✞ ✝
☎ ✆
原著論文
Original Paper
☞☞相互
k
-
近傍グラフを用いた半教師あり分類
Mutual
k
-Nearest Neighbor Graph Construction in Graph-based
Semi-Supervised Classification
小嵜
耕平
Kohei Ozaki
奈良先端科学技術大学院大学
Nara Institute of Science and Technology
[email protected], http://cl.naist.jp/˜kohei-o/
新保
仁
Masashi Shimbo
(同 上)
[email protected], http://cl.naist.jp/˜shimbo/
小町
守
∗1Mamoru Komachi
(同 上)
[email protected], https://sites.google.com/site/mamorukomachi/
松本
裕治
Yuji Matsumoto
(同 上)
[email protected], http://cl.naist.jp/staff/matsu/home.html
keywords:semi-supervised learning, classification, graph construction, document classification, word sense disambigua-tion
Summary
Graph construction is an important step in graph-based semi-supervised classification. While thek-nearest neighbor graphs have been the de facto standard method of graph construction, this paper advocates using the less well-knownmutualk-nearest neighbor graphs for high-dimensional natural language data. To evaluate the quality of the graphs apart from classification algortihms, we measure the assortativity of graphs. In addition, to compare the performance of these two graph construction methods, we run semi-supervised classification methods on both graphs in word sense disambiguation and document classification tasks. The experimental results show that the mutualk -nearest neighbor graphs, if combined with maximum spanning trees, consistently outperform thek-nearest neighbor graphs. We attribute better performance of the mutualk-nearest neighbor graph to its being more resistive to making hub vertices. The mutualk-nearest neighbor graphs also perform equally well or even better in comparison to the state-of-the-artb-matching graph construction, despite their lower computational complexity.
1.
は
じ
め
に
1·1 背 景
教師あり分類法において高い分類精度を得るためには,
通常十分な量の(正解ラベル付き)訓練データが必要で
あるが,訓練データを人手で整備するコストは高い.この
コストを削減するため,半教師あり分類(semi-supervised
classification)アプローチでは,少量のラベルありデータ
に加えて大量のラベルなしデータを活用する.中でも,グ
ラフ半教師あり分類(graph-based semi-supervised
classi-fication)は,語義曖昧性解消,意味解析,統計的機械翻訳
といった多様な自然言語処理タスクに応用され成功を収
めており[Goldberg 06, Alexandrescu 07, Niu 05,
Alexan-drescu 09],SVMなどの一般的な教師あり分類法が高い
分類性能を得るために必要とする,十分な量の訓練デー
タが得られない場合において,より優れた分類精度を達
成することが実験的に示されている[Niu 05].
グラフ半教師あり分類法への入力は,事例を頂点
(ver-tex)として表現したグラフである.入力グラフの構造が元
†1 2013年4月より首都大学東京
の事例空間での事例分布を反映していると考え,この構
造と,少数のラベルが既知の頂点(すなわち事例)を手が
かりに残りの頂点のラベルを推定する.元データがグラ
フとして表現されていない場合には,まずデータ(事例)
集合をグラフに変換するグラフ構築(graph construction)
の手続きを経る必要がある.
近年,グラフの頂点にどのように正しいラベルを割り当
てるかを焦点にして盛んに研究が行われ,数々のグラフ半
教師あり分類法が提案されている[Zhou 03, Zhu 03, Callut
08, Wang 08].その一方で,元データからのグラフ構築
に つ い て は ,い ま だ 研 究 の 余 地 が 大 き い[Zhu 05].実
際,グラフ半教師あり分類法を実データに適用する際に
は,深い議論のないままk-近傍グラフ(k-nearest neighbor
graph)∗1が用いられることが多い.しかしながら最新の
研究[Jebara 09]では,グラフ半教師あり分類の最終的な
精度は,用いられる分類法のみならず,グラフ構築の方
法にも大きく影響を受けることが示されている.
Ghazvininejadらは,構築されたグラフに対して,辺
の重みを適切に再定義するアルゴリズムを導入すること
で,元のデータ間距離をより正確に表現するグラフ構築
法を提案した[Ghazvininejad 11].このような「辺の重
みを適切に再定義する」議論は,「どの頂点間に辺を繋げ
るか」という議論と分けて議論ができ,組み合せること
が可能である.
本論文では,「どの頂点間に辺を繋げるか」ということ
に焦点を当てる.グラフ半教師あり分類法を自然言語デー
タに適用する状況を想定して,特にハブ(hub)と呼ばれ
る頂点の存在に着目し議論する.先に述べた通り,グラ
フ構築法としてはほとんどの場合k-近傍グラフが用いら
れるが,このグラフは極端に高い頂点次数を持つハブ頂
点を作りやすい欠点を持つ.この傾向は元のデータが高
次元である場合に特に顕著である.後程3·4節において,
ハブ頂点が実際にグラフ半教師あり学習の精度を悪化さ
せることを示す.
グラフ構築の文脈での研究ではないものの,Radovanovi´c
らは高次元空間におけるハブ「事例」について興味深い
観察をしている[Radovanovi´c 10].彼らは,与えられた
事例集合中で,他の多くの事例の(事例集合中のそれ以
外の事例と比較して相対的に)近くに位置する事例をハ
ブ事例と呼んでいる.このような事例は,次元の呪いの
副作用として高次元データ集合中に現れ,高次元空間に
おける近傍分類器(nearest neighbor classifiers)の分類精
度を悪くする一因となる.すなわち,ハブ事例のラベル
が既知な場合,この事例は多くの事例の近傍に存在する
ため,そのラベルがそれら多数の事例のラベル推定に影
響を与える可能性が高い.
Radovanovi´cらの結果は,k-近傍グラフにおいても同
様の問題が生ずることを示唆する.グラフ頂点の隣接関
係は元々が高次元空間にある事例の近接性によって決定
される.k-近傍グラフでは,ある頂点に対応する事例が
元の空間における他の事例のk-近傍集合に含まれている
とき,それらの二頂点間を貪欲に接続する.したがって,
事例空間で多数の事例のk-近傍集合に含まれるハブ事例
は,k-近傍グラフにおいてもハブ頂点となりやすい.さ
らに,ほとんどのグラフ半教師あり分類の手法はグラフ
上でラベルが既知の頂点から隣接した頂点に向けてラベ
ルの情報を徐々に伝搬させる.このため,(隣接頂点の多
い)ハブ頂点を通じて伝搬するラベル情報は数多くの頂
点に影響を与えることになる.
