環結合による類似検索の高性能化
8
0
0
全文
(2) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. してカタログ間にずれが生じてしまう。このずれを修正す. R-Tree は MBR の最小化のみを考慮してノード分割を行う. るためにクロスマッチ [9] という処理が行われる。クロス マッチの一部は低次元座標データに対する類似検索になっ ている。. 2.3 空間索引 n 次元データを格納したデータベース同士の類似検索に おいて、全ての組合わせに対して照合を行うと O(n2 ) の計 算負荷がかかる。よって、データ数の増加に伴い処理時間 図 2.2 R-Tree: ノード間の重なり. が急激に増加してしまう。空間索引を用いれば照合を行う 組合せの数を減らすことができ、類似検索を高速化するこ とができる。以下、本論文で扱う空間索引について説明を. ので、図 2.2(b) のように子孫関係にないノードとの重なり. していく。. が起こりやすく検索効率が悪化しやすい。. R*-Tree は上記の問題を解消するために MBR の面積、. 2.3.1 R-Tree R-Tree[11] は 1 次元空間索引である B-Tree を n 次元に. 外周、重なりを考慮したノード分割やデータ再挿入を行う。. 拡張したような木構造の空間索引であり、データベース. そのため、R-Tree よりもツリーの構築に時間がかかるが検. 中のデータ点を最小包囲矩形 (MBR: Minimum Bounding. 索効率が良くなっている。5 節にて R-Tree と R*-Tree の. Rectangle) によって再起的に分割して構築したツリーであ. 性能比較結果を記載する。. る (図 2.1)。ノードは子ノードのエントリ全てを内包する. 3. 環結合. MBR と子ノードへのポインタを持ち、葉ノードはデータ 点を内包する MBR とそのデータ点へのポインタを持つ。. R-Tree は R*-Tree[12] や X-Tree[15] などその後の空間索引 の基礎となっている。 入力データに対して類似検索を行う場合は、入力データ からの距離が閾値以内の範囲全てを内包する MBR(問合せ. MBR と呼ぶ) を用意し、それと重なるノードをルートから 順次たどっていく。最終的に得られた問合せ MBR と重な るデータ点について、入力データとの類似度が真に閾値以 内であるか計算する。. 図 3.1 環結合. 2 つのリレーション R、S の結合処理を考える。結合処理 ホストが n 台 (H0 , H1 , ..., Hn−1 ) あるとき、まずはリレー ション R、S をそれぞれ n 分割する (R → R0 , R1 , ..., Rn−1 .. S → S0 , S1 , ..., Sn−1 )。そして、分割後の Rk , Sk を Hk へ 図 2.1 R-Tree. 割り当てる。ホスト間における結合処理の手順は次のよう になる。. 2.3.2 R*-Tree R-Tree のノードは子孫ノードを内包するため、そのノー ドの MBR と子孫ノードの MBR は必ず重なり合う。しか し、子孫関係にないノードとの重なりが生じる場合もある。 図 2.2 は兄弟関係にあるノードで重なりがない場合 (a) と ある場合 (b) を示している。図中の Q で示す範囲へ問合せ を行うと、(a) では 1 つのノードを辿っていくことになる が、(b) では 2 つのノードを辿っていかなければならない。. c 2015 Information Processing Society of Japan ⃝. ( 1 ) Hk は Rk 1 Sk を処理しつつ、Sk を Hk+1 mod n へと 転送する。. ( 2 ) Hk は Hk−1 mod n より受け取った Sj を用いて Rk 1 Sj の処理をするとともに、Hk+1 mod n へ Sj を転送する。. ( 3 ) n 回の結合処理が行われたら終了する。そうでなけれ ば (2) へ。 環結合の構成を図示したものを図 3.1 に示す。 環結合ではテーブルを複数ホストに分配するという性質. 2.
