2016 年度 修士論文
スパムメールの時系列変化に 適応する悪性メール分類法
提出日: 2017 年 1 月 30 日
指導:後藤滋樹教授
早稲田大学 基幹理工学研究科 情報理工学・情報通信専攻 学籍番号: 5115F027-7
久保 佑介
目次
1 序論 6
1.1 研究の背景 . . . 6
1.2 研究の目的 . . . 6
1.3 本論文の構成 . . . 7
2 電子メールおよびスパムメールの概要 8 2.1 電子メールの概要 . . . 8
2.1.1 電子メール送受信の原理 . . . 8
2.1.2 電子メールで送信されるデータ . . . 9
2.2 スパムメールの概要 . . . 10
2.2.1 スパムメールとは . . . 10
2.2.2 スパムメールの問題 . . . 10
2.2.3 スパムメールの種類 . . . 11
3 提案手法 13 3.1 先行研究 . . . 13
3.2 提案手法 . . . 14
3.2.1 提案手法1:データスライディングの適用 . . . 14
3.2.2 提案手法2:特徴量の選択 . . . 16
3.2.3 提案手法3:決定不可能データの除外 . . . 17
4 スパムのデータセット 19 4.1 SpamTrap . . . 19
4.2 スパムデータセットの概要 . . . 19
4.3 メールのラベル付け . . . 20
目次
5 評価実験 25
5.1 予備実験:学習データの日数の変更 . . . 25
5.2 評価実験の概要 . . . 27
5.3 実験1:データスライディングの有効性の検証 . . . 27
5.3.1 実験1の概要 . . . 27
5.3.2 実験1の結果 . . . 29
5.4 実験2:特徴量の選択の有効性の検証 . . . 32
5.4.1 実験2の概要 . . . 32
5.4.2 実験2の結果 . . . 33
5.5 実験3:決定不可能データの除外の有効性の検証. . . 35
5.5.1 実験3の概要 . . . 35
5.5.2 実験3の結果 . . . 37
6 結論 40 6.1 まとめ . . . 40
6.2 今後の課題 . . . 40
謝辞 42
参考文献 43
図一覧
2.1 電子メール送受信の概要 . . . 8
2.2 電子メールのデータ構成 . . . 9
2.3 フィッシングメールの手口 . . . 11
2.4 マルウェアメールの手口 . . . 12
3.1 先行研究の手法の概要 . . . 14
3.2 先行研究のデータの扱い方 . . . 14
3.3 データスライディングの概要 . . . 15
3.4 決定不可能なパターン . . . 18
4.1 メールのラベル付けの概要 . . . 21
4.2 スパムメールのメール数 . . . 22
4.3 フィッシングメールのメール数. . . 23
4.4 マルウェアメールのメール数 . . . 23
5.1 先行研究の学習データとテストデータ . . . 27
5.2 データスライディングを適用する場合の学習データとテストデータ . . . 27
5.3 先行研究の実験手順 . . . 28
5.4 データスライディングを適用する場合の実験手順 . . . 28
5.5 実験1におけるスパムメールの検知率の時系列変化 . . . 30
5.6 実験1におけるフィッシングメールの検知率の時系列変化 . . . 30
5.7 実験1におけるマルウェアメールの検知率の時系列変化 . . . 31
5.8 特徴量の選択を行う場合の実験手順 . . . 32
5.9 実験2におけるスパムメールの検知率の時系列変化 . . . 33
5.10 実験2におけるフィッシングメールの検知率の時系列変化 . . . 34
5.11 実験2におけるマルウェアメールの検知率の時系列変化 . . . 34
図一覧
5.14 実験3におけるスパムメールの検知率の時系列変化 . . . 38 5.15 実験3におけるフィッシングメールの検知率の時系列変化 . . . 38 5.16 実験3におけるマルウェアメールの検知率の時系列変化 . . . 39
表一覧
3.1 先行研究で使用した16種類の特徴量 . . . 13
3.2 特徴量選択に使用するデータセット . . . 16
3.3 検討対象から除外した特徴量 . . . 17
4.1 SpamTrapに使用されたドメイン数 . . . 19
4.2 スパムデータセットの概要 . . . 20
4.3 スパムデータセットのメール数 . . . 22
4.4 テストデータの1日ごとのメール数 . . . 24
5.1 学習データの日数ごとの検知数 . . . 25
5.2 先行研究の検知数とデータスライディング適用時の検知数 . . . 29
5.3 特徴量の選択の有無による検知数 . . . 33
5.4 決定不可能データの除外の有無による検知数 . . . 37
5.5 決定不可能データのデータ数 . . . 37
第 1 章 序論
1.1 研究の背景
電子メールはインターネットの初期から存在する通信手段である.インターネットの普及に 伴い利用者が増加し,現在電子メールは世界で最も利用されている通信手段の一つとなってい るしかし,その中でスパムメール(迷惑メール)による被害が問題となっている.スパムメール には,出会い系サイトやアダルトサイトの広告,ワンクリック詐欺など,様々な目的のものが 存在する.中には,受信者を実在する企業の偽のホームページに誘導してクレジットカード番 号や暗証番号などの個人情報を入手することを目的としフィッシングメールや,受信者を不正 なソフトウェア (マルウェア)に感染させることを目的としたマルウェアメールといった,ユー ザが直接的に被害を受ける危険性の高いスパムメールが存在する.
