OpenACC
を用いた
MPS
法の近傍粒子探索の最適化
宮島 敬明
1,a)藤田 直之
1概要:Moving Particle Semi-implicit (MPS)法は流体力学などの分野で利用される粒子法の一種である。 計算対象となる物体や流体などの連続体は仮想粒子に分割され、各粒子は近傍の粒子と相互に作用しあう。 相互作用の対象となる近傍粒子の探索は、MPS法の演算の主要なボトルネックとなっている。本研究報告 では、宇宙航空研究開発機構の内製MPSコードに存在する最大値探索と近傍粒子探索をOpenACCを用 いてGPUへの移植と最適化を行った。それぞれ、大小2種類のデータセットと4種類のGPU(NVIDIA K20c、GTX1080、P100(PCIe)、P100(NVlink))で評価する。最大値探索では5種類の最適化を行い、追 加するOpenACCのディレクティブによって最大で3.5倍の性能差が出た。近傍粒子探索では3種類の最 適化を実装し、マルチスレッドのFortran実装に対し、小さなデータセットでは29.0倍、大きなデータ セットでは74.5倍の高速化を達成した。また、データセットとGPUの特徴、カーネルの計算負荷の関係 についても議論する。
1.
はじめに
MPS
法は大変形を伴う非圧縮性流体のシミュレーショ ンに用いられ、粒子法に分類される[1]
。空間を格子状に 分割し、各格子が物理量を保持する格子法と異なり、移動 する粒子が物理量を持っている。図1
にMPS
法による水 柱崩壊問題のシミュレーション結果を示す。各粒子の速度 などの物理量は近傍粒子との相互作用を元に計算されるた め、全粒子がそれぞれの近傍粒子を探索する必要がある。 この近傍粒子探索は大量のメモリリクエストを必要とし、 シミュレーション時間において大半を占めている。MPS
法のCUDA
を用いたGPU
への実装はいくつかの先行研 究が存在する[2] [3] [4]
が、OpenACC
を用いたGPU
への 移植・最適化は例がない。OpenACC
は近年登場したGPU
向けのAPI
であり、コンパイラ・ディレクティブやラインタイム・ライブラリ、環 境変数を提供する
[5]
。ユーザがディレクティブとそれに付 随する節(clause)
を既存のコードに追加すると、コンパイ ラが自動的にGPU
向けのコードを自動生成する。CUDA
やOpenCL
などの専用言語に比べ、既存コードを素早く移 植・実装でき、ポータビリティも高い。しかし、並列計算 に知識と対象のGPU
アーキテクチャの知識が必要である。 本研究報告では、我々のユニットが研究・開発中のMPS
コード
”NSRU-MPS”
を対象とする。NSRU-MPS
は For-1 宇宙航空研究開発 航空技術部門 数値解析技術研究ユニット 計算情報基盤セクション 〒182-8522東京都調布市深大寺東町7-44-1 a) [email protected]tran 95
で記述され、MPI
によって領域分割が行われてい る。OpenMP
などを用いたスレッドレベルの並列化は行わ れていない。最大値探索と近傍粒子探索を行う2
つのサブ ルーチンを選定し、OpenACC
を用いて移植・最適化した。 最大値探索では追加するディレクティブによる性能の差 を評価し、近傍粒子探索では、シングルスレッドとマルチ スレッド実装のCPU
と比較を行う。評価には大小2
種類 のデータセットと4
種類のGPU
を利用した。また、GPU
アーキテクチャとデータセットの組み合わせによって、最 適な実装が異なった理由についても議論する。2.
