量子化結合ニューラルネットワークの深層学習に関
する研究
著者
品川 政太朗
学位授与機関
Tohoku University
修士学位論文
量子化結合ニューラルネットワークの
深層学習に関する研究
品川 政太朗
東北大学大学院
情報科学研究科 応用情報科学専攻
博士課程前期
2
年
提 出 日 平成27年2月10日 審査員主査 中島 康治 教授 審 査 員 佐藤 茂雄 教授 田中 和之 教授iii
目次
第1章 序論 1 1.1 ニューラルネットワークによる情報処理の有用性 . . . 1 1.2 ニューロンの数理モデル . . . 2 1.3 機械学習器としてのニューラルネットワーク . . . 2 1.4 深い層構造を持ったニューラルネットワークとメモリ不足の問題 . . . 3 1.5 荷重値の離散化アプローチを行う意義 . . . 4 1.6 先行研究 . . . 5 1.7 本研究の目的 . . . 5 第2章 DNNの層数と離散幅の関係 7 2.1 実験条件 . . . 7 2.2 様々な構造での各層数の認識性能劣化比較 . . . 8 2.3 1層あたりの隠れ素子数を一定とした場合 . . . 11 2.4 ネットワーク全体での隠れ素子数を一定とした場合 . . . 14 2.5 2章のまとめ . . . 17 第3章 離散荷重値DNNの学習 19 3.1 実験設定 . . . 19 3.2 1層あたりの隠れ素子数を一定としたときの離散幅をパラメータとした 層数に対するエラー . . . 20 3.3 3章のまとめ . . . 26 第4章 結論 27 付録A RBMの学習 29 A.1 Boltzmann Machineとの関係 . . . 29iv 目次 A.3 RBMの学習則の導出 . . . 31 A.4 DNNの事前学習への適用 . . . 36 付録B Randomized Rounding法 37 付録C 2章での用いたネットワーク構成 39 謝辞 43 参考文献 45 本研究に関する発表 49
v
図目次
1.1 ニューロンの模式図 . . . 2 1.2 McCulloh Pittsによる数理モデル化 . . . 2 2.1 各層数でのDNNの誤認識率 . . . 8 2.2 各離散幅に対する誤認識率 . . . 10 2.3 各層数でのDNNの誤認識率 . . . 11 2.4 1層あたりの隠れ素子が100∼2000の層数に対する誤認識率比較 . . . 12 2.5 各層数での1層あたりの隠れ素子数に対する誤認識率比較. . . 13 2.6 ネットワーク全体の隠れ素子が500の場合の層数に対する誤認識率. . . . 14 2.7 ネットワーク全体の隠れ素子が1000の場合の層数に対する誤認識率 . . . 15 2.8 ネットワーク全体の隠れ素子が1500の場合の層数に対する誤認識率 . . . 15 2.9 各層数でのネットワーク全体の隠れ素子数に対する誤認識率比較 . . . 16 3.1 1層あたりの隠れ素子が100∼2000の層数に対する誤認識率比較 . . . 22 3.2 各層数での1層あたりの隠れ素子数に対する誤認識率比較. . . 23 3.3 3層隠れ素子2000と6層隠れ素子1層あたり300の荷重値数比較 . . . . 24 3.4 隠れ素子250での各離散幅における学習推移グラフ . . . 25 3.5 隠れ素子250での各離散幅における学習推移グラフの勾配による収束 . . 25 A.1 CD法の模式図 . . . 34 A.2 RBMによるDNNの事前学習 . . . 36 B.1 RR法の模式図 . . . 37vii
表目次
C.1 各隠れ層の構造(784-hidden-10)の全ネットワーク . . . 39 C.2 隠れ層の構造(784-hidden-10)全体の隠れ素子数が500,1000,1500の
1
第
1
章
序論
1.1
ニューラルネットワークによる情報処理の有用性
ニューラルネットワークとは人間の脳の神経細胞のネットワークを数理モデル化した ものである.なぜこのようなモデルが考案されたのかといえば,従来我々の周りをとりま く計算機(フォンノイマン型計算機)は単純な計算をするスピードは速いけれども苦手と している情報処理が存在するからである.それらはよくひとくくりに「知的情報処理」と 呼称されることが多い.知的情報処理とは例えば,人と人の顔を見比べて違いを見分ける などの「パターン認識」の問題や地図を見てなんとなく最短に近い経路を瞬時に判断する 「最適化」の問題などが挙げられる.人間にしてみれば「なんとなく」行っている情報処 理は最適な正解を導きだせるとは限らないが,非常に最適に近い答えを瞬時に導きだすこ とができる.一方,計算機を用いてこれらの問題を解こうとする場合は単純に解こうとす るとしばしば全探索を行う必要があり,計算量の爆発を引き起こす.例えば最適化問題でTransfer Salesman Ploblem(TSP)問題と呼ばれる問題を考えてみる.この問題は各都市に
ノードが割り当てられ,ノード間には都市間の距離がノード間の結合の重みとして定義さ れる.これをいわゆる一筆書きで一度通った都市は再び通ることのないように回るときの 最短経路を求める問題である.人間ならばおおよその「あて」をつけて一筆書きして最良 でなくとも比較的良い解を瞬時に与えることができるが,計算機では有限回の計算で最適 解を見つけることはできるが,O(n!)の計算を必要とするため都市数の増大によって計算 量が爆発し,現実的な時間で解けなくなってしまうという問題がある.では計算機が人間 のような知的情報処理能力を持つためにはどうすればよいか,と考える上で人間の脳の仕 組みに学ぼうというのは至極自然なアプローチである.この考えのもとに研究されてきた ニューラルネットワークは現在画像認識や音声認識,自然言語処理をはじめとして,ロ ボットの制御などさまざまな分野に応用されている他,構成論的アプローチによる脳の仕 組みや発達の解明など最終的に「人間の心を持ったロボット」を実現するための人工知能
2 第1章 序論 研究にも大いに役立つと考えられる.
1.2
ニューロンの数理モデル
if V > threshold 図1.1 ニューロンの模式図 u𝑖= 𝑗 𝑤𝑖𝑗𝑥𝑗 𝑥1 𝑥4 𝑥3 𝑥2 𝑥5 𝑏𝑖 1 0 𝑦𝑖 if 𝑢𝑖> 𝑏𝑖then 𝑦𝑖= 1 else 𝑦𝑖= 0 図1.2 McCulloh Pittsによる数理モデル化 一つの神経細胞(以下,ニューロン)の模式図を図1.1に示す.まずニューロンの核の 周りには樹状突起と呼ばれる突起が複数あり,他のニューロンからの信号を受け取る役 割を果たしている.ここで信号はニューロンの膜電位の上下により発生するパルスであ る.この入力信号の和により膜電位が時間変化し,ある閾値を超えるとニューロンの発火 現象が引き起こされ信号パルスが軸索を通って次のニューロンへ出力されるという機構 をとっている.McCullochとPittsはこのニューロンの信号を{0,1}に当てはめ,ニューラ ルネットワークを構成するとANDやORの演算回路を構成できることを示し,計算機の 論理値演算に利用できることを示した[1].彼らによって提案されたモデルはMcCulloch Pittsモデル(図1.2)と呼ばれ,現在の数理モデルとしてのニューラルネットワークの基 礎となっている.McCulloch Pittsモデルは生物ニューロンの機構を極めて簡素化したモ デルであるが,多数の素子がネットワークを形成することで最適化問題や学習の問題を解 くのに利用することができる.これは素子自体の機構が単純でもそれらが集まって形成さ れるマクロなネットワークが複雑で興味深い挙動を示すためである.特にニューラルネッ トワークを統計的な数理モデルとしてみる場合には入出力をパルスの平均発火頻度として 1/(1 + exp(−u))で表されるようなシグモイド関数を用いることで様々な知的情報処理に 適用可能となる.1.3
機械学習器としてのニューラルネットワーク
機械学習とは機械がプログラムに従って記号化された外界からの入力に従って適応的に 出力を変えたり,自己の内部構造を変化させたりすることを指す.中でもニューラルネッ1.4 深い層構造を持ったニューラルネットワークとメモリ不足の問題 3 トワークは優れたパターン識別能力や自己組織化能力を持つ.これは他の多くの手法が 適応の基準を人間の手によってヒューリスティックに決めていたのに対し,ニューラル ネットワークはその適応の基準自体も学習できるという利点があるからである.(これは ニューラルネットワークが学習規則や初期値や入力データに依存して自己組織的にネット ワークの構造を変化させることで学習を行うためである)最近では深い層構造を持った ニューラルネットワークが数多くのタスクでトップクラスの性能を上げ,画像認識や音声 認識など様々な分野で適用が進んでいる[2].