これに対して,筆者は卒業研究[1]において,メールのヘッダ情報から特徴量を求めて,こ れを機械学習に適用することで悪性メールを検出する手法を提案した.2014年当時のデータ で評価実験を行ったところ,90%以上の高い精度で検出することができた.しかし,その後の 分析の結果.この手法ではスパムメールの時系列変化に十分に対応できないことが分かった.
スパムメールは時間の経過に伴い性質が変化すると言われている.そのため,ある期間におい て最適な手法が異なる期間でも最適な手法であるとは限らない.実際に,卒業研究の手法を用 いて,異なる期間で実験を行ったところ精度が下がることがあった.
1.2 研究の目的
第1.1節で述べたように,スパムメールの中にはフィッシングメールやマルウェアメールの ような危険性の高い悪性メールが存在する.また,スパムメールは時間の経過に伴い性質が変 化するため,時系列変化に対応した手法が必要となる.
本研究では,筆者が卒業論文で提案した既存手法を改良することでスパムメールの時系列変
第 1 章 序論
化に対応することを目的とする.具体的には,スパムメールを収集する目的で使用されている メールアドレスであるSpamTrapに配送されたメールを用いて本研究で提案する手法の有効性 を評価する.なお,本研究では,悪性メールを高い精度で検出することを第一の目的としてい ない.本研究で提案する手法を既存手法に適用することで,検出精度がどのように変化するか という点に着目している.
1.3 本論文の構成
本論文は以下の章により構成される.
第1章 序論
本論文の概要を述べる.
第2章 電子メールおよびスパムメールの概要
スパムメールおよび悪性メールの概要を紹介する.
第3章 提案手法
本研究の提案手法を述べる.
第4章 スパムのデータセット
本研究で使用したデータセットの概要を説明する.
第5章 評価実験
提案手法に対する評価実験の結果,および考察を述べる.
第6章 結論
本論文の結論を述べるとともに,今後の課題を示す.
第 2 章
電子メールおよびスパムメールの概要
2.1 電子メールの概要
2.1.1 電子メール送受信の原理
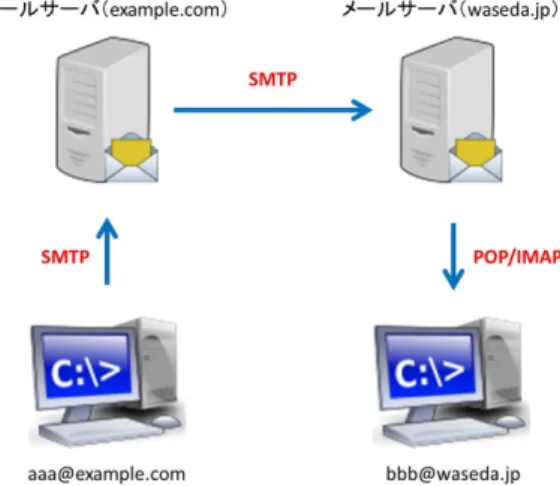
電子メールは,SMTPというプロトコルに従って,クライアントとサーバがメールデータ をやり取りしながら,宛先のメールアドレスにメール転送する.そして,受信側ではPOPや IMAPというプロトコルを用いてメールデータを受信する.例として,[email protected]から
[email protected]にメールを送信する場合の一連の流れを図2.1に示す.まず,送信側[email protected]
はSMTPを用いてメールサーバ (example.com)へメールデータを送信する.そして,メール データを受け取ったメールサーバは[email protected]というメールアドレスから宛先のメール
サーバ (waseda.jp)を調べる.そして,そのメールサーバへメールデータを送信する.受信側
[email protected]は,POPやIMAPを用いてメールサーバからメールデータを受信する.
図 2.1: 電子メール送受信の概要
第 2 章 電子メールおよびスパムメールの概要
2.1.2 電子メールで送信されるデータ
図2.2のように,送信されてきた電子メールには大きく分けて2つの領域が存在する.一つ は,メールの本文が記載されている「メールボディ」である.ここには,メールの内容や添付 ファイルのデータ,つまり,送信者が伝えたい内容が記載されている.もう一つが「メールヘッ ダ」である.メールヘッダには,ネットワークを経由する中で付加された様々な情報が記載さ れている.送信者のメールアドレスはもちろん,メールの送信に使われたサーバのIPアドレ スや,メールの送受信に使用したソフトウェアなど,有用な情報を多く含んでいる.
図 2.2: 電子メールのデータ構成
第 2 章 電子メールおよびスパムメールの概要
2.2 スパムメールの概要
2.2.1 スパムメールとは
スパムメールは迷惑メールとも呼ばれ,「受信者の意図に関わらず,自動的に送られてくる メール」や「不特定多数の相手に送られる,内容として広告・宣伝・誘導・詐欺などの性質が 強いメール」とされている.ただしスパムメールの定義に関しては幅広い見解があり,共通す る厳密な定義は定められてないのが現状である.
2.2.2 スパムメールの問題
スパムメールによって引き起こされる問題点として,以下が挙げられる.