以上により,高次元データに対してグラフ半教師付き
分類法を適用する際には,ハブを作りにくいグラフ構築
法を用いることが望ましい.無論その際には,構築の効
率も問題となる.
1·2 本 論 文 の 貢 献
本論文では,k-近傍グラフの変種ではあるが,使われ
る 機 会 の は る か に 少 な い 相 互k-近 傍 グ ラ フ(mutual k
-nearest neighbor graph)をグラフ半教師あり分類に用い
ることを提案する.相互k-近傍グラフはk-近傍グラフ構
築と同じ計算量で簡単に構築できる.さらに,構築され
たグラフにおいて,各頂点の次数はkで抑えられるが,
これは標準的なk-近傍グラフにはない性質である.次数
に上限が存在することを利用して,グラフにおける極端
に高い次数を持つ頂点(ハブ頂点)が作られないように
できるかを検証した.なお実験設定として,教師あり分
類器が高い分類精度を得るために必要な,十分な量の訓
練データが得られない場面を想定し,グラフ半教師あり
学習を用いることを前提とする.
我々はまず,特定の分類アルゴリズムに依存せずにグ
ラフの品質を評価するために,構築したグラフの隣接頂
点間のクラスラベルの相関を調べた.この評価により相
互k-近傍グラフはk-近傍グラフより同じラベルを持つ頂
点を結ぶ辺の比率が高いことを確認した.この結果から
相互k-近傍グラフは異なるラベルの情報をグラフ上で伝
播することがより少なくなると期待できる.また,相互
k-近傍グラフとk-近傍グラフ,最新のグラフ構築法であ
るb-マッチンググラフ(b-matching graph) [Jebara 09]を
用いた場合の2つの標準的な半教師あり分類アルゴリズ
ムの分類精度を比較した.この結果から相互k-近傍グラ
フはk-近傍グラフと比較して分類精度が優れていること
を確認した.また相互k-近傍グラフは,b-マッチンググ
ラフより少ない計算時間でありながら同程度か,ときに
はより優れた分類精度を達成した.相互k-近傍グラフは,
グラフの頂点数がnであるとき,O(n
2)
の計算量で構築
できる.これに対して,b-マッチンググラフの構築には
O(bn3
)の計算量が必要である.
2.
問 題 の 定 式 化
2·1 半教師あり分類問題
半 教 師 あ り 分 類 問 題 を 定 式 化する .与 え ら れ たn 事
例の集合をX={x1, . . . ,xn}とする.S={1, . . . , c}を
事例の分類ラベルの集合とし,yi∈Sを各事例xi(i=
1, . . . , n)に対するラベルとする.n個の事例のうち,は
じめのl事例のみラベル割り当てy1, . . . , ylが既知だと
し,残りの事例ラベルyl+1, . . . , ynは不明とする.
半教師あり分類アルゴリズムの目標は,これらn−l個
の隠されたラベルyl+1, . . . , ynを,各々に対応するラベ
ルなし事例xl+1, . . . ,xnおよび,それ以外のl個のラベ
ルあり事例(x1, y1), . . . ,(xl, yl)を用いて予測することで
ある
∗2
.アルゴリズムにはさらに,背景知識を反映した
事例間の類似尺度が与えられる.言い換えると,アルゴ
リズムは全事例間のn×n類似行列W にアクセスする
ことができる.W は非負対称行列であり,各(i, j)要素
Wijは事例xiとxj の類似度を表す.ここで,W 上で
類似している事例どうしは同じラベルを持ちやすいと仮
定する.この仮定は多くの半教師あり分類アルゴリズム
に用いられており,クラスター仮説(cluster assumption)
と呼ばれる[Zhou 03].
2·2 グラフ半教師あり分類
グラフ半教師あり分類法は,事例集合Xがグラフの頂
点であればそのまま適用可能であるが,そうでなければ
まずX をグラフに変換しなくてはならない.本論文で
は,このグラフ構築の方法に焦点を当てる.
事例集合から構築したグラフをGと表記する.グラフ
の頂点は事例に対応するため,Gはn個の頂点を持つ.
グラフG の(n×n次元)重み付き隣接行列をAとす
る.グラフ構築のタスクは,全点間類似行列W から非
ゼロ要素を減らし,より疎(スパース)なAを計算する
ことと同義である.
W を疎にすることなく,A=Wとしてそのまま用い
ることもできるが,Aを疎にすることによって,分類の
際に計算時間が節約できるのみならず,ときには分類精
度も向上する
∗3
と報告されている[Zhu 08].我々は,ど
のような方法でWから疎なAを得るか,言い換えると
W からゼロにする要素を選ぶ方策について関心がある.
二値の集合をB={0,1}と書く.グラフを疎にする方
策はn×n二値行列P ∈Bn×nにより表現できる.具体
的には,P の(i, j)要素Pij= 1のとき,AijはWijそ
のものであり,Pij = 0のとき,Aij= 0とする方策を表
す.したがって,構築するグラフGの重み付き隣接行列
AはAij=PijWij により与えられる.多くのグラフ半
教師付きアルゴリズムは入力として無向グラフを要求す
るため,AとP はともに対称行列であるとする.
3.
近傍グラフとハブの影響
事例集合から疎グラフGを作る標準的な手法にk-近傍
グラフがある[Szummer 02, Niu 05, Goldberg 06].
3·1 k-近 傍 グ ラ フ
k-近傍グラフは,元の事例空間における各事例と,そ
のk近傍事例に対応する頂点の間に無向辺を作ることで
得られるグラフである.k-近傍グラフを作るためには,ま
ず非対称行列Qについて次の最適化問題を解く.
∗3 6·3·2節 の実験結果も参照.疎にしていない隣接行列A=W を使ったケースをベースラインとして用いている.
max
Q∈Bn×n
i,j
QijWij (1)
s.t.
j
Qij=k, ∀i∈ {1, . . . , n} (2)
Qii= 0, ∀i∈ {1, . . . , n} (3)
ここでは最終的に求めたい方策PではなくQを最適化
していることに注意する.この最適化問題は簡単で,W
の各行iに含まれる要素を大きい順に並べ,Wijが上位
k番以内に位置する場合にはQij= 1,それ以外の場合
Qij= 0とすれば最適解Qが求まる.得られたQは対
称行列とは限らないため,その後でPij= max(Qij, Qji)
として対称行列Pを得る.最後に,グラフの重み付き隣
接行列AをAij=PijWijにより決定する.P とW は
ともに対称行列なので,行列Aもまた対称である.