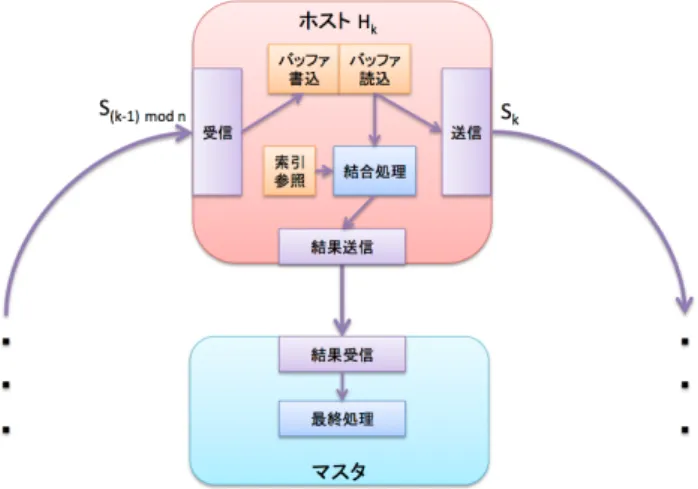
(3) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 上、テーブルサイズが大きく 1 台のマシンでは in-memory での処理ができなかったとしても、ホスト数を十分に確保. 4. 環結合の実装. すれば分散先のホストで in-memory に処理することが可. 問合せを受付けたり結合対象のテーブルを保持したりす. 能になる。これは大きな利点であるが、マシン間のデータ. るマシンをマスタ、結合処理を行うマシンをホストとする。. 転送がボトルネックになりやすいので [1] では高速なネッ. まず、マスタから複数のホストへデータを分配し、環結合. トワークで後述の RDMA 転送を使用することを前提とし. のアルゴリズムに従って結合処理を行う。ホスト上ではマ. ている。また、循環データ Sk の転送と結合処理を並列化. ルチスレッドで結合処理を行い、検索処理の効率を向上さ. するためにダブルバッファリングの仕組みを使用するとも. せるために空間索引も利用する。 結合処理の内容によっては、ホストが結果データを生成. 述べている。. する速度がマスタへ結果データを送信する速度を上回って しまう場合がある。このような事態にも対処できるように. 3.1 RDMA 転送 RDMA(Remote Direct Memory Access) 転送とは、リ. 各ホストに結果データを一時保存するためのリングバッ. モートマシン間で DMA 転送を行う仕組みである。一般的. ファを複数設け、そのバッファが一杯になったら結合処理. に使われているソケット転送における転送データの流れは. を一時的にストールさせるような仕組みを設ける。この節. 図 3.2 のようになる。CPU がメモリ上のデータをソケット. では今回実装した環結合の構成について説明していく。. 転送用に加工してから NIC が加工されたデータを読み出 し、転送する。一方、RDMA 転送では DMA 転送のよう に CPU を介さないデータ転送が可能である (図 3.3)。ソ. 4.1 モジュール構造 マスタ側の処理はホストへテーブルを配布する初期処. ケット転送ではなく RDMA 転送を用いることで、CPU の. 理、ホストから結果データを受け取る収集処理の 2 つに大. 負荷が減り、消費するメモリバンド幅も節約される [8]。結. 別できる。ホスト側の処理もマスタからのテーブル受け取. 果として、高スループットの通信やその他計算処理の高性. りを含む各種初期処理、ホスト同士でデータの循環・結合. 能化が期待できる。. を行いながらマスタへ結果を送信する結合処理の 2 つに大 別できる。. 図 3.2. ソケット通信のデータフロー. 図 4.1. 図 3.3 RDMA 通信のデータフロー. 環結合: 初期処理. 初期処理を図示すると図 4.1 のようになる。ホスト Hk はマスタより分割テーブル Rk , Sk を受け取り、Rk について の索引を構築しつつ隣接ホスト H(k−1) mod n , H(k+1) mod n. 3.2 環結合の類似検索への応用. との接続を確立してリング状のネットワークを構成する。. 環結合は任意の問合せに対して適用することが可能であ. 結合・収集処理は図 4.2 のようになる。ホスト Hk は自. る。さらに任意の索引とも組合わせることもできる。その. 身の持つテーブルに対する結合処理、ホスト H(k+1) mod n. ため、今回の類似検索の高性能化に環結合を応用する。結. への Sk の送信、ホスト H(k−1) mod n からの S(k−1) mod n. 合処理ホストを複数台用いるので、単一マシンで検索処理. の受信、マスタへの結果データの送信を並行に行う。マス. をしたときの性能を大幅に超えると予想される。. タは断続的に各ホストから結果データを受け取る。. c 2015 Information Processing Society of Japan ⃝. 3.
