7.
自己組織化マップ
本章では,臨床症例文書の疾患系分類を目的とした文書クラスタリングのもう一つの手法とし て,競合学習型ニューラルネットワークモデルの一つである自己組織マップを取り上げる.自己 組織化マップによる文書クラスタリングシステムを実装し,疾患系分類性能について評価する. また,アソシアトロンとの比較を行う.7.1 自己組織化マップ(
Self-Organizing Map)
の基礎理論
自己組織化マップ(SOM)[40], [42]は,トポロジカルマッピング[60]を拡張した教師なし競合学習型ニ ューラルネットであり,入力層とマップ(出力)層の2層構造をなす.また,データ間の特徴類似度に よる汎用的なクラスタリング能 力 を持つ .SOM を用いた文書情報検索 システムとしては, WEBSOM[12], [14], [16], [25]-[27], [31], [46]-[47], [49], [51]が知られている. SOM モデルは,入力層では n 個,マップ層では2次元的に配列されたm 個のニューロンからな る.入力層とマップ層の各ニューロンは全結合であり,それらの結合荷重は,m×n 行列で表現され る. 今,j 番目の n 次元入力ベクトルをxj,i 番目の重みベクトルをwiとすると,ベクトル間のユークリ ッド距離wi−xj を最小とする組をk とすると,SOM アルゴリズムによる重みベクトルwkの更新は次 式で示される. k old k j old k new k w (x w )z w = +α − (7.1) αは「学習率」と呼ばれ,学習回数t の単調減少関数である.Z は競合作用値であり,k に一致し た場合のみ1,それ以外では 0 を与える. 実際の学習では,k 番目のニューロンの幾何学的近傍についても式(7.1)を適用し,重み更新を 行う.7.2 統計的手法による臨床症例文書の特徴量抽出
SOM は,トポロジカルマッピングを拡張した教師なし競合学習型ニューラルネットワークであり,入 力層とマップ(出力)層の2層構造をなす.マップは通常,直角格子状に配置された2 次元ニューロ ン・ユニット(neuron unit)で表現される.ここで直角格子の1マスを簡単にセル(cell)と呼ぶ.また, データ間の特徴類似度による汎用的なクラスタリング能力を持つ.SOM を用いた文書情報検索シ ステムとしては,WEBSOM が知られている. 症例文書を疾患系毎に分類するために,SOM アルゴリズムを適用する.SOM への入力ベクトル は,2.2 で述べた医学用語の頻度順リスト(高頻度優先)から生成する. 実際には,系分類済みの症例サンプル(学習用データ)から,それぞれの頻度順リストを取得し, これらを合計した全体頻度順リストによる順位により入力ベクトルを求める. 以下,この手順を定式化する. 入力となる症例文書からm 個の異なり単語 wiが抽出され,その単語頻度がniであるとすると,単 語頻度取得関数をFreq として,頻度順リストL は次式で定義される.[
w
w
w
m]
L
≡
1,
2,
L
,
(7.2)( )
i m iFreq
w
n
n
n
n
=
,
1≥
2≥
L
≥
(7.3) また,頻度順リストの異なり単語頻度を再集計する関数をUniq とすると,N 文書からなる全体頻 度順リストLallは,次式のようになる.[
]
all j all i all n all all N k k all w w w w w L Uniq L ≠ = ≡ = , , , , 2 1 1 LU
(7.4) 今,Lallに含まれる単語wiが頻度順リストL に含まれる単語 wrに一致した場合の頻度nrを求め る関数SearchKeyOrder を次式で定義する.(
)
( )
∉
∈
=
=
∈
=
)
(
0
)
(
)
(
,
,
L
w
if
L
w
w
if
w
Freq
L
w
L
w
rder
SearchKeyO
n
i r i r all i i r (7.5) SOM 学習のための入力ベクトル x は,次式となる.∑
==
=
m k k r i nn
n
x
x
x
x
1 2 1,
,
),
(
L
x
(7.6) 次に,この入力ベクトルで学習したマップ上に配置された同一系に含まれるサンプル点の座標 si と,任意セルの座標s とから系毎の平均ユークリッド距離 d を求める.平均距離が最小となる疾患系 がその任意セルを占有すると考え,マップ全体の系領域を決定する. 疾患系Z(=C:循環器系 or R:呼吸器系 or D:消化器系)のサンプル点の個数がn 個である場合, 距離関数dzを次式で定義する.( )
∑
= − = n i i Z n d 1 1 s s s (7.7) 領域決定関数Cluster は次式となる.( )
( )
( )
= = = = ) ( " " ) ( " " ) ( " " ) ( min min min s s s s D R C d d if D d d if R d d if C Cluster (7.8) 以上から,任意の入力ベクトルが新たにマップに配置された時点で,その入力点が属する系を判 定することができるようになる.この操作手順がSOM 計算部分となる. システムによる処理をFig.7-1 にまとめる.◇診断 ............... ............. ◇現病歴 ............. ............... ◇現症 .... ............... ................... ◇入院時検査所見 ....................... ....................... All :: (Uniqs/Words :: 774/1121 = 0.690) 14 0.012 "高血圧" 13 0.012 "心不全" 11 0.010 "発熱" 11 0.010 "浮腫" 8 0.007 "血沈" 7 0.006 "胸部 CT" 7 0.006 "手術" 7 0.006 "血糖" 6 0.005 "腫大" "n019.txt::過敏性肺臓炎" 0.0000 0.0000 0.0153 0.0000 0.0000 0.0153 0.0153 0.0000 0.0000 0.0000 0.0076 0.0458 0.0000 0.0000 0.0000 0.0000 0.0153 0.0382 0.0382 0.0229 0.0000 0.0229 0.0000 0.0000 0.0000 " n015.txt::糖尿病" 0.0106 0.0000 0.0000 0.0000 0.1064 0.0106 0.0000 0.0000 0.0426 0.0106 0.0000 0.0000 0.0213 0.0319 0.0106 0.0000 0.0000 0.0000 0.0000 0.0024 0.0426 0.0000 0.0000 0.0000 0.0000 Clinical Cases in Japanese
Heuristic Extraction & Accounting
Medical Keywords in Cases
Creating Matrix of Attributes
for SOM Learning
Creating Map & Plotting
Each Cases on the Map
Clustering with SOM
to three Domains
-Circulatory
-Respiratory
-Digestive
a)
b)
c)
d)
e)
Fig.7-1 Clustering process with NLP and SOM
a) Clinical cases in Japanese, b) List of unique medical keywords sorted with its own frequency, c) Matrix of attributes to input, d) Self-organizing feature map for document clustering, e) 3-domain clustering
Fig.7-1 について補足する. 最初に,日本語で記述された症例文書(a)からキーワード(医学関連用語候補)の抽出,頻度計 数を行って,頻度順リスト(b)を作成する(2.3 参照).次に,全体頻度順リストからSOM への入力ベ クトル(c)を求め,SOM 学習を経て疾患系分類用マップ(d)を得る.ここでは,初期学習用分類済 みデータを用いることで,3疾患系領域(e)を計算できる.
