立命館大学審査博士論文
情報利用履歴に基づくユーザの活動支援に関する研究
(User’s Activity Support Methods based on Information Access History)
2015年3月 March, 2015
立命館大学大学院 情報理工学研究科 情報理工学専攻 博士課程後期課程
Doctoral Program In Information Science and Engineering
Graduate School of Information Science and Engineering
Ritsumeikan University
中村明順
Akinori Nakamura
指導教員:西尾 信彦 教授
i
和文要旨
情報技術の発展により多様で玉石混淆の情報が大量にアクセス可能になったため,ユー ザがその膨大な情報を有効に活用することは困難になっている.旅行の計画立てを例にと ると,旅先の店舗・名所に関する大量のWebページの中から価値あるページの発見が困 難である(情報の収集における困難さ).また通常,ユーザは旅行の計画以外にも様々な案 件を抱えているため,ユーザはそれぞれの案件ごとに保有する関連ファイルや閲覧した Webページの整理が強いられる(情報の整理における困難さ).仮に整理されていたとし ても,現在の作業に合わせてその整理された情報が容易にアクセスできなければストレス となる(情報へのアクセスにおける困難さ). 本研究では,情報利用履歴に基づいたユーザの活動の支援を目的として,先の3つの活 動を支援することに取り組む.情報利用履歴とは情報空間上に存在しているサービスを利 用することによって生成される履歴のことであり,旅行計画の例では,ユーザがこれまで に閲覧したり投稿した店舗・名所の口コミサイト上での活動履歴や,計画をまとめる際に 交したメール,閲覧・編集した文書ファイルやWebページなどである. 1. ユーザの嗜好に基づく情報推薦による情報収集活動の支援 情報収集活動を支援する方法として,情報利用履歴から生成されるユーザの嗜好に基づく 情報推薦がある.ユーザの嗜好に基づく情報推薦で主に利用されている協調フィルタリン グは,ユーザの嗜好と似ている他のユーザを見つけ出す必要があるため,ユーザの嗜好に 共通性が存在しない場合に推薦できないという問題がある.本研究では実世界に存在する 店舗・名所を対象として,店舗・名所といったコンテンツを評価する際に付与するタグや コメントを利用してユーザの嗜好を生成する手法を提案する.被験者による主観評価実験 の結果,提案手法は初めて訪れるエリアにおいても従来の精度を損なうことなく,高い被 覆率で嗜好に合った情報推薦が行なえることを確認した. 2. 情報間の関連性に基づく情報の自動分類による情報整理活動の支援 情報整理活動を支援する方法として,情報の共起関係,すなわち,ある時刻に同時に利 用されている関係から抽出された関連性に基づく情報分類がある.しかし,ユーザが複数ii 第0章 和文要旨 の作業を同時に行なう場合,共起している全ての情報が関連すると判断されるため,元来 の作業と関連の低い情報が混じって分類されるという問題がある.本研究ではユーザのパ ソコン利用におけるファイルやWebページ,ウィンドウといったリソースを対象として, 共起に基づく関連性抽出にユーザから見えているリソースの割合であるリソース可視率を 利用し,全リソースを作業ごとに分類する手法を提案する.評価の結果,提案手法は分類 精度ではアクセス関係から関連性を抽出し分類する手法と同程度であったが,マルチディ スプレイ環境においてディスプレイごとの作業状況の考慮が必要であることがわかった. 3. 関連情報集合の重要度に基づく利用情報予測による情報アクセス活動の支援 情報アクセス活動を支援する方法として,情報利用履歴から抽出された頻出アクセスパ ターンに基づく利用情報予測がある.しかし,ユーザが自由に情報利用を行なえるため, 過去に出現しないアクセスパターンに対応できないという問題がある.本研究ではパソコ ン上におけるユーザの自由なリソースアクセスを対象として,関連情報集合の各リソース の重要度に基づくリソースアクセス予測手法を提案する.提案手法は,デスクトップ上の 最前面で利用しているリソースが属する関連情報集合における各リソースの重要度を,リ ソース間のアクセス関係に基づき算出し,その重要度に応じて将来のリソースアクセスを 予測する.評価の結果,提案手法は,予測精度では頻出アクセスパターンに基づく手法よ り低かったが,過去のアクセスパターンに存在しないリソースアクセスを適確に予測で きた. 以上のことから,コンテンツ評価時の情報を利用することでユーザの嗜好に基づく情報 推薦により情報の収集が容易になり,情報の可視性による関連性抽出に基づいて案件ごと に自動的に情報が分類されることにより情報の整理の手間が削減され,関連情報集合の重 要度に基づくことで現在の作業に合わせたアクセス予測が可能になり情報へのアクセスが 簡便になった.
iii
Abstract
Development of information technology enables us to access a vast amount of infor-mation, and we often have difficulty making use of it. An example of making plans for a trip shows three issues. Firstly, it is difficult to find useful web-pages for the travel plan from many web-pages regarding stores or noted places at the destination (issue of information gathering). Secondly, in addition to the travel plan, since users have various tasks, files/web-pages are required to be classified into groups of tasks (issue of information classification). Finally, stress builds up when users can not access files/web-pages adapted for the current task (issue of information access).
The purpose of this paper is to support users’ activities based on information access history, which is generated by services on information space. To solve each issue, this paper presents three methods. First method is information recommendation using data given when users make comments on contents such as stores or noted places. Second method is information grouping using relationship based on co-occurrences between information. Third method is information prediction using importance of information calculated from information access.
Results of the evaluation by subjects show that the first method improved coverage in unfamiliar areas while preserving comparable precision. Moreover, accuracy of the second method is as accurate as traditional method. Furthermore, the third method predicts possible future access without access patterns. On the other hand the prediction accuracy is lower than the traditional method based on the access pattern.
In conclusion, this paper provides three contributions to support users’ activities. First one makes it easier to gather information by recommendation. Second one is that the workload of information classification is reduced by information grouping. Third one is that users can access information easily by information prediction.