MPS
法
MPS
法の計算精度は計算対象をいくつの粒子に分割する かによって大きく左右される。室谷らの研究では、4.0km
× 3.5km
の津波のシミュレーションに2
億6
千万個の粒子 を利用している[6]
。各粒子が独立して近傍粒子を探索し相 互作用を計算するため、並列度は粒子数に比例して増加す るが、メモリリクエストが増加する。その結果、計算時間 の大半が近傍粒子探索となり、この部分の高速化がMPS
法全体の高速化の鍵となる。2.1
支配方程式MPS (Explicit MPS
法)
は2
段階のフラクショナル・ス テップ法を用いており、以下の計算ステップを目的のシミュ レーション時間に到達するまで繰り返す。なお、r
j− r
iは 対象粒子i
と近傍粒子j
との距離計算を示す。Proc 0)
シミュレーションの初期値を設定図1: MPS法のシミュレーション例:水中崩壊問題
Proc 1)
仮速度の計算Proc 2)
粒子の仮位置を計算Proc 3)
密度の計算Proc 4)
密度勾配の計算Proc 5)
粒子の位置を計算Proc 6)
次の時間ステップへ(Proc 1
∼6
を繰り返す)Proc 0)
シミュレーションの初期値を設定MPS
法では初期値として、近傍粒子の距離の重み平均λ
0と初期の粒子数密度n
0、初期の密度ρ
を求める。λ
0=
∑
j̸=i′(
|r
0j− r
0i′|)
2ω(
|r
0j− r
0i′|)
∑
j̸=i′ω(
|r
0j− r
0i′|)
(1)
n
0=
∑
j̸=i′ω(
|r
0j− r
0i′|)
(2)
Proc 1)
仮速度の計算 計算ループでは、まず下式を用いて各粒子の仮速度を求 める。右辺第2
項と第3
項はそれぞれ粘性と重力である。u
∗i= u
k i+∆t
(
ν
2d
λ
0n
0∑
j̸=i(u
k j−u
ki)ω(
|r
j−r
i|)
)
+g(3)
ただし、kはタイムステップ、tは実時間、iとj
は粒子の 番号、νは動粘性率、dはシミュレーションの次元数、gは 重力加速度、uk i は時刻k
での粒子i
の速度、u∗i は時刻k
での粒子i
の仮速度である。Proc 2)
粒子の仮位置を計算 続いて、Proc 1
で得られた仮速度を用いて各粒子の仮位 置を求める。r
∗i= r
ki+ ∆tu
∗i(4)
ただし、rki は時刻k
での粒子i
の位置である。Proc 3)
密度の計算 その後、各粒子の次のタイムステップの圧力を求める。n
∗i=
∑
j̸=iω(
|r
∗j− r
∗i|)
(5)
図2: バケット法を用いた近傍粒子探索:計算領域は矩形のバ ケットに区切られ、計算対象の粒子(赤い粒子)は隣接 するバケットのみから近傍粒子を探索するP
ik+1= c
2ρ
0n
0(n
∗ i− n
0)
(6)
ただし、Pik+1は時刻k
での粒子i
の圧力、c
は音速、n
∗iは 時刻k
での粒子i
の仮の粒子数密度である。Proc 4)
密度勾配の計算 そして、各粒子の圧力から圧力勾配を求める。 ⟨▽P ⟩k+1 i = d n0 ∑ j̸=i ( (Pik+1+ P k+1 j )(rj− ri) |rj− ri|2 ωgrad(|rj− ri|) ) (7) ただし、ωgradは2.3節で述べる重み関数である。Proc 5)
粒子の位置を計算 最後に、次のステップの最終的な速度と位置を求める。 uk+1i = u∗i − ∆t ( 1 ρ▽ P )k+1 i (8) rk+1i = r∗i− ∆t ( 1 ρ▽ P )k+1 i (9) ただし、uk+1i とr k i は時刻k + 1での粒子iの粒子の速度と位 置である。Proc 6) Forward time step
次のタイムステップの計算を開始するために、粒子の最大速 度uから実時間∆tを求める。
2.2
近傍粒子探索 MPSは式5に代表されるように、1タイムステップの中で 複数回の近傍粒子探索を行う。式5では粒子数密度を求める ために、近傍粒子を探索し、見つけた粒子の物理量を対象の粒 子に足しこむ。各粒子によって近傍粒子は異なり、それぞれが 時々刻々移動するため、毎回計算を行わなければならない。近 傍粒子探索は最も負荷の高い計算であり、Smoothed Particle Hydrodynamics(SPH)法やN体問題に類似している。探索を 簡単化するために、バッケット法や双方向リスト法、ハッシュ 法、ブックキーピング法などの手法が提案されている[2] [7] [3]。 NSRU-MPSが採用するバケット法は、計算領域をバケットと図3: NSRU-MPS の 計 算 時 間 の 内 訳 。 Laplacian u と cal nden、grad p explicitが近傍粒子探索を行っている
呼ばれる格子に区切り、隣接するバケット内部の粒子のみを探 索の対象とすることで計算量を減少させる手法である。図2に バケット法を用いた近傍粒子探索の概要を示す。計算対象の粒 子の値は、隣接するバケット内の各近傍粒子の距離に応じた物 理量を足しこんで総和することで求められる。近傍粒子探索は 探索と距離計算、重みの計算、物理量の総和によって成り、計 算領域の全粒子がそれぞれにこの処理を行う。単純な並列化で は、物理量の足しこみの際にRead-After-Write(RAW)ハザー ドを起こしてしまうため、注意が必要である。
2.3
