「画像の認識・理解シンポジウム (MIRU2011)」 2011 年 7 月
自由視点TVのための3次元復元画像群のモザイキング
松崎
隆
†鈴木
俊光
†高橋
和晃
†矢口
勇一
†岡
隆一
††
会津大学コンピュータ理工学研究科 〒 965–8580 福島県会津若松市一箕町鶴賀E-mail:
†{
m5151104,m5151101,yaguchi,oka}
@u-aizu.ac.jp,††
[email protected]あらまし 本論文では自由視点テレビの Occlusion 問題を解決するための手法を提案する. 以前に高橋らが提案した自 由視点テレビは 3 台の未校正カメラによって撮影された時系列画像に対して, 各フレーム毎に 2 次元連続 DP(2DCDP) を用いたピクセル毎の物体の運動計測を行い, 因子分解法により被写体の 3 次元モデルを復元するというものである が, 3 次元モデル復元の一般的な課題である Occlusion 問題が解決されていない. 本論文ではこのシステムのカメラ台 数を 6 台にし, 2 つの 3D モデルを復元し, それを合成することでの Occlusion 問題の改善手法を提案する. キーワード 自由視点テレビ, Occlusion 問題
1.
は じ め に
自由視点テレビ (FTV) は従来のテレビと異なり, ユー ザーが任意に視点を変更できる次世代型のテレビであ る. 現在のテレビがカメラに依存した方向からの映像 を 2 次元平面に映すのに対し, FTV ではユーザーが望 んだ視点からの映像を映し出すことが可能である [1]. 現 在, FTV の実現方式は大きく 2 種類に分けられており, 一つは view-based method と呼ばれる手法, もう一方は model-based methodと呼ばれる手法である. view-based methodは主として, 従来テレビのような 2 次元の自由視 点映像を作成する方式である. view-based method の特 徴は主としてオブジェクトの幾何情報を使用せずにエピ ポーラ線, カメラパラメータ等を利用し与えられた画像 群から光線空間等を元に 2 次元画像を再構成する. その ため, この方式では数十から数百の校正カメラを使用して 撮影された大量の画像が必要となる. 一方, model-based methodは得られた大量の画像群からシーンの 3 次元形 状を復元し, 描画して自由視点映像を生成する方式であ り, ステレオ視 [2], 照度差ステレオ法 [3], 因子分解法 [4], 視体積交差法 [5] 等が一般的に有名である. 高橋らは, 2 次元連続 DP(2DCDP)[6], 因子分解法と 3 台の未校正カ メラを用いて, カメラ校正が不要かつ実時間処理が可能 な方法で FTV の実現をした [7]. しかし, 現在前景のも のが背景のものを遮ることで生じる Occlusion 問題は解 決されていない. Occlusion 問題は 3 次元復元の一般的 な問題であり大きな課題でもある. この問題の一般的な 解決手法は復元する対象物を複数台のカメラで取り囲む ことである. このシステムでは 3 台のカメラでは復元で きる部分は限定され, それに映っていない部分は遮蔽さ れている. 本論文では高橋らが提案したシステムのカメ ラを 6 台にし, 3 台ずつ離れた場所から撮影し, それぞれ の 3D モデルを復元し, それらを合成することによって, この問題の改善手法を提案する. 以下 2 章では FTV の Reference image Corresponding pixels Segmentation area Input images 図2 画像スポッティング: 非線形最適ピクセルマッチングと 抽出を同時に行う. 対象画像中にある参照画像の個数に 制限はない. 構成, 3 章では提案手法, 4 章ではまとめを述べる.2.