• メール整理に伴う時間の浪費,メール受信者への精神的負担
• 重要なメールの見落とし
• ネットワークトラフィックの圧迫
• サーバ資源の浪費
• フィッシング詐欺などの被害
• マルウェアの感染
第 2 章 電子メールおよびスパムメールの概要
2.2.3 スパムメールの種類
第1.1節で述べたように,スパムメールの中にはフィッシングを目的としたメールや,マル ウェア感染を目的とした悪質なメールが存在する.以下,フィッシングを目的としたメールを フィッシングメール,マルウェア感染を目的としたメールをマルウェアメールと呼ぶ.本節で は,フィッシングメールとマルウェアメールの手口について述べる.
フィッシングメール
フィッシングとは,金融機関や企業からの正規のメールやWebサイトを装い,暗証番号や クレジット番号などの個人情報を搾取する詐欺である.攻撃者は,本文に個人情報を入力する よう促す文章や,金融機関や企業の正規のWebサイトを装った偽のWebサイトへのリンクを 記載したメールを無差別に送りつける.受信者がリンク先のWebサイトで個人情報を入力す ると,攻撃者に情報が送信されてしまう.本研究では,このような個人情報を搾取することを 目的に偽装されたWebサイト(フィッシングサイト)のリンクが本文に記載されたメールを フィッシングメールと呼ぶ.フィッシングメールの手口を図2.3に示す.
図 2.3: フィッシングメールの手口
第 2 章 電子メールおよびスパムメールの概要
マルウェアメール
マルウェア感染を目的としたメールには,以下の2種類がある.
1. マルウェア感染サイトのリンクを本文に記載して,ユーザを感染サイトに誘導する 2. 文書ファイルや画像ファイルなどに偽装されたマルウェアを添付する
本研究では,2つの種類のうちマルウェア感染サイトのリンクが本文に記載されたメールをマル ウェアメールを以下で取り扱う.マルウェアメールの手口を図2.4に示す.文献 [2]では,メー ルを利用して受信者を攻撃コードを含むサイトに誘導し,マルウェアに感染させるWeb型受 動攻撃の調査を行っている.その調査によると,あるメールサーバに15日間で31,618の攻撃 サイトのリンクを含むスパムメールが送信されてきたという.
図 2.4: マルウェアメールの手口
第 3 章 提案手法
3.1 先行研究
筆者は先行研究[1]において悪性メールを検出する手法を提案した.これは,メールのヘッダ情 報から16種類の特徴量を求めて,その特徴量を教師あり機械学習の一つであるSVM (Support
Vector Machine)に適用することで悪性メールを検出するというものである.先行研究の手法
において使用した特徴量を表3.1に記載する.また,先行研究の手法の概要を図3.1に示す.
この手法を用いることで,スパムメールの検出率92.2%,フィッシングメールの正答率91.6%,
マルウェアメールの検出率96.1%という高い精度で悪性メールを検出することができた.
表 3.1: 先行研究で使用した16種類の特徴量
経由メールサーバ数 送信元アドレスのドメインレベル
Localhost (127.0.0.1)の有無 送信元アドレスのドメイン部の正引き
送信者のIPアドレスのDNS逆引き Reply-Toヘッダの有無 添付ファイルの有無 Mailerヘッダの有無
送信元アドレスのドメイン長 Content-Transfer-Encodingヘッダの有無 送信元アドレスのローカル長 Charsetの有無
送信元アドレスのドメイン部のエントロピー HTMLメールであるか否か 送信元アドレスのローカル部のエントロピー マルチパートメールであるか否か
第 3章 提案手法
図 3.1: 先行研究の手法の概要
3.2 提案手法
本研究は,先行研究の手法を改良することでスパムメールの時系列変化に対応することを目 的としている.以下に,本研究で提案する3つの手法について説明する.
3.2.1 提案手法1:データスライディングの適用
先行研究では,図3.2のように複数日分のテストデータをまとめて分類していた.しかし,
この方法では学習データセットの最も古いデータとテストデータセットの最も新しいデータと の時間差が大きい.結果として,学習データセットとテストデータセットの性質が離れてしま い誤検知の原因となる.
図 3.2: 先行研究のデータの扱い方
第 3章 提案手法
そこで,本研究では,データスライディングという手法を提案する.以下に,データスライ ディングの手順を記載する.また,データスライディングの概要を図3.3に示す.
1. ある1日分のテストデータを判別する
2. 判別を終えた1日分のテストデータを学習データセットに追加する.その際に,学習デー タセットのうち,最も古い1日分のデータを学習データセットから除外する.
3. ステップ1で使用したテストデータの次の日のメールデータを新しいテストデータとし てステップ1に戻る
テストデータを1日分にすることによって,学習データとテストデータの時間の差を小さく することができる.また,時間の経過に伴って分類器を更新し続けることで時系列変化に対応 することができる.ここで,データスライディングにおいて,学習データセットとして何日分 使用するかが考慮すべき重要なパラメータとなる.
図 3.3: データスライディングの概要
第 3章 提案手法
3.2.2 提案手法2:特徴量の選択
先行研究では,表3.1に示した16種類の特徴量をすべて使用した.しかし,スパムメールは 時間の経過に伴い性質が変化するため,異なる期間においては16種類の特徴量を使用するこ とが最適であるとは限らない.予備実験の結果,特徴量の組み合わせを変化させることで,精 度が向上する場合が見られた.