1.4
深い層構造を持ったニューラルネットワークとメモリ不
足の問題
近年では深い層構造を持つニューラルネットワークの学習手法(Deep Learning)が猫 の画像に選択的に反応するニューロンを自己組織化させられることを示し[3],一般物体 認識など複雑なタスクに対して高い認識性能を示したことから注目を集めている.深い層 構造を持つことでニューラルネットワークが高い性能を有するようになったのは,ニュー ラルネットワークの層間の計算が入力の非線形変換を行うことに対応しているためだと考 えられる.入出力層間の中間層が増えたことで非線形変換の回数が増え,より複雑な関数 モデルを仮定することができるようになったため複雑なタスクに対して認識性能を上げる ことができるようになったのだと考えられる.また,多層の構造自体がある関数を少ない 素子数で表現するのに有利であるという説明もなされている[4][5].しかし一方で,深い 構造を持ったニューラルネットワークは複雑な構造を仮定できるが故に学習用のデータに 対して過剰にフィッティングしてしまい未知データに対して正しい答えを返せなくなる 「過学習」という現象を引き起こしやすいという難点がある.過学習を防ぐ方法としては, 荷重減衰[6]や重みの共有[7][8]などといった結合の重みのパラメータ数を減らしてモデ ルの複雑さを緩和するような手法が提案された他,事前学習[9]と呼ばれる浅い学習器を 積み重ねて深いニューラルネットワークの事前の作り込みを行う方法や,DropOut[10]や DropConnect[11]といったニューラルネットワーク内部に情報の欠損を仮定したモデルを 複数用意しそれらを弱学習器としてアンサンブルすることで,一般性を保持した平均的な モデルを学習するという手法が提案されてきた.これらによって深い層構造のニューラル ネットワークの学習は人手で調整が必要なハイパーパラメータが増えたという点で扱いが 難しくなったものの,実用に耐えるレベルで制御することが可能になった. しかし,DeepLerningには他にも無視できない問題がある.ネットワークの巨大化 に伴う計算量の増大と,結合荷重値の増大によるメモリ不足の問題である.近年の DeepLearningの傾向はより複雑な問題(画像認識における一般物体認識や音声認識にお4 第1章 序論 ける連続音声認識など)を解くためのアプローチとしてより深いネットワークを構築する
ことで性能を向上させている報告が散見される[12][13].これらのネットワークを構成す
るのに必要な荷重値の数はゆうに数百万個に達する.ニューラルネットワークは構造的に
並列計算と相性が良くCPUクラスタやGPGPUの利用,またはFPGAなどを用いた専用
ハードウェアを用いることで計算時間を大幅に減らすことができるが,このように荷重値 の数が膨大になると1台のマシンでは現実的な時間で解くことが難しくなる.よって大規 模なタスクの計算には複数台のマシンを同時に利用することになるが,マシン間の通信時 間にボトルネックが生じるという根本的な問題をはらんでいるため,通信のチューニング は容易ではない.ビッグデータが盛んに喧伝されるようになりあらゆるデータが大量に得 られるようになった昨今,DeepLearningの利用は今後産業界を中心にますます多様なタ スクで利用されることになると思われるが,広く一般的に普及するためには応用上これら の問題をある程度緩和する必要があると考えられる.
1.5
荷重値の離散化アプローチを行う意義
本研究がDeep Learningのメモリ不足の問題に対して焦点を当てるのは,従来32bitや
64bitの浮動小数点で表現される荷重値を離散値で丸める,というアプローチである.荷 重値を離散化することには以下のような利点が考えられる. 1. マシン1台でも比較的大規模なニューラルネットを計算できる. 2. L1キャッシュに載る荷重値が増えるので同じ規模でも高速化が期待できる. 3. 特に荷重値を{-1,0,1}のような簡単な値に量子化出来れば,メモリ面積を最大限削 減できるだけでなく論理値演算による計算速度の向上が見込める. ニューラルネットワークは,有機物で構成される人間の脳の神経細胞をモデル化したもの ではあるが,モデルにアナログ値を用いること自体がパターン認識などの知的情報処理の 機能を実現するのにどの程度重要な役割を担っているのかは実のところ未だよく分かっ
ていない.アナログ値を用いることが有用なモデルとしてはChaos neural network[14]や
Inverse function Delayed モデル[15]などが提案されており,これらはニューロン一つ一
つの,時間連続的な振る舞いが知的情報処理に重要であることを示していると言えるだろ う.一方で,ネットワーク全体の統計的な振る舞いこそが重要であり,一個のニューロン はできるだけ簡単なモデルで表現しても知的情報処理の機能には差し支えないことを示し ているモデルも数多く存在する.代表的なモデルとしてはBack-Propagation学習 [16]に よって学習を行う層構造の決定論的ニューラルネットワークやBoltzmann Machine[17]な どが存在し,本研究で用いるDeepLearningの基礎もこれらのモデルに由来している.本 研究が特に注目している統計的なモデルの興味深い知見は前述のように「ネットワークの
1.6 先行研究 5 構成要素は単純で構わない」という点である.構成要素が単純で構わなければ,浮動小数 点で表現される荷重値ももっと単純化できる可能性が期待できる.
1.6
先行研究
同様の視点から,荷重値を離散化して学習を行う試みは過去にも数多く行われてきた. 荷重値を離散値に丸めることは離散幅に応じてしばしば性能の劣化を引き起こすという問 題があるが,特にRandomized Rounding法(RR法)[18]と呼ばれる荷重値を確率的に離 散値に丸める手法を用いた場合は入力層中間層出力層による3層ニューラルネットワー クで連続値よりもむしろ高い正解率を得た [19]という報告や,大きなスケールの問題に 対して高い精度を維持したまま使用メモリを大きく削減した[20]などの報告が存在する. また,荷重値の離散化の研究の中でも荷重値の取りうる値を有限の離散値のみに制限する 量子化についても,ハードウェア化にニューラルネットワークを実装する際に有用な技術 となることを見込まれて1990年代を中心に盛んに研究が行われてきた[21][22][23][24]. これらの手法は当時の計算機のパワーが十分でなかったため簡単なディジタル文字につい てのパターン認識などでしか議論されていなかったが,近年では [-1,1]を0.1刻みの 11 値量子化で道路の認識器を学習させたという報告[25]があり,比較的大きなデータセッ トでも入力が2値のような簡単なデータであれば量子化して学習することが可能であるこ とを示した.また,3値の量子化については文献[21][22]をDNNに適用して学習させた 事例[26][27]が報告されている.しかしこの手法はまず連続値でDNNを学習させ終わっ てから,3値に量子化して得た結果もしくはそこから再び学習を行って得られた結果であ る.この手法は学習後に得られたパラメータを用いて認識器としてハードウェアに実装す る際にメモリを削減する,という点では有効だが,学習には連続荷重値を用いているため 根本的に学習時に生じるメモリ不足の問題を解決するものではない.関連研究としては学 習で得られた畳み込みDNNの荷重値を3値に分解することで人検出のタスクを,精度を 維持しつつ高速に動作するハードウェアを実現した事例があるが,これもやはり学習自体 は連続値で行っている.よって3値の荷重値量子化学習は未だ現実的な精度で実現してい ないといってよい.1.7
本研究の目的
本研究の目的は学習を最初から3値量子化荷重値で行い,現実的な精度の認識器を構成 することにある.そのアプローチ方法としてRR法による離散化学習法と層構造ニューラ ルネットワークの多層化に注目する.理由は以下の通りである.6 第1章 序論 1. 3層の離散荷重値の学習ではRR法を用いた場合隠れ素子を増やすことである程度 までは性能が向上する.むしろ連続荷重値よりもよくなる事例もある[19]. 2. 隠れ素子を増やすことで3層ネットワークのエラー耐性(Fault tolerance)が向上 する[28]. ここで,エラー耐性とはハードウェア実装したニューラルネットワークの素子が故障に よって出力が突然0になる場合やランダムな値をとる場合を指しているが,これらの事例 が示しているのは隠れ素子を増やすことで離散荷重値でも性能の向上が見込めるというこ とである.隠れ層を増やすことも基本的には隠れ素子を増やすことであり,層数を増やす ことは非線形変換の数を増やし複雑なモデルを表現できる期待があることから,単に3層 のネットワークで隠れ素子を増やすよりも有効な戦略であることが期待できる.また,エ ラーの耐性の向上はRR法における荷重値更新の際の離散値への丸め誤差への耐性にもつ ながることが期待できる.以上のことから,連続荷重値の場合ではDNNの層数を増やす ことで性能が向上するように,離散荷重値でもDNNの層数を増やすことが性能向上ない しは荷重値を離散値に丸める際の性能劣化の緩和につながると期待できる. まとめると,本研究の目的は次のようになる. 1. DNNは層数を増やすことで荷重値離散化による丸め誤差への頑健性が向上すると いう仮説の検証 2. の仮説立証後,1.の性質が学習時にも成り立つかの検証,また3値量子化での学 習可能性の検証 具体的には,まず第二章で 1.について検証する.学習後のDNNの荷重値を段階的に粗 い離散値に丸めていき,層数と隠れ素子数に対する識別性能の劣化について調べる.これ はDNNがそもそも浅い層構造のネットワークよりも離散化の丸め誤差に対して頑健性が あるかどうかがまだはっきりと示されていないことから検証して確かめる必要があるため である.第三章では2.について検証する.RR法をDNNの学習時に適用し,3値量子化 も含めた各離散幅における,層数と隠れ素子数に対する識別性能の劣化ついて調べ,本研 究による手法での量子化可能性を検証する.学習後のDNNが離散化による丸め誤差に対 して頑健性を示したとして,それが学習時に同様の性質を示すかどうかは別問題である. しかしながら,本研究では事前学習を用いてDNNを構成するため,DNNは学習開始時 点である程度DNNとして事前につくり込まれている.よって学習開始時点のDNNも既 に学習後のDNNと同様離散化の丸め誤差に頑健性を示すのではないかということが期待 できるので,検証する価値があると考えられる.
