Title 人間との親和性向上のためのヒューマノイドビジョンシステムの研究( 本文(Fulltext) ) Author(s) 山本, 和彦; 加藤, 邦人 Report No. 平成16年度-平成17年度年度科学研究費補助金 (基盤研究(C) 一般 知覚情報処理・知能ロボティクス 課題番号 16500105) 研究成果報告書 Issue Date 2006-03 Type 研究報告書 Version URL http://hdl.handle.net/20.500.12099/2836 ※この資料の著作権は、各資料の著者・学協会・出版社等に帰属します。
人間との親和性向上のためのヒューマノイドビジョンシステムの研究
16500105
平成 16 年度∼平成 17 年度科学研究補助金
(基盤研究(C))研究成果報告書
平成 18 年 3 月
研究代表者 山 本 和 彦
岐阜大学工学部教授
はしがき 近年、ヒューマノイドロボットの研究が多方面で行われている。これらのロボットにしばしばカメラ が装着されるが、補助的視覚として用いられるのが一般的である。我々は、「ヒューマノイドロボット の眼は、やはりヒューマノイド的であるべき」との観点から、人間的なビジョンシステムを「ヒューマノ イドビジョン」と呼び、提唱してきた。ヒューマノイドビジョンの研究では、今までに行われてきた画像 処理技術のみに留まることなく、身体全体としての応答性を含め、あくまでユーザが人間らしさを感 じることができるビジョンシステムに主眼をおいた。又、ヒューマノイドは外見及び内部機能的な面 で、より人間をシミュレートできると考えられる。本研究では、各種の人間から見て人間らしさを感じ るインターフェースを考察し、ヒューマノイドビジョンとは何かについて明らかにした。 これらの研究のために、我々は 2 眼のアクティブカメラを搭載したヒューマノイドロボットを独自に 製作し、これをテストベッドとして人間との親和性を向上させるインターフェースの実現を目指し研 究を行った。ロボットは頭部を中心に 24 自由度を持たせてある。 ヒューマノイドビジョンついて考えた場合、いくつかのレベルが考えられる。まず、センサとしての 眼では、基礎パターンの認識、距離の測定、障害物や危険の判断などを行い、行動に直接結び つく初期視覚的な認識が求められる。また、これらはなるべく簡素な処理の集まりとして構成され、 それぞれは高速な処理時間が求められる。 一方、高速性は必ずしも要求されないが、高度な認識も要求される。例えば、今見えているのは 何なのか、自分はどこにいるのかなど、より高度な認識処理である。これらは、一般的な知識を必 要とし、その知識と画像処理結果から総合的な判断が必要である。 このような見地に立って、ヒューマノイドビジョンと言う新しい基本理念に基づき研究を行った。今 回用いたヒューマノイドロボットでは両眼カメラからの画像を用いて距離計測が実現できるが、本研 究では単なる距離計測に留まらずこれらの基本処理をベースに、ヒューマノイドビジョン実現のため の、より高精度な画像処理、ならびにロボットの制御手法を開発した。 また、距離の測定、人物の位置の特定、ジェスチャー認識を行い、人間とコンピュータとのより親 近感のあるコミュニケーションを目指す。その一つとして、本システムを用いたジェスチャー認識の 研究を行った。まず、両眼から得られた画像から顔テンプレートのマッチングにより、人物の大体の 位置を検出した。次に、得られた顔位置から両眼立体視により人物までの距離を計測する。この計 測距離情報を用い、人物の間接位置推定を行った。さらに、人物骨格モデルとの照合によりジェス チャーを認識した。これを、ヒューマノイドロボットに模倣させるシステムを作成した。 続いて、人間とロボットとの親和性についての研究を行った。人間がロボットを見たときに、より人 間らしさを感じるためには、ロボットが人間らしく動く必要があると考えた。そこで、人間の物体追跡 方法を観察し、モデル化することによりロボットにより人間らしい物体追跡を実現させた。これは、ヒ ューマノイドビジョンの観点からは、人間の物体追跡動作は人間の身体形状に最適化されている はずで、人間を模したヒューマノイドロボットにおいても、この追跡方法が最適となる可能性があると 考えられる。 まず本研究では、人物に移動スピードが異なるマーカーを追跡させ、眼球と首をどのような関係
で動かし追跡行動を行うかを調べた。それにより、人間はある一定速度までは眼球運動で追跡を 行い、視線がいっぱいになると首を用いることが分かった。また、ある一定速度を超えた追跡では、 初めから首を用いて追跡を行う。これらの観測結果を基に人間の物体追跡モデルを作成した。そ れを、ヒューマノイドロボットに搭載することにより、より人間らしい物体認識を実現することができ た。 平成 16 年度 1 ヒューマノイドビジョン理論の確立 本研究で提案する「ヒューマノイドビジョン」の概念と目標を確立した。ここでは、ユーザはコンピ ュータが人間らしい認識をしていると感じられるインターフェースの実現を目指した。そのためのロ ボットにおける認識手法、結果の提示方法を考案した。 2 距離計測方法の検討 本研究で用いたヒューマノイドロボットは 2 眼を持っており、距離計測が可能である。距離計測結 果を人物検出、ジェスチャー認識処理と親密に連動させ、より高い認識を実現した。ただし、本シス テムの距離計測では高精度な 3 次元形状の取得は目標とせず、大まかな前後関係や認識対象へ の距離の計測で十分であると考えた。なぜなら、距離計測、テンプレートマッチング、色情報を複 合的に用い人物検出、ジェスチャー認識を行う手法を目指したため、精度よりも処理速度を優先し た方が、結果的に親和性が向上するからである。 3 より人間らしさを感じる反応の開発 ユーザにロボットの目がアイコンタクトするだけで、ユーザは今までのコンピュータになかった親 近感を感じることができる。このような、人間らしさを感じるビジョンシステムの結果提示方法につい ての研究を行った。また、感情表現の仕方。人間の表情学習手法の開発を行った。 4 ヒューマノイドビジョンインタフェースの構築 以上の研究成果をもとに、ロボットの前で行ったジェスチャーを認識し、それをヒューマノイドロボ ットが模倣するシステムを製作した。これにより、ロボットへの動作の簡略化、人間とロボットとのコミ ュニケーションインタフェースの基礎手法を確立した。
平成 17 年度 1 眼球制御方法の確立 前年度の成果をもとに、眼球の制御方法を確立した。まず、認識に適した眼球の制御方法を検 討し制御アルゴリズムの開発を行った。眼球は距離計測、ならびに認識対象の追尾の役割を持ち、 動きアルゴリズムは認識をより確実なものとした。また、認識のためだけではなく、よりユーザに親近 感を持たせるため、表情の制御方法も重要である。これらのアルゴリズムも認識のための眼球制御 アルゴリズムとあわせ開発を行った。また、首の自由度も持たせてあるため、眼で追尾できないほど の移動には頭部自体の移動で対応できる。従って、頭部の移動方法と、それに合わせたビジョン システムによる眼球の制御方法の基礎研究開発を行った。 2 人間の物体追跡法の観察 ロボットの眼球制御アルゴリズムの開発にあたり、まず、人間がどのような物体追跡をするか、被 験者を用い実験を行った。スクリーンに等速度で移動する物体を投影し、その移動速度を変えたと きの、人間の追跡方法を観察した。この結果より、人間は低速度の移動ではまず目から追跡を開 始し、その後首を用いて追跡を行う。逆に、移動速度が速い場合は、初めから首のみで追跡を行う ことがわかった。 3 より人間らしい眼球、ならびに頭部の制御方法の検討 以上の成果をもとに、人間の物体追跡方法をモデル化し、ロボットに搭載した。同時に、物体追 跡システムの開発も行った。これにより、より人間らしいロボットによる物体追跡を可能とした。 研究組織 研究代表者 : 山本和彦 (岐阜大学工学部教授) 研究分担者 : 加藤邦人 (岐阜大学工学部助手) 交付決定額(配分額) (金額単位:円) 直接経費 間接経費 合計 平成 16 年度 1,400,000 0 1,400,000 併催 17 年度 1,500,000 0 1,500,000 総 計 2,900,000 0 2,900,000
研究発表
(1) 学会誌等