v
目次
第1章 はじめに 1 1.1 研究背景と目的 . . . 1 1.2 論文の構成 . . . 2 第2章 情報利用履歴に基づく活動支援に関する考察と本研究の課題 5 2.1 情報利用履歴に関する関連研究 . . . 5 2.1.1 集団の履歴に基づく研究 . . . 6 2.1.2 個人の履歴に基づく研究 . . . 7 2.1.3 情報利用履歴まとめ . . . 8 2.2 活動支援に関する関連研究 . . . 8 2.2.1 ユーザの嗜好に基づく情報推薦による活動支援. . . 8 2.2.2 情報間の関連性に基づく情報の自動分類による活動支援 . . . 9 2.2.3 頻出アクセスパターンに基づく利用情報予測による活動支援 . . . 10 2.2.4 活動支援まとめ . . . 11 2.3 本研究の課題 . . . 11 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現 13 3.1 ユーザの嗜好に基づく情報推薦手法 . . . 13 3.1.1 タグ手法とコメント手法 . . . 13 3.1.2 推薦の精度と推薦可能数の割合との関係 . . . 14 3.1.3 嗜好生成における問題点とそれに対するアプローチ . . . 15 3.2 推薦システム . . . 17 3.2.1 全体設計 . . . 17 3.2.2 推薦機構の設計 . . . 18 3.3 評価実験 . . . 20 3.3.1 実験仕様 . . . 20 3.3.2 実験の詳細. . . 21vi 目次 3.3.3 実験結果と考察 . . . 23 3.4 まとめと今後の課題 . . . 26 第4章 情報間の関連性に基づく情報の自動分類による情報整理活動支援の実現 27 4.1 情報間の関連性に基づく情報の自動分類手法 . . . 28 4.1.1 手法全体の流れ . . . 28 4.1.2 リソースの可視率と共起時間による関連度の算出 . . . 29 4.1.3 情報の流れの明確化 . . . 31 4.2 評価実験 . . . 31 4.2.1 実験仕様 . . . 32 4.2.2 評価の流れ. . . 32 4.2.3 実験結果と考察 . . . 34 4.3 まとめと今後の課題 . . . 40 第5章 関連情報集合の重要度に基づく利用情報予測による情報アクセス活動支 援の実現 43 5.1 関連情報集合の重要度に基づく利用情報予測手法 . . . 44 5.1.1 手法全体の流れ . . . 44 5.1.2 関連情報集合の重要度の算出 . . . 44 5.2 評価実験 . . . 45 5.2.1 実験仕様 . . . 45 5.2.2 評価の流れ. . . 46 5.2.3 実験結果と考察 . . . 48 5.3 まとめと今後の課題 . . . 50 第6章 考察 51 6.1 情報利用履歴に基づくユーザの活動支援に関する考察 . . . 51 6.2 本研究の応用例 . . . 52 第7章 おわりに 55 付録A buzzmapにおける画面遷移 57 謝辞 59 参考文献 61 著者発表論文 69
vii
図目次
1.1 研究目的 . . . 3 3.1 推薦の精度と推薦できる数の割合の関係. . . 15 3.2 ブックマーク済みスポットの単語のユーザプロファイルへの適用 . . . . 16 3.3 ユーザ・スポット・スポットマーク・タグ・コメントの関係 . . . 17 3.4 スポット推薦アルゴリズムのプロセスフロー . . . 19 3.5 一被験者の実験の流れ . . . 20 3.6 推薦リストの例 . . . 22 3.7 既知のエリアにおける平均P recision . . . . 24 3.8 不案内なエリアにおける平均P recision . . . 24 3.9 3 手法のCoverage . . . . 24 3.10 不案内なエリアにおけるCoverage拡大の影響比較 . . . 24 4.1 ユーザが複数の作業を同時に行なっている場合 . . . 27 4.2 リソースの可視率 . . . 29 4.3 3つのクラスタリング手法ごとの平均性能 . . . 36 4.4 各αごとの提案手法とベース手法の平均性能 . . . 37 4.5 各ディスプレイ環境におけるF-measureの差の平均 . . . 38 4.6 情報の流れの出力結果 . . . 38 4.7 ファイル挿入ありの性能結果 . . . 39 5.1 作業集合の重要度に基づくリソースアクセス予測手法 . . . 44 5.2 作業集合内リソースの中心性に基づくリソースアクセス予測 . . . 45 A.1 みんなの地図帳 . . . 57 A.2 マイ地図帳に登録 . . . 57ix
表目次
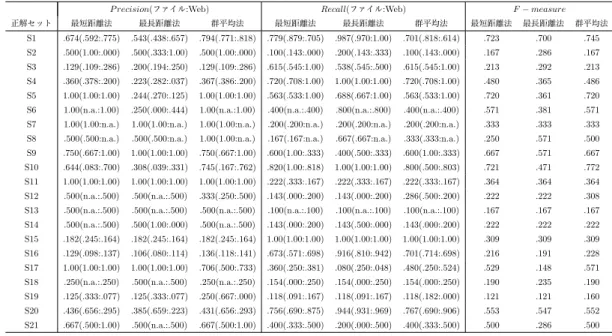
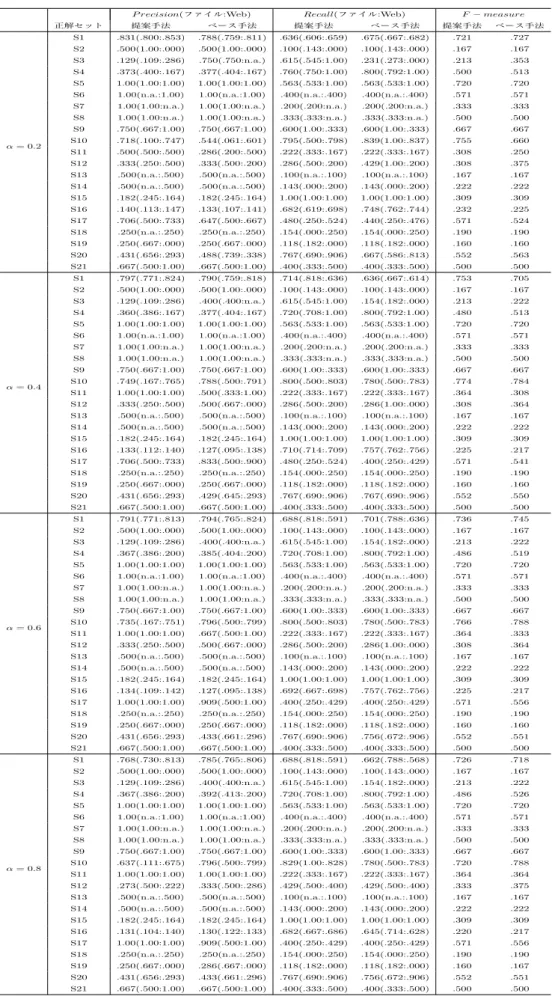
3.1 テストデータセットの内訳 . . . 22 3.2 被験者の既知のエリア/不案内なエリアの選択結果 . . . 23 4.1 正解セット . . . 33 4.2 ファイル挿入ありの正解セット . . . 34 4.3 3つのクラスタリング手法による実験結果 . . . 35 4.4 提案手法とベース手法との性能比較 . . . 41 5.1 正解作業集合 . . . 47 5.2 予測精度(r=5) . . . 48 5.3 予測精度(r=10) . . . 48 5.4 予測種類(r=5) . . . 49 5.5 予測種類(r=10) . . . 491
第
1
章
はじめに
1.1
研究背景と目的
情報技術の発展に伴う,多くのユーザによる容易な情報作成によって,急速に膨大な情 報が蓄積されており,情報爆発 (Information Explosion)が起こっている.IT専門の調 査会社であるIDC(International Data Corporation)は,アナログからデジタルへの推移 が2020年に完了することによって,情報量が35ゼタバイト(1ゼタバイトは1兆ギガバ イト)へと成長すると予測している[1].2009年時点では0.8ゼタバイトであると報告し ており,膨大な情報が蓄積されていることがわかる.従来の情報作成はプロの執筆者によ る情報の精査,編集という行程を経ているため,一定の質が保たれている.しかし,ユー ザによる情報作成では実体験や生の声が含まれているため,現在蓄積されている情報は玉 石混淆である. さらに,情報空間上に存在しているサービスが利用されることによって生成される履歴 (以降,情報利用履歴とよぶ)も蓄積されるようになっている.たとえば,商品や店舗に対 して意見・評判を記述することが出来る口コミサイト上に,ユーザがこれまで記述したコ メントや,旅行の計画を立てる際に閲覧したWebページや編集したファイルなどである. 蓄積される履歴には,商品の好みや作業内容といったユーザに関わる情報が含まれている ため,これら履歴を用いて,新しい価値ある情報を抽出する研究が盛んに行なわれている [2, 3, 4, 5].抽出された情報をユーザへ還元させることで,サービス利用を促し,更なる 履歴に基づいて別の新たな価値ある情報の抽出していくという循環が期待されている. 情報量の爆発的な増加は,ユーザにとって価値のある情報が存在する可能性が高まる 一方で,その情報を見つけ出すのが困難になることを意味する(1. 情報の収集における 問題).ユーザにとって価値のある情報が,膨大で玉石混淆な情報の中に埋もれてしまっ ているため,ユーザは情報を取捨選択することを強いられている.取捨選択には,まず, ユーザは膨大な情報の中から望む情報と関連される情報を収集し,次にその関連情報を確2 第1章 はじめに 認していき,価値があるかを判断する.この行程は十分な情報が入手されるまで何度も繰 り返される. 加えて,ユーザが蓄積する情報量が増加しているため,整理が負担になることも意味 する(2. 情報の整理における問題).記憶装置に関する技術進歩とオンラインストレー ジサービス*1*2の普及により,ユーザが多くのファイルを保存しておくことが可能になっ た.さらに Webを利用しながらファイル編集が日常的になっているため,作業中に閲覧 していた Webページも一緒に整理されているとよい.これらファイルやWebページを 作業ごとに整理することは手間がかかる. 一方,ユーザは必要な情報へのアクセスを繰り返しながら作業の完遂を目指している. 利用したい情報の名前や保存場所を想起・確認し,それを手掛かりにして情報へアクセス する.しかし,ユーザが膨大な情報すべての名前や保存場所を記憶しておくことは困難で あるため,アクセスに手間がかかる(3. 情報へのアクセスにおける問題). これらのことから,多様で玉石混淆の情報をユーザが有効に活用することが困難になっ ている.たとえば旅行の計画を立てる場合,旅先の店舗・名所に関する大量のWebペー ジの中から価値のあるページを見つけ出すことが難しくなっている.加えてユーザは計画 立て以外にも様々な案件を抱えているため,ユーザが有する全文書ファイル・Webペー ジを案件ごとに整理するのは相応の手間がかかる.さらに整理されていたとしても,現在 の作業に合わせた容易なアクセスができなければストレスとなる. そこで本研究の目的は,図1.1に示すように,情報利用履歴に基づいてユーザの活動を 支援することである.特に本研究では,1. ユーザの嗜好に基づく情報推薦による情報収 集活動の支援,2. 情報間の関連性に基づく情報の自動分類による情報整理活動の支援,3. 関連情報集合の重要度に基づく利用情報予測による情報アクセス活動の支援の3つの活動 支援を考える.情報利用履歴とは,たとえば,商品や店舗に対して意見・評判を記述する ことが出来る口コミサイト上に,ユーザがこれまで記述したコメントや,旅行の計画を立 てる際に閲覧したWebページや編集したファイルなどである.
