出手法による関連研究の分類 . . . 15
4 近似関数f と実測データの集合yの関係 . . . 20
5 行列E,Dの形状 . . . 21
6 QR分解時の行列Z, bの構造 . . . 22
7 標本点追加時の行列Rの構造 . . . 25
8 標本点逐次追加型性能パラメタ推定法の実行手順 . . . 28
9 コスト定義関数d-Splineを用いた近似例 . . . 30
10 標本点逐次追加型性能パラメタ推定法の適用例 . . . 33
11 インストール時ソフトウェア自動チューニング . . . 38
12 標本点逐次追加型性能パラメタ推定法の実行手順(インストール時) . . . . 39
13 実験計算機環境と自動チューニングの対象(インストール時) . . . 41
14 数値計算ライブラリごとの実験結果(インストール時) . . . 45
15 計算機環境ごとの実験結果(インストール時) . . . 47
16 選択を誤ったときの最適値に対する実行時間増加の割合 . . . 48
17 他コスト定義関数との比較 . . . 49
18 他コスト定義関数との比較 - 平均 - . . . 50
19 実行時ソフトウェア自動チューニング . . . 55
20 標本点逐次追加型性能パラメタ推定法の実行手順(実行時) . . . 56
21 CRS形式の構造 . . . 59
22 BCRS形式の構造 . . . 60
23 実験計算機環境と自動チューニングの対象(実行時) . . . 62
24 疎行列データの非零データ位置パタン(例) . . . 65
25 ブロック化時の非零データ率(例) . . . 66
26 計算機環境ごとの実験結果(実行時) . . . 68
27 標本点逐次追加型性能パラメタ推定法による標本点選択・追加のふるまい 72 28 評価尺度に対する計算機環境ごとのふるまい . . . 74
29 疎行列データの非零データ位置パタン . . . 99
30 ブロック化時の非零データ率 . . . 101
31 実験結果 SR11k . . . 103
32 実験結果 SR8k . . . 105
33 実験結果 Ppower . . . 107
34 実験結果 PCn1 . . . 109
表目次
1 最適化の観点とそれに対応する性能パラメタ群(例) . . . 5
2 実験結果 インストール時自動チューニング . . . 43
3 実験結果 インストール時自動チューニング -数値計算ライブラリの平均値- 44 4 3次スプライン補間との比較(選択を誤ったときの最適値に対する実行時 間増加の割合) . . . 51
5 実験に用いた疎行列データ一覧 . . . 64
6 すべての性能パラメタがとり得る値を用いたときの実験結果. . . 70
7 ブロック化の効果(CRS=1としたときの倍率) . . . 71
8 ブロック化の効果(CRS=1としたときの倍率) - 母数としてCRSが最 適であったケースを除く - . . . 71
9 d-Splineの生成時間 . . . 75
1 緒 言
1.1 本研究の背景と目的
気象,量子力学などの自然現象の解明,大規模LSI,新薬などの製品開発において,大 規模数値シミュレーションはなくてはならない存在である[52][63].航空機を開発する ための風洞実験を数値シミュレーションで実現する数値風洞(NWT,Numerical Wind Tunnel)[101],量子の世界を計算機上で再現するCP-PACS[96],地球規模の気象計算を行 なう地球シミュレータ[95]等,数多くのいわゆるスーパコンピュータが開発されている.
そして,それらの計算機上で,さまざまな大規模かつ複雑なモデルの数値シミュレーショ ンが実行されている.また,プロセッサの高速化により,PCサーバでもかなりの大規模 数値シミュレーションの実行が可能となり,さらに,PCサーバのクラスタ化やGRIDコ ンピューティング技術の実用化により,巨大な計算パワーが身近に手に入るようになって きている[14].
これまでは,数値シミュレーションを実行する技術者,研究者 (以下,ユーザと呼ぶ) は,数値シミュレーションの利用に関してもスペシャリストであった.しかしながら,数 値シミュレーションがより大規模かつ複雑なモデルを扱うようになり,それに伴う数値シ ミュレーション技術も高度に進化してきた.また,多くのユーザが膨大な計算機パワーを 手にできるようになってきたことにより,数値シミュレーションに精通していないユーザ の利用も広がりだしてきた.数値シミュレーションを実行するユーザは,それぞれ自ら の問題をモデル化(方程式化)し解くことが目的であり,それを効率よく解く数値シミュ レーション手法についての知識は直接的には必要ない.そのため,数値シミュレーション の実行環境を提供する側が,数値シミュレーションを,より高度に,かつ,より使いやす くする必要がある.
一方,さまざまな分野の数値シミュレーションを効率よく行なうために,多くの数値計算 アルゴリズムが開発されている.筆者等はベクトル型スーパコンピュータあるいは高並列 計算機向けに数値計算アルゴリズムを開発してきた[48][84][85][86][87][88][89][90][103].
これらの数値計算アルゴリズムの研究開発は,アーキテクチャやハードウェア方式を意識 しながらもより広く利用できることを目指してきた.
一般に,開発された数値計算アルゴリズムは,数値計算ライブラリの形式でユーザに 提供されることが多い[51].この数値計算ライブラリはある意味で 汎用的 に開発され ており,多くの計算機で それなりに 高速に動作するように設計されている.数値計算 ライブラリの開発者は,特定の計算機向けの最適化までは立ち入ることはしていなかっ た*1.また,その計算機に特化した数値計算ライブラリであっても,それはその計算機の ある標準構成に対する最適化である.その計算機が構成しうるすべてのパタン(CPU数,
CPU性能,メモリ,キャッシュ容量などの組合せ)をカバーしていることを保障している わけではなく,さらに,あらゆるユーザの解きたいモデル(方程式)に対して,その数値計 算ライブラリが最適に設定されているわけではない.