そこで,本研究では,最も分類精度が高くなると予想される特徴量を選択する手法を提案す る.特徴量を選択する方法として,以下の2つの手法がある.
1. フィルターアプローチ
特徴量ごとに評価値を算出する.そして,閾値以上の特徴量のみを使用する.
2. ラッパ−アプローチ
学習データに対して,分類アルゴリズムを適用する.その際,あらゆる特徴量の組み合 わせを試し,最も精度が高かった組み合わせを特徴量として使用する.
本研究では,ラッパーアプローチを元にした手法を提案する.本研究で提案する特徴量の選 択手法の手順を説明する.
1. 表3.2のように学習データセットを特徴量選択のための学習データセットとテストデー タセットに分割する.
表 3.2: 特徴量選択に使用するデータセット
データセット 概要
特徴量選択用学習データセット
学習データセットから
特徴量選択用テストデータを除いたもの 特徴量選択用テストデータセット
学習データセットの中で
各クラスの最も新しいメール300通ずつ
2. 特徴量選択のための学習用データセットを用いて,分類器を構築する.
3. 特徴量選択のためのテストデータセットを用いて,分類精度を求める.
4. 特徴量の別の部分集合でステップ2,ステップ3を実行する.
5. ステップ2から4までを繰り返す.そして,最も精度が高かった特徴量の部分集合を特 徴量として使用する.
本研究では16種類の特徴量を使用しているため,特徴量の部分集合のパターンは65,535通
第 3章 提案手法
予備実験で有効とされている特徴量を検討対象から除外し,他の特徴量に対して選択を行う こととする.本手法で,検討対象から除外した特徴量を表3.3に示す.なお,3.2.1で提案した データスライディングと組み合わせて使用する場合,学習データが更新される度に特徴量の選 択を行うことになる.
表 3.3: 検討対象から除外した特徴量
経由メールサーバ数 送信元アドレスのローカル部のエントロピー 送信元アドレスのドメイン長 送信元アドレスのドメインレベル 送信元アドレスのローカル長 HTMLメールであるか否か 送信元アドレスのドメイン部のエントロピー
3.2.3 提案手法3:決定不可能データの除外
本研究で使用するSVMは入力ベクトル空間上に超平面と呼ばれる線形関数を作成し,この 超平面によって二値分類を行う.SVMは基本的には2クラス分類器であるため,多クラス分 類をすることはできない.この問題に対して,先行研究ではペアワイズ法(one vs one手法)を 用いることで多クラス分類を実現した.ペアワイズ法では,各クラス対ごとに超平面を構築す る.n個のクラスがある場合,n(n-1)/2個の超平面を構築する.つまり,スパムメール,フィッ シングメール,マルウェアメールの3クラスの分類では3つの超平面が作成される.そして,
各超平面でテストデータを分類し,多数決で最も多くの票を得たクラスに分類される.
しかし,多数決方式では,クラスの決定が不可能な場合がある.例えば,A,B,Cの3クラ スの場合,AクラスとBクラスの超平面,AクラスとCクラスの超平面,BクラスとCクラ スの超平面の3つの超平面が作成される(以降,それぞれAB超平面,AC超平面,BC超平面 と呼ぶ).テストデータの分類において,AB超平面ではA,AC超平面ではC,BC超平面で はBと分類された場合,すべてのクラスが同じ票数となり多数決で決定することができない.
具体的には,図3.4のような場合である.図3.4のように超平面が構築された場合,各超平面 に囲まれた領域は多数決で決定することができない.このように多数決で決定することができ ないデータは,各超平面からの距離 (分類スコア) を元に最も近いクラスに分類される.本研 究では,このようなデータを決定不可能データと呼ぶ.
第 3章 提案手法
図 3.4: 決定不可能なパターン
実験結果を分析した結果,決定不可能データは誤検知している場合が多いことが分かった.
データスライディングを適用する場合,提案手法で分類したテストデータが学習データに追加 されるため,学習データに間違いを含むことになる.そのため,データスライディングを継続 していく中で,検知率が低下すると予想される.誤検知の可能性が高い決定不可能データを除 外することで,学習データに間違いを含む確率を下げることができる.なお,本手法はデータ スライディングと合わせて使用することを前提として,データスライディング適用時の課題を 解決するために提案する手法である.
第 4 章
スパムのデータセット
本章では,本研究で使用したスパムのデータセットについて説明する.
4.1 SpamTrap
本研究では,SpamTrapで収集したデータをスパムデータセットとして利用する.SpamTrap とは,スパムメールを収集することを目的としたメールアドレスのことである.SpamTrapの メールアドレスは,通常の用途には使用されていないため,SpamTrapに届くメールは宛先を 間違えたメールや,SpamTrapとして使用される前に使われていたメールアドレスに届くメー ルを除けば,無差別に送りつけられるスパムメールである.よって,SpamTrapで収集したス パムメールを分析することでスパム業者を特定したり,リスト化してスパムフィルタのフィル タリング情報として活用することができる.
本研究において使用したSpamTrapでは,合計で65のドメインを利用してスパムメールの 収集を行った.表4.1に本実験で用いたドメイン数をトップレベルドメインごとに示す.
表 4.1: SpamTrapに使用されたドメイン数
TLD com net jp org
ドメイン数 46 13 5 1
4.2 スパムデータセットの概要
本研究では,2016年10月2日〜2016年11月25日にSpamTrapで収集したメールをスパム
第 4 章 スパムのデータセット
を提案手法で分類することで精度を求める.表4.2にスパムデータセットの概要を記載する.