重み関数 MPSは式10や式11のように、重み関数を1タイムステッ プの中で複数回行う。図2に示す赤い点線の円は影響範囲と呼 ばれ、円の内部にある粒子は距離に応じて重みが加えられ、物 理量を計算対象の粒子に加算する。重みは距離のみで決定され、 式10が圧力勾配の計算、式11がそれ以外の計算に用いられる ωgrad(r) = re r − r re (10) ω(r) =re r − r re − 2 (11) ただし、reは影響範囲の半径、rは粒子iとjの距離である。2.4
NSRU-MPS
NSRU-MPSは、陽解法のMPS法(Semi-implicit MPS)を 採用して計算負荷を減らすとともに、単純な領域分割によって フラットMPI化を実現している。NSRU-MPSは大まかに粒子 の位置ri、速度ui、仮の速度ui∗、圧力Pi、仮の位置r∗i、圧 力勾配⟨▽P ⟩i、粒子数密度ni、粒子番号i、の9種類配列を 持っている。粒子番号i以外は単精度浮動小数点で表され、AoS (Array of Structure)形式の粒子の個数分だけの長さを持った 独立した配列として宣言されている。 予備評価として、移植前のシングルスレッド実装の処理時間 を大小2種類の水中崩壊問題のデータ・セットで計測した。評 価環境は、2ソケットのIntel Xeon E5-2697 v2 @ 2.7GHz(12 物理コア、24論理スレッド)と、128GBのDDR3-12800メモ リを搭載したシングルノードのマシンである。データセットは、図4: CPU-GPU間の実行バンド幅。NVlinkがPCIe Gen3の
最大2.7倍の実行性能となった 小規模のものが35×35×7バケットで25,704個の粒子を持った もの、大規模のものが70×70×14バケットで224,910個の粒子 を持ったものである。データセット大はデータセット小の8.75 倍の粒子を保持している。時間計測にはMPI Wtimeを用い、 最初の200タイムステップの平均をとった。MPIプロセス数は 2で、データセット大では各プロセスに112,455 個の粒子が、 データセット小ではプロセス0に14,688個の粒子、プロセス1 に11,016個の粒子が割り当てられている。 図3にNSRU-MPSのプロファイル結果を示す。Laplacian u とgrad p ex-plicit、cal ndenの3つのサブルーチンの合計の 計算時間が全計算時間の86%と89%を占めている。それぞれ、 計算ステップ1と4、3に相当し、内部で近傍粒子探索を行っ ている。なお、データセット小でのLaplacian uの処理時間は 252.8[ms]であった。これ以外のサブルーチンは、衝突の計算 を行うelastic collisionが全計算時間の9%と10%を占め、それ 以外が2%程度を占める結果となった。
3.
OpenACC
を用いた移植と最適化
ここからは、timestep サブルーチン内の最大値探索と近傍 粒子探索を行うLaplacian uサブルーチンの移植と最適化につ いて述べる。評価にはTesla K20c, GeForce GTX1080, Tesla P100(NV-link), P100(PCIe)の4種類のGPUを利用した。表1 に各GPUの詳細を示す。計算ノードは2CPUと2GPUを持ち、 各GPUがCPUに接続されている。コンパイラは2種類のPGI Fortran Compilerを利用した。K20cとGTX1080, P100(PCIe) については、x86-64版(ver 16.10)を利用した。P100(NVlink) については、linuxpower版(ver 16.10)を利用している。コンパ イラオプションは、“-acc -ta=nvidia, cuda8.0, fastmath, cc60” であるが、K20cについては、cc60でなくcc35を利用した。 MPI通信にはOpenMPI 1.10.2を利用し、各CPUに1プロセ スを割り当て、1プロセスが1GPUを専有する形とした。なお、timestepとLaplacian uのどちらにもMPI通信は存在しない。 その他の時間計測方法やシミュレーションの設定は、2.4節と 同様である。
各計算ノードの予備評価として、CPU-GPU間のデータ転 送のバンド幅について評価を行った。4種類の計算ノードはそ
はPCI-Express Generation 2 x16、GTX1080とP100(PCIe)は PCI-Express Generation 3 x16、P100(NVlink)はNVlinkを持 つ。図4に実効バンド幅と転送データサイズの関係を示す。 NVlinkは論理ピーク性能の82.7%を達成し、PCIe Gen3 x16 に比べて2.7倍のバンド幅を持つ。40KB以下のデータサイズ についてはGTX1080が最も高い性能を見せている。これは、 GTX1080の動作周波数がP100に比べて330MHz高いためで あると考える。
3.1
timestep
サブルーチンの最大値探索 ここでは、OpenACCと各GPUノードの特性を理解するた めに、比較的簡単なサブルーチンを移植・最適化の対象とする。 Proc 6のtimestepサブルーチンでは、単精度浮動小数点の二次 元配列から最大値を探索し、実時間の進展幅とする。この最大値 探索処理にOpenACCとCUDAを用いて5種類の最適化を行っ た。対象となる配列の要素数は、データセット小で44,064 (3次元 ×14,688)、データセット大で337,365(3次元×112,455)となる。 CPUからGPUへのデータ転送量は、それぞれ、176,256 bytes (44,064×4byte)と1,349,460 bytes (337,365×4byte)である。データの転送にかかった時間を表2に、データ転送を含んだ 処理時間をそれぞれ図5と図6に示す。 表2: CPUからGPUへの転送の所要時間とバンド幅 データサイズ 172.13KB 1.29MB 時間[ms] BW [GB/s] 時間[ms] BW [GB/s] K20c 0.030 5.41 0.216 5.81 GTX1080 0.018 9.09 0.126 9.94 P100(PCIe) 0.023 6.96 0.167 7.50 P100(NVlink) 0.007 22.90 0.044 28.25
