修士論文
型 動 駆 タ ン デ
アプリケーション層マルチキャス トの 配信手法の高速化 について
/ / 一 一 ヽ
■ヽ /
■‑ 111 ‑‑1‑ヽ
r ヽ+・ く ′‑ /
\、 d F
亀 z Z t ,? i,
・、
.
‑ 、t 、宣 ゝ一岬 一 一 P■'' L .I二 十 ̲
平成 21 年度修 了 三重大学大学院 工学研究科 博士前期課程 情報工学専攻
越賀 雅士
目次
は じめに
第 1 章 Pe er ‑ t o‑ Pe er ( P2P) 1 . 1 P2 P 型 .
1 . 2 クライアン ト ・サーバ型
1 . 3 P2 P 型の分類 .
1 . 3. 1 ハイブ リッ ド P2 P‥ .‥ ...‥ ... . ... ... ..‥ . 1 . 3. 2 ピュア P2 P . . . ‥ . ...‥ . . .. . 1 . 3. 3 スーパー ノー ド型ハイブ リッ ト P2 P . ... ‥ ..‥ . ... ..‥ .
第 2 章 マルチキャス ト
2. 1 概要 ‥ . ..‥ . . ... ‥ ‥ ‥
2. 2 I P マルチキ ャス ト . . . . ‥ . . . . ...‥
2. 3 ALM . ... ... . . ... .
第 3章 ALM の転送方式
3. 1 ツ リー型 ALM . . .‥ ‥ .. . ... . .‥
3. 2 メッシュ型 ALM . . . .‥ ..‥ . .‥ ‥ . . .‥ . 3. 3 デー タ駆動型 ALM . . ‥ .‥ ‥ . .‥ . . .‥ . .
第 4 章 関連研究
4 . 1 デー タ駆動型 ALM の関連研究
4. 2 CooI St r e ami ng . 4. 3 Cha i ns a w .. . . .
第 5 章 提案手法 5. 1 提案手法の概要 5. 2 BM 送信 タイ ミング
2 2 3 3 4 4 5
7 7 7 8
1 0 1 0 E F l 1 2
1 4
1 4
1 4
1 6
5. 3 要求セグメン ト解析
第 6 章 評価実験 6. 1 実験の概要 . 6. 2 予備実験 .
6. 2. 1 実験 内容
6. 2. 2 実験結果 . . 6. 2. 3 考察 . 6. 3 シミュレーシ ョン実験
6. 3. 1 実験 内容 ‥ . . 6. 3. 2 実験結果 ( 転送データ 5 MB) 6. 3. 3 実験結果 ( 転送デー タ 1 0 0 MB) 6. 4 実機実験 . .. ..
6. 4. 1 実験 内容 . .. . 6. 4. 2 実験結果
6. 5 考察
おわリに
謝辞
参考文献
● ● l l
2 0
22 2 2 2 3 2 3 2 4 2 5 2 6 2 6 2 7 3 0 3 3 3 3 3 4 3 7
38
39
40
は じめに
近年では,プロセ ッサの高速化,メモ リの大容量化,ネ ッ トワー クの広帯域化を背景 として,多 くのユーザが高画質の映像をインターネ ッ トを通 して視聴できるようになった. しか し,従来のク ライアン ト/サーバ型では,サーバへの負荷が集中することにな り,大規模配信を行 うには大規模 サーバを必要 としていた. これに対 して,近年 Pe e r ‑ t o‑ Pe e r ( P2 P) 型での映像配信が注 目されて いる. この映像配信の手法をアプリケー シ ョン層マルチキ ャス ト ( Appl i c a t i onLa ye rMul t i c as t , 以下 ALM) とい う.
マルチキ ャス トの手法 として一般的に 「 I Pマルチキャス ト」 と 「 ALM」の 2 種類ある.I Pマル チキ ャス トは,デー タ複製 の為マルチキ ャス トをするノー ドの経路上のルー タ全てがマルチキ ャ ス ト対応のルー タを用いる必要があるのでコス トの面の問題 で普及は難 しい.ALM は I Pマルチ キ ャス トで通常 I P層で行われているマルチキャス トの技術を,アプリケーシ ョン層で実現 してい る手法である.デー タは ALM の各ノー ドで複製 され,ネ ッ トワー ク上の問ノー ドでユニキャス ト を用いてデータ転送が行われる.ALM ではマルチキャス トを行 うのに特別な装置を必要 としない ので,ALM によるマルチキャス トが主流 となってきている.従来,ALM ネ ッ トワー クの構築及 びデー タ転送方法 としてツリー型 とメッシュ型の 2 種類が考えられていたが,近年ではデータ駆動 型 とい う新たなデータ転送方法の研究が盛んに行われている.
ツ リー型 ALM はその名の通 りデー タ配信 ノー ドを木の根 として節ノー ド ・葉ノー ドへ とデータ を転送 してい く手法である.メッシュ型 ALM ではツリー型で持 っている親子の関係がな く,隣接 するノー ドか らデータを送受信することでネ ッ トワー ク全体にデータを広めてい く手法である. こ れに対 して,デー タ駆動型 ALM は トポロジはメッシュ型 と同 じであるが,データを一方的に送 る pus h 型の転送ではな くデータを要求する pul l型のデータ転送方式を とっている手法である.
そ こで本研究では,ALM の転送方式の 1 つデー タ駆動型に注 目し,データ駆動型 ALM で制御 パケ ッ ト量を抑 えつつ,ノー ドの上 り帯域を効率良 く使用することによって遅延を少な くする手法 を提案する.
本論文では第 1 章において,P2Pについて述べる.第 2 章において,マルチキ ャス トについて 述べる.第 3 章において,ALM の転送方式について述べ る.第 4 章において,関連研究について 述べ る.第 5 章において,データ駆動型 ALM の提案方式について述べる.第 6 章において,提案 する手法の有効性を示す実験 について述べる.
