Statistical approach to enhancing esophageal speech based on Gaussian mixture models
4
0
0
全文
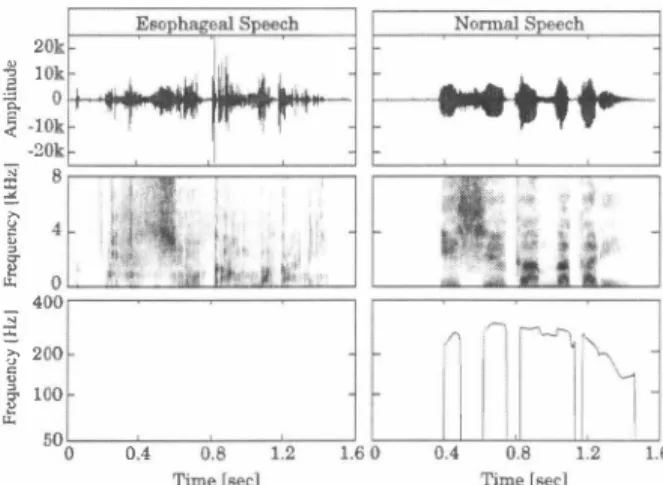
(2) 4品Z ' A AU ri151」 -卜1 -liriO K K K8 0 O K 0 0 0 0 nυ AU A V AO 内υ nυ nU FO η4 ・A -A 。& 6・z η& 'A 出 z s g u h Z 一N 尚 E 2 5 E 一 4 2 守 〈 日 三 喜 喧 ω Fig. 1. Example. 合= ['ÎI� "・197司‘ー ρJjT is determined by maximizing the fol. 担nnal生盟主. lowing objective function,. 。=ö叩na.xP(YIX.入)ωP(叫ν)1入(ul) y suLjCCL LO Y = Wy. よ4i. where W is a window matrix to extend the static feature vector se quence into the joint feature vector sequence of static and dynamic features [7]. A balance between P(YIX,入) and P(v(y)1入(VJ) is controlled by the weight ω. ll川h|. of waveforms. spectrograms and. Fo contours. 3.3. One-to・ManyEVC. An eigenvoice GMM (EV-GMM) mod巴ls the joint probability den sity in th巴 same manner as shown inEqs, (1) and (2). except for a definition of the target mean v巴ctor wntten as. textual features of source speech, e,g., the joint static and dynamic featur巴 vector 01' the concatenated feature vector from multiple frames, As an output speech feature vector, we use Yt = [凶ν, ム ν;rjT丁 c∞o∞ns凶I時of sta以山tic and dyr山nic features, Using a pan廿lel training data set consisting of time-align己d in put and ouゆut parameter vectors [X!.Yi]T. [XI.YJjT. [xi,Y引T, where l' denotes the 101al number of frames, lhe joinr probabilitydensity of the input and output parameter vectorsis mod eled by a GMM [6] as follows. '. (. 1I. whcrc bm and Am [am(l),・ \αm(J)j are a bias vectOl and e明nvectors am (j) for the m'h mixture component, respec tively, The number of eigenvectors is J. The target speaker individuality is controlled by the J-dimensional weight vector 、'W(J)jT Consequently, th巴EV-GMM has target 山= [即(1), m耐r-independent p釘ameter見1入(EV)consisting ofμjf),Am bm.and :E��\:.\ï and target-speaker-dependent parameter w TheEV-GMM is 汀ained using multiple parallel data sets con sisting of a single input speech dala set and many outpul speech dala S巴ts including various speakerピvoices, The trainedEV-GMM al lows us to control the converted voice quality by manipulating the weight vectOl世J. Moreover, the GMM for the input speech and new target speech are flexibly built by automatically dete口nining the weight vector叩using only a few arbitrary utterances of the target speech in a text-independent manner.. I. I. 4. VOICE CONVERSION FROM ESOPHAGEAL SPEECH (2). where N(-;μ,E) denotes the Gaussian distl均utJon w油a mean vector μand a covariancc matrix :E, The rnixture compon巴nt index IS?凡The total number of mixture components is JH. A parameter set of the GMM is入,which consists of weights Wm‘mean vectors μ.�;.Y) and full coval;ance matr悶s :E�: .Yl for individual mixture components. Th巴 probabi口lηl町 d白臼E白I附1ザy ofthe GV v(ν) of the outpゆ uωr s引ra以tJωc f,己た a仕ν '[. lu川 r陀eve氏叫cは1ωtor凶s ν = [ν 7 ,yJjT over an u 旧rance is also modeled by aGaussian dis廿ibution.. '@•@ • .. P(切(ν)1入(吋) = N(v(y);μい'J, :E(り). (3). wl町E山e GVv(ν) = [v(l),・・,V(Dy)jT is calculatcd by. 拾い)一品川)). (4). =. TO SPEECH (ES-TO-SPEECH). 1n order 10significantly enh,mce esophageal speech,it is essenti,ùto remove the speci自c noise sounds and to gcnerate smoothly varying speech parameters over an uttcrancc, Moreover, in order to syn thesize cnhanced speech with modi日cd spcech p紅白netcrs,it is also cssential to deal with difficulties of fcature cx汀action of esophageal spcech目To address thcs巴 issucs,wc propose statistical voice conver sion from esophagcal speech into normal specch, B巴cause conv巴此ed speech paramctcrs are gcncratcd from thc statistics of thc nonnal speech, the specifìc noise sounds and unstable variations are alle viated effectively by the conversion process, FurthemlOre. even if some specch paramctcrs such as Fo and unvoicedlvoiced informa lion are diffìcult to extract合om esophageaJ spccch, thosc parame lers exhibiting properties similar to those of normal specch would be estimated by the conversion from other speech parameters robustly extracted from esophageal speech (巴。