確率的感性ユーザーモデルによる人のモデル化とその適合度の
検証
Accuracy Verification of a Probabilistic User Modeling Method Based on
users’ kansei
櫻井 瑛一
1∗本村 陽一
1 1国立研究開発法人 産業技術総合研究所 人工知能研究センター
Abstract: 物やサービスの利用体験を最大化するために,利用者の利用場面に即した物・サービスの 設計を行う必要が出てきている.この設計を実現するために利用者のモデル化が必要となっている. 我々はアンケートデータからこのモデル化を行う方法とその実際の研究を行ってきた.その一環とし て,アンケートデータに感性的な設問を取り入れることで使用者の感性を反映したデータを収集す ることや,そのデータに対して確率的なクラスタリングすることで使用者の典型的なタイプを見出 すことを行ってきた.先行研究では,この手段を用いて各々の分野でどのような傾向がみられるかに ついての分析を行ってきたが,本論ではクラスタリングされたセグメントの識別力はどれほどである かの検証を複数のアンケートデータを通じて行った.1
はじめに
製品・サービスの競争環境の中,モノ・サービスの設 計者は使用するユーザーの生活パターンや行動に適合 した商品をつくることが求められている.このような, 人ごとに合わせた商品設計を実現するためには,消費 者が必要としている物を深く理解すると同時にその人 の生活・ライフスタイルといった各人の好み・性格に 合う使われ方を理解する必要がある.この理解を実現 するために,使用者 (ユーザー) のモデル化を行う試み がなされてきている. ユーザーのモデル化に向けた取り組みのひとつとし て,ペルソナ法がある [2].この方法では,実際にサー ビス・製品を使うであろう人の背景情報をなるべく詳 細に網羅した仮想的な使用者 (このイメージをペルソナ と呼ぶ) の作成を行う.ペルソナにより製品の実際に使 われる際のシーンを製品設計者が容易に想像できるよ うにすることが可能となり,それにあわせた製品・サー ビスの想定と設計を可能とする.実際のペルソナの作 成では,使用者の行動を記録した文章から人の想像力 を用いて使用者の典型例たる人物を作成し,性格・生 活様式などから製品利用のシーンを想像可能なように 人物像の肉付けを行っていく.そのため,ペルソナの 作成には十分なデータと分析者の時間が多大に必要で ある.また,十分な製品利用シーンを想像するために は,使用者のモデルがひとつでは不十分であり複数の ∗連絡先: 産業技術総合研究所 E-mail: [email protected] ペルソナを作成する必要もある.以上のように,ペル ソナ作成にはコストという問題がつねに存在している. そこで,われわれはアンケートのデータをクラスタ リングすることで回答者のセグメントを見出しペルソ ナとすることができないかの研究を行ってきた.ペル ソナとして十分な背景を持つために,アンケート設問 に対象となる製品についての感性を問う設問と回答者 の考え方の理解を行うために回答者のライフスタイル や物事の考え方を問う設問を含むようにした.例えば 車に対するアンケートでは,車に対する好みについて の設問に加え車に対するわくわく感とその感情を感じ る情景についての設問とライフスタイルの設問を組み 合わせたアンケートを車の使用者からの定性調査から 作成し [3, 5],クラスタリングを行った [6].クラスタ リングの結果から,車の走りについて熱心な層がある 程度存在する一方,経済性や機能性,また車に対する ファッション性を見るそうがいることが示された.一方, 食に対するアンケートでは,食 (パン食) に対する価値 観についてのアンケートではパンに対する感情・感性 とそれが発揮される場所についての設問と車の場合同 様にライフスタイルの設問を組み合わせたアンケート を作成し,クラスタリングを行った [4].その結果,車 のケースと同様パンにこだわりを持って好きな層がい るが,同時にパンを外で食べる生活や職場内で食べる 生活など食生活のシーンに即した層の結果が得られた. 我々の従来の取り組みでは,クラスタリングにより いかに有効なユーザーセグメントルとその説明モデル が構築できるかを見て,その有効性を示してきた.本論では,各データセットで構築したユーザーモデルの 識別モデルをどれだけの精度で見分けることができる かについての比較検証を行った.