自由視点 TV システム
2. 1
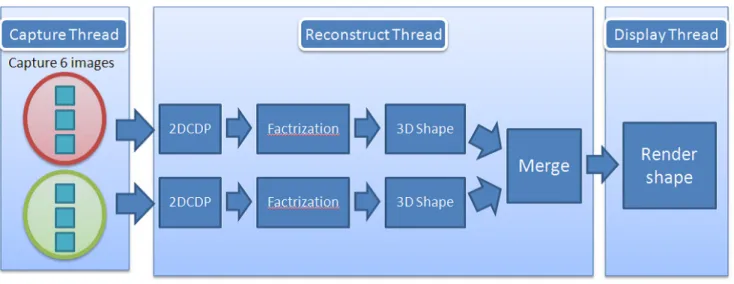
システム概要 提案システムでは, 4 台のカメラから得られた時系列 画像に対して, 2DCDP によって得られる全ピクセルの 対応関係を用い, ピクセル毎の運動から因子分解法を用 いて 2 つの 3 次元形状を復元し, 2 つの 3D モデルを合成 する. そのモデルを時系列順に描画することで連続的に 3D映像を復元する. システムの概略は図 1 に示す.2. 2
2DCDP
FTVシステム中で画像のマッチングとして使用する 2DCDP アルゴリズムは, 矢口ら [6] の実装を用いてい る. 2DCDP アルゴリズムは, 画像スポッティング認識と 呼ばれ, 図 2 に示されるような, 対象画像の認識と同時 に抽出を行う手法であり, さらに, ピクセル対応によって 内包されるデータの動きをも据えることが出来るもので ある. 2DCDP は動的計画法 (DP) を基に, 2 次元格子状 のデータに対する quasi-optimal な画像スポッティング を行う手法の一つである.図1 システムの概要図 図3 画像復元における4点メッシュの制約条件:点(m−1, n−1) に対応可能な参照点は,点(m, n),点(m, n− 1),および 点(m− 1, n − 1)によって決定される. 対象画像と参照画像のそれぞれの座標点を S , {(i, j)|1 5 i 5 I, 1 5 j 5 J} (1) R, {(m, n)|1 5 m 5 M, 1 5 n 5 N} (2) と定義し, 対象画像の各ピクセル値を Sp(i, j) ={r, g, b}, 参照画像の各ピクセル値を Rp(m, n) ={r, g, b} とする. 次に, 参照画像 R の座標点に対応する対象画像 S 中の座 標店に対する写像 R → S を定義する. つまり,(m, n) ∈ R について, (m, n)∈ R ⇒ (ξ(m, n), η(m, n)) ∈ S (3) なる ξ および η が成立する. ここで, ξ(M, N ) = ˆi, η(M, N ) = ˆj (4) なる対応点を累積の終点として考える. 累積時に与えられ る各点に対する重みを w(i, j, m, n), Sp(i, j)と Rp(m, n) での対応するピクセル間距離を d(i, j, m, n) とすると, 2DCDP における対象画像 S における最小の累積空間 J (i, j)は以下の評価式を実現するものになる. J (ˆi, ˆj) = 1 W minξ,η{ M ∑ m=1 N ∑ n=1 w(ξ(m, n), η(m, n), m, n)d(ξ(m, n), η(m, n), m, n)}(5) この時,ξ(m, n), η(m, n) に対して最適な解 ξ∗(m, n),η∗(m, n) を定義する時, W は最適な累積の重みを示すとして以下 のように定義できる. W =∑ m,n w(ξ∗(m, n), η∗(m, n), m, n) (6) また, 2 次元的な単調性及び連続性を保障するために, 参 照画像 m 方向に対応する対象画像における移動可能な 点の集合を K(m, n) ={ξ(m, n), η(m, n)}, 参照画像 n 方 向の局所パスの集合を L(m, n) ={ξ(m, n), η(m, n)} と すると, 点 (m, n) に対応する点 (m− 1, n − 1) は, (ξ(m− 1, n − 1), η(m − 1, n − 1)) ∈ K(m, n)⊗ L(m − 1, n) ∩ L(m, n)⊗ K(m, n − 1) (7) を満たす必要がある. ここで, 演算子⊗ は, 左辺式の 点から右辺式の集合を接合する意味で用いる. この式 を満たす場合, 局所的に単調性及び連続性を保障した, (m, n), (m, n−1), (m−1, n), (m−1, n−1) の 4 点を用い たメッシュが作成される. 矢口ら [10] はランク l = m + n を定義し, 図 5 のように参照画像の対角方向に累積値を 積み上げて行く方式をとる事で, 入力画像に対して参照 画像のマッチングを行う際, 局所的な単調連続性を確保 しつつ連続 DP を行う方法を提案し, これによって画像 間の最適ピクセル対応問題を 2DCDP によって実現出来 る事を示した. 2DCDP では累積時に局所パスの幾何的 な制約を与える事によってピクセル間の非線形変形度合 いを決める事が出来る. 図 6 の様に累積コストの積み上 げ時に x 方向,y 方向局所パスにそれぞれ 7 本のパス制 約を加える事で,(1) 等倍, (2) 等倍±45 度回転, (3)2 倍, (3)2倍±45 度, (4) 縮小を許したピクセル間の非線形変 形を可能としている. また, 縮小については累積時とバッ クトラック時の制約として連続縮小制限を与えている.