なお,本研究では,フィッシングサイトのURLが本文に記載されたメールをフィッシングメー ル,マルウェア感染サイトのURLが本文に記載されたメールをマルウェアメールと分類して 検出する対象としている.そのため,本文にURLが記載されていないメールはスパムデータ セットから除外する.
表 4.2: スパムデータセットの概要
データセット 期間
スパムデータセット 2016年10月2日〜2016年11月25日 テストデータセット 2016年11月6日〜2016年11月25日
4.3 メールのラベル付け
スパムデータセットに対して,以下の処理を行いメールのラベル付けを行う.このラベルを 正解として,分類器の構築や提案手法の評価を行う.
1. メール本文に記載されているURLをすべて抽出する.
2. Google Safe Browsing API [3]を用いて,抽出したURLを以下のように分類する.
• phishing:Google Safe Browsing APIでphishingもしくはphishing,malwareと判 定された場合
• malware:Google Safe Browsing APIでmalwareと判定された場合
• non:phishing・malware どちらにも該当しなかった場合
3. ステップ2のURLの分類結果に基づいて,以下のようにメールを分類する.
• フィッシングメール:phishingと判定されたURLが記載されている場合
• マルウェアメール: malwareと判定されたURLが記載されている場合
• スパムメール:nonと判定されたURLが記載されている場合
なお,Google Safe Browsing APIとは,Googleが提供しているフィッシングサイト及びマ ルウェア感染サイトの疑いがあるページリストに基づき,URLを分類するサービスである.
フィッシングサイトと判定されたURLはphishing,マルウェア感染サイトと判定されたURL
はmalware,フィッシングサイトかつマルウェア感染サイトと判定されたURLはphishing,
第 4 章 スパムのデータセット
メールのラベル付けの概要を図4.1に示す.
図 4.1: メールのラベル付けの概要
第 4 章 スパムのデータセット
4.4 メール数
本研究に用いたスパムデータセットのメール数を表4.3に示す.
表 4.3: スパムデータセットのメール数
データセット スパムメール フィッシングメール マルウェアメール 合計 スパムデータセット 1,096,857 31,880 8,542 1,137,729 テストデータセット 873,375 30,877 1,884 906,136
テストデータについては,スパムメール,フィッシングメール,マルウェアメールそれぞれ のメール数の時系列の変化を図4.2,図4.3,図4.4に示す.また,1日ごとのメール数を表4.4 に記載する.
図4.3より,フィッシングメールのメール数が19日以降に急激に増加していることが分かる.
また,図4.4より,マルウェアメールのメール数の14日にピークがあることが分かる.このよ うに,メール数からも時間の経過に伴う変化があることが分かる.
図 4.2: スパムメールのメール数
第 4 章 スパムのデータセット
図 4.3: フィッシングメールのメール数
第 4 章 スパムのデータセット
表 4.4: テストデータの1日ごとのメール数
データ収集日 スパムメール フィッシングメール マルウェアメール 合計
2016/11/06 32,719 6 89 32,814
2016/11/07 61,219 13 49 61,281
2016/11/08 34,031 14 103 34,148
2016/11/09 85,210 34 315 85,559
2016/11/10 31,540 39 3 31,582
2016/11/11 28,065 41 24 28,130
2016/11/12 29,814 12 12 29,838
2016/11/13 29,039 218 110 29,367
2016/11/14 30,423 249 859 31,531
2016/11/15 33,709 121 53 33,883
2016/11/16 29,885 44 2 29,931
2016/11/17 39,041 915 4 39,960
2016/11/18 45,868 62 0 45,930
2016/11/19 39,047 3,735 56 42,838
2016/11/20 33,186 4,201 117 37,504
2016/11/21 66,584 3,978 46 70,608
2016/11/22 44,264 4,463 27 48,754
2016/11/23 71,473 4,595 4 76,072
2016/11/24 71,886 4,490 4 76,380
2016/11/25 36,372 3,647 7 40,026
第 5 章 評価実験
第3章では,本研究が提案する既存手法を改良する手法について述べた.本章では,第4章で 説明したデータセットを用いて,本研究で提案する手法の評価実験を行う.
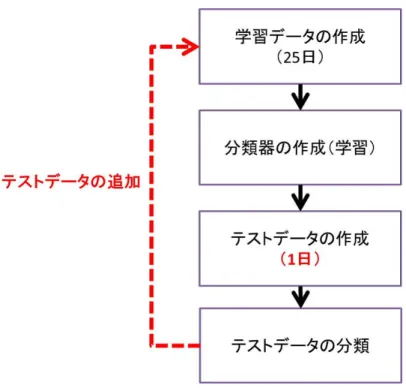
5.1 予備実験:学習データの日数の変更
データスライディングの説明において,学習データの日数は重要なパラメータであると述べ た.予備実験では,学習データの日数を変動させた際の検知数の変化を観測する.そして,最 も結果が良かった日数を評価実験において学習データの日数のパラメータとして使用する.テ ストデータは,2016年11月6日〜2016年11月25日に収集したものを使用した.表5.1に,各 学習データの日数の検知数を記載する.
