Environmental Sound Source Identification Based on Hidden Markov Model for Robust Speech Recognition
4
0
0
全文
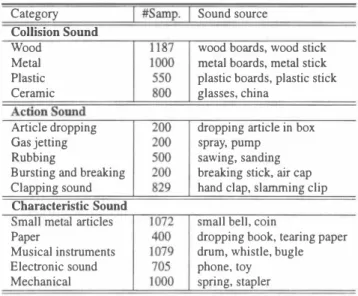
(2) EUROSPEECH 2003 - GENEVA. ゆ Table 2: Experimental condition. Table 1: EnvironmentaJ sound sources (Ory source sounds). 同函p. I. Category. Environmental sound m品1s and Speech m1Ms. Sound source. I. Num. of states. Collision Sound Wood. wood boards, wood stick. Metal. metal boards, metal stick. Plastic. plastic boards, plastic stick. Ceramic. glasses, china. I. Feature vector Sarnpling freq. Env. sound OB Speech DB. I. I. I. 3 states MFCCムMFCCムPower 12 kHz RWCP sound scene OB [5] ATR Speech OB [6]. Exp. A (Identification with environmental sound sources). 互百io五百ound ArticJe dropping. dropping articJe in box. Gas jetting. spray, pump. Rubbing. sawing, sanding. Bursting and breaking. breaking stick, air cap. Clapping sound. hand cJap, slarnming clip. Num. of models. small bell, coin. NSET CNSET. I. 92 Jcinds of continuous-occurrence env. sounds. 92 kinds of env. sounds. Paper. dropping book, tearing paper drum, whistle, bugle. Electronic sound. phone, toy. Mechanical. spring, stapler. Exp. B. Training data Test data SNSET SCNSET. We first conducted the甘aining of the environmentaJ sound HMMs. 45 sarnples. x. 5 sets 5 sets. (Classification with environmentaJ sounds and speech). Num. of models. 3.1. Design of environmental sound HMMs and speech HMMs. x. 92 kinds of single-ωcurrence env. sounds. x. Musical instruments. for the environmental sound source identification.. 92 models Open test. Test data. Characteristic Sound Small metaJ articles. I. I I I. τ'raining data. The HMMs. I I. Env.: 1 rnodel. Speech: 1 model. Env.: 92 kinds of env. sounds. x. 20 sarnples. Speech: 2620 Jap唱nese words (one speaker). I Open test I {92 Jcinds of single-occurrence env. sounds +. 216 Jap岨Lese words (speech). }. x. 5 sets. +. 216 Jap岨ese words (speech). }. x. 5 sets. I {92 Jcinds of continuous-occurrence env. sounds. were left-to-right models with three states, and the feature vec tors employed 16 orders of MFCC, 16 orders ofムMFCC and one. Table 3: Experimental results for env. sound source identi白catlOn. order of ムpower. The sampling合equency was 12 kHz. Table 2. Continuous-occurrence. Single-occurrence. shows the experimental condition. We conducted two evaJuation experiments: Exp. A and Exp. B. Exp. A ís the identification with environmental sound sources, and Exp. B is the cJassification with environmental sound so町∞s and speech. 3.2. Experimental results for the identification with environ. mental sound sources (Exp. A). Test data. Ident. rate[%]. Test data. Ident. rate[%]. NSET l. 96.7. CNSET l. 69.5. NSET2. 94.6. CNSET2. 67.4. NSET3. 96.7. CNSET3. 72.6. NSET4. 94.6. CNSET4. 60.0. NSET5. 94.6. CNSET5. 60.0. Ave.. 95.4. Ave.. 65.9. The environmental sound HMMs were trained with 92 kinds of en vironmental sounds. x. clink and cup clink) in白is evaluation experiment.. 45 samples. We first evaluate the environ. mental sound source identification with the single-occurrence en. Although 出is approach did not achieve a higher identifica. vironmental sounds. 92 kinds of single-occurrence environmental. tion perform組ce in continuous-occurrence environmentaJ sound. sounds. 5 sets are used as the test data (NSET). We also evaluate. source identification, we can confirm that the identi白cation e町ors. the environmentaJ sound so町ce identification with the continuous-. tend to occur in a similar category as shown in Table 4. Therefore,. occuπence environmentaJ sounds. 92 Jcinds of continuous-occurrence. this approach promises to cluster出e environmental sound sources. x. 5 sets are used as the test data (CNSET). The continuous-occurrence environmentaJ sounds are designed by connectmg 出e single-occurrence environmental sounds. Table 3 shows the experimental results in the above experimental condition. Based on the evaJuation experiments,出is approach can achieve environmental sounds. x. a higher identification performance in single-occurrence environ. to some categories with clusteríng rnodels of environmental sound sources for robust speech recognítíon. 