1
令和元年度 修士論文
JavaScript による自動設計のための回路
トポロジーデータ収集用インターフェース作成
指導教員 髙井 伸和 准教授
群馬大学大学院 理工学部 理工学専攻
電子情報・数理教育プログラム
髙井研究室
T181D004
新井 貴之
2
目次
第1章
研究背景・目的··· 3
1.1 研究背景・目的 ··· 3 1.2 本論文の構成 ··· 3第2章
作成したインターフェースの概要··· 4
2.1 概要 ··· 4 2.2 開発環境 ··· 4 2.3 操作方法 ··· 5第3章
各機能実装手法··· 9
3.1 回路情報出力方法 ··· 9 3.2 検索機能実装方法 ··· 11 3.2.1 TopologyDNA の概要 ··· 11 3.2.2 ネットリストから TopologyDNA への変換 ··· 13 3.2.3 トポロジー比較方法 ··· 16 3.3 回路情報保存方法 ··· 19第4章
実行結果 ··· 21
第5章
まとめと今後の課題 ··· 27
5.1 まとめ ··· 27 5.2 今後の課題 ··· 273
研究背景・目的
1.1 研究背景・目的
IoT の拡大に伴いアナログ集積回路の用途も拡大しており、回路に要求される仕様 や性能が多様化している。それによる開発過程の複雑化や回路設計の短期化等の要求 により、人の手のみによる電子回路設計が困難となっている。現在、ディジタル集積 回路設計では自動設計が積極的に利用されているが、アナログ集積回路設計では考慮 すべきパラメータの数が多いため、いまだに確立に至る手法が提案されていない。そ のため、アナログ回路設計者の過去の経験や知識により、適切な回路図や素子値を決 定しており、回路設計全体における設計期間の大部分を占めている。また、回路設計 者の育成には時間やコストが必要であり、開発期間の短縮やコスト削減が求められて いる。そこで、回路設計の効率化を測るためにコンピュータによる深層学習を用いた 回路設計の自動化が行われている。しかし、回路の自動設計では回路トポロジーを学 習させるために大量の学習用データが必要となるが、良質な大量の回路データの収集 は困難である。そこで、本論文ではブラウザ上で回路を設計し、回路のデータベース を作るインターフェースを作成することを目的とする。1.2 本論文の構成
本論文は5章で構成される。まず、第 2 章で作成したインターフェースについて説 明する。次に、第3章で本インターフェースの各機能について述べる。そして、第4 章で実際の各機能の動作を説明する。最後に、5章でまとめと今後の課題を述べる。4
作成したインターフェースの概要
2.1
概要
本インターフェースはブラウザ上で動作する回路設計ツールへ回路情報をデータベ ースへ保存する機能を追加したものである。回路を作成し、その回路情報をデータベ ースへ保存することが可能である。その際に登録したい回路が既にデータベース内に 存在するか確認する検索機能も備えている。これにより同一トポロジーの回路を重複 して保存することを未然に防ぐことができ、人の手で作られた良質なデータベースを 作成する。2.2
開発環境
本インターフェースの言語は HTML5、JavaScript を使用している。JavaScript は Web ブラウザ用の言語である。ブラウザで動作する言語は JavaScript の他には PHP などが あるが、JavaScript が最も複雑な動作、制御が可能である。また、JavaScript は Windows、 Mac、Linux など、いかなる OS、環境でも関係なく簡単に動作させることが可能であ る。データベースとのやり取りには JavaScript のサーバーサイド言語である Node.js を 使用している。Node.js は JavaScript 言語のランタイム環境であり、「V8」というプロ グラムで作成されている。これは JavaScript で書いたスクリプトを読み込んで実行する プログラムの事である。そのため、Web ブラウザの中だけでなく単独で JavaScript の プログラムを実行可能である。これにより JavaScript による開発環境が可能となり、サ ーバー側、クライアント側の両方で1つの言語だけで開発することができる。フレーム ワークは Express を使用し、テンプレートエンジンは EJS を使用している。データベー スはサーバー型の SQL データベースである MySQL を使用する。