ユーザの視点で考えれば,数値計算ライブラリは 汎用的 である必要はなく,ユーザ が解きたいモデル(方程式)が速く,確実に,安定して実行されればよいだけである.そ のために, 汎用的 な数値計算ライブラリを,ユーザの使用する計算機環境において,
ユーザの解くべきモデル(方程式)に自動的に最適化する,いわゆる ソフトウェア自動 チューニング の研究開発が進められている[7][10][32][55].
ソフトウェア自動チューニングは,実用化に向けてワーキンググループあるいはプロ ジェクトとして,各大学,研究機関で研究開発が進められている.代表的なプロジェクトと して,California大のPHiPAC[5][67],BeBOP[4],Sparsity[24][75],OSKI[65][99],Illinois 大のAutopilot[71][72],Maryland大のActive Harmony[15][80],MITのFFTW[13], Tennessee大のATLAS[2][100],SANS[74],SALSA[73],東大のI-LIB[22][31],電通大 のFIBER[11][33][35]などがある.
ソフトウェア自動チューニングの目的は,ユーザプログラムの実行時間を短縮すること にある*2.そのために,汎用に作られた数値計算ライブラリをユーザが使用する計算機環
*1計算機ベンダやソフトウェアベンダでも,特定の計算機向けにターゲットを絞りながらも,できるかぎり 汎用性を持たせた数値計算ライブラリを開発している.
*2ソフトウェア自動チューニングは,性能だけでなく,メモリ容量の削減,ユーザの求める精度の保証な ど,最適化の目的としていろいろな視点が考えられる[38].しかしながら,本論文では,まず性能向上と
!#"$%#&('*)&+
/
132 &(4356 $%#,56
789#&*:<; 789&*:<;
78
=3>
/
#0?@
A#BDC3EF3GHJI
KMLNPORQ
S#TU
HWV3X
図1 ソフトウェア自動チューニングにおけるユーザプログラム,計算機環境と 数値計算ライブラリの関係
境で実行するユーザプログラムに合わせ,数値計算ライブラリの中に準備されている複数 の性能パラメタ群を自動的に最適化する.数値計算ライブラリを対象とするソフトウェア 自動チューニングにおけるユーザプログラムと計算機環境との関係を図1に示す*3.ここ で,計算機環境とは,ユーザプログラムを実行する計算機のハードウェア構成とその上 で実行されるコンパイラ等のソフトウェア群全体を示す*4.計算機としては,スーパコン ピュータ,高並列計算機,ベクトル計算機,PCサーバ,クラスタなどのさまざまなアー キテクチャおよびハードウェア構成[16][18][19][54][69]があり,また,近年では,既存の 計算機資源を有効利用するために生じる非均質なクラスタ環境や,GRIDコンピューティ ング環境も実用化されつつある[14].
いう視点に特化し,ユーザプログラムの実行時間を短縮することを目的に議論を進める.それ以外の目的 については,今後の課題で言及する.
*3ソフトウェア自動チューニングを効率よく行なうためには,性能チューニングに関するユーザ情報を用い ることが有効である.しかしながら,本論文では,提案する性能パラメタ推定法の汎用性を示すために,
ユーザ情報は一切用いないこととする.
*4場合によっては,マルチユーザ環境などの運用形態も考慮する必要がある.しかしながら,本論文では計 算機あるいは計算機の一部を占有して用いると仮定する.
これらの計算機環境上で実行する数値計算ライブラリの性能チューニング対象について 述べる.数値計算ライブラリの高速化のために,さまざまなプログラミング技法が研究開 発されている.そのプログラミング技法をユーザプログラムそれぞれに最適化できるよう に,数値計算ライブラリの中に性能パラメタの形で埋め込んでおく.
たとえば,計算機の中のパイプライン演算器のハードウェア構成(パイプラインの段 数,種類,数等)は性能に大きく影響する.このパイプライン演算器群を有効に用いるた めに,プログラミング技法として,ループアンローリングが用いられる[53].ループアン ローリングの深さを決めるループアンローリング段数は,ユーザプログラムの演算内容な らびに配列サイズに依存する.このループアンローリング段数を性能パラメタとする.多 重パイプライン演算器を限りなく効率よく動作させることを目的に開発されたベクトル型 スーパコンピュータでは,このループアンローリングの効果は大きい[17][42].現在の計 算機はさまざまなハードウェア構成の多重パイプライン演算器を装備しており,それぞれ 効果を最大に発揮するループアンローリング段数は異なる.
また,パイプライン演算器の高速化により,演算性能とメモリとパイプライン演算器間 のアクセス速度との乖離が広がり,現在の計算機は階層型キャッシュ構造をとることが一 般的である.この多階層キャッシュを有効に利用するために,行列データを小行列(この 行列単位をブロックと呼ぶ)に分け,そのブロックの単位で演算を実行する手法,いわゆ るキャッシュブロッキングが行なわれている[61].この場合,小行列の大きさ(ブロック サイズ)が性能パラメタとなる.これは,SMP *5 型並列計算機のように,メモリを共有 するタイプの並列計算機では特に効果が大きい.今後,ひとつのLSI上に複数のCPUコ アを持つマルチコア・アーキテクチャが主流になりつつあり[29][78],この傾向はさらに 強まると考える.