1.2
論文の構成
本論文は,第2章で情報利用履歴と活動支援の関連研究について考察し,本研究で取り 組む課題を導出する.第2章で明らかになった3つの活動支援における課題についてそ れぞれ第3から第5章で取り組んでいく.第6章で,本研究について考察し,応用例につ いて述べる.最後に第7章で本論文をまとめ,今後の課題について述べる. *1https://onedrive.live.com/ *2https://www.box.com/1.2 論文の構成 3
情
報
利
用
履
歴
蓄
積
支援サービス
支援サービス
支援サービス
支援サービス
支援サービス
支援サービス
履
歴
提
供
履
歴
提
供
履
歴
提
供
集団の履歴に基づく支援
個人の履歴に基づく支援
図1.1 研究目的5
第
2
章
情報利用履歴に基づく活動支援に関
する考察と本研究の課題
本章では,情報利用履歴と活動支援に関する研究をそれぞれ分類,考察することによっ て,本研究を位置づけ,取り組む課題を導出する.2.1
情報利用履歴に関する関連研究
本節では,情報空間上で提供されるサービスの利用履歴である情報利用履歴を利用する 研究について利用方法の観点から分類し,考察する.利用方法には,多くのユーザから収 集された情報利用履歴を利用する研究(集団の履歴に基づく研究)と,個人のみの情報利 用履歴を利用する研究(個人の履歴に基づく研究)とがある. 情報利用履歴は一般化すると誰が,いつ,何に対して,何をしたかによって構成される. 履歴にはAmazon.comをはじめとするオンラインショッピングサイトを例にすると,気 にいった・欲しい商品を購入した購入履歴,商品に対して個人的な意見や評価を記述した レビュー履歴などがある.購入履歴には購入者,購入時刻,購入対象の商品が含まれ,レ ビュー履歴にはレビュー者,レビュー履歴時刻,レビュー対象の商品,レビュー内容が 含まれる.ほかの情報利用履歴には,旅先の店舗・名所に関してまとめることを例にする と,名所が記載されている複数Webサイトのページを閲覧したWebアクセス履歴や,ま とめるためにパソコンやスマートフォンといった情報デバイス上のリソースへアクセスし たリソースアクセス履歴などがある.Webアクセス履歴にはアクセス者,アクセスした 時刻,アクセスしたWebページ,Webページの内容が含まれ,リソースアクセス履歴に はアクセス者,アクセスした時刻,アクセス対象のリソース,どんなアクセスを行なった かが含まれる.6 第2章 情報利用履歴に基づく活動支援に関する考察と本研究の課題
2.1.1
集団の履歴に基づく研究
集団から収集された購入履歴に基づいた研究には,アイテム間の類似性を算出する手 法[6, 7]や購入順序を効率的に用いて高速性と高予測精度を同時に実現する手法 [8],各 ユーザの嗜好とユーザ間の関係の両尺度における時間経過に伴う変化を考慮する手法 [9] などがある.レビュー履歴に基づく研究には,映画へのユーザの評価点を利用した GroupLens[10, 11]や,Video Recommender[12],音楽を対象としたRingo[13]がある. これらの研究は主に,多くのユーザからの履歴に基づいて,あるユーザが何を好むのかと いう情報を生成し,嗜好が類似している他のユーザがお勧めしているものを発見すること を目的としている. 単一Webサーバー上でのユーザのWebアクセス履歴は,ユーザ側に特別なプログラ ムやツールを用いさせることなく収集できるという利点があるため,さまざまな研究が 行なわれてきた.たとえば,ある一定期間内でアクセスされた Webページ群を基に相関 ルールを構築する研究[14, 15]や,一定期間内における同一ユーザからのアクセス順序を 考慮した研究[16],Webサイト上で目的ページへの最短アクセスを発見する研究[17]が ある.さらに,オンラインショッピングサイトにおいてユーザの商品購入に向かう状態と 購入を取り止める状態の変化を発見する研究 [18]や,ユーザが検索エンジンに入力した 検索語と,検索エンジンによって提示された結果の中からユーザが実際にアクセスした Webページとの組を用いて,検索語のクラスタリングにより関連語の抽出を行なう研究 [19, 20, 21]がある. 一方,テレビ視聴率の調査と同様に,統計的に全体推定に値するように構築されたユー ザ群の全 Webアクセス履歴を収集する事業*1の登場により,単一Webサーバー上での 多くのユーザからの Webアクセス履歴による研究とは異なる研究が成されるようになっ た.たとえば,大塚ら[22, 23, 24]はユーザの全Webアクセス履歴から,検索語に関連す る語を抽出する手法の提案と,関連語の提示による検索支援システムの構築を行なってい る.ほかに,杉山ら[25, 26]は異なるユーザからの同一検索語であっても同一の結果を提 示するという問題に対して,ユーザの全Webアクセスに基づいてユーザの嗜好を動的に 更新し,その嗜好とWebページとの類似性に基づいて検索結果を適応させている. 集団のリソースアクセス履歴に基づく研究には,Autograph[27]や宋ら[28]の研究が ある.これらの研究は,多くのユーザに共通する業務の流れを抽出し,情報作成 →情報 作成→情報伝達といった一連の流れにおける各行程で必要な情報の提示を目的としてい る.一方,柴田[29]はユーザのリソースアクセスにかかる時間の総和に基づき,ディスプ *1http://www.videoi.co.jp/index.html2.1 情報利用履歴に関する関連研究 7 レイ構成の違いがリソースアクセスに与える影響を定量的に測定している.その結果,リ ソースアクセスにかかる時間という観点において,大画面ディスプレイよりも多画面ディ スプレイのほうが優れていることを確認した.