この手続きは,各頂点からそのk-近傍の頂点への辺の
みを保ち,その後すべての辺を無向辺とすること(対称
化)に等しい.対称化のステップはk-近傍関係が対称で
あるとは限らないために必要となる.つまり,ある頂点
iのk-近傍に他の頂点jが含まれていたとしても,頂点
jのk-近傍にiが含まれるとは限らない.対称化したP
に基づく隣接行列Aが表すk-近傍グラフは一般に,頂
点次数が一律でない非正則な(irregular)グラフとなる.
このため頂点次数がkよりも大きい頂点が作られ,ハブ
が現れる可能性が生じる.
3·2 相互k-近傍グラフ
その一方で,相互k-近傍グラフは頂点i,jの(元の類
似行列W における)k-近傍にお互いの頂点が含まれて
いる場合のみ,頂点間に辺を作るグラフとして定義され
る.これに対してk-近傍グラフは,頂点i,jのどちらか
一方のk-近傍にお互いの頂点が含まれている場合に頂点
間の辺を作る.したがって,同じ事例集合から同じパラ
メータkを用いてk-近傍グラフ,相互k-近傍グラフを計
算した場合,後者は前者の部分グラフとなる.
相互k-近傍グラフの構築は,k-近傍グラフの場合同様,
最適化問題(1)を解くことから始まるが,その後の対称
化のステップにおいて二値の対称行列P を,各要素が
Pij= min(Qij, Qji)となるように定義することで得られ
る.このminによって,頂点i, j双方から見てk近傍で
ある場合に限り,頂点間に辺を作る対称化が行なわれる.
この結果,構築された相互k-近傍グラフにおいて,頂点
次数はすべてk以下となり,k-近傍グラフのように極端
に高い頂点次数を作ることはない.
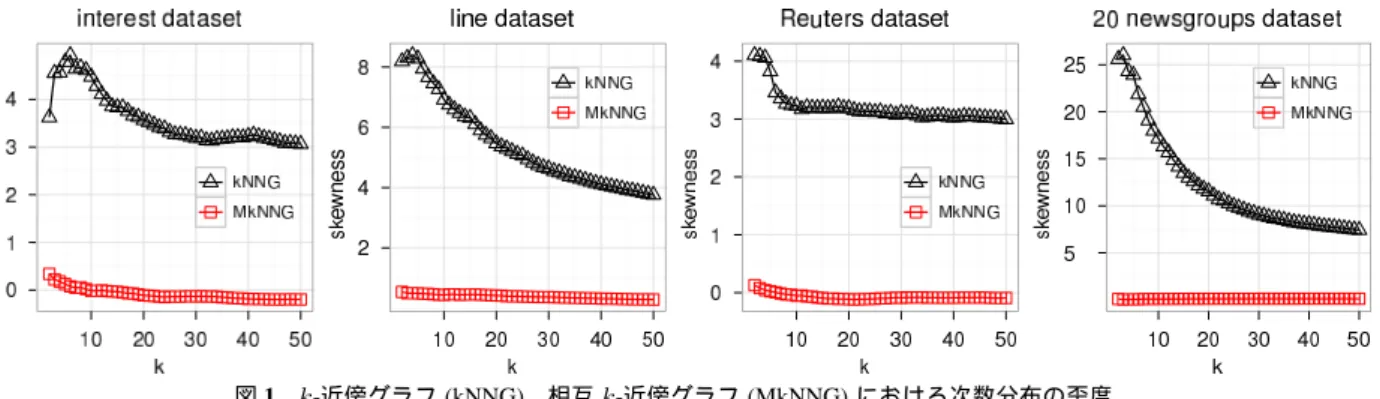
3·3 近傍グラフの歪度
k-近傍グラフは正則(つまり頂点次数が一律)とは限
らない.そこで実データにおいて,k-近傍グラフの頂点次
図1 k-近傍グラフ(kNNG),相互k-近傍グラフ(MkNNG)における次数分布の歪度 (skewness)を用いて調べた.歪度は統計学において分布
の非対称性を測る尺度として一般に用いられている.図
1では相互k-近傍グラフとk-近傍グラフを語義曖昧性解
消タスクと文書分類タスクのデータセット(詳細は6·1
節)から構築し,それぞれのグラフの頂点次数分布の歪
度を比較したものである.正の歪度は,分布が右に歪ん
でいることを表し,これは頂点次数の分布に当てはめる
と,ハブが出現していることを表す.なお,正則グラフ
の次数分布の歪度は0となる.図1から,k-近傍グラフ
における次数分布の歪度は相互k-近傍グラフと比較して
高い.特にkが小さい場合においてはk-近傍グラフは高
い歪度を持つ傾向がある.
3·4 分類におけるハブの影響
この節では,k-近傍グラフにおけるハブが半教師あり分
類に対して悪影響を及ぼすことを示す.そのために,我々
はk-近傍グラフにおける次数の高い頂点(つまりハブ)
を取り除き,その他の頂点の分類精度の変化を調べた.
こ の 予 備 実 験 に は ,語 義 曖 昧 性 解 消 タ ス ク に お け る
“line”データセット[Leacock 93]を用いた.データセッ
トをランダムに1:9の割合で分割し,前者の事例をラベ
ルあり事例,後者をラベルなし事例とみなし,ラベルな
し事例のラベルを予測する半教師あり分類の問題を考え
た.なお,このデータセットと問題設定は後で行う6章の
実験と同じである.詳細についてはそちらを参照のこと.
ま ず k-近 傍 グ ラ フ (k= 3) を デ ー タ セット か ら 構 築
し ,代 表 的 な グ ラ フ 半 教 師 あ り 分 類 法 で あ るGaussian
Random Fields (GRF) [Zhu 03]によってラベルなし事例
のラベルを予測した.さらに,30以上の頂点次数を持つ
頂点をハブとみなし,k-近傍グラフからこれらハブ頂点
とそれに接続する辺を取り除いたグラフを作成し,これ
に対してもGRFを適用した.