3.1.1
acc kernels
実装 表1に示す実際のコードのように、元のコードは各次元を maxval()関数でそれぞれ探索したものであった。本実装は非常 に単純で、acc kernelsディレクティブを元のFortranコードに 追加したものである。コンパイル後に自動生成されたCUDAの コードは2,3,4行目のmaxval()関数からそれぞれ3つのCUDAKernel(合計9つ)が自動生成されていた。生成されたKernel
は、NVIDIAのGPUで効果的とされる2段階のリダクショ ン[8]を行うものと、最後にデータをCPUに戻すものであった。 cxmax, cymax, czmaxの3つの中間データはCPU側に一旦転 送されており、効率の良くない実装であると考えられる。なお、 P100(NVlink)のコンパイラであるlinuxpower版はx86-64版
セージによれば、4行目で逐次実行のコードを生成している。 データセット小ではGTX1080にほうがどちらのP100よりも 短時間で処理が完了している。
Listing 1: acc kernelsディレクティブを追加
1 !$acc kernels copyin(Nm)
2 cxmax = maxval(c(1,1:Nm))!オリジナルのコード 3 cymax = maxval(c(2,1:Nm))!オリジナルのコード 4 czmax = maxval(c(3,1:Nm))!オリジナルのコード 5 cmax = max(cxmax,cymax)!オリジナルのコード 6 cmax = max(cmax,czmax)!オリジナルのコード 7 !$acc end kernels
3.1.2
maxval
実装“maxval”実装では、一つのmaxval()関数とacc kernelsディ レクティブを利用した。生成されたKernelは、acc kernels実 装と同様に、3つのCUDA Kernelで2段階のリダクションと CPUへのデータ転送を行うものとなった。ただし、maxval() 関数が1つしかないため、合計で3つのCUDA Kernelが生成 され、中間変数の無駄なCPUへの転送はなくなっていた。な お、linuxpower版はx86-64版とは異なるコードを生成している ようだ。起動されるKernelの数は9から3に減ったが、K20c とGTX1080については、acc kernel実装よりも遅くなってし まった。 Listing 2: maxval()が1つの実装 1 !$acc kernels copyin(Nm)
2 cxmax = maxval(c(:3,:Nm)) 3 !$acc end kernels
3.1.3
reduction
実装reduction実装では、maxvalの代わりにmax 関数と reduc-tion 節を利用した。これは、PGIコンパイラがmax 関数を GPU向けの組み込み関数としてサポートしているためである。 以下に示すように、外部ループにacc loop reductionを内部ルー プにacc loop vector(32)ディレクティブを追加した。生成され
たCUDA Kernelは2段階のリダクションを行うもので、どの コンパイラでも同じものであった。結果はどちらのデータセッ トでもmaxval実装よりも高速なものとなった。これは、生成 されたKernelがキャッシュを用いたより効率的なリダクショ ンを行うものであったためと考えられる。GTX1080では、acc kernels実装に対し、データセット小で3.2倍、データセット大 で1.6倍の高速化を達成した。
図5: データセット大での処理時間。GTX1080が最も高速な GPUとなっている
図6: データセット小での処理時間。P100(NVlink)が最も高速 なGPUとなっている
Listing 3: max()関数とreduction節を利用 1 !$acc parallel copyin(Nm)
2 !$acc loop reduction(max:cmax) 3 dorow=1,3
4 !$acc loop vector(32) 5 docol=1,Nm
6 cmax = max(cmax, c(col,row)) 7 end do
8 end do
9 !$acc end parallel
3.1.4
unroll
実装unroll実装ではreduction実装に加え、collapse(2)節を外側 ループに追加した。collapse(N)節は、連続するN個のループを 展開するものである。今回の場合、コンパイラはループを完全 に展開しようとする。生成されたCUDA Kernelは、acc kernel 実装よりも1.6倍∼3.5倍程度、reduction実装よりも1.4∼1.9 倍程度高速であった。これはループの展開により発行されるメ モリリクエストが増加したためであると考える。P100(NVlink) を除き、本実装がOpenACCだけを用いたものの中で最も高速 であった。
3.1.5
ネイティブCUDA
