選択と集中に関するシミュレーション
Simulation of Selection and Concentration
小柴 等
(KOSHIBA, Hitoshi)1∗ 1文部科学省 科学技術・学術政策研究所(NISTEP) Abstract: 予算等の資源を配分を行う際,一部に対して優先的・集中的に配分する“選択と集中”戦略 が選択される場面は珍しくない.ここで,投資に対して見込める利益率の分布が“べき分布”をとり,か つ,見込める利益率の予測ができない場合には選択をせず,遍く対象に投資する方が全体としての利益 が大きくなることが示されている[野田19].ただし,予算等の資源は有限ではないため,たとえば申請 があったものについてはすべて予算を支出するとした場合,予算が十分に確保できない可能性が高いほ か,当初から利益が見込めない課題を乱発して自己の資源確保最大化を図るような行動も予想され,現 実的には遍く対象に投資することは難しく,一定のフィルタリングは必要になると考えられる.そこで 本報では投資に対して見込める利益率の分布が“べき分布”の場合に,選択と集中の程度と,個々の課題 の利益率に関する予測精度の関係について,モンテカルロ・シミュレーションを通じて明らかにした.1
はじめに
科学研究費助成事業(学術研究助成基金助成金/科学 研究費補助金)*1をはじめ,研究資金などの配分を行う 際,一般に,応募者全員に申請額をそのまま付与するの ではなく,何らかの評価を行った上で,高評価なものか ら資金配分を行う.予算等の上限が限られていることを 考えれば,何らかの評価基準を設けて高評価なものを選 択する,もしくは低評価なものを排除するという行為は 合理的で適切と考えられ,研究資金配分に限らず社会の 様々な場面で見ることのできる行為でもある. ところで,研究という作業を考えると,過去になかっ た新たな知識を開拓する試みと捉えることもできる.こ れまでに存在しないものに付いての作業であるので,作 業した結果,所望の結果を得ることができるか否かも必 ずしも明らかでは無い.この傾向はいわゆる基礎研究に 関するものほど強いと考えられる.そのため,研究費の 申請時点すなわち研究構想時点において,その研究課題 の評価を適切に行うことは原理的に難易度が高いことが 推察される.さらに評価にあたっては研究内容について の理解も要するため,評価の難易度は更に高まる.こう した背景のもと,例えば科研費については論文査読と同 ∗連絡先:文部科学省科学技術・学術政策研究所 〒100-0013 東京都千代田区霞が関 3-2-2 中央合同庁舎第 7 号館東館 16 階 E-Mail: hitoshi.koshiba @ nistep.go.jp *1 以下,科研費という. 様に,専門家による評価に依っている. このように,評価は負荷の高い作業である.また,競 争的外部資金を獲得するには申請作業が必要であり,申 請者にも申請作業等のコストが生じる.他方,近年の運 営費交付金の低下に伴って,研究費を確保するためには 競争的外部資金の獲得は不可欠である.結果として申 請・評価のコストが研究作業の推進をかえって阻害して いるのではないかといった懸念もあり,研究費に関する 過度の選択と集中に対する指摘も存在する[豊田19]. ところで,このときにどのように資金配分を行うこと が望ましいか,といった配分の方式については必ずしも 明らかではない.たとえば,ランダムに課題を選択して 資金を配分した場合と,評価を行って配分した場合とで は,最終的にどの程度の差が生じるのか.たとえば,あ る研究が産み出すであろう成果の評価について,まった く評価できない場合と,1割程度の正確さで評価できた 場合とでは,最終的にどの程度の差が生じるのか.たと えば,評価の正確さが一定として,全体の1割に集中さ せるのと,5割に集中させるのとでは,最終的にどの程 度の差が生じるのか. こうした疑問について,実際に数理的に考察を行った ものもある[野田19].ただし,ここでは「べき分布」前 提とし,かつ「(将来産み出す価値の付いて事前の)評価 は原理的に困難」という前提での評価に留まっていた. これらの主張については一定の合理性を有しており 納得のゆくものである.ただし,成果算出に関する分布 の形状が「べき分布」とは限らない可能性はある.また 「わずかでも評価できる」とした場合に,評価の正確性がどのように影響するかについても検討の余地はある. そこで本稿では,選択と集中の程度と,個々の課題の 利益率に関する予測精度の関係について,モンテカル ロ・シミュレーションを通じた検証を行った.