[1] Tomoki Kobayashi, Yukihiro Ogawa, Kunihito Kato and Kazuhiko Yamamoto: "Expression Learning and Recognition System for a Family Robot", Proc. of the 1st Canadian Conference on Computer and Robot Vision (CRV2004), pp.259-264, 2004.5.17 [2] Tomoki Kobayashi, Yukihiro Ogawa, Kunihito Kato and Kazuhiko Yamamoto: "Learning
System of Human Facial Expression for a Family Robot", Proc. of The Sixth International Conference on Automatic Face and Gesture Recognition (FG2004), pp.481-486, 2004.5.18 [3] Hideaki Mitsugami, Kazuhiko Yamamoto, Kunihito Kato and Yukihiro Ogawa: "Motion
Emulation System with Humanoid Robot and Image Processing", Proc. of the 1st Asia International Symposium on Mechatronics (AISM2004), pp.716-721, 2004.9.28
[4] Tomoki Kobayashi, Yukihiro Ogawa, Kunihito Kato and Kazuhiko Yamamoto: "Interactive System of Learning Facial Expression for a Family Robot", Proc. of the 10th International Conference on Virtual System and Multimedia (VSMM2004), pp.317-321, 2004.11.17
[5] Hideaki Mitsugami, Kazuhiko Yamamoto, Kunihito Kato and Yukihiro Ogawa: "Development of Motion Emulation System Using Humanoid Robot", Proc. of the 10th International Conference on Virtual System and Multimedia (VSMM2004), pp.1136-1141, 2004.11.19 (2) 口頭発表 [1] 光上英明, 山本和彦, 加藤邦人: "ヒューマノイドを用いた人物動作模倣システムの構築 ", 第 9 回知能メカトロニクスワークショップ, pp.231-236, 2004.8.6 [2] 小林友樹, 小川行宏, 加藤邦人, 山本和彦: "人工ペットにおける顔表情学習システム のための顔領域検出手法の提案", 平成16年度電気関係学会東海支部連合大会, O-460, 2004.9.27
1. はじめに 4 2. 動作模倣システム 5 2.1. 動作模倣システムの必要性 5 2.2. 動作の取り込み問題 6 2.3. センサーを用いたモーションキャプチャ 6 2.3.1. マーカーを用いたモーションキャプチャ 6 2.3.2. 画像を利用した動作の取り込み 7 2.3.3. 使用する手法の決定 8 2.4. ヒューマノイドロボット“YAMATO” 8 3. 二次元動作模倣システム 12 3.1. システム概要 12 3.2. 人物領域検出 12 3.3. 手・顔位置検出 13 3.4. 首・肩・肘位置検出 14 3.5. 形状情報を用いた手・頭頂位置検出 16 3.6. 動作例 19 4. 三次元動作模倣システム 21 4.1. 概要 21 4.2. 三次元動作の取り込み 22 4.3. 画像の補正 22 4.3.1. ロボットから得られる画像 22 4.3.2. エピポーラ線 23 4.3.3. キャリブレーション 24
4.4. 視差画像の作成 27 4.4.1. 原画像サイズの視差画像 28 4.4.2. 低解像度化による高速化 29 4.4.3. テンプレートサイズの決定 29 4.5. 人物領域検出 31 4.6. 関節点検出 33 4.7. 動作例 35 4.8. システムの高速化 37 4.8.1. 低解像度視差画像の作成 37 4.8.2. 低解像度視差画像を基にした視差画像 40 4.8.3. 人物領域抽出 41 5. 人物動作模倣システムのまとめ 44 6. 物体追跡運動解析とヒューマノイドビジョンの表現 45 7. 人間の物体追跡運動解析 46 7.1. 撮影方法及び環境 46 7.2. 実験 47 7.3. 目と顔の移動量グラフの作成方法 49 7.4. 目と顔の移動推移グラフ 52 7.4.1. 指標の速度 120deg/s 52 7.4.2. 60deg/sのとき 53 7.4.3. 40deg/sのとき 54 7.4.4. 30deg/sのとき 55 7.4.5. 24deg/sのとき 56 7.4.6. 20deg/sのとき 57 7.5. 考察 58 8. YAMATOにおける物体追跡手法 59
8.1. モデルの作成 59 8.2. 物体追跡手法 59 8.2.1. 手法概要 59 8.2.2. 特徴パラメータの計算 60 8.2.3. 角度の算出 62 8.3. 動作結果 63 8.4. 考察 64 9. 物体追跡運動模倣システムのまとめ 66 参考文献 67
1.
はじめに
近年、様々な企業や大学などの研究機関により、ロボットの研究・開発が盛 んに行われ、各分野における活躍には目覚しいものがある。本研究では、その 中でもヒューマノイドロボットに注目し、「ヒューマノイドにはヒューマノイド らしさが必要である」との観点からヒューマノイドビジョンに関する研究を行 った。 はじめに、現状のヒューマノイドロボットは決められた動きをするものが多 い。これは、ロボットの動作があらかじめ開発者によってプログラムされてお り、ロボットはこれを実行しているだけに過ぎないためである。人と共存して いくためには決められた動作を行うだけではなく、必要な動作を学習していく 必要がある。これは、ロボットを使用する人が必要な動作をプログラムするこ とで解決できるが、プログラムを行うためには多くの専門知識が必要となる。 ロボットの開発に携わっている者ならともかく、一般のユーザにこれを求める のは困難である。 もしロボットが人の動きをまねることができれば、ロボットは人の動作を見 ることによりその動作を学習することが可能となる。また、プログラムにより 動作を生成するよりも、より直感的に動作を生成することができると共に、動 作作成時の手間を大幅に減らすことができると考えられる。そこで、本研究で は新たなロボット制御方法として、見ることによる学習を提案し、ロボットが 人の動きを模倣するシステムの構築を行った。 次に、カメラを搭載したロボットが見られるようになったが、それは補助的 視覚として使われているのが現状である。本研究ではカメラがヒューマノイド ロボットにおいて顔を表現する重要な要素のひとつであると考えた。また、カ メラはヒューマノイドロボットにおいて目であり、人間らしく動かすことや認 識手法により最適な画像処理ができるのではないかと考えた。 そこで、まず人間の目と顔の使い方に着目した。今回、人間の物の追い方(物 体追跡運動)について解析を行うことで得られた特徴を動作に実装し、ヒューマ ノイドビジョンを実現する研究を行った。 今回、これらの研究を行うために、我々が開発したヒューマノイドロボット YAMATO 上に実装した。2.
動作模倣システム
本研究で構築する動作模倣システムは、ロボットが外部に設置されたカメラ、 もしくは自身に搭載されているカメラを用いて人物の状態を認識し、これを再 現するものである。本システムでは、人物の上肢の状態の推定、及びロボット での再現を行う。動作を模倣するにあたり重要な要素となるものは、動作を再 現する際の精度と速度である。高精度な推定を高速に行うことができるのが最 善ではあるが、一般に高精度な推定を行うほど処理が複雑になり、速度が低下 する。本システムでは精度よりも処理速度に重点を置き、リアルタイムで模倣 を行えるシステムを構築した。2.1.
