深層学習を用いたQAサイト質問文のカテゴリ分類
6
0
0
全文
(2) Vol.2016-NL-228 No.10 2016/9/30. 情報処理学会研究報告 IPSJ SIG Technical Report. リが存在する.. する.. (1)∼(4) の手順で得られた単語をベクトルの要素とし,個々 2.1 データ収集. の要素はその単語が出現すれば 1,出現しなければ 0 の 2. 機械学習手法を用いてカテゴリ分類を行う場合,学習. 値を取る.OKWave コーパスは自動生成されたものである. データ(training data) ,検証データ(validation data) ,テ. ため,ベクトルの要素を 1 つも含まない質問文が含まれて. ストデータ(test data)が必要になるため,ラベル付きの. いるが,本稿では,ベクトルを生成する時に,トップ N 以. 質問文が多く必要になる.本稿では質問文が属するカテゴ. 内の単語が一度も出現しない質問文を用いないこととする.. リをラベルと呼ぶ.小分類では,カテゴリごとの質問文が. 機械学習において,ベクトルの次元数の違いによる分類. 少なくなる問題があるため,中分類の中から 10 種類のカテ. 性能を比較するため,トップ N の N をそれぞれ 300(その. ゴリの質問文を自動で入手しコーパスを作成した.用いた. 結果,ベクトルが 1,276 次元),500(同 2,018 次元)とし. カテゴリは「AV 機器」 「Macintosh」 「PC パーツ」 「SNS」. た.また,各カテゴリのデータを学習用、検証用,テスト. 「Windows」 「ウィルス対策」 「ソフトウェア」 「ネットショッ. 用の 3 つに分類した.具体的には,1 カテゴリあたりに学. ピング」 「マルチメディア」 「携帯・スマートフォン・PHS」. 習データを 2,000 個,検証データを 400 個,テストデータ. である.これらは,デジタルライフカテゴリに属する中分. を 400 個用意した.すなわち,10 カテゴリの全データにお. 類のカテゴリの中から選択している.なお、検証データは. いては,学習データ,検証データ,テストデータをそれぞ. 最適なハイパーパラメータを決定するのに用いる.表 1 は. れ合計 20,000,4,000,4,000 個用意した.. ラベルと質問文のペアの例を示す. 表 1 コーパスの例 ラベル. AV 機器. 深層学習とは,従来のニューラルネットワークを多層構. 質問文. 造にした機械学習手法の総称である.機械学習のアルゴ. ウォークマンの液晶の修理費について今日、鞄に. リズムは大きく分けて教師あり学習,教師なし学習,強. 入れていたらウォークマンの液晶が割れていまし た。このウォークマンは去年の 12 月に買ったばっ. Windows. 3. 深層学習. 化学習の 3 つであり,深層学習はそのいずれにも適用す. かりで、4 ヶ月ほどしか経っていません。修理費. ることができる.DBN や SdA は,それぞれデータのよ. はどのくらいかかるのでしょうか?機種は A16 で. い特徴を抽出する事前学習(Pre-training)を行う教師な. す。. し学習器(ディープニューラルネットワーク)と,その. Windows7 を使用しています。アップグレードの. 事前学習で抽出した,よい特徴のベクトルに対して事後. 予約を完了したのに何の連絡もないため、Windows. 学習(Fine-tuning)を行う教師あり学習器から構成され. Update の更新履歴を確認したところ、何度も更新 に失敗したとの履歴が出てきました。どのような 対処をすればいいのか教えてください。. る.DBN に用いられる教師なし学習器は積み重ねられて いる (Stacked) Restricted Boltzmann Machine (RBM) で あり,SdA に用いられる教師なし学習器は重ねられてい る (Stacked)Denoising Autoencoder (dA) である.RBM,. dA のどちらも深層学習の事前学習法の一種だが,RBM が 2.2 ベクトル変換. 確率モデルであるのに対して,dA は決定的モデルである.. 機械学習に用いるテキストコーパスはベクトルに変換す. 中間層に RBM もしくは dA を用いたディープニューラ. る必要がある.テキストから単語を抽出した後,ベクトル. ルネットワークの例を図 1 に示す.図では,3層の RBM. に変換し Bag-of-Words (BoW)で表現する.コーパスは. もしくは dA から中間層が構成されている.中間層の数は. およそ 33,000 の質問文からなっており,異なり単語の数が. 必要に応じて変えることができる.. 膨大となるためベクトルの次元数が膨大となり機械学習で 学習にかかるコストがとても大きくなるため,次のような 手順でベクトル変換を行う. ( 1 ) コーパスの形態素解析 *5 を行い,名詞(固有名詞,サ 変接続,一般)を抽出する.. ( 2 ) 名詞が連続しているのであれば,結合し 1 つの単語と みなす.. 3.1 Denoising Autoencoder (dA) dA はランダムにノイズを与えた信号を入力し,ノイズ 加算前の信号を復元する Autoencoder の一種である [10]. 入力のベクトルを x とし,ノイズを加算したベクトルを x ˆ とする.中間層の出力を式 (1),出力層の出力を式 (2) と する.. ( 3 ) 単語は全角・半角を統一し,英単語は全て大文字で統 一する.. ( 4 ) 各ラベルから出現頻度がトップ N 以内の単語を抽出 *5. 形態素解析には MeCab を用いた.. c 2016 Information Processing Society of Japan ⃝. yj = sigmoid(. n ∑. Wji x ˆ i + bj ). (1). i=1. 2.