表 5.1: 学習データの日数ごとの検知数
日数 スパムメール フィッシングメール マルウェアメール 合計
35 657,771 26,254 1,392 685,417
30 688,592 25,317 1,346 715,255
25 714,689 26,179 1,427 742,295
20 707,452 21,662 1,263 730,377
15 704,893 24,502 1,284 730,679
10 741,688 24,453 976 767,117
表5.1より,学習データの日数によって検知数が変化することが分かる.スパムメールにお
第 5章 評価実験
ることが分かる.一方で,フィッシングメールやマルウェアメールは,日数が多い場合の方が 検知数が多かった.これは,学習データに含まれる検体数が影響していると考えらえれる.第 4.4節からも分かるように,スパムメールは毎日大量に送信される.しかし,フィッシングメー ルやマルウェアメールのような悪性メールはスパムメールに比べ送信量が少ない.そのため,
学習データの日数を少なくしすぎると,学習データに悪性メールの検体を十分に確保すること ができず,学習データに偏りが生じてしまう.これらのことから,学習データの日数を少なく することで学習データとテストデータの時間を近くすることは重要であるが,その一方で検体 の確保のためにある程度の日数が必要があることが分かる.
本実験の結果,学習データの日数を25日とした場合の検知結果が最も良かったため,評価 実験においては学習データの日数のパラメータとして25日を使用する.なお,本研究で使用 したデータでは25日が最適なパラメータであったが,他のデータでもこの値が必ずしも最適 であるとは限らない.
第 5章 評価実験
5.2 評価実験の概要
本研究では,各手法の有効性を検証するために3つの実験を行う.以下に,各実験の概要と 結果を記載する
5.3 実験 1 :データスライディングの有効性の検証
5.3.1 実験1の概要
実験1では,先行研究の実験結果とデータスライディングを適用する場合の実験結果を比較 することで,データスライディングの有効性を検証する.先行研究では,図5.1のように,2016 年10月12日〜2016年11月5日に収集した25日分の学習データで作成した分類器を用いて,
全テストデータの分類を行う.その際,データスライディング適用時との検知率の比較をする ために,テストデータの1日ごとの検知結果を求める.
図 5.1: 先行研究の学習データとテストデータ
一方,データスライディングを適用する場合は,図5.2のように学習データとテストデータ を1日単位で更新する.なお,本実験では,テストデータを学習データに追加する際に,デー タのラベルは検知結果ではなく第4.3節でラベル付けした結果を使用する.つまり,学習デー タはすべて正しいラベル付けがされている.
第 5章 評価実験
図5.3に先行研究の実験手順を,図5.4にデータスライディングを適用する場合の実験手順 を示す.
図 5.3: 先行研究の実験手順
図 5.4: データスライディングを適用する場合の実験手順
第 5章 評価実験
5.3.2 実験1の結果
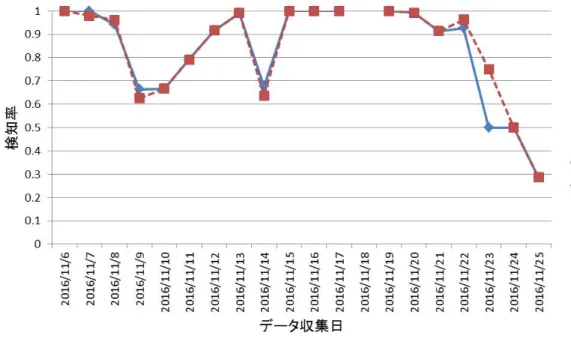
表5.2に先行研究の検知数とデータスライディング適用時の検知数を記載する.また,スパ ムメール,フィッシングメール,マルウェアメール1の検知率の時系列の変化をそれぞれ図5.5,
図5.6,図5.7に示す.フィッシングメールやマルウェアメールは検知率に大きな変動がみられ
る.これは,メールの検体数が少なく,1つの間違いが大きな影響力を及ぼしてしてしまうた めである.
表 5.2: 先行研究の検知数とデータスライディング適用時の検知数
スパムメール フィッシングメール マルウェアメール 合計 テストデータセット 873,375 30,877 1,884 906,136
先行研究 644,634 11,188 1,470 657,292
データスライディングの適用 714,689 26,179 1,427 742,295
表5.2より,データスライディングを適用することで,スパムメール,フィッシングメール の検知数が増加していることが分かる.特に,フィッシングメールについては2倍以上増加し た.
また,図5.6に着目すると,フィッシングメールの20〜25日の検知率が先行研究と比較して 大幅に上昇していることが分かる.これは,テストデータに時間が近いデータが学習データに 含まれていることが関係していると考えられる.つまり,20〜25日のフィッシングメールの検 知に19日以降のデータが効いている.第4.4節で述べたように,19日〜25日はフィッシング メールの送信量が増加した時期である.しかし,19日の検知率はデータスライディングを適 用したとしても上昇していない.このことから,19日に誤検知したメールと19日以前に送信 されたメールは性質が異なる,つまり,異なるキャンペーン2であると考えられる.また,一 方で,20日以降の検知率が上昇していることから,19日に誤検知したメールとデータスライ ディングを適用することで検知できた20〜25日のメールは同じキャンペーンに属すると予想 される.