7
第
2
章
DNN
の層数と離散幅の関係
本章ではDNNの層を増やすことで荷重値離散化による丸め誤差への頑健性が向上する という仮説を検証する.まず本章では既に学習の終わったDNNを各離散幅で近傍値に丸 めることでDNNの層数と丸め誤差の頑健性について考察する.また,丸め誤差への頑健 性には隠れ素子の数が大きく影響すると考えられるので,1層あたりの隠れ素子数を一定 にした場合,ネットワーク全体での隠れ素子数を一定とした場合についてそれぞれ結果を 検証することで,層数の差による影響について考察する.2.1
実験条件
本実験ではMNISTの文字認識データセット[29]を用いた.MNISTのデータセットは 1文字あたりが28× 28のグレースケールで表現され,訓練用データが6万,テスト用データが1万のデータセットである.DNNに用いるモデルはDeep belief network[9]事前学
習にはRestricted Boltzmann Machine(RBM)を用いた.学習方式はStochastic Gradient
Descent(SGD)に則ってデータを 100文字ずつのミニバッチに分割してバッチ単位のオ
ンライン学習を行った.学習率を0.1,50epoch計算させる間モメンタム(momentum)は
20epochまで0.5,50epochまでは0.9とした.荷重減衰(weightdecay)は0.002 として
学習を行った.DNNのfine-tuningでは事前学習と同様100文字ずつのミニバッチによる SGDで学習率を0.1 とし,モメンタムや荷重減衰は加えずに学習を行った.比較として 荷重値を離散化する前の学習後の結果を図2.1に示す.図2.1の結果は30∼8000の隠れ 素子数を用いて3層,4層,5層,6層に対して19,46,53,38種類(付録C参照)の DNNを構成した識別結果である.これをみると,層数を増やすことでエラーが減少傾向 にあることがわかる.6層の結果は5層より若干悪くなっているが,これはMNISTのよ うな簡単なデータセットに対して層を重ねすぎたことでネットワークの冗長性が増し,局 所最適値にトラップされやすくなってしまったためだと考えられる.
8 第2章 DNNの層数と離散幅の関係
2
3
4
5
6
7
0.01
0.015
0.02
0.025
0.03
0.035
0.04
The number of layers
Miss Classification Rate
図2.1 各層数でのDNNの誤認識率
2.2
様々な構造での各層数の認識性能劣化比較
図2.2は図2.1で示したネットワークのうち,各層数ごとに構造のことなる6つをピッ クアップし,2のベキ乗の離散幅で近傍値に丸めた結果である.離散幅を2のベキ乗とし たのは離散値を表現するのに必要な bitを見積もるためであり,またハードウェア化の際 には乗算をシフト演算によって簡単に行うことができるからである[21].この際,DNN の構造によって荷重値の分布は異なっており,対等に評価するため活性化関数のゲインを 調整することで[-1,1]の正規化を行った.具体的には,各層間での活性化関数の計算を yi = sigmoid(β ∑ j wijxj) (2.1) = sigmoid(β∑ j |wij|max· wijnormalizedxj) (2.2) = sigmoid(β|wij|max ∑ j wijnormalizedxj) (2.3) のように変形した.ここでwij は荷重値,xj は入力でyi が活性化関数の出力である. ただし,バイアスは常に1を出力する素子が入力側にあるものとしてその荷重値をバイア2.2 様々な構造での各層数の認識性能劣化比較 9 スbとして扱っている.つまりx0 = 1,wi0 = bi として ∑ j wijxj = wi0x0+ wi1x1+ wi2x2+· · · + winxn (2.4) である.|wij|maxは各層間における荷重値の絶対値の最大値,wijnormalizedは正規化さ れた荷重値を表す.実際の計算では離散化するのはwnormalizedij であり,ゲインは連続値 としてβ ← β|wij|maxとする. 図2.2について横軸は離散幅に対応している,これをみると,層数が多い方がどのよう な構造に対しても安定して同程度に丸め誤差に対して頑健性を示しているようにみえる. 一方3層の場合は構造によって大きなばらつきが見える.ただ,重要なのはエラーの上が り際での比較である.ここで,エラーがあまり悪化しすぎていない離散幅2−6 の場合に 注目して各層の性能を比較すると,結果は図2.3のようになった.ここで,originalは図 2.1のグラフに対応する.離散化の前後を比べてみると,層数が増えるほど離散化による 丸め誤差による性能劣化が緩和される傾向にあるのがわかる.離散幅が2−6 で性能劣化 が始まる理由としては議論が難しいが,本実験では荷重値1つあたりの離散値表現に必要 なbit数nbitはnbit=(符号bit)+(整数bit)+(小数bit)のように表すことにすると,荷重値
の正規化を行っているので(整数bit)=1bitであることに注意すると n = 1 + 1 + x = 2 + x (2.5) であるから離散幅 2−6 を表現するのに必要なbit数は8bitとなる.離散荷重値での学習 では精度を落とさず学習するのに最低でも8bit必要であると主張している論文はいくつ か存在しており,本実験の結果もそれに準じた結果なのではないかと推測される.文献 [30]によると,8bit以下の精度では0に丸められてしまう荷重値の数が急激に増えるため であるという考察もなされている.おそらくこれは荷重減衰によって荷重値の分布がガウ ス分布の形をとっており,多くの荷重値が0近傍の値をとるようになったためだと考えら れる.
