統計遺伝学の歴史
とくに量的形質の解析に関連して
鵜飼保雄 前 東京大学大学院農学生命科学研究科 e-mail:[email protected] 1. 量的形質はメンデルの遺伝法則の下にどのように解釈されたか 1.1 メンデリズムと量的形質の遺伝 生物の特性が集団の個体間で異なり,その差異が部分的にも遺伝的であるとき,その特性を形 質という.まったく遺伝しない特性は形質とよばない.形質にはさまざまな種類がある.植物で いえば,白花と赤花,早生と晩生,病害抵抗性と罹病性などである.形質は質的形質と量的形質 に大別される.質的形質とは,エンドウの白花と赤花のように個体間における形質の表現が不連 続な階級に分類できる形質をいう.メンデルが遺伝実験に用いた 7 形質は,草丈以外はすべて質 的形質である.一方,量的形質とは,数または長さ,重さ,時間などの量で表される形質をいう. ヒトでいえば,身長や体重が,植物では収量や開花期などが例である.動植物の改良には量的形 質の解析が重要となる. 遺伝学は世代から世代へ形質がどのような法則で伝わるかを探ることから始まった.1900 年に メンデルの法則が再発見されると,植物や動物の多くの種で形質が遺伝法則に則して子孫に伝わ ることが実験的に確認された.遺伝子の本体はまだ不明であったが,メンデルの法則に従って遺 伝する因子を仮定することにより遺伝現象を見事に説明できた. しかし,それは質的形質についてだけで,量的形質についてはメンデルの法則は適合しないと 考える研究者もいた.それは英国の生物学者ウエルドンや統計学者ピアソンなど生物測定学派と よばれた人たちである.もともと論争は進化論から始まった.彼らは「変異の連続性」と「連続 変異の蓄積による進化」というダーウイン以来の伝統的考えを信じていた.それに対して真っ向 から挑戦したのが同じ英国のベーツソンである.彼は不連続な形質変異の実例を 800 以上集め, 生物は不連続な変異の蓄積によってこそ進化すると強く主張した.メンデルの法則が再発見され ると,英国内で最初に紹介し最大の擁護者となった.彼はメンデルの法則によって生物測定学派 は息の根を止められたとして,反論する者を講演や著作で容赦なく攻撃した.議論の焦点は進化 論から遺伝法則へ移った.激しい論争はウエルドンの急逝によってようやく終焉したが,連続変 異をする量的形質の遺伝をどのように説明するかは未解決のまま残った. ベーツソンは,ウエルドンとの論争の中で,連続的にみえる形質も 2 つの対立形質からなる複数の要素に分解できるとすれば,その遺伝もメンデルの法則で説明できると主張した.米国では スターテヴァント,マラーなどの遺伝学者も,またイースト,シャル,ライトなどの生物測定学 者も,効果の小さいメンデル因子が多数関与しているとすれば,連続変異を示す量的形質の分離 も説明できると当初から考えていた.しかし,それをメンデルの法則にもとづいて正確に理論づ けたわけでも,実験例を示したわけでもなかった. 1.2 ニルソン・エーレによる同義因子による量的形質の遺伝の説明 スワレフにあるスウェーデン種子協会の研究所では,19 世紀末から穀類を中心に交雑育種が開 始されていた.メンデルの法則が再発見されると,多くの農業形質についての遺伝様式の調査を 大規模におこなった.その中で 1909 年にニルソン・エーレ(Herman Nilsson-Ehle)は,コムギの 粒色の遺伝様式を調べるため,赤色品種と白色品種の交配を多数の組合わせで行った.その結果, ある組合わせの F2では予想に反して全個体が赤色粒をつけ,また赤色個体間には色の濃淡が認め られた.F3での調査結果とあわせてこの結果は,(1)コムギ粒の赤色をもたらす同じような効果 をもつ遺伝子が 3 個あり,(2)それらは独立に遺伝し,(3)赤色遺伝子は白色遺伝子に対して優性 で,(4)赤色遺伝子の数が多いほど粒の赤色が濃くなり,また赤色遺伝子の数が同じならどの組 合わせでも同じ程度の赤色となる,とすればよく説明できた.彼はさらに思考を進めて,ある形 質に同程度の小さな効果をもつ遺伝子が多数関与し,交雑後の雑種世代でそれらが独立に分離し, さらにそれらの遺伝子の効果に環境効果が加わることにより,形質の表現が連続的になると考え た.遺伝における「同義因子」の発見である.これにより初めて連続変異を示す量的形質も,メ ンデルの遺伝法則に従うと結論された.その後米国のイースト(E. M. East)もトウモロコシの穂 の粒列数やタバコの花冠の長さなどの量的形質の遺伝が同義因子により説明できることを示した. 1.3 ヨハンセンによる量的形質における遺伝変異と環境変異の分割 メンデルの遺伝法則の再発見に加えて,量的形質の遺伝についての基本的な原理となったのは, デンマークのヨハンセン(Wilhelm Ludwig Johannsen)による「純系説」である.ヨハンセンは, 生物測定学者のゴールトンが唱えた「回帰の法則」を応用して,量的形質について極端な個体を 毎代選抜し続ければ選抜の効果が上がるはずだと考え,インゲンマメの粒重を対象として実験を 行なった.1900 年に市販の 19 粒の種子を親豆として選び,自殖によって翌年 574 粒,翌々年 5,494粒を得た.各粒の重さを測り,親子関係を記録した.1902 年の 5,494 粒の重さは正規分布 に近かった.各粒の重さを 1900 年の親豆からの由来別に平均すると,2 倍近い差があった.し かし各親豆由来の系統内で,1901 年の重さ別にわけた 1902 年の粒の重さは,平均してほとんど 差が認められなかった.つまり親豆間の変異はそのまま縮小されずに子孫に伝達されたが,各親 豆の子孫内の個体間変異は伝わらず,系統内で選抜しても効果がなかった.これにより量的形質 の変異には,「遺伝する変異」と「遺伝しない変異」があることがわかった.彼は各親豆由来の 子孫のように,遺伝変異を含まない系統を「純系」となづけた.選抜効果があるのは純系間の変 異であり,純系内の変異は遺伝しない.これを「純系説」という.ヨハンセンは gene(遺伝子), genotype(遺伝子型),phenotype(表現型)の用語をはじめて定義した.彼は,遺伝子型自体は不 連続であるが,それに環境変異が加わるために,各遺伝子型の示す形質の分布曲線が重なって, 形質の測定値からだけでは遺伝子型を識別できないことを初めて指摘した.