2
既存研究
資金の配分(アセットアロケーション)は研究開発投 資に限らず,資本主義社会においては様々な場面で問題 となる.たとえば,株式市場においてどの会社の株をど の程度購入するか,資材購入とスタッフ雇用にそれぞ れどの程度の資金を配分するか,など,枚挙にいとまが ない. 特に株式市場における商品購入については,低リスク 低リターンな商品と,高リスク高リターンな商品を組み 合わせるポートフォリオなど,一種の購買戦略も知名度 を得ている.研究課題についても,一種の金融商品と見 なすことはでき,金融工学等の知見を活用する余地は十 分にある.ただし,今回我々が想定するようなケースを 取り扱った論文・理論は見付けることができなかった. 他方,研究開発投資を直接対象として,資金集中と分 散のどちらが良いかについて実際に数理的な検討を試み たものがある[野田19].ここでは,研究課題の産み出す 価値が「べき分布」に従うことを仮定した上で,その場 合に,資金集中と分散でどちらのほうが全体としての利 益が大きくなるかを解析的,数値的に検証している.結 果として,1.(基本的にはパラメータと関係なく)研究 課題数が増すほど利益率も大きくなる,2.資金を集中 させるよりも,広く遍く研究課題に投資する方が利益が 大きくなる,といったことを報告している.ただし先行 研究では,そもそもどのような研究課題が大きな利益を 生み出すかを予測することはできない,という前提のも とで分析を行っている. この前提について,著者らも肯定的にとらえているも のの,一般に「遍く研究課題に資金を配分する」とした場 合には,実施の意図がない研究課題や,到底妥当とは考 えがたい予算額を申請する研究課題など,意図的な「た だ乗り」が生じ,結果として「共有地の悲劇」のような状 況が発生する可能性も高い*2.したがって,現実的には 「足きり」など何らかの評価・ファイルタリングは必要 になる.また研究課題に限らず,多額の投資を行おうと する場合,リスク(例えば研究の実現可能性)とリター ン(例えば研究成果の生み出す価値)のバランスをみて, *2 そうした悪意のある申請について,研究を実施したか事後に確 認したり,不正発覚時の処罰を厳格化するなどして抑止するよ うな運用も考えられるが,事後確認は結局,確認のためのコス トの問題を生じることになる. どの程度の投資が妥当かの判断を行う.翻って,研究投 資についても事前の段階において,やはり,その研究課 題のリスクとリターンについて一定の評価(高額なもの についての厳密な評価)が求められると想定される. そこで,仮に研究課題のリターンについてもある程度 は予測できるとした時に,予測精度(事前評価の精度) と資金集中度が利益に対してどのような影響を及ぼすの か,といった問についての疑問がある. また,「べき分布」は計量書誌学の世界でも一般的な法 則であり,研究開発投資を考える上でも一定の説得力を 有する一方で,たとえば「対数正規分布」のように「べ き分布」に類する他の分布も存在するが,そうした分布 でも先行研究と類似の結果になるのか,疑問がある.3
実験
ここでは以下のRQを検証するためにモンテカルロ・ シミュレーションを行う. RQ1「べき分布」に従う場合,予測精度と資金 の集中は利益全体に対してどのような影響を及ぼ すか RQ2「べき分布」の代わりに「対数正規分布」を 用いた場合でも,「べき分布」と同様の傾向を示 すか3.1
前提条件
ここで,すでに先行研究で指摘されているとおり,「べ き分布」を想定した場合には,研究課題数が多ければ多 いほど,期待値が向上する事が示されている.したがっ て,研究課題数がパラメータのひとつとなる. 次に,我々が設定したRQにおいては,「予測精度」と 「資金の集中度合い」について言及しているため,これ らもパラメータとなる. 以上より,最低限設定すべきパラメータは,研究課題 数,予測精度,資金の集中・分散度合い,の3点になる. 加えて,予測については,A.期待される成果が投入 量を上回るか(利益率が1以上か否か)という2値予測 と,B.期待される成果の具体値がいくらかという数量 予測との2種類を設定する. この他,確率分布のパラメータも影響するが,これは 分布毎に異なるので,ここではいったん除外する. 1.研究課題数1000,10000,100000の3パタン 2.予測精度0%, 10%, 25%, 50%の4パタン 3.予測種類2値予測,数量予測 の2パタン4.資金の分散度合い100%, 75%, 50%, 25%, 10% の5パタン なお,「資金の分散度合い」100%は全ての研究課題 に資金が1単位ずつ配分されている状態,「資金の分散 度合い」50%は半数の研究課題に2単位ずつ資金が配 分されている状態,「資金の分散度合い」10%は1割の 研究課題に10単位ずつ資金が配分されている状態,を 意味する.従って,資金の分散度合いが小さいほど,少 数の研究課題に集中投資をする状態を表し,分散度合い が大きいほど,多数の研究課題に分散投資をする状態を 表す. 予測については,精度0%以外のケースでは全ての課 題に対してなんらかの予測を実施する.例えば精度10% の場合,10%の確率で正しく2値予測もしくは数値予 測の結果を返す.それ以外の場合は,2値予測の場合は 一様分布に従ってランダムに0(投資額以下の利益),1 (投資額以上の利益)を,数値予測の場合は,べき分布に 従って数値を返す.