2.1.2
個人の履歴に基づく研究
一人のユーザのWebアクセス履歴から,アクセスされたWebページの文章に対して自 然言語処理を行なう研究がある.たとえば,松尾ら[30]はユーザ個人が閲覧した全Web ページから頻出語を抽出し,頻出語との共起の偏りが大きい語をハイライトさせるシステ ムを構築している.河合ら[31, 32]はユーザが既にWebページの分類体系を理解してい るWebサイトのレイアウトを通した情報提示システムMy Portal Viewer(MPV)を提案 している.MPVでは,ユーザのWebアクセス履歴から抽出されたユーザが興味を持っ ていると考えられる語に基づいて,MPVに提示する情報を分類している.ニュース記事 に限定されているが,大槻ら[33, 34]はユーザに一度提示したがアクセスされなかった Webページにも興味がないというユーザの嗜好が含まれているとして,アクセス/非ア クセス履歴に基づいた記事提示システムを提案している. 自然言語処理ではないWebアクセス履歴分析を行なう研究として,富士谷ら[35]はブ ラウザにプラグインをインストールし,ページの遷移元とタブの切替えとによるアクセス 履歴間の関連性に基づいた履歴分類手法を提案している.ほかには履歴間のアクセスした 時刻の近さを利用する研究[36, 37]や,アクセス回数やアクセス時間に基づく研究[38]が ある. パソコン上でのファイルやWeb ページ,ウィンドウといったリソースへのアクセス の履歴を利用し,ユーザが過去に行なったアクセスに関する情報の想起を容易にする研 究がある.Memory-Retriver[39]は,ユーザが複数メーカで類似商品の比較調査といっ たWeb ページアクセスによって得られた情報を想起させることを目的としたシステム で,Webページのサムネイル画像を記録して視覚的に提示している.俺デスク[40]では, Webアクセス時刻やクリップボードの利用履歴に基づいて算出される関連度を用いた関 連検索ツールによって,たとえば企画書を作成していたときに Web アクセスしていた Webページの検索が可能になり,さらにWebアクセス時間やWebアクセス回数に基づ いて算出される着目度を用いた時系列ビューアによって,たとえば一昨日の夜中に Web アクセスしていたレストランガイドの再Webアクセスが可能になった.近藤[41, 42]は, スクリーンショットを定期的に行なうことによって,ユーザが過去の作業に利用した情報 の想起を容易にしている.8 第2章 情報利用履歴に基づく活動支援に関する考察と本研究の課題
2.1.3
情報利用履歴まとめ
集団の履歴に基づく研究は,多くのユーザに共通して表れる何らかの価値を抽出するこ とであるといえる.たとえば,おすすめWebページの提示やある検索語に関連する語を 発見することである.複数ユーザからの履歴が必要であるため,ユーザ数が一定以上存在 することが求められる. 他方,個人の履歴に基づく研究は,ユーザ個人に特化し,個人が有する価値を抽出する ことであるといえる.たとえば,ユーザがこれまでWebアクセスした全Webページで 頻出する語の抽出や,作業遂行にアクセスしていたWebページの関連性抽出などである. ユーザ個人の履歴に基づくため,複数のユーザを必要としない. 以上のことから,情報利用履歴は提供したいサービスによって,履歴の種類や,個人か 集団かといった利用方法が定まる.2.2
活動支援に関する関連研究
本節では,ユーザの活動に対して支援することを目的とした研究についてまとめ,考察 する.活動支援に関する研究には,ユーザの嗜好に基づく情報推薦や,情報間の関連性に 基づく情報の自動分類,頻出アクセスパターンに基づく利用情報予測がある.2.2.1
ユーザの嗜好に基づく情報推薦による活動支援
ユーザの嗜好に基づいて情報を推薦する手法として,主に内容ベースフィルタリングと 協調フィルタリングが注目されてきた [10, 6, 43, 44, 45].内容ベースフィルタリングは 情報のメタデータを抽出し,情報間の類似度を算出しておき,推薦対象ユーザが注目した 情報に類似する情報を推薦する手法である.そのため,ユーザが1人であっても推薦が可 能で,粗なユーザ分布に耐性がある.神嶌[46]は内容ベースフィルタリングには,ユーザ 自身が嗜好を入力する直接指定型と,ユーザの情報利用履歴に基づき情報に対する嗜好の 度合いを定量化したプロファイルを生成する間接指定型とがあると述べている.ユーザ数 が十分でなくユーザ間の嗜好の類似性判定が困難な情報を推薦する場合,直接指定型が適 していると述べている.しかし,直接指定型の内容ベースフィルタリングはユーザへの推 薦履歴を考慮しないため,継続的に利用するとユーザが既に知っている情報ばかり推薦さ れる恐れがある. 一方,協調フィルタリングは情報のメタデータを一切必要とせず,推薦対象ユーザが注 目した情報を評価しているほかのユーザを発見した上で,類似ユーザが評価済みかつ推薦 対象ユーザにとって未評価の情報を推薦する手法である.内容ベースフィルタリングと比2.2 活動支援に関する関連研究 9 較して,推薦結果に対する目新しさと意外さとを含んだ指標であるセレンディピティのあ る推薦が期待できることが経験的にわかっている.継続的に推薦を受けるなら,予測精度 の向上する協調フィルタリングがよいと神嶌は述べている[46]. 協調フィルタリングによる情報推薦の研究として,たとえば,竹内ら[47]はユーザの位 置情報と協調フィルタリングを用いてユーザが頻繁に訪れる店と類似している店を推薦す る手法を提案している.街にある店舗に対する評価値を単位としたユーザプロファイルを 生成し,アイテム間型の協調フィルタリングによるモバイル端末向け推薦システムを実装 している.東京都渋谷区代官山町の1 街区をフィールドに10 名の被験者による主観評価 実験を試みている.ほかには,篠田ら[48, 49]も同様に協調フィルタリングを用いたモバ イル端末向け推薦システムを提案しているが,GPS から取得したユーザの位置情報をそ のまま協調フィルタリングの材料とせず,GPS などのユーザの移動履歴から行動パター ンを抽出してユーザ間の類似度判定に用いることを試みている.
J¨aschke ら[50]やLipczak[51]は,ユーザプロファイルに “blog”や“web”といった タグを使用し協調フィルタリングによりタグを推薦することで,ユーザのタグ付けをサ ポートするシステムを提案している.タグ付け時における推薦するタグの精度を評価して いる.
2.2.2
情報間の関連性に基づく情報の自動分類による活動支援
情報間の関連性を抽出する研究は,主につぎの3種類に分類される.一つ目はファイ ル名やウィンドウ名といったメタデータから抽出したキーワードの類似性に基づく研究 [52, 53]である.二つ目は情報間の共起関係,すなわち,ある時刻に同時に利用されてい る関係から関連性を抽出する研究[27, 54, 55, 56]である.最後はWebページ分類に特化 された研究[35, 57, 58, 59]である. メタデータの類似性による関連性を抽出する研究として,大峡ら[52]はファイル名から 抽出されたキーワードの頻度分布を利用して,適切な粒度で階層的な分類を生成する手法 を提案している.SWISH[53]では同一の作業に利用されるウィンドウのタイトルが類似 されるという仮定に基づき,ウィンドウタイトルから抽出されたキーワード群をクラスタ リングさせることで,情報群に分類させる手法を提案している.ほかには,情報内に記載 されている単語の出現頻度やその単語の重要度から情報の類似性を抽出する手法[60, 61] や,同義語・多義語を考慮した文書解析手法[62, 63]などがある.しかし,ゼミに用いる パワーポイントのファイルといった特徴を,複数の情報から抽出し分類できても,同じ作 業で利用したものとは限らない.さらに,同じ作業に使っていた情報であっても,全てに 同じキーワードが含まれているとは限らない. 関連性抽出手法の二つ目である共起関係に基づく研究として,Autograph[27]では情報10 第2章 情報利用履歴に基づく活動支援に関する考察と本研究の課題 利用履歴を一定の期間ごとに分割し,頻出する情報利用履歴集合を抽出する手法を提案し ている.Push-and-Pull Switching[64]は,ウィンドウの重なりを利用して作成されたグ ループに対して同時操作を容易にするシステムである.小田切ら[55, 65, 66]が提案する 手法は,情報の共起時間に着目し,2つの情報の共起回数や共起時間,使用開始時刻の類 似度などを用いて情報間の関連性を抽出する.栄ら[67]は2種類の情報利用履歴を用い てそれぞれの関連性を抽出する手法を提案している.ファイルの読み書き等を記録した ファイルアクセス履歴と,Webページのアクセス履歴を統合し,一定の期間内に同時に 利用していることが多い組み合わせを同じ作業に使っていたファイル,Webページとし ている.これらに対し,定免ら[56]は,複数の情報を同時に利用していても,1つの作業 につき利用する情報群は決まっていることを指摘している.提案された手法は,情報間の 共起時間に加え,利用している情報間でのアクセス回数やアクティブにしている時間を利 用する. Webページ分類に特化された手法として,ページ内に存在するリンク情報を解析し, 同じリンク先あるいはリンク元を多く持っているページ同士は類似しているとする手法 [57, 58] や,ニュース系サイトやブログ系サイトといった Web ページの形式に着目し HTMLタグの特徴を抽出しWebページ同士の関連性を抽出するもの[59]がある.