2. 量的形質の統計遺伝モデルの開発 2.1 フィッシャーによる平均効果モデルの開発 量的形質の遺伝もメンデルの法則で説明できることが認められるようになった 1910 年代になっ ても,量的形質の遺伝を解析する方策はなく,論文でも交配子孫での形質値の分布のヒストグラ ムをただ提示するだけであった.量的形質の遺伝解析には,統計学の援用が必要であった.ただ し,それはピアソン流の生物測定学ではなく,メンデリズムに根ざした新しい学問でなければな らなかった.その道を切り開いたのが二十世紀最大の数理統計学者であるフィッシャー(Ronald Aylmer Fisher)であった.
彼は中学校教師をしていた二十歳代半ばに,The correlation between relatives on the supposition of Mendelian inheritance(メンデル遺伝の想定から期待される近親間の相関)という論文を書きあ げた.これをピアソンが主宰する雑誌 Biometrika に投稿したが却下された.最終的に 1918 年エ ジンバラ英国学士院会報に一部費用を著者負担で掲載された.これこそ量的形質の解析への道を 開いた論文であった.生物測定学派が示した親子,兄弟,いとこなどの近親者間での量的形質の 相関は,メンデリズムに基づいたモデルに即した理論計算によって導くことができることが明ら かにされた.彼は,ピアソンが仮定した完全優性や遺伝因子の効果の均等性は必要ないことを示 し,無作為交配下で遺伝因子が独立遺伝することだけを条件として,結果を導いた.また因子間 で交互作用がある場合も考慮にいれ,これをエピスタシス(epistasis)とよんだ.さらに優性ホモ, ヘテロ,劣性ホモの遺伝子型値に対する直線回帰を適合して,遺伝分散を回帰で説明される分散 と残差分散にわけ,遺伝分散中の回帰にもとづく分散の割合として,種々の近親間の相関を求め ることに成功した.これはのちに集団遺伝学(population genetics)とよばれる領域の誕生といえ る.論文には,この領域における基本的概念がすでに多く含まれていた.なお統計学の重要な概 念となる「分散」もはじめてこの論文で定義された. フィッシャーのモデルはその後多くの研究者により洗練された.以下に木村(1960)の説明にも とづいてモデルを簡単に説明する.形質に関与する遺伝子座について,ある個体がもつ対立遺伝 子についての集合を遺伝子型という.いま 2 倍性生物のある集団においてある座 A に注目したと き 3 種の遺伝子型を A1A1, A1A2, A2A2と表すとする.集団における各遺伝子型の個体の頻度を それぞれ f11, 2f12, f22(f11+ 2f12+ f22= 1),遺伝子型値を g11, g12, g22とする.ただし対立遺 伝子は A1, A2の 2 個とする.このとき対立遺伝子の頻度は A1: p = f11+ f12 A2: q = f12+ f22 (1) となる (p + q = 1).無限個体からなる集団を考え,集団全体の遺伝子型値の平均を ¯gとすると ¯ g = f11g11+ 2f12g12+ f22g22 (2) となる.ここでそれぞれの遺伝子型値そのものでなく,¯gからの偏差を考え y11= g11− ¯g y12= g12− ¯g
y22= g22− ¯g (3) とおく.もしこの修正された遺伝子型値(y11, y12, y22)が遺伝子型に含まれる個々の対立遺伝子の 効果の和で決まるならば,いいかえると対立遺伝子の効果が遺伝子型に関係なく一定ならば,対 立遺伝子 A1, A2の遺伝効果を θ1, θ2とするとき,A1A1, A1A2, A2A2の遺伝子型値はそれぞれ 2θ1, θ1+ θ2, 2θ2となる.しかし実際には通常は対立遺伝子間交互作用つまり優性(dominance)が ある.そこで集団の各遺伝子型についての遺伝子型値の期待値からの偏り(たとえば A1A1 につ いては y11− 2θ1)を考え,集団全体での 2 乗和 Q = f11(y11− 2θ1)2+ 2f12(y12− θ1− θ2)2+ f22(y22− 2θ2)2 (4) Qを最小にするような量として θ1, θ2を定義する.このとき θ1, θ2をそれぞれ対立遺伝子 A1, A2 の「平均効果」(average effect)という.平均効果は,遺伝子型値 y11, y12, y22が θ1+ θ1, θ1+ θ2, θ2+ θ2によって最もよく近似できるように定められたものといえる.また平均効果は遺伝子型値 の A1遺伝子の数への直線回帰によって説明される部分である(図 1).集団遺伝学的には,ある対 立遺伝子の平均効果とは,その対立遺伝子をある親から受けついだ子供全体における遺伝子型値 の平均の集団平均からの偏差に等しい.ただし親の集団は無作為交配をしているとする. Qを最小にする θ1, θ2を求めるには,式 (4) の右辺を θ1, θ2で微分した式を 0 に等しいとおい て得られる連立方程式を解けばよい.すなわち 図 1. フィッシャーの平均効果モデル.平均効果 θ1, θ2は集団の 遺伝子型頻度に依存する.(g11= 100, g12= 90, g22= 60とする. 回帰直線のうち実線は f11= 0.25, f12= 0.25, f22= 0.25の場合で, ¯ g = 85, θ1= 10, θ2=−10 となる. 点線は f11= 0.50, f12= 0.25, f22= 0.00の場合で,¯g = 95, θ1= 2.5, θ2=−7.5 となる)
∂Q ∂θ1 =−4f11(y11− 2θ1)− 4f12(y12− θ1− θ2) = 0 (5a) ∂Q ∂θ2 =−4f12(y12− θ1− θ2)− 4f22(y22− 2θ2) = 0 (5b) これを解くと pθ1+ qθ2= 0 (6) ここで θ = θ1− θ2 (7) とおくと θ1= qθ (8a) θ2=−pθ (8b) と表される.θ を遺伝子 A1を A2で置きかえたときの「置換による平均効果」とよぶ.これは集 団において対立遺伝子 A1を A2で置換したときに,子供の世代で生じる集団全体での遺伝子型値 平均の変化量に等しい. なお p = q の場合には,平均効果は遺伝子型値だけで決まり,遺伝子型頻度に関係なく世代間 で一定となる.また平均効果は後述のホモ接合体基準モデルにおける相加効果 a と等しくなる. 遺伝子型 A1A1, A1A2, A2A2の平均効果だけにもとづく期待値 2θ1, θ1+ θ2, 2θ2 を「育種価」 という.ある個体の育種価は,その個体がもつ遺伝子の平均効果の和に等しい.平均効果,した がって育種価も,遺伝子型だけではきまらず,集団における対立遺伝子頻度によって変わる. 遺伝子型値から育種価を引いた差を優性偏差という.優性偏差は遺伝子型値の A1遺伝子の数 への回帰によって説明できない部分である.すなわち δ11= y11− 2θ1 (9a) δ12= y12− θ1− θ2 (9b) δ22= y22− 2θ2 (9c) 優性偏差も遺伝子型頻度の関数であり,一般に遺伝子型 A1A1, A1A2, A2A2によって異なる.