実装本実装は、最大値探索を行うdev maxval関数をCUDA For-tranで実装し、OpenACCのCUDA Kernel呼び出し機能を用 いて実装したものである。以下に示す実際のコードでは、2行 目のacc host data use deviceディレクティブで配列cのデバ イスポインタを取得する。dev maxval関数は渡されたデバイ スポインタに対し、CUDA Fortranのmaxval関数で処理を行 う。unroll実装に比べ最大で35%の高速化を達成している。な お、linuxpower版ではコンパイル時にエラーが発生してしまっ たため、評価できていない。
Listing 4: CUDA Fortranの関数を呼び出し、処理を行う
1 !$acc data copyin(c(:3,:Nm)) 2 !$acc host data use device(c) 3 cmax = dev maxval(c, 3, Nm) 4 !$acc end host data
5 !$acc end data
1 attributes(device)real functiondev maxval(gdata, x, y) 2 usecudafor, gpu maxval => maxval
3 integer,value :: x, y 4 real,device :: gdata(x,y)
5 dev maxval = gpu maxval(gdata) 6 end functiondev maxval
3.1.6
Multicore
実装PGIコンパイラでは、-ta=multicoreオプションによってマ ルチコアCPU向けのコードを生成することができる。ネイティ ブCUDA実装を除く上記の実装に本オプションを利用して、本 実装とした。評価にはXeon E5-2697 v2を利用し、MPIのオプ ションは“mpiexec -bind-to none -n”を用いた。結果を表3に 示す。acc kernels実装を元にしたものを除き、K20cに迫る結 果となった。
表3: Multicore実装の計算時間([ms])
データセット “acc kernels” “maxval” “reduction” “unroll” 小 15.180 1.029 1.101 1.062 大 14.603 1.511 1.184 0.827
3.2
Laplacian u
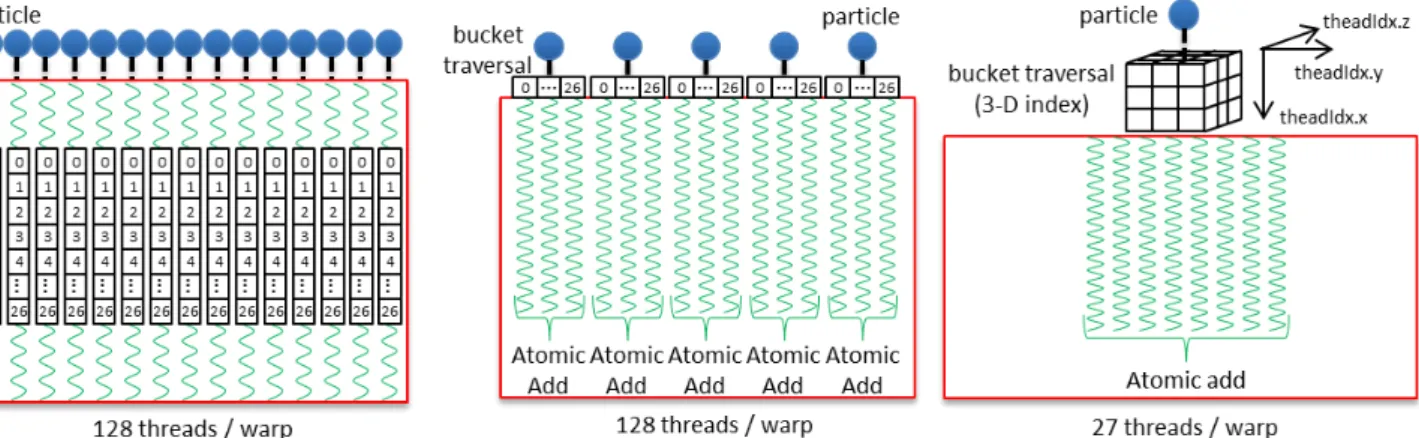
サブルーチンの近傍粒子探索の最適化 リスト7に移植前のシングルスレッド実装の擬似コードを示 す。5重ループで構成され、最初のループ(do-loop1)で対象の 粒子を選び、ループ2,3,4(do-loop2,3,4)で3×3×3 (=27)の隣 接バケットを走査する。最内の5つ目のループで実際の近傍粒 子探索を行う。最内ループのイテレーションの回数はバケット の内部の粒子の個数であり、不定回ループとなり並列化は困難 である。また、19行目の足し込み以外の計算は全て並列に処理 が可能である。17行目の距離と重みの計算が最も演算負荷の 高い部分である。加えて、13,15行目はバラバラかつ粒度が小 さいメモリアクセスが大量に発生する。シングルスレッド実装 の計算時間はデータセット小で257.66[ms]、データセット大で 1924.98[ms]であった。 このサブルーチンに対し、OpenACCを用いて3種類の実装 を行った。各実装を大小2種類のデータセットと4種類のGPU 上で評価し、その結果を図10に示す。図7: “Naive”実装の概要 図8: “Atomic”実装の概要 図9: “3-Dスレッド”実装の概要
Listing 5: 近傍粒子探索の擬似コード
1 ! for all the particles
2 do−loop1: target ptcl = 1,all ptcl 3 ib = bucket num[m]
4 ! traverse adjacent buckets (3−dim: 3x3x3=27) 5 do−loop2: x=x1,x2
6 do−loop3: y=y1,y2
7 do−loop4: z=z1,z2
8 ibb = get adj bucket num(x,y,z)
9 num of ptcl = get num of ptcl in bucket(ibb) 10 ! accumulate all the neighbour−particles 11 do−loop5: np = 1,num of ptcl! indefinite loop 12 if(ptcl is in halo)
13 lcr = ptcl halo[np]! random access 14 else
15 lcr = ptcl[np]! random access 16 end if
17 dist = sqrt(dot product(m, lcr))! get distance 18 weight = get weight(dist)
19 accum = accum + phys(weight)! aggregation 20 m phys[m] = m phys[m] + accum! in−place add
3.2.1
Naive
実装“Naive”実装は1粒子をGPUの1スレッドに割り当てたも
のである。並列化は最外ループのみとし、内部のループは逐次 実行とした。以下にOpenACCディレクティブを追加した擬似 コードを、図7に実装の概要を示す。do-loop1にacc kernels
とacc loop gang vector を追加し、最外ループを並列化した。 do-loop2の直前にacc loop collapse(3) seqを追加し、3つの