2.2.3
頻出アクセスパターンに基づく利用情報予測による活動支援
頻出アクセスパターンに基づく利用情報予測に関する研究は,主につぎの2種類に分類 される.一つ目はある条件 pが起こっている場合に事象 qが起こるといった相関ルール を抽出する研究[68, 69, 70]である.二つ目はファイルシステム上のレイテンシを向上さ せることを目的として,ファイルアクセスを予測する研究[71, 72]である. 相関ルールの抽出の代表的な手法として,Aprioriアルゴリズム[73, 74]とBacktracking アルゴリズム [75]がある.これらの手法はアイテムの集合であるトランザクションの集 合において,全アイテムに対する各アイテムの組み合わせである共起関係に基づいて抽出 する.全アイテムが,たとえば{a, b, c}では,共起関係には集合{a}と集合{b},集合{a}と集合{c},集合{b}と集合{c},集合{a, b}と集合{c},集合{a, c}と集合{b}, 集合{b, c}と集合{a}の計6種類ある.トランザクション集合において相関ルールの抽 出には,まず空集合からはじめ,アイテムを1 つずつ追加する操作を網羅的に行なってい くことで,頻出の条件を満たした相関ルールを発見する.Aprioriアルゴリズムは要素の 追加を幅優先的に行なう,Backtrackingアルゴリズムは深さ優先的に行なう手法である. さらにトランザクション間の順序関係を考慮した手法[76, 77, 78]がある.抽出された相 関ルールに基づいて,ある状態が条件pと合致している場合に事象qに関する支援が可能 になる.
2.3 本研究の課題 11 ファイルアクセスを予測する研究は,暗黙的に,ファイルアクセスパターンがn次マ ルコフモデルによってモデル化できるという仮説に基づいている.たとえば,Automatic Prefetching[79]は,ユーザのファイルアクセス履歴を蓄積し続け,あるファイルがアク セスされた後にアクセスされる可能性が高いファイルを高速なメモリへと事前配置す ることで,ファイルシステム上のレイテンシを向上している.Ahmed ら[71]は,Best k-out-of-mによるファイルアクセス予測手法を提案している.これは,最新m個のファ イルアクセス履歴から,あるファイル(i)の次にアクセスしたファイル(j)という組(i, j) の出現回数が最小k回以上出現し,かつ最大となるファイル (j)を予測する.ただし実験 の結果から,mの値が大きい場合,ファイル(i)の直後にアクセスしている回数が最も多 いファイル(j)とした方が精度が高いと述べている.Jehanら[80]は,ファイルアクセス の予測を確率的な手法へと展開しているが,その本質はマルコフモデルに従っている.
2.2.4
活動支援まとめ
情報収集活動を支援することを考えると,セレンディピティのある推薦が期待でき,継 続的な推薦利用により予測精度が向上される協調フィルタリングが適している.内容ベー スフィルタリングでは,粗なユーザ分布に耐性があるが,ユーザへの推薦履歴を考慮しな いため,継続的に利用するとユーザが既に知っている情報ばかり推薦される恐れがある. 情報整理活動を支援することを考えると,ユーザが過去の作業に閲覧・編集したファイ ル・Webページごとに整理したいという要求を満たすために,情報利用履歴における情 報間の共起関係に基づいて関連性を算出させる手法が適している.ファイル名やウィンド ウ名などのメタデータから抽出したキーワードの類似性に基づく手法では,同じ作業に利 用していたファイル・Webページであっても,全てに同じキーワードが含まれていると は限らないため,作業ごとに集約することが困難である. 情報アクセス活動を支援,特にユーザが自由に情報利用を行なえる場合において支援す ることを考えると,相関ルール抽出手法,マルコフモデルに従ったファイルアクセス予測 手法ともに,過去に出現しないアクセスパターンに対応できないという問題がある.両手 法とも過去に一度でもアクセスしていない限り,同一の作業に関する情報へのアクセスで あっても予測できない.2.3
本研究の課題
本節では,3つの活動を支援する手法における問題を述べ,本研究で取り組む課題を明 らかにする. 1. ユーザの嗜好に基づく情報推薦による情報収集活動の支援12 第2章 情報利用履歴に基づく活動支援に関する考察と本研究の課題 協調フィルタリングは,情報利用履歴に基づいて生成されたユーザプロファイルと似て いる他のユーザを見つけ出す必要があるため,ユーザ間に共通する嗜好が存在しない場合 に推薦できないという問題がある.本研究では実世界に存在する店舗・名所を対象として 取り組む.実世界でのユーザの行動が地理的な距離による制約を受けるため,店舗・名所 といったコンテンツを基にする従来手法において生成されるユーザプロファイルは,各 ユーザが日常的に行動しているエリアのコンテンツの評価値に偏る.その結果,1度も訪 れたことのない不案内なエリアにおいての協調フィルタリングはユーザ間の嗜好の類似性 が見つけられないため,うまく働かず推薦を受けられなくなる.たとえば,大阪在住でほ とんど大阪のコンテンツしか評価していないユーザが東京の浅草に旅行で初めて訪れた際 に,浅草のコンテンツは何も推薦されないといった状況が起こりうる. 2. 情報間の関連性に基づく情報の自動分類による情報整理活動の支援 共起関係に基づいて関連性を抽出する手法では,ユーザが複数の作業を同時に行なって いる場合,作業間で利用される情報にも関連付けが発生するため,元来の作業と関連の低 い情報が含まれて分類されてしまうという問題がある.本研究ではユーザのパソコン利用 におけるファイルや Webページ,ウィンドウといったリソースを対象として取り組む. 大量のリソースを用いながらパソコンが利用されるが,画面解像度の制約により一度に見 られるリソースには限りがあるため,ユーザから見えにくいリソースは共起による関連性 が低いと考えられる.たとえば,旅行の計画立てにおいて,予定をファイルにまとめる 際,旅先の店舗・名所が記載されているWebページが同時に見えるようにリソースの配 置を操作して,計画を立てていく.このとき,作業と関係の低いリソースは,リソースの 背面に配置され,前面に存在するリソースによって隠されるため,ユーザから見えない. 3. 関連情報集合の重要度に基づく利用情報予測による情報アクセス活動の支援 相関ルール抽出やマルコフモデルに従ったファイルアクセス予測といった頻出アクセス パターンに基づく利用情報予測手法では,過去に存在しないアクセスパターンに対応でき ない.さらにユーザが自由に情報利用を行なえるため,新出アクセスが現れる可能性が高 いという問題がある.本研究ではパソコン上におけるユーザの自由なリソース利用を対象 として取り組む.ファイルアクセス予測では一般的にOSレベルを対象としており,プロ グラム等によってアクセスが制御されるが,本研究ではアプリケーションレベルを対象と しており,ユーザによって自由にアクセスされるため,アクセスパターンが不定である. たとえば,旅行の計画立てにおいて,予定をまとめたファイルaと旅先の店舗・名所が記 載されている Webページb, cの3つのリソースが作業に関連し,これまでファイル a とWebページb,ファイルaとWebページcのそれぞれでアクセスがあり,現在Web ページbを最前面にしている場合,将来アクセスされるのはファイルaに加えWebペー ジbである可能性がある.