動作模倣システムの必要性
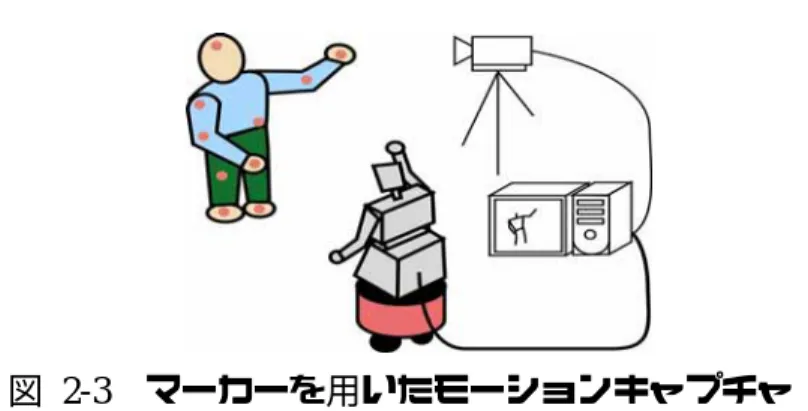
本システムの概観図を図 2-1 に示す。本システムは人物の動作を取り込むた めのカメラと、処理を行うためのコンピュータ、また模倣を行うためのヒュー マノイドロボットによって構成される。大まかな処理の流れは、 1. 動作画像の取り込み 2. 人物の動作の解析 3. ロボットの動作への変換 4. ロボットの動作 となる。カメラから取り込まれた画像はコンピュータに渡され、コンピュータ コンピュータ カメラ(ロボットの目) ユーザ ヒューマノイドロボット 図 2-1 システムの概観図 上で人物の動作の解析を行う。動作の解析は、人物の上半身の各関節点を検出 することで実現する。各関節点を検出した後に、人物の動きをロボットの動きへと変換する。これはロボットの腕の長さと人物の腕の長さが違うため、動作 のスケールを変換する必要があるためである。そして最後に得られたデータを 用いてロボットの動作を行う。 図 2-2 センサーを用いたモーションキャプチャ
2.2.
動作の取り込み問題
ッ ためには、人の動きを取り込む必要がある。 こ2.3.
センサーを用いたモーションキャプチャ
2.3.1. マーカーを用いたモーションキャプチャ 2-3 に示すように人物の動き を ロボ トが人の動作を模倣する の「動きをどのようにして取り込むか」がシステムを構築する上での大きな 問題となる。動きを捉えるための方法としては、センサーを用いたモーション キャプチャを利用する方法、マーカーを用いたモーションキャプチャを利用す る方法、カメラから得られる画像を用いる方法などが挙げられる。各方法の利 点・欠点は次の通りである。 センサーを用いたモーションキャプチャ[1]では、動作の計測を行う部分に磁気 センサーなどを取り付け、このセンサーの動きを捉えることで人物の動きを取 り込むものである。図 2-2 に示すように、センサーがケーブルで計測器とつな がっているため、ユーザが身動きをとりにくいといったことが懸念される。ま た、動作を学習させるたびに、全身にセンサーを身につけなくてはいけないた め、ユーザへの負担が非常に大きい。しかし、センサーを用いて直接的に動き を計測できるため、高精度で位置情報を得ることが可能である。得られる情報 の精度・信頼性は高いが、ユーザが自然な動きをできるかどうかという問題が残 るシステムである。 マーカーを用いたモーションキャプチャ[2]は、図 計測する各点にマーカーを取り付け、このマーカーの動きをカメラなどで捉図 2-3 マーカーを用いたモーションキャプチャ えるものである。センサーを用いたモーションキャプチャのように、センサー と計測器がケーブルによって接続されるようなことがないため、動作を行う際 にケーブルを気にする必要がなく、自然な動作を行うことが可能である。また、 マーカーを用いることにより、動きをほぼ直接的に取り込むことができるため、 ある程度高精度で動きの情報を得ることができる。しかし、動作を学習させる たびにマーカーを体中に身につける必要があり、動作全体を撮影するには複数 台のカメラが必要となる。これによりシステムが大きくなるという問題が発生 する。 図 2-4 画像を用いた動作の取り込み 2.3.2. 画像を利用した動作の取り込み 画像を用いて動作を取り込む手法を用いた場合、図 2-4 のようにカメラを用 いて人物の動作を撮影し、得られる画像のみを用いて関節点などを検出するた め、ユーザがセンサーやマーカー類を身につける必要はない。ユーザは何も気 にすることなく動作ができるため、もっとも自然な動きができる。しかし、得 られた画像から動きを捉える部分を検出する必要がある。各動作点の位置を直 接的に得ることができないため、検出精度は他の手法に比べ劣る。複数台のカ メラを用いたシステム[3][4][5]の場合、カメラを複数台利用することで、多方向か
ら動作を撮影し、検出精度を上げることが可能であるが、この場合システムが 大きく、また複雑になってしまうという欠点を持つ。これに対し、1 台のカメラ のみを用いたシステム[6][7][8]の開発もされている。これは検出精度よりもシステ ム全体としての使いやすさを重視したものであるが、検出できる空間が限られ たり、検出できる動きが限られるなどの問題点がある。 2.3.3. 使用する手法の決定 の の利点・欠点から、検出精度を上げるほどユーザ へ るにあたり、まず本システムの使用目的を明 確 り込む方法を 採 むことで、これらの負担は大幅に軽減される。し か
2.4.
ヒューマノイドロボット
YAMATO
程度の自由度がロボット に 現状 それぞれのシステム の負担は大きくなり、ユーザへの負担を軽くするには、精度の低下が避けら れないということが分かった。 本研究で使用する手法を決定す にする。システムの使用環境は家庭内を想定する。これは、未来の家庭内に おいてのロボットの動作作成を目的としているためである。家庭での使用を想 定した場合、ユーザへの負担はできるだけ少ないほうがよいと考えられる。こ れはユーザへの負担が大きいシステムは、たとえ一般家庭に普及したとしても、 継続的に使用されることを見込むことができないためである。 以上のことをふまえ、本システムでは、画像を用いて動作を取 用した。センサーやマーカーを用いたモーションキャプチャを利用した場合、 動作を取り込むために専用の装置を必要とするうえ、動作の学習を行わせるた びにユーザがセンサーやマーカーを身につける必要がある。家の中に専用の装 置を用意することは困難であり、学習毎にセンサー類を体に身につけることは 非常に大きな負担となる。 画像を用いて動作を取り込 し、画像を用いる手法では、カメラ構成と関節点の検出方法が精度に大きな 影響を与える。カメラ台数が多いほど検出精度の向上を見込むことができるが、 システム全体としての構成が大きくなってしまい、センサーやマーカーを用い た場合と同じ問題を持ってしまう。そこで、家庭内での学習の場所を選ばず、 ある程度の精度で関節点の検出を実現するために、ヒューマノイドロボットの 目の部分に取り付けられた 2 台のカメラを利用して、ロボット自身が動作を見 て人物の動作の取り込みを行うこと目指す。 ロボットが人物の動きを再現するためには、人と同 なければならない。これを実現するために、図 2-6 に示すヒューマノイドロ ボット YAMATO を本研究に用いた。YAMATO は主に頭部と腕部によって構成される。頭部に 9、各腕に 6、合計 21 自由度を持つように設計されている。頭 部、腕部の詳細な自由度を表 2-1 に示す。人物の腕の動きは肩と肘の 5 自由度 を用いて再現される。また、ロボットの下半身には自律移動型ロボットである Magellan Pro を用いている。 図 2-6 ヒューマノイドロボット 表 2-1 YAMATO の自由度 部位 自由度 目 3 首 4 頭部 口 2 肩 3(×2) 肘 2(×2) 腕部 指 1(×2) 合計 21 図 2-5 頭部画像 YAMATO
ロボット頭部の目には図 2-5 のように2つのカメラが取り付けられている。 目は左右方向には独立して動き、上下方向には、連動して動く。よって左右方 向に 2、上下方向に 1 の合計 3 自由度を持っている。このカメラを使うことで、 ロボット正面の映像を撮影することが可能である。また、両カメラの画像を用 いることで、ステレオ視を実現することができる。図 2-7 に両カメラから得ら れる画像の例を示す。カメラから得られる画像は歪みを含んでおり、また各カ メラの方向は微妙にずれている。左右方向には独立して目を動かすことが可能 なため、左右方向のずれは目を動かすことで補正が可能である。しかし、上下 方向の移動は連動しているため、カメラの取り付け方を手動で調整する必要が ある。しかし、手動での位置調整では手間がかかる上、正確に平行にすること は難しい。よって、今回は両眼を固定し、あらかじめカメラキャリブレーショ ンを行った。 (a) 左カメラ画像 (b) 右カメラ画像 図 2-7 目のカメラから得られる画像例 表 2-2 送信命令の構造 J0R 00 0000 0000 0000 0000 0000 0000 000000000 右腕 部位 時間 肩 1 肩 2 肩 3 肘 1 肘 2 指 文字数調整 J0L 00 0000 0000 0000 0000 0000 0000 000000000 左腕 部位 時間 肩 1 肩 2 肩 3 肘 1 肘 2 指 文字数調整 J0H 00 0000 0000 0000 0000 0000 0000 000000000 顔 部位 時間 唇 両目 右目 左目 文字数調整 J0E 00 0000 0000 0000 0000 0000 0000 000000000 首 部位 時間 顔 1 顔 2 首 1 顔 3 文字数調整 時間単位は 100[ms] 送信角度単位は[°]
YAMATO の制御は各関節に対して動作角と動作時間を指定することで行う。 制 御 命 令 の 送 信 は コ ン ピ ュ ー タ の シ リ ア ル ポ ー ト を 通 じ て 行 う 。 最 初 に YAMATO の初期化命令を送信し、その後に各関節に対し動作角度を送信する。 送信する命令は 38 文字の文字列であり、右腕、左腕、頭部、首の 4 つに大別さ れ て い る 。 表 2-2 に 命 令 の 構 造 を 示 す 。 命 令 は 最 初 に 制 御 す る 区 分 (J0R,J0L,J0H,J0E)を指定し、その後に、動作時間(100ms 単位)、そして各関節の 動作角度(°単位)を設定する。各関節の動作角度を指定しても、命令が 38 文字 に満たないため、不足部分には 0 を設定して送信をする。
3.