10 第 2 章 DNN の層数と離散幅の関係 −100 −9 −8 −7 −6 −5 −4 −3 −2 −1 0 1 0.2 0.4 0.6 0.8 1
discrete grid(2
x)
Miss Classification Rate
The number of layers = 3
784−30−10 784−100−10 784−300−10 784−500−10 784−1000−10 784−1500−10 −100 −9 −8 −7 −6 −5 −4 −3 −2 −1 0 1 0.2 0.4 0.6 0.8 1
discrete grid(2
x)
Miss Classification Rate
The number of layers = 4
784−500−300−10 784−500−500−10 784−1000−1000−10 784−100−100−10 784−300−300−10 784−2000−2000−10 −100 −9 −8 −7 −6 −5 −4 −3 −2 −1 0 1 0.2 0.4 0.6 0.8 1
discrete grid(2
x)
Miss Classification Rate
The number of layers = 5
784−500−300−100−10 784−500−500−500−10 784−1000−1000−1000−10 784−100−100−100−10 784−300−300−300−10 784−2000−2000−2000−10 −100 −9 −8 −7 −6 −5 −4 −3 −2 −1 0 1 0.2 0.4 0.6 0.8 1
discrete grid(2
x)
Miss Classification Rate
The number of layers = 6
784−500−300−100−30−10 784−500−500−500−500−10 784−1000−1000−1000−1000−10 784−100−100−100−100−10 784−300−300−300−300−10 784−2000−2000−2000−2000−10 図2.2 各離散幅に対する誤認識率
2.3 1層あたりの隠れ素子数を一定とした場合 11
2
3
4
5
6
7
0
0.05
0.1
0.15
discrete grid = 2
−6The number of layers
Miss Classification Rate
rounding 2
−6grid
original
図2.3 各層数でのDNNの誤認識率2.3
1
層あたりの隠れ素子数を一定とした場合
離散化による丸め誤差への頑健性には隠れ素子の数にも大きく影響することが予想され る.隠れ素子と層数でどちらが離散化の丸め誤差に対して支配的な影響力を持っているか を定量的に評価するため,1層あたりの隠れ素子数を一定として,隠れ素子数が100,250, 300,375,500,1000,2000の場合について調べた.結果は図2.4,2.5のようになった.12 第 2 章 DNN の層数と離散幅の関係 3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=100
3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=250
3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=300
3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=375
3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=500
3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=1000
3 4 5 6 0 0.2 0.4 0.6 0.8 1
The number of layers
Miss Classification Rate
Hidden units per layer=2000 21 20 2−1 2−2 2−3 2−4 2−5 2−6 2−7 2−8 2−9 2−10 図2.4 1層あたりの隠れ素子が100∼2000の層数に対する誤認識率比較
2.3 1 層あたりの隠れ素子数を一定とした場合 13 1000 200 300 500 1000 2000 0.2 0.4 0.6 0.8 1
The number of all hidden units per layer
Miss Classification Rate
The number of layers=3
1000 200 300 500 1000 2000 0.2 0.4 0.6 0.8 1
The number of all hidden units per layer
Miss Classification Rate
The number of layers=4
1000 200 300 500 1000 2000 0.2 0.4 0.6 0.8 1
The number of all hidden units per layer
Miss Classification Rate
The number of layers=5
1000 200 300 500 1000 2000 0.2 0.4 0.6 0.8 1
The number of all hidden units per layer
Miss Classification Rate
The number of layers=6
21 20 2−1 2−2 2−3 2−4 2−5 2−6 2−7 2−8 2−9 2−10 図2.5 各層数での1層あたりの隠れ素子数に対する誤認識率比較
14 第2章 DNNの層数と離散幅の関係 図2.4,2.5について,パラメータは離散幅であり,上から順に離散幅が大きいものに対 応している.図2.5は図2.4について隠れ素子数で比較するための別の視点として用意し た.まず図2.4に注目すると,概して層数が多いネットワークの方が丸め誤差に対して頑 健性を示していると言える.隠れ素子が500∼2000の場合では5層でのエラーが4,6層 に比べて高くなっている.これは荷重値の分布が事前学習での荷重減衰の影響でガウス分 布で分布しており大半が0近傍の値をとっているため,隠れ素子数が増えることで0に 丸められる荷重値が増えてしまい,結果として全体の誤差がネットワーク全体で許容でき る誤差よりも大きくなってしまうためだと考えられる.図2.5についても同様のことが言 え,層数の増加に比べて,隠れ素子を増加が必ずしも丸め誤差に対する頑健性を向上させ るとは限らないのだと言える.
2.4
ネットワーク全体での隠れ素子数を一定とした場合
続いて,ネットワーク全体の隠れ素子数を一定とした場合の結果についても評価する. 結果はそれぞれ図 2.6∼2.8のようになった.また,層数を一定として各層数ごとにネッ トワーク全体の隠れ素子数で比較した場合は図2.9となった.パラメータは先程と同様離 散幅であり,各図のグラフは上から離散幅が大きい順に対応している.3
4
5
6
0
0.2
0.4
0.6
0.8
1
The number of layers
Miss Classification Rate
The number of all hidden units=500
2
12
02
−12
−22
−32
−42
−52
−62
−72
−82
−92
−10 図2.6 ネットワーク全体の隠れ素子が500の場合の層数に対する誤認識率2.4 ネットワーク全体での隠れ素子数を一定とした場合 15
3
4
5
6
0
0.2
0.4
0.6
0.8
1
The number of layers
Miss Classification Rate
The number of all hidden units=1000
2
12
02
−12
−22
−32
−42
−52
−62
−72
−82
−92
−10 図2.7 ネットワーク全体の隠れ素子が1000の場合の層数に対する誤認識率3
4
5
6
0
0.2
0.4
0.6
0.8
1
The number of layers
Miss Classification Rate
The number of all hidden units=1500
2
12
02
−12
−22
−32
−42
−52
−62
−72
−82
−92
−10 図2.8 ネットワーク全体の隠れ素子が1500の場合の層数に対する誤認識率16 第 2 章 DNN の層数と離散幅の関係 5000 1000 1500 0.2 0.4 0.6 0.8 1
The number of all hidden units
Miss Classification Rate
The number of layers=3
5000 1000 1500 0.2 0.4 0.6 0.8 1
The number of all hidden units
Miss Classification Rate
The number of layers=4
5000 1000 1500 0.2 0.4 0.6 0.8 1
The number of all hidden units
Miss Classification Rate
The number of layers=5
5000 1000 1500 0.2 0.4 0.6 0.8 1
The number of all hidden units
Miss Classification Rate
The number of layers=6
21 20 2−1 2−2 2−3 2−4 2−5 2−6 2−7 2−8 2−9 2−10 図2.9 各層数でのネットワーク全体の隠れ素子数に対する誤認識率比較
2.5 2章のまとめ 17 図2.6∼2.8 をみると,やはり層数が増えることでエラーが低く抑えられていることか ら,離散化による丸め誤差による性能劣化が緩和されており,層数の多いネットワークほ どより頑健性を示していると言える.一方,図2.9をみて分かるように,各層数において ネットワーク全体の隠れ素子数の変化は層数の変化に比べてエラーの上下には影響しない と言える.