g" spectral cnvelope), Thises llmatlOn proce回may be regarded as a statistical feature ex廿actlon process 4.1. Feature Extraction in ES-to-Speech [8]. A parameter set入(叫consists of a mean vcctor μ(,.) and a diagonal covananc巴 matnx :E(V) [Y!. .. .Y;r. LetX = [X[,,,, ,xi.. ,XijT and Y Yi jT be a tin問1 tωur陀e v巴ctωors, r陀esp巴ctively, Th巴 conv巴引rtほed s幻ta剖tJにc f,たeatωur陀e s鉛巴qu己nc巴. ,. (6). ) 、、1te,J I 2 2 r a μ. T Tt Y Tt x. 〆't 、 t、 ν M Zぃ11 リ川 m n 一 一 し μμ λ 「|lL れ = m … ぼp x μ. i ゃ ( λ二Y l :E�m;�l') 7ft =- I中川 I E�,�X) :E�γY ml. :E�;�' \'). 3.2. Convcrsion Process. μゴ) = Amω+bm,. of. め(Dν)jT at frame 1:, wher巴T denotes transposition of the vector As an input sp巴ech parameter vector. we use X t to capture con. ド(d). (5). The spcc甘al components of esophagcal speech vary unstably as mcntioned in Section 2, Moreover. spectral fcaturcs of some phonemes are often collapsed due to dif自culties of producing them in esophageal speech. To alleviate these issues. we use a spectral segment feature extractcd frorn rnultiple frames. At each frame, a spectral parameter vector at the current frame and those at several preceding and succeeding frames are concat巴nated, Then.dimension. 4251. nHV 口6 n〆UH.
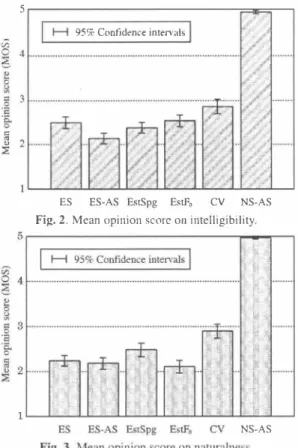
(3) reduction with principaJ component analysis (PCA) is performed to extract the spec佐al segm巴nt feature Although it is difficult to ex汀act Fo from esophageal speech (see Figl1re 1), we usuaJly perceive pitch infonnation of esophageal speech. Assuming that r巴levant infonnation is incll1ded in spectral parameter5. we use the spectral segment feature as an input featllre for estimating Fo in the conversion process. Moreover, in order to m法e the estimated Fo corrc�pond to the perccived pitch infonna tion of esophageal speech, as an Olltpllt featllrc we use Fo vaJlles extractcd from nonnal speech uttered by a non-Iaryngcctomce 50 as to makc its prosody similar to that of esophagcal spcech. TabIc 1. Estimafion accumcy vf me/-cepsfru川川TI削tT pOlVer wuj aperiodic componenTs. MeL-ceps Tr,日/ disTυrTion wiTh jJower (i.e.. in.. sholl'l1 in pω'enthes出 Mel-cepstral Aperiodic d1Stβrlion [dB] I distortion [dB). ι/uding the Oth co�fJicient) is. 846 (11.95) 4.96 (6.16). I I. 6.99 3.71. F o cor re lafion coefficiel1f (Ccm:) beT\Veen TIIl' ex Fo and the target Fo exrracted.from normal speech al1d ul1voicedlvoiced decisiol1引開仁For cxalllple, “VU" shvws rhe rafe of es timatil l g a voiced .fmllleαs al1凶n'oiced. UN dec凶ion error [別 I I Corr. I 内rable 2.. rracted/converted. 4.2. Training and ConversioJl In order to convert esophageal speech into normal speech, we use three different GMMs to estimat巴 three speech parameters 01' the target normal speech, i.e., sp巴ctrurn. Fo, and aperiodic components that captllre noise strength of an excitation signal on 巴ach frequency band [9]. For the sp巴ctral estimation, we use a GMM to cOl1vert the mput sp巴:ctral segment features into the coπesponding output spec tTal parameters. For the Fo estimation‘we use a GMM to convert the input spectral segment features into the output Fù vaJues and urト voiced/voiced infonnation. For the aperiodic estimation. we use a Gl\1M to convert the input spectral segment features into the output aperiodic components.. I. ,I. Extracted. 