1
第 1 章
Pe e r ‑ t o ‑ Pe e r ( P2P)
本章では, P2 P のネッ トワー ク トポロジについて述べる. 1 . 1 において, P2 P 型について述べ る. 1 . 2 において,クライアン ト/サーバ型について述べる. 1 . 3 において, P2 P 型の分類について 述べる.
1 . 1 P2P 型
P2 P とは Pe e r ‑ t o ‑ Pe e r の略であ り, Pe e r には 「 対等」 と言 う意味がある.つま り,「 対等のも の同士が対等の立場で相互にや りとりを行 う方式」である・クライアン ト/サーバ型ではアクセス が非常に多 くなると,サーバがパンクすることがあるのに対 して, P2 P 型では元 となるデータを一 極集中 していないのでアクセス数が多 くなっても問題ない. P2 P 型の通信例を図 1 に示す.
i L 軸
観 ● 歯
‑3 iノ ー . ■ ■ ■ 一 一 I 慧 一 . 一 毒毒 一 J
】
一 一 ■ T ‑ 、 ■ ■● 正 n ̀ 一 ‑ L ! 一 . コ 一 一 忘j J 一 、 一 一 r ‑̀
ど ‑ . ・ . .
図 1 P2 P 型
長所 としては,処理が分散できるため,個々のコンピューターの負担が大 き くな りに くい.ま た,個々で通信を行 うため比較的秘密裏に処理を行えるため隠匿性が高い とい う点があげ られる.
また,短所 として,処理が分散するために管理や監視が しにくい とい う点があげられる.
三 重 大 学 大 学 院 工 学 研 究 科
1 . 2 クライアン ト・サーバ型
P2 P 型に対 して従来か らの通信形態 としてクライアン ト・サーバ型がある.クライアン ト・サー バ型 とは,各 コンピュータの役割がサーバ とクライアン トに分かれているコンピュータネットワー クのソフ トウェアモデルである.サーバはデータの配信,蓄積,検索な どのサー ビスを提供する役 割を持 ってい る.一方,クライアン トはサーバに対 してサー ビスを要求 し,そのサー ビスを利用 する役割である. このようにコンピュータの役割は固定され,変わることはない.クライアン ト ・ サーバ型の様子を図 2 に示す.
電信サーバ
図 2 クライアン ト・サーバ型
長所 としては,クライアン トの処理が少な くてすむとい う点,システムの管理及び監視が行いや すい とい う点があげられる.また,短所 として,サーバーの処理が非常に重 くなるため,高価なコ ンピュータをそろえる為のコス トが必要 とい う点,サーバーに処理が集中するため,回線帯域を圧 迫 しやす くなるので大容量の回線が必要 とい う点などがあげられる.
1. 3 P2P 型の分業 頁
P2 P 型の構築方法を大別するとハイブリッ ト P2 P ,ピュア P2 P そ してスーパーノー ド型ハイブ リット P2 P の 3 種類ある.
三 重 大 学 大 学 院 工 学 研 究 科
1. 3. 1 ハ イブリッ ド P2P
ハイブリッ ド P2P は,クライアン ト・サーバ型 と P2 P 型をハイブリッ ド ( 複合) した方式であ る.データの所在情報は固定的なサーバーに管理させ,各ノー ドはあらか じめ知っているサーバー に問い合わせ ることでデータ場所を知 る.データの探索を行 うサーバーのことを 「 インデックス サーバー」 とい う.インデックスサーバーはデータの所在情報のみを扱 う.データのや り取 りは ノー ド同士で行 うとい う点がクライアン ト・サーバ型 との違いである.ハイブリッ ド P2P の様子 を図 3 に示す.
インデックスサーバ
図 3 ハイブ リッ ド P2 P
長所 としては,シンプルであ りシステムを管理 ・制御 しやすい とい う点があげられる.また,短 所 としては,所在情報だけではあるがシステムに中心を持つため,スケーラビリティや耐障害性が 十分に発揮されない とい う点があげられる.
1. 3. 2 ピュア P2P
ピュア P2P は,ハイブリッ ド P2 P とは異な りデータの所在情報を持つインデ ックスサーバー す ら持たず,純粋にノー ド同士のみでシステムを形成する.探索方法 としてはノー ド同士が助け合 う形で実現 している.通常 ピュア P2 P では,各ノー ドは近接のノー ドと定常的な接続をメッシュ 状に張 っている.探索には 「 フラッディング」 と 「 DHT( Di s t r i bu t e dHa s hTa bl e ,分散ハ ッシュ テーブル ) 」 な どがある.フラッディングとは,探索 クエ リ ( 探索要求のこと)を隣接ノー ドへバケ ツリレー式に伝搬 し,見つかればその結果を再び伝搬することでデータの所在を知る.また DHT
とは,ノー ドとデータにそれぞれ単一の I D が割 り当てられる.ノー ドなら I P ア ドレス, デ ータ
三 電 大 学 大 学 院 工 学 研 究 科
一 一 一 一 一 一 J
… … データ所在情報の探索 壬 ・ 一 一 一 一 ‑ 一 一 一 一 一 う データ転送線
図 5 スーパー ノー ド型ハイブ リッ ト P2 P
長所 としては,ハイブリッド P2 P とピュア P2 P の両方の良さを持つ とい う点があげられる.ま た,短所 としては,探索データの分散化などの実装が難 しくなる.ノー ド数がある程度増えるまで 安定 しない可能性があるとい う点があげられる.
三 重 大 学 人 学 院 工 学 研 究 科
第 2 章
マルチキャス ト
本章では,マルチキャス トの概要について述べる. 2. 1 において,マルチキャス トの概要について 述べる. 2. 2 において ,I P マルチキャス トについて述べる. 2 . 3 において ,ALM について述べる.