2.5
2
章のまとめ
本章では,学習後のDNNの荷重値を段階的に粗い離散値に丸めていき,層数と隠れ素 子数に対する識別性能の劣化について調べた.本章が主張することは以下の通りである. 1. 層数の多いネットワークほど丸め誤差に対する頑健性はネットワークの構造によら ず安定して良くなる傾向にある(図2.2,2.3). 2. DNNは1層あたりの隠れ素子数を増やすよりも単純に層を増やすことで丸め誤差 に対して頑健性が増す(図2.4∼2.9). 3. むしろ1層あたりの隠れ素子数を増やしていくとエラーが増大する傾向があった. これは,大部分の荷重値がプレトレーニングにおける荷重減衰により0付近に分布 していたことで隠れ素子数の増大に比例して丸め誤差の悪影響が大きくなったため だと考えられる(図2.5). 4. 離散幅は2−6 程度であればDNNの識別性能に大きな影響を与えない.この結果 は学習後のパラメータを近傍値に丸めただけの結果であり,確率的遷移を行って学 習を進めるRR法を用いて学習すれば,さらに粗い離散値でも良い結果が得られる と期待できる.よって,これは3章で丸め誤差に対する指標として用いる.19
第
3
章
離散荷重値
DNN
の学習
本章ではRandomized Rounding法(RR法)をDNNの学習に適用し,3値量子化も含 めた各離散幅における層数と隠れ素子数に対する識別性能の劣化について調べ,本研究に よるアプローチでのDNNの量子化可能性について検証する.3.1
実験設定
第2章では層数の多いネットワークが丸め誤差に対して頑健性を示す傾向があることを 示したが,これが学習においても成り立つとは限らない.しかしプレトレーニングによる 事前のつくり込みによって最上層間以外の結合荷重値がDNNとして最適な値に比較的近 いと仮定すれば,DNNのfine-tuning(BP学習)においても2章で示したような離散値へ の丸め誤差に対する頑健性を同様に見出せると期待される.加えて,離散値で学習を行う 方法として有望な手法であるRR法を用いることでDNNが2章の結果より幅の大きな離 散化でも学習できることが期待されることから,このアプローチによって荷重値の量子化 を行った場合DNNにどの程度の識別性能の劣化が起こるかを検証することは意義がある と考えられる. 本研究では,プレトレーニングは連続値(浮動小数点表現)で行っている.プレトレー ニングから離散値をで学習する場合も興味深くはあるが,離散荷重値はしばしば連続荷重 値に比べ情報の欠落を伴う.プレトレーニングでは前のRBMからの隠れ層の状態を用い て次のRBMを学習させることを考えると,離散荷重値でのプレトレーニングはプレト レーニングとして有効な方法になり得るとは考えがたい.また,そもそもRBM単体の学 習ではメモリ不足の問題は起きないと考えられるので,連続荷重値でプレトレーニングを 行うことはDNNを離散荷重値で学習させるための合理的な戦略であると考えられる. 従来の量子化学習手法では,連続値で学習した後ゲインについても勾配法により学習を 行うが,本研究ではプレトレーニングを行ったあとRR法による学習を採用している.プ20 第3章 離散荷重値DNNの学習 レトレーニングによってDNN全体のパラメータがほぼ最適に近いということ,離散幅の 大きな荷重値を用いる場合には小さな相関は無視されるということを考え,本研究では各 エポックごとに更新された荷重値を[-1,1]に正規化してRR法による離散化を施す.具体 的には2章と同様に荷重値の正規化のために各層間における荷重値の絶対値の最大値を次 のステップのゲインとして学習させる.
3.2
1
層あたりの隠れ素子数を一定としたときの離散幅をパ
ラメータとした層数に対するエラー
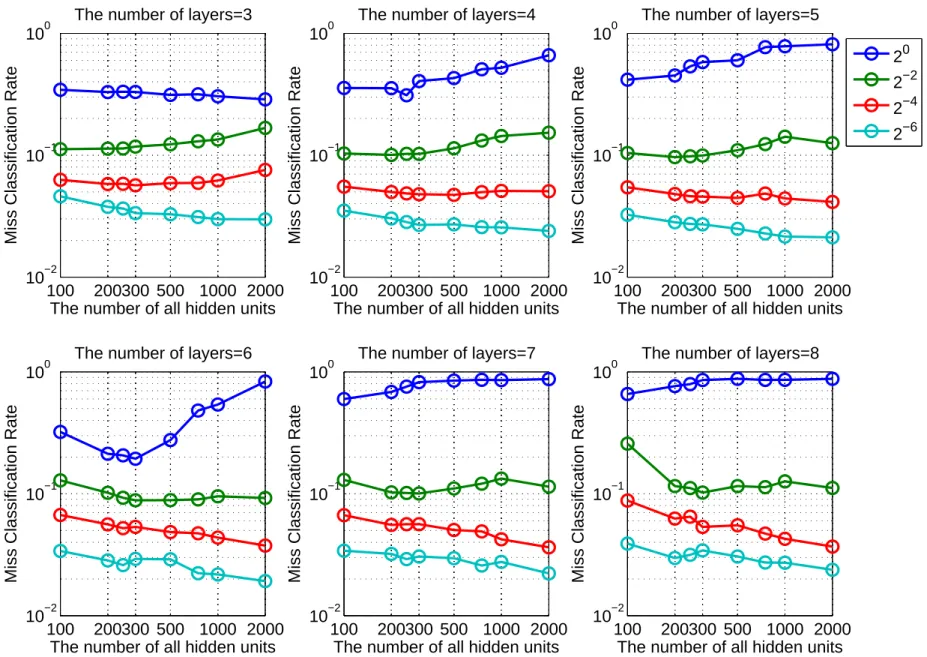
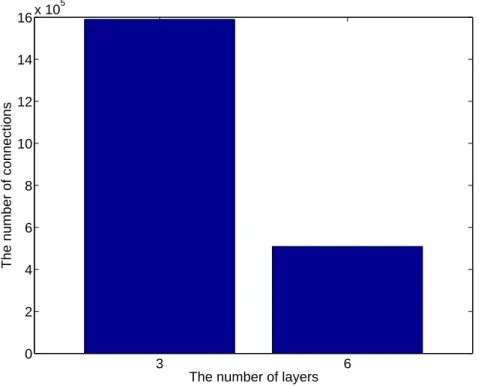
学習には時間がかかるため,本章では1層あたりの隠れ素子数を一定とした層数に対す るエラーにおける結果のみについて実験を行った.2章と同様,隠れ素子と層数でどちら が離散化の丸め誤差に対して支配的な影響力を持っているかを定量的に評価するため,1 層あたりの隠れ素子数が100,200,250,300,500,750,1000,2000の場合について, 各隠れ素子数での層数別比較(図3.1)と,各層数での隠れ素子数別比較(図3.2)の2つの 視点から考察を行う. 図3.1,3.2)の各図においてパラメータは離散幅を表しているが,本章の実験ではRR 法による学習を行っているので性能は第 2章の結果よりも良くなると見込めたので離散 幅20∼2−6 について実験した.離散幅が 20 のときが3 値の量子化に対応する.まず図 3.1 について,縦軸の誤認識率が対数になっていることに注意すると,隠れ素子数が100 ∼500の範囲では層数が6層の量子化学習の場合の方が3層の量子化学習の場合よりもよ くなるという結果が得られた.隠れ素子数が 300の場合では3層の場合よりも10%程度 性能劣化が緩和されたと言える.他の離散幅では概ね層数が増えるに従ってエラーが減少 し,さらに増えると上昇するという傾向を示した.これはMNISTデータセットに対して ネットワークが冗長になりすぎ,局所解に収束しやすくなったためだと考えられる.次に 図3.2をみると,量子化の場合は層数が6層のとき隠れ素子300で正解率81%と最も良 い結果となった.一方層数が3層の場合では隠れ素子を増やすことでエラーが減少し,隠 れ素子数2000の場合で71%という結果となった.よって層数を増やすことで10%の性 能劣化の緩和が得られていると言える.さらに荷重値の数を比較してみると(図3.3),3 層のときは1,590,010個,6層のときは509,410個であり必要なメモリは3層から6層に することで3分の1まで減少したと言える.さて,他の離散幅については2章の結果と異 なり,離散幅が大きくなるほど隠れ素子が増えるに従ってエラーが下がる傾向にあった. これはRR法の学習によるパラメータ最適化効果がうまく働いたのだと考えられる.特に 離散幅 2−6 では連続値の場合と同程度のエラーを維持し,ほとんど劣化がみられなかっ た.よってMNISTが簡単なデータセットであることを考えると,学習においては少なく3.2 1層あたりの隠れ素子数を一定としたときの離散幅をパラメータとした層数に対するエラー21
22 第 3 章 離散荷重値 DNN の学習 3 4 5 6 7 8 10−2 10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=100
3 4 5 6 7 8 10−2
10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=200
3 4 5 6 7 8 10−2
10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=250
3 4 5 6 7 8 10−2
10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=300 20 2−2 2−4 2−6 3 4 5 6 7 8 10−2 10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=500
3 4 5 6 7 8 10−2
10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=750
3 4 5 6 7 8 10−2
10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=1000
3 4 5 6 7 8 10−2
10−1 100
The number of layers
Miss Classification Rate
Hidden units per layer=2000
3.2 1 層 あ た り の 隠 れ 素 子 数 を 一 定 と し た と き の 離 散 幅 を パ ラ メ ー タ と し た 層 数 に 対 す る エ ラ ー 23 100 200300 500 1000 2000 10−2 10−1 100
The number of all hidden units
Miss Classification Rate
The number of layers=3
100 200300 500 1000 2000 10−2
10−1 100
The number of all hidden units
Miss Classification Rate
The number of layers=4
100 200300 500 1000 2000 10−2
10−1 100
The number of all hidden units
Miss Classification Rate
The number of layers=5
100 200300 500 1000 2000 10−2
10−1 100
The number of all hidden units
Miss Classification Rate
The number of layers=6
100 200300 500 1000 2000 10−2
10−1 100
The number of all hidden units
Miss Classification Rate
The number of layers=7
100 200300 500 1000 2000 10−2
10−1 100