2
確率的感性ユーザーモデルの構築
方法
本節では,[6, 4] などで使用していた確率的感性ユー ザーモデル (以降,感性ユーザーモデルと略す) の構築 方法について記載する.2.1
感性ユーザーモデル構築方法の全体像
我々は,感性ユーザーモデル構築をアンケートデー タからのクラスタリングとクラスタリング結果である 潜在セグメントを見分ける識別モデルの構築により行っ てきた.本節ではその概要を示す. 感性ユーザーモデルを構築する源となるアンケート データを作成するためには,使用者の感性を理解し・反 映することができる設問及び選択肢を作成する必要が ある.そのために,我々は定性的な調査を活用すること で設問と選択肢の設計を行ってきた.車を対象とした場 合では [5],自動車を使用した際のワクワク感について グループインタビューによる定性的調査を行い,車に対 するワクワクとそのワクワク感が発露される場所・状況 についての調査を行った.そして,ワクワク感が発露さ れる場所・状況などについて分析者が想像し,選択肢を 増やしたうえでそれらの選択肢が本当に答えやすいも のであるかの検証を少量の定量データ (100 程度) によ り行った.この時は,自動車販売店に協力いただき,顧 客に対してアンケートを行うことで精緻化を実現した. このような手続きで得られた感性の設問とライフスタ イルを問う設問を加えたアンケート設問を作成し,イ ンターネット調査で定量的なデータを取得して確率的 なクラスタリングを行うことでユーザーの典型的な回 答を得ることで,ユーザーのモデル化を行った.この中 で,クラスタリング手法は Probabilistic Latent Semantic Analysis(以降 PLSA と略す) [1] によりクラスタリング を行っていた.そのうえで,セグメント化された人の 特徴を見るために,PLSA によりアンケート回答をハー ドクラスタリングを行い,ベイジアンネットワーク [?] によりセグメント間の識別モデルの構築を行っている. ベイジアンネットワークは条件付確率によるモデル化 であるため,そのネットワークから設問を Qiとセグメ ントを C 間の条件付確率 P (C|QC1, . . . , QCm) がわか り,セグメント C と判定するために必要な設問,すな わちそのセグメントの特徴が判明する. 上記の手法をまとめると,確率的ユーザーモデルの 構築方法は下記のようになる. 1. 調査したい対象に関連する感性を定性調査に基づ き明らかにする 2. 感性とそれが発露される状況などを問う設問を 作成し,それを利用する人のライフスタイルを明 らかにする設問を組み合わせた質問紙を作成し, データを取得する 3. 得られたアンケートデータを PLSA を用いてクラ スタリングを行う 4. クラスタリング結果を識別するモデルをベイジア ンネットワークにより構築し,ユーザーセグメン トの特徴を明らかにする この構築法のなかで,クラスタリングに用いている PLSA および,ベイジアンネットワークについて次に 簡潔に説明を行う.2.2
PLSA
PLSA は文書分類のために考案された手法である [1]. この手法では,文章データがどのようなモデルで生成 されたかを明らかにすることを目的としている.文書 の生成モデルとしては次のようになる. 1. 各単語 w は話題 (潜在変数)z によって出現確率が 異なるものとする (P (w|z)) 2. 各文章 d ごとに,話題の生起確率が決まっている (P (z|d)) 3. 各文章ごとの話題の生じる確率 P (z|d) により話題 が決定され,その話題 z に基づき単語 w が P (w|z) によって決定されるということが,文章 d の長さ だけ繰り返されることで文章が構築される この生成モデルにより,文書集合D = diの生成確率 は以下のように計算できる: P (D) =∏ d P (d) = ∏ d∈D ( ∑ z P (d)P (z|d)P (w|z) )n(d,w) . ただし,n(d, w) は文章 d に出現する単語 w の数である. この P (D) を最大化するように P (d), P (z|d), P (w|z) を EM 法を使用してもとめる.2.3
ベイジアンネットワーク
ベイジアンネットワークは,条件付独立性に基づき データ項目間の関係性をモデル化し,条件付確率の関 係を有向非巡回グラフとして表現したものである.図 1: ベイジアンネットワークの例 例えば,X1, . . . , X5の同時確率が以下のように書き あわらせたとする: P (X1, . . . , X5) = P (X1)P (X2|X1, X4)P (X3)P (X4|X1)P (X5|X3, X4) このとき,条件付確率 P (A|B) という関係を B から A に対するベクトルとして表したグラフィカルモデルの 構築を行う.この同時確率のネットワークを図示する と,図 1 のようになる.このようなネットワーク構造を データから学習することで,データ属性間の条件付独 立性が明らかになる.確率的ユーザーモデルでは,こ の方法を潜在セグメントの識別に必要な設問選択肢を 見つける手段として用いている.