7.3 クラスタリングシステムの実装
症例クラスタリングでは,症例文書から得られた情報を元に,入力ベクトルを生成し,これらに SOM アルゴリズムを適用してマップを生成することで,症例文書そのものを3疾患系(①循環器系, ②消化器系,③呼吸器系)毎に分類するものである[66], [68], [70]. 基本システム構成を Fig.7-2 に示す.SOM
Engine
Searching & Browsing Engine
Visualization Engine
Full-text
Clinical Case
Database
Biometrics Authentication
Database
Attribute Manager
User Interface
Attribute & Index
Database
Documents
Fig.7-2 Basic System Construction
システム(Fig.7-2)は,マップ生成のための SOM エンジンを中心に,情報視覚化エンジン (Visualization Engine),データ検索・閲覧エンジン(Searching & Browsing Engine),属性管 理ツール(Attribute Manager)およびこれらを統合するユーザインタフェース部(User Interface) から構成される.
属性管理ツールは,症例文書の全文データベース(Full-text Clinical Case Database)とリンク した文書属性およびインデキシング情報データベース(Attribute & Index Database)を制御す る. システム構成的にみると,マップ生成のための SOM エンジン,視覚化エンジン,およびユーザイ ンタフェースについては,臨床症例以外の対象についてもそのまま利用することができると考えられ る. そこで,システムの汎用化と拡張を以下の4 つのフェーズに分けてそれぞれ検討する. ① 情報抽出 ② 入力ベクトルの構成 ③ SOM アルゴリズムの適用 ④ 情報視覚化およびクラスタリング結果提示 7.3.1 汎用化と拡張性の向上 SOM クラスタリングを利用した臨床症例文書の自動分類を行う上で,情報抽出および属性ベクト ル生成というフェーズに着目した場合,これらの汎用化と拡張性の向上を重視すべきである.このた めには,各種パラメータのチューニングを自由に行えるツールの提供が必要不可欠となる. 7.3.2 情報抽出 臨床症例を扱う場合は,各症例文書から自然言語処理的なアプローチにより,キーワードと見な せる単語を自動抽出する(Fig.7-3 参照).最終的には,これらの出現頻度から出現確率を求め, SOM の入力ベクトルを構成することになる.
Word List
Word 1
Word 2
Word n
Clinical Case
Word
List
Word
List
Word
List
Word
List
Word
List
Allow Word
Dictionary
Deny Word
Dictionary
Word Selector
Heuristic
Word
Dictionary
単語抽出におけるフィルタリング処理としては,特定の用語を積極的に抽出するための辞書照合, 逆に特定の用語を排除するための辞書照合を考えることができる. 通常,前者は医学関連用語辞書,後者は一般用語辞書を用いることで対応することができるが, 形態素解析(字句解析)や辞書照合の負荷を軽減する場合は,文字種別によるヒューリスティクスを 用いる方法を筆者は既に提案している[73]-[76]. 頻度情報の文脈的な抽出(文字,あるいは語などの連接共起情報の抽出)を行う場合は,形態素 解析におけるn-gram を用いることで対応できる.一般に,n は 3 程度までであり,n=1 の場合, uni-gram と呼び,単語出現確率に一致する.n=2 の場合を bi-gram,n=3 の場合を tri-gram と 呼び,n 個連接した単語(形態素)の組をエントリと考えて,頻度(出現確率)を求める方法である.こ のn-gram 方式を用いる場合は,対象となる文書量が比較的大きいものである必要がある(Fig.7-4 参照).
