次世代3次元実装メモリのメモリネットワーク構成に関する初期検討
8
0
0
全文
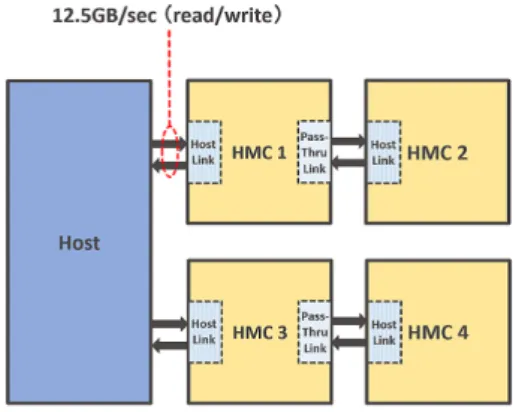
(2) Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 1 Hybrid Memory Cube の構造. モジュールを経由したデータ転送ではメモリアクセス遅延 が増大し,性能に影響を及ぼす可能性がある.これまでに,. 図 2 ネットワークリンク機能を用いたトポロジ例. このメモリネットワークの遅延が性能に与える影響は十分 に解析されていない.. プロセッサとの通信に加えて,HMC モジュール間をリ. 本稿では,HMC の持つネットワーク機能によりメモリ. ンクで接続し,プロセッサへとの途中経路にある HMC を. を増設した場合の,メモリアクセス遅延が性能へ与える. 中継ルータとして利用してすることで,メモリを増設する. 影響をシミュレーションにより評価する.また,CPU の. こともできる.HMC モジュール間の接続に用いるリンク. 近接にある HMC をキャッシュとして利用することで,モ. を pass-thru Link,プロセッサなどのホストとの通信に利. ジュール数増加による性能への影響を低減するための手法. 用するリンクを Host Link とし,ネットワークが構築され. を検討する.. 2. Hybrid Memory Cube(HMC) 2.1 アーキテクチャ. る.図 2 に HMC のネットワークリンク機能を用いたトポ ロジ例を示す. 各 HMC に識別 ID を割り振り,メモリアドレスから ID を決定してアクセスすることで,パケット通信によりプロ. Hybrid Memory Cube (HMC) は,Micron 社をはじめと. セッサとデータが存在する HMC との間で通信を行う.こ. する企業や研究機関が提唱し,開発を進めている新しい. の際に,データやアドレスは 16-Byte のフリット毎に分割. メモリ規格である.HMC は,DDR 等の従来のメモリ規. され,フリットベースの通信プロトコルを利用して通信を. 格とは異なり,DRAM とロジックが集積されたチップを,. 行うことで,高い柔軟性を実現している.. TSV を用いて 3 次元方向に 4 枚から 8 枚積層した構造を 持つ.最下層部のロジック部にはメモリへのアクセス制御. 2.2 HMC を用いたシステムの実例. のためのメモリコントローラやプロセッサとの I/O インタ. 現在は,Micron 社より HMC モジュールのプロトタイ. フェース,ルータ等が実装されている.HMC の構成を図. プ版が提供されている段階であり,Xilinx 社や Altela 社は. 1 に示す.. HMC の評価基盤を公開している [6].また,富士通株式会. ロジック部には複数のメモリコントローラが搭載され,. 社の次期 HPC システム向けプロセッサである SPARC64. 各コントローラの上に集積されたメモリを合わせて 1 つ. XIfx では,主記憶メモリとして HMC を採用することを発. のブロック (Vault と呼ばれる) が構成される.図は 4 × 4. 表している [4], [5].. のブロックを持つ HMC 構成の例である.これまでの複数. SPARC64 XIfx では,図 3 に示すように,1 つのプロセッ. チャネルを持つ DDR 規格のメモリシステムと比較して,. サに対して,8 つの HMC モジュールが接続される構造が. メモリアクセスの並列性を大幅に高めることが可能である.. 採用されており,1 モジュールあたりの Vault 数が 4 つ,. 3 次元積層技術により 1 チップに大容量の記憶素子を実. 積層 DRAM チップ数が 4 チップ,モジュールあたりの容. 装できるため,プロセッサの近傍に少数チップのみを配. 量が 4GB のプロトタイプ版が採用されると考えられてい. 置してシステムを構築することができる.そのため,プロ. る.また,1 モジュールからのリンク数は 2 リンクであり,. セッサ・HMC モジュール間で高速な通信路を設けること. メモリバンド幅は,モジュールあたりで 60GB/sec,シス. ができ,従来の DDR に比べてメモリバンド幅を大幅に向. テム全体で最高 240GB/sec と考えられる.. 上することが可能である.プロセッサ・HMC モジュール 間通信の単位は,10Gbps から 15Gbps の速度を持つシリ. 2.3 課題. アル通信路を受信および送信の双方で 16 本束ねたものを. HMC は,3 次元実装技術によりモジュールあたりの搭. 1 リンクとして接続される.1HMC モジュールあたり,2. 載メモリ容量を大きくでき,プロセッサの近傍にモジュー. または 8 本のリンクを持ち,1 モジュールあたりのメモリ. ルを配置することで高いバンド幅を得ることができる.し. バンド幅は最大で 480GB/sec にもなる.. かし,プロセッサと直接接続できるモジュール数は,プロ. c 2014 Information Processing Society of Japan ⃝. 2.