5
2.3
操作方法
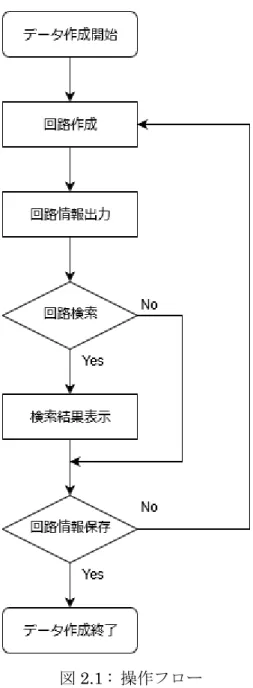
データベースに保存するデータ作成の流れを図 2.1 に示す。本インターフェースの操 作方法を操作フローと実際の画面に即して説明する。
6
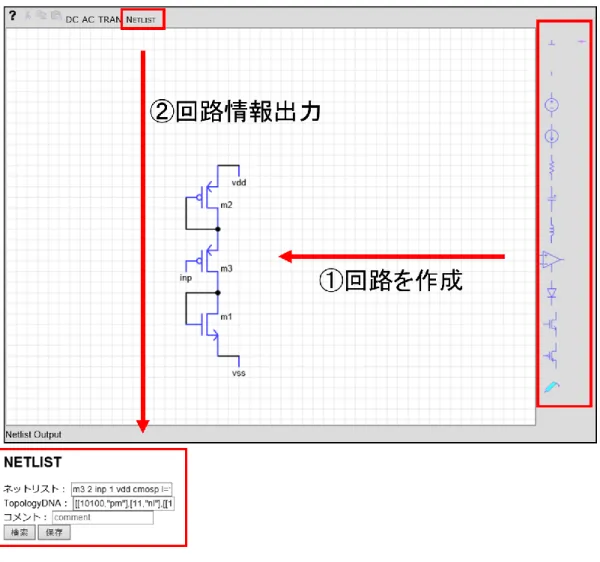
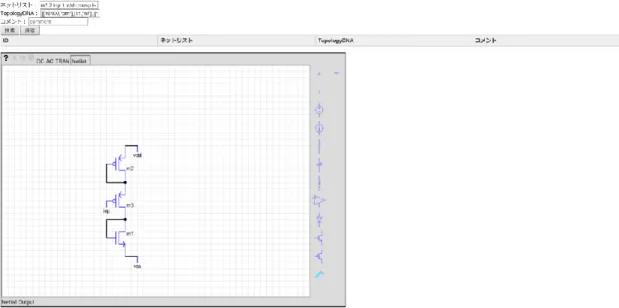
回路作成 メインとなるページと操作方法を図 2.2 に示す。まず右枠の素子群から素子を使用 し、回路を作成する。本論文では PMOS、NMOS、R、C の 4 種類を使用する。このと き、素子値もデータベースへ保存したい場合には素子値を入力する。また、注意事項と して入力の名前は inp、inm を使用し、最高電位を vdd、最低電位を vss としなければ ならない。また、PMOS、NMOS の Bulk はそれぞれ vdd、vss へ自動的に接続される。 回路情報出力 図 2.2 画面上部の NETLIST ボタンを押し、画面下部に回路情報であるネットリス ト、TopologyDNA(参考文献[1]で定義)を出力する。TopologyDNA とはネットリス トを変形させたものであり、回路検索の際にトポロジーを比較するために使用する。詳 しくは 3 章 2 節で説明する。また、回路情報出力の際には作成した回路のスクリーンシ ョットをローカルストレージに保存する。 回路検索 図2.2 画面下部の検索ボタンを押し、同一トポロジーがデータベース内に存在する か検索する。検索は出力したTopologyDNA を使用し、データベース内の全てのトポロ ジーと TopologyDNA を比較することで各々が同一のトポロジーか異なるトポロジー かの判定を行う。 検索結果表示 作成した回路がデータベース内に存在するか検索した結果、同一トポロジーが存在 しなかった場合の画面は図2.3 のようになる。存在した場合の画面は図 2.4 のようにな り、検索で該当した全てトポロジーの情報を表示する。検索結果を表示する際には保 存した回路のスクリーンショットを表示する。これにより回路情報保存の前に今一度 トポロジーの確認をすることができる。 回路情報保存 図2.2 画面下部、図 2.3、図 2.4 画面上部の保存ボタンを押すことで、回路情報をデ ータベースへ保存する。保存する項目はID、ネットリスト、TopologyDNA、コメント である。ID はデータベース側で「AUTO_INCREMENT」という設定にしている。これ によりデータを保存する毎に自動で「1、2、3・・・」のように連番で ID を割り振っ7
ている。回路情報の保存は回路の検索をせずに行うこともできる。また、検索した結 果回路情報の保存をやめる場合には回路作成へ戻る。
8
図2.3 : 検索結果表示画面
9
各機能実装手法
3.1
回路情報出力方法
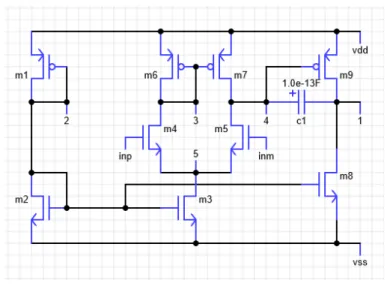
NETLIST ボタンを押すことで作成した回路のネットリスト、TopologyDNA を出力 する。本インターフェースでは、回路を作成する際に素子を置くごとに素子に番号を 振り、それぞれの素子の端子にノード番号を振る。その際に素子同士が接続され、ノ ードが同一のものとなった場合には同じ番号となる。例として図 3.1 を用意し、その ネットリストを表 3.1 に示す。図 3.1 の TopologyDNA は である。図 3.1 の回路では NETLIST ボタンを押すこと表 3.1 のネットリストと TopologyDNA である Array の回路情報が表示される。各素子の種類やノードなどの情 報は JSON データとして配列に格納しており、その要素を取り出すことでネットリス トを作成する。TopologyDNA はネットリストを変換して多次元配列の形にして作成す る。TopologyDNA の具体的な作成方法は次節の検索機能説明の際に解説する。10