w
0
w
1
w
2
w
3
w
4
w
5
bi-gram
tri-gram
word
(uni-gram)
Fig.7-4 N-gram for keywords
7.3.3 入力ベクトルの構成 基本的に,入力層に与えるデータ群は,数量化された任意の属性値からなるベクトル表現であれ ば,SOM によるクラスタリングマップを生成することが可能である(Fig.7-5 参照). 実際に試みたクラスタリングマップ生成のための属性値(医療関連データ)の例としては以下のも のがある. ① 症例文書中の医学間連用語の出現頻度 ② 肝機能血液検査結果の数値データ ③ 胃内視鏡画像診断の医師所見に基づく数量化データ ④ 腹部超音波診断の医師所見に基づく数量化データ
Input Layer
Input Vector(
n-dimension)
Mapping Layer
Attribute Value
Fig.7-5 Data mapping of input vectors (n - dimension)
7.3.4 属性値の正規化・標準化 上記①のように,頻度データを扱う場合は,実際には,出現確率や共起確率を求める必要がある. それ以外の数値データや数量化データは種類の異なるものを混在させる場合,特定の属性値の影 響を抑えるために,正規化・標準化を施す必要がある. 単純な正規化の例としては,同一属性内の相対的な割合としてパーセント値を用いる方法がある. あるいは,特定のレンジ内に振り分ける一次変換を考えることもできる.更に,属性の2値化を行うこ とにより,論理型として扱うことも可能である. 多くの場合,各属性のレンジオーダーを揃えた方が良いが,ある属性値が他の属性値に対して独
立でない場合,予想通りのクラスタリング結果とならない場合がある. このように,SOM のクラスタリング性能を左右する最も重要なパラメータが属性ベクトルであり,こ の属性値のチューニングを簡便に行うためのツールが必要不可欠となる. 7.3.5 属性の選択と入力層への投入順序 汎用データを扱う場合,クラスタリングを行うべきデータと属性値との対応付けが重要である (Fig.7-6 参照). 属性数が多いと,SOM 学習に要する時間が長くなるため,全データフィールドから属性を取捨選 択できた方が良い.属性の順列に関しては,学習への影響はないと考えられるが,入力ベクトルの 把握を行うのは,ユーザであるため,インタフェース設計としては,並びが可変である方が良い. また,SOM 学習に関わる属性値の投入順序は,一般にはランダムに行われるが,これをあらかじ めグループ化されたデータ毎に投入する方法や,グループを循環させてシーケンシャルに投入する 方法など,SOM 入力層へのベクトル投入に関するいくつかのバリエーションを考えることができる.
Field #0
Labels
Data Sets
Field #1
Field #n-1
A
0A
1A
2A
m-1Attributes
n
m
≤
7.3.6 SOM アルゴリズムの適用 SOM アルゴリズムの適用部分では,学習回数,マップサイズというパラメータの他に,学習率曲線, 近傍判定曲線の選択が可能である方が良い.これは,生成されたマップの良さを比べる上で必要な 機能となる. 近傍モデルに関しては,マップ上のセル形状により,主に正方形や正六角形が用いられる (Fig.7-7 参照).
t
α
t
t
α
α
t
r
t
t
r
r
Exponential
Linear
Inverse
Proportional
Exponential
Linear
Inverse
Proportional
Learning rate
Neighborhood
Square
Hexagon
7.3.7 情報視覚化およびクラスタリング結果提示 マップ部分を階層構造化することでさまざまな情報提示が可能となる.ノードへのラベル付け,クラ スタリング領域のカラー化,属性強度のカラー化,同一セルへマッピングされたノードの個数などが 独立のレイヤーで操作できる方が良い(Fig.7-8 参照).
Mesh Layer
Coloring Layer II
Coloring Layer I
SOM Layer
Label Layer
Frequency Layer
Fig.7-8 Display layers for SOM viewing
この他,情報視覚化については,3 次元的なマップ表示や画面操作インタフェースが望ましいと 考えられるが,現行のシステム設計ではそこまで対応していない.
実装システムは,臨床症例文書の類似度による疾患系分類,および分類結果としての2 次元マッ プの表示を最大の目的としている.従って,現在のシステムは,SOM の分類性能を評価するために, SOM 学習条件の設定を行う各種 GUI コントロールが用意されている(Fig.7-9 参照).
また,症例文書の分類結果を簡単に把握できるよう情報の視覚化という点でマップ表示を工夫し ている.また同時に,直観的な検索インタフェースへの応用として,マップ状の領域をマウスで範囲 選択する検索方式についても検討した.これら詳細については,2.6 で詳しく述べる.
システムは Java 言語により実装されており,先に示した通り,NLP 部(クラス数:5, ソース行数: 680),および SOM 部(クラス数:5, ソース行数:1252)からなる.
Fig.7-9 は,一般的なブラウザからJava アプレットを起動した画面(計算条件:マップサイズ 80× 80,学習回数 800,属性数 30,入力ベクトル数 10)である. 図中,ウィンドウのクライアント領域上半分に示された各種コントロールが,計算条件を設定するイ ンタフェースになっており,画面下半分に計算結果としてマップが表示される. SOM 学習によりマッピングされた症例文書は高輝度のピクセルとして表示され,マップ全体につ いて,3疾患系毎に色分けされた領域を確認することができる.この領域がクラスタリング領域となる. クラスタリング領域はグラデーション表示されており,同一疾患系に含まれる症例文書の配置点の重 心から辺縁部に向けて輝度が徐々に下がっていく.この減少率は,インタフェースのBrightness 値 およびContrast 値で指定することができる. 7.3.8 情報抽出・属性ベクトル生成ツール 臨床症例クラスタリングにおける属性ベクトルは,元の症例報告文書に出現する医学関連用語 (キーワード)の出現頻度が元になっている.そこで,以下のようなチューニングのための重み変化 (①∼④)を行える情報抽出・属性ベクトル生成ツールを試作した. ① 定数バイアス ② 定数倍 ③ キーワードの文書間共有数倍 ④ 文書内頻度順位倍 システムはC++言語によりUNIX サーバ上に CGI アプリケーションとして実装した.これによりク ライアント側は一般的なブラウザのみで実行が可能となる.プログラムは,以下の3つの部分から構 成される. ① 自然言語処理部 ② CGI インタフェース部 ③ 入力ベクトル生成部 プログラムソースの規模は,自然言語処理部(上記①)816 行,CGI インタフェース部(上記②) 1,581 行,入力ベクトル生成部(上記③)1,099 行であり,合計 3,496 行となる. 本ツールの動作画面例として,入力インタフェース画面,抽出結果表示画面,入力ベクトル生成 画面をそれぞれ,Fig.7-10, Fig.7-11,および Fig.7-12 に示す.