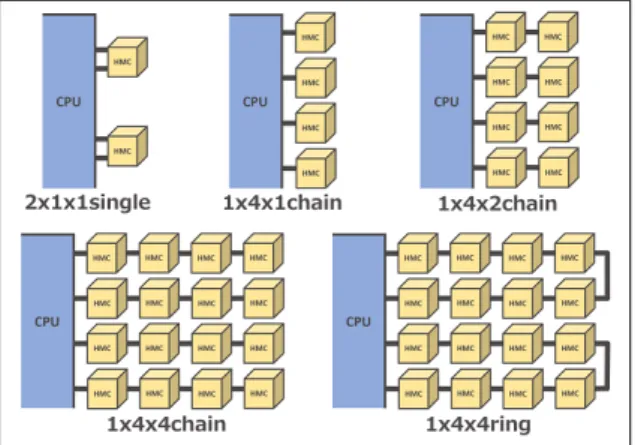
(3) Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 3. 図 4. SPARC64 XIfx のメモリ接続構成. 2 リンク HMC モジュールの接続構成. 2-link HMC モジュールを利用する場合,図 3 に示す セッサのピン数やモジュールの実装面積の点で限界があ. SPARC64 XIfx プロセッサのメモリ接続では,2 本のリン. る.そのため,プロセッサあたりのメモリ容量を確保する. クともプロセッサ側に接続されており,メモリモジュール. ことが難しくなる.. をネットワーク接続することはできない.そこで,1 リン. 実際,SPARC64 XIfx プロセッサでは,チップのピー. クを Host Link とし,もう 1 方を Pass-thru Link とする. ク浮動小数点演算性能が 1.1TFLOPS と,京コンピュータ. ことを考える.この場合,プロセッサ側に接続する合計モ. で用いられている SPARC64 VIIIfx の 8.6 倍,後継機種の. ジュール数がそのままであれば,トータルメモリバンド. FX10 で用いられている SPARC64 IXfx プロセッサの 4.7. 幅が減少してしまう.しかしプロセッサチップのピン数. 倍の性能であるにも関わらず,プロセッサあたりのメモ. には余裕ができるため,プロセッサ側に接続する HMC モ. リ容量は SPARC64 VIIIfx プロセッサの 2 倍,SPARC64. ジュール数を倍にすることができれば,メモリバンド幅を. IXfx プロセッサと同程度と演算性能あたりのメモリ容量は. 確保することができる *1 .. 大幅に小さくなっている.. メモリネットワーク構成例を図 4 に示す.なお,図では. HPC 分野での,大容量のメモリを必要とするアプリケー. 4 リンク分の接続のみを示しており,実際にはこの構成が,. ションに対しては,HMC の高いメモリバンド幅という特. プロセッサへの接続リンク数分だけ複製されることになる.. 徴を持ちつつ,メモリ容量を増加させることが望まれる.. 図中の 1x4x2chain のように表記されている接続パターン. 上記で述べたように,HMC はモジュール間をリンクで. 名は「1 モジュールあたりの Host Link 数 ×CPU に接続す. 接続し,ネットワークを構築することで HMC モジュール を増設することができる.しかし,アクセス対象の HMC. るモジュール数 ×CPU から数えた最遠モジュールまでの モジュール数 (距離)+トポロジ名」を表している.例えば,. モジュールをアクセスするまでに経由する HMC モジュー. 1x4x2chain は各 HMC モジュールから CPU に接続される. ル数,すなわち Hop 数が増加する毎にシリアル・パラレ. Host Link 数は 1 本であり,4 モジュールが CPU に接続さ. ルデータ変換やルータでの調停等が必要になり,メモリア. れ,さらに CPU からの最大モジュール距離が 2 であるこ. クセスにかかる遅延時間が増加してしまう可能性がある.. とを示している.トポロジとしては,以下が考えられる.. そのため,HMC のネットワーク構成やデータ配置を適切 に行う必要があるが,これまでに HMC ネットワークを構 築した際の性能への影響は十分に評価や検討がなされてい ない.. 3. HMC モジュール間ネットワーク アーキテクチャの検討. • single: HMC モジュール間のネットワークを用いず に,全モジュールが CPU に直結. • chain: HMC モジュールを daisy-chain 型で接続 • ring: chain ネットワークの終端をお互いに接続しリ ング型ネットワークを構成. • mesh: メッシュ型に HMC を接続 2 リンク HMC モジュールでは,1 方のリンクを Pass-thru. 本検討では,先ほど紹介した富士通の SPARC64 XIfx の. Link とすることで,chain 型,あるいは ring 型のメモリ. 接続アーキテクチャをベースにして,将来的にメモリ容量. ネットワークを構築することができる.これにより,モ. スケーリングを行う際に用いられる,HMC を利用したメ. ジュール ID の上限など,制御上の制限に達するまでは,メ. モリネットワークの接続パターンを分類し評価を行う.. モリ容量を増加させることが可能となる.chain 型と ring 型は,CPU から見て直結する HMC 数,および直結された. 3.1 1CPU の場合の HMC ネットワーク接続 (1) 2-link HMC Module. c 2014 Information Processing Society of Japan ⃝. *1. 基板上への実装の点からの検討が必要であるが,本稿では倍に実 装できるものとして議論を進める. 3.