(3) Vol.2016-NL-228 No.10 2016/9/30. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 1. zi = sigmoid(. m ∑. fij yj + ebi ) W. DBN と SdA の構造の例. (2). j=1. E(x, z) = −. n ∑. (4) の順にサンプリングの工程を繰り返す.サンプリング を k 回行った後,以下の更新式に従い,重みとバイアスが 更新される.. [xk log zk + (1 − xk ) log(1 − zk )] (3). k=1. ただし,入力層のユニットを n 個,隠れ層のユニットを m 個とし,W ,b はそれぞれ入力層から中間層の結合の重み f ,eb は中間層から出力層の結合重み とバイアスであり,W. W ← W +ϵ(h(1) vT−P (h(k+1) = 1|v (k+1) )v (k+1)T )(6) b(1) ← b(1) + ϵ(v − v (k+1) ). (7). b(2) ← b(2) + ϵ(h(1) P (h(k+1) = 1|v (k+1) )). (8). とバイアスである.一般に式 (1) は符号化,式 (2) は復号 化と呼ばれる.ノイズ加算前の x と復号化された z との差 を表す誤差関数は式 (3) のようになる.式 (3) は交差エン トロピー関数であり,この誤差関数を最小化させるように. ただし,ϵ は学習率である.サンプリングの繰り返しの 回数を十分に行うことを Gibbs sampling と呼ぶが,かな りの計算コストを要するため,サンプリングを有限回で止 める Contrastive Divergence (CD) 法が用いられることが. 符号化と復号化を繰り返し,学習を行う.. 多い.CD 法は経験的にサンプリングを 1 回行う場合でも 十分良い結果 [10] になることから,本研究も CD 法を用い. 3.2 Restricted Boltzmann Machine (RBM) RBM は可視層と,隠れ層の 2 層で構成されたボルツマ ンマシンの一種で,同じ層内のユニット同士に結合を持た. て,サンプリングを 1 度だけ行い学習をする.. 4. 実験. ず,可視層と隠れ層とのユニット間にのみ結合を制限して. 4.1 実験条件. いるものである.. RBM の可視層のユニットを n 個,隠れ層のユニット を m 個とするとき,可視変数は (v1 , v2 ..., vn ),隠れ変数は. (h1 , h2 , ..., hm ) である.RBM は以下の条件付き確率分布. = 1|v. (k). )=. (2) sigmoid(bi. +. m ∑. (k). = 1|h. )=. テゴリ分類を行う.DBN,SdA の有効性を確認するため, いる.. (k) wij vj ). (4). j=1 (k+1) P (vj. のベクトルをもとに用意したデータセットを用いて,カ ベースライン手法として MLP,SVM (Linear,RBF) を用. に基づきサンプリングを行う. (k) P (hi. 本実験では,2.1 節に従い構成した次元数の異なる 2 つ. (2) sigmoid(bj. +. n ∑. タは,グリッドサーチを行うことで決定した.各機械学 (k) wij hi ). (5). ただし,k(≥ 1) はサンプリング繰り返し回数,wij はユ (1). (2). と bj. 習手法のハイパーパラメータの組み合わせの数がほぼ同 等になるように設定されており,その数は DBN,SdA で. i=1. ニット vi と hj 間の結合の重み,bi. それぞれの機械学習における最適なハイパーパラメー. はそれぞれ可. 視層と隠れ層のバイアスである.学習のアルゴリズムは,. 216,MLP で 228,SVM で 225 通りとなっている.グリッ ドサーチに用いるハイパーパラメータの詳細は表 2 に示す. 例として,DBN の入力が 2,018 次元の場合の隠れ層の構. 可視変数に学習データ v を与えた後,式 (4) を用いてサン. 造の欄に 1513-1009-504 とある.これは,DBN が 3 つの中. プリング,その後 (5) を用いてサンプリング,そして再度. 間層(ノードの数が入力層側から順に 1513,1009,504)を. c 2016 Information Processing Society of Japan ⃝. 3.