円. ,. 0.07. I. ,、68 I. 43.82 (V-U: 42.60. U\i:卜22) 8.36 (\/U: 4.06. UV 4.30). 8 frames in both the spectral estimation and the apeliodic estimation and the current土16 frames in the Fo estimation. respectively.. 5.2. Objcctive Evaluations Tables J and 2 show estimation accuracy of spectrum, aperiodic cOll1ponents, and Fo. It is observed that the acoustic features of esophageaJ speech are very differ巴nt froll1 those of norll1al speech. Tbese larg巴 differenc巴s of the acoustic features are significantly re duced by ES-to-Speech. We can see that the proposed conversion ll1ethod is very effective for estimating any of the three acoustic fea tures.. ln synthesizing the converted speech, we design a mixed excita tion based on町estimated日and aperiodic components [9]. Then. we synthesize the converted speech by filtering the mixed excitation with the estimated spec町al parameters. 5.3. Perceptual Evaluatiol1s. 4.3. Applyil1g Ol1e-to・恥'1al1y EVC to ES-to-Speech. We conducted two op叩ion tests of inteJligibility and naturalness. The foJlowing six types of speech sampJes were e六faluated by 10 Iisteners. We fUl1hcr apply onc-to-many EVC to ES-to-Speech for flexibly controlling convel1巴d voicc quality. The one-to-many EV-GMM for spectraJ conversion is traincd using muJtiple parall巴I data sets of esophageaJ speech data uttcr巴d by the laryngcctomee and normaJ spcech data uttered by many non-Iaryngectomees. The trained EV GMM allows laryngectomees to speak in th巴ir favorite voices, which are created by manipulating the weight vector for eigenvoices or by estill1ating proper weight vaJues using onJy a smaJl amount of those voices' data as adaptation if they are given.. ES recorded esophageal speech. ES・AS analysis-synthesized csophagcal spccch. EstSpg synthetic sp巴巴ch using converted ll1el-ccpstrum, convcrlcd. apcriodic componcnts, and Fo extractcd f[om esophagcal speech EstFo synthetic speech using extracted ll1cl-ccps汀Ull1‘cxtractcd apcriodic components, and convcrtcd Fo CV synthetic speech using converted meJ-cepstrum唱∞nverted ape 吋odic components, and converted Fo NS・AS analysis-synthesized normaJ speech. 5. EXPERlMENTAL EVALUATIONS 5.1. Expl.'rimental Conditiol1s We recorded 50 phoneme-balanced sentences of esophageal speech uttered by one Japanese male laryngectoll1ee. We aJso recordcd the sall1e sentcnces of nOl1l1al spccch llttered by a Japanese maJe non laryngectomee. He tried to imitate thc prosody of山e laryngectoll1ce utterance-by-utterance as closcly as possible. Sampling frequcncy was set to 16 kHz. We conducted a 5-fold cross vaJidation test in which 40 utterance-pairs were llsed for training, and the rCll1ω111ng 10 uttcr白lcc-pairs were uscd for evaJuation. Th巴Oth through 24th meJ-cepstral co巴f自cients extracted with STRAJGHT anaJysis [1OJ wer巴 used as the spectraJ parameter. As the source excitation features of normal speech, we used 10含scaled Fo巴xtracted with STRATGHT Fo analysis ll l] and aperiodic com ponents 19J on five frequency bands, i.e., 0- J, 1-2, 2-4, 4-6, and 68 kHz, which were used for designing mixed excitation. The shift length was 5 ms. We pl官liminarily optimiæd several parameters such as the num ber of mixture components of each GMM and the number of frames used for extracting the spectral segment feature [8]. As a result. we set th巴 number 01' mixture components to 32 for each of three GMMs. For the segment feature extraction, we used the cu汀ent土. Each listener evaluatcd 120 sall1pJes' in each of thc two tcsts. Figur官s 2 and 3 show thc