3.3. Experimental result for c1assification with environmental. sound sources and speech (Exp. B). rnental sound source identi自cation. Figure I shows exarnples of. Next, we甘ied to conduct a two-cJass cJassification betw巴en enVl. 出e spectrum of the identification error (clipping sound and break. ronmental sound sources 組d speech with the H恥仏1. We designed one environmental sound model and one speech model for the cJas. ing stick sound) in this evaluation experiment. sification. The environmental sound model was町ained with 92. Compared with the results of the single-occurrence environ mental sound source identification, the continuous・occurrence en. Jcinds of environmental sounds. vironrnental sound source identification perform加ce is significantly. was trained with 2620 Japanese words.. x. 20 sarnples and the speech model. This is because one continuous-occurrence environ. We evaluate the two-class classification performance by using. rnental sound wiIl be identified as two or more sirnilar single- or. the 216 Japanese isolated words and 92 Jcinds of single-occurrence. degraded.. continuous-occurrence environmental sounds. Figure 2 shows ex. environmentaJ sounds. arnples of出e spectrum of the identification error (bottle (glass). isolated words and 92 Jcinds of continuous-occuπence environ-. x. 5 sets (SNSET), and山e 2 1 6 Japanese. Fhu n/U n〆臼.
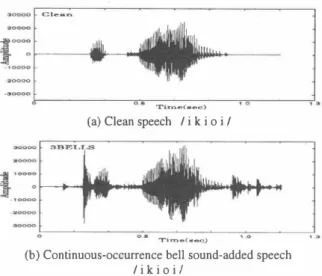
(3) EUROSPEECH 2003 - GENEVA. φ. EE 亘. 容. 6000 。 0 0 4 。 0 0 2 。. 0.1 Ti D1.c[sec】. |. 0.2. E 富国 亙. (a)Clipping sound. 6000. Table 4: An example of id昌ntification eπor results in continuous0cc凶Tence environmental sound so山∞ identification. Correct Bottle clink (continuous) Bottle clink (continuous). 0 0 0 4. Dropping sound of coins (continuous). 0 0 0 2 。. 0.1 Tin‘e【sec]. 6000. 2000 。. 0.2. 0.1. 0.3 Time【sec】. Dropping sound of coins (sin gle) 釦d throwing sound of dice (∞ntinuous). Single-occurrence. Con白lUous-occurrence Class. rate[%]. Test data. Class. rate[%]. Test data. SNSET1. 99.7. SCNSET 1. 99.7. SNSET2. 100.0. SCNSET2. 99.7 99.7. SNSET3. 99.7. SCNSET3. SNSET4. 100.0. SCNSET4. 99.7. SNSET5. 99.7. SCNSET5. 100.0. Ave.. 99.9. Ave.. 99.8. 0.4. E 一芸ES. (a) Bottle (Glass) c1ink. 4.1. Experimental condition. 6000 0 0 0 4. Table 6 shows the cons汀uctional condition of the environmen. 0 0 0 2. ta1 sound H恥岱1 and speech (phoneme) m1M. In the ASR, the speaker dependent Japanese phoneme-balanced isolated 2 1 6 words are employed as the test data. We conducted two experiments. One. 。. 0.1. 0.2. 0.3 T同時[sec]. 0.4. Figure 2: An example of the spectrum of identification eπor results in continuous-occurrence env. sound source identification x. IS出e single-∞C山花nce bell sound-added speech recognition. ln this experirnent, the single-occ山Tence bell sound-added speech is. (b) CUp c1ink. mental sounds. Bottle cJink (single) and pott巴Iγ clink (continuo岨s). Tabl巴 5: Experirnenta1 results for the two-c1ass classification be. in single-occuπence env. sound source identification. J. I I. Bottle clink (single) and cup clink (continuous). tween env目sound so町ce 組d speech. Figure 1・ An example of the spec甘um of identi負cation eπor results. 4000. I. Identification result. 