二次元動作模倣システム
3.1.
システム概要
まず、比較的簡易な動作模倣を実現するために、人物の動作を二次元平面上 と限定し、二次元動作模倣システムの構築を行った。本システムでは、1 台のカ メラを単純な背景下で用い、画像の取得を行った。また、人物モデルを用いて 人物の状態の推定を行った。 本システムの流れを図 3-1 に示す。最初にカメラから入力画像を取得し、画 像中から人物領域を抽出する。次に肌色の情報を用いて、手・顔位置の検出を行 う。抽出された人物領域と、検出された手・顔位置は、首・肩・肘の位置を検出す るために用いられる。各点が検出されたら、肩と肘の角度を計算し、これをロ ボットに送信して動作させる。以上の処理を取得される画像ごとに繰り返すこ とで、人物の模倣を行う。 ロボット動作 肩・肘角度計算 首・肩・肘位置検出 手・顔位置検出 人物領域抽出 入力画像取得 図 3-1 処理の流れ3.2.
人物領域検出
人物の動きを捉えるためには、まず画像中から人物を検出する必要がある。 画像中から人物を抜き出す手法としては、背景画像をあらかじめ記憶し、現在 の画像と差分をとることによって得られる画像を利用する背景差分法や、人の 形をあらかじめ記憶しておき、これを取得した画像中で検索するテンプレート マッチング法などがある。 本システムではできるだけ問題をシンプルにし、動作の模倣のみに焦点を当 てるため、ロボットの位置は固定し、単純な背景を用いて背景差分による人物 領域を検出を行った。図 3-2 (a)はシステムが記憶している背景画像、図 3-2 (b)(a)背景画像 (b)入力画像 (c)結果画像 図 3-2 背景差分 はカメラから得られた入力画像である。図 3-2(c)は背景差分の結果であり、差 分が得られた領域を黒で示している。正確に人物領域を抽出できていることが わかる。
3.3.
手・顔位置検出
本システムでは、画像中から手・顔位置を検出するために肌色情報を用いた。 肌色情報はカメラから得られるカラー画像を用いることで得ることができる。 肌色領域の抽出には、LUV表色系を用いた肌色領域検出法[9]を用いた。肌色の 値は日本人の肌色にあわせてある。図 3-3 に図 3-2(b)から肌色領域を抽出した 結果を示す。肌色領域抽出により、主として顔と手の領域を得ることができる。 得られた結果のうち、最大面積となる領域を顔領域と決定し、両手は顔領域を 除く、上位 2 つの面積と決定した。また、右手と左手は顔に対する相対的な位 置関係を用いて決定した。図 3-3 肌色領域抽出
3.4.
首・肩・肘位置検出
首・肩・肘位置は距離変換画像と人物モデルを用いて検出を行う。距離変換画 像は図 3-2(c)で得られる人物領域の画像に、外側から内側に向けて重みをつけ 図 3-4 距離変換画像 首 頭 肩 肘 手 図 3-5 人物モデルていったものである。こうすることにより、人物領域の中心部分で重みが大き くなり、外側に行くほど小さくなる画像を得ることができる。図 3-4 に作成さ れた距離変換画像を示す。黒いほど重みは小さく、白いほど重みが大きくなる ように表している。特に体の中心部分で、値が大きくなっていることがわかる。 人物モデルは図 3-5 のようなスティックモデルを用いており、各関節点とそれ を結ぶ棒で構成されている。本システムでは、人物の腕の動きを真似るため、 顔から手にかけてのモデルを使用した。 各関節点の検出を行うにあたり、最初に図 3-6 に示すように距離変換画像上 に顔・手位置検出で得られた結果を重ね、首位置を検出する。首位置は人物モデ ルの顔−首間の長さを用いて探索される。顔中心から顔−首間の長さの円弧を 描き、この円弧上で距離変換画像の距離値が最大となる点を首と決定した。距 離値が最大となる点を取ることにより、ほぼ正確に関節点を検出することがで きる。 図 3-6 首の検出 図 3-7 肩・肘の検出
首位置を決定した後に、検出された首位置を使って肩位置の検出を行う。図 3-7 に示すように、肩位置は首位置を中心とした首−肩間の長さの円弧を描き、 この円弧上で距離値が最大となる点として決定される。同様にして肘位置は肩 位置を中心とし、肩−肘間の長さを利用して検出される。このようにして各関 節点が決定される。 図 3-2(b)の入力画像に対し、関節点を検出した結果を図 3-8 に示す。画像か ら、各関節点が正確に検出できていることがわかる。 各関節点を検出した後に、肩と肘の角度を計算し、ロボットを動作させる。 本システムでは二次元の動作の模倣を行うため、人物の動作は肩と肘を制御す ることで再現することが可能である。 図 3-8 関節点検出結果
3.5.