13
第
3
章
ユーザの嗜好に基づく情報推薦によ
る情報収集活動支援の実現
本章では,2.3節で述べた情報収集活動の支援における課題,ユーザ間に共通する嗜好が 存在しない場合に推薦できないという課題に対し,実世界に存在する店舗・名所といった 地理情報が付与されたコンテンツ(以降,スポットとよぶ)を対象として取り組む.ユー ザの情報に対する嗜好の度合いを定量化したプロファイル(以降,ユーザプロファイルと よぶ)を,店舗・名所といったコンテンツ単位よりも抽象的な単位による評価値を用いて 生成させる手法について3.1節で提案し,3.2節でシステムを設計し,3.3節で評価する.3.1
ユーザの嗜好に基づく情報推薦手法
本研究では,抽象化されたユーザプロファイルを生成するために,スポットを特徴付け る語を利用する手法を提案する.スポットを特徴付ける語を抽出する方法として2 つの 手法を提案する.一方はスポットにWeb コンテンツ分類手法であるタグを適用する手法 (タグ手法)と,他方はスポットに対するユーザの意見であるコメントを利用する手法(コ メント手法)である.スポットを評価するという行為はそのスポットに対して良い評価で あると仮定し,また,タグやコメントの内容もスポットに対して良い評価であると仮定し ている.3.1.1
タグ手法とコメント手法
近年,「ユーザの操作や反応」を積極的に利用するfolksonomy (フォークソノミー) [81]と呼ばれるタグ付けによるWeb コンテンツ分類手法が注目されている.フォークソ14 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現
ノミーの最たる例は,delicious*1やはてなブックマーク*2に代表されるソーシャルブック
マーク(SBM) のタグ付けである.SBM では,各々のユーザの「気に入った/価値があ
ると感じた」Web コンテンツ(Web ページに限らずWeb 上でURL の与えられている ものすべて)にタグ付けしてブックマークし,それらをユーザ間で共有することで,タグ により分類された Web コンテンツの集合知が形成されている.ユーザはWeb コンテン ツの内容を端的に表すタグを使用しており,表現の幅は狭いが,付けやすく沢山集まる可 能性がある.タグ手法では各ユーザの利用するタグとその利用回数に着目しユーザプロ ファイルを生成する.タグを単位としてユーザプロファイルを抽象化することで,スポッ ト単位で生成されたユーザプロファイルよりも地理的制約を受けない推薦を実現できるは ずである. Web 2.0 といわれ始めて以来,多くのサイトではWeb コンテンツに対しコメントでき るようになった.ユーザはコメントを通じてWeb コンテンツに対し,個人的な評価・判 断・意見・評論・批判を述べる.コメントはタグと比較して,入力するのは面倒であるが 表現できる幅は広いので,Web コンテンツの内容をより詳細に説明することができる. コメント手法ではコメントを形態素解析して,スポットを特徴付ける形態素によってユー ザプロファイルを生成する.タグに対応していない既存のWeb 2.0 のようななサイトは 多いので,適用範囲が広がる. また,以降はコメントから抽出した形態素およびタグを総じて単語と呼ぶ.
3.1.2
推薦の精度と推薦可能数の割合との関係
ユーザが日頃から生活圏としているエリアでの推薦の精度は,これまで述べたスポット 手法・タグ手法・コメント手法のうち,スポット手法が同じスポットを評価しておりより 嗜好に合うため一番高いと考えられる.抽象化したユーザプロファイルの中では,コンテ ンツの内容を端的に表しているためより嗜好が類似しやすいと考えられるタグ手法のほう が,表現の幅が多いため表記揺らぎを他より多く含むコメント手法よりも精度がよいと考 えられる.初めて訪れるような不案内なエリアでのスポット手法では十分なプロファイル を得られず抽象化したユーザプロファイルのほうが精度が高く,抽象化したユーザプロ ファイルの中では生活圏としているエリアと同様にタグ手法,コメント手法の順になると 考えられる. 推薦できる数の割合は,抽象化したユーザプロファイルはエリアにとらわれないため高 いと考えられる.その中でも,表記揺らぎを多く含んでいるコメント手法のほうが,タグ 手法より高い考えられる.スポット手法では同じスポットを評価しなければ,他のスポッ *1https://delicious.com/ *2http://b.hatena.ne.jp/3.1 ユーザの嗜好に基づく情報推薦手法 15 図3.1 推薦の精度と推薦できる数の割合の関係 トを推薦できないため抽象化したユーザプロファイルより低く,特に不案内なエリアに関 しては,推薦できる数は極端に低いと考えられる. 以上をまとめると,図3.1に示すように,推薦の精度と推薦できる数の割合はトレード オフの関係である.推薦の精度を高めると推薦できる数の割合は低くなり,推薦できる数 の割合を増やすと推薦の精度は下がる.
3.1.3
嗜好生成における問題点とそれに対するアプローチ
上記手法によってユーザプロファイルを生成する場合,2 つの問題が考えられる. • 単語の表記揺らぎ あるユーザはラーメン屋をブックマークする際,[ラーメン] という単語を付加す る.一方で,別のユーザはラーメン屋をブックマークする際,[拉麺] という単語を 付加する場合,それらを単純なマッチングなどで同じ嗜好であると判定することは 難しい.単語は自由記述のため,2 人のユーザプロファイルを比較しても単語の不 一致により類似しないと判断される.さらに,そもそもタグ付けやコメントはユー ザの自由意志に任されているため,ユーザによってはタグ付けやコメントをまった く行なわずにブックマークする可能性がある.このようにユーザの方針が異なると ユーザプロファイルが粗になりユーザ間の類似度判定が困難となる. • 汎用的な単語の悪影響 例えば,[グルメ] や[観光地] といった汎用的な単語は,多くのスポットに適用でき る.それと比較して,[ペットフード] や[歌舞伎]は適用可能なスポットの絶対数は16 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現 図3.2 ブックマーク済みスポットの単語のユーザプロファイルへの適用 多くないであろう.汎用的な単語に基づいたユーザプロファイルによる協調フィル タリングでは,ほとんどのユーザの嗜好が同様になり,推薦結果はありきたりにな る恐れがある.したがって,希少性のある単語に重きを置く必要がある. 2 つの問題を解決するために本研究では図3.2 のようにユーザプロファイルを生成す る.前者の問題を解決するため,赤枠に示すような,あるスポットをブックマークする際 に全ユーザが付加した単語を単位とする.具体的には,ユーザがあるラーメン屋に[ラー メン] という単語のみを付加してブックマークしており,他のユーザが同じラーメン屋を [拉麺][とんこつ][濃厚]という単語を付加してブックマークしている場合,それらの単語も ユーザプロファイルに含める.これにより,方針の異なるユーザ間であってもスポットを 通じて互いの単語をユーザプロファイルとして利用することができるようになる.これに よって推薦候補の数が増加すると見込める. 後者の問題を解決するため,全ての単語に対してtf-idf[82]値を算出する.tf-idf は文 書中の単語の登場頻度tf と,全文書中の単語の逆登場頻度(希少性の指標)idf の積か ら成り,文章を特徴づける単語であるほどtf-idf 値は高い.この値を利用することでそれ ぞれの単語の希少度を考慮してユーザプロファイルを算出することができる.これによっ て重要な単語から得られた推薦を優先的に行なうことができ,精度を維持できると考えら れる.また,全ての単語のtf-idf 値を算出するため,汎用的な単語の悪影響を解決する案 は推薦候補の数に影響を与えない.単語の数や閾値によってユーザプロファイルに利用す る単語の数を制限し,適合率や再現率を向上させる研究もある[83, 84].しかし,本研究
3.2 推薦システム 17 図3.3 ユーザ・スポット・スポットマーク・タグ・コメントの関係 の目的は推薦候補数の向上であるため,ユーザプロファイルに利用する単語は単語の数や tf-idf 値の閾値によって制限しない.