0.2. (b)Breaking stick sound. �. I I. 5 sets (SCNSET) as test data. Table 5 shows. the experimental results in the above condition. As a result, we can confirrn出at the c1assification of single- and continuous-occurrence environrnenta1 sound sources and speech achieves very effective performance. Therefore, this method will be very useful for voice. activity detection for robust sp民主h recognition or talker localiza tion for microphone array steering. designed by adding the single-occurrence bell sounds (10 sampl巴S of bells3 in出巴 RWCP-DB) to speech. The 0出er is the continuous occぽTence bell sound-added speech recognition. Jn this experi・ ment, the continuous-∞currence bell sound-added speech is de signed by adding the continuous-occurrence bell sounds (30 sam ples of bells l , bells2, and bells3 in the RWCP-DB) to speech Figure 3 shows the c1ean speech and continuous-occu町ence bell sound-add巴d speech. These test data do not include data while出巴 HMMs are trained. Also, the SNR (Signa1-to-noise ratio) is 5 dB m contmuous-∞C山Tence bell sound-added speech. Although sta tionary noise usually does notωcur so much, similar noise sound. 4. ENVIRONMENTAL SOUND-ADDED SPEECH RECOGNITION WITH 田川M COMPOSITION We attempted to improve the ASR perfoロnance in environrnental. continuously occurs in rea1 acoustic env江onments (for 巴xample, the sound of a door c1osing). We assume this situation, and simu late it by continuous-o∞urrence bell sound-added speech with 30 samples of bells 1 , bells2 and bells3 in the RWCP・DB. sound-added speech wi出 a new m⑪f composition. A conven T'able 6・Cons町uctiona1 c⑪ndition of m1Ms. tional f品1M composition method composed of speech m1Ms and. I 1. 釦 environrnenta1 sound HMM紅白ned using noise periods prior. Feature vector. to the target speech in a captured signal. Although this紅白nmg. Sampling freq.. method is e仔'ective in a stationary noisy environment, it is not. Environmental sound HMM. so effective in a non-stationary noisy environment, such as a real room, because of noise mismatch. Therefore, we propose a new H恥酌1 composition method such白紙the environmental sounds are c1ustered into a similar category in adv釦ce, 組d出e category is se lected based 0目白e identification of environmental sound periods pnor to 白e target speech in the captぼed signal.. Then, the cat. egorized environmenta1 sound m1M for the selected category is. Num. of states Database. I I. 恥1FCC 12kHz 2 states ergodic RWCP sound scene database. Phonemem品f Num. of states Database Training data. composed to speech m仏1s. I I. I. 3 states ATR Japanese speech database Speak釘dependent 2620 Japanese words. ハhu n〆臼 円〆臼.
(4) EUROSPEECH 2003 - GENEVA. ゆ. 4 きまZ. Cl..._.,.. Table 7:. ASR results in single-occurrence bellsl sound-added. speech. I I I. HB岱1 sp即h fThilM Conventional HMM ∞mposition. τ・孟me{・eo). wι出 bellsl sounds and speech. (a) Clean speech / i k i 0 i /. Proposed HMM composition with categorized bell sounds and spωch. I I I. Reωg. rate [%] 26.4 95.8. 94.4. Table 8: ASR results in continuous-occurrence bells l , bells2, and bells3 sound-added speech 'Tim・(.・0). I I I I I I. HMM. (b) Continuous-occurrence bell sound-added speech. Speech HMM. /iki0 i/. Conventional HMM composition with bellsl sounds and speech. Figure 3・An example of test data on the ASR with HMM compo slt10n. w凶bells2 sounds and speech with bells3 sounds and speech Proposed HMM composition. 4.2. Experimental results. with categorized bell sounds and speech. Recog. rate [%] 41. 2 43.1 77.3 85.2. I 95.8. We carried out evaluation experiments on the ASR with the clean speech HÑ仏1, conventional HMM composition by one kind of. into categories based on the above proposed method for robust. environmental-sound trained HMM and speech HÑ仏1,and出e pro. speech recognition.. posed HMM composition by the categorized environmental sound HMM for a selected category and speech HMM.. 6. ACKNO羽fLEDGEMENT. Tables 7 and 8 show the experimental results. Although the conventional HMM composition and proposed HMM composi. This research was p紅tially supported by The Telecommunications. tion perforrnances are almost the same in the single-occuπence. Advancement Organization of Japan and The Ministry of Edu. bell sound-added speech, the proposed HMM composition with. cation, Culture, Sports, Science and Technology of Japan under. the categorized environmental sound HMM for a selected category. Grant-in-Aid No. 14780288. and speech HMM is about 10% more effective 出組曲e conven tional HMM composition with one kind of environmental-sound. 