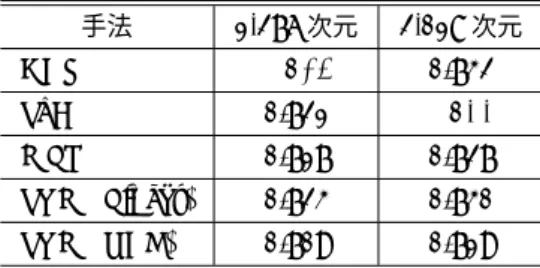
(4) Vol.2016-NL-228 No.10 2016/9/30. 情報処理学会研究報告 IPSJ SIG Technical Report. DBN. SdA. MLP. パラメータ. 1,276 次元. 2,018 次元. 増加率. 1531,1531-1,531,1531-1531-1531. DBN. 0.723. 0.734. 1.52%. 入力が 2,018 次元の. 1009,1345-672,1513-1009-504,. SdA. 0.720. 0.735. 2.08%. 隠れ層の構造. 2421,2421-2421,2421-2421-2421. Pre-training の学習率. 0.01,0.005,0.001. MLP. 0.717. 0.727. 1.39%. Pre-training の学習回数. 100,300,500. SVM (Linear). 0.723. 0.731. 1.11%. Fine-tuning の学習率. 0.1,0.01. SVM (RBF). 0.717. 0.723. 0.84%. 活性化関数. ReLU,Sigmoid. 入力が 1,276 次元の. 638,851-425,957-638-319,. 隠れ層の構造. 1531,1531-1531,1531-1531-1531. 入力が 2,018 次元の. 1009,1345-672,1513-1009-504,. 隠れ層の構造. 2421,2421-2421,2421-2421-2421. Pre-training の学習率. 0.01,0.005,0.001. Pre-training の学習回数. 100,300,500. Fine-tuning の学習率. 0.1,0.01. 活性化関数. ReLU,Sigmoid. 入力が 1,276 次元の. 638,851-425,957-638-319,. 隠れ層の構造. 1531,1531-1531,1531-1531-1531. 入力が 2,018 次元の. 1009,1345-672,1513-1,009-504,. 隠れ層の構造. 2421,2421-2421,2421-2421-2421. 638,851-425,957-638-319,. 隠れ層の構造. 活性化関数. SVM. 値. 入力が 1,276 次元の. 学習率. (Linear). 表 3 分類精度と精度の増加率. グリッドサーチに用いるハイパーパラメータ. C γ C. 0.725 0.720 0.715 0.710 0.705. 0.1-0.01 間に 10 等分割, 0.009-0.001 間に 9 等分割. 0.700. ReLU,Sigmoid 10−4 -104 間に対数 (基底 10). 0.695 1. スケールで 225 分割 −4. SVM(RBF). 手法. Average Precision. 表 2 機械学習. 10. DBN SdA MLP SVM_Linear SVM_RBF 5. 10. 4. -10 間に対数(基底 10). スケールで 15 分割. 図 2. 10−4 -104 間に対数(基底 10). 15 top N. 20. 25. 30. 1,276 次元での各機械学習手法の精度. スケールで 15 分割. 0.735. 持つことを表している.つまり,その DBN は 2018-1513-. 0.730. 1009-504-10 という構造を持つことになる.ただし,ここ. 0.725 Average Precision. での 2018,10 とは入力層と出力層のノードの数であり,そ れぞれ学習に用いるデータセットのベクトルの次元数とラ ベルの数に対応している.ハイパーパラメータとしての隠 れ層のノードの数は,徐々に減らしていく構造を持つもの. 0.720 0.715 0.710. と,入力層のノードの数を 1.2 倍したものを同等に並べた 構造を持つものを用いている.. 0.705. 