平均効果モデルは集団遺伝学(population genetics)における基本モデルとして用いられるよう になった.集団遺伝学は進化を数理的に解明することを目的とするため,もっぱら集団における 遺伝子頻度の変化を追及し,形質の値自体には注目しない.そのため環境変異は重要ではない. 対立遺伝子 A1 と A2 の遺伝子頻度を p, q とするとき,無作為交配下では A1A1, A1A2, A2A2 の頻度がそれぞれ p2, 2pq, q2の頻度となり,世代が進んでも遺伝子頻度も遺伝子型頻度も変化し ない.これをハーディ・ワインベルク平衡(HW 平衡)という.集団遺伝学では,集団内の個体は 無作為交配下で HW 平衡にあるという前提で理論を構築することが多い.HW 平衡下では,平均 効果も育種価も世代によって変わらないので,平均効果モデルを使うことに支障はない.むしろ 集団遺伝学が主に対象とする自然集団では集団内の遺伝子頻度が不明の場合が多いので,平均効 果モデルならば相加分散や優性分散を簡潔な形で表現できるという利点がある.たとえば,遺伝
子型値のよる分散,すなわち遺伝分散 Vgは
Vg= f11y211+ 2f12y212+ f22y222 (10)
と表され,このうち遺伝子の平均効果による部分は,無作為交配下では Va= f11(2θ1)2+ 2f12(θ1+ θ2)2+ f22(2θ2)2 = p2(2θ1)2+ 2pq(θ1+ θ2)2+ q2(2θ2)2 = 2pqθ2 (式 (6) より) (11) という簡潔な形で表現される. 2.2 フィッシャーのホモ接合体基準モデル
フィッシャーは 1932 年に The genetical interpretation of statistics of the third degree in the study of quantitative inheritance(量的遺伝の研究における三次統計量の遺伝的解釈)という論文 を発表した.これは米国農務省所属の遺伝学者インマー(F. R. Immer)およびスウェーデンのワイ ブルスホルム植物育種場の育種家テディン(Olof Tedin)との共著であった. ここで提示された遺伝モデルは前論文の平均効果モデルとは異なっていた.ここでは,ある遺 伝子座について,両親の平均(これを中間親値という)を基準として,優性ホモ,ヘテロ,劣性ホ モ個体の遺伝子型値の基準点からの偏差を d, h,−d で表わした.d と h はそれぞれ相加効果およ び優性効果とよばれた.フィッシャーは,植物集団を対象に品種間交配の後代において,F2個体 間分散,F3系統の分散の平均,F3系統の平均の分散,などの 9 種類の 2 次統計量と,F2個体の 歪み,F3系統の歪みの平均などの 11 種類の 3 次統計量を,この d と h の関数で表現できること を示した.ただし,環境効果については,触れてはいるが,モデル中に明示されてはいない.論 文では,これらの統計量について,レタス,トウモロコシ,オオムギのデータを実例として,と くに分布の歪みを中心に議論している.なぜか相加効果や優性効果の推定はしていない.この論 文は,量的形質の遺伝モデルをはじめて示したもので,「統計遺伝学」または「計量遺伝学」とよ ばれる分野の源流となった. フィッシャーはなぜ平均効果モデルとは異なるモデルを新しく考えたのであろうか? その秘 密は共著者にある.共著者の目的は集団遺伝学がめざす進化の解明ではなく,品種の改良にあっ た.とくにコムギやオオムギなど自殖性作物の改良のための遺伝モデルの開発をフィッシャーに 依頼したのであろう.平均効果モデルでは平均効果,育種価,優性偏差のすべてが遺伝子型の集 団内頻度に依存する.このモデルによるとたとえば F2と戻し交配世代とでは遺伝子型頻度が異 なるので,世代間で共通した遺伝効果を推定できない.これでは品種改良に応用しにくい.品種 育成では交配後のできるだけ早い世代で,量的形質の集団内変異のうちどれだけが遺伝的で,ま た遺伝的に品種として固定できるかを推定することである.また最近では量的形質遺伝子につい ても遺伝子が単離可能になりつつあるが,その場合,遺伝子の効果は集団の遺伝的構成とは独立 に定義されるべきであり,平均効果モデルはその点からも適当でない. 自殖性植物の改良では,2 品種(または系統)間で交雑し,その子孫から優良個体を選抜して,そ れをさらに何代か自殖して最終的に完全なホモ接合個体の新品種とする.この場合,親となる品 種は純系,つまり全遺伝子座でホモ接合(完全ホモ接合)である.親が完全ホモ接合であれば,交
配子孫における分離遺伝子座の遺伝子型の期待頻度は既知となり,遺伝効果の推定が可能となる. そこで 2 純系間交配に由来する子孫を対象として,ホモ接合体を基準とした統計遺伝モデルが考 案された.ここではこれを「ホモ接合体基準モデル」とよぶ.このモデルはのちに英国の細胞遺 伝学者マザー(Kenneth Mather)によりさらに改良されて植物における量的形質の遺伝解析に広く 応用されるようになった.以下,それにもとづいてモデルを解説する. ある個体の形質がある特定の環境条件の下に発現されたものを「表現型」という.ただし量的 形質では形質の観察値は連続的で,質的形質における赤花対白花のような離散的な階級(つまり 型,タイプ)は存在しない.ある個体のある量的形質について測られた表現型の値を「表現型値」 という.遺伝子型は生物固有で,形質の測定以前に確定しており,将来は DNA の塩基配列によっ て決定できるであろう.それに対して量的形質では表現型値はある環境下での生物の生育と形質 の計量をとおしてはじめて決まる. 表現型値には,遺伝的に決まる部分と,環境によって決まる部分が含まれる.そこで前者を g, 後者を e とするとき,表現型値 p は単純に, p = g + e (12) と表せる.これが量的形質に係わる基本的な統計遺伝モデルである.g を「遺伝子型値」という. 遺伝子型値は形質に関与する遺伝子座の遺伝子型で決まる.この場合の遺伝子座には分離遺伝子 座だけでなく,非分離遺伝子座も含まれる.e を「環境効果」という.