ループ(do-loop2,3,4)がアンローリングされ、逐次的に処理さ
るようにした。また、do-loop5にacc loop seqを追加し、処理 が逐次的に行われるようにした。コンパイル時の解析により、 ブロックサイズは128となった。1粒子がGPUの1スレッド に割り当てられるため、CUDAスレッドの総数は粒子数と同じ になる。データセット小(1プロセスあたり14,688粒子)では、 グリッドサイズは115 (= 14,688÷ 128)である。occupancyは 100%となるため、GPUのリソースをフルに使うことができる。 なお、ブロックサイズを64,256,512に変化させたが、実行時間 に変化はなかった。データセット大ではP100(NVlink)が最も 高速になり、シングルスレッド実装に対し451倍の高速化を達 成した。 Listing 6: “Naive”実装の擬似コード 1 !$acc kernels
2 !$acc loop gang vector(128) 3 do−loop1: target ptcl = 1,all ptcl 4 ...
5 !$acc loop collapse(3) seq 6 do−loop2: x=x1,x2
7 do−loop3: y=y1,y2
8 do−loop4: z=z1,z2
9 ...
10 !$acc loop seq
11 do−loop5: np = 1,num of ptcl 12 ...
3.2.2
Atomic
実装 “Atomic”実装は、各粒子のバケットの走査を別々のスレッ ドにし、物理量の足しこみにatomic演算を利用、同時実行可 能なスレッド数を増加させた実装である。図8に示すように、 27(3× 3 × 3)個の各隣接バケットがGPUの1スレッドに割り 当てられるため、CUDAスレッドの総数はNaive実装の27倍 となる。少データセット(1プロセスあたり14,688粒子)でブ ロックサイズが128の場合、全スレッド数は396,576(= 14,688 × 27)、グリッドサイズは3,099 (= 14,688× 27 ÷ 128)となる。 Naive実装と同様に、occupancyは100%となるためGPUのリ ソースをフルに使うことができる。以下にAtomic実装の擬似 コードを示す。結果を正しく保ちatomic演算を利用するため に、バケットのインデックス計算と物理量の足し込みのコード をdo-loop1からdo-loop4に移動させた。また、do-loop1にacc parallelとacc loop collapse(4) gang vectorを追加し、各隣接 バケットの走査をGPUの1スレッドに割り当てている。また、 15,17行目にacc atomic updateを追加し、atomic演算での物 理量の足しこみを行った。少データセットでは、P100(PCIe)が 最も高速で、シングルスレッド実装に対し220倍の高速化を達 成した。Listing 7: “Atomic”実装の擬似コード 1 !$acc parallel
2 !$acc loop collapse(4) independent gang vector(128) 3 do−loop1: target ptcl = 1,all ptcl
4 ...
5 do−loop2: x=x1,x2
6 do−loop3: y=y1,y2
7 do−loop4: z=z1,z2
8 ...
9 ! moved here from do−loop1 10 ib = bucket num[m] 11 !$acc loop seq
12 do−loop5: np = 1,num of ptcl
13 ...
14 ! moved here from do−loop1 15 !$acc atomic update
16 m phys[m] = m phys[m] + accum! in−place add 17 !$acc end atomic
3.2.3
3-D thread
実装 “3-D thread”実装はMPSコードの物理的背景を意識し、隣 接バケットの捜査を三次元のスレッドインデックスを利用して 実装したものである。図9に示すように、隣接バケットは三 次元的に配置されるため、それらをCUDAのthreadIdx.x と threadIdx.y, threadIdx.zでインデキシングする。27個の各隣接 バケットがGPUの1スレッドに割り当てられるため、CUDA スレッドの総数はAtomic実装と同様であるが、ブロックサイ ズが27に減少してしまう。そのため、occupancyが低くなり、 GPUのリソースをフルに利用することができない。少データ セット(1プロセスあたり14,688粒子)ではブロックサイズが 27なので、全スレッド数は396,576(= 14,688× 27)、グリッド サイズも14,688 (= 14,688× 27 ÷ 27)となる。以下に擬似コー ドを示すように、do-loop2,3,4のそれぞれにacc loop vector(3)を追加することで、本実装を実現している。データセットが小 さい場合も大きい場合も、”Naive”実装とAtomic実装よりも 低速となった。これはoccupancyが低いためであると考える。
Listing 8: “3-D thread”実装の擬似コード
1 !$acc kernels
2 !$acc loop independent
3 do−loop1: target ptcl = 1,all ptcl 4 ...