result of the intelligibility test and that of the naturaJness test, respectivcly. ES-AS causcs significant intcl ligibility degradation compared to ES duc 10 the difficulties of the acoustic fcature extraction in esophageal speech. The specific noiscs and unstable variations on the sp巴C住ogram 111巴sophageaJ speech are signi自cantly aJJeviated by using the estimated spectral features Moreover、the conv官rted spe巴:ch exhibiting pitch information sim ilar to pitch p巴rceiv官d in esophageaJ speech is generated by using the estimated Fo contour. AJthough significant improvemenls in in t巴lligibility and naturalness are not observed when using only one of th巴se e坑imated features, we can see that the ES-to-Speech (CV) estimating all acoustic features yields signi日canlly lllore intelligibJe and natural speech than esophageal speech These results suggesl that the proposed ES-to-Speech is very ef fective for improving both the naturaIness and lhe intelligibility of esopha.geal speech IS引eraJ samples副e availabJe frol11 http://spalab.naist.jp/hironOll-cVJCASSP/ES2SPlindeλhtml. 4252. TIE n6 っ“.
(4) 95% CollÍïdence. interv,ùs. む宮吾 品E〈. - I IH. I. 2f.. . . .1ぞ ES-AS. EstSpg. EstFo. CY. 5 2F邑h出 ]h υ N目白 {. ノ�I r/é�.ヰrょう ES. NS-AS. Fig. 2. Mean Opillioll SCOI官Oll illtel1igibility 。. nu nu nu aAZ nUAυ nU ハU a仏τ 04 唱i. �. zωロr日片山 hu N-12} {. 串 仁. i31. '且'ι K -K nunu nUAU ハU n6 21 4 3. 5. 50. 0. U. 0.8 Ti血e [secl. 0.4. 1.6. Fig. 4. Example 01' wavefonn, spectrogram. and }ò of the cOl1verted speech by one�to-many EVC. spef'ch illtO spectmm.. Fo, and aperiodic components of nonnal. speech independently using three different GMMs.. The experト. mental results have demonstrated that ES-to-Speech yields Sigllifi cm1t improvements ill illtelligibility and naturalness of esophageal speech.. Moreover, we have also applied olle�to�many eigenvoice. conversioll to ES-to-Speech for flexibly COll町ol1ing voice quality of. 1. the converted spe巴ch.. NS-AS. 7. REFERENCES [1). 5.4. ElTectiveness of One-to・manvVC. lIsing a comb fìlter."lmernational Conference on Disability, Y inual Re ality and Associated Technologies, pp. 39-46. 2002. To makc voicc quality of the convc口cd spcech simiJar to the Jaryn. [2). gectomec‘5 OWll voice quality. we applied onc�to�many EVC to ES sets consisting of the esophageal speech and. 1 834, Phoenix, Arizona. May 1999. 30 speakers' nonnal. |β3J. speech. The EV-G恥1M was adapted to an esophageal sp巴巴ch sam ple shown in Figllre 1, and then the esophageaJ speech sample was. Spワeech. alld AI“Idio Pro. Yo叫l.. maximum likelihood estimation of spcctral parametcr tr句ectory円IEEE. Fo 1) acoustic features of. 7ト即日ASLP, Yol. 1 5. No. 8. pp. 2222-2235. Nov. 2007. [51. the converted speech vary more stably than those of the origillal esophageal speech sample出ld. tran目sfor口rmη、 for voi町ce convers剖】on," IEEE 7罰ワrans.. 6, No. 2, 1 'p. 131-1 42, 1998 [4) T. Toda, A、11. Black, and K. Tokuda, ‘Yoice conve円ion based on. Figure 4 shows an example of waveform. spectrogram, and. T.. Toda, Y. Ohtani, and K. Shikano守. ‘One-to-many and many-to-one. voice conversion based on引genvoices," Proc. ICASSP, pp. 1249-1252,. 2) the specific noise sounds afe sig. nific,mtly ,ùleviated by the conversion process.. Y. SIりげylia叩n叩l(旧o川1I, O. C“叩ppe, and E.. Mo山ulin即1暗es.. c、es口sr附ng,. converted inlo nonnal speech using the adapted EV�G恥1M We can see that. K. Matlli. N. Hara, N. Kobayashi. and H. Hirose, "Enhancement of esophageal specch using formam synthesis," Pr.