図 3.1 : MOSFET を 3 つ使用した回路トポロジー
表 3.1 : 図 3.1 のネットリストvdd
vss
1
2
m1
m2
inp
m3
NAME Drain Gate Source Bulk Model L W M m1 1 1 vdd vdd cmosp x x x m2 2 inp 1 vdd cmosp x x x m3 2 2 vss vss cmosn x x x
11
3.2
検索機能実装方法
データベース内に保存したい回路と同一トポロジーの回路が存在するか確認するた めに、トポロジーの検索機能を作成する。検索を正確に行うためには保存したい回路 とデータベース内の回路が同一のトポロジーか判定する機能が必要である。しかし、 ただネットリストを比較するだけでは同一構成であるのに素子名やノード名が異なる 回路等が検索に引っかからない問題がある。そのため、どのような回路でも正しく判 定できるような汎用的な手法が必要である。そこで、同一トポロジーの判定手法は参 考文献[1]を参考にし、本インターフェースの検索機能として実装した。以下、同一ト ポロジー判定手法について説明する。対象とする回路トポロジーに使用する素子は、 PMOS、NMOS、R、C の 4 つである。これらの組み合わせで構成される回路トポロ ジーを判定するために、素子と素子の接続点(ノード)毎に情報を取得する。ノード 毎に取得した情報を NodeDNA(参考文献[1]で定義)とし、全てのノード情報を組み 合わせたものを TopologyDNA として判定を行う。3.2.1
TopologyDNA の概要
ここからは具体的に回路トポロジーを用いて判定手法を説明する。例とする回路トポ ロジーは図 3.1 を使用する。また、図 3.1 の回路情報を示したネットリストは表 3.1 で ある。まず、図 3.1 の回路トポロジー内に存在するノードに着目し、各ノードに接続さ れる素子の情報をノード別に取得する。このとき、2 種類の情報を取得する。1つ目の 情報は、対象となるノードに接続される素子の種類(PMOS, NMOS, R, C)である。但 し、MOSFET については以下に示す位置情報も加えて取得する。vdd と接続されてい るものを High、vss と接続されているものを Low、どちらとも接続されていないものを Middle とする。つまり、MOSFET は(PMOS_High, PMOS_Middle, PMOS_Low, NMOS_High, NMOS_Middle, NMOS_Low)の 6 種類に分類する。実際に使用する際 には PMOS_High は ph, PMOS_Middle は pm, NMOS_Low は nl のように省略して 使用している。2つ目の情報は端子の種類(入力, Drain, Gate, Source, Bulk, 正側のノ ード, 負側のノード)である。例として、図 3.1 の内部ノード”1”についての取得情報を 表 3.2 に示す。表 3.2 における端子情報は、左から「inm, inp, Drain, Gate, Source, Bulk」 を表している。また、端子情報は十進数表記であり、接続数だけ加算していく。そのた12
め、あるノードに同情報の端子が 10 個以上接続されないことを仮定している。C の場 合は正側、負側のどちらに接続しているか、R は接続しているかどうかの情報を取得す る。同様に、回路トポロジー内に存在する全てのノードに対して情報を取得する。これ らの取得情報は各ノードを構成する情報なため、NodeDNA とする。図 3.1 における全 ての NodeDNA をまとめたものを表 3.3 に示す。この情報は回路トポロジーを構成す る情報のため、TopologyDNA とする。以上が参考にした同一トポロジー判定手法であ る。表 3.2 : 図 3.1 のノード”1”の NodeDNA