5 !$acc loop vector(3) 6 do−loop2: x=x1,x2 7 !$acc loop vector(3)
8 do−loop3: y=y1,y2
9 !$acc loop vector(3)
10 do−loop4: z=z1,z2
11 ...
12 ! moved here from do−loop1 13 ib = bucket num[m] 14 !$acc loop seq
15 do−loop5: np = 1,num of ptcl
16 ...
17 ! moved here from do−loop1 18 !$acc atomic update
19 m phys[m] = m phys[m] + accum! in−place add 20 !$acc end atomic
3.2.4
Multicore
実装“Multicore”実装には、PGIコンパイラの-ta=multicoreオプ ションを利用した。追加したディレクティブは”Naive”実装と同 様だが、“Loop not vectorized/parallelized: too deeply nested” というコンパイラメッセージが出たため、並列化は行われてい ないようである。MPIの実行にはXeon CPUのメモリバンド 幅が充分に利用されるよう、“mpiexec -bind-to none -n 2”オプ ションを利用した。mpstatコマンドの結果によると、2プロセ スでの実行時には、24コアが20∼60%の利用率で推移してい た。実行時間は、データセット小で34.03[ms]、データセット 大で318.16[ms]となり、7.5倍と6.1倍の高速化が達成された。 また、プロセス数を増加させた際の結果を表4に示す。プロセ ス数を増やしても、更なる高速化は達成されなかった。 表4: Multicore実装の処理時間におけるプロセス数の影響 プロセス数 2 4 8 16 Processing time [ms] 34.03 72.48 141.75 315.43 Speed-up ×7.57 ×3.55 ×1.82 ×0.82
3.3
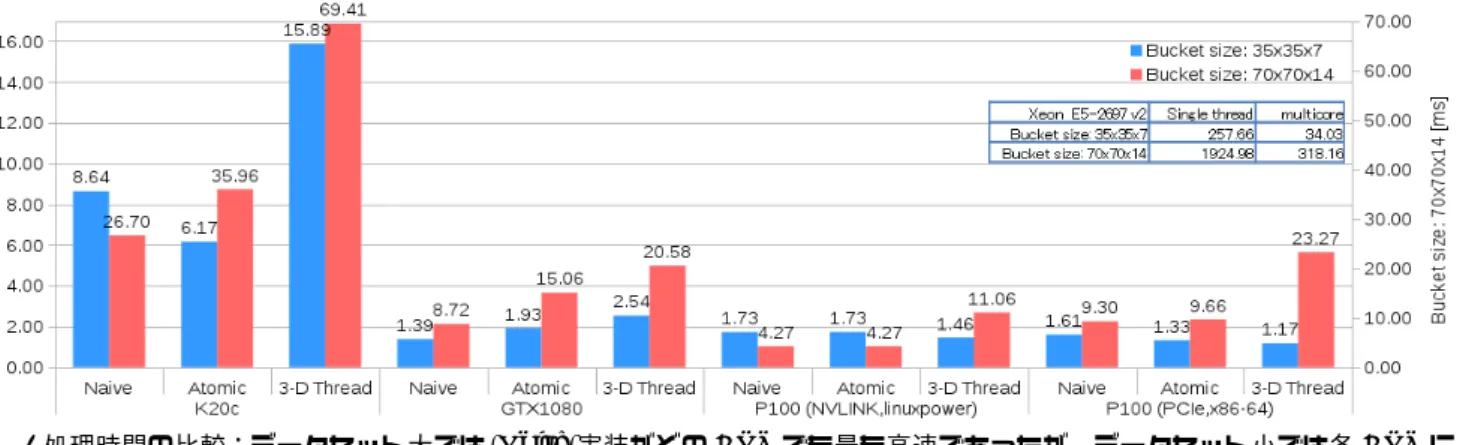
結果の議論 ここでは、3.1節と3.2節で得られたの結果について議論する。 3.1節 の 図5が 示 す よ う に 、デ ー タ セ ッ ト 小 で は ど の 実 装でもGTX1080 が最も高速なものとなった。具体的には、 GTX1080 はP100(PCIe)より 18%∼27%程度高速であった。 これはGTX1080がメモリ帯域は低いものの、動作周波数が P100に比べて330MHz高いためであると考える。図6では、 P100(NVlink)がどちらのデータセットとどの実装でも最も高 速なものとなった。また、P100(NVlink)はP100(PCIe)よりも 20%∼44%程度高速であった。前者の論理性能は後者のそれよ りも14%ほど高いが、理由はこれだけではないと考える。 3.2節の図10が示すように、データセット大ではNaive実装 がどのGPUでに最も高速であるが、データセット小ではそう ではなかった。100(PCIe)とP100(NVlink)では、Naive実装よりも3-D Thread実装が速い。3.1節の最大値探索の処理がす べて同じ負荷であるのと異なり、それぞれの実装の計算負荷が 異なる。Naive実装はatomic演算を持たないが、1スレッドで 隣接バケットの操作を行うため、計算量が多いが同時に行われ るメモリ・リクエストがAtomicに比べ少ない。3-D Thread実 装は1スレッドブロック内のatomic演算と全体のメモリ・リ クエストも少なく、occupancyも低い。 ここから以下のことがわかった • 並列計算とGPUの構造を理解しながら、OpenACCはディ レクティブを追加する必要がある • GTX1080は小さいデータセットではP100よりも処理が 速かった。これは動作周波数が330MHz高いことが理由と して考えられる
図10: 処理時間の比較:データセット大では”Naive”実装がどのGPUでも最も高速であったが、データセット小では各GPUに よって最も高速な実装が異なる • スレッド数とatomic演算の量が増えてもP100はGTX1080 よりも性能の劣化が小さい
4.
Conclusion