2. 1 概要
マルチキャス トとは,ネットワーク内で複数の相手を指定 して同じデータを送信するとい う通信 である.これに対 してネ ッ トワー ク内の全員へ同 じデータを送信することを 「 ブロー ドキャス ト」
と言い,特定の相手のみにデータを送信することを 「 ユニキャス ト」 とい う.マルチキャス トの送 信者はどこに居ても良 く,受信者は複数存在するとい う状況が想定されている.マルチキャス ト受 信者は,「 マルチキャス トグループ」と呼ばれるグループに 「 j oi n」することにより,データを受け 取れるようになる.
マルチキャス トには一般に 2 つの手法がある. 1 つは I P マルチキャス トといい, OS I 参照モデ ルにおけるネ ッ トワー ク層でマルチキャス トを行 う手法である.詳 しくは 2. 2 において説明をす る.もう 1 つは ALM と言い,ネットワーク層ではな くアプリケーション層でマルチキャス トを行
う手法である.詳 しくは 2 . 3 において説明をする.
2. 2 1 P マルチキャス ト
I P マルチキャス トとは ,OS I 参照モデルにおけるネッ トワー ク層を用いてマルチキャス トを行 う手法である.最小限のネ ッ トワー ク帯域幅を使用 して,送信元にも受信者にも負担をかけずに, アプ リケーシ ョンのソース トラフィックを複数の受信者に配信する.マルチキャス トは,グループ とい う概念を基盤 とする.マルチキャス トグループとは,特定のデータス トリームを受信 したい と い う意向を表明 した任意の受信者 グループを表す. このグループには物理的または地理的な制約 がな く,イ ンターネッ トまたはプライベー トネ ッ トワー ク上の どの場所にホス トが存在 しても良 い. I P マルチキャス トを行 うには,マルチキャス トア ドレスと呼ばれる特殊な I P ア ドレス ( クラ ス D のア ドレス, 2 2 4. 0. 0. 0 ‑2 3 9 . 2 5 5. 2 5 5 . 2 5 5 ) を用いてデータが送信される.各マルチキャス ト グループ宛に送信されたパケットは,マルチキャス トルーティングプロ トコルにより設定された送 信ノー ドを根,中継のルータを節,多数の受信ノー ドを葉 とするツリー上を伝送され,各受信ノー ドに届 く.中継のルータで,必要に応 じてマルチキャス トパケッ トの複製が行われる.また,マル
7
チキャス トグループに属する受信ノー ドの管理情報を,送信ノー ドではな くネッ トワー ク上のルー タが行 うことで,送信ノー ドの管理負荷の集中を回避 している.
I P マルチキャス トの様子を図 6 に示す.
㍗ ∴ 一 、 、 ‑ ヾ 配信ノード
図 6 I P マルチキャス ト
I P マルチキャス トの長所 として, 1 つのデー タをルータな どで複製をすることで複数の相手へ 送信することによ り,容量の大 きなデータでも回線を圧迫することな く配信することができるとい
う点があげられる.
また,短所 として,ルーターでデータを複製するにはマルチキャス ト対応のルータでない とでき ない とい う点があげ られる.よって,送信先までの経路上のルータ全てがマルチキャス ト対応ルー タである必要がある.
2. 3 ALM
ALM とは,その名の通 りネ ッ トワー ク層 ではな くアプ リケーシ ョン層でマルチキ ャス トを行 う手法である. I P マルチキャス トではルー タが行 っていたマルチキャス トに関する機能,即ちパ ケ ッ トの複製やマルチキャス トルーティング,グループ管理などをアプリケーシ ョン層に組み込む ことで実現 している.ネッ トワー ク層ではユニキャス トのみをサポー トする.また,ALM は P2 P
型で通信を行い,ノー ド間はデータをユニキャス トを用いてノー ド問を中継 して全てのノー ドへ送 信 される.実際のパケ ッ ト転送 にはルータが介在 しているが,論理的には送信ノー ドを根 として, 全受信ノー ドが節であ り葉 ともなる.各受信ノー ドで,マルチキャス トに関する機能を提供する必 要がある.
三 重 大 学 大 学 院 工 学 研 究 科
ALM の様子を図 7 に示す.
図 7 ALM
長所 として, I P マルチキャス トと異な りネッ トワー ク層ではユニキャス トしか行わないので経 路上にマルチキャス ト対応ルーターがな くても全てのノー ドにデータを送信できるとい う点があげ られる.また, P2 P によるデータ送信であるから強力なサーバを設置 しな くてよいので,サーバ ・ クライアン ト型の場合に比べ負荷を分散できるとい う点があげられる.
短所 として,今 までネッ トワーク層で対応 してきた機能をアプリケーション側で行 うので,開発 するアプリケーシ ョンが複雑になるとい う点があげられる.また、 I P マルチキャス トに比べて実 ネッ トワー クの トラフィックが増大するとい う点があげられる.
三
乗 大 学 大 学 院 工 学 研 究 科
第 3 章
ALM の転送方式
本章では,ALM の転送方式について述べ る. ALM のネ ッ トワー ク構築方法 として 3 種類の構 築法が考 え られる.ツ リー型 ALM とメッシュ型 ALM,そ してデー タ駆動型 ALM である.3. 1
において,ツリー型 ALM について述べる.3. 2において,メッシュ型 ALM について述べる.3. 3 において,データ駆動型 ALM について述べる.