分散記憶型並列計算機環境においては,データの分割の形態,計算機ノード*6間のデー タ通信の性能(スループット,レイテンシなど)および計算機ノード間の同期処理(順序 制御処理)の手法が全体の性能に大きく影響する[94].データの分割としては,取り扱う
*5SMP:Symmetric Multi-Processor
*6分散記憶型並列計算機あるいはクラスタを構成するメモリ,演算器およびI/Oからなる計算機単位を計 算機ノードと呼ぶことにする.
表1 最適化の観点とそれに対応する性能パラメタ群(例)
最適化の対象 対応する性能パラメタ群
・演算器の構成 ・ループアンローリング段数 (パイプラインの段数,種類,数等)
・階層型キャッシュ構造,サイズ ・ブロックサイズ
・ループアンローリング段数
・計算機ノード間のデータ分割 ・データ分割の形態
・計算機ノード間データ転送 ・転送回数,ブロックサイズ レイテンシ,スループット
・計算機ノード間同期処理 ・同期処理手順
行列データを行あるいは列方向に分割するか,あるいは,矩形に分割するかは,計算機 ノード間で必要となるデータ転送パタンおよびデータ転送量,あるいは,データ転送量と 各計算機ノードで行なわれる演算処理のバランスで決まる.また,通信性能特性により,
計算機ノード間で送受信するデータをまとめる単位が変わってくる.同期処理についても 1対1の計算機ノード間で行なう場合と全体で一括して同期を取る場合なども並列計算機 のアーキテクチャおよびハードウェア構成方式に合わせる必要がある.それぞれ,データ 分割する際のデータの形状,計算機ノード間データ転送時のデータブロックサイズ,同期 処理の手法が性能パラメタとなる.さまざまなアーキテクチャおよびハードウェア構成方 式において,この性能パラメタの特性は大きく異なる[66][102].
数値計算ライブラリに関連する性能パラメタを最適化することにより,ユーザの使用す る計算機環境において,数値計算ライブラリを用いたユーザプログラムの実行時間を短縮 できる.そのために,性能パラメタのとり得る値を探索し,その中から性能パラメタの最 適値を選択する必要がある.
性能パラメタのとり得る値は,その最適化の対象を実現するアーキテクチャあるいは ハードウェア構成方式に依存する.たとえば,ループアンローリングの段数はパイプライ ン演算器の深さ(パイプラインの段数)やパイプライン演算器の数に関連する.これらは,
計算機が進化するほど,周波数向上によりパイプライン段数が増え,集積度向上により演
算器の数が増える.これらに伴い,最適なループアンローリング段数は増える方向にな る.また,ブロックサイズにおいても,キャッシュの容量が増加したり,演算性能と演算 器とメモリとの間のデータ転送のスループットやレイテンシが大きくなることは,ブロッ クサイズも大きくなる方向に働く.そのため,性能パラメタの最適値を選択するために探 索する性能パラメタのとり得る値の範囲は広がる方向になっている.
もうひとつ,考慮する必要があるのは,ユーザにソフトウェア自動チューニングを意識 させるかどうかである.前述したように,数値計算ライブラリの高速化はユーザ視点から すれば二次的な技術である.したがって,ソフトウェア自動チューニングは,できるかぎ りユーザから直接操作させなくてすむようにしたい.本論文では,ユーザからの直接操作 は仮定しない.つまり,ユーザの持つ知識は利用しない*7.そうすることにより,
1. ユーザがソフトウェア自動チューニングに関する知識を持たなくても済む,
2. 前提条件をつけないことにより,適用先の計算機環境あるいは数値計算ライブラリ に制約がつかない.
そのためには,ソフトウェア自動チューニング自体を,ユーザに影響ないように実行する 必要がある.また,性能パラメタの最適値を決定するための処理時間を,可能なかぎり短 くする必要がある.
本論文の目的は,ソフトウェア自動チューニングにおける性能パラメタ推定を効率よく 行なう方式を提案し,その有効性を提示することにある.ソフトウェア自動チューニング には多くの研究課題がある.それらの課題について2.2節で整理し,その中での性能パラ メタ推定の効率化の位置づけを明確にする.
*7ユーザの知識を利用して,さらにソフトウェア自動チューニングの効率および精度を上げることについて は,今後の課題として,6.2節で言及する.
本論文でのユーザはいわゆるエンドユーザである.ソフトウェア自動チューニングを利用するユーザに は,数値計算ライブラリの開発者もいる.ただし,この開発者は積極的に開発者の持つ知識を駆使して,
数値計算ライブラリを開発する.本論文で提案する新しい性能パラメタ推定法は,開発者としてのユーザ が作成した数値計算ライブラリでも用いることができる.
1.2 コンパイラとの関係
ユーザプログラムの最適化を行なうという点では,従来からコンパイラが主導的役割を 持つ.ここではソフトウェア自動チューニングとコンパイラとの関係を考察する.
コンパイラは,ユーザプログラムの制御フロー解析およびデータフロー解析を行なうこ とにより,動作する計算機環境に合うようにユーザプログラムを最適化する[53].ここで コンパイラが使えるのは,ユーザプログラムのソースコード上の情報のみである.