本実験で用いる DBN,SdA 及び MLP は Deep Learning. 0.700 1. Tutorials*6 に記載されているスクリプトを用いる.SVM においては機械学習ライブラリ scikit-learn の SVM を用い. DBN SdA MLP SVM_Linear SVM_RBF 5. 図 3. る.なお,SVM (Linear) は LIBLINEAR に基づいて実装. 10. 15 top N. 20. 25. 30. 2,018 次元での各機械学習手法の精度. されており,SVM (RBF) は LIBSVM に基づいて実装さ. していることがわかる.SdA の増加率が 2.08%,DBN の. れている.. 増加率が 1.52%となっており,どちらもベースライン手法 の増加率より高くなっている.これは,次元数の増加に. 4.2 実験結果 ハイパーパラメータの組み合わせの内,最も検証誤差の. よって,DBN と SdA が他の手法よりも大きく精度が向上 すると考えられる.. 小さいパラメータセットを用いたときの各機械学習の精度. ハイパーパラメータの組み合わせを検証誤差の小さい順. と,次元数の変化による精度の増加率を表 3 に示す.ここ. に並べ,上位 N 個(ただし N = 1,5,10,...,30)を用いた時. での精度は,テストデータに対する分類精度である.. の各機械学習手法の平均精度を図 2,図 3 に,N =1,5,10. 表 3 より,最も精度が高かったのが SdA(2,018 次元)の. の時の各機械学習手法の平均精度をそれぞれ表 3. 0.735 である.次いで,DBN(2,018 次元) の 0.734 となっ. 表 5 に示す.ただし,図 2,図 3 はそれぞれ 1,276 次元の. ている.また,全ての機械学習手法で精度の増加率が正の. ベクトルと 2,018 次元のベクトルを用いた場合である.. 値を取ることから,次元数を増やすことにより精度が向上 *6. http://www.deeplearning.net/tutorial. c 2016 Information Processing Society of Japan ⃝. *7 ,表. 4,. 1,276 次元において,検証誤差の一番小さい(N = 1)時 *7. 表 3 は実際は N = 1 の平均精度の結果と同じである.. 4.
(5) Vol.2016-NL-228 No.10 2016/9/30. 情報処理学会研究報告 IPSJ SIG Technical Report 表 4. N = 5 の時の各機械学習の平均精度. 手法. SVM (RBF) に対して有意差があるが.DBN は SVM (Lin-. 1,276 次元. 2,018 次元. ear) より有意差があると確認できない.SdA は検証誤差の. DBN. 0.725. 0.733. 低い上位 10 個のハイパーパタメータを用いたとき,SVM. SdA. 0.720. 0.734. (Linear) より平均精度が低いため,表の値は SVM (Linear). MLP. 0.717. 0.727. が SdA に対して有意な差があると考えられる.2,018 次元. SVM (Linear). 0.723. 0.731. において,SdA はベースライン手法に対して有意差がある. SVM (RBF). 0.711. 0.722. ことが確認できる.DBN は,MLP と SVM (RBF) に対し て有意差があるが,SVM (Linear) に対して有意水準 0.1 で. 表 5. N = 10 の時の各機械学習の平均精度. 手法. 1,276 次元. 2,018 次元. DBN. 0.724. 0.732. SdA. 0.721. 0.733. MLP. 0.717. 0.727. SVM (Linear). 0.723. 0.730. SVM (RBF). 0.709. 0.719. 有意差があるが,有意水準 0.05 では有意差がない.. 4.3 考察 実験結果から,SdA で最も高い精度であることがわかっ た.