3.2
推薦システム
本節では,実世界でのスポットを対象としたユーザプロファイル抽象化手法による推薦 システムについて設計する.3.2.1
全体設計
スポットの推薦対象となるユーザたちはモバイル端末を所持し,GPS や無線LAN を 利用した測位を任意のタイミングで行なえるものとする.これによりシステムはユーザの 現在地周辺のスポットを検索できる.提案システムはモバイル端末をクライアントとする クライアント/サーバ型である.モバイル端末からの推薦要求とユーザの現在地の情報を 受け取り,ユーザの嗜好に合った周辺のスポット情報を協調フィルタリングによって選出 し,モバイル端末に返答する. 図3.3に,ユーザのスポットに対して行なうタグ付けあるいはコメントを提案システム がどのように管理するかを述べる.提案システムにおけるスポットとは,ユーザにとって “意味のある場所”の総称である.スポットには「東京ミッドタウン」のような建築物・ ランドマークを指すものもあれば,その中にある「東京ハヤシライス倶楽部」といった店 舗を指すものもありえる.他にも「品川」や「首都圏」のように一定のエリアを示すもの も,それがユーザにとって何らかの意味を持つ場所であればスポットと捉える.また,ス ポットに対して5 段階の評価値やタグやコメントを付加してブックマーク化したものを18 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現 「スポットマーク」,スポットマークを作成する行為を「スポットマークする」と定義する. ユーザはスポットマークする際,既存のスポットを選択する.目的のスポットがない場合 は新規にスポットを作成した上でスポットマークする.スポットは重複が発生しないよう にID 管理されている.スポット情報はスポットに付随する様々な情報を内包する.例え ば,スポットに付与されているタグやコメントといったものである.
3.2.2
推薦機構の設計
ユーザプロファイルは単語を基とするn 次元ベクトルとして表現する.コメント手法 において全ての形態素を,スポットを特徴付ける形態素として利用した方が,本研究の目 的である推薦候補数の向上には役に立つ.しかし,例えば,助詞の「は」や助動詞の「ま す」といった形態素は,ユーザの嗜好を表しているとは考えられない.そのため,これら の形態素をユーザプロファイルに利用し,スポットを推薦してもユーザの嗜好に合った推 薦にはならない.そこで,本研究では推薦候補の数と推薦の精度との両立のために,コメ ント手法では,コメントの形態素のうち接続詞と感動詞とを除いた自立語をスポットを特 徴付ける形態素として利用する.一般的に,自立語は文章において最も重要な語として位 置づけされているため利用する.接続詞と感動詞は前後関係を考慮しなければならないの で,単位として利用しないこととする. すべての手法においてあるユーザur のユーザプロファイルup,r を次のように定める. up,r = (t0,r, t1,r, ..., tk,r, ..., tn,r) (3.1) tk,r = tfk,r∗ idfk (3.2) tfk,r = Sr,tk (3.3) idfk = log(N/dfk) (3.4) tk,r は単語tk についてのユーザ ur の嗜好の強さを示す.tfk,r は単語tk が付いてい るスポットをユーザurがスポットマークしている数,idfk は単語が希少なほど大きな値 となるため,tfk,r と乗算することでtk,r が強調される.なお,dfk はある単語tk が付い ているスポットの数,N は全スポット内でスポットマークされているスポットの数であ る.「スポットマークされているスポットの中で,付加されたスポットが少ない単語」ほ どidfk が大きな値となることを利用して,汎用的な単語ばかりがユーザの嗜好となるこ とを防ぐ. ユーザプロファイルの類似度は式(3.5)の通り,コサイン距離で求める.また,推薦候 補スポットs の推薦対象ユーザur に対する推薦ランクRs,ur は次の式通り,コサイン距 離とスポットに対する評価値vs,uc の加重平均で求める.3.2 推薦システム 19 図3.4 スポット推薦アルゴリズムのプロセスフロー cos(up,c, up,r) = ∑ ti,c· ti,r √ ∑ t2 i,c· √ ∑ t2 i,r (0≤ cos(up,c, up,r)≤ 1) (3.5) Rs,ur = ∑
cos(u∑ p,i, up,r)· vs,ui
cos(up,i, up,r) (3.6) 推薦する対象となっているユーザ(推薦対象ユーザ)の周辺にあるスポットそれぞれに ついて,ユーザプロファイルを用いて図3.4の手順で推薦ランクを算出する.協調フィル タリングに基づいたアルゴリズムとなっている. 設計1 推薦対象ユーザur の現在地から特定の範囲内にあり,なおかつ推薦対象ユーザ の未評価スポットを推薦候補スポットsとする.ユーザはあらかじめ範囲を指定す ることができるとする. 設計2 ある推薦候補スポット sについて,sをスポットマークしている比較対象のユー ザuc のユーザプロファイル up,c と,推薦対象ユーザ ur のユーザプロファイル up,r のコサイン距離cos(up,c, up,r)を算出する. 設計3 比較対象ユーザuc が複数存在する場合,uc それぞれとcos(up,c, up,r)を算出し, それぞれのコサイン距離とユーザのスポットに対する評価値vs,uc を加重平均した 値を,推薦候補スポットsの推薦対象ユーザurに対する推薦ランクRs,ur とする. 推薦対象ユーザur とユーザプロファイルの類似する比較対象ユーザが大勢スポッ トマークしているスポットほど,推薦ランクRs,ur は高くなる. 設計4 全推薦候補スポットについて設計 2,3 の処理を繰り返し,すべての推薦候補ス ポットの推薦ランクを求める.算出した推薦ランクの高いスポットをユーザに推薦 する.この推薦ランクの閾値はユーザ・スポット・スポットマーク数によって変化 すると考えられるが,適切な値の予測は難しいためヒューリスティックに決定する
20 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現 図3.5 一被験者の実験の流れ ことにする.
3.3
評価実験
本節では,3.1節と 3.2で提案している,ユーザプロファイルの抽象化によるスポット 推薦性能について,評価実験を行なう.3.3.1
実験仕様
提案手法の2 つと従来型の協調フィルタリングの性能を被験者による机上で主観評価 した.なお,被験者たちは20 代の男女26 名である.実験では,既存のWeb サイトから 取得したデータを用いて被験者に対して推薦する.被験者が少なくとも 1 つよく知って いるエリアを持つために,出身地・現住所を考慮して6 つのエリア(京都市の三条∼四条 周辺,大阪市の梅田周辺,神戸市の三宮周辺,東京都区部の上野周辺,名古屋市の伏見周 辺,仙台市の東六番丁周辺のそれぞれ1km 四方のエリア)を設定した.6 つのエリア内 には少なくとも700以上のスポットが登録されており,その内訳も服飾店,飲食店,観光 名所,百貨店,大型電気店と多種多様である.エリアによってスポットの内訳に多少の傾 向の違いはあるが,ユーザの嗜好に合った推薦の性能を評価するエリアに適していると判 断した. 一被験者の実験の流れを図3.5に示す.まず,i) 各被験者に「実際によく知っているエ3.3 評価実験 21 リア」を1 つ選択してもらい,そのエリア内に限って少なくとも20 箇所をスポットマー クしてもらった.選択したエリアはその被験者にとっての「既知のエリア」であり,それ 以外のエリアは「不案内なエリア」と見なした.次に,ii) スポットマークして得られた 被験者のスポットマークしたスポット,タグあるいはコメントの形態素を基に各被験者の ユーザプロファイルをそれぞれ3.2.2項の式(3.1)の設計通りに生成した.スポット手法 のユーザプロファイルはスポットを単位とするn次元ベクトルで,あるスポットをスポッ トマークしているなら1 ,していないなら0 で生成する.ユーザプロファイルの生成方法 は異なるが,その後の各スポットの推薦ランクの算出方法も3.2.2項の設計3 の通りであ る.最後に,iii) 各被験者に対してそれぞれのエリアごとにスポットを協調フィルタリン グによってリスト形式で推薦し,iv) 推薦された各スポットの主観評価結果を得た.なお, 各リストは3 手法で推薦されたスポット情報をシャッフルし,被験者にはどのスポット情 報がどの手法で推薦されたかはわからないようにした.そして,ユーザプロファイル生成 方法における3 手法を推薦精度とエリアを選ばず推薦できるスポット数の割合の 2 つで 比較する.