The number of all hidden units
Miss Classification Rate
The number of layers=8
20 2−2 2−4 2−6
24 第3章 離散荷重値DNNの学習 3 6 0 2 4 6 8 10 12 14 16x 10 5
The number of layers
The number of connections
図3.3 3層隠れ素子2000と6層隠れ素子1層あたり300の荷重値数比較
3.2.1
各層数におけるエラー推移と学習の収束傾向
エラーが高い場合と低い場合についての差を考察するため学習中のエラーの推移を示す (以下,学習推移曲線と呼称する).学習推移曲線は離散荷重値でRR法を用いると図3.4 の各図のように振動していた.これは荷重値が確率的に遷移しているためだと言える.3 層から6層を比べてみると,3層と6層の場合は量子化でも振動の幅が小さいが,4層5 層の場合は振動が大きくなってしまっていた.これは,荷重値の離散グリッド上の点が極 小値から遠かったためだと考えられる.これらの振動は学習率を逐次的に下げていくこと で一定値に収束させることも可能だと思われる. RR法を用いた量子化結合ニューラルネットワークは情報が欠落して精度が落ちている が,図3.4での3層6層のように学習がうまくいく場合には学習が早い段階である一定値 に漸近しているのではないかということが考えられる.図 3.5では隠れ素子250で特に6 層の場合の学習推移グラフについてスプライン近似を行い,その1次微分をとることで学 習推移の勾配をとり,学習推移の収束性の評価を試みた.ただし,epoch1∼4については 変化が急すぎるためスプライン近似ができなかったので差分近似によって勾配を簡略的に 求めた.4∼100epochについては変化が小さいので,拡大図を添付した.量子化の場(離 散幅20)をみると,他の離散幅よりも早めに収束しているのが確認できる.この収束の早3.2 1層あたりの隠れ素子数を一定としたときの離散幅をパラメータとした層数に対するエラー25 0 20 40 60 80 100 0 0.2 0.4 0.6 0.8 1 epoch
Miss Crassification Rate
The number of layers = 3 20
2−2 2−4 2−6 0 20 40 60 80 100 0 0.2 0.4 0.6 0.8 1 epoch
Miss Crassification Rate
The number of layers = 4
20 2−2 2−4 2−6 0 20 40 60 80 100 0 0.2 0.4 0.6 0.8 1 epoch
Miss Crassification Rate
The number of layers = 5
20 2−2 2−4 2−6 0 20 40 60 80 100 0 0.2 0.4 0.6 0.8 1 epoch
Miss Crassification Rate
The number of layers = 6
20 2−2 2−4 2−6 図3.4 隠れ素子250での各離散幅における学習推移グラフ 1 2 3 4 10 20 40 60 80 100 −0.9 −0.8 −0.7 −0.6 −0.5 −0.4 −0.3 −0.2 −0.1 0 0.1 epoch first derivative 4 10 20 40 60 80 100 −2 −1 0 1 2x 10 −3 epoch
Enlarged view of first derivative
20 2−2 2−4 2−6 original 図3.5 隠れ素子250での各離散幅における学習推移グラフの勾配による収束 さはオリジナルを除いて離散幅が大きいほど収束が早い傾向にあった.量子化の場合では 70epoch程度でエラーの上昇が確認できたが,これはRR法によって荷重値がよくない極 小点に移動してしまったためだと考えられる.
26 第3章 離散荷重値DNNの学習
3.3
3
章のまとめ
本章ではRR法をDNNの学習時に適用し,3値量子化も含めた各離散幅における,層 数と隠れ素子数に対する識別性能の劣化ついて調べ,本研究による手法での量子化可能性 を検証した.本章が主張することは以下の通りである. 1. 多層の量子化結合ニューラルネットワークは,6層の場合で3層のネットワークに 比べて識別性能が著しく向上しているものの存在が確認できた. 2. 3 層のように層が浅い場合でも隠れ素子数を増やすことで性能劣化を緩和できる が,6層の場合ではより少ない荷重値数で性能劣化の緩和効果を得られた. 3. 離散幅が大きくなるにつれ,学習推移曲線は振動するようになる.これは各層数で の荷重値空間の離散グリッド上に極小値が載っているとは限らないからである.し かし,6層のネットワークのように量子化と比較的相性の良い構造も存在する可能 性がある. 4. 量子化によって精度が犠牲になった反面,収束が早いことからぎりぎりまで良い精 度を出すために計算時間をかける必要はなくなったとも言える.この量子化結合 ニューラルネットワークを弱学習器としてアンサンブル学習させることで高精度の 学習器を比較的高速に構成することが可能になると期待できる.27
第
4
章
結論
本研究ではDNN のメモリ面積の削減を行うことを目的として,DNNの量子化結合 ニューラルネットワークを学習により構成することを試みた. • 第二章では,層数を増やすことでDNNの丸め誤差に対する頑健性が向上すること を示した.この性質から,量子化結合ニューラルネットワークを構成すること目指 す上で既存の離散化手法に多層化を組み合わせることが有効な戦略であることを示 唆した. • 第三章では,既存の有望な離散化手法であるRR法にゲインの正規化を加えること で,DNNの量子化結合ニューラルネットワークを学習により構成することを試み た.6層の場合には3 層の場合の誤認識率を下回るものが確認でき,量子化結合 ニューラルネットワークにおいても多層化が識別性能の向上につながる事例を示 した. • また,6層の最良の場合は3層の最良の場合より3分の1以下の荷重値数で10%性 能劣化の緩和に差がみられた.よって多層にすることが量子化結合ニューラルネッ トワークに必要なメモリをさらに削減することにもつながる可能性を示した. • 量子化によって,情報は欠落し性能の劣化は避けられないことから,精度にある程 度こだわる必要がある場合は離散化や多値の量子化を行うことが適度にメモリを削 減する方法として無難であるかと思われる.しかし,3値の量子化を行うことはメ モリを大幅に削減するだけでなく,簡単な演算のみで演算を行えることから計算量 も減らせるという利点がある.さらに,本手法による量子化学習は収束が早いこと から1つあたりのネットワークの学習に必要な計算量を抑えられる.これらの性質 をうまく利用する方法としてアンサンブル学習が有効な手法だと考えられ,これに より精度自体の向上も見込め,実用性が期待できると考えられる.29
付録
A
RBM
の学習
本研究でDNNのプレトレーニングに用いているRestricted Boltzmann Machine(RBM)[31] の学習について説明する.
A.1
Boltzmann Machine
との関係
RBMは隠れ素子ありのBoltzmann Machine(BM)[17]について,可視素子同士,隠れ素
子同士の結合を排除する制限を加えた学習モデルである.RBMはBMとしての一般性を
失わず,BMと同様の学習器として扱うことができる.これを以下に示す.
あるマルコフ確率場(Markov random fields,MRF)を考えたときに,確率変数S1,· · · , Sn
を持つ有限個のサイトとサイト間の双方向の確率的結合を,それぞれノードの集合 V と エッジの集合E に対応させた無向グラフG = (V, E)で表すことにする.このとき,MRF は無向グラフィカルモデルとも呼ばれる.BMはこの無向グラフィカルモデルに属するモ デルとしてみることができる. ここで,無向グラフGをノード間が完全結合しているような集合であるクリークに分割 することを考える.このとき,各クリークにおけるエネルギー関数をVC とおくと,MRF の結合確率P (s) = P (S1 = s1,· · · , Sn = sn)は, P (s) = 1 Z exp ( −∑ C Vc ) (A.1) と書くことができる[32].Zは正規化定数である.今,クリークのサイズの最大値を2と して式(A.1)をサイズ1のクリークのエネルギー関数Vi(1), (i ∈ V )とサイズ2のクリー クのエネルギー関数Vij(2), ((i, j)∈ E)で表すことを考えると, P (s) = 1 Z exp ( −(∑ i∈V Vi(1)+ ∑ (i,j)∈E Vij(2) )) (A.2)
30 付録A RBMの学習 ここで,RBMの結合確率は可視バイアスbv i と隠れバイアスbhi,結合荷重値wij をそ れぞれVi(1) とVij(2) に対応させて表せて, P (v, h) = 1 Z exp ( −(( Nv ∑ i bvivi+ Nh ∑ i bhihi) + Nv ∑ i Nh ∑ j 1 2wijvihj )) (A.3) と書ける.ただし,s = (v, h) = (v1,· · · , vNv, h1,· · · , hNh)とした.よって,RBMの 定常状態の結合確率もボルツマン分布となることから,RBMはBMとしての一般性を失 わず,少なくともBMと同様の学習則を適用することができる.
