分散深層学習を高速化させるFPGA Ring-Allreduceの検討
2
0
0
全文
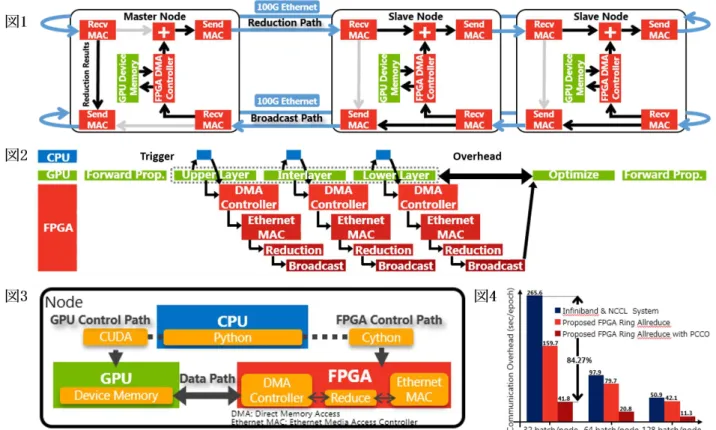
(2) 情報処理学会第 82 回全国大会. 図 1: 作成した FPGA Ring-Allreduce の回路とデータ移動の模式図。図 2: 勾配計算と集団通信を極力 オーバーラップさせた提案手法(PCCO)のタイムチャート。図 3: 今回の性能評価に用いた 1 ノー ドの構成とソフトウェアの役割。図 4:Infiniband を用いたシステム、FPGA Ring-Allreduce を採用 したシステム、FPGA Ring-Allreduce と PCCO を採用したシステムの集団通信オーバーヘッドを 様々なバッチサイズで比較した。 システムの構成を図3に示す。このシステムを用 参考文献 [1] Tal Ben-Num, and Torsten Hoefler: Demystifying いて、従来のInfiniband、GPU Direct RDMAを用 Parallel and Distributed Deep Learning: An Inいた分散深層学習と、提案するシステムを用い Depth Concurrency Analysis, た分散深層学習で、学習精度、Allreduce時間、 arXiv:cs.LG/1802.09941, (2018). 学習全体の時間で比較した。 [2] Takuya Akiba, Shuji Suzuki, and Keisuke 学習精度に関わるアルゴリズムの変更は施し Fukuda: Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes, ていないので、同程度の学習精度が確認された。 Deep Learning at Supercomputer Scale (NIPS’17 集団通信のオーバーヘッドは分散深層学習でよ Workshop), arXiv:cs.DC/1711.04325, (2017). く使用される 32 bach/node で 84.27 %削減でき [3] Xianyan Jia, Shutao Song, Wei He, Yangzihao た。その他のバッチサイズであっても大幅に削 Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, 減できることが示された(図 4)。全体の学習時 Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang 間としては 7 %の高速化が実現できた。 Chen, Guangxiao Hu, Shaohuai Shi, Xiaowen Chu:. 5. まとめと今後の課題 本研究は分散深層学習のボトルネックである 集 団 通 信 時 の デ ー タ 移 動 が 最小となるような FPGA Allreduce を提案し、また、そのアーキテ クチャに適した分散深層学習スケジューリング に関しても提案した。その結果、学習精度の劣 化無く、大幅な高速化に成功した。今後は、ノ ード内の計算リソース・ノード数を増大させた 場合のスケーラビリティに関して調査する。. 1-32. Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes, Workshop on Systems for ML and Open Source Software at NeurIPS 2018, arXiv:cs.CV/1807.11205, (2018). [4] Chris Ying, Sameer Kumar, Dehao Chen, Tao Wang, Youlong Cheng: Image Classification at Supercomputer Scale, , Workshop on Systems for ML and Open Source Software at NeurIPS 2018, arXiv:cs.CV/1811.06992, (2018).. Copyright 2020 Information Processing Society of Japan. All Rights Reserved..
(3)
図
関連したドキュメント
平成 27 年 2 月 17 日に開催した第 4 回では,図-3 の基 本計画案を提案し了承を得た上で,敷地 1 の整備計画に
試験体は図 図 図 図- -- -1 11 1 に示す疲労試験と同型のものを使用し、高 力ボルトで締め付けを行った試験体とストップホールの
計算で求めた理論値と比較検討した。その結果をFig・3‑12に示す。図中の実線は
腐植含量と土壌図や地形図を組み合わせた大縮尺土壌 図の作成 8) も試みられている。また,作土の情報に限 らず,ランドサット TM
絡み目を平面に射影し,線が交差しているところに上下 の情報をつけたものを絡み目の 図式 という..
当図書室は、専門図書館として数学、応用数学、計算機科学、理論物理学の分野の文
高(法 のり 肩と法 のり 尻との高低差をいい、擁壁を設置する場合は、法 のり 高と擁壁の高さとを合
問題解決を図るため荷役作業の遠隔操作システムを開発する。これは荷役ポンプと荷役 弁を遠隔で操作しバラストポンプ・喫水計・液面計・積付計算機などを連動させ通常