3.3.2
実験の詳細
実験には,スポットに対するタグとコメントの両方を兼ねそろえているテストデータ セットを用いて,ユーザプロファイル生成方法における3 手法を比較する必要がある. So-net buzzmap*3(2010年3月23日をもってサービス停止*4)は大勢のユーザの手で 登録された幅広いスポット情報を公開しているWeb サイトで,全ユーザ間で共有されて いる「みんなの地図」と,ユーザが各自で管理する「マイ地図帳」の2 種類の地図から構 成される(詳細は付録Aに).ユーザは「みんなの地図」上のスポットを「マイ地図帳に 登録」し,その際にスポットに自由にタグやクチコミ(コメント)を書くことができる. これらの構造は本研究の想定するデータ構造とほぼ同等と見なせるため,実験に用いるテ ストデータとして,So-net buzzmapで公開されているデータを利用する.また,So-net はブログサービスを提供しておりSo-net buzzmap のスポットと連携することができる. ブログはクチコミで記載しきれなかった情報やそのスポットにまつわる思い出などを記述 するために利用するので,ブログもコメントと見なしユーザプロファイル生成に利用す る.スポットに対する評価値は存在しないので,推薦ランクはコサイン距離の合算の平 均で求める.実験のためにRuby 言語のMechanize*5で実装したツールを用いてSo-netbuzzmap から可能な限りのデータ(2009 年9 月18 日現在)を取得し,本研究の想定
*3http://buzzmap.so-net.ne.jp/spot/
*4http://buzzmap.blog.so-net.ne.jp/2010-01-12 *5https://rubygems.org/gems/mechanize
22 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現 表3.1 テストデータセットの内訳 ユーザ スポット スポットマーク タグ コメント 9,867 人 245,730個 118,441 個 20,258 種 125,034 個 図3.6 推薦リストの例 するデータ構造を持つテストデータセットとして再構築した.構築したテストデータは 表3.1の通り,9,867 人のユーザ,245,730 個のスポット,118,441 個のスポットマーク, 20,258 種のタグ,125,034個のコメントからなっている.以降,So-net buzzmap につい て記述する場合も「マイ地図帳に登録」を「スポットマーク」と置き換えて記述する. また,被験者には6 つの評価用エリアから選択した「既知のエリア」内に限定して少な くとも20 箇所をスポットマークしてもらい,タグ付けやコメントは被験者の自由意志に 任せているが,buzzmap上でスポットマークの数が20以上とアクティブにシステムを利 用していると考えられるユーザ数は,テストデータセット中で9,867人中の上位1,243人 (12.6%)と突出するほど少なくないことが確認できている. 各被験者の選択した1 つの「既知のエリア」とそれ以外の5 つの「不案内なエリア」そ れぞれで,推薦リストを3 つの手法で作成する.この時点で被験者ひとりあたり6 エリ ア× 3 手法の推薦リストができる.なお, すべての手法で,ひとつの推薦リストに含む スポットの上限は20 までのtop-20 リストとした. それぞれのエリアについて3 手法で 作成した推薦リストの中身をシャッフルし,被験者にはどのスポットがどの手法で推薦さ れたか見分けの付かない評価用推薦リストを作成する.3 手法間で同一スポットを推薦す る場合,評価用推薦リストには一つだけ追加する.つまり,評価用推薦リストには20∼ 60 個程度のスポットが含まれる.そうして作成した6 エリア分の評価用推薦リストを被 験者に図3.6のように提示し,スポットのリンクをクリックするとスポット情報を表示す る.[Google で検索]をクリックするとスポット名をGoogle で検索した結果を表示する. 被験者は評価用推薦リストに含まれる各スポットに対して,次のいずれかの主観評価値 を付ける.
3.3 評価実験 23 表3.2 被験者の既知のエリア/不案内なエリアの選択結果 京都 大阪 神戸 東京 名古屋 仙台 延べ人数 「既知のエリア」であ る被験者数 9 12 2 0 1 2 26 「不案内なエリア」で ある被験者数 17 14 24 26 25 24 130 • A:興味があり,内容が自分と関係が深い • B: 興味はあるが,万人向けの内容である(内容が自分と関係が深いとは言えない) • C: 興味はないし,内容も自分とは関係ない スポット情報のみで評価の判断がつかない場合に,Web で別途検索し詳細情報を得る ことを促した. 推薦精度の指標には,下記のP recisionを用いる. P recision-A = 評価A を得た推薦スポット数 推薦リスト中のスポット数 (3.7) P recision-AB = 評価A またはBを得た推薦スポット数 推薦リスト中のスポット数 (3.8) 各手法ごとに「既知のエリア」と「不案内なエリア」での推薦のP recisionを求める. ユーザの嗜好に合った推薦ができているほど,平均 P recision-Aと平均P recision-AB は高くなる. 同時に,次の指標も求める. Coverage = 推薦スポット数 推薦候補スポット数 (3.9) Coverage の低いシステムはそもそも推薦ランクを算出できるコンテンツの数が少ない ため,ユーザの嗜好に合った推薦を行なえる可能性は低いことになる.特に,不案内なエ リアにおいてスポット手法で推薦ランクの算出できるスポット数は,提案手法に比べて圧 倒的に少なくなると推測できる.
3.3.3
実験結果と考察
被験者の既知のエリア/不案内なエリアの分布を表3.2に示す.24 第3章 ユーザの嗜好に基づく情報推薦による情報収集活動支援の実現 図3.7 既知のエリアにおける平均P recision 図3.8 不案内なエリアにおける平均P recision 図3.9 3 手法のCoverage 図 3.10 不 案 内 な エ リ ア に お け る Coverage拡大の影響比較 推薦アルゴリズムそのものの性能を測るために,3 手法とも既知のエリアのみを対象と した,すなわち推薦候補が潤沢に用意できる良好な条件下で P recisionを評価する.26 名の被験者から得られた,既知のエリアにおける平均P recision-A,平均P recision-AB を図3.7に示す.上の棒グラフが平均P recision-A,下の棒グラフが平均P recision-AB を表し,単位はパーセントである.図3.7から,既知のエリアの平均P recisionは3.1.1 項の仮説通り,スポット手法→タグ手法→コメント手法の順に並んでいる.しかし,平 均P recision-Aの3 手法間と平均P recision-ABの3 手法間についてそれぞれ対応のな いt 検定を行なったところ,有意水準5% において有意的な差があるとは言えない結果と なった.したがって,推薦精度は3 手法で同等である. 全被験者の不案内なエリアにおける平均P recision-Aと平均 P recision-ABを図3.8 に示す.図 3.8から,不案内なエリアの平均 P recisionは3.1.1項で仮説したタグ手法 → コメント手法 → スポット手法ではなく,タグ手法 → スポット手法 → コメント手法 の順に並んでいる.しかし,平均P recision-Aの3 手法間と平均P recision-ABの3 手 法間についてそれぞれ対応のないt 検定を行なったところ,有意水準5% において有意的 な差があるとは言えない結果となった.したがって,不案内なエリアにおいても3 手法の 推薦精度は同程度である. スポット手法は実世界の物理的制約が原因となって不案内なエリアにおいてそもそも推 薦自体ができないか,もしくは推薦の精度が著しく低下すると仮説していた.この仮説を