3
識別正解率の比較
本節では,確率的ユーザーモデル構築方法にて構築 したユーザーモデル間の識別モデルがどれほどの精度 で推定されるかの実験を別種類のアンケートデータに より検証を行った.3.1
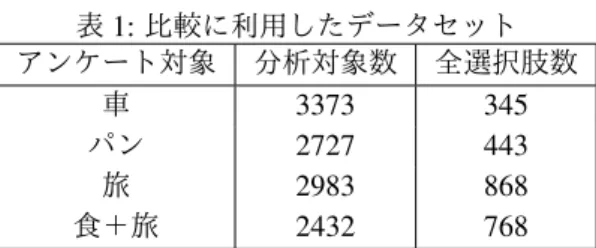
使用したアンケートデータ
使用したアンケートデータはそれぞれ,車のわくわ く感に関するアンケート・パン食に対する感性に関す るアンケート・旅に対する感性に関するアンケート・食 と旅に対する感性に関するアンケートの 4 つを使用し た.各アンケートデータに関する統計は表 1 である.3.2
実験結果
各データにたいして PLSA を適用し,AIC にて最適 なモデル数を選択した.PLSA の際には EM を 1000 イ テレーション行い,5 回の初期値を変更して最適なモデ 表 1: 比較に利用したデータセット アンケート対象 分析対象数 全選択肢数 車 3373 345 パン 2727 443 旅 2983 868 食+旅 2432 768 表 2: セグメント推定精度 アンケート対象 平均精度 精度中央値 全体精度 車 0.644 0.705 0.695 パン 0.565 0.593 0.653 旅 0.602 0.679 0.701 食+旅 0.436 0.462 0.528 ルを探索していた.その結果潜在クラスの数はそれぞ れ,車に関するアンケートでは 7,パンに関するアン ケートでは 8,食と旅に対する感性に関するアンケー トでは 9,旅に対する感性に関するアンケートでは 11 となった.そのうえで,各潜在セグメントを識別する ベイジアンネットワークを構築し各セグメントの識別 精度を比較した.その結果が表 2 である.なお,平均 精度は各潜在セグメントの識別精度の単純平均を,精 度中央値は各潜在セグメントの識別精度の中央値を示 す.そして,全体精度は全てのセグメントでの正解数/ アンケート回答者全体である. 本結果から,全体では多くの例で平均 7 割前後の正 答率を示すことが解る.一方,セグメント数が多い場 合正答率が減少することもわかる.これは,非常に似 たクラスができており識別が難しくなっていると予想 される.実際,セグメントごとの識別結果をみると図 2 から図 5 のようになった.この図において,各列は 真のセグメントを表しセグメントへ所属しているアン ケート回答者人数が多いほど左にならぶよう配置され ている.そして,各行はベイジアンネットワークによ り識別されたセグメントを表し,棒の割合が真のセグ メントに対する割合を示している.各図の傾向からわ かるように,セグメントに所属する回答結果が少ない ほど正答率が低下する傾向が見られた.特に所属数が 最低のセグメントでは識別精度があまり良好ではない ことも見て取れる.これは,クラスタリングによって 他では説明不可能なデータをまとめたセグメントが生 じる傾向にあるためと考えられる.図 2: セグメントごとの識別割合 (アンケート対象=車). 各列は真のセグメントを表しセグメント所属数が昇順 で配置されている.各行は識別されたセグメントを表 し,棒の割合が真のセグメントに対する割合を示して いる 図 3: セグメントごとの識別割合 (アンケート対象=パ ン食).
4
まとめ
本論では,アンケートデータを PLSA によりクラス タリングすることで回答傾向のセグメントを抽出し,そ のセグメントの識別モデルをベイジアンネットワーク により作成する確率的ユーザーモデル構築法がどれほ どの識別精度を持つかの検証を複数のアンケートデー タに対して適応することで検証した.その結果,セグメ ント数が少ない場合は 7 割程度あることを示した.種々 のデータでどれくらいの差になるかなど今後検証して いきたい.謝辞
本研究(の一部)は国立研究開発法人科学技術振興 機構(JST)の研究成果展開事業「センター・オブ・イ ノベーション(COI)プログラム」の支援によって 行われた.参考文献
[1] T. Hofmann. Probabilistic latent semantic analysis. In Proceedings of the Fifteenth conference on
Uncer-tainty in artificial intelligence, pp. 289–296. Morgan
Kaufmann Publishers Inc., 1999.
図 4: セグメントごとの識別割合 (アンケート対象=旅).
図 5: セグメントごとの識別割合 (アンケート対象=食+ 旅).
[2] J. Pruitt and J. Grudin. Personas: Practice and theory. In Proceedings of the 2003 Conference on Designing
for User Experiences, DUX ’03, pp. 1–15, New York,
NY, USA, 2003. ACM.
[3] 櫻井, 本村, 安松, 坂本 和夫 道田. 感性ユーザーモデ ルの構築のためのデータ収集方法. 日本行動計量学 会 第 44 回大会予稿集, 2016. [4] 櫻井, 本村, 安松, 道田. 食についての感性モデル に向けて. 日本行動計量学会 第 46 回大会予稿集, 2018. [5] 櫻井, 本村, 安松, 坂本, 道田. ビッグデータと確率モ デリング技術を用いた自動車ディーラーにおける自 動車ユーザモデルの構築. 人工知能学会合同研究会 第 27 回 社会における AI 研究会 (SIG-SAI), 2016. [6] 櫻井, 本村, 安松, 坂本, 道田. 感性に基づく確率的 ユーザーモデルの構築. 日本行動計量学会 第 45 回 大会予稿集, 2017.