形状情報を用いた手・頭頂位置検出
ここまでの手法では手・顔位置を検出するために、肌色情報を用いていた。し かし、色情報は照明などの外部環境が少し変化しただけで大きな影響を受ける ことが多い。模倣を行うに際し、手位置は非常に重要な情報である。検出され た手位置が実際の位置と異なった場合、ロボットの動作はユーザの動きとは別 のものになってしまう。 環境の変化による影響を少なくする手法の一つとして、色情報ではなく、形 状情報を用いることがあげられる。そこでシステムの改良として、形状情報と して人物の輪郭を用い、輪郭情報から頭頂および手先位置の検出を行った。 輪郭情報を作成するに当たり、最初に重心と頭頂位置の決定を行う。重心位 置は図 3-4 の距離変換画像を使い、次の式を用いて検出する。( )
( )
⎥ ⎦ ⎤ ) 0 , 0 ( / ) 1 , 0 ( 0 , 0 / 0 , 1 d d d d M M ⎢ ⎣ ⎡ = ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ g t g t M M y x(
)
=∑ ∑
i j ij p p d p q i j d M , (3-1) (3-2) ここで、i, jはそれぞれ画像上でのx座標、y座標を表しており、dijは距離変換画 像上での(i, j)成分を表している。これによりMd(0, 0) は距離変換画像の各画素値 の和が、Md(1, 0) は距離値にx座標をかけたものの和が、Md(0, 1)は距離値にy座 標をかけたものの和が得られる。頭頂位置は得られた重心位置から上方に探索 していき、人物領域の端となる部分に決定した。このようにして検出された頭 頂と重心位置を図 3-9 に示す。 重心と頭頂位置を検出した後に、手先位置の検出を行う。手先位置は、頭頂 から輪郭線上を探索していき、頭頂と重心からの距離を用いて決定される。手 先位置を求めるための評価値を L(s)とすると、 図 3-9 頭頂と重心位置 p(s) g(s) 点 s 図 3-10 L(s)モデル( )
s p( )
s g( )
s L = 2 + 2 (3-3) で求められる。図 3-10 に L(s)を求める際のモデルを示す。s は輪郭線上の位 置であり、p(s)、g(s)はそれぞれ、点 s における頭頂からの距離と重心からの距 離である。図 3-4 の距離変換画像を用いて作成した L(s)特性を図 3-11 に示す。 x 軸は頭頂から左右に輪郭線上を探索していった距離を表しており、正方向が右 側へ探索した場合、負方向が左側へ探索した場合である。y 軸は式(3-3)によって 得られる L(s)の値を表している。グラフから、特性の端部分を除くと、3 つのピ ークがあることがわかる。中心部分のピークは頭頂であり、その左右のピーク がそれぞれ左右の手の手先位置を表している。他のポーズの場合の L(s)特性の例 図 3-13 ポーズ 1 0 50 100 150 200 250 -500 -300 -100 100 300 500 s L( s) 図 3-12 ポーズ 1 に対する L(s)特性 0 -300 -100 100 50 100 150 200 250 -500 300 500 図 3-11 L(s)特性0 50 100 150 200 250 -500 -300 -100 100 300 500 s L( s) 図 3-15 ポーズ 2 図 3-14 ポーズ 2 に対する L(s)特性 を図 3-12 及び図 3-14 に示す。図 3-12 は図 3-13 に対する特性を、図 3-14 は図 3-15 に対する特性を表している。これら 3 つの特性において、ユーザがとって いるポーズは違うが、特性に大きな違いが表れないことがわかる。つまり、二 次元の動きであれば、その姿勢によらず安定して頭頂及び手先の検出が可能で あるということを示している。 首、肩、肘位置については、前節と同様に人物モデルを用いたマッチングに より検出を行う。これによって検出された各関節点の結果を図 3-16 に示す。ほ ぼ正確に頭頂、手先が検出できていることがわかる。
3.6.
動作例
ス 倣の動作例を図 3-17 に示す。左の列にカメラから得られた画 像 テムは Pentium4 2.0GHz のコンピュータ上で 1 秒間約 7 枚の画像を処 図 3-16 関節点検出結果 本シ テムの模 の例を、右の列にこの画像を用いてロボットが模倣を行った結果を示す。人 物とロボットの画像を見比べると、ほぼ人物の動きを再現できていることがわ かる。 本シス理することが可能であった。そのため、ロボットはリアルタイムで人物の動作 を模倣することが可能である。 (a) 入力画像 1 (b) 模倣結果 1 (c) 入力画像 2 (d) 模倣結果 2 (e) 入力画像 3 (f) 模倣結果 3 (g) 入力画像 4 (h) 模倣結果 4 図 3-17 模倣の動作例
4.
三次元動作模倣システム
4.1.
概要
三次元動作模倣システムは、二次元システムを基に、模倣する動作を三次元 に拡張したものである。二次元システムでは外部環境やシステム構成をシンプ ルにすることで、簡単な処理で高速に動作するステムを構築した。しかし、実 際の人物の動きは三次元的な動きであるうえ、背景などの外部環境も常に一定 であるとは限らない。特に一般の家庭での動作を考えた場合、二次元システム で想定したような単純な背景が常に存在しているとは限らないので、背景の複 雑さに影響されず動作するシステムを構築しなければならない。 そこで本システムでは、三次元的な動きを再現できること、及び複雑な環境 下での模倣を行えることを目指してシステムの構築を行った。 三次元システムの処理の流れを図 4-1 に示す。最初にロボットのカメラを用 いて左右それぞれの画像を取得し、得られた画像を用いて視差画像を作成し、 距離計測を行う。次に、視差画像上で視差が存在する領域に対し、テンプレー トマッチングによる顔の探索を行い、探索結果を用いて視差画像中から人物領 域を抜き出す。そして、入力画像から肌色領域を抽出し、得られた人物領域と 照らし合わせることにより手位置を決定する。また、人物領域と人物モデルを 用いて首、肩位置を決定する。最後に検出された肩、手位置を使いヤコビ行列 を用いた逆運動学を解くことにより、腕の各関節の角度を求める。この求まっ た角度をロボットに送信することにより、ロボットに模倣を行わせる。 入力画像取得 距離計測 顔検出 人物領域抽出 関節点検出 関節角度計算 図 4-1 処理の流れ4.2.
三次元動作の取り込み
元 模倣するためには、三次元的な動きを捉える必要があるが、画 い を捉えようとした場合どのようにして情報を得るかが非常に大 き られている。 三 た、ロボットから得られる画像はカラー画像であるため、色情報を利用す ることが可能である。また、 本システムではこれらの多数の特徴を適4.3.