次に,図5.6に着目する.マルウェアメールのメール数のピークがあった14日を見ると,デー タスライディングを適用したとしても検知率が向上していないことが分かる.これは,フィッ シングメールの時と同様で,14日に誤検知したメールと14日以前に送信されたメールの性質 が異なるためであると考えられる.
第 5章 評価実験
以上の結果から,データスライディングを適用することで精度が向上することが分かった.
しかし,過去に見られなかったキャンペーンのメールが送信された場合,本手法では対応する ことができない可能性が高いことが分かった.
図 5.5: 実験1におけるスパムメールの検知率の時系列変化
図 5.6: 実験1におけるフィッシングメールの検知率の時系列変化
第 5章 評価実験
図 5.7: 実験1におけるマルウェアメールの検知率の時系列変化
第 5章 評価実験
5.4 実験 2 :特徴量の選択の有効性の検証
5.4.1 実験2の概要
実験2では,表3.1に示した特徴量をすべて使用する(特徴量の選択無し)場合の実験結果と 特徴量の選択を行う(特徴量の選択有り)場合の実験結果を比較することで,特徴量の選択の 有効性を検証する.本実験では,実験2で既にデータスライディングの有効性が分かったため,
データスライディングを適用して実験を行う.つまり,特徴量をすべて使用する場合,実験1 のデータスライディング適用時と同じ手順で実験を行う.なお,本実験でも,実験1と同様に テストデータを学習データに追加する際に,データのラベルは検知結果ではなく第4.3節でラ ベル付けした結果を使用する.図5.8に特徴量の選択を行う場合の実験手順を示す.
図 5.8: 特徴量の選択を行う場合の実験手順
第 5章 評価実験
5.4.2 実験2の結果
表5.3に特徴量の選択の有無による検知数を示す.また,スパムメール,フィッシングメー ル,マルウェアメールの検知率の時系列変化をそれぞれ図5.5,図5.6,図5.7に示す.
表 5.3: 特徴量の選択の有無による検知数
スパムメール フィッシングメール マルウェアメール 合計 テストデータセット 873,375 30,877 1,884 906,136
特徴量の選択無し 714,689 26,179 1,427 742,295 特徴量の選択有り 700,658 26,881 1,620 729,159
表5.3より,フィッシングメールやマルウェアメールの検知数が増加していることが分かる.
つまり,悪性メールの検出において特徴量の選択が有効に働いたことが分かる.一方で,スパ ムメールは,全テストデータで見ると検知数は減少している.しかし,日単位で見ると特徴量 の選択を行うことで検知数が増加する場合が見られた.
以上の結果から,特徴量の選択を行うことで精度が向上することが分かった.しかし,本実 験では,すべての特徴量を使用する場合と特徴量の選択を行う場合の比較しか行えていない.
そのため,特徴量の部分集合の中で,本手法で選択した特徴量が最も精度が高くなるパターン であるかは検証できていない.
第 5章 評価実験
図 5.10: 実験2におけるフィッシングメールの検知率の時系列変化
図 5.11: 実験2におけるマルウェアメールの検知率の時系列変化
第 5章 評価実験
5.5 実験 3 :決定不可能データの除外の有効性の検証
5.5.1 実験3の概要
実験3では,決定不可能データを学習データから除外することの有効性を検証する.実験1,
2では,テストデータを学習データに追加する際に,データのラベルは第4.3節においてラベ ル付けした結果を使用した.つまり,学習データに間違いを含むことはなかった.しかし,本 実験では図5.12のようにテストデータを追加する際に,提案手法で分類した結果を使用する.
つまり,学習データに間違いを含むことになる.本実験では,実験2で既に特徴量の選択の有 効性が分かったため,特徴量の選択を行う.図5.13に決定不可能データの除外を適用する場合 の実験手順を示す.
図 5.12: 実験3の学習データとテストデータ
第 5章 評価実験
図 5.13: 決定不可能データを除外する場合の実験手順
第 5章 評価実験
5.5.2 実験3の結果
表5.4に決定不可能データを除外する場合としない場合の検知数を記載する.また,スパム メール,フィッシングメール,マルウェアメールの検知率の時系列の変化をそれぞれ図5.14,
図5.15,図5.16に示す.
表 5.4: 決定不可能データの除外の有無による検知数
スパムメール フィッシングメール マルウェアメール 合計 テストデータセット 873,375 30,877 1,884 906,136
除外しない 625,236 23,296 1,432 649,964
除外する 640,910 23,794 1,495 666,199
表5.4より,決定不可能データを除外することで検知数が増加していることが分かる.この ことから,決定不可能データを除外することは有効であることが分かる.しかし,実験2の結 果と比較すると検知数が減少している.つまり,学習データにテストデータを追加する時に提 案手法で分類した結果を使用すると,検知精度が低下することが分かる.
また,本実験で除外した決定不可能データのデータ数を表5.5に記載する.本実験で除外し たデータの検知結果を分析したところ,すべてのデータを誤検知していることが分かった.