Fig.7-10 Document browsing & Configuration of keyword extraction Fig.7-10 に示した画面は,文書ファイルの内容確認を行うためのブラウジングダイアログとして機 能する一方,キーワード抽出条件の指定ダイアログとしても機能する.抽出条件には,臨床症例文 書用の医学関連用語抽出フラグ(画面「BODY 優先」チェックボックス)のほか,文書中の自立語成 分として「英字優先」,「数字優先」,「カタカナ優先」のフラグ指定が可能である.これらは,症例文書 内の検査項目および検査結果に関する表記に対して効果的である.
また,特定文字,もしくは 特定語句をNG ワードとして外部ファイルに登録しておき,これらを排除 するための「NG ワード」フラグの指定ができる.
さらに,ノイズ除去のための「文字列長」フィルタ,および「頻度」フィルタを備えている.前者は,1 文字の自立語成分をカットする.後者は出現頻度1のものをカットする.
Fig.7-12 Created Input Vectors Fig.7-11,および Fig.7-12に示した画面は,結果表示例である.Fig.7-10の実行ボタンをクリック することで,自動抽出されたキーワードリストを提示するとともに,最終的には各キーワードリストから 出現確率を算出することで,SOM 学習用の入力ベクトルの生成結果を表示する. Fig.7-11 の先頭に表示されている部分がHTML リンクによるショートカットメニューになっている. ここをクリックすることで,ユーザは特定の結果画面を迅速に表示することができる.
入力ベクトルは,Fig.7-12 に示したように,HTML におけるフォーム(FORM)タグ系のテキストエ リア(<TEXTAREA>∼</TEXTAREA>)を利用して内容表示を行っているので,ユーザは入力ベ クトルの再編集が簡単にできる.また,ユーザはコピー&ペーストを利用することができるため,エデ ィタなど他のアプリケーションとの連携も容易である.
7.4 SOM を利用した検索インタフェース
SOM により分類されるデータは,n次元入力ベクトルの属性値により類似度が判定され,距離的 な近さとして 2 次元マップ上にプロットされる.また,本システムの疾患系分類では,マップを3領域 に分割する. 分類結果を検討するためには,情報の視覚化が重要である. 症例文書を疾患系毎に分類する方法には,①疾患系への平均距離の最小値から判定する方法, ②SOM 学習の重み行列の値から判定する方法の2つが考えられる.前者(①)は,分類済みの学 習用データが必須となる.また,後者(②)は,入力ベクトルのどの属性を用いるかにより結果が変わ ってくる. 前者(①)により領域決定を行って,視覚化したマップの表示例を Fig.7-13 に,また,後者(②)により視覚化したマップの表示例をFig.7-14 に示す. これらは共に同一のデータ群を用いており,具体的には,3 疾患系×15 文書=45 文書を学習用 データとし,各文書からそれぞれ30 個のキーワードを抽出し,5,000 回の学習をさせた場合である.Fig.7-13 A SOM-map colorized by the minimum distance Fig.7-14 は,学習完了時点での重み行列のうち,分散値が高い属性値をそれぞれ R, G, B に対 応させて表示したものである. 検索では,ある症例に類似したいくつかの症例を選択することが目的となる.筆者は既に,自然 言語による任意文章検索方式,および症例文書そのものによる類似検索方式については提案を行 っているので,本節では,より直観的なインタフェースとしてマウス操作だけで行える検索について 提案する. よって,SOM マップの領域をマウスでドラッグ(drag)して円形に範囲指定し,その領域に含まれ るプロット点をマップから読み出す方式を採用した. 現在の実装では,円形領域の範囲指定により類似症例を選択・閲覧することができる.また,複数 の円形領域のAND 検索,OR 検索などへの対応も可能である.
Fig.7-13, Fig.7-14 における円領域は,マウスで指定した範囲である.円領域の指定は,マップ 上の任意の点をクリックすることで,円の中心が指定されたこととなり,そのままボタンを離さずにマウ スを移動することで,円の半径を指定することができ,ボタンを離すとその円領域が決定される.円 領域の決定と同時に,そこに含まれる症例文書がデータベースから検索・抽出され,ユーザは文書 名を選択することで,登録文書内容を閲覧することができる.
Fig.7-14 A SOM-map colorized by weight values
SOM マップの見方について補足する. 症例文書は,高輝度のピクセルで表示される.ピクセル周辺には症例文書から自動抽出されたキ ーワードのうち,頻度が最も高い語がラベルとして付される.また,背景色は分類境界を視覚化した ものであり,症例がプロットされている領域を容易に把握することができる.これにより,ユーザは,特 定の症例に関連する領域と範囲を指定することができる. キーワード検索方式と本方式とを併用することで類似症例検索がさらに容易となると思われる.