3.2
予備実験
ここでは,「べき分布」に基づくモンテカルロ・シミュ レーションに際し,先行研究同様,べき分布の累積密度 分布関数の逆関数を用いて,「べき分布」に基づく数値 生成を行うこととした. ここで,べき分布を以下で定義する. 𝑓 (𝑥) = 𝛽𝑥−𝛼 (1) ただし,𝛼 > 1, 𝑥 ≥ (𝛼−1𝛽 )( 1 𝛼−1) .このとき,べき分布の 累積分布は以下の通り表現できる. 𝐹(𝑋) = 1 −𝛼 − 1𝛽 𝑋−𝛼+1 (2) 従って,逆関数𝐺(𝑝)は以下の通り表現できる. 𝐺(𝑝) = { (1 − 𝑝)(𝛼 − 1) 𝛽 } 1 1−𝛼 (3) その上で,Python3.7のrandomパッケージで提供さ れるrandom関数を用いて𝑝を設定することとして,分 布のパラメータを𝛼 = 1.90, 𝛽 = 0.18に固定し,10000 回ランダムサンプリングして理論値と比較した.結果を 表1に示す. 表1のとおり,基本的には理論値と一致する観測値が 得られており,シミュレーションのベースとなる値には 誤りがなさそうなことが分かる.3.3
実験
「べき分布」のパラメータについては今回は先行研究 を参考に,𝛼 = 1.90, 𝛽 = 0.18として,1.研究課題数, 2.予測精度,3.予測種類,4.資金の分散度合い,の 各パラメタを変化させ,結果を比較する. 3.3.1 実験の設定 本実験を以下のようなゲームと想定すると理解がしや すい. •「なんらかの数値が書かれたカード」が数値の書 かれた面を伏せてテーブルに並べられていると する. • プレイヤーは,カードの枚数と同数のコイン*3を 持っており,好きなカードに手持ちのコインを好 きなだけ置くことができる. • プレイヤーが全てのコインを置き終わったらカー ドを開け,カードの数字にコインの数をかけた値 が得点となる. ここで,カードは研究課題,カードの数値が研究の生 み出す価値(利益率),コインが研究投資である. 3.3.2 実験の手続き モンテカルロ・シミュレーションの特徴を加味して実 験の手続は以下の通りとする. 1. 任意の研究課題数𝑛件分のカードを作成し,べき 分布にしたがってランダムに価値を割り付ける 2. このカードの山に対して,予測精度,種類,集中 度合いを変化させた全組合せ(40パタン)の試行 を実施する 3. 上記,1.,2.を1000回繰り返し,平均的な傾向 を得る つまり,特定のカードのセットを用い,「予測精度が 0%で,全てのカードにコインを1枚ずつ置いた場合(資 金分散100%)」「予測精度が0%で,半分のカードコイ ンを2枚ずつ置いた場合(資金分散50%)」など,複数 のパタンを試行する.その上で,40パタン全てを終えた ら,新たなカードの山を作成し,再び40パタンを試行 する. なお,予測精度が0%ではない場合,既に述べたとお りに全カードについて予測を行う.このときに,資金分 *3 シミュレーション上は整数に限らず,2.5 枚といった配置も可 能なため,ポイントと考える方がより正確ではある.表1 べき分布に基づく区間出現数の理論値と観測値 数値 件数 数値 件数 〜 1 8053 〜 11 16 〜 2 920 〜 12 14 〜 3 300 〜 13 10 〜 4 173 〜 14 16 〜 5 106 〜 15 8 〜 6 75 〜 16 8 〜 7 43 〜 17 8 〜 8 41 〜 18 12 〜 9 33 〜 19 8 〜 10 23 〜 20 6 数値 累積率 累積数 区間数 数値 累積率 累積数 区間数 1 80.0% 8000 8000 11 97.7% 9771 21 2 89.3% 8930 930 12 97.9% 9788 17 3 92.6% 9258 328 13 98.0% 9803 15 4 94.3% 9428 170 14 98.2% 9815 13 5 95.3% 9532 104 15 98.3% 9827 11 6 96.0% 9603 71 16 98.4% 9836 10 7 96.5% 9655 52 17 98.5% 9845 9 8 96.9% 9694 39 18 98.5% 9853 8 9 97.2% 9725 31 19 98.6% 9860 7 10 97.5% 9750 25 20 98.7% 9866 6