(4) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 索引を構築することになる。索引は使い捨てになってしま うが、使わない場合と比べて類似度の計算回数を減らすこ とができるので結果として処理の高速化が見込める。. 4.4 結果データの制御 ホスト上の結合処理における結果データの生成速度がマ スタへの送信速度を上回ると送信しきれなかった結果デー タがメモリ上にどんどん溜まっていってしまう。メモリ領 域を大量に確保してしまうとストレージへのスワップアウ トや OS によるプロセスへの KILL シグナルの送信が起こ る。これらを避けるためにはメモリから溢れるまえに結果 データをストレージに書き込むか、あるいは、結果データ 図 4.2 環結合: 結合・収集処理. の生成を一時的に止めておくことが考えられる。前者の方 法をとると、ストレージへの書き込みと読み出しにより処. 4.2 スレッドレベル並列 データの送受信・結合処理、結果データの送信を並行に. 理が大幅に遅れる可能性が高い。よって、後者の結果デー タの生成を一時的に停止する方式を採用する。. 処理するためにホスト上で以下の 4 種類のスレッドを動作 させる。なお、結合処理を高速化するために Join は複数 動作させる。. • 次のホストへデータを送信する: Send • 前のホストからデータを受信する: Recv • 所持しているデータの結合処理をする: Join • マスタへ結果データを送信する: Send result 4.2.1 ダブルバッファリング Recv が受信したデータ Sk を Send が送信に、Join が結. 図 4.3. 合処理に使うことになるが、Sk を格納するためのバッファ が 1 つしかない場合は Send, Join の現在のデータに対する 処理が完了するまで Recv は隣接ホストからのデータを受 け取ることができない。 そこで、Sk を格納するバッファを 2 つ用意する。バッ ファ 1 のデータを Send, Join が使用している間にバッファ. 2 へ Recv がデータを書き込むようにする。すると、Send, Join の完了を待たずして隣接ホストから転送されるデータ を受け取ることができる。Send, Join がバッファ 1 に対す る処理を、Recv がバッファ 2 に対する処理を完了したら 使用するバッファを入れ替える。Send, Join がバッファ 2 を、Recv がバッファ 1 を使うことになる。バッファ 2 に は既にデータが格納されているのですぐに送信・結合処理 を行うことができる。同様に、バッファ 1 のデータは全て 使い終わっているので新たに受信したデータで上書きして しまっても問題にはならない。. リングバッファによる制御. メモリに格納する結果データの量を制限するために、各. Join にリングバッファを持たせる。Join はリングバッファ に空きがあれば結果データを書き込む。Send result はそ れぞれのリングバッファに結果データが格納されているか 調べ、格納されているならばそれを送信する。Send result によるリングバッファ中のデータの消費速度がある Join によるデータの書き込み速度を下回り、リングバッファが 一杯になってしまった場合はリングバッファに空きができ るまでその Join をストールさせる (図 4.3)。. 4.5 疑似コード 大まかな構成を示した疑似コードを以下に記載する。 コード 4.1 はマスタの処理内容を表している。コード 4.2 はホストのメインスレッド、コード 4.3 はホストの通信ス レッド、コード 4.4 はホストの結合スレッドの処理内容を 表す。. 4.3 空間索引の利用 環結合によって結合処理をしても全組合わせについて照 合をしてしまうとやはり計算に時間がかかってしまう。そ こで、空間索引を用いて照合を行う組合せの数を減らして いく。環結合ではマスタからホストへテーブルを分配する という構成上、ホストは担当のテーブルを受け取ってから. c 2015 Information Processing Society of Japan ⃝. 4.