表1では2つのグラフにおけるGRFの分類精度を比
較している.この表では事例全体の分類精度と,ハブ頂
点からの距離(最小のホップ数)dによる層別の分類精
度を示している.“ハブ削除前”の行がk-近傍グラフに対
する結果を,“ハブ削除後”がそこからハブ頂点を取り除
いたグラフに対する結果を表している.ハブ頂点からの
距離ごと(各列ごと)に,最大の分類精度を太字で記し
表1 k-近傍グラフにおけるハブ頂点周辺の頂点の分類精度とハブ 頂点を取り除いたグラフにおける分類精度を,ハブ頂点から の距離(最小のホップ数)dごとに比較
d 1 2 ≥3 total
頂点数 1610 1947 164 3721
ハブ削除前 65.9 65.7 69.8 66.0 ハブ削除後 66.6 66.0 69.8 66.4
た.表から分類精度はハブを取り除いた後で向上してい
ることがわかる.また,ハブに近い頂点における分類精
度(d= 1,2)が向上している点も注目に値する.これら
の結果はグラフにおけるハブの出現が分類精度を悪くす
ることを示唆している.
4.
半教師あり分類のための相互
k
-
近傍グラフ
3·4節で示したように,ハブ頂点をk-近傍グラフから
取り除くことで半教師あり分類の精度を向上できた.し
かしながら,この方法は取り除く頂点の次数の閾値とい
うグラフ構築法のパラメータを増やす.また,取り除か
れたハブ頂点にラベルを割り当てる方法がないという問
題がある.したがって,k-近傍グラフのようにパラメー
タを1つしか持たず,同時にハブ頂点を作りにくいグラ
フ構築方法が望まれる.
本論文では,半教師あり分類のために相互k-近傍グラ
フを用いることを提案する.相互k-近傍グラフは新しい
概念ではないが,特に半教師あり学習の文脈でk-近傍グ
ラフに比べて用いた研究は皆無である.
4·1 非連結成分の解消
相互k-近傍グラフは,同一のkに対する標準的なk-近
傍グラフと比較して辺の数がより少ないことから,小さ
な非連結成分を含むグラフを作りやすい.クラスタリン
グにおいては(グラフを個々の成分に分けることが目的
であるため)非連結成分ができることは比較的大きな問
題ではないが,半教師あり分類に対しては悪影響が大き
い.というのも,多くのグラフ半教師あり分類法はグラ
フ上の辺に沿ってラベル情報を伝播し各頂点のラベルを
推定する.したがって,もしある連結成分にラベルあり
ムはその成分に含まれる頂点のラベルを予測できないか
らである.
この問題を解決する単純な方法として,我々は相互k
-近傍グラフに元の類似度行列W を隣接行列とみなした密
グラフ上の最大全域木を組み合わせた.正確には,最大全
域木のうち,重みの大きな辺から順番に,相互k-近傍グ
ラフでの異なる連結成分間を結ぶ辺を選び,グラフの連結
成分がただ1つになるまで辺を加えた.最大全域木の計算
には,グラフの辺の数をmとしたとき,O(m+nlogn)
の計算量が必要である[Cormen 09].今回は全頂点間の
類似度行列を隣接行列とする完全グラフを扱うため,辺
の数mはO(n
2)
であり,全体の計算量も同様にO(n
2)
となる.この計算量は,相互k-近傍グラフを構築する際
に必要な計算量より小さく,グラフ構築全体を通しての
計算量に影響を与えない.
4·2 計 算 の 効 率
標準的なk-近傍グラフはフィボナッチヒープ[Fredman
87]を用いることで,O(n
2+
knlogn)のならし計算量
(amortized complexity)で構築できる.相互k-近傍グラ
フも,k-近傍グラフ構築と同じ計算量で構築可能である.
これは以下の手続きにより標準的なk-近傍グラフから相
互k-近傍グラフに変換できることから明らかである.
(1) 優先度付きキュー(priority queue)をn個作成し,
入力として与えられたk-近傍グラフの各頂点に各々
を関連付ける.このキューはグラフの辺を格納する
ために用い,辺重みを優先度とする(重みが大きい
ほど優先度が高い).
(2) k-近傍グラフの各辺sについて,その両端の2頂
点のキューそれぞれに辺sを挿入する.
(3) それぞれのキューから,上位k個の重みを持つ辺
を取り出す.その際,別途用意した大域的なテーブ
ルに,各辺が全体として何回取り出されたかを記録
する.このステップで各辺が取り出される回数は,た
かだか2回であることに注意する(前ステップで,1
個の辺はちょうど2個のキューに入れられたため).
(4) 大域的テーブルを参照しながら,ステップ(3)で
キューから2回取り出された辺のみを残し,残りの
辺を削除すると,相互k-近傍グラフが得られる.
優 先 度 つ き キュー の 実 装 に フィボ ナッチ ヒ ー プ を 用 い ,
入力のk-近傍グラフは(重み付き)接続行列 (incidence
matrix)として表現されていると仮定すると,この手続き
の計算量はO(kn)である.このことから,相互k-近傍
グラフを構築する全体を通しての計算量は,標準的なk
-近傍グラフを構築する際に必要となる計算量を含めると O(n2+knlogn)
となる.
より効率良く求めることができる各種近似k-近傍グラ
フ(approximate k-nearest neighbor graph) [Beygelzimer
06, Chen 09, Ram 10, Tabei 10]に対しても,同様に上の
手続きを用いることで,対応する近似的「相互」k-近傍
グラフを効率的に作ることができる.
5.
関
連
研
究
5·1 b-マッチンググラフ
最近になって,b-マッチンググラフと呼ばれる新しい
グラフ構築方法が提案され,半教師あり分類においてk
-近傍グラフより高い分類精度を達成したと報告されてい
る[Jebara 09].b-マッチンググラフでは,すべての次数
が一様にbである(b-正則グラフ;b-regular graph).b
-マッチンググラフは次の最適化問題を解くことにより得
られる.
max
P∈Bn×n
ij
PijWij
s.t.
j
Pij =b, ∀i∈ {1, . . . , n} (4)
Pii= 0, ∀i∈ {1, . . . , n} (5)
Pij=Pji, ∀i, j∈ {1, . . . , n} (6)
Pが求められた後に,グラフの重み付き隣接行列Aは
Aij=PijWijにより決定される.制約(6)は二値行列P
を対称化し,(5)は自己との類似性(ループ)を無視する
ための制約であり,(4)の制約はグラフを正則グラフにす
るためのものである.3·1節のk-近傍グラフの最適化問
題と比較すると,最初の2制約((4)と(5))は(2), (3)と
同一であり,対称化制約(6)が追加されている点が異な
る.k-近傍グラフでは,対称化を最適化の際の制約とせ
ず,後処理としてグラフの無向化を行うため,最終的に
得られるグラフは一般的には正則グラフではない.一方,
b-マッチンググラフでは,行列の対称性を最適化の際の
制約として用い,直接正則なグラフを求める.