理論値
観測値
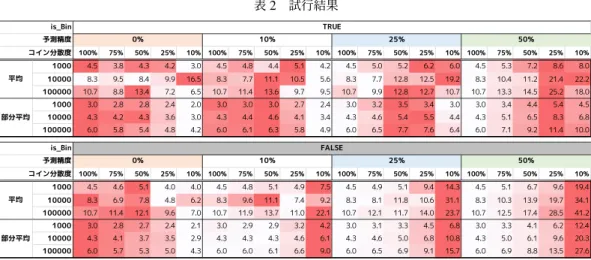
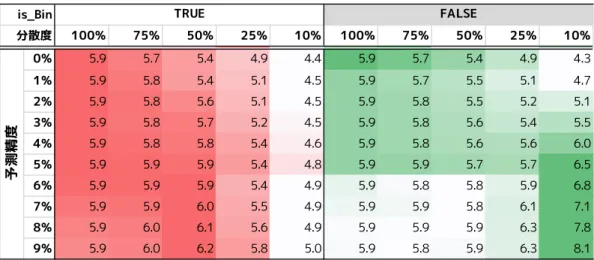
α= 1.90, β= 0.18 散の割合が100%を下回っており,1.2値予測の場合, 投資額以上の利益が返ってくると予測したカードの山か ら順にコインを配置する.投資額以上の利益が返ってく ると予測したカードの山をすべて引き終えて,まだコイ ンが残っていたら,残りのカードに順次,コインを配置 する.2.数値予測の場合,予め予測した価値の大きさ に沿って降順にカードをソートし,価値が高いと予測し たカードから順にコインを配置する. 3.3.3 実験の結果 1 実験の結果を以下に示す. 表2において,is_Binは2値予測か否かを示してお り,Trueの場合は2値予測,Falseの場合は数値予測を 意味している. べき分布の性質上,極めて大きな価値をもつカードも 出現することから,単純な平均を取った表では傾向が読 み取りづらい.そのため部分平均を中心として結果を読 み取る. 部分平均は,得点の上位・下位10%を除外した上で 平均をとったもので,今回は1000試行を行っているた め,上位下位各100件,計200件を除いた800試行の結 果の平均となる. 最初に,予測精度0%のケースについてみてみる.こ のケースは理論的には先行研究と一致するはずで,ここ がベースラインとなる.結果を確認すると,コインが分 散している方が全体としての利益が大きいこと,課題数 が多くなるほど全体としての利益率が大きいこと,が確 認でき,先行研究と一致する結果を得られている. 続いて,予測を行ったケースについてみる.まず,課 題数が多くなるほど全体としての利益が大きいこと,に ついては,予測を行ったケースでも,予測精度・種別に かかわらず同様の結果が保持されている. 次に差異について確認する.2値予測の場合,精度 10%および25%の場合は全体の50%程度に絞り込ん で投資する方が,全体としての利益が大きくなり,精度 75%では25%程度に絞り込んで投資する方が利益が大 きくなるような傾向を示している.数値予測の場合は, 精度10%, 25%, 75%の各ケースで全体の10%に集中投 資する方が利益が大きくなるような傾向を示している. ここで,予測精度10%では2値予測と数値予測の間 で面白い現象も確認できる.具体的には,コイン分散度 75%, 50%のケースで,数値予測よりも2値予測の方が 利益が大きくなっている.これは,予測精度が低い状況 下では粗い予測の方がかえってよい可能性を示してい る.例えば,予測精度が十分でないときに「午後15時 から10分ほど雨が降る」と予測するよりは「午後雨が 降る」と予測する方があたりやすい.これと同様の構造 で,予測精度が低い数値予測をした場合,ハズレを引く 確率が高まり,局所的に逆転現象が起きていると考えら れる. べき分布の場合,片側に裾が広がる分布形状自体はパ ラメタ(𝛼, 𝛽)が変わっても変化しないため,これらの 結果はパラメタによらず,成立すると考えられる. 3.3.4 実験の結果 2 前節の結果から,予測精度によって利益が変化するこ とが確認できた.このときすでに,10%の精度であっ ても予測ができるのであれば,集中投資する方が(わず かながら)高い利益を得られる可能性があることが示さ れた. そこで,こうした傾向は0%から10%まで単純な増加 傾向を示すのか,どこかで逆転を起こすのかについて, 詳細に調査した. 具体的には課題件数を10000件に固定した上で,予測 精度を0%から9%まで1%ずつ変化させ,傾向を確認 した.