環境効果は多くの環境要因 の総合的影響であり,ふつう平均が 0,分散が各環境に固有の値(σ2)をもつ正規分布にしたがう と仮定される.集団が無限個体で構成されるとき,表現型値の集団内個体全体にわたる平均は遺 伝子型値と等しくなる.このモデルでは,環境効果は遺伝子型値と統計的に独立であるとされる. もし,質的形質のように表現型から遺伝子型が決定できるならば,分離世代における各個体の 表現型値を観測値とし,相加効果 ai,優性効果 diを母数,環境効果 e を残差として,通常の統 計手法である回帰分析を応用して遺伝効果を求められる.遺伝子型が既知ならば,それを要因の 水準として用いることができる.しかし量的形質では,関与する遺伝子座が多いため分離世代で 分離する遺伝子型の種類が多く,遺伝子型間の差が小さい.そのうえ遺伝子型値に環境による変 動が加わる.そのため表現型から各個体の遺伝子型を推定することは不可能である.そこで通常 の統計学手法とは異なる方法が必要とされる. 2純系間の交配 P1(♀)× P2(♂)に由来する子孫である自殖世代の F1, F2, F3や戻し交配世代 などを 2 純系間交配後代とよぶ.交配子孫の世代では当然ながら,親間で対立遺伝子が異なる遺 伝子座で遺伝的分離がおこる.このような遺伝子座を「分離遺伝子座」とよぶ.親間で対立遺伝 子が同一である遺伝子座は,分離が生じないので「非分離遺伝子座」とよぶ. ここで (12) 式のモデルからさらに進んで,遺伝子型値を各種の遺伝効果にわけて考える.ある 分離遺伝子座 A について,2 つの対立遺伝子 A1と A2を考え,3 種の遺伝子型である,ホモ型 A1A1,ヘテロ型 A1A2,ホモ型 A2A2の遺伝子型値をそれぞれ g11, g12, g22とおく.このとき, 二つのホモ型間の差の半分 (g11− g22)/2を遺伝子座 A の「相加効果」といい,ここでは aAで表 す.相加効果とは,A1と A2の効果の間に交互作用(後述の優性効果)がないとき,遺伝子 A1を A2で置き換えたときの効果である.
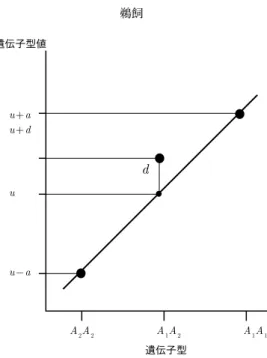
図2. フィッシャーのホモ接合体基準モデル. 相加効果 a と優性効 果 d は,集団の遺伝子型頻度に依存しない.(g11= 100, g12= 90, g22= 60とする. このとき u = 80, a = 20, d = 10 となる). 2つの対立遺伝子のうち,どちらを A1とするかは任意である.マザーは形質値を増加させる 方向に働く対立遺伝子を A1,減少させる方向に働く対立遺伝子を A2と定義した.この場合は相 加効果 aiはつねに正値となる.しかし最近は母親由来を A1,父親由来を A2とすることが多い. ここでもそれに従う.この場合は aiは正値とは限らない. ヘテロ型とホモ型平均との差 g12− 1 2(g11+ g22)を遺伝子座 A の「優性効果」といい,ここで は dA で表す.この優性効果は平均効果モデルでの優性偏差とは異なる.優性効果は正,0,負 のどのような値もとりうる.dA= 0のとき遺伝子座 A は無優性,|dA| < |aA| のとき不完全優性, |dA| = |aA| のとき完全優性,|dA| > |aA| のとき超優性という.ここで「優性」は対立遺伝子間の 交互作用の様式を表すだけで,機能的な優秀性を意味するものではない. 2純系間の交配 P1(♀)× P2(♂)において,A, B の 2 遺伝子座が関与しており,A, B 座の相 加効果を aA, aB,優性効果を dA, dB,とするとき,たとえば両親とその F1の遺伝子型値は,エ ピスタシスがないとすると,つぎのとおりに表される. A1A1B1B1 u + aA+ aB (13a) A1A2B1B2 u + dA+ dB (13b) A2A2B2B2 u− aA− aB (13c) uは遺伝子型に無関係な定数であり,非遺伝的効果(環境変異とは別の)と非分離遺伝子座の効果 の和である.u は非分離遺伝子座の効果に依存するので,通常は交配親の組合わせによって異な る.両親の遺伝子型値の平均と等しい遺伝子型値をもつ仮想的な個体を考え,これを「中間親」
とよぶ.エピスタシスがなければ中間親の遺伝子型値は定数 u と等しくなる. ここで相加効果および優性効果について,全分離遺伝子座(その数を k とする)にわたる和をつ ぎのように定義すると, (a) = k X i=1 ai (14a) (d) = k X i=1 di (14b) 式 (13a,b,c) はさらに簡単に以下で表される. A1A1B1B1 u + (a) (15a) A1A2B1B2 u + (d) (15b) A2A2B2B2 u− (a) (15c) 分離集団の遺伝子型値の集団平均は,それぞれの遺伝子型の遺伝子型値に期待分離比を乗じて 求められる.たとえば遺伝子座 A と B で分離する (k = 2) F2 では 9 種の遺伝子型 A1A1B1B1, A1A1B1B2, A1A1B2B2, A1A2B1B1, A1A2B1B2, A1A2B2B2, A2A2B1B1, A2A2B1B2, A2A2B2B2 が 1 : 2 : 1 : 2 : 4 : 2 : 1 : 2 : 1 の比で分離するので,その集団平均は
Mg[F2] = (1/16)A1A1B1B1+ (1/8)A1A1B1B2+··· + (1/16)A2A2B2B2 = (1/16)(u + aA+ aB) + (1/8)(u + aA+ dA) +··· + (1/16)(u − aA− aA)
= u + (1/2)dA+ (1/2)dB = u + (1/2)(d) (16) となる. 相加効果の和 (a) や優性効果の和 (d) は,異なる世代の表現型値の平均から容易に推定できる. しかし,遺伝子座間で正負が相殺されることがあり,その場合には実際の遺伝効果を過小評価す ることになる. そこで遺伝効果の和ではなく分散および共分散を考える.表現型値の分散すなわち「表現型分 散」は,式 (12) より, VP= VG+ E (17) となる.VGは「遺伝分散」,E は「環境分散」である.ただし遺伝効果と環境効果は独立とする.