ユーザプログラムでは多くの情報が変数の形で記述される.たとえば,問題サイズ (行 列サイズ)や反復解法における終了条件としての反復回数などである.これらは,プログ ラム実行時にユーザから入力情報で与えられる.これらの変数で与えられた情報に対し て,個別の最適化はできない.一般に,コンパイラが作成するのはひとつのオブジェクト コードである*8.
一方,ソフトウェア自動チューニングでは,性能パラメタを用いて複数のパタンのソー スコードを準備する.複数のパタンのうち,どのパタンがよいかは,事前に数値計算ライ ブラリを実行することにより決定する.行列サイズなどのユーザプログラムに関する情報 が変数となり不明のときは,できるだけパタンを絞り込んでおいて変数が確定したとき に,絞り込んだパタンの中から,あるいは,数値計算ライブラリを再実行することにより,
最適なパタンを選択する.このとき,ソフトウェア自動チューニングで用いた複数パタン 自体は,コンパイラにより最適化される.
このように,ソフトウェア自動チューニングはコンパイラで対応が難しいところを補う 形で実行される.
さらに,コンパイラにもコンパイラ・ディレクティブという (性能)パラメタがある.
これらは,ユーザが指定することになるが,このコンパイラ・ディレクティブ自体をソフ
*8たとえば,コンパイラでもループアンローリングを行なうオブジェクトコードを生成する[53].ただし,
ソースコードからわかる範囲(ループ構造内の演算量など)で判断したある意味で 汎用の 最適化オブ ジェクトコードである.変数で指定されている行列サイズはわからないままなので,個別のユーザプログ ラムにとって最適なループアンローリング段数となっている保証はない.
トウェア自動チューニングの性能パラメタと考え,最適化の対象とすることも考えられ る*9.
1.3 本論文の構成
本論文は7つの章から構成される.
第1章は本章であり,本研究の背景,目的および意義について述べた.また,コンパイ ラとの関係について考察した.
第2章では,ソフトウェア自動チューニングにおける性能パラメタ推定の位置付けにつ いて述べる.まず,ユーザが数値計算ライブラリを用いるときにソフトウェア自動チュー ニングを実行するタイミングを示し,それぞれのタイミングでのソフトウェア自動チュー ニングの役割を示す.次に,ソフトウェア自動チューニングにおける研究課題を整理し,
その中で,本論文で取り上げた性能パラメタ推定法について説明する.さらに,性能パラ メタ推定法の研究動向を示し,本研究の位置付けを明確にする.
第3章では,新しい性能パラメタ推定法として,性能パラメタのとり得る値の中から標 本点を逐次に選択し追加しながら性能パラメタ推定を行なう,標本点逐次追加型性能パラ メタ推定法を提案する.この新しい性能パラメタ推定法の検討方針として2つの着眼点を 示す.(a) 複数の標本点ごとの数値計算ライブラリの実行時間をコストとするコスト定義
関数d-Splineを定義し,その導出方法および計算量などの特徴について述べる.(b) 標本
点を逐次追加するための基準として,標本点選択基準と終了判定基準を示す.さらに,標 本点逐次追加型性能パラメタ推定法の適用事例を示す.
第4章では,インストール時ソフトウェア自動チューニングへの標本点逐次追加型性能 パラメタ推定法の適用について実機を用いた実験を行ない,その結果を考察する.まず,
実験に用いた計算機環境およびソフトウェア自動チューニングの対象となる性能パラメタ
*9ただし,コンパイラ・ディレクティブはコンパイラで解析しきれない情報をユーザに要求している.たと えば,プログラムのソースコード上からはデータの依存関係が不明なときにでも,アルゴリズム上から データの依存関係はないことが明らかなことを,コンパイラ・ディレクティブにより,ユーザが強制ベク トル化や強制並列化を指定する.このような可否のレベルをソフトウェア自動チューニングで最適化対象 とすることは難しい.
について述べる.計算機環境として,スーパコンピュータならびにPCクラスタを用い る.対象数値計算ライブラリとして,代表的な密行列計算である固有値計算ライブラリの 主要ルーチンを用いる.その主要ルーチンでの性能パラメタとして,ループアンローリン グ段数,キャッシュブロッキングでのブロックサイズを取り上げる.次に,その実験結果 をもとにした標本点逐次追加型性能パラメタ推定法についての考察を行なう.また,コス ト定義関数として他の関数を用いた場合との比較を行なう.
第5章では,実行時ソフトウェア自動チューニングへの標本点逐次追加型性能パラメ タ推定法の適用について述べる.ソフトウェア自動チューニングの対象として,疎行列の 行列ベクトル積計算を用いる.疎行列を構成する非零要素の位置は実行時にしか決まらな いため,疎行列を対象とする自動チューニングは実行時にしか行なうことができない.こ こでは,疎行列の行列ベクトル積計算の性能向上のために,行列構造のブロック化を行な い,そのときのブロックサイズを性能パラメタとする.実用水準の疎行列ベンチマーク データを用いて実測を行ない,提案した性能パラメタ推定法を適用し,その効果を考察す る.さらに,性能パラメタ推定法を用いたソフトウェア自動チューニングに要する時間が 無視できる範囲であることを実測により確認する.
第6章では,今後取り組むべき課題について整理する.さらに,本論文では扱わなかっ たユーザ知識の活用についても,今後の課題のひとつとして触れる.
第7章では,本研究の結言として,研究結果についてまとめる.
2 ソフトウェア自動チューニングにおける性能パラメタ推定 の位置付け
2.1 ソフトウェア自動チューニングを実行するタイミング
ユーザが作成したユーザプログラムを実行する計算機環境上で,数値計算ライブラリを 用いる手順を図2 に示す.