表2 試行結果 α= 1.90, β= 0.18 平均は1000試行の平均,部分平均は上位下位10%を除いた800試行平均 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 1000 4.5 3.8 4.3 4.2 3.0 4.5 4.8 4.4 5.1 4.2 4.5 5.0 5.2 6.2 6.0 4.5 5.3 7.2 8.6 8.0 10000 8.3 9.5 8.4 9.9 16.5 8.3 7.7 11.1 10.5 5.6 8.3 7.7 12.8 12.5 19.2 8.3 10.4 11.2 21.4 22.2 100000 10.7 8.8 13.4 7.2 6.5 10.7 11.4 13.6 9.7 9.5 10.7 9.9 12.8 12.7 10.7 10.7 13.3 14.5 25.2 18.0 1000 3.0 2.8 2.8 2.4 2.0 3.0 3.0 3.0 2.7 2.4 3.0 3.2 3.5 3.4 3.0 3.0 3.4 4.4 5.4 4.5 10000 4.3 4.2 4.3 3.6 3.0 4.3 4.4 4.6 4.1 3.4 4.3 4.6 5.4 5.5 4.4 4.3 5.1 6.5 8.3 6.8 100000 6.0 5.8 5.4 4.8 4.2 6.0 6.1 6.3 5.8 4.9 6.0 6.5 7.7 7.6 6.4 6.0 7.1 9.2 11.4 10.0 is_Bin TRUE 予測精度 0% 10% 25% 50% コイン分散度 平均 部分平均 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 1000 4.5 4.6 5.1 4.0 4.0 4.5 4.8 5.1 4.9 7.5 4.5 4.9 5.1 9.4 14.3 4.5 5.1 6.7 9.6 19.4 10000 8.3 6.9 7.8 4.8 6.2 8.3 9.6 11.1 7.4 9.2 8.3 8.1 11.8 10.6 31.1 8.3 10.3 13.9 19.7 34.1 100000 10.7 11.4 12.1 9.6 7.0 10.7 11.9 13.7 11.0 22.1 10.7 12.1 11.7 14.0 23.7 10.7 12.5 17.4 28.5 41.2 1000 3.0 2.8 2.7 2.4 2.1 3.0 2.9 2.9 3.2 4.2 3.0 3.1 3.3 4.5 6.8 3.0 3.3 4.1 6.2 12.4 10000 4.3 4.1 3.7 3.5 2.9 4.3 4.3 4.3 4.6 6.1 4.3 4.6 5.0 6.8 10.8 4.3 5.0 6.1 9.6 20.3 100000 6.0 5.7 5.3 5.0 4.3 6.0 6.0 6.1 6.6 9.0 6.0 6.5 6.9 9.1 15.7 6.0 6.9 8.8 13.5 27.6 FALSE 予測精度 0% 10% 25% 50% コイン分散度 平均 部分平均 is_Bin 図1 パラメータと対数正規分布 結果を以下に示す. 表3を見ると,概ね予測精度5%以下では選択・集中 の効果が見られず,それ以上になると,徐々に選択・集中 することで全体の利益が大きくなる傾向が確認できる. 3.3.5 実験の結果 3 ここまではRQ1について見てきた.ここからはRQ2 について見ていく. 「べき分布」のように,片側に長い確率密度分布を有 する分布は複数存在する.たとえば「対数正規分布」も パラメータによっては「べき分布」と類似する形状を示 す.図1に,パラメータを変化させて描画した対数正規 分布のいくつかの例を示す. そこで,「対数正規分布」を用いた場合でも「べき分 布」と同様の傾向を示すか確認する.ここでは,図2に 示すようにべき分布に近い形状を示す𝜇 = −5,𝜎 = 5で 試行する.また,予測精度についてはこれまでの試行を 参考に,0%, 1%, 5%, 10%, 25%, 50%の6パタンに変更 図2 𝜇 = −5, 𝜎 = 5の対数正規分布 して行う. 対数正規分布に基づく数値の取得はNumPy*4の run-dom.lognormal関数を用いておこなった. 結果を以下に示す. 表4からは,べき分布に基づいて試行した表2と同 様,課題数が増えるに従って全体の利益率も増加する傾 向,予測精度0%では広く遍く課題に資金配分を行う方 が全体の利益も増加する傾向,予測精度が上がるに従っ て,資金の集中配分が全体の利益を増加する傾向,など が確認された. 3.3.6 実験の結果 4 ところで,対数正規分布は図1に示したとおり,パ ラメータによって全く異なる形状をとる.そこで,パラ メータの違いによってどの程度傾向が変化するかについ ても確認した. *4 Version: 1.16.2