表 3.3 : 図 3.1 の TopologyDNA
素子 端子情報 PMOS_High 001100 PMOS_Middle 010010 PMOS_Low NMOS_High NMOS_Middle NMOS_Low ノード 素子 000011 001100 010001 010010 011000 010100 000011 001100 PMOS_Middle PMOS_Low NMOS_High NMOS_Middle NMOS_Low VDD VSS 1 2 inp PMOS_High13
3.2.2 ネットリストから
TopologyDNA への変換
参考手法を検索機能として実装するために、TopologyDNA の作成をする。 TopologyDNA はネットリストから変換することで作成する。そこで、ネットリスト から TopologyDNA を作成する際のプログラムの流れを具体的にネットリストを用い て説明する。例として図 3.1 の回路のネットリストを示す。 ネットリストは文字列であるため、初めにネットリストの各素子値を削除し、配列に 格納し 2 次元配列にする。 それぞれの要素をスペース毎に区切り、複数の要素にする。 各要素をそれぞれ配列にすることで 3 次元の配列とする14
続いて、各要素に端子情報用数字と位置情報を与える。端子情報用数字について説明 する。端子情報用数字は端子情報を作成するための数字である。NodeDNA における 各ノードの端子情報は、左から「inm, inp, Drain, Gate, Source, Bulk」である。そのた め、Drain であれば端子情報用数字として 1000、Source であれば 10 のように数字を 与える。入力 inm, inp に接続されている素子の場合は特殊な処理をする。例えば入力 inp に接続されている素子の場合は Drain であれば 11000、Source であれば 10010 の ように数字を与える。入力はノードと違い場所を正確に特定するために入力に接続さ れている素子の全端子に「この素子には入力が接続されている」という情報を与えな ければならないためである。例として素子 m1 について考える。m1 はどの端子にも入 力は接続されていない。そのため、Drain には 1000、Gate には 100、Source には 10、Bulk には 1 の数字を与える。また、素子 m2 について考える。m2 は Gate が inp に接続されている。そのため、Drain には 11000、Gate には 10100、Source には 10010、Bulk には 10001 の数字を与える。続いて、位置情報について説明する。各素 子の Model を確認する。cmosp の場合は PMOS、cmosn の場合は NMOS である。6 種類ある位置情報は PMOS_High は ph、PMOS_Middle は pm、PMOS_Low は pl、 NMOS_High は nh、 NMOS_Middle は nm、NMOS_Low は nl として各要素に与え る。
15
ノード名に着目する。NodeDNA 作成のため、ノード名が同じもの同士で配列の要素 をまとめる。その際にノード名の要素は削除する。これにより同一トポロジーだがノ ード名が異なる回路でも正確に判定が可能になる。 最後に同一ノードの中で位置情報が同じものの端子情報用数字を足す。 これにより全ノードの NodeDNA を作成し、ネットリストから TopologyDNA への変 換を完了した。16
3.2.3
トポロジー比較方法