7. REFERENCES. trained HMM and speech HMM. In the above evaluation experiments, we confirrned that the proposed f品卸[ composition by the categorized environmental sound. [1] J.L. Flanagan, J.D. Johnston, R. Zahn, and G.w. E1k:o, “Computer-steer巴d Microphone Arrays for Sound Transduc tion in Large Rooms," 1. Acoust. Soc. Am., Vol. 78, No. 5,. HMM for a selected category and clean speech HMM achieves effective and robust perforrnance in environmental sound-added. pp. 1508-1518, Nov. 1985.. speech.. [2] S.F. Boll,“Suppression of Acoustic Noise in Speech Using. 5.. Spectral Subtraction," IEEE Trans. ASSP, Vol. ASSP-27, No. CONCLUSIONS. 2,pp. 113-120, 1979.. In this paper, we attempted to accurately identify and recognize. [3] F. Martin, K. Shik組0,. environmental sound sources for robust speech recognition. As a result, continuous-occurrence environmental sound identification. Minami, “Recognition. of. [4] T. T,誌iguchi, S. Nakamura, 釦d K. Shikano, “H1v⑪1Separation- Based Speech Recognition for a Distant Moving. tive perforrnance. However, we confirrned that identification er. Speakerぺ IEEE Tr釦s. SAP, Vol. 9, No. 2, pp.127-140, Feb.. ror tends to occur in similar categories in the evaluation experi ments. Also, as a result of the classification experiment of 巴nviron. Y.. Proc. EUROSPEECH'93, pp. 1031-1034, Sep. 1993.. could not achieve effective perfo口nance,although single-occurrence environmental sound identification sufficiently achieved出e effec-. and. Noisy Speech by Composition of Hidden Markov Models,". 2001.. mental sound source and speech, we confirrned that environmen-. [5] S. Nak銅山a, K. Hiyane, F. Asano, T. Yamada, 釦d T. Endo,. tal sound source 組d speech c組 be classi白ed effectively with an. “Data Collection in Real Acoustical Environments for Sound. HMM. In addition, we proposed a new HMM composition me白od. Scene Understanding and Hands齢Free Speech Recognition,". with a categorized environmental sound HMM and speech HMM.. Proc. EUROSPEECH'99, pp. 2255-2258, Sep. 1999.. As a result of the evaluation experiment, we confirrned 出at the proposed HMM composition achieves effective and robust perfor・. [6] K. Takeda, Y. Sagisaka, and S. Katagiri,“'Acoustic-Phonetic Labels in a Japanese Speech Database," Proc. European Con. mance in environm巴ntal sound-added speech. In future work, we. ference on Speech Technology, Vo1. 2, pp. 13-16, Oct. 1987. will attempt to automatically classify the environmental sounds. 円i 円〆臼 円〆U】.
(5)
図

関連したドキュメント
In 18 unilateral spatial neglect patients, six types of sound image (1, 2, and 3 times threshold sounds for each side) based on the inter-aural time difference discrimination
We developed a new mammalian cell-based luciferase reporter gene assay for androgenic and antiandrogenic activities of chemicals and environmental samples.. Environmental
Required environmental education in junior high school for pro-environmental behavior in Indonesia:.. a perspective on parents’ household sanitation situations and teachers’
Recognition process with a laser-assisted range sensor(B) 3.1 Principle of coil profile measurement This system is only appii~ble fm the case where the coils are all
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
スライダは、Microchip アプリケーション ライブラリ で入手できる mTouch のフレームワークとライブラリ を使って実装できます。 また
patient with apraxia of speech -A preliminary case report-, Annual Bulletin, RILP, Univ.. J.: Apraxia of speech in patients with Broca's aphasia ; A
On a theoretical side, we state a sound probability space for lucidity and thus for modularity and prove that in this paradigm of lucidity, using a subtractive trade-off and either