しかしながら,k-近傍グラフでは簡単な問題であった
ものが,対称性制約(6)の追加によって高い計算コストが
必要な最適化問題となる.Jebaraら[Jebara 09]はbelief
propagationを用いた二部グラフのb-マッチング問題の解
法アルゴリズム[Huang 07]を拡張しb-マッチンググラ
フを構築しているが,最悪の場合の時間計算量はO(bn
3)
であり,これは規模の大きなグラフに対しては実用的で
はない.k-近傍グラフと相互k-近傍グラフは4·2節 で
議論した通り,はるかに小さな時間計算量で構築するこ
とができる.6章 では,b-マッチンググラフと相互k-近
傍グラフの性能について比較実験を行う.
5·2 ǫ-近 傍 グ ラ フ
ǫ-近傍グラフは,閾値ǫより大きい類似度の頂点間に
のみ辺を作る典型的な近傍グラフの構築手法であり,k
-近傍グラフとの比較のためによく用いられる.このグラ
フ構築法は,閾値ǫが適切でないとき,構築されるグラ
表2 実験に使用したデータセット
データセット 事例の数 特徴量の数 クラス数
“interest” 2,368 3,689 6
“line” 4,146 8,009 6
Reuters 4,028 17,143 4
20 newsgroups 19,928 62,061 20
の調節が難しい.ǫ-近傍グラフは一貫して悪いパフォー
マンスを与えると報告されていることから[Jebara 09],
本論文ではǫ-近傍グラフは取り扱わない.
5·3 クラスタリングにおける相互近傍グラフ
Maierら[Maier 09]はクラスタリングの文脈における相
互k-近傍グラフに対してrandom geometric graph theory
を用いた理論的な分析を行っている.彼らの分析による
と,もっぱら最大クラスターの同定に関心がある場合に
は,相互k-近傍グラフは優れたクラスタリング結果を与
えるという.しかしながら,この分析結果から,半教師
あり分類に関する影響について何らかの結論を導けるか,
は明らかではない.
6.
実
験
我々はk-近傍グラフ,相互k-近傍グラフ,b-マッチング
グラフを語義曖昧性解消タスクと文書分類タスクにおい
て比較した.いずれもマルチクラス分類のタスクである.
6·1 タスクとデータセット
§1 語義曖昧性解消
語義曖昧性解消の目的は,用例の出現文脈の類似度を
手がかりにして,語義が未知の用例の語義を推測するこ
とである.語義をクラスと考え,語義が既知の用例(ラ
ベルあり事例)少量と,未知の用例(ラベルなし事例)が
大量に与えられれば,半教師付き分類の問題とみなせる.
実験には,語義曖昧性解消の代表的な評価データセッ
トである“interest”と“line”を用いた.“interest”データ
[Bruce 94] は,Wall Street Journalコーパスから多義語
“interest”の用例を集め,それぞれに対して6語義のう
ち1つ を 人 手 で 割 り 振った も の で あ る .候 補 の6語 義
は,辞書Longman Dictionary of Contemporary English
に あ る 定 義 か ら 採 用 さ れ て い る .一 方 の“line”デ ー タ
[Leacock 93]は多義語“line”の用例を集めたもので,各
用例はWordNetシソーラス上の6語義のうちの1つが
割り振られている.
実験においては[Niu 05]に倣い,文脈特徴量として,
近隣する語の品詞,周辺文脈の語,局所的なコロケーショ
ン,の3種類を用いた.文脈特徴量の詳細については[Lee
02]を参照のこと.
§2 文書分類
文書分類実験ではReutersと20 newsgroupsという2
つのデータセットを用いた.Reutersデータセットはテ
キスト分類のテストコレクションRCV1-v2/LYRL2004
[Lewis 04]における4つの大カテゴリ(企業,経済,政
治,市場)からランダムに約4,000文書を選んで実験用
データセットを作成した.特徴量には[Lewis 04]で説明
されているものを用いた.20 newsgroupsデータセット
は文書分類やクラスタリングにおいてよく用いられる.
このデータセットは元々は[Lang 95]により作られ,20
個のUsenetニュースグループに投稿された20,000近く
のメッセージから構成される.各メッセージは,[Rennie
01]に記述された二値のbag-of-words特徴量によって表
現されており,投稿先のニュースグループを表すラベル
が割り当てられている.表2に実験に用いたデータセッ
トの性質についてまとめた.
6·2 クラスラベルに対するassortativityの比較
まず,グラフ構築法の良し悪しを特定の分類アルゴリ
ズムに依存することなく評価するために,k-近傍グラフ,
相互k-近傍グラフ,b-マッチンググラフのそれぞれについ
て,クラスラベルに対するassortativity係数[Newman
03] (以下,単にassortativityと呼ぶ)を計算し比較した.
Assortativityは主に隣接する頂点間の次数相関を調べる
ために用いられるが,カテゴリカルデータに対しての尺
度も同様に定義されており,本論文ではこれを用いて構
築されたグラフの質の評価を行った.カテゴリカルデー
タに対するassortativityrは以下のように定義され,隣
り合った頂点がどの程度同じクラスラベルを持つかの指
標とみなせる.
r=
ieii−ia
2
i
1−ia
2
i
(7)
ここで,eijはあるクラスラベルi, jでラベル付けされてい
る頂点間を結ぶ辺の数を,グラフ全体の辺の数で正規化し
た値であり,aiはあるクラスラベルiでラベル付けされて
いる頂点を結ぶ辺の数を,グラフ全体の辺の数で正規化し
た値(すなわちai=jeij)と定義される.eij, aiはそれ ぞれ正規化された値であるため,
ijeij= 1,
iai= 1
となる.本論文で扱うグラフは無向グラフであるため対
称性eij=ejiがある.