7.5 症例文書クラスタリング実験
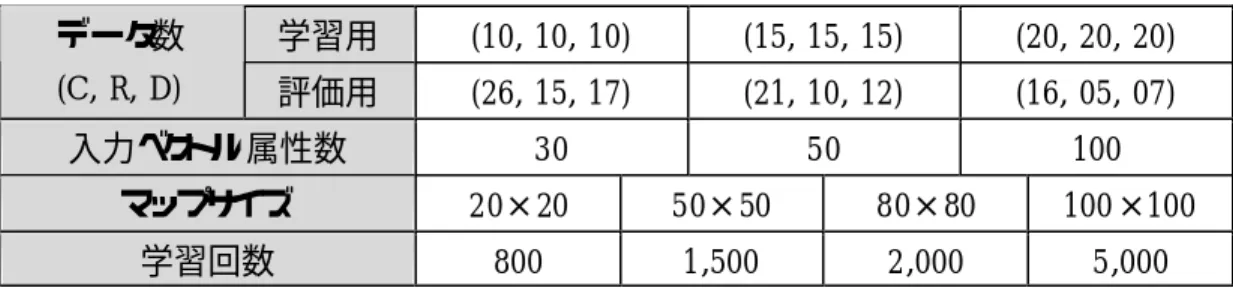
SOM による系分類の性能評価を目的として,以下の評価実験を行った. 7.5.1 方法 臨床症例報告書88 件をあらかじめ人手により3系(循環器系:C, 呼吸器系:R, 消化器系:D)に 分類する.さらに,それぞれの系に属するデータをデータサイズ順に整列後,学習用,および評価 用に2分する.学習用データが(C, R, D)=(10, 10, 10), (15, 15, 15), (20, 20, 20) のそれぞれの場 合について,サイズ(縦×横)がそれぞれ,20×20, 50×50, 80×80, 100×100 の SOM マップを 計算し,系領域を求める.次に評価用データをマッピングして先の領域から系を判定し,最初の分 類と比較して,正解率を求める.なお,入力ベクトルの属性数は,30, 50, 100 の場合について調べ る. 評価条件とデータ数の関係をTable 7-1 にまとめる. なお,表中の三つ組みは,それぞれC, R, D の症例文書数を表す.Table 7-1 Conditions of Evaluation
学習用 (10, 10, 10) (15, 15, 15) (20, 20, 20) データ数 (C, R, D) 評価用 (26, 15, 17) (21, 10, 12) (16, 05, 07) 入力ベクトル属性数 30 50 100 マップサイズ 20×20 50×50 80×80 100×100 学習回数 800 1,500 2,000 5,000
C: Circulatory, R: Respiratory, D: Digestive
Table 7-1 の評価条件は,データ数条件が 3,属性数条件が 3,マップサイズ条件が 4,学習回数 条件が4 パターンあり,総計 144(=3×3×4×4)回の試行を意味する. 7.5.2 結果 学習データ数 10, 15, 20,属性数 30, 50, 100 についての,マップサイズと正解率との関係を Table 7-2 に示す.また,学習回数毎の平均正解率の変化をグラフとして Fig.7-15 に示す. Table 7-2 について補足する.マップサイズは,生成するマップの解像度を示すパラメータである が,同時に疾患系の分類精度基準を示すパラメータであるとも言える.症例文書のクラスタリングを 行う場合,マップサイズを大きくすることは,精度基準を引上げることを意味し,結果としてよりシビア な評価を要求する.今回の実験では,正解率マップ平均の変動範囲は,マップサイズ(セル数)が 20×20 のとき 57.7∼81.0[%]であり,100×100 のとき 55.7∼77.7[%]となっている.変動範囲の下 限値は,4 種類のマップサイズでほぼ均一となり,平均で 57.2[%](σ=1.0[%])となる.上限値は平 均で77.4[%](σ=2.6[%])である.
Table 7-2 Results of Evaluation (#1/3) a) 学習データ数;(C, R, D)=(10, 10, 10) 学習回数 マップサイズ毎の正解率 [%] 800 20×20 50×50 80×80 100×100 属性平均 30 82 73 67 84 76.5 50 76 76 78 89 79.8 属 性 数 100 73 56 51 60 60.0 マップ平均 77.0 68.3 65.3 77.7 72.1 1,500 20×20 50×50 80×80 100×100 属性平均 30 87 62 71 67 71.8 50 71 64 64 60 64.8 属 性 数 100 58 56 67 64 61.3 マップ平均 72.0 60.7 67.3 63.7 65.9 2,000 20×20 50×50 80×80 100×100 属性平均 30 84 62 89 69 76.0 50 73 69 73 62 69.3 属 性 数 100 60 62 64 69 63.8 マップ平均 72.3 64.3 75.3 66.7 69.7 5,000 20×20 50×50 80×80 100×100 属性平均 30 76 62 62 71 67.8 50 71 69 69 64 68.3 属性数 100 58 56 80 49 60.8 マップ平均 68.3 62.3 70.3 61.3 65.6
Table 7-2 Results of Evaluation (#2/3) b) 学習データ数:(C, R, D) =(15, 15, 15) 学習回数 マップサイズ毎の正解率 [%] 800 20×20 50×50 80×80 100×100 属性平均 30 80 70 87 87 81.0 50 80 70 60 80 72.5 属 性 数 100 83 63 63 60 67.3 マップ平均 81.0 67.7 70.0 75.7 73.6 1,500 20×20 50×50 80×80 100×100 属性平均 30 80 87 97 70 83.5 50 77 70 63 70 70.0 属 性 数 100 63 63 60 57 60.8 マップ平均 73.3 73.3 73.3 65.7 71.4 2,000 20×20 50×50 80×80 100×100 属性平均 30 70 77 77 77 75.3 50 80 67 67 73 71.8 属 性 数 100 63 63 60 60 61.5 マップ平均 71.0 69.0 68.0 70.0 69.5 5,000 20×20 50×50 80×80 100×100 属性平均 30 77 70 63 87 74.3 50 60 67 70 67 66.0 属 性 数 100 53 53 60 57 55.8 マップ平均 63.3 63.3 64.3 70.3 65.3