次元数の大きいデータを用いたとき,DBN,SdA の 両方でベースライン手法より高い精度となることがわかっ た.また,次元数を増やしたときの精度の増加率が SdA が. の平均精度では,DBN と SVM (Linear) が同じで最も高い が,N が 5 以上の時の平均精度を見ると DBN が最も高い ことがわかる.2,018 次元において,DBN,SdA は全ての ベースライン手法より平均精度が高いことが見て取れる. このことから,次元数を増やすことにより深層学習の平均 精度が高くなることがわかる.また,N が 10 までの平均 精度が最も高いのが SdA だと見て取れる.1,276 次元では. SdA は DBN より平均精度が低いが,2,018 次元では SdA の方が平均精度が高いことがわかる.次元数を増やすこと. 高次元のデータの中から,より良い特徴を抽出し,学習が できたからだと考えられる.しかし,次元数の小さいデー タを用いた場合では,SVM (Linear) の精度は SdA より高 く,平均精度においても DBN と近い結果であった.その 原因としては,学習に用いるハイパーパラメータの数が. SVM (Linear) は 1 つと,DBN,SdA と比較してとても少 ないため,最適なハイパーパラメータの選択が容易になり, 精度が高くなったと考えられる.. 5. おわりに. で SdA が最も性能が向上した. ハイパーパラメータの組み合わせを検証誤差の小さい順 に並べ,上位 10 個を用いた場合について,DBN,SdA と ベースライン手法との性能に有意差があるかを確認するた め,t 検定を行った.検定結果を表 6,表 7 に示す. (表の 数値は p 値を表している.有意水準が 0.10 で有意差があ るものには*,有意水準 0.05 で有意差があるものには**を 付けている.) 表 6. 最も高く,次いで DBN が高かった.これは,深層学習が. 本稿では,QA サイトの質問文を深層学習を用いてカテ ゴリに分類した.深層学習の分類精度がベースライン手法 よりも高いことから,QA サイトの質問分のカテゴリ分類 において,深層学習が有効であることが確認できた.また, 入力データの次元数を増やした場合の分類精度の増加率 は,深層学習の方がベースライン手法より高いことから, 次元数の多い入力データが深層学習に有効であることを示. 1,276 次元での DBN, SdA とベースライン手法との t 検定. SVM (Linear). MLP. した.. SVM. 今回の最適なハイパーパラメータの決定方法はグリッド. (RBF). サーチで行った.しかし,分類精度の向上に影響の大きい. DBN. 0.203. 0.000 **. 0.000 **. ハイパーパラメータの値が,候補群に入っていなかった可. SdA. 0.006 **. 0.000 **. 0.000 **. 能性が考えられる.そのため,ハイパーパラメータの最適 化にランダムサーチ [12][13] が必要になると考えられる. 本稿では 10 種類のカテゴリを用いて分類を行った.し. 表 7. 2,018 次元での DBN, SdA とベースライン手法との t 検定. SVM (Linear). MLP. SVM (RBF). DBN. 0.096 *. 0.000 **. 0.000 **. SdA. 0.018 **. 0.000 **. 0.000 **. かし,実際の QA サイトのカテゴリ数は非常に多い.その ため,分類に用いるカテゴリを増やした場合でも,精度を 低下させないことなどが今後の課題として考えられる.ま た,次元数を更に増やした入力データを用いた場合の,分 類精度への影響を検証する予定である. 謝辞 本研究は科研費(25330368)の助成を受けたもの である.. 表より,1,276 次元において,DBN,SdA の両方で MLP,. c 2016 Information Processing Society of Japan ⃝. 5.