3 1 2 5 4 6 8 7 9 n m 1 2 3 4 5 Rank m n dn dm 図4 左:累積におけるランクの定義と計算順序: (m + n)を rankとし,下から順に積み上げ計算を行う. 右:Rp(m, n) 各データ点に与えられる累積方向は2入力,2出力となる. 図5 ピクセルマッチングとメッシュの当てはめ: 参照画像の 左上を開始点として,参照画像の右下まで格子状のメッ シュを変形する形で空間的に当てはめる. + = --45° 5 2 0° 4 1 7 +45° 6 3 4 1 7 5 2 6 3 3 1 7 5 3 4 2
Row-direction path Column-direction path
i j )) , ( ), , ( ( )) , 1 ( ), , 1 ( ( m n m n K mn mn Rξ − η − = ξ η R(ξ(m,n−1),η(m,n−1))=L(ξ(m,n),η(m,n)) 図6 局所パスの方向について: 45度回転,拡大,および縮小 をサポートする7点の候補を持つ. Reference Area
Left camera image Center camera image Right camera image
1 2 3 (x1, y1) (x2, y2) (x3, y3) Trajectory Vector : Tǩ= (x1ǩy1ǩx2ǩy2ǩx3ǩy3ǩ)⊤(ǩ= 1, 2, . . . , P) t 図7 軌跡ベクトル: 中心画像から参照区間を選択し,それを 参照画像として3枚の画像に対して2DCDPを用いて 軌跡ベクトルを計算する.
2. 3
因子分解法 M 枚の画像 Fκ(κ = 1,· · · , M) を用い, 2DCDP によっ てこれらの画像間の N 個の対応点が求められたとする. 1つの対応点を表す軌跡ベクトル pαは以下のように表 すことができる (図 7). pα= (x1αy1α · · · xM α yM α)⊤ (α = 1,· · · , N) (8) このとき, 画像 Fκ中の α 番目の対応点 (xκα, yκα)は次 のように書ける. ( xκα yκα ) = ˜m0κ+ aαm˜1κ+ bαm˜2κ+ cαm˜3κ (9) ˜ m0κ, ˜m1κ, ˜m2κ, ˜m3κは画像 Fκ におけるカメラ位置や 内部パラメータで決まる 2 次元ベクトル, (aα, bα, cα) は Fκ中の α 番目の対応点における 3 次元座標である. mk = ( ˜m⊤k1 · · · ˜m⊤kM)(k = 0, 1, 2, 3)とすることで, pα= m0+ aαm1+ bαm2+ cαm3 (10) となる.{pα} からこれらの平均を引くことで m0を消去 し, p′αと置き換える. p′α = pα− 1 N N ∑ α=1 pα = aαm1+ bαm2+ cαm3 (11) ここで m1, m2, m3は, モーメント行列 C = N ∑ α=1 p′αp′α⊤ (12) の大きい 3 つの固有値 λ1, λ2, λ3に対応する単位固有ベ クトル u1, u2, u3の線形結合として次のように表すこと ができる. mj= 3 ∑ i=1 Aijui (13) 観測行列を W = (p′1 · · · p′N)とすると, 式 (11) を代入 することで W = ( m1 m2 m3 ) a1 · · · aN b1 · · · bN c1 · · · cN (14) = MS (15) となるので, モーメント行列 C を固有値分解して得られ る u1, u2, u3と, M = ( u1 u2 u3 ) A (16) = UA (17) の関係式から得られる任意の 3× 3 の行列 A = (Aij)よ り各対応点の 3 次元座標を求めることができる. この行 列 A は画像ごとに算出されるため, 以降 Aκとする. ところで, アフィンカメラモデルを平行投影と仮定し たので, ( ˆ m1κ ˆ m2κ ) = ( ˜ m1κ m˜2κ m˜3κ ) = ( 1 0 0 0 1 0 )(18) となり, 以下の関係式を得る。 ˆ m1κ· ˆm2κ= 0 | ˆm1κ|2= 1 | ˆm2κ|2= 1 (19) ˆ m1κ, ˆm2κは 2M × 3 行列 M の第 2κ− 1, 2κ 行である. これに式 (17) を代入すると, ˆ u⊤1κAκA⊤κuˆ2κ= 0 ˆ u⊤1κAκA⊤κuˆ1κ= 1 ˆ u⊤2κAκA⊤κuˆ2κ= 1 (20) となり, 非線形最小二乗法等を用いることで上式から計 量行列 AκA⊤κ を求めることができ, カメラ運動と物体形 状を鏡像解を除いて一意に求めることができる (ただし, ˆ u1κ, ˆu2κは 2M × 3 行列 U の第 2κ− 1, 2κ 行). 一般に, 復元解を一意に求める際には計算上 3 枚の異なる画像が 必要とされており, FTV はこの制約より 3 台のカメラを 使用して同一シーンを撮影し復元している.
3.