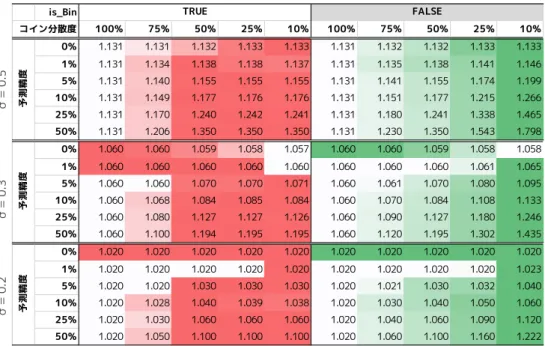
表3 予測精度と利益率 is_Bin 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% TRUE FALSE 分散度 0% 5.9 5.7 5.4 4.9 4.4 5.9 5.7 5.4 4.9 4.3 1% 5.9 5.8 5.4 5.1 4.5 5.9 5.7 5.5 5.1 4.7 2% 5.9 5.8 5.6 5.1 4.5 5.9 5.8 5.5 5.2 5.1 3% 5.9 5.8 5.7 5.2 4.5 5.9 5.8 5.6 5.4 5.5 4% 5.9 5.8 5.8 5.4 4.6 5.9 5.8 5.6 5.6 6.0 5% 5.9 5.9 5.9 5.4 4.8 5.9 5.9 5.7 5.7 6.5 6% 5.9 5.9 5.9 5.4 4.9 5.9 5.8 5.8 5.9 6.8 7% 5.9 5.9 6.0 5.5 4.9 5.9 5.9 5.8 6.1 7.1 8% 5.9 6.0 6.1 5.6 4.9 5.9 5.9 5.9 6.3 7.8 9% 5.9 6.0 6.2 5.8 5.0 5.9 5.8 5.9 6.3 8.1 予測精度 α= 1.90, β= 0.18, 課題数 10000件 1000試行中上位下位10%を除いた部分平均 表4 対数正規分布での試行結果 is_Bin 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 0% 282.8 255.7 215.7 151.8 88.8 282.8 251.2 216.3 136.4 77.7 1% 282.8 232.4 224.2 141.7 82.5 282.8 255.3 205.2 136.8 82.6 5% 282.8 245.0 221.7 142.6 94.2 282.8 282.9 217.6 172.6 155.1 10% 282.8 257.0 265.9 183.3 112.0 282.8 270.4 251.9 229.6 215.4 25% 282.8 290.9 315.9 261.5 173.5 282.8 286.3 289.0 369.7 499.2 50% 282.8 323.5 396.8 471.5 275.8 282.8 320.5 376.9 600.5 1280.8 予測精度 TRUE FALSE コイン分散度 0% 508.7 484.6 444.2 386.9 239.9 508.7 473.4 448.0 372.4 249.6 1% 508.7 463.6 419.1 361.7 249.3 508.7 463.1 443.3 391.0 334.7 5% 508.7 482.2 482.7 358.4 291.1 508.7 481.3 442.1 411.1 482.5 10% 508.7 507.4 501.7 460.2 304.0 508.7 499.5 462.1 512.6 646.0 25% 508.7 564.6 657.7 579.9 430.2 508.7 551.8 563.9 719.6 1176.4 50% 508.7 596.6 788.5 1010.3 746.1 508.7 583.9 732.2 1156.8 2548.0 予測精度 0% 866.8 835.8 788.3 676.3 556.0 866.8 839.8 