Table 7-2 Results of Evaluation (#3/3) c) 学習データ数:(C, R, D)=(20, 20, 20) 学習回数 マップサイズ毎の正解率 [%] 800 20×20 50×50 80×80 100×100 属性平均 30 80 87 80 60 76.8 50 73 80 53 60 66.5 属 性 数 100 73 60 47 47 56.8 マップ平均 75.3 75.7 60.0 55.7 66.7 1,500 20×20 50×50 80×80 100×100 属性平均 30 67 60 67 80 68.5 50 53 53 53 40 49.8 属 性 数 100 53 87 53 47 60.0 マップ平均 57.7 66.7 57.7 55.7 59.4 2,000 20×20 50×50 80×80 100×100 属性平均 30 73 60 67 60 65.0 50 67 53 60 67 61.8 属 性 数 100 67 60 67 60 63.5 マップ平均 69.0 57.7 64.7 62.3 63.4 5,000 20×20 50×50 80×80 100×100 属性平均 30 67 60 87 67 70.3 50 53 60 60 47 55.0 属 性 数 100 87 73 53 60 68.3 マップ平均 69.0 64.3 66.7 58.0 64.5 属性数は,本来,分類データに含まれる特徴や性質の個数であるが,今回の場合は,各症例報 告に含まれる医学関連用語候補の出現確率の個数となっている. 先に述べた通り,頻度順リスト(高頻度優先)を利用することから,属性数が少ない場合,高頻度 の用語のみから入力ベクトルが構成されることになり,結果として都合がよい.反面,属性数が多くな ると,ノイズとなる用語の割合が増える.実験では,正解率属性平均の変動範囲は,属性数 30 のと き49.8∼83.5[%]であり,属性数 100 のとき 55.8∼68.3[%]となっている.変動範囲の下限値は,3 種類の属性値の中で100×100 のときがやや高く,平均で 51.8[%](σ=3.5[%])となる.上限値は 平均で77.2[%](σ=7.9[%])である. 学習回数は,計算精度を高めるパラメータであるが,計算時間とのトレードオフを常に意識する必 要がある.今回の場合,5,000 回までの評価しか行わなかったので,それぞれの学習回数の正解率 への影響に関しては,特別な差は見られなかった.この点ついては8章で考察する. 次に,Fig.7-15 について補足する.各グラフ a)∼d)を見ると,学習回数が増えるほど,各条件の 正解率の変動範囲は小さくなっていくことが分かる.実際,学習回数 800 回のとき標準偏差σ= 9.7[%]となり,1500, 2000, 5000 回で,それぞれσ=7.9[%], σ=5.3[%], σ=4.6[%]となる.ま
た,変動範囲の下限値は,学習回数が増えるほど,53.7, 56.0, 61.7, 59.3[%]と変化し,上昇傾向 にあるのに対し,逆に上限値は, 80.7, 78.3, 77.7, 75.0[%]と変化し,下降傾向にあることが分かる. 平均値は70.8, 65.6, 67.5, 66.9[%]と変化し,やや下降傾向を示す. a) Training Counts: 800 40 60 80 100 20x20 50x50 80x80 100x100 Map size Rate of Correct Answer[%] 30 50 100 b) Training Counts: 1500 40 60 80 100 20x20 50x50 80x80 100x100 Map size Rate of Correct Answer[%] 30 50 100 c) Traning Counts: 2000 40 60 80 100 20x20 50x50 80x80 100x100 Map Size Rate of Correct Answer[%] 30 50 100 d) Training Counts: 5000 40 60 80 100 20x20 50x50 80x80 100x100 Map Size Rate of Correct Answer[%] 30 50 100
7.6 考察
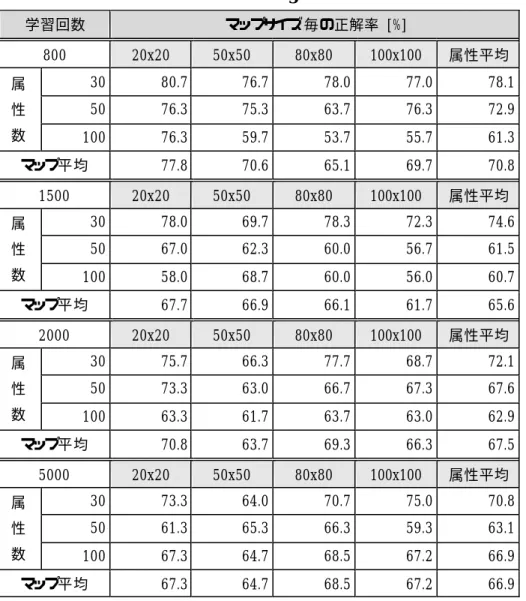
7.6.1 属性数と学習データ数について 学習データ数10, 15, 20 の総平均をTable 7-3 に示す. SOM 学習は,結合重みの初期値として乱数を用いる.従って,学習毎に生成されるマップは異 なったものとなる.評価実験では条件の組み合わせが144 通りにのぼり,各条件で1試行ずつのデ ータしか得られなかった.この点を考慮しなければならない.Table 7-3 Total Average of the Results
学習回数 マップサイズ毎の正解率 [%] 800 20x20 50x50 80x80 100x100 属性平均 30 80.7 76.7 78.0 77.0 78.1 50 76.3 75.3 63.7 76.3 72.9 属 性 数 100 76.3 59.7 53.7 55.7 61.3 マップ平均 77.8 70.6 65.1 69.7 70.8 1500 20x20 50x50 80x80 100x100 属性平均 30 78.0 69.7 78.3 72.3 74.6 50 67.0 62.3 60.0 56.7 61.5 属 性 数 100 58.0 68.7 60.0 56.0 60.7 マップ平均 67.7 66.9 66.1 61.7 65.6 2000 20x20 50x50 80x80 100x100 属性平均 30 75.7 66.3 77.7 68.7 72.1 50 73.3 63.0 66.7 67.3 67.6 属 性 数 100 63.3 61.7 63.7 63.0 62.9 マップ平均 70.8 63.7 69.3 66.3 67.5 5000 20x20 50x50 80x80 100x100 属性平均 30 73.3 64.0 70.7 75.0 70.8 50 61.3 65.3 66.3 59.3 63.1 属 性 数 100 67.3 64.7 68.5 67.2 66.9 マップ平均 67.3 64.7 68.5 67.2 66.9 評価実験の結果から,属性数 30 の場合が最も成績が良く,全マップサイズにおける属性平均で 見ると,学習回数平均で正解率は 73.9[%]となる.他の属性数に対する正解率の変化を Fig.7-16 に示す.