次 に 、 回 路 ト ポ ロ ジ ー の 比 較 方 法 に つ い て 説 明 す る 。 ト ポ ロ ジ ー の 比 較 は TopologyDNA を 比 較 す る こ と で 行 う 。 比 較 し た 結 果 全 て の NodeDNA が 一 致 (TopologyDNA が一致)すれば比較した2つの回路は同一トポロジーであると判定さ れる。まず、図 3.1 との比較対象として、図 3.2 を用意する。図 3.2 の TopologyDNA を表 3.4 に示す。図 3.1 と図 3.2 のトポロジーはノード名が異なるが、同一構成である ため、同一トポロジーである。しかし、表 3.3、表 3.4 から互いの TopologyDNA を比 較すると、ノード”1”, ”2”は異なる NodeDNA を持ち、TopologyDNA が異なってしま うため同一トポロジーではないと判断されてしまう。そのため、同一構成であるがノー ド名が異なる回路トポロジーについても正確に判定できるようにしなければならない。 参考にした「電子回路の同一トポロジー判定手法の提案」では NodeDNA を全通り比 較してトポロジーの比較を行っている。そして、全ての NodeDNA に同一の NodeDNA が存在した場合に同一のトポロジーであると判定している。これにより、同一構成であ るがノード名が異なる回路でも判定を可能にしている。しかし、このトポロジー比較の 手法を導入するには1つ問題があり、データベース内に大量の回路データが存在する場 合に検索時間の長期化が予想される。回路検索の際には作成した回路の TopologyDNA とデータベース内のデータの TopologyDNA を1つずつ比較しており、その度に毎回 NodeDNA の全通り比較をするためである。データベース内のデータ数が少ない内は検 索時間は短いが、将来的にデータ数が膨大になれば検索時間も長期化してしまう可能性 がある。そこで、TopologyDNA をソートしてトポロジー比較を行う手法を提案する。 ネットリストから TopologyDNA へただ変換するだけでは素子やノート番号の順番が 違うため NodeDNA の順番が変化してしまう。そこで、TopologyDNA を文字列に変換 し、Unicode コードポイント順にソートする。これにより配列の要素の順番を統一する ことができ、正確に TopologyDNA の比較をすることが可能となる。実際に使用する形 式の TopologyDNA で具体例を示す。図 3.2 の TopologyDNA は17
である。Array7 と Array8 を比較すると異なる TopologyDNA であるため、図 3.1 と図 3.2 の回路は異なるトポロジーと判定されてしまう。そこで、Array7、Array8 を図 3.3 のようにソートする。ソートをすることで両者の NodeDNA の順番を統一し、同一の TopologyDNA にする。これにより、同一構成だがノード名が異なる回路でも同一トポ ロ ジ ー と し て 判 定 し 、 正 確 に 検 索 す る こ と が 可 能 と な る 。 ま た 、 ソ ー ト 後 の TopologyDNA を保存しているため、即比較が可能な状態で保存している。そのため、 検索の際に全通り比較の様にアクションを挟む必要がなく、ただ比較し同じ文字列のデ ータを取り出すだけで済む。これにより、NodeDNA の全通り比較をするよりも高速で 検索を行うことが可能である。検索時間を比較するために、NodeDNA の全通り比較を した際の検索時間とソートをして検索した際の検索時間を比較した結果を表 3.5 に示 す。表 3.5 より、データベース内のデータ数が1つだけの場合、TopologyDNA の比較 をソートにより行うことで検索時間は約5分の 1 となる。また、データ数が 10 倍の 10 個の場合、NodeDNA の全通り比較をした際の検索時間は約 2 倍となり、ソートをした 際の検索時間はほとんど増加しなかった。そのため、データ数が 10 個の場合には検索 時間を約 9 分の 1 まで減少した。以上のことから、ソートをして検索を行うことで検索 時間を短縮することが可能であり、この手法はデータ数が多いほどより効果の高い比較 方法である。 図 3.2 : 図 3.1 との比較用回路