(5) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. コード 4.1 マスタ: 全体 1: function main() 2: for Hi in 全てのホスト do 3: Hi を accept; 4: end for 5: 6: for Hi in 全てのホスト do 7: Hi へ総ホスト数を通知; 8: Hi へ担当分テーブルを送信; 9: Hi へ検索範囲 (閾値) を通知; 10: Hi へ隣接ホストのアドレス情報を通知; 11: end for 12: 13: 全てのホストを同期する; 14: 15: for i ← 0 to 総ホスト数-1 do 16: スレッド receiveResult(i) を作成; 17: end for 18: 19: for i ← 0 to 総ホスト数-1 do 20: スレッド receiveResult(i) の完了を待つ; 21: end for 22: 23: for Hi in 全てのホスト do 24: Hi との接続を close; 25: end for 26: end function 27: 28: function receiveResult(t) 29: while Ht から全ての結果を受け取るまで do 30: Ht から結果を受け取る 31: end while 32: end function. コード 4.2 ホスト: メインスレッド 1: HOSTNUM; /* 総ホスト数 */ 2: BUF R; /* 分割テーブル R 用バッファ */ 3: BUF S[2]; /* 分割テーブル S 用ダブルバッファ */ 4: IDX ← 0; /* S 用ダブルバッファで使用する添字 */ 5: 6: THRESH; /* 検索で使用する閾値 */ 7: TREE INDEX; /* 検索で使用する索引 */ 8: CJ STEP ← 0; /* 環結合の経過ステップ数 */ 9: COMP ← false; /* 終了フラグ */ 10: PROC STEP; /* 結合スレッドが扱う単位エントリ数 */ 11: JT NUM; /* 結合スレッドの数 */ 12: RESULT[JT NUM]; /* 結果を格納するリングバッファ */ 13: 14: function main() 15: マスタへ connect; 16: 17: マスタから総ホスト数を受け取る; 18: HOSTNUM ← 総ホスト数; 19: マスタから担当分テーブルを受け取る; 20: BUF R ← 担当分のテーブル Rk ; 21: BUF S[0] ← 担当分のテーブル Sk ; 22: マスタから検索範囲 (閾値) を受け取る; 23: THRESH ← 閾値; 24: マスタから隣接ホストのアドレス情報を受け取る; 25: 26: 全ホストを同期する; 27: 28: if 索引を使用する then 29: 索引を構築する; 30: TREE INDEX ← 構築した索引; 31: end if 32: 33: スレッド sendTable() を作成する; 34: スレッド sendResult() を作成する; 35: スレッド receiveTable() を作成する; 36: for i ← 0 to JT NUM-1 do 37: スレッド joinTables(i) を作成する; 38: end for 39: 40: スレッド sendTable() の完了を待つ; 41: スレッド receiveTable() の完了を待つ; 42: for i ← 0 to JT NUM-1 do 43: スレッド joinTables(i) の完了を待つ; 44: end for 45: 46: COMP ← true; 47: 48: スレッド sendResult() の完了を待つ; 49: 50: マスタとの接続を close; 51: end function. c 2015 Information Processing Society of Japan ⃝. コード 4.3 ホスト: 通信スレッド 1: function sendTable() 2: 隣接ホストを accept; 3: 4: while CJ STEP が HOSTNUM-1 未満 do 5: if BUF S[IDX] が送信済み then 6: IDX が更新されるまで待つ; 7: continue; 8: end if 9: BUF S[IDX] を隣接ホストへ送信する; 10: end while 11: 12: 隣接ホストとの接続を close; 13: end function 14: 15: function receiveTable() 16: 隣接ホストへ connect; 17: 18: while CJ STEP が HOSTNUM-1 未満 do 19: if BUF S[(IDX+1)%2] にデータを受信済み then 20: IDX が更新されるまで待つ; 21: continue; 22: end if 23: BUF S[(IDX+1)%2] へ隣接ホストからのデータを受け取る; 24: end while 25: 26: 隣接ホストとの接続を close; 27: end function 28: 29: function sendResult() 30: while COMP = false do 31: for i ← 0 to JT NUM-1 do 32: if RESULT[i] が空でない then 33: RESULT[i] 中の結果をマスタへ送信する; 34: end if 35: end for 36: end while 37: 38: /* 最後に結果の送り残しがないか確認する */ 39: for i ← 0 to JT NUM-1 do 40: if RESULT[i] が空でない then 41: RESULT[i] 中の結果をマスタへ送信する; 42: end if 43: end for 44: end function. コード 4.4 ホスト: 結合スレッド 1: function joinTables(t) 2: while CJ STEP が HOSTNUM-1 以下 do 3: Lock; 4: if Lock 成功 then 5: if BUF S[IDX] 中の全エントリに対して 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37:. BUF R との結合処理が完了 then BUF S[IDX] の隣接ホストへの送信が完了するまで待つ; BUF S[(IDX+1)%2] に隣接ホストからデータを受信完了するまで 待つ; CJ STEP ← CJ STEP + 1; IDX ← (IDX+1)%2; end if Unlock; end if. BUF S[IDX] 中の未だ joinTables によって取り出されていないエントリか ら PROC STEP だけ取り出す; buf ← BUF S[IDX] から取り出されたエントリ; /* その数は PROC STEP 以下 */ if buf 中のエントリ数 = 0 then IDX が更新されるまで待つ; continue; end if if 索引を使用する then TREE INDEX を用いて buf 内エントリの近傍候補を BUF R から 抽出; condidate ← 抽出された近傍候補; buf と candidate で距離計算を行い閾値 THRESH 以内の距離にある組 合せを結果とする; else buf と BUF R で距離計算を行い閾値 THRESH 以内の距離にある組合 せを結果とする; end if if RESULT[t] に空きがない then 空くまで待つ; end if RESULT[t] ← 結合結果; end while end function. 5.