ほとんどのグラフ半教師あり分類手法は辺に沿ってラ
ベル情報を伝播するために,異なるクラスラベルを持つ
頂点間を結ぶ辺は誤った分類を引き起こす可能性がある.
したがって,隣り合った頂点間のクラスラベルが一致す
る頻度(すなわちassortativity)が高いほど望ましいグラ
フであるといえる.
各 デ ー タ セット か らk-近 傍 グ ラ フ,相 互k-近 傍 グ ラ
フ,b-マッチンググラフをパラメータk, bの値を変えな
図2 k-近傍グラフ(kNNG),相互k-近傍グラフ(MkNNG),b-マッチンググラフ(bMG)におけるクラスラベル に対するassortativityの比較.
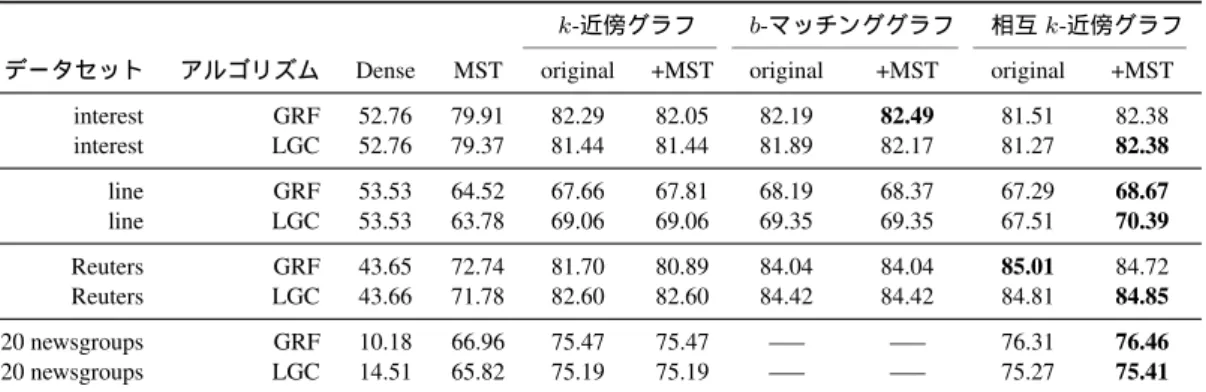
表3 語義曖昧性タスクと文書分類タスクにおける分類精度の比較
k-近傍グラフ b-マッチンググラフ 相互k-近傍グラフ
データセット アルゴリズム Dense MST original +MST original +MST original +MST interest GRF 52.76 79.91 82.29 82.05 82.19 82.49 81.51 82.38 interest LGC 52.76 79.37 81.44 81.44 81.89 82.17 81.27 82.38
line GRF 53.53 64.52 67.66 67.81 68.19 68.37 67.29 68.67
line LGC 53.53 63.78 69.06 69.06 69.35 69.35 67.51 70.39
Reuters GRF 43.65 72.74 81.70 80.89 84.04 84.04 85.01 84.72 Reuters LGC 43.66 71.78 82.60 82.60 84.42 84.42 84.81 84.85
20 newsgroups GRF 10.18 66.96 75.47 75.47 —– —– 76.31 76.46
20 newsgroups LGC 14.51 65.82 75.19 75.19 —– —– 75.27 75.41
のが 図2である.図におけるy軸は構築されたグラフ
のassortativityを表しており,x軸は構築されたグラフの
辺の数を表している.パラメータk, bをx軸としなかっ
たのは,これらパラメータの手法ごとの意味付けが異る
ため,同じ値どうしの比較が意味を持たないためである.
実際,これらパラメータをすべて同じ値に設定したとし
ても,各種法で構築されるのは全くスパースさ(辺の数)
が異なるグラフである.
先に言及した通り,assortativityは高いほど望ましい.
図から,構築されたグラフが同程度のスパースさを持つ
場合には,相互k-近傍グラフが他の2手法より高い
as-sortativityを持っていることがわかる.
20 newsgroupsデータにおいてb-マッチンググラフの
結果が含まれていないが,これはすべてのbに対するグ
ラフ構築が一週間以内に終了しなかったためである
∗4
.一
方で,k-近傍グラフと相互k-近傍グラフは同じ計算機に
て同じデータセットのためのグラフを15分ほどで構築
することができた.
6·3 分 類 実 験
§1 実験設定
半教師あり分類の設定を模倣するため,データセット
の全事例のうちランダムに選択した10%をラベルあり事
∗4 すべての実験は2.3 GHz AMD Opteron 8356 processors, 256GB RAMの計算機上にて行った.b-マッチンググラフ構築アルゴ リズムは,他のアルゴリズムの実装と条件を揃えるため,また Jebaraらの実装にメモリーリークがあったために,Jebaraらの 実装をもとにC++で再実装した.
例として扱い,残りの90%をラベルなし事例とみなした.
この状況で,ラベルなしとされた事例のラベルを推定す
るのがタスクである.実験結果の信頼性を保証するため,
各データセットについてそのような1 : 9のランダムな
データセット分割を10通りずつ作成した.
データセットから,比較対象の3種類のグラフ構築法
それぞれを用いてグラフを構築し,同一のグラフ半教師
あり分類アルゴリズムを適用する.先に作った10通りの
データ分割に対する平均の分類精度を計算し,グラフ構
築法の評価とする.分類アルゴリズムには最もよく用い
られているGaussian Random Fields (GRF) [Zhu 03]と
Local/Global Consistency (LGC) [Zhou 03]の2種類を用
いた.事例間の類似度尺度(すなわち行列W の要素)と
しては,語義曖昧性解消タスクと文書分類タスクにて一
般的に用いられているコサイン類似度を用いた.
グラフ構築法のパラメータ(kあるいはb)は2分割
交差検定により決定した.具体的には,まずラベルあり
データを2分割してそれぞれを訓練用事例と開発用事例
として用い,k, b∈ {2, . . . ,50}から最適なパラメータを
決定した.LGCのスムージングパラメータµはµ= 0.9
に固定した.