οc. ICASSP, pp. 1831-. to�Speech. We trained the one�to�many EV�GMM using parallel data. of the converled speech.. A.H】抽出and H. Sawada. "Real-time c1 arificalion of esophageal speech. Hawaii, USA, Apr. 2007 [6). Namely, evell if. A. Kain and M.W. Macon、"Spectral voice conversion for texl-to-speech synthesis." Proc. ICASSP, pp. 285-288, Seattle, l1SA, May 1 998. esophageal speech is used as the adaptation data. the adapted EV. [7). G孔仏1 provides the converted speech of which properti目立re Slm1-. K. Tokllcla.. T.. Yoshimura. T. Masuko, T. Kobayashi. and T. Kilamura.. '.Speech paramet町generation algorithms for HMM-based叩eech !:.yn. .. lar 10 those of llonnal speech. In addition. we have observed that. the日5 ." Prac. ICASSP, pp. 1315-1 31 8, I st anbuJ TlIrkey, June 2000. the adapted EV-G孔仏1 makes the conve11ed voice quality clos巴r to. 18) H. Doi, K. N玖amu問、T. Toda. H. Saruwatari, and K. Shikano.“En hancement of Esophage立1 S1'eech l1sing Statistical Yoice Conversion,". the laryngcctomec's voice quality compared with the GMM lIscd in. APSIPA 2009.1'1.' 805-808, Sapporo. Japan, OCl. 2009. [9j H. Kawahara, J. Estill, and O. FlIjimllra,“Aperiodicity extraction and. the previous cvaluations, which wcre trained using the single 110n laryngcctomec・s spcech. FlIrthermore, w巴 have also observed that. control using mixed mocle excitation and !,'TOUp delay m,mipulation for. the converted voice qllality is flexibly challg巴d by manipulating the. a high quality speech analysis, modifìcation and system STRAIGHT,". weight valucs of the EV�GMM. The proposed ES-to-Sp巴cch with. MAVEBA 2001, Florcncc, Jtaly, Sept. 2001. one-to-mally EVC is cxpected to make possible a new speaking aid. [10) H. Kawahara.. system that allows laryngcctomees to control the converted voice. l.. Masucla-Katsuse, and A. Cheveigne.“Restructu口ng. sp�ech representations using a pitch-adaptive time-frequency smoothing and an instantaneolls-frequency-based fò extraction: Possible role of a. quality as they want. repetitive structure in sounds,". 27. No. 3-4.. [1 1) H. Kawahara. H, Kalayose. A. Che\'cigne. and R. D. Patterson.“Fixed. This paper has presented a novel method for enhancing esophag巴al spe巴ch using statistical voice conversion.. Spnch Commwtication, Vol.. p1'. 1 87-207.1999. 6. CONCLUSION. point analysis of freqllency to instantaneous仕equency mapping for ac. The propos巴d method. curate 出timation of. (ES-to�Sp巴ech) converts a sp巴ctral segment fealllre of esophageal. Fb. and periodicity," Proc. EVROSPEECH. pp.. 2781-2784, Budapest. Hungary. SepL 1999. 4253. 円〆“ nku つ'“.
(5)
図
関連したドキュメント
Today Iʼm going to make a speech about my dream... )in
In this thesis, I intend to examine how freedom of speech has been legally protected in consideration of fundamental human rights, and how the double standards in the
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
patient with apraxia of speech -A preliminary case report-, Annual Bulletin, RILP, Univ.. J.: Apraxia of speech in patients with Broca's aphasia ; A
The 100MN hydraulic press of the whole structural model based on the key dimension parameters and other parameters is analyzed in order to verify the influence of the
One of the procedures employed here is based on a simple tool like the “truncated” Gaussian rule conveniently modified to remove numerical cancellation and overflow phenomena..
By an inverse problem we mean the problem of parameter identification, that means we try to determine some of the unknown values of the model parameters according to measurements in
Abstract. In Section 1 we introduce Frobenius coordinates in the general setting that includes Hopf subalgebras. In Sections 2 and 3 we review briefly the theories of Frobenius