F2におけるある遺伝子座 A の分離の期待比は (1/4)A1A1: (1/2)A1A2: (1/4)A2A2となり,分 離による分散は,つぎのとおりとなる.ただしエピスタシスはないとする.
VG[F2] = (1/4)a2+ (1/2)d2+ (1/4)(−a)2− ((1/4)a + (1/2)d − (1/4)a)2
= (1/2)a2+ (1/4)d2 (18)
ある任意の個体の遺伝子型値は,各座の遺伝子型にもとづく寄与分の和であるので,もし遺伝子 座間でその寄与分が統計的に独立ならば,遺伝分散は各遺伝子座の寄与分の和として表わされる.
この場合には計算は簡単になる.このような統計的独立性が成り立つのは,遺伝的分離の独立性 つまり遺伝子座間で連鎖がないこと,および遺伝効果の独立性つまりエピスタシスがないことの 両条件がともに成り立つ場合である. ここで以下のように分離遺伝子座 i の相加効果 aiおよび優性効果 diの全分離遺伝子座にわた る 2 乗和をそれぞれ A, D とおくと, A = k X i=1 a2i (19a) D = k X i=1 d2i (19b) F2個体間の表現型分散 VP[F2]は, VP[F2] = 1 2A + 1 4D + E (20) となる.E は個体間の環境分散である.A を「相加分散」,D を「優性分散」とよぶことが多い. 同様にして F3の分散,P1への戻し交配世代(BC1)の分散と P2への戻し交配世代(BC2)の分散 の和はつぎのとおりとなる. VP[F3] = (3/4)A + (3/16)D + E (21) VP[BC1] + VP[BC2] = (1/2)A + (1/2)D + 2E (22) また F2個体別 F3系統平均の分散,F2 個体別 F3系統内分散の平均,F2個体とその次代系統 平均との共分散なども求められる.純系の親 P1, P2や F1のように全個体が同じ遺伝子型をもつ 非分離集団では VG= 0, VP= Eとなるので,非分離集団の表現型分散を環境分散の推定に用い ることができる. これらの分散,共分散はどれも A, D および E の関数となる.そこで非分離世代も含めて 3 種 以上の分散,共分散の観測値があれば,A と D を推定できる. なお,ある分離世代の表現型分散 VP が A, D, E の関数として, VP = c1A + c2D + E (23) と表されるとき(c1, c2は係数,たとえば F2では c1= 1/2, c2= 1/4), h2B= (c1A + c2D)/(c1A + c2D + E) (24) を「広義の遺伝率」, h2N= c1A/(c1A + c2D + E) (25) を「狭義の遺伝率」とよぶ.前者は表現型分散中の遺伝分散の割合,後者は表現型分散中の固定 可能な遺伝効果すなわち相加効果に基づく分散の割合である.自殖性植物では狭義の遺伝率が高 い形質では選抜効果が高いといえる.広義の遺伝率が低い形質は,環境効果が大きいので,選抜 は個体単位ではなく系統平均にもとづいておこなうことが勧められる.詳細は鵜飼(2002)を参照 されたい.
統計遺伝モデルには,ホモ接合体基準モデルのほかに「要因配置モデル」がある(Anderson and Kempthorne 1954).このモデルでは,統計学の実験計画法における要因配置に準じて遺伝効果が 定義され,エピスタシスが存在する場合でも遺伝分散・共分散を一般的な形で簡潔に表現できる (鵜飼 1972).しかしモデルとして後発であるため残念ながら普及が進んでいない. 3. 古典的統計遺伝学の発展と停滞 3.1 集団遺伝学と統計遺伝学 生物測定学の研究の中からメンデリズムに基づいて進化を理解したいとする大きな学的流れと して集団遺伝学が生まれた.生物集団の遺伝学的解明に数学や統計学を応用する点では,集団遺 伝学も統計遺伝学も同じであるが,両者はその目的や方法論が大きく異なる.集団遺伝学は記述 的な分野として,生物進化過程を説明できる数理モデルを構築し,それに基づいて推論を行う. そこでは自然の生物集団において変異が保有される機構自体の探求に焦点があてられ,無作為交 配下あるいは選択,移住,突然変異などの影響下での遺伝子頻度および遺伝子型頻度の変化がお もな研究対象となる. いっぽう統計遺伝学は解析的で,実験集団とくに育種対象となる生物集団において,量的形質 の表現型値を観察データとして,形質に関与する遺伝子座の遺伝効果を推定することをおもな目 的とする.量的形質の変異を遺伝部分と環境部分に分割し,遺伝部分をさらに相加,優性,エピ スタシスによる部分にわけて推定することが重要である.また集団が保有する変異を正確に捉え, これにより選抜効果やヘテロシスなど作物や家畜の改良上重要な課題の解明に役立たせる.統計 遺伝学では遺伝子頻度や遺伝子型頻度の世代に伴う変化は解析対象とならない.とくに植物では それらの頻度は実験的に制御できる場合が多い. 近親交配の影響や選抜に伴なう集団の遺伝構造の変化など,集団遺伝学と統計遺伝子学とで共 通の課題も少なくないが,集団遺伝学が育種に応用される場面は多くない. 3.2 マザーと量的形質遺伝のポリジーン説 フィッシャーは,上述のとおり 1918 年および 1932 年にそれぞれ集団遺伝学と統計遺伝学の基 礎となった遺伝モデルを発表した.しかし,彼が生涯に発表した 294 もの論文中で量的形質の理 論を主題にしたものはこの 2 報以外にはない.統計遺伝学はフィッシャーのモデルを土台として, マザーをはじめ他の多くの研究者らにより理論の拡張と応用化への研究が進められ,とくに育種 における選抜のための理論的基礎を提供した. マザーは 1949 年に Biometrical Genetics を著わした.そこではフィッシャーのモデルにもとづ いて,2 純系間交配由来の雑種集団における量的形質の解析方法が詳しく示された.この本では じめて環境効果が明確にモデルに組み込まれた.17 種類の分散・共分散が相加分散,優性分散お よび環境分散の関数として記述され,それらのパラメータの推定法が提示された.ただしフィッ シャーがとりあげた三次統計量の歪みは重要視していない.この本は,量的形質の遺伝解析に携 わる研究者のバイブルとなった. 彼はこの書の中で,ニルソン・エーレが発見した同義因子説を念頭に量的形質に関与する多因 子系を polygenic system(ポリジーン系)となづけた.ポリジーン系は,(1)多数の遺伝子がひと