§2 分類結果
表3に語義曖昧性タスクと文書分類タスクの各データ
セットにおける分類精度をまとめた.各データセットと
分類アルゴリズムの組み合わせにおいて,最も高い分類
精度を太字で記している.ベースラインとしてグラフを
表4 相互k-近傍グラフと他のグラフの平均分類精度に対する片側 paired t-testの結果
データセット・手法 vs.kNNG (+MST) vs.bMG (+MST)
interest (GRF) ∼ ∼
interest (LGC) ∼ ∼
line (GRF) ∼ ∼
line (LGC) > ∼
Reuters (GRF) ≫ ∼
Reuters (LGC) ≫ ∼
20 newsgroups (GRF) ≫ —–
20 newsgroups (LGC) > —–
グラフの隣接行列として使った場合の結果を‘Dense’と
して表記している.また隣接行列W から最大全域木を
求め,これをグラフ構築法として用いた結果を‘MST’と
表記し表に加えた.4·1節 にて述べたグラフの非連結性
を解消するために,最大全域木を組み合わせた場合の結
果を‘+MST’の列に記した.多くのケースにおいて相互
k-近傍グラフは他のグラフ構築法と比較して優れた分類
精度を達成していることが確認できる.
表4はk-近傍グラフとb-マッチンググラフに対して,提
案する相互k-近傍グラフと最大全域木の組み合わせによ
る平均分類精度における片側paired t-testの結果を表して
いる.“≫”,“>”,“∼”はそれぞれp-valueがp <0.01, p∈(0.01,0.05],p >0.05の場合に対応している.表4
から,文書分類タスクにおいて相互k-近傍グラフはk-近
傍グラフと比較して有意に良い結果であることがわかる.
一方で,b-マッチンググラフと相互k-近傍グラフの精度
には有意な差は見られなかった.しかしながら,相互k
-近傍グラフはb-マッチンググラフより少ない時間計算量
を持ち大きなデータセットに対しても適用可能である上,
同程度の分類精度を達成している.
7.
ま
と
め
グラフ半教師あり分類において,標準的なk-近傍グラ
フに代わり相互k-近傍グラフを用いることを提案した.
相互k-近傍グラフではすべての頂点次数はkで押さえ
られるためハブが生じにくく,さらにクラスター仮説に
より忠実なグラフとなっていることを,様々な自然言語
処理データセットにおいて確認した.広く用いられてい
る2種類のラベル伝搬法をこれらのデータに適用する場
合,データからのグラフ構築に標準的なk-近傍グラフを
用いた場合よりも,相互k-近傍グラフを用いた方が,よ
り高い分類精度が得られた.相互k-近傍グラフにおいて
生じやすいグラフの非連結性は,最大全域木をグラフに
加えることで深刻な問題とはならなかった.しかしなが
ら,得られる精度改善の程度はデータセットごとにばら
つきがあり,どのような条件のもとで大きな改善が得ら
れるかは明確ではない.したがって,今後の課題として
相互k-近傍グラフ構築が分類アルゴリズムに与える影響
の理論的な分析を検討する.
またk-近傍グラフの計算に全点間の類似度計算を必要
とするため,本論文では大規模なデータセットに関する
実験は行なっていない.ウェブデータなどの大規模なラ
ベルなしデータとグラフ構築の近似アルゴリズムを活用
することでより高い分類精度を達成できる可能性がある.
大規模なデータセットにおける相互k-近傍グラフの効果
を調査し,大規模なデータセットに対して適切なグラフ
構築法を提案することもまた重要な課題であり,今後取
り組む.
謝 辞
本研究は一部科研費基盤(B) 2430057の支援を受けた.
♦
参
考
文
献
♦
[Alexandrescu 07] Alexandrescu, A. and Kirchhoff, K.: Data-driven graph construction for semi-supervised graph-based learning in NLP, inProc. of Human Language Technology: The 2007 Annual Confer-ence of the North American Chapter of the Association for Compu-tational Linguistics (NAACL-HLT ’07), pp. 204–211 (2007) [Alexandrescu 09] Alexandrescu, A. and Kirchhoff, K.: Graph-based
learning for statistical machine translation, inProc. of Human Lan-guage Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT ’09), pp. 119–127 (2009)
[Beygelzimer 06] Beygelzimer, A., Kakade, S., and Langford, J.: Cover trees for nearest neighbor, inProc. of the 23rd International Conference on Machine Learning (ICML ’06), pp. 97–104 (2006) [Bruce 94] Bruce, R. and Wiebe, J.: Word-sense disambiguation
us-ing decomposable models, inProc. of the 32nd Annual Meeting of the Association for Computational Linguistics (ACL ’94), pp. 139– 146 (1994)
[Callut 08] Callut, J., Franc¸oisse, K., Saerens, M., and Dupont, P.: Semi-supervised classification from discriminative random walks, inProc. of the 2008 European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD ’08), pp. 162–177 (2008)
[Chen 09] Chen, J., Fang, H.-r., and Saad, Y.: Fast approximate kNN graph construction for high dimensional data via recursive Lanczos bisection,Journal of Machine Learning Research, Vol. 10, pp. 1989– 2012 (2009)
[Cormen 09] Cormen, T. H., Leiserson, C. E., Rivest, R. L., and Stein, C.: Introduction to Algorithms, The MIT Press, 3rd edition (2009)
[Fredman 87] Fredman, M. L. and Tarjan, R. E.: Fibonacci heaps and their uses in improved network optimization algorithms,Journal of the ACM, Vol. 34, pp. 596–615 (1987)
[Gammerman 98] Gammerman, A., Vovk, V., and Vapnik, V.: Learn-ing by transduction, inProc. of 14th Conference on Uncertainty in Artificial Intelligence (UAI ’98), pp. 148–155 (1998)
[Ghazvininejad 11] Ghazvininejad, M., Mahdieh, M., Rabiee, H. R., Roshan, P. K., and Rohban, M. H.: Isograph: Neighbourhood graph construction based on geodesic distance for semi-supervised learn-ing, inProc. of: 11th IEEE International Conference on Data Mining (ICDM ’11), pp. 191–200 (2011)
[Goldberg 06] Goldberg, A. B. and Zhu, X.: Seeing stars when there aren’t many stars: Graph-based semi-supervised learning for sen-timent categorization, inProc. of TextGraphs Workshop on HLT-NAACL, pp. 45–52 (2006)
[Jebara 09] Jebara, T., Wang, J., and Chang, S.-F.: Graph construction and b-matching for semi-supervised learning, inProc. of the 26th International Conference on Machine Learning (ICML ’09), pp. 441– 448 (2009)