808.4 629.2 503.5 1% 866.8 843.9 781.9 653.6 500.3 866.8 810.5 742.4 652.2 582.0 5% 866.8 877.4 851.9 746.3 562.6 866.8 852.3 779.8 757.2 831.2 10% 866.8 908.4 911.0 831.3 642.4 866.8 859.3 870.1 945.3 1164.0 25% 866.8 934.7 1092.2 1167.7 912.3 866.8 900.2 1013.0 1325.5 2284.6 50% 866.8 1045.9 1347.5 1824.3 1531.0 866.8 989.0 1249.7 1986.7 4109.3 予測精度 1000 件 10000 件 100000 件 μ = -5.0, σ = 5.0 1000試行中上位下位10%を除いた部分平均 具体的には図3に示した4パタンのうち,前節で既に 示した𝜇 = −5,𝜎 = 5を除いた3パタンについて,課題 件数を100000件に固定して試行する. 結果を以下に示す. 表5からは,分布形状が「べき分布」とは大きく異な るような形状を示す場合,結果も異なる傾向を示すこと が読み取れる.
4
考察
実験を通じ,下記のRQそれぞれに対して一定の回答 を得た. RQ1「べき分布」に従う場合,予測精度と資金 の集中は利益全体に対してどのような影響を及ぼ すか 予測ができない場合については,既存の報告[野田19] の通り,広く遍く課題に投資することで最も大きな利益 を上げられることは確認できた.その上で,おおむね予 測精度25%程度からは集中させることで一定の効果が 認められそうなことがわかった, RQ2「べき分布」の代わりに「対数正規分布」を 用いた場合でも,「べき分布」と同様の傾向を示 すか表5 対数正規分布での試行結果(パラメタの違い) μ = 0.0, n = 100000 1000試行中上位下位10%を除いた部分平均 is_Bin 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 0% 1.131 1.131 1.132 1.133 1.133 1.131 1.132 1.132 1.133 1.133 1% 1.131 1.134 1.138 1.138 1.137 1.131 1.135 1.138 1.141 1.146 5% 1.131 1.140 1.155 1.155 1.155 1.131 1.141 1.155 1.174 1.199 10% 1.131 1.149 1.177 1.176 1.176 1.131 1.151 1.177 1.215 1.266 25% 1.131 1.170 1.240 1.242 1.241 1.131 1.180 1.241 1.338 1.465 50% 1.131 1.206 1.350 1.350 1.350 1.131 1.230 1.350 1.543 1.798 TRUE FALSE コイン分散度 予測精度 0% 1.060 1.060 1.059 1.058 1.057 1.060 1.060 1.059 1.058 1.058 1% 1.060 1.060 1.060 1.060 1.060 1.060 1.060 1.060 1.061 1.065 5% 1.060 1.060 1.070 1.070 1.071 1.060 1.061 1.070 1.080 1.095 10% 1.060 1.068 1.084 1.085 1.084 1.060 1.070 1.084 1.108 1.133 25% 1.060 1.080 1.127 1.127 1.126 1.060 1.090 1.127 1.180 1.246 50% 1.060 1.100 1.194 1.195 1.195 1.060 1.120 1.195 1.302 1.435 予測精度 0% 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1% 