つの系として連続変異を示す量的形質に関与している,(2)それらの多数の遺伝子はたがいに類 似した効果をもち,たがいに補いあう,つまり同義的である,(3)個々の遺伝子の効果は非遺伝 的変異(環境変異)にくらべて小さいか,少なくとも変異全体にくらべて小さい,などの特性をも つと定義された.
マザーの書物のほかにも,量的形質の遺伝の入門書がいくつも出版された.動物の遺伝育種では米 国アイオワ州立大学のラッシュ(Jay L. Lush)による Animal Breeding Plans(動物育種計画)(1937), 理論面では同大学のケンプソーン(Oscar Kempthorne)による Introduction to Genetic Statistics (遺伝統計学入門)(1957),英国エジンバラ大学の動物遺伝学研究所のファルコナー(Douglas Scott Falconer)による Introduction to Quantitative Genetics(量的遺伝学入門)(1961)などが広く読ま れた. また植物の遺伝育種では Hayman (1954a,b) による複数品種の同時遺伝解析のための「ダイアレ ル分析」,Griffing (1956) によるトウモロコシなど他殖性植物の「組合せ能力」の検定法,Finlay と Wilkinson (1963) による「遺伝子型×環境交互作用」の解析など,さまざまな方面で量的形質 の理論や育種的応用の開発が行われた.1950 60 年代は古典的統計遺伝学の黄金時代であった. 3.3 統計遺伝学の育種的適用の停滞 1930年代前半から約 50 年間における量的形質の解析理論の研究は,基本的にはフィッシャーの 提示した手法の枠内で発展してきたといえる.その間動物育種では統計遺伝学の育種への応用が進 展したが,植物育種ではそうでなかった.前者では,個体の表現型値のデータや家系記録が綿密 にとられ世代をこえて保存されるので,統計遺伝学理論の育種への適用がそのまま可能であった. 解析に必要な計算の労力もコンピュータの普及につれて解消した.しかし,後者では,雑種集団 で扱う個体数が著しく大きいことと,量的形質の計測に適した成育時期が短いことなどから,選 抜したい集団について 1 個体ずつ量的形質を測ることは労力上無理な場合が多かった.1970 年代 には,ダイアレル解析や遺伝子型×環境交互作用の解析は盛んにおこなわれたが,遺伝パラメー タ推定や選抜に関する理論とその育種的利用に関しては,世界的に研究が停滞気味であった. 4. DNA マーカー利用連鎖地図と QTL 解析 4.1 古典的統計遺伝学の弱点 古典的統計遺伝学では,交配子孫の各世代で得られる量的形質の表現型値(観察値)の平均や分 散・共分散にもとづいて,分離遺伝子座全体についての相加効果,優性効果,エピスタシスなど の和や 2 乗和が推定される.これらが分かると,分離世代における量的形質の変異中の遺伝する 割合(遺伝率),ある閾値以上の表現型を示す個体を選抜したときに遺伝子型が改良される割合(選 抜効率),関与遺伝子座全体での優性効果の相加効果に対する比(平均優性度)などの情報が得ら れる. しかしその方法では,量的形質に関与する個々の遺伝子座についての相加効果や優性効果は推 定できない.また量的形質の遺伝子座について,ゲノム全体でいくつが関与しているのか,個々 の遺伝子座は染色体上のどこに位置するのかなど,質的形質の遺伝学では最初に問われるべきこ とも,まったくわからない.このようなことを解明するには,量的形質の表現型値だけを情報と
する解析法では原理的に無理であった. 4.2 量的形質と質的形質の連鎖 量的形質に関与する遺伝子座の近傍に質的形質の遺伝子座があれば,それとの遺伝的連鎖を利 用して量的形質の遺伝子座の染色体上位置と遺伝効果を推定できる.連鎖とは,AABB の遺伝子 型をもつ母親と aabb の父親とを交配した F1の減数分裂後に得られる配偶子(植物なら卵と花粉) 中で,両親のもつ遺伝子組み合わせと同じ型の AB と ab が,組換え型の Ab と aB より多くなる 現象をいう.配偶子中の組換え型の頻度を「組換え価」といい,0 から 0.5 の範囲の値をとる.連 鎖は遺伝子座 A と B が染色体上で近接している場合に起こる.2 遺伝子座間が近いほど一般に組 換え価が小さくなる.ただし組換え価には相加性がないため,連鎖地図は最終的に組換え価では なく「地図距離」で表現される.地図距離は減数分裂における染色体部分の乗換えの頻度として 定義され,組換え価の関数として求められる.ただし地図距離は DNA 塩基配列長などの物理的 距離には必ずしも比例しない. 量的形質に関連を示す質的形質の例は,1920 年代からインゲンマメ,エンドウ,オオムギ,家 畜など多くの生物種で見出されていた.しかし,たとえばモチ稲とウルチ稲では収量が異なるよ うに,質的形質の遺伝子はそれ自体が量的形質の表現型に影響を与えてしまうものが多く,量的 形質の解析は進まなかった. 1960年代になりアイソザイム(酵素活性が同じであるがアミノ酸配列が異なる酵素)が遺伝実験 に使われるようになると,アイソザイムと関連する遺伝子をマーカーとしてそれとの連鎖により 量的形質遺伝子座を位置づけようとする試みが始まった.アイソザイム型も遺伝法則に従って子 孫に伝わり,しかも量的形質の表現型にはほとんど影響しないことが大きな利点であった.ただ 分離世代で分離する数はたかだか数十で,連鎖解析に使うには不十分であった. 4.3 DNA マーカー連鎖地図と QTL 解析 微生物で進展した分子生物学的技術が 1980 年代後半になると動植物の実験の世界でも普及し, RFLP(制限酵素断片長多型)をはじめ,RAPD,AFLP,SSR など各種の「DNA マーカー」が利 用できるようになった.それを用いて同じ生物種でも個体間で DNA 塩基配列が異なり,「DNA 多型」が存在することが発見された.この DNA 多型が質的遺伝子と同様にメンデルの法則に従っ て遺伝する.DNA 多型は形質の表現型に影響しない.またきわめて多数の種類が開発されてい るので,数百のマーカーが同時に分離する雑種世代が容易に得られる.