A.2
RBM
を「学習させる」とは
式(A.3)で示したRBMの結合確率を,新たに学習パラメータΘ ={bv, bh, w}を明示 して表すと, P (v, h|Θ) = 1Z(Θ) exp(−E(v, h|Θ)) (A.4)
Z(Θ) =∑
v
∑
h
exp(−E(v, h|Θ)) (A.5)
ここで,Z(Θ)は可視素子と隠れ素子が実現可能な全ての状態の足し合わせということで あり, ∑ v ∑ h := ∑ v1=±1 ∑ v2=±1 · · · ∑ vNv=±1 ∑ h1=±1 ∑ h2=±1 · · · ∑ hNh=±1 (A.6) である.E(v, h|Θ)はエネルギー関数で E(v, h|Θ) = − Nv ∑ i bvivi− Nh ∑ i bhihi− Nv ∑ i Nh ∑ j wijvihj (A.7) である. ここで,式(A.4)をみると,RBMにおいて,あるパラメータのもとでどの状態が出や すくなるかはエネルギー関数の高低によって決まってくることが分かる.具体的にはエネ ルギーが低い状態ほど頻出しやすくなっている.そして,ある状態のエネルギー関数の高 低を決めているのは式(A.7)であることが分かる.よって,RBMはこれら学習パラメー タをうまく調整することで所望のパターンを生成させることが期待できる.これが,BM やRBMがパターン認識器として有用であるとされる理由だと考えられる.RBMの「学 習」は学習パラメータを入力データに従って自動的に調整することを指している.
A.3 RBMの学習則の導出 31
A.3
RBM
の学習則の導出
A.3.1
KL
情報量からの導出
RBMをDNNの構成要素として用いる場合,RBMが生成すべき所望のパターンは入 力となる観測データセットのパターンである.つまり,RBMは本質的には教師無し学習 を行っているが,RBMの可視層は入力層であると同時にパターンを生成する出力層とし ての役割を持つため,入力を教師とした教師有り学習とみることもできるだろう.以下で は,各パターンの集合をパターンの確率分布で表現することにし,RBMが可視変数の確 率分布を観測データセットの確率分布に近づけるための学習方法について説明する. 今,RBMに学習させたいある真の分布からN個の観測データを入手できたとする.本 当は真の分布を入力分布とすることが望ましいが,真の分布は分からないのでNが十分 大きければそのサンプル平均が真の分布に近似できると仮定する.これによって得られた 観測データセットのサンプル平均による分布を経験分布q(v)と定義すると,q(v)は以下 のように書ける. q(v) := 1 N N ∑ µ=1 δ(v, x(µ)) (A.8) ここで,x(µ) はµ番目の観測データで, x(µ) = (x(µ)1 , x(µ)2 ,· · · , x(µ)N v) (A.9) のように表される. 一方,RBMの可視変数の確率分布はA.4の結合確率を隠れ変数について周辺化したも のになるので,以下のように表される. Pv(v|Θ) = ∑ h P (v, h|Θ) (A.10) これらの確率分布の近さを表す尺度としてKullback-Leibler情報量(KL情報量)を用い ると, KL[q(v)||Pv(v|Θ)] = ∑ v q(v) ln q(v) Pv(v|Θ) =∑ v q(v) ln q(v)−∑ v q(v) ln Pv(v|Θ) (A.11)32 付録A RBMの学習 ここで,式(A.11)の第1項はRBMの学習パラメータによらず一定である.よって,第2 項を最小化することがRBMの学習の目的になる.また,第2項は負の対数尤度関数であ り,KL情報量の最小化は最尤推定における尤度最大化と等価であることが分かる. KL情報量を最小化するように学習パラメータを調整するには学習パラメータについて 負の勾配をとれば良い.今,学習パラメータΘについての負の勾配をとると, −∂KL[q(v)||Pv(v|Θ)] ∂Θ = ∑ v q(v)∂ ln Pv(v|Θ) ∂Θ =∑ v q(v) ∂ ∂Θln ∑ h P (v, h|Θ) =∑ v q(v) ∂ ∂Θln ∑ h 1 Z(Θ) exp(−E(v, h|Θ)) =∑ v q(v) ∂ ∂Θln ∑ h exp(−E(v, h|Θ)) −∑ v q(v) ∂ ∂Θln ∑ h Z(Θ) =−∑ v q(v)∑ 1 hexp(−E(v, h|Θ)) ∑ h ∂E(v, h|Θ) ∂Θ exp(−E(v, h|Θ)) − 1 Z(Θ) ∂Z(Θ) ∂Θ =−∑ v ∑ h q(v)∂E(v, h|Θ) ∂Θ exp(−E(v, h|Θ)) ∑ hexp(−E(v, h|Θ)) + 1 Z(Θ) ∑ v ∑ h ∂E(v, h|Θ) ∂Θ exp(−E(v, h|Θ)) ここで,ベイズの定理より,可視変数固定のもとでの隠れ変数の条件付き確率は, Ph|v(h|v, Θ) = P (v, h|Θ) Pv(v|Θ) = ∑exp(−E(v, h|Θ)) hexp(−E(v, h|Θ)) (A.12) よって, −∂KL[q(v)||Pv(v|Θ)] ∂Θ =− ∑ v ∑ h q(v)Ph|v(h|v, Θ) ∂E(v, h|Θ) ∂Θ + 1 Z(Θ) ∑ v ∑ h ∂E(v, h|Θ) ∂Θ exp(−E(v, h|Θ))
A.3 RBMの学習則の導出 33 =−∑ v ∑ h ∂E(v, h|Θ) ∂Θ q(v)Ph|v(h|v, Θ) + ∑ v ∑ h ∂E(v, h|Θ) ∂Θ P (v, h|Θ) =−∑ v ∑ h ∂E(v, h|Θ) ∂Θ q(v)Ph|v(h|v, Θ) + ∑ v ∑ h ∂E(v, h|Θ) ∂Θ P (v, h|Θ) =− ⟨ ∂E(v, h|Θ) ∂Θ ⟩ q(v)Ph|v(h|v,Θ) + ⟨ ∂E(v, h|Θ) ∂Θ ⟩ P (v,h|Θ) (A.13) 式(A.13) の第1 項と第2 項の期待値は,それぞれ可視変数を経験分布で固定した時の RBMの結合確率分布による期待値と,固定していないRBMの結合確率分布による期待 値である.第1項については,RBMの層内結合無しという制約から,各隠れ変数は可視 変数に対して条件付き独立が成り立つので,式 (A.14)を用いて期待値計算を容易に行う ことができる. Ph|v(h|v, Θ) = Nh ∏ i=1 p(hi = 1|v, Θ) = Nh ∏ i=1 sigmoid (N v ∑ j=1 wijvj + bvi ) (A.14) 一方,第2項は容易に期待値計算することが難しい.これは RBMの結合確率が式(A.4) で表されるため,正規化定数Z(Θ)を求めるために,可視変数と隠れ変数の実現可能な全 ての状態について計算する必要があるためである.全ての素子の状態が{0,1}や{-1,1}の2 状態である場合,正規化定数Z(Θ)を求めるには2Nv+Nh 回計算を行う必要があるため, 素子数が増えることで計算量が爆発してしまい,現実的な時間で計算することができない という問題がある.よって実際の計算には近似的な手法を用いる必要がある.RBMの学 習ではContrastive Divergence法(CD法)と呼ばれる近似手法が用いられる.