3. 1 ツリー型 ALM
ツ リー型は,ノー ドがマルチキャス トのためのデータ配信木を作成 し,木構造 に沿 って根か ら 葉に向かってデー タを配信する.データがネッ トワー ク上を流れる前に流路が決 まっているため, デー タがあるノー ドに到達するまでの時間を低 く抑えやすい手法である.ツリー型 ALM を用いた ものに,CoopNe t[ 1 ] , Nar ada[ 2] などが挙げ られる.ALM では,各ノー ドが受信 したデータを他 のノー ドへ提供するので,受信用の下 り帯域幅だけでな く,送信用の上 り帯域幅が重要 となる.例 えば,500kbps のデータを受信 している場合,上 り帯域幅が 500kbps な ら1ノー ドに しかデータ 転送ができないが,5Mbps なら 1 0ノー ドに同時にデータ転送ができる.ツリー型 ALM では子を 持たないノー ド,つま り葉ノー ドの場合,他のノー ドへデータ転送を行わない.つま り,上 り帯域 幅を活用 していない状態のノー ドが存在する.木構造に置いては葉ノー ドは案外多 く,2 分木でも 半分強は葉ノー ドとなる. このことは,上 り帯域幅を重要視する ALM では大きな問題である.そ こで,木構造で この問題を解決する為に,複数の Sc r i be[ 3] と呼ばれる配信木を構築 し,それぞれ でデー タの一部を流す手法である Spl i t St r eam[ 4] が提案された.
ツリー型 ALM の様子を図 8に示す.
1 0
配信ノード
図 8 ツリー型 ALM
利点 として,データ配信経路の管理や操作,最適化を行いやすい点がある.欠点 として,ノー ド の離脱などが起 こると素早 く修復する必要があ り,もし修復に問題があればデータ配信に失敗する
ことがある.もし,故障,離脱 したノー ドがデータ配信木の根の近 くなら,その影響は大きなもの となる.
3. 2 メッシュ型 ALM
メッシュ型は,ツリー型が持つ親子関係の制約を無 くし,複数の隣接ノー ドへ 且oodi ng でデータ を転送する.データの受信が初めてであれば,受信 したノー ドを除いた全ての隣接ノー ドに対 して データを転送する.受信済みであれば転送 し射 、 方法を とっている. この f loodi ng での手法では, 無駄なデータ転送の量が多い とい う問題がある. 且oodi ng を用いてかつ無駄なデータ転送の量を抑 える手法 として, gos s i p プロ トコル [ 5 ] とい うものがある. gos s i p プロ トコルは文字通 り,噂が人 づてに伝わる様子に似た動作を行 う.基本的には,転送処理 として隣接ノー ドの中か ら転送先をラ ンダムに選んで転送する動作を繰 り返す.受信済みのノー ドへ一定回数転送を行 ったら,転送を止 める.
メッシュ型 ALM の様子を図 9 に示す.
ll
三 電 大 学 大 学 院 工 学 研 究 科
図 9 メッシュ型 ALM
利点 として,他の隣接ノー ドか らデータ受信ができるため,ノー ドの離脱に対 して素早 く修復す る必要がない.欠点 として,無駄なデータ転送が多いので,それを低減する工夫する必要がある.
既存手法 として Bu l l e t [ 6 ] な どが挙げられる・
3. 3 データ駆動型 ALM
ツ リー型 ・メッシュ型 ALM は基本的に pu s h 型のプロ トコルである.木構造では単一の親か らしかデータを受け取 らないので, pu l l 型の親への要求は無駄である. しか し,メッシュ型では 鮎 odi ngや gos s i pのように同一のデータが複数のノー ドか ら送信 される.この無駄を省 くために
pu l l 型 プロ トコルは有効 である.データ駆動型 とは,メッシュ型の トポロジを構成 し,デー タを 隣接 ノー ドへ一方的に送 るのではな く,隣接ノー ドか らの要求を受けて送信する pu l l 型の転送方 式である.隣接ノー ドへデータ要求するには,隣接ノー ドのデータ保持情報が必要 となるため,あ らか じめデータ保持情報を隣接ノー ドに知 らせてお く必要がある.一般にデータ保持情報では,転 送データを分割 し,セグメン ト毎に分けてシーケンス番号を付け,その番号や ビッ トマ ップで保持 データを表現する.
データ駆動型 ALM の様子を図 1 0 に示す.
1 2
三 重
大 学 大 学 院 工 学 研 究 科
図 1 0 デー タ駆動型 ALM
利点 として,メッシュ型で起 こる無駄なデータ転送を無 くすことができる.また,ノー ドの頻繁 な出入 りに強い性質を持っている.欠点 として,要求を受けてから,データを送信するのでツリー 型やメッシュ型に比べると遅延が大きくなる.また,データ保持情報などの制御パケッ トの通知頻 度でも遅延の大小は変わって くる.
1 3
三 重 大 学 大 学 院 工 学 研 究 科
第 4 章
関連研究
本章では,データ駆動型 ALM の関連研究について述べる. 4. 1 において,データ駆動型 ALM の 関連研究について述べる. 4. 2 において, CooI St r e a mi ng について述べる. 4. 3 において, Cha i ns a w について述べる.
4. 1 データ駆動型 ALM の関連研究
データ駆動型 ALM の関連研究 として, CooI St r e a mi ng や Cha i ns a w な ど [ 7 ] [ 8 ] [ 9 ] が挙げられ る. どちらの場合 もデータ転送方法 として,まず転送するデータをセグメン トと呼ばれる分割され たデータ片に分ける.その後,隣接ノー ド間でセグメン ト毎に送受信を行 う.各ノー ドのセグメン ト保持の有無については, Bi t Ma p( 以下 BM) と呼ばれるセグメン ト保持情報を定期的に送受信す ることで隣接ノー ドへ知 らせることになっている. BM は 0 と 1 で表されるビッ ト配列であ り, 0 で持 っていないセグメン ト, 1 で持 っているセグメン トを表 している.オ リジナルデー タを持つ データ配信ノー ド( ソースノー ド)の BM は全て 1 となる.
また,近年では DONLE[ 1 0 ] などが提案され,盛んにデータ駆動型 ALM が研究されている.
以下では本研究で比較実験を行 う CooI St r e a mi ng , Cha i ns a w のデータ転送方式 と問題点につい て述べる.