[Lang 95] Lang, K.: Newsweeder: Learning to filter netnews, inProc. of the 12th International Conference on Machine Learning (ICML ’95), pp. 331–339 (1995)
[Leacock 93] Leacock, C., Towell, G., and Voorhees, E.: Corpus-based statistical sense resolution, inProc. of the 1993 ARPA Work-shop on Human Language Technology (HLT ’93), pp. 260–265 (1993)
[Lee 02] Lee, Y. K. and Ng, H. T.: An empirical evaluation of knowl-edge sources and learning algorithms for word sense disambiguation, inProc. of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP ’02), pp. 41–48 (2002)
[Lewis 04] Lewis, D. D., Yang, Y., Rose, T. G., Li, F., Dietterich, G., and Li, F.: RCV1: A new benchmark collection for text categoriza-tion research,Journal of Machine Learning Research, Vol. 5, pp. 361–397 (2004)
[Maier 09] Maier, M., Hein, M., and Luxburg, von U.: Optimal con-struction of k-nearest-neighbor graphs for identifying noisy clusters,
Theoretical Computer Science, Vol. 410, pp. 1749–1764 (2009) [Newman 03] Newman, M. E. J.: Mixing patterns in networks,
Phys-ical Review E, Vol. 67, No. 2, p. 026126 (2003)
[Niu 05] Niu, Z.-Y., Ji, D.-H., and Tan, C. L.: Word sense disam-biguation using label propagation based semi-supervised learning, in
Proc. of the 43rd Annual Meeting of the Association for Computa-tional Linguistics (ACL ’05), pp. 395–402 (2005)
[Radovanovi´c 10] Radovanovi´c, M., Nanopoulos, A., and Ivanovi´c, M.: Hubs in space: Popular nearest neighbors in high-dimensional data, Journal of Machine Learning Research, Vol. 11, pp. 2487–2531 (2010)
[Ram 10] Ram, P., Lee, D., March, W., and Gray, A.: Linear-time algorithms for pairwise statistical problems, inAdvances in Neural Information Processing Systems 23: Proc. of the 2010 NIPS Confer-ence, pp. 1527–1535 (2010)
[Rennie 01] Rennie, J. D. M.: Improving multi-class text classifi-cation with naive Bayes, Master’s thesis, Massachusetts Institute of Technology (2001), Also available as MIT AI Technical Report AITR-2001-004
[Szummer 02] Szummer, M. and Jaakkola, T.: Partially labeled clas-sification with Markov random walks, inAdvances in Neural Infor-mation Processing Systems 15: Proc. of the 2002 NIPS Conference, pp. 945–952 (2002)
[Tabei 10] Tabei, Y., Uno, T., Sugiyama, M., and Tsuda, K.: Single versus multiple sorting in all pairs similarity search, inProc. of the Second Asian Conference on Machine Learning (ACML ’10), Vol. 13, pp. 145–160 (2010)
[Wang 08] Wang, J., Jebara, T., and Chang, S.-F.: Graph transduction via alternating minimization, inProc. of the 25th International Con-ference on Machine Learning (ICML ’08), pp. 1144–1151 (2008) [Zhou 03] Zhou, D., Bousquet, O., Lal, T. N., Weston, J., and
Sch¨olkopf, B.: Learning with local and global consistency, in Ad-vances in Neural Information Processing Systems 16: Proc. of the 2003 NIPS Conference, pp. 321–328 (2003)
[Zhu 03] Zhu, X., Ghahramani, Z., and Lafferty, J. D.: Semi-supervised learning using Gaussian fields and harmonic functions, inProc. of the 20th International Conference on Machine Learning (ICML ’03), pp. 912–919 (2003)
[Zhu 05] Zhu, X.:Semi-supervised Learning with Graphs, PhD the-sis, Carnegie Mellon University (2005), CMU-LTI-05-192 [Zhu 08] Zhu, X.: Semi-supervised Learning Literature Survey,
Tech-nical Report 1530, Department of Computer Sciences, University of Wisconsin-Madison (2008)
〔担当委員:花沢 健〕
2012年12月1日 受理
著 者 紹 介
小嵜 耕平
2009年東京理科大学理工学部情報科学科卒.2011年奈良
先端科学技術大学院大学情報科学研究科博士前期課程修了. 同年より奈良先端科学技術大学院大学情報科学研究科博士
後期課程に入学.情報処理学会,ACL各会員.
新保 仁(正会員)
1992年京都大学工学部電気工学第二学科卒.1994年同大
学院工学研究科修士課程電気工学第二専攻修了.1997年
同大学院工学研究科博士後期課程情報工学専攻研究指導認
定退学.博士(工学).現在奈良先端科学技術大学院大学情
報科学研究科准教授.ACM会員.
小町 守(正会員)
2005年東京大学教養学部基礎科学科科学史・科学哲学分
科卒.2010年奈良先端科学技術大学院大学情報科学研究
科博士後期課程修了.博士(工学).同年より同研究科助
教を経て,2013年より首都大学東京システムデザイン学
部准教授.専門は自然言語処理.大規模なコーパスを用い た意味解析および統計的自然言語処理に関心がある.情報
処理学会,言語処理学会,ACL各会員.
松本 裕治(正会員)
1977年京都大学工学部情報工学科卒.1979年同大学大学
院工学研究科修士課程情報工学専攻修了.同年電子技術総
合研究所入所.1984∼85年英国インペリアルカレッジ客
員研究員.1985∼87年(財)新世代コンピュータ技術開発
機構に出向.京都大学助教授を経て,1993年より奈良先
![表 2 実験に使用したデータセット データセット 事例の数 特徴量の数 クラス数 “interest” 2,368 3,689 6 “line” 4,146 8,009 6 Reuters 4,028 17,143 4 20 newsgroups 19,928 62,061 20 の調節が難しい. ǫ- 近傍グラフは一貫して悪いパフォー マンスを与えると報告されていることから [Jebara 09] , 本論文では ǫ- 近傍グラフは取り扱わない. 5 ·3 クラスタリングにおける相互近傍グラフ Maier](https://thumb-ap.123doks.com/thumbv2/123deta/6437477.151518/6.892.95.401.147.239/データセットデータセットクラスパフォー取り扱わクラスタリング.webp)