画像の補正
4.3.1. ロボットから得られる画像 ロボットのカメラから得られる画像 -2 に示す。得られる画像は解 像度 320×240 のカラー画像である。カメラの性能により、画像には歪が発生し ている。歪成分は、本来直線である 曲線になってしまう原因とな り、画像の端に行くほどその影響 くなる。また、左右の画像を見比べる 三次 動作を 像を用 て動き な問題となる。複数台のカメラを用いた場合はカメラの構成を工夫すること で比較的簡単に三次元情報を得ることができるが、一度カメラを配置してしま うとそこから動かすことができなくなってしまう。本システムではこのように カメラを特別に配置するのではなく、ロボット自身のカメラを用いて動作を撮 影し、その三次元情報を獲得する。 2 章でも述べたように、ロボットの頭部には 2 台のカメラが設置されている。 2 台のカメラの間隔は約 7cm であり、人間の目を模して取り付け 次元的な情報は、左カメラ画像と右カメラ画像の間の視差を利用することで 得ることができる。 ま 入力画像からエッジを抽出することも可能である。 所に適応することにより、人物の各関 節点をリアルタイムで抽出することを目指した。 の例を図 4 部分がゆがみ は大き (a) 左カメラ画像 (b) 右カメラ画像 図 4-2 カメラから得られる画像と、両 メラの方向がずれているこ 置が左 の画像でずれしまっている カ とがわかる。このため、画像中の人物の位 右 。このカメラの方向ずれは、視差画像を作 成 をT、回転成分をRとしたとき、基礎行列F は する際に大きな影響を与える。 4.3.2. エピポーラ線 左カメラ画像を基準として考えた場合、画像中のある一点に対応する点を右 カメラ画像上で探索する場合には、エピポーラ線の方程式を算出し、この線上 を探索すればよい。左カメラ、右カメラそれぞれの内部パラメータをAr、Al、左 カメラから右カメラへの平行移動成分 、
( )
−1 −1 r l T と表される。このとき = A TRA F ( 4-1 ) 、左カメラ画像上のある一点を(ul,vl)、その点に対応する 右カメラ画像上の一点を(ur,vr)とした場合、拡張ベクトルml、mrは次のように定 義される。 ) 1 , , ( ) 1 , , ( r r l l v u v u = = r l m m ( 4-2 ) この二つの拡張ベクトルは、基礎行列Fにより次のように結びつく。 0 = r lFm m ( 4-3 ) 関 一点に対応する右カメラ画像上の一点はあ る この 係から、左カメラ画像上の 線上に拘束されることがわかる。つまり、 ) , , (a b c = F ml ( 4-4 ) としたとき、 0 = + +bv c aur r ( 4-5 ) となり、対応点はこの直線上に存在することとなる。この対応点の位置を拘束 する直線のことをエピポーラ線と呼ぶ。 図 4-3 に顔の探索を行った場合のエピポーラ線を示す。これは左カメラ画像 上で求めた顔領域を表す矩形の左上の点に対するエピポーラ線を右カメラ画像 上に描画したものである。また、左カメラ画像で得られた顔領域から作成われ たテンプレートを用いてエピポーラ線上を探索し、類似度が最大となったとこ ろに矩形を描画した。探索の結果から、対応点が正確にエピポーラ線上に存在 していることがわかる。左カメラ画像と右カメラ画像の対応点がそれぞれ求ま れば、それらの点の位置の差分を取ることにより視差を求めることができる。このように、左カメラ画像上のある点に対し、右カ マッチングを行っては計算コストが非常に高くなる。そこで、 対応点の探索を容易にするために、左右の画像が平行になるように補正を行う。 こうすることにより、左カメラ画像上の一点の対 一の点から水平方向にだけずれた状態になる。画像の補正を行うことにより、 各 な計算 を行う必要がなくなる。 4. がある。キャリブレーションは各カメラの内部パラメータ、外部パラメータを 求める作業のことである。キャリブレーション結果 正を行うことができる。今回キャリブ レーションには SRI 社のキャリブレーションソフトを メラ画像上での対応点を 求めることにより、視差を得ることができる。また、この処理を各点に対し行 うことにより、視差画像を作成することができる。しかし、各点に対してエピ ポーラ線を求め、 応点は、右カメラ画像上の同 点に対してエピポーラ線の方程式を求める必要はなくなるため、無駄 3.3. キャリブレーション 画像を平行化するためには、左右のカメラのキャリブレーションを行う必要 から得られる各パラメータ を用いることにより、歪や方向ずれの補 用いた。図 4-4(a)、(b)、 (c)のようにキャリブレーションボードをさまざまな角度から撮影し、数パター (a) (b) (c) 図 4-4 キャリブレーションに用いた画像 (a) 左カメラ画像 (b) 右カメラ画像 図 4-3 顔探索を行った場合のエピポーラ線
ンの画像対を用いてキャリブレーションを行う。キャリブレーションではテス トパターンのコーナーを検出することにより左右のカメラの対応点を求め、対 応点のずれから各パラメータを計算する。 キャリブレーション結果として、各カメラの内部パラメータと外部パラメー タなどを得ることができる。内部パラメータAは、 ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ = 1 0 0 0 0 y y x x C f C f A ( 4-6 ) の形 x x y をそれぞれ 表している。外部 れる。 で表され、f ・f は焦点距離を、C ・C はカメラの光学中心の位置y パラメータEは、次に示す 3×4 の行列で表さ
( )
⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ = = z y x T R R R T R R R T R R R 33 32 31 23 22 21 13 12 11 T R E ( 4-7 ) ここで回転行列Rはx、y、zそれぞれの軸の回転角度をα、β、γとすると、 ⎟ ⎟ ⎟ ⎞ ⎜ ⎜ ⎜ ⎛ − ⎟ ⎟ ⎟ ⎞ ⎜ ⎜ ⎜ ⎛ ⎟ ⎟ ⎟ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ − = ⋅ ⋅ = γ γ β β α α α α sin cos 0 0 0 1 0 1 0 sin 0 cos 0 0 cos sin 0 sin cos z y x R R R R ⎠ ⎝ ⎠ ⎝−⎠ sinβ 0 cosβ 0 sinγ cosγ 1 0 ⎟ ⎞ + − α γ α β γ α γ γ β
αsin sin sin cos cos sin cos sin sin
⎟ ⎞ ⎜ ⎜ ⎜ ⎛ = 0 512 114.3494 889903 . 156 0 942482 . 325 ⎟ ⎟ ⎠ ⎜ ⎜ ⎝ − − + = γ β γ β β γ α γ β α γ β α γ α β α cos cos sin cos sin sin cos cos sin sin sin sin sin cos cos cos sin ( 4-8 ) と求められる。 図 4-4 から得られたキャリブレーションの結果である内部パラメータAr、Al及 び、外部パラメータEr、Elは、 ⎜
⎛cosαcosβ cos
⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ = 1 0 0 079331 . 116 531329 . 337 0 934394 . 160 0 493902 . 329 r A ⎟ ⎟ 22 974 . 332 l A ⎠ ⎝ 0 0 1
⎟ ⎟ ⎞ ⎛ − − − − − = 024764 . 4 9992014 . 0 0313262 . 0 0248055 . 0 066800 . 0 0296759 . 0 9974884 . 0 0643137 . 0 732876 . 71 0267579 . 0 0635263 . 0 9976214 . 0 E ⎜ ⎜ ⎜ ⎝ = 1 0 0 0 0 1 0 l E となった。ここで、外部パラメータは左カメラから見た右カメラのパラメータ また、キャリブレーションにより歪パラメータκ1、κ2が得られる。歪パラメ ータは画像中の歪みの補正に用いられる。画像中の一 (x,y)は、
(
)
⎟ ⎜ ⎜ ⎜ r ⎠ ⎝ ⎞ ⎛1 0 0 0 ⎟ ⎠ 0 ⎟ ⎟ として求められているため、左カメラの外部パラメータは回転、平行移動の成 分のない結果となる。 点(xd,yd)の歪補正後の座標(
)
(
)
(
2 4)
2 1 1 x d d x d C r r C y y= − +κ +κ + ( 4-9(
)
2(
)
2 2 2 1 4 2 1 y d x d d y d d y d C y C x r C r r C x x − + − = + + + − = κ κ ) で与えられる。 最後にこれらのパラメータを用いて、歪を補正された画像の平行等位化を行 う。左右のカメラのカメラ座標原点をOl、Or、とすると、 l r O O b b b x= , = − ( 4-10 ) 0 r r 0 l l r l r l z R z z R z z z z z zˆ , = −1 , = −1 + + = ( 4-11 ) z x x z z= ˆ−a , a= ⋅ˆ ( 4-12 ) x zˆ− a x z x z y × × = ( 4-13 ) ここで、bはカメラ間のベースラインであり、 =(0,0,1,1)T 0 z である。ここで求 められるzl、zrは二つのカメラ座標系における、z軸に平行なベクトルとなる。こ こで求められたx、y、zを用いて、左右の画像の並行等位化を行っ結果を図 4-5 示す。画面の端部分に顕著に現れていた歪みの影響が緩和されていることがわ かる。また、二つの画像が平行になっており、左画像の対応点が水平方向のみ に探索することで求められることがわかる。の三次元的な動きを再現するためには、三次元的な動きを読み取る 必要がある。また、人物の動きを読み取る前に、画像中から人物の存在する領 域を抜き出す必要がある。二次元システムで用いた や、背景に動物体が含まれる場合には対応しきれない。そこで、今回は人物領 域の抽出、及び三次元的な動きを捉えるために距離情報を用いた。距離情報は ることによって得ることができる。視差画像は複数台のカメ メラを用いて視差 画像の作成を行った。 本システムでは、左カメラ画像を基準とし、右カメラ画像上で対応点を発見 することにより視差を求めた。図 4-6 に探索のモデル図を示す。画像の補正に より画像は水平方向にのみずれた状態になっているので、視差 される。左カメラ画像においてxlの点でテンプレートを作成し、右カメラ画像の (a) 左補正画像 (b) 右補正画像
4.4.