50 60 70 80 90 100 20 30 40 50 60 70 80 90 100 110 属性数 正解率 [%] 平均値 最小値 最大値
Fig.7-16 Match Rate on each Attributes
結果でも述べたが,単純に正解率が高いだけでは分類(クラスタリング)性能を判断することが難 しい.Fig.7-16 に見られる属性数は,1文書あたりの異なりキーワード(特徴)の個数であり,30 個で 少ないわけではない.Web のサーチエンジンでも,キーワード指定が 30 以上となるのはまれである. 逆に,100 個もの属性を扱うためには,元の文書サイズがある規模以上でなければならないことが分 かる.今回の実験でも,属性数 100 の場合に,抽出キーワード数が 100 に満たない場合もあった. よって,本手法の実用化では,属性数が30 以下に設定することが望ましいものと結論できる. 次に学習データ数であるが,本稿で述べている頻度順リスト(高頻度優先)を利用する場合,1疾 患系あたりの学習データ数15(全体の 51%)のときが最も成績が良く,平均で 70.0[%]となる.デー タ数10(全体の 34%), 20(全体の 68%)のときがそれぞれ 68.3, 63.5[%]であることから,データ数 がある値以上となると,ノイズの影響が増加するものと考えられる.このことから,分類したい文書デ ータサイズを考慮し,全体の文書数から判断して,50%以下となるようにすればよいことが判る.
7.6.2 マップサイズと学習回数について 前節から正解率の高い結果が得られる条件として,属性数 30,学習データ数(1疾患あたり)15 のデータに注目すると,マップサイズ毎の正解率は,20×20, 50×50, 80×80, 100×100 で,それ ぞれ76.8, 76.0, 81.0, 80.3 [%]となる(Fig.7-17). また,同じ条件で,学習回数毎の正解率は,800, 1500, 2000, 5000 で,それぞれ 81.0, 83.5, 75.3, 74.3 [%]となる(Fig.7-18). これらのグラフから,総体的な判断をすると,マップサイズについては,50×50 以上,80×80 以 下の範囲で決定すべきであることが判る.また,学習回数については,1500∼2000 回の範囲が妥 当であると言える.100×100 以上のマップや,5000 回以上の学習については,データが得られて いないため不明である. マップサイズとは,SOM 出力層のニューロン・ユニットの数に一致する.例えば,20×20 のマップ は,縦20 列,横 20 行の直角格子状に配置された合計 400 個のニューロンからなる.マップサイズ が大きいと学習時間が大幅に伸びる.また,計算に用いる重み行列は,ニューロン・ユニット数×属 性数に一致するため,入力ベクトルのサイズが大きくなると消費されるメモリ容量が増えることにな る.
50
60
70
80
90
100
20x20
50x50
80x80
100x100
マップサイズ
正解率
[%]
平均値
最小値
最大値
50
60
70
80
90
100
0
1000
2000
3000
4000
5000
6000
学習回数
正解率
[%]
平均値
最小値
最大値
Fig.7-18 Match Rate on each Learning Times
評価実験における最適なSOM 学習条件をTable 7-4 にまとめる.
Table 7-4 Optimum Conditions 学習データ数 (C, R, D) = (15, 15, 15) 属性数 30 マップサイズ 50×50 ∼ 80×80 学習回数 1,500 ∼ 2,000 上記条件に合致する試行は4 試行あり,正解率の平均値は,84.5[%]となる.参考までに,マップ サイズ範囲を50×50∼100×100,学習回数範囲を1500∼5000 に拡大すると,試行数は 9 となり, その正解率平均は78.3[%]となる.また,属性数 30 のみを条件とした場合,試行数は 48 となり,正 解率平均は73.9[%]となる.
7.6.3 単語重複率について 疾患系毎の症例文書の統計値をTable 7-5 にまとめる. Table 7-5 において,単語重複率とは,NLP 部分において自動抽出された医学関連用語候補の 重なり数と異なり数との割合である.従って,この値の最小値は1であり,このとき単語の重複はない. 逆に,この値が大きいほど,同一単語の使用頻度が高いと見なせる. 本稿で述べた SOM 学習のための入力ベクトル値は,頻度順リスト(高頻度優先)から生成される ため,単語重複率が重要なファクターとなる.各単語頻度が一定であると,単語間の重みが均一とな り,特徴点が失われるため,クラスタリング(分類)性能が低下する恐れがある.故に,分類性能を一 定レベルより高めるためには,①ある程度の文書サイズを有し,②単語頻度の分散値が大きく,③単 語重複率が高い,文書集合を学習データとして選択する必要があるものと思われる.