A.3.2
Contrastive Divergence
法
(CD
法
)[33]
通常の無向グラフィカルモデルではマルコフ連鎖モンテカルロ法(MCMC法)などによ るサンプリング法によって近似的な結果を得るが,これらサンプリング法は計算に時間が かかるという難点がある.CD法は本質的にMCMC法の1種であるギブスサンプリング であるが,前述した条件付き独立性に加えサンプリング回数を途中で打ち切ることで,高 速に近似解を求めることを可能にしている.以下ではCD法について説明する. CD法は図A.1のように可視変数に経験分布を入力として固定した状態を初期状態とし て,可視変数固定のもとで隠れ変数をサンプリング,隠れ変数固定のもとで可視変数をサ ンプリングを交互に繰り返す.各可視変数はRBMの制約より隠れ変数に対して条件付き 独立である.よって式(A.14)と同様に式(A.15)で表されるので,並列にサンプリングを
34 付録A RBMの学習 図A.1 CD法の模式図 行うことができる利点がある. Pv|h(v|h, Θ) = Nv ∏ i=1 p(vi = 1|h, Θ) = Nv ∏ i=1 sigmoid (N h ∑ j=1 wijhj + bhi ) (A.15) 交互のサンプリングによって得られた状態を,経験分布を初期値として順に v → h → ˆv1 → ˆh1 → · · · → ˆvk → ˆhk と表すと,式(A.13) の第1項の結合確率分布 q(v)Ph|v(h|v, Θ) を表すのがサンプル v, hの集合であり, 第2項の結合確率分布P (v, h|Θ)を近似的に表すのがk → ∞での サンプルvˆk, ˆhk の集合にあたる.しかし,実用上はk = 1でサンプリングを打ち切って しまっても大抵の場合は問題ない.これは解析的には級数展開によってギブスサンプリン グにおけるバリアンスを軽減していると解釈できるという主張がある[34].これにより, パラメータの微分値は最適な値に強く近似されていることが期待できる.また,RBMの 学習自体も事前学習の効果が現れる程度に適度に良い学習パラメータを学習できれば良 く,最適である必要がないからである.本研究でも実験は全てk=1で行った. また,本研究では文献[35]に従い,式(A.13)の第2項の期待値計算に用いる可視変数 と隠れ変数の状態v, ˆˆ hはサンプリングを行わず,サンプリングに用いる条件付き確率を そのまま用いた.つまり ˆ v = Pv|h(ˆv1|h, Θ) (A.16) ˆ h = Ph|v(ˆh1|ˆv1, Θ) (A.17) とした.これは,サンプリングノイズの軽減を目的としている.
A.3 RBMの学習則の導出 35
A.3.3
学習パラメータの更新
式(A.13)を,各学習パラメータについてCD法で得られたv, h, ˆv, ˆhを用いて変形する と以下の式が得られる.v, h, ˆv, ˆhが列ベクトル表示であることに注意すると, ∆w = vT · h − ˆvT· ˆh (A.18) ∆bv = v− ˆv (A.19) ∆bh = h− ˆh (A.20) ここで,∆w, ∆bv, ∆bh は各学習パラメータの更新量を表す.ただし, ∆Θ =−∂KL[q(v)||Pv(v|Θ)] ∂Θ (A.21) ∂E(v, h|Θ) ∂wij =−vi· hj (A.22) ∂E(v, h|Θ) ∂bv i =−vi (A.23) ∂E(v, h|Θ) ∂bhj =−hj (A.24) であることに注意する.最終的にパラメータの更新は,更新後をΘnew 更新前をΘold とすると,Θnew = Θold + ϵ∆Θ (A.25)
36 付録A RBMの学習
A.4
DNN
の事前学習への適用
RBMをDNNの事前学習に用いる場合には,「訓練データを入力として最初のRBMを 学習し,学習後にもう一度入力からCD法によりサンプリングされた隠れ層の状態を次の RBMの訓練データとして学習する」という操作を繰り返すことで任意の階層のDNNの 事前学習を行うことができる.実際には文献 [35]より,2値のサンプリングは行わず式 (A.17)に従った条件付き確率をそのまま次のRBMの入力として用いることが多い.これ はサンプリングノイズの軽減を目的としており,本研究もこれに従ってDNNを構成した. 図A.2 RBMによるDNNの事前学習37
付録
B
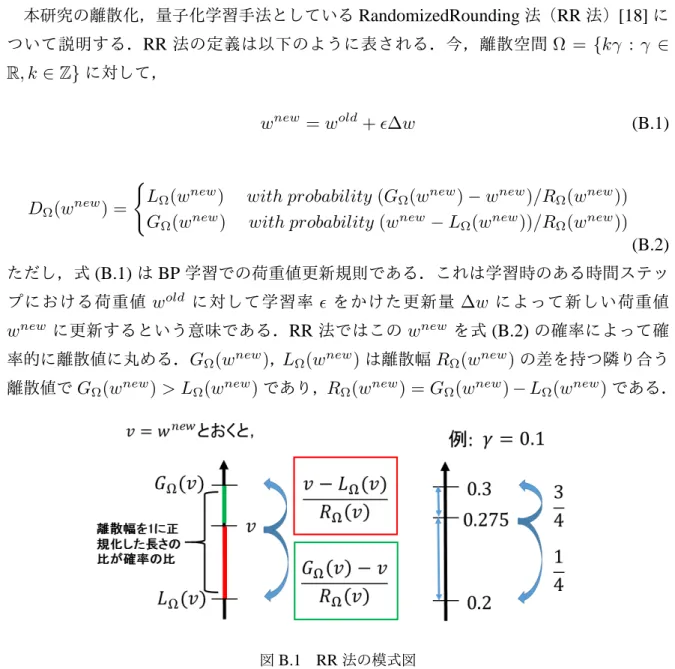
Randomized Rounding
法
本研究の離散化,量子化学習手法としているRandomizedRounding法(RR法)[18]に ついて説明する.RR法の定義は以下のように表される.今,離散空間 Ω = {kγ : γ ∈ R, k ∈ Z}に対して, wnew = wold+ ϵ∆w (B.1) DΩ(wnew) = {LΩ(wnew) with probability (GΩ(wnew)− wnew)/RΩ(wnew))
GΩ(wnew) with probability (wnew− LΩ(wnew))/RΩ(wnew))
(B.2)
ただし,式(B.1)はBP学習での荷重値更新規則である.これは学習時のある時間ステッ
プにおける荷重値 wold に対して学習率 ϵ をかけた更新量 ∆w によって新しい荷重値
wnew に更新するという意味である.RR法ではこのwnew を式(B.2)の確率によって確
率的に離散値に丸める.GΩ(wnew),LΩ(wnew)は離散幅RΩ(wnew)の差を持つ隣り合う
離散値でGΩ(wnew) > LΩ(wnew)であり,RΩ(wnew) = GΩ(wnew)− LΩ(wnew)である.
38 付録B Randomized Rounding法
ここで,RR法によって得られる離散値DΩ(wnew)の期待値は式(B.3)のように表され
る.
E(DΩ(wnew)) = wnew (B.3)
よって,離散化を行った後の離散値の期待値は離散化前の連続値に一致することから,離 散化を行っても連続値と同様の学習則を適用し,学習を進めることができるのだと考えら れる.
ただし,本研究では2のベキ乗で離散化を行うため,離散空間は以下のように定義され
る.
![図 2.1 各層数での DNN の誤認識率 2.2 様々な構造での各層数の認識性能劣化比較 図 2.2 は図 2.1 で示したネットワークのうち,各層数ごとに構造のことなる 6 つをピッ クアップし, 2 のベキ乗の離散幅で近傍値に丸めた結果である.離散幅を 2 のベキ乗とし たのは離散値を表現するのに必要な bit を見積もるためであり,またハードウェア化の際 には乗算をシフト演算によって簡単に行うことができるからである [21] .この際, DNN の構造によって荷重値の分布は異なっており,対等に評価す](https://thumb-ap.123doks.com/thumbv2/123deta/5909010.1050050/17.892.144.584.198.558/ネットワーククアップハードウェアシフトによっできるによっ.webp)