表 5.5: 決定不可能データのデータ数
スパムメール フィッシングメール マルウェアメール 合計
1,261 2 0 1,263
第 5章 評価実験
図 5.14: 実験3におけるスパムメールの検知率の時系列変化
図 5.15: 実験3におけるフィッシングメールの検知率の時系列変化
第 5章 評価実験
図 5.16: 実験3におけるマルウェアメールの検知率の時系列変化
第 6 章 結論
6.1 まとめ
本研究では,スパムメールの時系列変化に対応することを目的に3つの手法を提案した.そ の手法が,データスライディングの適用,特徴量の選択,決定不可能データの除外である.デー タスライディングを適用することにより,学習データとテストデータの性質を近くできる.さ らに,1日ごとに分類器を更新し続けることで時間の経過に伴う変化に対応できる.また,特 徴量の選択を行うことにより,最も精度が高くなると予想される特徴量の組み合わせを選択す ることができる.そして,決定不可能データを除外することで,誤検知の可能性が高いデータ を除くことができる.
各提案手法に対して,SpamTrapで収集したスパムデータを用いて評価実験を行い,手法の 有効性を検証した.その結果,各提案手法の有効性を確認することができた.特に,データス ライディングの適用が時系列変化に対応するために有効であると言える結果が得られた.また,
特徴量の選択や決定不可能データを除外することで検知精度が向上することが分かった.しか し,本研究の実験結果はスパムのデータセットに依存しているのは事実である.
6.2 今後の課題
本研究の今後の課題を以下に述べる.
• 様々な観点からの評価や実験結果の分析
本研究では,そのメールが所属するクラスに正しく分類することができた数を検知数と して提案手法の評価を行った.しかし,本当に時系列変化に対して有効であるか検証する ためには他の観点からの評価や実験結果の分析が必要である.また,検知/誤検知デー タの分析を詳細に行うことでスパムメールの性質を見つけることができると考えられる.
第 6 章 結論
• 過去のメールとは性質が異なるメールの検知
過去に送信されたメールとは異なる性質,つまり,異なるキャンペーンのメールが突発 的に大量に送られてきた場合,本手法では検知することができないことが分かった.こ のような,メールを機械学習手法で検知することは難しい.そのため,ルールベースで 検知するような新たな手法が必要となる.
• 他のデータセットや手法での検証
本研究では,スパムデータセットとしてSpamTrapで収集したメールデータを使用した.
本手法の有効性を確かめるために,他のスパムデータセットでの評価を行う必要がある.
また,本研究の提案手法は他の検出手法に適用することも可能である.他の手法に適用 して評価をすることで有効性の確認や改善点の発見をすることができる.
謝辞
本修士論文を作成するにあたり,日頃よりご指導を頂いた早稲田大学基幹理工学研究科の後藤 滋樹教授に深く感謝致します.また,本研究においてご協力とご指導をいただいた早稲田大学 基幹理工学研究科の森達哉准教授に深く感謝いたします.最後に,本研究を進めるにあたり,
多大なるご協力を頂きました後藤研究室の皆様に重ねて感謝致します.
参考文献
[1] 久保 佑介, ヘッダ情報の機械学習による悪性メールの分類法 ,早稲田大学卒業論文,
Feb. 2015.
[2] 川古谷 祐平,秋山 満昭,青木 一史,伊藤 光恭,高倉 弘喜, スパムメールに起因する Web型受動攻撃の実態調査 ,電子情報通信学会技術研究報告. ICSS,情報通信システム セキュリティ109(33),pp.21–26,May 2009.
[3] Google Safe Browsing API
https://developers.google.com/safe-browsing/
[4] 小坂 翔吾,北園 淳,小澤 誠一,班 涛,中里 純二,島村 隼平, 自律学習能力を有す る悪性スパムメール検出システム ,電子情報通信学会,信学技報,vol,115,no,488,
ICSS2015-50,pp.19–24,Mar,2016.
[5] 志村 正樹, 電子メールに含まれるURLの情報を用いた悪性メールの分類法 ,早稲田 大学卒業論文,Feb. 2014.
[6] 志村 正樹, スパムトラップによるマルウェア付スパムメールの特徴分析 ,早稲田大学 大学院修士論文,Feb. 2016.
[7] 坂井 哲也, ヘッダ情報の機械学習によるspamメール判別法 ,早稲田大学大学院修士 論文,Feb. 2014.
[8] 本嶋悠也, IPアドレスの特徴を用いたSVMによるspamメールの判別方法 ,早稲田大 学大学院修士論文,Feb. 2011.
[9] 千葉 大紀,森 達哉,後藤 滋樹, 悪性Webサイト探索のための優先巡回順序の選定法 , コンピュータセキュリティシンポジウム2012論文集,2012(3),pp.805–812,Oct. 2012.
参考文献
[11] 濱崎 邦秀,三浦 孝夫, SVMにおける超平面への距離を用いたクラス分類 ,情報・シス テムソサイエティ特別企画 学生ポスターセッション予稿集, p.148, May, 2014.
[12] スパムメールとは ,Kaspersky Labs Japan,http://www.viruslistjp.com/spam/
153350526.html,Nov. 2017.
[13] ネット詐欺:フィッシング詐欺 ,Symantec,http://jp.norton.com/cybercrime- phishing/promo,Nov. 2017.
[14] LIVSVM -A Library for Support Vector Machine- http://www.csie.ntu.edu.tw/~cjlin/libsvm/
[15] Google Safe Browsing API Developers Guide ,https://developers.google.com/
safe-browsing/lookup_guide
[16] 渡部綾太,愛甲健二, スパムメールの教科書 ,DATA HAOUSE,2006.