4. 2 CooI St r eaml ng
CooI St r e a mi ng ではス トリー ミングデータを隣接ノー ドに転送する際には,ス トリー ミングデー タを 1 0 00 ms e c 毎に分割 したセグメン トに分け,セグメン ト毎で隣接ノー ドとの送受信を行 う.各 ノー ドは自身の隣接ノー ドと一定時間毎に BM の交換を行 う.
CooI St r e a mi ng のデータ転送の様子を図 11 に示す.
1 4
隣接ノード 1
一定期 間 t x 抄I
ノー ド 隣 接ノード 2
図 1l CooI St r e ami ng のデー タ転送の様子
1.‑定時間毎に隣接ノー ドへ BM の送信を行 う.
● この動作は一定時間経過 しない限 りアルゴリズム内で再び実行 される事はない.
2. 隣接ノー ドか ら送 られて くる BM を解析 して,保持 していないセグメン トを持っているノー ドへセグメン トの要求を出す.もし無ければ要求を しない.
3. 隣接ノー ドか ら要求 したセグメン トを受信 したら, 自身の BM を新たに更新する.
4. もし自身が設定 した一定時間が過ぎていれば,隣接ノー ドへ BM の送信を行 う.
(2) 〜(4 )を繰 り返 し行 うことでデータ送受信を行 う.
この手法の問題点 として,BM の通知頻度が高い と制御パケット量が増大 して しまい帯域の無駄 使いを して しまうことが挙げらる.また,BM の通知頻度が低い と新たなセグメン トを取得 しても 隣接ノー ドへの通知が遅れて しまい,隣接ノー ドのセグメン ト取得の時間が遅 くなってしまうこと が挙げられる.
1 5
三 重 大 学 大 学 院 工 学 研 究 科
4. 3 Chai ns a w
Cha i ns a wでは転送データを隣接ノー ドに転送する際には,転送データを 1 6KB毎に分割 したセ グメン トに分け,セグメン ト毎に隣接ノー ドとの送受信を行 う.各ノー ドは新たなセグメン トを取 得 した時に,隣接ノー ドへ取得 したセグメン トの情報を知 らせるための制御パケッ トを送信する.
Chai ns a wのデータ転送の様子を図 1 2 に示す.
隣 接ノード 1 ノー ド 隣 接ノード2
〜
BM通 知 t W ー一 . 一 一 ′ ̲ L i . 」 ′ '
■ ■ ■ ▲ ー
セグメ̲ ?̲ ヒ軍 事 ̲ ̲ ̲ ̲ ̲ ̲ ̲ ー 1 ■ 一 ‑ セ グメ ン ト 送倍
小. . . . . . . . J i . . . . . . . . . . . . . . I . . . . . . . . . . . 1 ■
■ ■
」 ■
1 ■ ・ . . . . . ‑. . ‑ ‑ . . . ‑ . . ‑ ‑ . . ‑ . . ‑ ‑ . ト
「 ■ ■ 一 」 ■ ■
r
4‑‑‑‑. ‑‑ ‑ ‑ ‑ ‑ ‑ ‑ . . . . . . ‑ ‑ . . ‑
図 1 2 Cha i ns a w のデー タ転送の様子
1 サイクル 1 サイクル
1. 隣接ノー ドへ BM を送信する.
2. 隣接ノー ドの BM を解析 し,自分が持っていないセグメン トを探す.
3.もし自分が持 っていないセグメン トがあれば,隣接ノー ドへ要求を出す.もしなければ何 も 要求 しない.
4. 隣接ノー ドか ら要求 したセグメン トを受信する.
5. 隣接ノー ド全てに取得 したセグメン トの情報を送信する.
(2) 〜(5 )を繰 り返 し行 うことでデータ送受信を行 う.また,各ノー ドが保持 している隣接ノー 1 6
三 重 大 学 大 学 院 工 学 研 究 科
ドの BM は, ( 1 ) 〜( 5) の動作を実行 している間でも同時進行で更新 されてい くので,問題な く デー タ送受信が行える.
この手法の問題点 として,セグメン ト受信毎に制御パケットを全ての隣接ノー ドへ送信すること になるので,制御パケッ ト量が増大 して しまい帯域の無駄使いを して しまうことが挙げられる.
1 7
第 5 章
提案手法
本章では,本研究で提案するデータ駆動型 ALM の手法について述べる. 5. 1 において,提案手 法の概要について述べる. 5 . 2 において, BM 送信タイミングについて述べる. 5 . 3 において,要求 セグメン ト解析について述べる.
5. 1 提案手法の概要
CooI St r e a mi ng では一定時間毎に BM の送受信を行 うことによ り, BM 転送回数は一定数に抑 えることができるが,新たなセグメン トを取得 してもす ぐには隣接ノー ドへ通知されず,セグメン トの送受信が一定期間されない場合がある.つまり,上 り帯域の使用を うまく活用できていない問 題がある.また, Cha i ns a w のよ うに新 たなセグメン トを取得 した時に BM の送受信を行 う時で は、上 り帯域の使用効率は問題ないが, BM 送受信星が多 くなって しまい,通信処理の負担が大幅 に増えて しまう.
これ らの欠点を補 う為の手法 として,新たなデー タ転送方法 とセグメン ト要求解析方法を提案 する.
5. 2 BM 送信タイミング
提案手法 [ 1 1 日1 2 ] では, CooI St r e a mi ng や Cha i ns a w の欠点を補 う為に, BM の送信のタイミン グを新たに設定する.デー タ転送時における BM の送信を全ての隣接ノー ドへセグメン トを送信 し終えたときに行 うことで,各ノー ドの上 り帯域を効率良 く使用 し, BM の送信量を抑え,遅延を 少な くできると考えられる.
提案手法のデータ転送の様子を図 1 3 に示す.