(6) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2016-NL-228 No.10 2016/9/30. 参考文献 [1]. [2]. [3]. [4]. [5]. [6]. [7]. [8]. [9]. [10]. [11]. [12]. [13]. Q. Ma, I. Tanigawa, and M. Murata: Retrieval Term Prediction Using Deep Learning Methods, to appear in the 30th Pacific Asia Conference on Language, Information and Computation (Paclic 30), 2016. 馬青,谷河息吹,村田真樹:Deep Belief Network を用い た検索用語の予測,自然言語処理,Vol. 22,No. 4,pp. 225-250,2015. Q. Ma, I. Tanigawa, and M. Murata: Retrieval Term Prediction Using Deep Belief Networks, The 28th Pacific Asia Conference on Language, Information and Computing (Paclic 28), pp. 338-347, 2014. 栗山和子,神門典子:Q&A サイトにおける質問と回答の 分析,情報処理学会研究報告,Vol. 2009-DBS-148,No. 19,2009. 田中友二,望月崇由,八木崇史,徳永幸生,杉山精:Q&A サイトにおける情報検索型質問の自動抽出,情報処理学 会第 74 回全国大会 全国大会論文集,pp. 529-531,2012. 劉舒暢,伊東栄典,中島幸子,廣川佐千男:Yahoo!知恵 袋の質問文分類のための質問文分析,言語処理学会第 21 回年次大会 発表論文集,pp. 357-360,2015. 大森勇輔,森田和宏,泓田正雄,青江順一:擬似訓練デー タを用いた Q&A サイトの質問分類,言語処理学会第 21 回年次大会 発表論文集,pp. 489-492,2015. 渡邊直人,島田諭,関洋平,神門典子,佐藤哲司:QA コ ミュニティにおける質問者の期待に基づく質問分類に関 する一検討,第3回データ工学と情報マネージメントに 関するフォーラム(DEIM2011),B5-1,2011. G. E. Hinton, S. Osindero, and Y. Teh, A Fast Learning Algorithm for Deep Belief Nets, Neural Computation, Vol. 18, pp. 1527-1554, 2006. Y. Bengio, Learning Deep Architectures for AI, Foundations and Trends in Machine Learning, vol. 2(1), pp. 1-127, 2009. Y. Bengio, P. Lamblin, D. Popovici, and H. Larochelle, Greedy Layer-Wise Training of DeepNetworks, In Transactions on Pattern Analysis and Machine Intelligence, Vol. 35(8), pp. 1798-1828, 2007. J. Bergstra and Y. Bengio, Random search for heperparameter optimization, The Journal of Machine Learning Research, Vol. 13, pp. 281-305, 2012. 神嶌敏弘 編:深層学習-Deep Learning- 人工知能学会監 修,2015.. c 2016 Information Processing Society of Japan ⃝. 6.
(7)
図
![図 1 DBN と SdA の構造の例 z i = sigmoid( ∑m j=1 fW ij y j + eb i ) (2) E(x, z) = − ∑n k=1 [x k log z k + (1 − x k ) log(1 − z k )] (3) ただし,入力層のユニットを n 個,隠れ層のユニットを m 個とし, W , b はそれぞれ入力層から中間層の結合の重み とバイアスであり, fW , eb は中間層から出力層の結合重み とバイアスである.一般に式 (1) は符号化,式 (2) は復号](https://thumb-ap.123doks.com/thumbv2/123deta/6472775.1635497/3.892.147.750.123.378/DBN構造=∑ただしユニットユニットそれぞれバイアスバイアス.webp)

関連したドキュメント
This review is devoted to the optimal with respect to accuracy algorithms of the calculation of singular integrals with fixed singu- larity, Cauchy and Hilbert kernels, polysingular
This review is devoted to the optimal with respect to accuracy algorithms of the calculation of singular integrals with fixed singu- larity, Cauchy and Hilbert kernels, polysingular
This review is devoted to the optimal with respect to accuracy algorithms of the calculation of singular integrals with fixed singu- larity, Cauchy and Hilbert kernels, polysingular
Note: The number of overall inspections and overall detentions is calculated corresponding to each recognized organization (RO) that issued statutory certificate(s) for a ship. In
The following maritime Authorities in the Asia-Pacific region are the signatories to the Memorandum: Australia, Canada, Chile, China, Fiji, Hong Kong (China), Indonesia,
Article 58(3) of UNCLOS provides that in exercising their rights and performing their duties in the EEZ, “States shall have due regard to the rights and duties of the coastal
2016 年 9 月 17 日に国際学会 APACPH(Asia-Pacific Academic Consortium for Public Health Conference)においてポスター発表を行った。. 題名「Social Support and
中里貝塚の5つの本質的価値「貝類利用に特化した場」 「専業性の高さを物語る貝塚」 「国内最