視差画像の作成
人物の腕 背景差分では、複雑な背景 視差画像を作成す ラから得られる画像を用い、それぞれ対応点を求めることで作成される。本シ ステムでは、ロボットの目の部分に取り付けられた 2 台のカ 図 4-5 補正した画像 はx座標の差で表 対応点は水平方 x x 向上に存在 図 4-6 対応点の探索 水平方向上でマッチングを行う。対応点の検出には次の式で求められる、単純類似度Sを用いた。
∑ ∑
∑ ∑
∑ ∑
⋅ ⋅ = x y xy x y xy x y xy xy I T I T S ) , ( ) , ( ) , ( ) , ( ( 4-14 )T(x,y)はテンプレート画像の座標(x,y)における成分を、I(x,y)はマッチング対象の
(x,y)に相当する位置の成分をそれぞれ表している。探索した領域の中で類似度が xr 本 ことが前提条 件として考えられる。そのため、ユーザがロボットから 1.0~1.5m の領域にいる 差を 10%程度に抑えることを目 指した。 画像 最大となる点を対応点とした。検出された対応点のx座標をxrとすると視差はxl -で求められる。 一般に視差画像は、物体がカメラからの距離が離れるほど、精度が悪くなる。 システムでは、ユーザはロボットに対し、動作を例示している と仮定し、この領域で奥行き方向の距離推定誤 4.4.1. 原画像サイズの視差 視差画像を作成するために、最初にカラー画像である入力画像を濃淡画像に 変換する。次に左画像の微小領域からテンプレートを作成し、右画像上でマッ チングを行う。マッチング結果の x 座標の差を視差として視差画像の作成を行 う。作成した視差画像を図 4-7 に示す。 視差画像では視差が大きな領域は白くなり、視差が小さな領域は黒くなるよ うに表している。つまり、ロボットに近い領域ほど白く、遠い領域ほど黒く表 す。人物が前に伸ばした手の部分が、段階的に白くなっていることから、人物 領域の視差がほぼ正確に求められていることがわかる。図のように正確に視差 画像は求められているが、原画像サイズで視差画像を求めた場合処理時間が長 図 4-7 視差画像(320×240)
く、一枚の画像を処理するのに約 8 秒を要した。これではシステム全体として 大きなボトルネックとなってしまうため、視差画像の作成をより短時間で行う 必要がある。 4.4.2. 低解像度化による高速化 値が小さくなるため、三次元位置の計算精度が落ちてしまう。 解 4-8 では腕の部分の視差の変化が少なく、また他の視差画像に比べ、 局地的な誤差が目立っている。また、低解像度化したため、背景と人物領域と の ている。 4.4.3. 視差画像の作成を高速化する場合、もっとも大きな効果が期待できるのは、 処理する画像の解像度を下げることである。解像度を 4 分の 1 に下げた場合、 探索範囲が単純に 4 分の 1 となるため、高速化が見込める。しかし、解像度を 落とすと、視差の 像度を 4 分の 1 に下げた場合は、計算精度は半分に低下する。 これらを踏まえた上で、解像度を 4 分の 1 に下げた場合と 16 分の 1 に下げた 場合の視差を求めた。この結果を図 4-9 及び図 4-8 に示す。図 4-9 では人物の 腕の視差の変化がしっかり表れており、比較的に良好な視差画像が作成できて いる。図 の視差 差が小さくなってしまっ これらの結果から、処理時間、計算精度的に妥当であると思われる解像度 4 分の 1 の視差画像を用いて以降のシステムを構築した。 テンプレートサイズの決定 図 4-9 解像度 視差画像 4 分の 1 (160×120) 図 4-8 解像度 16 視差画像(80× 分の 1 60)
(a) 4×4 (b) 6×6 (c) 8×8 (d) 10×10 (e) 12×12 図 4-10 テンプレートサイズを変えた場合の変化 視差画像を作成するに場合、精度に大きな影響を与える要因の一つとしてテ ンプレートのサイズがあげられる。テンプレートのサイズが小さいほどきめが 細 トサイズを大きくし 荒い視差画像が作成される。そこで、 て、作成される視差画像の比較を行っ に示す。 では人物領域の輪郭が他と比べはっきりとしている。 エラーが多数あることが目立つ。サイ ズを の時に比べ、腹部のマッチングエラーが小さくなっ さな抜けの部分が修正されていること がわ 見比べると、 ている。 8×8 以 部の領域のエラ なっている。 これらのサイズではエラーは少なくなるが、その反面背景領域が視差画像に多 く表れている。また、視差画像中の人物領域の大きさが、大きくなってきてお 確 まっている。特に 12×12 の場合、首や脇の 部 かい視差画像を作成することができるが、領域を小さくしすぎると特徴が少 ないため、マッチングの失敗が増えてしまう。テンプレー た場合はマッチングの成功率は上がるが、 テンプレートサイズを数段階に変化させ た。作成した視差画像を図 4-10 テンプレートサイズ 4×4 しかし、特に腹部あたりにマッチングの 6×6 にした場合、4×4 ている。また、人物領域の中にあった小 かる。しかし、他の画像と 腹部のエラーがまだ目立っ ーがほぼ目立たなく 上のサイズでは、この腹 り、正 な輪郭が表れなくなってし 分でこれが顕著に表れている。 これらの結果から、本システムではテンプレートサイズとして 8×8 を用いる ことに決定した。このサイズではテンプレートサイズが小さいときに現れる微 小領域の穴抜けや、マッチングエラーをある程度防ぐことができ、テンプレー トサイズが大きいときに現れる人物領域及び背景領域の拡大を防ぐことができ
ている。8×8 のテンプレートを用いて、ロボットから 100cm 及び 200cm の距離 に人物が立った場合の視差画像を図 4-11 に示す。 に (a) 100cm 原画像 (b) 200cm 原画像 (c) 100cm 視差画像 (d) 200cm 視差画像 図 4-11 各距離の視差画像 ステレオ視の特性上、カメラから近い部分では奥行き精度は向上し、カメラ から離れるほど精度は低下する。このため、100cm の位置に人物が立った場合 は、手の視差の変化が大きく、200cm の位置に立った場合は、全体的に視差が 小さく、人物が両手を前に出しても他の距離に比べて変化が少なくなっている ことがわかる。
4.5.
人物領域検出
視差画像を求めた後に、人物領域の抽出を行う。人物領域はロボットからの 距離によって切り出しを行う。人物が立っている距離を計測するために、最初 人物の顔を検出する。顔の検出にはテンプレートマッチングを用いた。今回 はユーザを 1 人に限定したため、あらかじめユーザの顔を用いてテンプレート を作成しておき、入力画像とマッチングを行うことにより検出を行う。示するために、ロボットからある程度の距離にいると予想で きる。このため、ロボットから距離が遠い領域、すなわち視差の小さい領域に は人物はいることがないと考えられる。 の点の視差は D はベースライン b、焦点距離 f を用いて、 テンプレートマッチングを行う際に、探索範囲の絞込みを行う。ユーザはロ ボットに動作を例 ロボットから 1.5m 942597 . 7 1500 08696 . 166 732876 . 71 1500 = × − = = bf D ( 4-15 ) となる。人物がロボットから 1.5m の位置にいると仮定した場合、この視差より も視差が小さい領域を青色に塗りつぶした結果が図 4-12 である。これらの領域 は探 の 全体の探 索 顔の検出を行った後に、視差画像から人物領域の抽出を行う。人物領域は検 索範囲から外れる領域である。これら 領域を除いた場合、画像 図 4-12 探索領域の絞込み 図 4-13 顔検出結果 に比べ約半分の探索範囲に絞ることができている。 探索範囲の絞込みを行い、顔探索を行った結果を図 4-13 に示す。図中の十字 の位置が検出された顔位置である。顔位置が正確に検出できていることがわか る。
出された顔位置に連結している領域であ 前方 70cm り、ロボットからの距離が顔位置から までの領域とした。これは図 4-14 に示すように、人の腕の長さが約 4-10(c) 背景領域を除 る。また、画像中に数箇所存在する白 いマッチングエラー部分も除去することができている。
4.6.