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1.020 1.023 5% 1.020 1.020 1.030 1.030 1.030 1.020 1.021 1.030 1.032 1.040 10% 1.020 1.028 1.040 1.039 1.038 1.020 1.030 1.040 1.050 1.060 25% 1.020 1.030 1.060 1.060 1.060 1.020 1.040 1.060 1.090 1.120 50% 1.020 1.050 1.100 1.100 1.100 1.020 1.060 1.100 1.160 1.222 予測精度 σ = 0. 5 σ = 0. 3 σ = 0. 2 図3 パラメータと対数正規分布2 「対数正規分布」でも,「べき分布」に類似する分布パラ メータの場合は,傾向としては概ね同じことがわかった. 一方で,実務の面では後述する留意事項に加えて,こ こまでのレベルでもいくつかの課題もわかった. たとえば,予測精度の向上は審査コストと比例すると 考えられる.ここで,(部分平均をベースとして)予測 なしに全体にまいた場合の利益は2.7~2.8,25%の精度 で予測して全体の5割に集中させた場合の利益は3.3~ 3.5である.25%の精度での予測を行うために必要なコ ストが0.6~1.5の利益増加に見合うか,そもそも予測精 度を評価できるか,といった点は実務上重要である. さらに,数値予測の場合は予測精度10%で全体の1 割に絞ると高い利益が得られるが,仮に外部資金のみで 研究を行うような世界を考えた場合,残りの9割は死に 絶えてゆきシュリンクしていく可能性もある. また,既存の報告[野田19]とも関連するが,これま でになかったような革新的なアイデアを評価することは 困難性が伴う.単純な話としても“10万円の投資で1万 儲かる”と言われた場合と,“10万円の投資で1000万儲 かる”と言われ場合とで,後者はにわかには信じがたい. したがって,現状の技術の延長線上にあるか,解離の度 合いが小さいもの程度しか評価できず,大きな価値を持 つものほど見落としてしまうような問題が生じる可能性 も高い. 以上より,現状の設定の範囲においても実務上はさま ざまな留意を要する.
4.1
追加実験
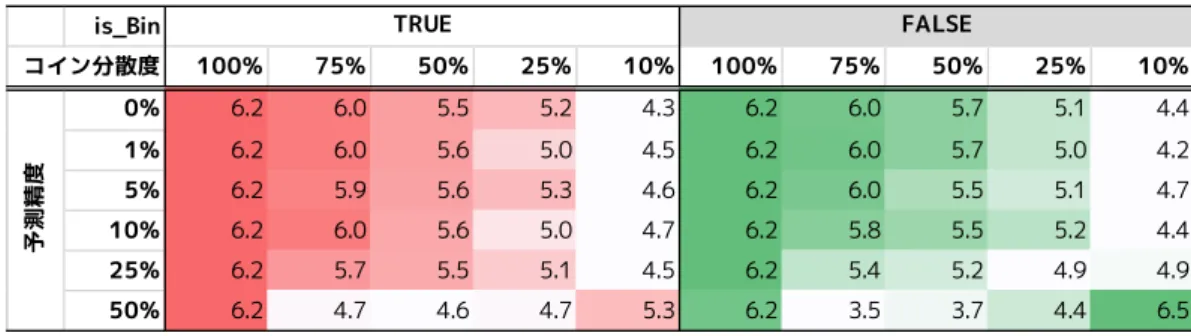
上記の考察の一部を補強するため,1の投資で100以 上の価値を産み出すことが予測される奇特なものを忌避 し,そのような場合には価値ゼロと予測を修正した場合 のシミュレーションを試行する. ここでは簡単のためにすでに見てきた,べき分布(𝛼 = 1.90, 𝛽 = 0.18)を前提とし,予測精度については0%, 1%, 5%, 10%, 25%, 50%の6パタンを採用する. 表6を見ると,このケースでは全体の価値を引き上 げる高価値な課題を積極的に切り捨ててしまうため,予 測の精度にかかわらず,予測を行わず広く遍く課題に資表6 高価値な課題を忌避した場合 is_Bin 100% 75% 50% 25% 10% 100% 75% 50% 25% 10% 0% 6.2 6.0 5.5 5.2 4.3 6.2 6.0 5.7 5.1 4.4 1% 6.2 6.0 5.6 5.0 4.5 6.2 6.0 5.7 5.0 4.2 5% 6.2 5.9 5.6 5.3 4.6 6.2 6.0 5.5 5.1 4.7 10% 6.2 6.0 5.6 5.0 4.7 6.2 5.8 5.5 5.2 4.4 25% 6.2 5.7 5.5 5.1 4.5 6.2 5.4 5.2 4.9 4.9 50% 6.2 4.7 4.6 4.7 5.3 6.2 3.5 3.7 4.4 6.5 TRUE FALSE コイン分散度 予測精度 α= 1.90, β= 0.18, 課題数 10000件 1000試行中上位下位10%を除いた部分平均 金配分を行う方が,全体の利益を増加することが読み取 れる.