(6) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. の処理時間を記載した。索引を利用すると選択率 4, 5%か. 5. 評価実験. ら性能が劣化していくので、ある程度選択率が大きい場合. 5.1 実験環境. は索引を使うべきではない。 表 5.1. Group. Mem. IB. 台数. Processor E5-2695 v2. 64GB. FDRx4. 5. Processor E5-2665. 64GB. FDRx4. 6. CPU. A. Intel. B. Intel. R ⃝ R ⃝. Xeon Xeon. R ⃝ R ⃝. より小さい選択率について比較した結果を図 5.3, 5.4 に. 実験環境. 示す。これらの結果から選択率が小さいほど索引を用いた ことによる高速化率が大きいことがわかる。. 評価実験を行った環境を表 5.1 に示す。表中の CPU は 搭載されている CPU の種類を、Mem はメモリ容量を表し ている。IB は InfiniBand[6] の規格を示している。台数は 同じスペックのマシンの台数を表す。実験で使用するプロ トタイプの実装には C++を用いた。 SELECT R.id, S.id FROM R, S WHERE (R.x - S.x)2 + (R.y - S.y)2 < r2 図 5.1. 類似検索 (近傍検索). ここでは図 5.1 のように、リレーショナルモデル中の 2. 図 5.2. 単一マシンでの結果: 0–10%. 図 5.3. 単一マシンでの結果: 0–1%. 次元座標データに対して類似検索を行った場合について取 り扱う。実験では選択率を変えながら結合処理にかかる時 間を計測する。結合処理対象のテーブルを R, S としたと き、選択率は次のように求められる。. |R 1 S| |R| × |S| ただし |R| はテーブル R 中のタプル数を表す。結合対象と なるテーブルのスキーマは {key int4, val[2] float8} とし、. key にはタプルを特定するためにテーブル中で一意な 32bit 非負整数を、val には乱数生成した 64bit 倍精度浮動小数の. 2 次元座標データを格納する。それぞれのテーブルにおけ るエントリ数は 1 × 106 とする。R 1 S による結果データ のスキーマは {rkey int4, skey int4} であり、rkey は R 中 のタプルを特定するための非負整数、skey は S 中のタプル を特定するための非負整数とする。. 5.2 単一マシンでの実験 環結合との性能比較のためにまず、単一マシンで類似 検索処理を行う。検索処理を高速化するためにマルチス レッドによる処理や SSE 命令、空間索引なども利用する。 実験には表 5.1 中の A から 1 台使用し、結合処理は全て. in-memory, 24 スレッドで行った。索引を利用する場合は、 その索引は既に作成済みであったと仮定し作成時間を含め ない。 選択率 0 から 10%までの結果を図 5.2 に示す。グラフの 縦軸は結合処理にかかる時間を、横軸は選択率を表してい る。S-NL には索引を使わないで検索処理を行ったときの. 図 5.4. 単一マシンでの結果: 0–0.1%. 処理時間を、S-RT には索引として R-Tree を用いたときの 処理時間を、S-R*T には索引として R*-Tree を用いた場合. c 2015 Information Processing Society of Japan ⃝. 6.