この利点を生かして,全 ゲノムの染色体領域にわたり,マーカーや遺伝子の相対的位置を示した「連鎖地図」を,小人数 の研究室でも短期間に作製できるようになった.連鎖地図の作成は,種々の生物で一気に進めら れた. DNAマーカー利用の詳細な連鎖地図が作成されるようになると,それを利用した量的形質の解 析手法として,1989 年に米国の Lander と Botstein により区間マッピング法(Interval Mapping) が提案された.また Quantitative Trait Locus(量的形質遺伝子座)は略して QTL,その解析は 「QTL 解析」とよばれるようになった.QTL 解析では,雑種世代での各個体の示す量的形質の表 現型値だけでなく,QTL 近傍の DNA マーカーの分離型も情報として用いられる.QTL 解析に よってはじめて,対象とする QTL の数,各 QTL の染色体上の位置,各 QTL の遺伝効果などが
かなり正確に推定可能となった.これにより,質的形質と量的形質の間にあった遺伝解析手法の 溝が埋まり,両者がほぼ同じ土俵で扱えるようになった.量的形質の解析は,ふたたび遺伝学お よび育種学で大きな課題として復活した.QTL 解析では従来の統計遺伝学的解析よりもはるかに 計算労力がかかるが,コンピュータの普及と専用プログラムの開発がそれを支え,QTL 解析は 種々の生物集団の解析に広く普及した. 4.4 QTL 解析 以下に区間マッピング法にもとづいて QTL 解析を説明する.詳細は鵜飼(2000)を参照された い.解析対象の世代は 2 純系間交配の F2とする.ただし QTL 解析に先立ち,全ゲノムにわたっ て詳細な連鎖地図が作成済みとする.いま QTL 中のある 1 個の遺伝子座 Q が,2 つの隣接マー カー座 A, B で挟まれた区間内のある点に位置するとする.A, Q, B の 3 座における母親と父親の 遺伝子型をそれぞれ AAQQBB, aaqqbb と表す.ただし対立遺伝子の大文字と小文字は,それぞ れが母親および父親に由来することを示す.F1の遺伝子型は AQB/aqb となる.ここで記号 / は AQBが一方の,aqb が他方の相同染色体に乗っていることを示す.A–Q 座間および Q–B 座間の 組換価をそれぞれ r1, r2とする.A–B 座間の組換え価(r1+2と表す)は推定可能なので,r1が決 まれば r2は r1の関数として求められる.
F2では,AABB, AABb, AAbb, AaBB, AaBb, Aabb, aaBB, aaBb, aabb の 9 種のマーカー遺 伝子型が分離する.これら遺伝子型に 1–9 の番号をつけて示す.また Q 座の遺伝子型に QQ, Qq, qqに 1–3 の番号をつける.F2においてマーカー遺伝子型が i 番目であるとき,Q 座の遺伝子型 が j となる条件つき確率 pijは表 1 に示されるとおり組換え価 r1, r2, r1+2の関数として表され る.Q 座の相加効果と優性効果をそれぞれ a, d で表すと,QQ, Qq, qq の遺伝子型値は,それぞれ 表1. 2 つの近接マーカー座の遺伝子型が i であるとき QTL 遺伝子型が Q1Q1, Q1Q2, Q2Q2で ある条件付き確率 pij(F2). i :マーカー遺伝子型 Q1Q1(pi1) Q1Q2(pi2) Q2Q2(pi3) 1 : A1A1B1B1 q21 2 q1q2 q22 2 : A1A1B1B2 q1q3 q1q4 + q2q3 q2q4 3 : A1A1B2B2 q23 2 q3q4 q24 4 : A1A2B1B1 q1q4 q1q3 + q2q4 q2q3 5 : A1A2B1B2 z1q1q2 + z2q3q4 z1(q12 + q22) + z2(q23 + q42) z1q1q2 + z2q3q4 6 : A1A2B2B2 q2q3 q1q3 + q2q4 q1q4 7 : A2A2B1B1 q24 2 q3q4 q23 8 : A2A2B1B2 q2q4 q1q4 + q2q3 q1q3 9 : A2A2B2B2 q22 2 q1q2 q21 注) q1= (1− r1− r2+ r12)/(1− r1+2) q2= r12/(1− r1+2) q3= (r2− r12)/r1+2 (r12= 2r1+2· r1· r2) q4= (r1− r12)/r1+2 z1= (1− r1+2)2/{(1 − r1+)2+ r21+2} z2= 1− z1 pi1+ pi2+ pi3= 1 (i = 1, 2, . . . , 9)
u + a, u + d, u− a となる.u は定数である.表現型値はこの遺伝子型値に残差 e が加わったもの となる.残差 e は平均 0,分散 σ2の正規分布に従うとする.QQ, Qq, qq である個体が表現型値 y を示す確率密度は, QQ : φ1=√1 2πe −(y−u−a)22σ2 (26a) Qq : φ2=√1 2πe −(y−u−d)22σ2 (26b) qq : φ3=√1 2πe −(y−u+a)22σ2 (26c) となる.マーカー遺伝子型が i であるとき,Q 座の遺伝子型がたとえば 1(QQ)で,表現型値が y である確率は pi1ϕ1に比例する.ゆえにある個体についてマーカー遺伝子型が i で,量的形質の表 現型値が y(連続値)であるというデータがえられたとき,その個体の Q 座の遺伝子型が QQ, Qq, qq である確率 z1, z2, z3は次式で与えられる(z1+ z2+ z3= 1). QQ : z1= pi1ϕ1/(pi1ϕ1+ pi2ϕ2+ pi3ϕ3) (27a) Qq : z2= pi2ϕ2/(pi1ϕ1+ pi2ϕ2+ pi3ϕ3) (27b) qq : z3= pi3ϕ3/(pi1ϕ1+ pi2ϕ2+ pi3ϕ3) (27c) z1, z2, z3を用いると,尤度は L∝ 9 Y i=1 ni Y j=1 (pi1φij1)zij1(p i2φij2)zij2(p i3φij3)zij3 (28) となる.ここでたとえば zij1 は,マーカー遺伝子型が i 番目のタイプである個体群の j 番目
(j = 1, . . . , ni)の個体が,Q 座において遺伝子型 QQ をもつ頻度を示す.pi1φij1, pi2φij2, pi3φij3は