1 8
隣 接ノード1
1 サイクル
ノー ド 隣 接ノード 2
8M通 知 1 ▼ ー i ‑ . ̲ . ■ ′ i
セグメント要 求 ー ■ ■ ー
I セグメント送信
4‑. . ‑‑‑. ‑‑‑‑‑. . . . . ‑暮 . t . ‑.
一 . ■
‑ ■
‑J . ‑ ‑ 1 . ‑‑ ‑ . ‑ ‑ ‑ ‑ ‑ ‑ . ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ‑ ー ・ ■ ‑. . ‑. . . . . . . ‑‑‑‑. 暮 . . t . . . . . ‑. . ●.
1 ■
̲ ‑ l
I ■ . . ‑■ . . . . i ‑. . . ‑. ‑. ‑‑. . . ‑‑. . . . . ト
図 1 3 提案手法のデー タ転送の様子
1.各ノー ドは全ての隣接ノー ドへ BM を送信する
2. 全ての隣接 ノー ドか ら BM を受信 したら解析 し,保持 していないセグメン トを隣接ノー ド に要求する
3. セグメン トを受信する隣接ノー ドか らの要求を受けたら,要求されたセグメン トを隣接ノー ドへ送信する
4. 隣接ノー ドか ら要求 したセグメン トを受信する全ての隣接ノー ドへセグメン トを送信 した ら,再び隣接ノー ドへ BM を送信する
後は ( 2) 〜(4 )を繰 り返 し行 うことでデータ送受信を行 う.
1 9
三 重 大 学 大 学 院 工 学 研 究 科
5. 3 要求セグメン ト解析
セグメン ト要求時に自身の BM と隣接ノー ド全ての BM を解析 し,なるべ く隣接ノー ドが所持 していないセグメン トを優先 して取得する.これによりネットワーク全体にファイルが拡がる効率 が良 くなると考えられる.
提案手法の要求セグメン ト解析の様子を図 1 4 に示す.
前半部 後半部 自分の解析
用 BM 通信相 手 の BM 他 の隣 接 ノ‑ ドの BMl
他 の隣 接 ノー ドの BM2
「 「 「「
柵 柵 柵 欄 柵
2 4 30 0 3 3 210 3
012 3 4 5 6 789
セグメント送信4 の場 合:
図 1 4 要求セグメン ト解析
図 1 4 の解析の流れを以下に載せる.
1.通信相手の BM から自分が所有 していないセグメン トを調べる 2. 前半部を優先 して取得するように重み付けを行 う
3. 他の隣接ノー ドの BM キャッシュを調べ,通信相手が所有 していて,他の隣接ノー ドが所有 していないセグメン トがあれば優先 して取得するように重み付けをする
4. 最終的に最 も重み付けの大きいセグメン トから順に前から一定数を要求する
20
三 重 大 学 大 学 院 工 学 研 究 科
(4 )で一定数を要求する理由は,セグメントは複数の隣接ノー ドか ら取得するので, 1 つの隣接 ノー ドか ら全てのセグメン トを取得 しても効率は良 くない.全ての隣接 ノー ドか ら効率良 くセグ メン トを取得するために,一定数セグメン トを取得 した ら,再びセグメン ト要求解析を行 うように なっている.
21
第 6 章
評価実験
本章では,提案手法の有効性を示すための実験 について述べる. 6. 1 において,実験の概要につ いて述べる. 6. 2 において,予備実験について述べる. 6. 3 において,シミュレーシ ョン実験につい て述べる.6. 4 において,実機実験について述べる.6. 5 において,実験の考察について述べる.
6. 1 実験の概要
本研究では提案手法の有効性を示す為にシミュレーシ ョンによる比較実験,及び実機による比較 実験を行 う.それぞれの実験では,提案手法, CooI St r e a mi ng , Cha i ns a w を実装 し実験を行 った.
また今 回提案す るシステムの評価値 として,上 り帯域使用率 ( Out boundBa ndwi dt hRa t eof Us e ,以下 OBRU) ,平均 BM 送信回数 ( Ave r a geNumbe rofBM T rans mi s s i on ,以下 ANBT) , 全体遅延時間 ( Tbt alDe l a yTi me ,以下 TDT) の 3 つを用いる.
OBRU とは,隣接ノー ドとの送受信時間に対する自身が持 っているセグメン トを隣接ノー ドへ 送信する時間の割合である .OBRU は,式 ( 1 ) で求めれる.
OBRU ‑ 学 × 1 00 (
1 )ここで,S は各セグメン トの送信時間 .T はデータ送受信時間である.
ANBT とは,ネ ッ トワー ク全体 での BM 送信 回数 を全 ノー ド数 で割 った平均 の数 であ る.
ANBT は,式 ( 2) で求め られる.
AⅣβr = ( 2 )
ここで, B は各ノー ドの BM 送信回数 .N は参加ノー ド数である.
TDT とは,データ転送開始時間か ら全ての参加ノー ドがデータを受信するまでの時間である.
シュミレーション実験で以上の評価値を求める.
22
6. 2 予備実験
6. 2. 1 実験内容
既存手法 との比較実験の前に予備実験 として, 5. 3 で提案 した要求セグメン ト解析の有効性を示 すために,5. 2 で提案 した手法に対 して要求セグメン ト解析の適応前,適応後での全体遅延時間の 比較をシミュレーシ ョンで行 った.実験内容については表 1 に示 している.
表 1 実験 内容
参加ノー ド数 1 00or1 000or5000or1 0000 転送データサイズ 5( MB)or1 00( MB)
隣接ノー ド数 3‑5
セグメン トサイズ 1 6( KB) BM 送信サイズ 1 28( bi t ) 上 り帯域幅 5( Mbps )
また,データ駆動型 ALM ネッ トワークの構築について以下で述べる.