Occlusion
問題改善手法
カメラを図のように 6 台設置し, 左のカメラから撮影 した画像を c1, c2, c3, c4, c5, c6とする. {c1, c2, c3}, {c4, c5, c6} それぞれ 3 枚の画像で 3D モデルを 1 つずつ復元 する. この時復元する 3D モデルは c3, c4を元にするも のとする. これは 因子分解法の出力結果から選択でき る. 復元した 3D モデルをそれぞれ m1, m2とする. 始 めに, m1, m2の共通部分に合わせて重ね合わせるよう に位置を調整する. これには c3, c4の対応点情報を使用 する. この情報は 2DCDP から得られる. ここで c3, c4 は画像の一部しか共通してはいないので対応点情報を使 用する範囲を制限する必要がある. 使用している画像サ イズを幅, 高さそれぞれ w,h さらに X1 = wα,X2 = w, Y1=hβ2 , Y2= h−Hβ2 , 0 <= α <= 1, 0 <= β <= 1 とすると difx= ∑X2 x=X1 ∑Y2 y=Y1(|m1(x, y)x+ tx− m2(x, y)x| 2) dify= ∑X2 x=X1 ∑Y2 y=Y1(|m1(x, y)y+ ty− m2(x, y)y| 2) difz= ∑X2 x=X1 ∑Y2 y=Y1(|m1(x, y)z+ tz− m2(x, y)z| 2) (21)dif1= difx+ dify+ difz (22)
m1(x, y)x, m1(x, y)y, m1(x, y)zはそれぞれ 3D モデル m1の元画像の座標 (x, y) のピクセルが 3 次元復元され た結果の x 座標, y 座標, z 座標. この dif1を最小にする tx, ty, tzを求め, その数値だけ m1を平行移動する. 復 元された 3D モデルの深度は復元に使用した画像によっ て異なってしまう. よってさらに, 合わせるために深度の 調整も行う. 図8 カメラを6台用意し3台ずつで3Dモデルを復元する. 図9 FTVシステム. ノートPC上で実装されている. difz2= X2 ∑ x=X1 Y2 ∑ y=Y1 (|m1(x, y)z∗r −m2(x, y)z|2) (23) この difz2の値が最小になるような r を求め. m1の全て の頂点の z 座標に r を掛ける. さらに Z 軸を固定し XY 平面に対して m1の回転を行い位置調整をする. difx2= ∑X2 x=X1 ∑Y2 y=Y1 {|(m1(x, y)xcos a− m1(x, y)ysin a)− m2(x, y)x|2} dify2 = ∑X2 x=X1 ∑Y2 y=Y1 {|(m1(x, y)xsin a + m1(x, y)ycos a)− m2(x, y)y|2} (24)
dif2= difx2+ dify2 (25)
この dif2を最小にする回転のパラメータ a を求め, その 値だけ XY 平面に対して m1を回転する. この 3D モデ ルは 4 頂点を使用した面で構成されている. 同じ XY 座 標に二つの面が存在する場合, 深度が深いほうを採用し て再構成する. その判定には面の中心座標を使用する.
4.
ま と め
本論文では高橋らが提案した FTV システムを改善し て Occlusion 問題に対応したシステムの提案を行った. 今後は実験を行い有用性を確認していく. 実験は図 8 の ような状況で撮影した画像 (図 9, 図 11) から復元した 3D モデル (図 10, 図 12) を提案した手法で合成を行う.文 献
[1] K. Sohn, H. Kim and Y. Kim, ”3-D Video Processing for 3-D TV,” Three-Dimensional Imaging, Visualiza-tion, and Display, Springer, pp.251-278, 2009. [2] S. Barnard and M. Fischler, ”Computational stereo,”
ACM Computing Surveys (CSUR), vol. 14, no. 4, pp. 553-572, 1982.
[3] R. Woodham, ”Photometric method for determining surface orientation from multiple images,” Optical en-gineering, vol. 19, no. 1, pp. 139-144, 1980.
[4] C. Tomasi and T. Kanade, ”Shape and motion from image streams under orthography: a factorization method,” International Journal of Computer Vision, vol. 9, no. 2, pp. 137-154, 1992.
[5] H. Baker, ”Three-dimensional modelling,” in Pro-ceedings of the 5th International Joint Conference on Artificial Intelligence, pp. 649-655, 1977.
[6] Y. Yaguchi, K. Iseki, and R. Oka, ”Full Pixel Match-ing between Images for Non-linear Registration of Ob-jects,” IPSJ Transactions on Computer Vision and Applications, Vol.2, pp. 1-14, February, 2010.
[7] 高橋和晃,矢口勇一,山口晃史,吉田幸裕,奥山祐市,岡 隆一, ”2次元連続DPを用いた自由視点テレビの実現”, 画像の認識・理解シンポジウム(MIRU2010)論文集,pp. 91-98(2010). [8] 岡隆一,矢口勇一,溝江真也, ”連続DPの一般スキーム について: 画像スポッティングための全画素最適マッチ ング”,電子情報通信学会技術研究報告. PRMU,パター ン認識・メディア理解(2010), 245-252
図10 入 力 画 像
図11 3Dモデル
図12 入 力 画 像