それぞれ i 番目の遺伝子型をもつ j 番目の個体における QTL 遺伝子型 Q1Q1, Q1Q2, Q2Q2の生 起確率に比例する.ただし,式 (28) は実際には欠測値である Q 座における 3 種の遺伝子型の分 離数が観察できたと仮定したときの尤度である.欠測値であることを考慮した不完全データの尤 度は L∝ 9 Y i=1 ni Y j=1
(pi1φij1+ pi2φij2+ pi3φij3) (29)
と表せる. QTL解析で推定すべき遺伝パラメータは,定数 u,相加効果 a,優性効果 d,残差分散 σ2の 4 つである.u は遺伝情報としては重要でない.QTL が 1 個の場合には残差分散は環境分散に等し い.QTL が複数の場合は,残差分散は環境分散と解析対象外の QTL の遺伝的分離による分散と の和となる.残差分散の大小は QTL の遺伝効果や位置の推定精度に影響する. 上記の尤度 L またはその対数(対数尤度)を最大にするようなパラメータのセットをもとめるの が,最尤法の原理である.推定値 ˆu, ˆa, ˆd, ˆσ2が得られたとき,その値を用いて対数尤度 log L1を求 める.これと遺伝効果がまったくない場合を帰無仮説として,H0: ˆu = u0, ˆa = 0, ˆd = 0, ˆσ2= σ02 とおいたときの対数尤度 log L0を求める.これより対数を常用対数に変換して
図 3. 区間マッピング法による QTL 解析における LOD 曲線. 68cM(センチモルガン)の長さの染色体部分に 17 個(A–Q)のマー カーがある場合.LOD の最大値は 33cM 付近に認められる.
LOD = log10L− log10L0 (30) を求める.一連の計算には EM アルゴリスムという方法が使われる. QTLの位置を染色体(連鎖群)の端からある一定の地図距離幅(たとえば 1 センチモルガン(cM)) ずつ移動させながらこのような計算を行い,各点での LOD を求める.LOD の極大値がある閾値 を超えるとき,極大値の点を QTL の位置と推定する(図 3).また推定された QTL 位置における パラメータの値を,その QTL についてのパラメータの推定値とする.現在では QTL の推定位置 にもとづいて,DNA から QTL に関与する遺伝子を実際に単離できるようになっている. 5. お わ り に 生物学の諸現象が DNA ないし分子レベルで解明されるようになった現在,生物学およびその 応用分野で産出されるデータはじつに膨大である.それらのデータが含む情報を適格に取り出し 解析を進めるためには量的形質の解析理論を含めて広義の統計遺伝学の発展が必要である.日本 ではこの分野の研究者の組織的な育成機関がきわめて少ないため研究の継続と進展が阻まれてお り,早急な対処が望まれる. 参考文献
Anderson, V.L. and Kempthorne, O. (1954). A model for the study of quantitative inheritance. Genetics, 39: 883–898.
Finlay, K.W. and Wilkinson, G.N. (1963). The analysis of adaptation in a plant-breeding pro-gramme. Australian Journal of Agricultural Research, 14: 742–754.
Fisher, R.A. (1918). The correlation between relatives on the supposition of Mendelian inheri-tance. Transactions of the Royal Society of Edinburgh: Earth Sciences, 52: 399–433. Fisher, R.A, Immer, F.R. and Tedin, O. (1932). The genetical interpretation of statistics of the
third degree in the study of quantitative inheritance. Genetics, 17: 107–124.
Griffing, B. (1956). Concept of general and specific combining ability in relation to diallel crossing systems. Australian Journal of Biological Sciences, 9: 463–493.
Hayman, B.I. (1954a). The analysis of variance of diallel tables. Biometrics, 10: 235–244. Hayman, B.I. (1954b). The theory and analysis of diallel crosses. Genetics, 39: 789–809. Kempthorne, O. (1957). Introduction to Genetic Statistics. Iowa State Univ. Press. Iowa.
木村資生 (1960). 集団遺伝学概論. 培風館.
Lander, E.S. and Botstein, D. (1989). Mapping Mendelian factors underlying quantitative traits using RFLP linkage maps. Genetics, 121: 185–199.
Lush, J.L. (1937). (1st), (1943) (2nd). Animal Breeding Plans. Iowa State Univ. Press. Ames, Iowa.
鵜飼保雄 (1972). エピスタシスが存在する場合の 2 純系由来の集団における分散・共分散の一般 的記述方法. 育種学雑誌, 22: 147–152.
鵜飼保雄 (2000). ゲノムレベルの遺伝解析. 東京大学出版会. 鵜飼保雄 (2002). 量的形質の遺伝解析. 医学出版.