1. ユーザプログラムを実行する計算機環境に,ソフトウェア自動チューニング機構を 組み込んだ数値計算ライブラリをインストールする.
2. ユーザプログラムの中に数値計算ライブラリを呼ぶインタフェースを組み込む.
3. ユーザプログラムをコンパイルし,数値計算ライブラリと結合する.
4. ユーザプログラムを実行する.このとき,数値計算ライブラリはユーザプログラム から繰り返し呼び出される.
この一連の手順の中で,数値計算ライブラリに対して,ソフトウェア自動チューニング を実行するタイミングとして,本研究ではつぎの2つのフェーズに対して検討した.
1. インストール時ソフトウェア自動チューニング −数値計算ライブラリを計算機環 境にインストールする時:
ここでは,計算機環境の情報がわかるので,計算機環境に対して数値計算ライブラ リが最適になるように,性能パラメタを自動チューニングする.ただし,ユーザプ ログラムに関する情報はわからない.たとえば,対象とするユーザプログラム上で の問題サイズ(行列サイズ)が特定できない.そのため,複数の行列サイズに対す る数値計算ライブラリの実行時間の実測結果を用意しておく必要がある.その結 果,自動チューニングの実行に1日単位の時間を要するのが現状である[2].それ でもすべての行列サイズを実行することは不可能であり,複数の行列サイズを選択 して実測する.選択されなかった行列サイズについては,選択された行列サイズの 実行結果を用いて性能パラメタの最適値を推定する.
!"#%$'&
!(#)*+,
-.
!"#%$./01
!"##$
2345
!(6)*7,98:<;%*>=%?A@9B#CDE<F(#
GB%CDE<FH(%
IKJLMNO
PQ!RS
I
UT#VW
X8YZ[\
98:;#*]=%?^@9B%CDHEF(%
98_`-Xab9B%CDHEF(%
JLMNO
PQ!<RScde9f
JL
dg9de
I
dehAibHj9klm98YneZ[\
o p
(%q!,
図2 数値計算ライブラリを用いたユーザプログラムの実行手順とソフトウェア 自動チューニングの実行タイミング
なお,インストール時ソフトウェア自動チューニングは,計算機環境が変わらなけ れば(メモリの増強,CPUの交換,あるいは,関連ソフトウェアの更新など),数 値計算ライブラリのインストール時に1度行なうだけで十分である.それ以降は,
インストールされた結果を用いればよい.
2. 実行時ソフトウェア自動チューニング −数値計算ライブラリを組み込んだユーザ プログラムを実行する時:
実行時にしかわからない情報を取り込んで,性能パラメタを自動チューニングす る*10.実行時にしかわからない情報としては,行列サイズ,あるいは,5章で評価
*10ユーザプログラムの実行時にしかわからない情報のうち,ユーザプログラムの実行前に必要な情報が提供 されれば,その時点でソフトウェア自動チューニングが可能となる.たとえば,事前に行列サイズが明示 されれば,この情報をもとに性能パラメタを最適化することができる.これは,実行起動前ソフトウェア 自動チューニングとして,インストール時ソフトウェア自動チューニングおよび実行時ソフトウェア自動 チューニングと区別されている[34].しかしながら,本論文では,後述するように性能パラメタ推定法に
実験に用いる疎行列データの非零データの位置情報などがある.実行時ソフトウェ ア自動チューニングでは,数値計算ライブラリがユーザプログラムから呼び出され るたびに,数値計算ライブラリに付随する自動チューニング機構が動作する.した がって,性能パラメタの最適値を推定し決定するまでは,性能パラメタのとり得る 値を変えることにより,いろいろなチューニングパタンが実行される.ただ,どの パタンでもユーザプログラムに戻す数値計算ライブラリでの計算結果の値は一致す る*11.この性能パラメタの最適値が決定したあとは,数値計算ライブラリはその 最適値をつねに用いることになり,その後,実行時ソフトウェア自動チューニング は実行しない.
2.2 ソフトウェア自動チューニングの研究課題
ソフトウェア自動チューニングは,まだ研究の歴史が浅い分野である [59][60].主な研 究課題を以下に列挙する.
1. 対象とする計算機環境の拡大への対応:
当初のソフトウェア自動チューニングは(特にスーパスカラ型の)シングルプロセ サを対象としていた[100].さらに,SMP型並列計算機,クラスタ,さらには,既 存の計算機資源を有効利用するための非均質なクラスタ環境やGRIDコンピュー ティング環境へと適用対象を広げている.これらにどのように対応するかを考えな くてはならない.
2. 新規の数値計算アルゴリズム開発に伴う性能パラメタの抽出:
ソフトウェア自動チューニングの研究は新規アルゴリズム開発と密接に結びつい ている.新規アルゴリズムを開発する際に,どのような性能パラメタがそのアルゴ
関する研究である.性能パラメタ推定法の手順からすれば,実行起動前ソフトウェア自動チューニング は,インストール時ソフトウェア自動チューニングと同じと考えられるので,区別はしない.
*11演算順序が異なる可能性があるので厳密には一致しない.演算順序の問題は並列化した場合の逐次プログ ラムとの差,あるいは,コンパイラにより計算順序が入れ替えられるなどにより起こりうることであり,
本論文では,問題としないことにする.
リズムを組み込んだライブラリに影響を与えるかを知るための感度解析が必要に なる.