関節点検出
出を行う。手位置は肌色抽出と人物 領域を用いて検出を行う。 積 70cm であるため、腕を前に伸ばした状態での長さを考慮したものである。図 から人物領域の抽出を行った結果を図 4-15 に示す。 図 4-15 人物領域抽出結果70c
70c
(a) 上から見た図 (b) 横から見た図 図 4-14 人物の腕の長さ いて人 物領域のみが抽出できていることがわか 人物領域が抽出されたら、各関節点の検 図 4-5(a)から肌色領域を抽出した結果を図 4-16 に示 す。抽出された肌色領域と人物領域を比較し、人物領域上にない肌色領域を削 除する。また、残った肌色領域の中で最大面 となるのが顔領域であるため、 この領域も手の候補領域からはずされる。こうして残った手の候補領域を、図4-17 に示す。手候補領域が 2 つ以上存在した場合は、上位 2 つの面積の領域を 候補領域として絞り込む。左右の手の決定は顔に対する相対的な位置により決 定している。顔領域の左側に位置してい 手位置の検出の後に、首位置、肩位置の 画像と人物モデルを用いて決定される。図 4-15 る領域が右手、右側に位置している領 域が左手とした。 検出を行う。これらの点は距離変換 を用いて作成した距離変換画像 図 4-16 肌色領域抽出結果 図 4-17 手候補領域 を図 4-18 に示す。検出された顔位置から顔-首間の長さを用いて首を、またこれ により検出された首位置から首-肩間の長さを用いて左右の肩の検出を行う。人 物モデルは二次元システムで用いたものと同様のものを用いた。 各点の検出結果を図 4-19 に示す。それぞれの点がほぼ正確に検出できている ことがわかる。
図 4-18 距離変換画像 図 4-19 関節点検出結果
4.7.
動作例
本システムの動作例を図 4-20 に示す。図中左の列にはロボットの左カメラか ら得られた入力画像を、右の列には入力画像を用いて模倣を行った結果を示す。 本システムは Pentium4 3.6G 秒間に約 1 枚の画像を処理し て動作を模倣している。図中の人物の動きとロボットの動きを見比べると、ほ ぼ Hz のパソコン上で、1 人物の動きを再現できていることがわかる。入力画像 1 (b) 模倣動 (a) 作 1 入力画像 2 (d) 模倣動 (c) 作 2 (e) 入力画像 3 (f) 模倣動作 3 (g) 入力画像 4 (h) 模倣動作 4 図 4-20 三次元動作模倣の動作例
4.8.
た。 える。 る。 である。 4.8.1. 図 4-21 ある。 なる。システムの高速化
これまでのシステムにより、ロボットが人物の動きを模倣することに成功し しかし、1 秒間に 1 枚のみの画像を処理している状態ではリアルタイムで模 倣しているとはいいがたい。ロボットに制御命令が送信されるのは 1 秒刻みで あるため、推定に間違いが発生した場合、ロボットはこれを忠実に再現してし まう。このような動作を防ぐには、数枚の推定の結果を用いてその平均のデー タをとるなどしてある程度防ぐことが可能であるが、そのためにはシステムを より高速で動作させる必要が出てくる。 本システムにおいて処理時間を最も要するのは視差画像の作成である。処理 時間を短縮するには、視差画像の作成を高速化することがもっとも効果的とい 4.4.2 で述べたように、視差画像を低解像度にした場合、高速で作成する ことが可能である。しかし、低解像度の視差画像では、模倣を行うために十分 な奥行き精度を得ることができない。ただし、低解像度の視差画像においても、 人物領域と背景領域の間には明確な視差の差がある。そこで本節では、多重解 像度戦略を用いて視差画像を作成し、システムの高速化する手法について述べ 多重解像度戦略とは、最初に低解像度の視差画像を作成し、作成された低解 像度視差画像を元に高解像度の視差画像を作成するものである。低解像度の視 差画像は、精度が悪いものの高速で作成することができる。よってこの低解像 度の視差画像の情報を元に高解像度の視差画像を作成すれば、対応点の探索範 囲の絞込みが容易に行うことができ、視差画像作成の高速化を図ることが可能 低解像度視差画像の作成 4-5 の補正画像を解像度 40×30 まで低解像度化して作成した視差画像を図 に示す。図を見ると、マッチングのミスが非常に多いことがわかる。低解 像度視差画像の作成において重要となることは、できる限り誤差が少ない視差 画像を作成することである。これは、この視差画像を元に高解像度の視差画像 が作成されるため、最初に誤差があった場合この誤差が蓄積してしまうためで つまり、図 4-21 を用いて作成された高解像度の視差画像は、エラーを大 量に含んだものになってしまう。これでは視差画像を高速に作成できたとして も、各関節点の距離に誤差が多く含まれ、正確に動作を模倣することは難しく このようにこれまでの手法を用いて作成した低解像度視差画像を用いた場合、図 4-21 視差画像 (40x30) す 向面に分割した すため、四方向面に分割せずに解像度 を 誤差が大量に発生し、精度の良い視差画像を得ることは難しい。多重解像度 を用いて精度を向上するためには、低解像度でのマッチングのエラーを少なく る必要がある。そこで、低解像度でのマッチングに強い四方向面特徴[10]を用 いて低解像度視差画像の作成を行った。 四方向面特徴は文字認識や人物認識の分野でよく用いられている特徴の一つ であり、ある画像に対し、水平、垂直、右上がり、右下がりの四方向のエッジ 強度を求め、これを濃淡特徴とするものである。得られた各方向の特徴に対し、 ガウシャンフィルタと低解像度化を行うことにより、特徴を低解像度化してい き、この低解像度化された特徴を用いてマッチングを行うものである。エッジ を四方 後に解像度を落と 落とす方法よりも高解像度でのエッジ情報が残されている。四方向面特徴の 長所として、 ・低解像度でのマッチングに強い ・ある程度のサイズ、位置ずれを吸収する 図 4-22 入力画像
があげられるが、今回はこの低解像度に強いという点を用いている。 4-22 に左カメラから得られた入力画像を、また図 4-23 にこの入力画像か 図 図 4-23 四方向面特徴 (a) 水平 (b) 垂直 (c) 右上がり (d) 右下がり (a) 水平 (b) 垂直 (c) 右上がり (d) 右下がり 図 4-24 低解像度化された四方向面特徴(40×30)
ら得られる四方向面特徴を示す。得られた各エッジ画像に対しガウシャンフィ ル ッチングを行う。マッチングの際には次の式で求められる類似度 s を用いて対応 点を検出する。 タと低解像度化を行い、右目画像から同様にして得られる四方向面特徴とマ

![図 4-21 視差画像 (40x30) す 向面に分割した すため、四方向面に分割せずに解像度 を 誤差が大量に発生し、精度の良い視差画像を得ることは難しい。多重解像度を用いて精度を向上するためには、低解像度でのマッチングのエラーを少なくる必要がある。そこで、低解像度でのマッチングに強い四方向面特徴[10]を用いて低解像度視差画像の作成を行った。四方向面特徴は文字認識や人物認識の分野でよく用いられている特徴の一つであり、ある画像に対し、水平、垂直、右上がり、右下がりの四方向のエッジ強度を求め、これを濃淡](https://thumb-ap.123doks.com/thumbv2/123deta/10087742.1488841/44.892.343.536.145.352/難しいマッチングエラー少なくるマッチングに対し四方向エッジ.webp)