Table 7-5 Statistics of Documents 学習データ数 a) 循環器系 10 15 20 平均テキストサイズ [KB] 9.04 7.86 7.00 異なり 54.60 49.00 44.40 平均抽出単語数 重なり 71.00 63.00 56.20 平均単語重複率 1.30 1.29 1.27 学習データ数 b) 消化器系 10 15 20 平均テキストサイズ [KB] 3.51 2.96 2.52 異なり 35.00 28.87 23.25 平均抽出単語数 重なり 44.80 38.13 31.05 平均単語重複率 1.28 1.32 1.34 学習データ数 c) 呼吸器系 10 15 20 平均テキストサイズ [KB] 5.50 4.49 3.72 異なり 51.00 47.40 40.40 平均抽出単語数 重なり 63.50 57.80 49.70 平均単語重複率 1.25 1.22 1.23 7.6.4 キーワードの自動抽出について 提案した手法では,文字種別に関するヒューリスティクスを用いることで,高速にキーワードを自動 抽出することができる.
文書数15(C, R, D 各 5 文書),属性数 30 の条件で学習用に自動抽出されたキーワード2384 語中,異なり数は1,447 語であった.これらの上位 50 語を頻度順に Table 7-6 に示す.第 312 位 以降は出現頻度1 であった. 第26 位に「目的」という一般用語が含まれているが,基本的には先に述べた通り,分類正解率平 均が 73.9[%]であることからも,臨床症例文書からの医学関連用語のキーワード自動抽出について, 自然言語処理を応用した本手法が有効であると判断できる.
Table 7-6 Sample of Keywords
No. Word Freq No. Word Freq
1 心不全 28 26 目的 10 2 発熱 22 27 心カテ 10 3 高血圧 21 28 加療 9 4 糖尿病 19 29 合併症 9 5 入院目的 19 30 冠動脈疾患 9 6 間質性肺炎 19 31 感染 9 7 血糖コントロール 17 32 腫大 9 8 浮腫 16 33 食事療法 8 9 血沈 15 34 血栓 8 10 低酸素血症 15 35 胸部不快感 8 11 血圧 14 36 胸水 8 12 血糖 13 37 胸痛 7 13 心筋生検 13 38 腹部 CT 7 14 手術 12 39 精査加療目的 7 15 心筋障害 12 40 貧血 7 16 胸部 CT 12 41 疼痛 7 17 過敏性肺臓炎 11 42 心筋 6 18 糖尿病患者 11 43 冠動脈造影 6 19 糖尿病性腎症 11 44 虚血性心疾患 6 20 輸血歴 11 45 特発性間質性肺炎 6 21 サルコイドーシス 10 46 腫瘍 6 22 再生不良性貧血 10 47 肺野 6 23 心電図 10 48 狭心症 6 24 咳嗽 10 49 腎症 6 25 心エコー 10 50 不整脈 6
![Table 7-2 Results of Evaluation (#1/3) a) 学習データ数;(C, R, D)=(10, 10, 10) 学習回数 マップサイズ毎の正解率 [%] 800 20×20 50×50 80×80 100×100 属性平均 30 82 73 67 84 76.5 50 76 76 78 89 79.8 属性 数 100 73 56 51 60 60.0 マップ平均 77.0 68.3 65.3 77](https://thumb-ap.123doks.com/thumbv2/123deta/8632444.1821704/22.894.166.731.148.754/TableResults学習データC学習回数マップサイズマップ.webp)
![Table 7-2 Results of Evaluation (#2/3) b) 学習データ数: (C, R, D) =(15, 15, 15) 学習回数 マップサイズ毎の正解率 [%] 800 20×20 50×50 80×80 100×100 属性平均 30 80 70 87 87 81.0 50 80 70 60 80 72.5 属性 数 100 83 63 63 60 67.3 マップ平均 81.0 67.7 70.0](https://thumb-ap.123doks.com/thumbv2/123deta/8632444.1821704/23.894.168.733.131.756/TableResults学習データ=学習マップサイズマップ.webp)
![Table 7-2 Results of Evaluation (#3/3) c) 学習データ数:(C, R, D)=(20, 20, 20) 学習回数 マップサイズ毎の正解率 [%] 800 20×20 50×50 80×80 100×100 属性平均 30 80 87 80 60 76.8 50 73 80 53 60 66.5 属性 数 100 73 60 47 47 56.8 マップ平均 75.3 75.7 60.0 55](https://thumb-ap.123doks.com/thumbv2/123deta/8632444.1821704/24.894.167.733.128.753/TableResults学習データC学習回数マップサイズマップ.webp)
![Table 7-4 Optimum Conditions 学習データ数 (C, R, D) = (15, 15, 15) 属性数 30 マップサイズ 50×50 〜 80×80 学習回数 1,500 〜 2,000 上記条件に合致する試行は 4 試行あり,正解率の平均値は, 84.5[%]となる.参考までに,マップ サイズ範囲を50×50〜100×100,学習回数範囲を1500〜5000 に拡大すると,試行数は 9 となり, その正解率平均は 78.3[%]となる.また,属性数](https://thumb-ap.123doks.com/thumbv2/123deta/8632444.1821704/29.894.138.768.143.522/TableOptimum学習データ属性数マップサイズマップサイズとなり率平均.webp)
![Table 7-5 Statistics of Documents 学習データ数 a) 循環器系 10 15 20 平均テキストサイズ [KB] 9.04 7.86 7.00 異なり 54.60 49.00 44.40 平均抽出単語数 重なり 71.00 63.00 56.20 平均単語重複率 1.30 1.29 1.27 学習データ数 b) 消化器系 10 15 20 平均テキストサイズ [KB] 3.51 2.96](https://thumb-ap.123doks.com/thumbv2/123deta/8632444.1821704/30.894.174.720.427.1004/TableStatisticsデータテキストサイズ平均単データテキストサイズ.webp)