vdd
vss
m1
m2
m3
1
2
inp
18
表 3.4 : 図 3.2 の TopologyDNA 図 3.3 : 配列のソート 表 3.5 : 検索時間の比較 ノード 素子 000011 001100 010001 011000 010010 010100 000011 001100 PMOS_Low NMOS_High NMOS_Middle NMOS_Low VSS 1 2 inp PMOS_High PMOS_Middle VDD データ数 全通り比較(ms) ソート(ms) 1 24.717 5.240 10 46.849 5.30819
3.3
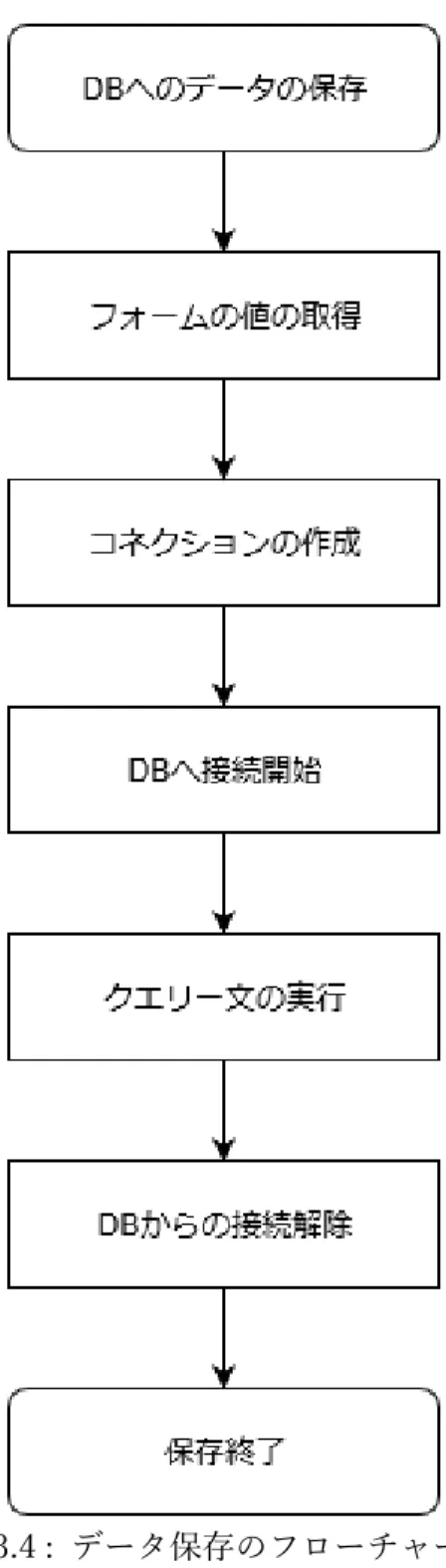
回路情報保存方法
回路情報の保存の際に実際に実行している処理について説明する。データベースへの データの保存は図 3.4 のフローチャートに沿って行う。フォームを送信されたときの処 理は、req.body から送られてきた値を取り出して行い、各入力フィールドの値をまとめ る。送信されたフォームの値をそれぞれ変数に取り出し、ひとまとめに変数 data とし て用意する。レコードの作成は用意した変数を元にクエリー文でレコード作成の SQL をデータベースに送り実行する。SQL 文はレコードを新規追加するための「insert」を 実行する。クエリー文の中で保存先のデータベースを指定し、変数 data を保存する。 これにより、フォームの内容をデータベースへ保存する。20
21
実行結果
本章では3章で使用した図 3.1 の回路よりも回路規模が大きい回路トポロジーで本 インターフェースの画面を用いて実際の動作、検索機能等の正確性を示す。対象トポ ロジーを図 4.1 に示す。図 4.1 は基本構成のオペアンプ回路である。図 4.1 の TopologyDNA を表 4.1 に示す。表 4.1 におけるキャパシタの端子情報の数字が 2 桁の 意味は、左から正側のノード、負側のノードである。図 4.1 の回路情報をデータベー スに ID5 で保存する。図 4.1 と比較する例として、図 4.2 と図 4.3 を用意する。図 4.1 と図 4.2 は同一トポロジーであるが、ノード名が異なる回路である。図 4.2 は図 4.1 と 同一トポロジーであるため、TopologyDNA も同一である。そのため、トポロジーの 検索をした際に ID5のデータが表示されれば良い。図 4.1 と図 4.3 はノード名は同一 であるが、入力端子が逆になっている。そのため、図 4.1 とは異なるトポロジーであ るため検索した際に検索結果は表示されなければ良い。まず、図 4.1 と図 4.2 のトポ ロジー検索について説明する。図 4.2 の回路でトポロジー検索した結果の画面を図 4.4 に示す。図 4.4 からノード名が異なる場合でも同一トポロジーであると判定され、正 確にトポロジーの検索が可能であることを確認した。続いて、図 4.1 と図 4.3 のトポ ロジー検索について説明する。図 4.3 の TopologyDNA を表 4.2 に示す。表 4.1 と表 4.2 を比較すると、表 4.2 のノード”2”と”3”の NodeDNA が表 4.1 と一致しない。その ため、TopologyDNA が同一でないので、図 4.1 と図 4.3 は異なるトポロジーと判定さ れる。図 4.3 のトポロジーの回路を検索した結果を図 4.5 に示す。図 4.5 から入力端子 が逆の回路は異なるトポロジーであると判定され、該当する回路は存在しないためデ ータは表示されないことを確認した。最後に、図 4.2 の回路を ID6、図 4.3 の回路を ID7 でデータベースへ保存した。図 4.1 でトポロジー検索した結果を図 4.6 に、図 4.3 でトポロジー検索した結果を図 4.7 に示す。図 4.6 では検索結果として ID5、ID6 の データのみが表示され、図 4.7 では ID7 のデータのみが表示されている。以上のこと からデータベース内に同一トポロジーが存在しているか正確に判定ができていること が分かり、検索、保存機能等は正常に動作していることを確認した。22