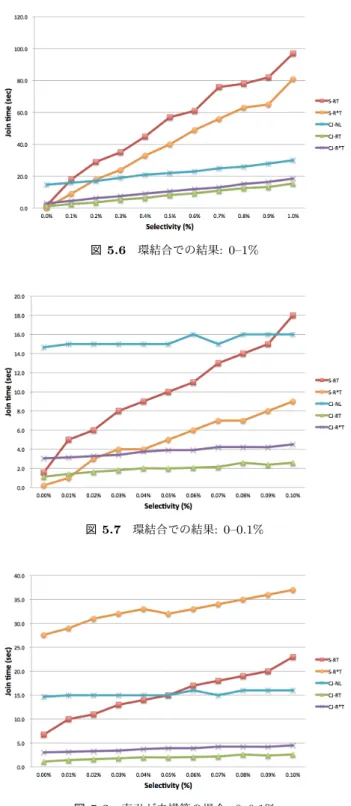
(7) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 5.3 環結合の実験 この環結合の実験では、RDMA 転送は使用せずに Infini-. Band を用いて IP による通信を行う IPoIB[7] とソケット 転送を用いた。4.5 節ではスレッド間で共有する変数に対 してロックを用いているが、今回の実装では compare and. swap や fetch and add などのアトミック命令を使用した。 表 5.1 中の A からマスタとして 1 台を、ホストとして A から 4 台、B から 6 台の計 10 台を使用し結合処理は全て. in-memory, 24 スレッドで行った。4.3 節で述べたように索 引を利用する場合は各ホストがデータを受け取ってから索 引を構築することになる。そのため、環結合の処理時間に. 図 5.6 環結合での結果: 0–1%. はテーブルの転送時間に加えて索引の構築時間も含まれて いる。 図 5.5, 5.6, 5.7 中の CJ-NL は環結合で索引を用いなかっ た場合を、CJ-RT は索引として R-Tree を用いた場合を、. CJ-R*T は索引として R*-Tree を用いた場合を表している。 選択率 0 から 10%までの結果、図 5.5 を見ると、環結合の 性能がかなり良いことが分かる。より小さい選択率 0 から. 1%まで (図 5.6) を見ると、選択率が 0.2%程度あれば索引 を使わない環結合の性能が単一マシンで索引を使った場合 の性能を上回ることが確認できる。さらに小さい選択率 0 から 0.1%まで (図 5.7) を見てみると、選択率が 0.01%程度 であれば環結合よりも単一マシンで R*-Tree を用いた方が 図 5.7. 高速であることが分かる。. 環結合での結果: 0–0.1%. ただし、これらの結果は単一マシンで索引が構築済みで あるという仮定に基づいている。もし索引が未構築であっ た場合には図 5.8 のような結果になる。単一マシンでは索 引を構築するのに一定以上の時間がかかる。一方、環結合 では分割したテーブルそれぞれに対して同時並行的に索引 を構築するので構築時間は単一マシンのそれよりも小さく なる。結果、どの選択率においても環結合で索引を用いた 場合の方が高速になる。. 図 5.8. 索引が未構築の場合: 0–0.1%. 6. 結論 6.1 結論 本研究では、類似検索を単一マシンで処理した場合と環 結合によって処理した場合の性能を比較した。索引が既 に作成されている場合、選択率 0.02%程度からは環結合と 図 5.5 環結合での結果: 0–10%. R-Tree の組合せが最も高速であり、選択率 0.01%以下では 単一マシンで R*-Tree を用いたほうが高速である。索引が まだ作成されていない場合は全ての選択率において環結合 と R-Tree の組合せが最も高速である。. c 2015 Information Processing Society of Japan ⃝. 7.
(8) Vol.2015-HPC-150 No.16 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 6.2 今後の課題 今回の実験では R-Tree よりも R*-Tree のほうが高性能 であるにも関わらず、環結合においては R-Tree のほうが. R*-Tree よりも高性能であるという結果が得られた。なぜ. [13]. このような逆転現象が起こっているのか解明する必要があ る。もし、このようなケースが少なくないのであれば、環 結合では利用する索引に気をつける必要がある。 謝辞 本研究の一部は、JST CREST「ポストペタスケー. [14]. [15]. ルデータインテンシブサイエンスのためのシステムソフト ウェア」 、JST CREST「EBD:次世代の年ヨッタバイト処 理に向けたエクストリームビッグデータの基盤技術」 、JST. [16]. CREST「広域撮像探査観測のビッグデータ分析による統 計計算宇宙物理学」、科研費「#25280043HA」による。 参考文献 [1]. Philip W. Frey, Romulo Gonalves, Martin Kersten, and Jens Teubner. Spinning Relations: High-Speed Networks for Distributed Join Processing. Proceedings of the International Workshop on Data Management on New Hardware, pp.27–33, 2009. [2] Philip W. Frey, Romulo Gonalves, Martin Kersten, and Jens Teubner. A Spinning Join that does not get Dizzy. Proceedings of the International Conference on Distributed Computing Systems, pp.283–292, 2010. [3] Romulo Gonalves, Martin Kersten. The Data Cyclotron Query Processing Scheme. Proceedings of the ACM Transactions on Database Systems, Volume 36 Number 4, pp.1-35, 2011. [4] Romulo Gonalves, Martin Kersten. The Data Cyclotron Query Processing Scheme. Proceedings of the International Conference on Extending Database Technology, pp.75–86, 2010. [5] Claude Barthels, Simon Loesing, Donald Kossmann, Gustavo Alonso. Rack-Scale In-Memory Join Processing using RDMA. Proceedings of the ACM SIGMOD International Conference on Management of Data, pp.1463– 1475, 2015. [6] InfiniBand Trade Association. InfiniBand Architecture Specification. available from ⟨http://www.infinibandta.org⟩ [7] RFC4391: Transmission of IP over InfiniBand (IPoIB) [8] Pavan Balaji, Hemal V. Shah, D. K. Panda. Sockets vs RDMA Interface over 10-Gigabit Networks: An Indepth analysis of the Memory