1. ノー ドがネッ トワー クに参加 した時,参加ノー ドが 4 ノー ド以下ならソースノー ドに接続.
4ノー ド以上ならソースノー ド以外の一般ノー ドへ と接続する.
2. 自信が参加 してか ら一定期間過ぎたら,他の参加ノー ドの情報を得る為にソースノー ドへ と アクセスする.
3. ソースノー ドから得たリス トを参照 し,参加ノー ドからランダムに選んだノー ドを隣接ノー ドとする.もし選んだ参加ノー ドの隣接ノー ド数が最大で接続できなければ選んだノー ドを 除外 したリス トか ら再びランダムに選んで,隣接ノー ドを探す.
4. 全てのノー ドが参加 し,ネッ トワークを構築 した後に転送データを送信する.
上記の実験環境で全体遅延時間の比較実験を行 う.
23
6. 2. 2 実験結果
転送デー タサイズが 5 MB のシミュレーシ ョン実験の結果を以下 に示す.
実験結果 ( TDT) を図 1 5 と表 2 に示す.
0 0
1000 2000 3000 4000 5000 6000 7000 8000 9000 1 0000
n o d en u m
図 1 5 全体遅延
表 2 全体遅延
(
S)適応後 ( a 氏e r ) 適応前 ( be f or e ) 1 00 2 9 . 4 3 0. 9 1 0 0 0 3 6. 5 3 8. 4 5 0 0 0 41 . 7 4 3. 6
2 4
転送 デー タサイズが 1 0 0 MB のシミュレーシ ョン実験 の結果を以下 に示す.
実験結果 ( TDT) を図 1 6 と表 3 に示す.
0 0
1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
n o d e‖ u m
図 1 6 全体遅延
表 3 全体遅延
( S) 適応後 ( a托e r ) 適応前 ( be 玩) r e ) 1 0 0 5 8 0. 7 6 0 9. 6 1 0 00 71 5. 9 7 5 1 . 6 5 0 0 0 81 1 . 3 8 51 . 9
6. 2. 3 考察
転送 デー タサイズが 5 MB,1 0 0 MB の両方 とも要求セグメン ト解析適応前 に比べて適応後 の方が 約 5%ほ ど高速化 された. この
実験 によ り要求セグメン ト解析を適応することで高速化 されること を示せ た. これ よ り以下の実験での提案手法 は全 て要求セグメン ト解析を適応 した手法 とす る.
2 5
6. 3 シミュレーション実験
6. 3. 1 実験内容
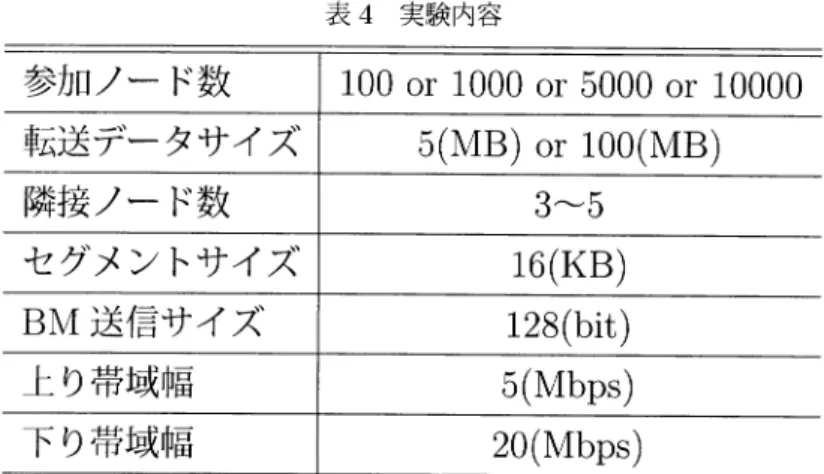
シミュレーシ ョン実験では提案手法, Coo I S t r e a mi ng , Cha i ns a w をシミュレーシ ョン上で実行 し比較を行 った.実験内容については表 4 に示 している.
表 4 実験 内容
参加ノー ド数 1 00or1 000or5 000or1 0000 転送デー タサイズ 5( MB)or1 00( MB)
隣接ノー ド数 3‑5
セグメン トサイズ 1 6( KB) BM 送信サイズ 1 28( bi t ) 上 り帯域幅 5( Mbps )
また,データ駆動型 ALM ネッ トワー クの構築について以下で述べる.
1. ノー ドがネットワー クに参加 した時,参加ノー ドが 4 ノー ド以下ならソースノー ドに接続.
4 ノー ド以上ならソースノー ド以外の一般ノー ドへ と接続する.
2. 自 信が参加 してか ら一定期間過ぎたら,他の参加ノー ドの情報を得る為にソースノー ドへ と アクセスする.
3. ソースノー ドから得たリス トを参照 し,参加ノー ドからランダムに選んだノー ドを隣接ノー ドとする.もし選んだ参加ノー ドの隣接ノー ド数が最大で接続できなければ選んだノー ドを 除外 したリス トか ら再びランダムに選んで,隣接ノー ドを探す.
4. 全てのノー ドが参加 し,ネットワー クを構築 した後に転送データを送信する.
上記の実験環境で 6. 1 で述べた評価方法を基に実験を行 う.
26
6. 3. 2 実験結果 ( 転送データ 5MB)
転送データサイズが 5 MB のシミュレーシ ョン実験の結果を以下に示す.