図 4.1 : 基本構成オペアンプ回路 表 4.1 : 図 4.1 の TopologyDNA ノード 素子 000044 001100 001200 001100 110002 011000 101000 000033 001300 10 ノード 素子 001000 110020 100100 10100 001000 001000 01 NMOS_Low Capacitor inp PMOS_Middle PMOS_Low NMOS_High NMOS_Middle Capacitor 4 PMOS_High 5 inm 3 PMOS_High PMOS_Middle PMOS_Low NMOS_High NMOS_Middle NMOS_Low VDD VSS 1 223
図 4.2 : 比較用回路トポロジー1
24
25
表 4.2 : 図 4.3 の TopologyDNA 図 4.5 : 図 4.3 回路の検索結果画面 ノード 素子 000044 001100 001200 001100 110002 101000 011000 000033 001300 10 ノード 素子 001000 110020 100100 10100 001000 001000 01 PMOS_Middle PMOS_Low NMOS_High NMOS_Middle NMOS_Low Capacitor 4 5 inm inp PMOS_High 1 2 3 PMOS_High PMOS_Middle PMOS_Low VDD VSS NMOS_High NMOS_Middle NMOS_Low Capacitor26
図 4.6 : 図 4.2 回路の検索結果画面 2
27
まとめと今後の課題
5.1
まとめ
本論文では、回路設計自動化の効率化のため良質なデータベースを作成するインタ ーフェースを作成した。その主な機能である回路トポロジーの表示、検索、保存がそ れぞれ正常に動作しており、データベースの作成が実現できていることを確認した。5.2
今後の課題
当初はメイン画面のまま画面下部に検索結果を表示する予定だったが、それでは検 索結果を表示した際に作成した回路が消えてしまう問題があった。これでは検索結果 を表示しても回路を確認することができず、どんなトポロジーか一目で判断すること ができない。その解決のため検索結果表示の際は別の画面へ切り替え、回路のスクリ ーンショットをローカルストレージに保存し、それを呼び出すことで回路図の表示を している。現在はこの方法で検索後に回路の確認ができるようにしているが、これで は検索結果を確認したその場で回路の編集を行えないため、検索をしても回路が消滅 しないようにする必要があると考える。また、現在の仕様ではどんな回路でもデータ ベースへ保存することができる。例えば素子一つだけなどの未完全な回路も保存する ことができる。これでは良質なデータベースを作成するというコンセプトに反してお り、反対に質を低下させてしまう。そのため、回路保存の前に最低限どこにも接続し ていない端子がないか等のチェックを行う機能が必要であると考えている。28
謝辞
本研究を進めるにあたり、有益な助言を頂いた所属研究室の高井伸和准教授、同期 の久保友助氏、松場輝樹氏、同研究分野の今野哲史氏、新井信吾氏、猿田将大氏、齋 藤彰寛氏、中島望夢氏、永嶋宣彦氏に心より感謝を申し上げます。また、論文審査をし て頂きました伊藤直史准教授、弓仲康史准教授に心より感謝申し上げます。29
参考文献
[1] 根岸孝行,加藤雅人,関洋明,菅原誉士紀,鈴木研人,高井伸和,小林春夫,「電子回 路の同一トポロジー判定手法の提案」,電子情報通信学会, ICD2014-30,2014.7