本研究報告では、宇宙航空研究開発内製のMPSコードの最 大値探索と近傍粒子探索をOpenACCを用いて移植・最適化し た。前者には5種類の最適化、後者には3種類の最適化を実装 し、大小2種類のデータセットと4種類のGPU上で評価した。 最大値探索では、追加するディレクティブによって最大で3.5 倍の性能差が出た。また、近傍粒子探索では、Xeon CPU上の シングルスレッド実装に比べ小さなデータセットでは220倍、 大きなデータセットでは451倍の高速化を実現した。マルチ スレッドのFortran実装に対し、小さなデータセットでは29.0 倍、大きなデータセットでは74.5倍の高速化を達成した。ま た、データセットとGPUによって最適な実装が異なることが わかった。 今後、各GPUでの性能の違いをさらに解析したうえで、MPS コード全体のGPU化を行う予定である。 謝辞 本研究に有用な議論とアドバイスを頂いた、NVIDIAの成瀬 明氏に感謝いたします。 参考文献[1] Koshizuka, S. and Oka, Y.: Moving particle semi-implicit method for fragmentation of incompressible fluid, Nuclear
Science and Engineering, Vol. 123, pp. 421–434 (1996).
[2] Seiya, W., Takayuki, A., Satori, T. and Takashi, S.: Neighbor-particle Searching Method for Particle Simula-tion Based on Contact InteracSimula-tion Model for GPU Com-puting, IPSJ Transactions on Advanced Computing
Sys-tems, Vol. 8, No. 4, pp. 50–60 (2015).
[3] Murotani, K., Masaie, I., Matsunaga, T., Koshizuka, S., Shioya, R., Ogino, M. and Fujisawa, T.: Performance im-provements of differential operators code for MPS method on GPU, Computational Particle Mechanics, Vol. 2, No. 3, pp. 261–272 (online), DOI: 10.1007/s40571-015-0059-2 (2015).
[4] Sota, Y., Watanabe, A. and Kojima, T.: Accerelation of the moving paricle semi-implicit method through multi-GPU parallel computing with dynamic domain
decompo-sition, Journal of Japan Society of Civil Engineers, Ser.
A2 (Applied Mechanics (AM)), Vol. 69, No. 2 (2013).
[5] : OpenACC Home — www.openacc.org,
http://www.openacc.org/.
[6] Murotani, K., Koshizuka, S., Tamai, T., Shibata, K., Mitsume, N., Yoshimura, S., Tanaka, S., Hasegawa, K., Nagai, E. and Fujisawa, T.: Development of Hierarchi-cal Domain Decomposition Explicit MPS Method and Application to Large-scale Tsunami Analysis with Float-ing Objects, Journal of Advanced Simulation in Science
and Engineering, Vol. 1, No. 1, pp. 16–35 (online), DOI:
10.15748/jasse.1.16 (2014).
[7] Sun, H., Tian, Y., Zhang, Y., Wu, J., Wang, S., Yang, Q. and Zhou, Q.: A Special Sorting Method for Neigh-bor Search Procedure in Smoothed Particle Hydrodynam-ics on GPUs, Parallel Processing Workshops (ICPPW),
2015 44th International Conference on, pp. 81–85
(on-line), DOI: 10.1109/ICPPW.2015.46 (2015).