3. 性能パラメタの最適値の導出:
ソフトウェア自動チューニング自体の実行は,ユーザからはその実行時間の隠蔽を はかる必要があり,そのため,効率のよい導出方法の開発が必要となる.
4. 推定した最適値の数値計算ライブラリへの組み込み:
推定した最適値をどのように数値計算ライブラリに組み込み,ユーザに提供するか を検討する必要がある.
5. ユーザプログラムの精度,実行時間を保証するための性能パラメタの設定基準 [25][26][27][28][56][57][58]:
ユーザの求める精度あるいは実行時間に対して,実行したソフトウェア自動チュー ニング機構がどこまで保証できるのか,検討する必要がある.
2.3 性能パラメタ推定の関連研究
本研究では,第 1章で述べたように,ソフトウェア自動チューニングの実用化に向け て,重要な課題である性能パラメタのとり得る値から最適値を選択する 性能パラメタの 最適値の導出 について検討を行なう.性能パラメタの最適値を導出する方法について,
現在の研究状況を整理し,本研究の位置付けを明らかにする.
まず,代表的なソフトウェア自動チューニングについて概観し,それぞれの性能パラメ タの最適値を導出する方法を調査する.
1. PHiPAC(Portable, High-Performance, ANSI, C Coding)
PHiPACは,Cで書かれたループレベルを対象としている.評価する性能パラメ
タは,レジスタブロッキング,L1キャッシュ対応ブロッキング,L2キャッシュ対 応ブロッキングなどである.
【性能パラメタの最適値の導出】 まず,レジスタブロッキングについて全数探索 して,そこで選択された最適値を固定して,L1キャッシュ対応ブロッキングにつ
いて探索,さらに,L2キャッシュ対応ブロッキングについて探索する.各段階で は全数探索を実施する.探索の順番により結果が異なる可能性がある.
2. ATLAS(Automatically Tuned Linear Algebra Subprograms)
ATLASは,密行列向けのBLAS関数を対象とし,評価する性能パラメタはループ
アンローリング,ブロッキングおよび数値計算ライブラリ選択などである.
【性能パラメタの最適値の導出】 数値計算ライブラリをインストールするときに,
全関数をBLASレベルでその計算機環境に対して最適化する.そのため,1日単 位の実行時間を必要とする[2].
3. I-LIB(A Parallel Automatically Tuned Intelligent Library)
I-LIBは,疎行列ベクトル積のループアンローリング,反復法アルゴリズムの選択,
反復法における前処理アルゴリズムの選択などを行なう.
【性能パラメタの最適値の導出】 ループアンローリング段数などにおいて,あら かじめ,1,2,4,8などの値を決め,その中から最適値を探索する.
4. 東大 小谷,須田グループ[46]
行列積を対象とし,評価する性能パラメタはループアンローリング(3重ループの すべてのループ)である.
【性能パラメタの最適値の導出】 ループアンローリングについては,2重から5 重までのすべての値について実測の対象とする.行列サイズについては事前に標本 点を設定し,それらの組合せで実測を行なう.これらの実測値をもとに,実験計画 法を用いて行列サイズ方向の特性を調べる.
5. FIBER/ABC-Lib (Framework of Installation, Before Execution-invocation and Run-time optimization Layers/Automatically Blocking and Communication- adjustment Library)
FIBERは,3つのソフトウェア自動チューニングのフェーズ(インストール時,実
行起動前,実行時)で実施するフレームワークを提供する.ABC-LibはFIBERを 実現するためのコンポーネントで,ABCLibScriptと呼ぶスクリプト言語を準備し ており,ソフトウェア自動チューニング付きライブラリを設計できる環境を提供し
ている.FIBER/ABC-Libでは,密行列計算を対象とし,評価する性能パラメタ は,ループアンローリング,ブロッキング,並列計算機での計算機ノード間の通信 プロトコル選択などである.
【性能パラメタの最適値の導出】 あらかじめ選択した性能パラメタのとり得る値 について,対象とする数値計算ライブラリの実測を行ない,それを多項式近似によ る推定を実施する.多項式の中でも経験的に5次多項式がよいとしている.
以上のソフトウェア自動チューニングに対して,性能パラメタの導出法の分類を図3の ように整理する.
1. すべての性能パラメタがとり得るすべての値を調べつくす全数探索を実施:
すべての性能パラメタがとり得るすべての値を対象に,その値に対する数値計算
! "$#
%&$')($*,+
.-/
'!021
3 45
-/67
8:9
;=<?>@;BA
3
<DCFEFE@CFGHGHCFCFI
7
JHKKL MON?PMQ;SR
3T
R=U
7
JHKKFV
U=>H;SAOW
$')XY +
Z
[\^]
._`
ab[cedf\
ghij 2k$#
lmno!p
qr st > sU 3 u I 7
JHKKFK
vwyx{z}|~B 3u I 7
@FF
e].
_ l$o
!
o
ab[ced\
e)
ab )_
) Y +
s UO
3
I 7
@F
Z ¡¢£¤
')021
8¦¥ ].
9§¥ _
p qr
'!021
¨ ©ª}«
6¬
88
8:9
89
8
¯®B°12±
²³
#´ p
qr
qrµ¶
©ª ' «
qrµ¶·
¸¹
')º»
図3 性能パラメタ最適値導出手法による関連研究の分類
ライブラリを実行する.そのため,性能パラメタの最適値の導出に時間がかかる.