Traffic Bottleneck. Proceedings of the Workshop on Remote Direct Memory Access (RDMA): Applications, Implementations, and Technologies, 2004. [9] 田中昌宏, 白崎裕治, 本田敏志, 大石雅寿, 水本好彦, 安田直 樹, 増永良文. バーチャル天文台 JVO プロトタイプシステ ムの開発. DBSJ Letters, Volume 3 Number 1, pp.81–84, 2004. [10] Data Release 12 | SDSS-III DR12. available from ⟨http://www.sdss.org/dr12/⟩ [11] Antonin Guttman. R-trees: A Dynamic Index Structure for Spatial Searching. Proceedings of the ACM SIGMOD International Conference on Management of Data, pp.47–57, 1984. [12] Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider,. c 2015 Information Processing Society of Japan ⃝. [17]. Bernhard Seeger. The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles. Proceedings of the ACM SIGMOD International Conference on Management of Data, pp.322–331, 1990. C´edric du Mouza, Witold Litwin and Philippe Rigaux. SD-Rtree: A Scalable Distributed Rtree. Proceedings of the International Conference on Data Engineering, pp.296–305, 2007. David A. White, Ramesh Jain. Similarity Indexing with the SS-tree. Proceedings of the International Conference on Data Engineering, pp.516–523, 1996. Stefan Berchtold, Daniel A. Keim, Hans-Peter Kriegel. The X-tree: An Index Structure for High-Dimensional Data. Proceedings of the International Conference on Very Large Data Bases, pp.28–39, 1996. Roger Weber, Hans-J. Schek, and Stephen Blott. A Quantitative Analysis and Performance Study for Similarity-Search Methods in High-Dimensional Spaces. Proceedings of the International Conference on Very Large Data Bases, pp.194–205, 1998. Yasushi Sakurai, Masatoshi Yoshikawa, Shunsuke Uemura, Haruhiko Kojima. The A-tree: An Index Structure for High-Dimensional Spaces Using Relative Approximation. Proceedings of the International Conference on Very Large Data Bases, pp.516–526, 2000.. 8.
(9)
図
関連したドキュメント
Power and Efficiency Measurements and Design Improvement of a 50kW Switched Reluctance Motor for Hybrid Electric Vehicles. Energy Conversion Congress and
Adaptive-Agent Simulation Analysis of a Simple Transportation Network, Proceedings of the Joint 2nd International Conference on Soft Computing and Intelligent Systems and
In Combinatorial Surveys: Proceedings of the Sixth British Combinatorial Conference, pages 45–86.. On generic rigidity in
Bae, “Blind grasp and manipulation of a rigid object by a pair of robot fingers with soft tips,” in Proceedings of the IEEE International Conference on Robotics and Automation
T´oth, A generalization of Pillai’s arithmetical function involving regular convolutions, Proceedings of the 13th Czech and Slovak International Conference on Number Theory
de la CAL, Using stochastic processes for studying Bernstein-type operators, Proceedings of the Second International Conference in Functional Analysis and Approximation The-
Taking care of all above mentioned dates we want to create a discrete model of the evolution in time of the forest.. We denote by x 0 1 , x 0 2 and x 0 3 the initial number of
Amount of Remuneration, etc. The Company does not pay to Directors who concurrently serve as Executive Officer the remuneration paid to Directors. Therefore, “Number of Persons”