実験結果 ( OBRU) を図 1 7 と表 5 に示す・
a S ⊃ J O alβ ] u lP !A P
ut2gPunOqlnO
1000 2000 3000 4000 5000 6000 7000 8000 9000 1 0000
nodenum
図 1 7 上 り帯域使用率
表 5 上 り帯域使用率
( %) Cha i ns a w Cool St r e a mi ng 提案手法 ( da t adr i Ve n) 1 00 2 4. 9 1 8. 1 2 4. 2
1
000 2 4. 8 1 8. 1 23. 7
5 0 00 2 4. 4 1 8. 0 23. 4
27
実験結果 ( ANBT) を図 1 8 と表 6 に示す.
uo!ss
!
uJsu tZJ J. m 皿1
0LaqLu n
Na6tZLa^V0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
node‖um
図 1 8 平均 BM 送信 回数
表 6 平均 BM 送信回数
( 回) Cha i ns a w Cool St r e aml ● ng 提案手法 ( da t a dr i Ve n) 1 00 76. 5 2 4. 6 31. 1
1 000 77. 2 24. 4 32. 5 5000 77. 2 24. 4 33. 0
2 8
実験結果 ( TDT) を図 1 9と表 7 に示す・
a Lu !l At2 I
aP I t210 1 0 0
1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
nodenum
図 1 9 全体遅延
表 7 全体遅延
(
S )Chai ns a w Cool St r e ami ng 提案手法 ( dat adr i Ve n) 1 00 30. 6 36. 5 29. 4
1 0 00 39. 4 44. 1 36. 5
5000 46. 0 50. 3 41. 7
29
6. 3. 3 実験結果 ( 転送データ 1 00MB)
転送デー タサイズが 1 00MBのシミュレーシ ョン実験の結果を以下に示す.
実験結果 ( OBRU) を図 20と表 8 に示す.
a
⊃ J l ∝ u l P ! P
皿PqlO S O a t Z J V t
ut2unOn010002000300040005000600070008000900010000 nodenum
図 20 上 り帯域使用率
表 8 上 り帯域使用率
( %) Cha i ns a w Cool St r e ami ng 提案手法 ( da t adr i Ve n) 1 00 25. 8 1 8. 6 24. 5
1 000 25. 9 1 8. 7 24. 9 5000 25. 9 1 8. 7 24. 9
30
実験結果 ( ANBT) を図 21 と表 9 に示す・
uo!ss!
Lu Su tZJ ト m 皿 1
0L a q ∈ n N a 6 t2 L a
^V0 0 6
10 0 4 1 0 0 2 ■l 0 0 0.1
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
nodenum
図 21 平均 BM 送信 回数
表 9 平均 BM 送信回数
( 回) Cha i ns a w Cool St r e ami ng 提案手法 ( da t adr i Ve n) 1 00 1 525. 3 49 0. 7 61 1. 6
1 000 1 539. 2 49 4. 0 61 8. 0 5 000 1 5 40. 4 493. 2 61 9. 0
31
実験結果 ( TDT) を図 22 と表 1 0 に示 す.
∞ 0Jl
1 000 2000 3000 4000 5000 6000 7000 8000 9000 1 0000 nodenum
図 22 全体遅延
表 1 0 全体遅延
( S ) Cha i ns a w Cool St r e a ml ● ng 提案手法 ( da t adr i V e n) 1 0 0 603. 1 72 9. 7 58 0. 7
1 0 00 77 2. 5 881. 5 71 5. 9 50 00 901. 7 98 8. 2 811. 3
32
6 . 4 実機実験 6. 4. 1 実験内容
実機実験 として,インターネ ッ ト環境を想定 したシミュレーシ ョンシステムを用いて実際に提 案手法の実験を行 う.本実験でも提案手法, Co o I S t r e a mi ng , Cha i ns a w を実装 し実機シミュレー
シ ョンシステム上で比較を行 った.実験内容については表 11 に示 している.
表 11 実験 内容
参加 ノー ド数 6 4
転送デー タサイズ 5 ( MB)
隣接 ノー ド数 3 ‑5
セグメン トサイズ 1 6 ( KB) BM 送信サイズ 1 2 8 ( b i t )
上 り帯域幅 1 ( Gb p s )
下 り帯域幅 1 ( Gb p s )
また,データ駆動型 ALM ネットワークの構築について以下で述べる.
1. ノー ドがネ ッ トワー クに参加 した時,参加ノー ドが 4 ノー ド以下ならソースノー ドに接続.
4 ノー ド以上ならソースノー ド以外の一般ノー ドへ と接続する.
2. 自信が参加 してか ら一定期間過ぎたら,他の参加ノー ドの情報を得る為にソースノー ドへ と アクセスする.
3. ソースノー ドか ら得たリス トを参照 し,参加ノー ドか らランダムに選んだノー ドを隣接ノー ドとする.もし選んだ参加ノー ドの隣接ノー ド数が最大で接続できなければ選んだノー ドを 除外 したリス トか ら再びランダムに選んで,隣接ノー ドを探す.
4. 全てのノー ドが参加 し,ネッ トワークを構築 した後に転送データを送信する.
また,実験で使用 したシミュレーシ ョンシステムは, 4Co r ex2 の CPU を搭載 したシミュレー シ ョンサーバ 8 台を用いて 1 台につき 8 ノー ド ( 各ノー ドには個別の NI C 有 り)動か し,計 64 ノー ドでデータ配信を行 う.本システムを用いることにより,よ り実環境に近い実験が行えると考 えられる.
上記の実験環境で 6. 1 で述べた評価方法を基に実験を行 う.
33
6. 4. 2 実験結果
実機実験の結果を以下に示す.
実験結果 ( OBRU) を図 23 と表 1 2 に示す・
a S ⊃ J O a lC
正三P!)VLPut2gPunOqlnO 8 6 4 6 6 6 2 0 6 6
図 2 3 上 り帯域使用率
表 1 2 上 り帯域使用率
( %) Cha i ns a w Cool St r e aml ● ng 提案手法 ( da t a dr i V e n) ml n 65. 9 53. 3 6 5. 2
a Ve 6 8. 3 53. 9 6 6. 3 ma x 7 2. 5 55. 1 6 8. 3
3 4
実験結果 ( ANBT) を図 2 4 と表 1 3 に示す・
uo