例:PHiPAC,ATLAS.
2. 性能パラメタの値を絞り込んでから全数探索を実施:
性能パラメタのとり得る値からあらかじめ最適値となる候補を絞って探索する.最 適値はこのあらかじめ絞った候補の中から選ばれる.したがって,最適値を最初か らはずしてしまう可能性がある.例:I-LIB.
3. 事前に与えられた複数の値(標本点)を選択し最適値推定を実施:
あらかじめ選択した性能パラメタのとり得る値を用いることは項番2 と同じであ る.その選択した値に対する数値計算ライブラリの実測値をもとに,関数近似など を用いて最適値を推定する.この場合は,関数近似による推定の時間と精度に課題 がある.例:FIBER/ABC-Lib,東大 小谷・須田グループ.
これらの方式に対し,本論文では,第4の方式として標本点を逐次に追加する新しい性 能パラメタ推定方式を提案する.この方式のこれまでの3つの方式との根本的な違いは,
探索範囲を事前に固定して決めてしまうか,あるいは,探索範囲を柔軟に可変にするかに ある.あらかじめ,標本点をすべて決めておくのではなく,必要に応じて標本点を逐次的 に追加することにより,柔軟性を持ち,効率のよい性能パラメタ推定を実現することがで きることを3章以下で明らかにする.
2.4 本章のまとめ
本章では,ソフトウェア自動チューニングにおける性能パラメタ推定の位置付けについ て述べた.
1. ユーザが数値計算ライブラリのソフトウェア自動チューニングを行なうタイミング には,(a)数値計算ライブラリをユーザの計算機環境にインストールするときのイ ンストール時ソフトウェア自動チューニングと,ユーザプログラムを実際に実行す るときの実行時ソフトウェア自動チューニングの2つがあることを示した.
2. それぞれのタイミングでのソフトウェア自動チューニングの役割として,
(a)インストール時ソフトウェア自動チューニングでは,計算機環境に対する チューニングを行なうこと,ユーザプログラムに関する情報がないので,行列 サイズなどについては多くのパタンを調べる必要があることを示した.
(b)実行時ソフトウェア自動チューニングでは,ユーザプログラムに関する情報と して,行列サイズなどを特定することができるので,範囲を絞った性能パラメ タ推定ができること,ユーザプログラムの実行中にソフトウェア自動チューニ ングを行なうので,その時間を限りなくユーザに見せないようにする必要があ ることを示した.
3. ソフトウェア自動チューニングにおける研究課題を整理し,研究課題として,(a) 対象とする計算機環境の拡大,(b)新規の数値計算アルゴリズム開発に伴う性能パ ラメタの抽出,(c)性能パラメタの最適値の導出,(d)推定した最適値の数値計算 ライブラリへの組み込み,(e)ユーザプログラムの精度,実行時間の保証について,
述べた.その中で本論文では,(c)性能パラメタ最適値の導出のための性能パラメ タ推定法を対象とする.
4. 性能パラメタ推定法について,関連研究の分類を行なった.(a) 全数探索:すべて の性能パラメタの組み合わせパタンについて,数値計算ライブラリを実測,(b) 選 択した値の中で全数探索:性能パラメタのとり得る値の中で事前に複数の値を選択 し,その中から,最適な値を決定,(c) 標本点を用いた推定:性能パラメタのとり得 る値の中から,複数の標本点を選択し数値ライブラリを実行.その実測値から推定 を実施し,標本点でない値も含めて最適値を推定する.これらの方式に対し,第4 の方式として標本点を逐次に追加する新しい性能パラメタ推定方式を提案する.こ の方式のこれまでの3つの方式との根本的な違いは,探索範囲を事前に固定して決 めてしまうか,あるいは,探索範囲を柔軟に可変にするかにある.この柔軟性によ り,効率のよい性能パラメタ推定を実現することができることを3章以下で示す.
3 標本点逐次追加型性能パラメタ推定法の提案 3.1 新しい性能パラメタ推定法の検討方針
数値計算ライブラリに組み込まれている性能パラメタを,ユーザの持つ計算機環境で実 行するユーザプログラムに最適に設定するのが自動チューニングである.そのために,性 能パラメタのとり得る値を変えながら数値計算ライブラリを繰り返し実行し,その実行 時間を測定する.数値計算ライブラリの性能は主要な複数のループ構造の性能で決まる [97].それぞれのループ構造の中に,パラメタ化された性能チューニング項目を設定する.
しかしながら,各々のループ構造の最適な性能パラメタ値の組合せを調べつくすには,膨 大な時間がかかる.さらに,インストール時自動チューニングの段階では,ユーザプログ ラムを実際に実行する時に必要とする問題サイズが不明なので,問題サイズを変えなが ら,数値計算ライブラリを繰り返し実行する必要がある.しかしながら,すべての問題サ イズを用いてあらかじめ実行することは不可能である.そのため,性能パラメタのとり得 る値からいくつかの点を選択し標本点とし,その標本点を用いて性能パラメタ推定を行な うことにより,自動チューニングを行なう.
実測データをもとに,実測していないパラメタのとり得る値を含めて,コスト定義関数 を用いてデータフィッティングによる最適なパラメタ値の推定を行なう.ここで,コス ト定義関数とは,評価の基準となる関数であり,最適化問題のコストを定義する.自動 チューニングにおいては数値計算ライブラリの性能として実行時間をコストとする*12.
通常,実測結果に基づくパラメタ推定は,事前に与えられた標本点における実測データ だけを用いて行なわれる.標本点が適切に選択されているかどうかが,パラメタ推定の精 度,つまり,最適なパラメタ値を推定できるかどうかの条件になる.この標本点の選択は 一般に難しい.数値計算ライブラリの性能パラメタの自動チューニングにおいても,実行 時間をコストとしたコスト定義関数が,さまざまの計算機環境およびユーザプログラムに
*12本来,コストとしては,性能以外に,使用するメモリ量,精度,使用量などが考えられるが,本論文では,
性能(=実行時間)に特化して扱う
おいて,どのような特徴を持っているかはわからない.
ソフトウェア自動チューニングにおける標本点の選択について考察する.ここでは,対 象とする計算機環境があり,(時間が許せば)どの性能パラメタのとり得る値についてでも 数値計算ライブラリを実測することができる.実測済みの標本点だけでは結果が不十分と なれば,必要とする標本点をさらに追加して実測することも可能である.したがって,最 初から実測データを揃えるのではなく,まず,コスト定義関数の形状を表現するのに必要 な最低限の数の実測データを用いた推定から開始し,推定結果が十分であるか否かを判定 する.もし十分でなければ,実測すべき標本点を逐次追加する.このことより,推定の効 率と精度を向上できる可能性がある.この場合,推定結果が十分であるか,そうでないか をどのように判断するかの基準や,標本点を逐次追加するときに,どのような基準で選択 するかを決める必要がある.
一方,コスト定義関数については,一般に,多項式近似などの関数近似法などが用いら れる.関数近似法では,その関数をあらわす係数パラメタを最小二乗法などで決定する.
しかし,この方法では関数形そのものの特性が出てくるために,よりよい近似を求めるこ とが難しい.さらに,今回提案する標本点を逐次追加する推定法では,繰り返しコスト定 義関数を計算するので計算量を抑えること,および少ない標本点でも安定した結果が得ら れることが必要となる.したがって,コスト定義関数として,最初から多くの標本点を必 要とする関数(たとえば,区分多項式のB-Splineなど)を用いることも難しい.
以上をまとめると,新しい性能パラメタのチューニング方式では,次の2点について検 討をする必要がある.
1. コスト定義関数の選択
(a)少ない標本点から計算できること
(b)再計算のための計算量(=実行時間)が小さいこと 2. 標本点を動的に追加する方法を用いる時の2つの基準
(a)標本点を追加するか否かの終了判定基準
(b)標本点を追加すると判定したときの選択基準
!"
!
!"#
!$
s s s s
%&('*),+,-(.0/213,4576,8:9<;>=?&
s
'*@,A,9CB E FGH
IJ
HK
L
M
NO
P
図4 近似関数f と実測データの集合yの関係
本論文では,各々について提案を行ない,それらを組み合わせることにより,「標本点 逐次追加型性能パラメタ推定手法」を実現する[91][92][93].
3.2 コスト定義関数 d-Spline
3.2.1 コスト定義関数d-Splineの導入
性能パラメタのとり得る値ごとの数値計算ライブラリの実行時間で構成される関数形 は,滑らかさとか凸性は保証されない.また,標本点を追加するたびにコスト定義関数を 再計算する必要がある.そこで,データの動きに柔軟に追随する 柔らかさ を持ち,さ らに,標本点が少なくても安定に解が得られ,かつ,計算量の少ないコスト定義関数とし て,近似関数f(x)を次のように定義する.
近似関数 f(x) をn個の離散点上の値 fj =f(xj),1≦j≦nで表現する.つまり,
f =(f1, f2, f3, . . . , fj, . . . , fn)t,tは転置を示す.
ここでxj,1≦j≦n は等間隔とする.滑らかさを出すために,nは性能パラメタのと
1-2 1 1 -2 1
1 -2 1
1 -2 1 1 -2 1
1 1
0 1
0 0 1
0 1
1-2 1 1 -2 1
1 -2 1
1 -2 1 1 -2 1
1 1
0 1
0 0 1
0 1
図5 行列E,Dの形状
り得る値の数Nより十分大きくとる*13.いまN個の中からk個の標本点の実測データが とられているとする(k≦N).この実測データをyi (1≦i≦k)とする.
y= (y1, y2, y3, . . . , yi, . . . , yk)t,tは転置を示す.
近似関数f とk個の実測データの集合 y および性能パラメタのとり得る値との関係を 図4に示す.xj(1≦j≦n)の一部が性能パラメタをとり得るN個の値であり,図中の
□で囲んだxj となる.□のうちのk個の □S で示したxj が標本点であり,その標本点 に対する実測データがyi となる.すべての□が標本点となるわけではない(図4ではx9
に対してyi が存在していないことに注意).
yだけではyi よりfj の数の方が多いので,f を確定するために,f の滑らかさを式(1) であらわす.
|fj−1−2fj+fj+1|2,1≤j ≤n−1. (1)
この近似関数f を評価関数
minf (ky−Ef k2+α2kDf k2) (2) を最小にするように選ぶ.ここで,E,D は図 5 に示すような行列であり,それぞれ k×n,(n−2)×nのサイズである.式(2)の第1項はデータyと近似関数f との距離で
*13後で述べるように2階差分でf の滑らかさを表現しているので,fjの場所は各性能パラメタのとり得る 値の間に最低2点,また両端に2点を配置する.したがって, N個の性能パラメタのとりうる値が等間 隔ならば,n=N×3 + 2 となる.