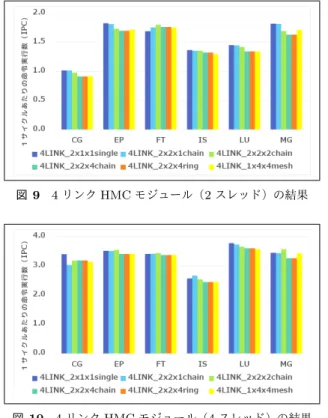
(4) Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. 情報処理学会研究報告 IPSJ SIG Technical Report 表 2. 評価環境. パラメータ. 値. CPU Clock. 3GHz. L1 Cache size. 64KB. L2 Cache size. 256KB. Cache coherence. Directory-based MOESI. 域を設け,他の HMC モジュールから中継のために送られ るフリットから,データ取得に一時的にキャッシュするこ とを考える.CPU から再度同じアドレスに対するデータ がリクエストされた場合は,キャッシュ領域からデータを 取得可能なので,HMC を Hop する回数を大きく減らすこ とができると考えられる.. 3.3 複数 CPU のメモリネットワーク接続 図 5. 4 リンク HMC モジュールの接続構成. 3.1 節で述べたメモリネットワークは,1 ノードに 1CPU (ソケット) の構成を前提にしていた.しかし,HPC シス. HMC に接続する HMC 群の数が同数であれば,最大 Hop. テムでは複数 CPU ソケットを搭載するシステムも多い.. 数やメモリバンド幅などの基本的なパラメータは一致する.. HMC ではメモリネットワークに対して複数の CPU を接. chain 型と比較した ring 型の利点としては,一部の HMC. 続することが可能であり,実際,複数 CPU を接続する場. モジュール,あるいはリンクに故障が発生した場合や,一. 合のメモリネットワーク構成に関する研究も進められて. 部が混雑して性能のボトルネックとなるような場合に代替. いる [19].HMC ネットワークをより活用するためには,. ルートを利用してメモリアクセスを行うこともできること. CPU 間のインターコネクトも含めた構造は,今後有力な. にある.なお,2 リンク HMC モジュールでは mesh 型は. アーキテクチャになると予想される.. リンク数が不足することから採用することができない.. CPU 間の接続を含めたメモリネットワークにおいても, CPU からの距離が遠いモジュールへのアクセス遅延増加. (2) 4-link HMC Module 図 5 に 4 リンク HMC モジュールのメモリネットワーク 構成例を示す. リンク数が 4 本の HMC モジュールの場合には,モジュー ルあたりで CPU との接続に利用するリンク数を増加させ ることもでき,構成の柔軟性が増加する.ただし,1 つの. HMC モジュールに対して CPU 側で必要なピン数が増加 するため,近接の HMC モジュール数が減少することが欠. は大きな問題になると考えられるため,本稿の検討結果は 複数 CPU のメモリネットワーク接続においても有用にな ると考えられる.複数 CPU のメモリネットワーク接続の 場合におけるレイテンシ削減手法の評価などは今後の課題 とする.. 4. 評価 4.1 評価方法. 点として考えられる.また,4 リンク HMC モジュールで. 本稿では,HMC モジュールをネットワーク接続した際. は,1x4x4mesh 構成のように,メッシュ型ネットワークを. の,複数モジュールを経由したメモリアクセスが性能に及. 採用することも可能となり,より複雑な経路を選択してメ. ぼす影響と,3.2 節で述べたキャッシュ機構の効果をサイ. モリアクセスを行うことも可能になる.. クルレベルシミュレーションにより評価する.シミュレー. これらの構成のまとめとして,各構成の比較を表 1 に示. タは gem5+Ruby を利用した NoC のシミュレーション環. す.構成ごとに最大 Hop 数はもとより,経路の拡張性・冗. 境を HMC 向けに拡張したものを利用した.HMC 自体の. 長性等の性質が異なることが分かる.. サイズ,アクセスレイテンシは表 3 のようにした.使用し た評価環境を表 2 に示す.利用したベンチマークプログラ. 3.2 アクセスレイテンシ削減手法. ムは NAS Parallel Benchmarks(NPB)のプログラムから. 前述のように,HMC モジュールの増加によるレイテン. いくつかを選択して用いた.使用したのは CLASS=W を. シ増加の影響を削減するためには,利用頻度の高いデータ. もとに,シミュレーション時間の削減の目的で,問題サイ. をより CPU 近傍の HMC モジュールに配置したい.そこ. ズ,カーネルループのイテレーション数を変更したものを. で,CPU と直結した HMC モジュール上にキャッシュ領. 利用した (表 4).. c 2014 Information Processing Society of Japan ⃝. 4.
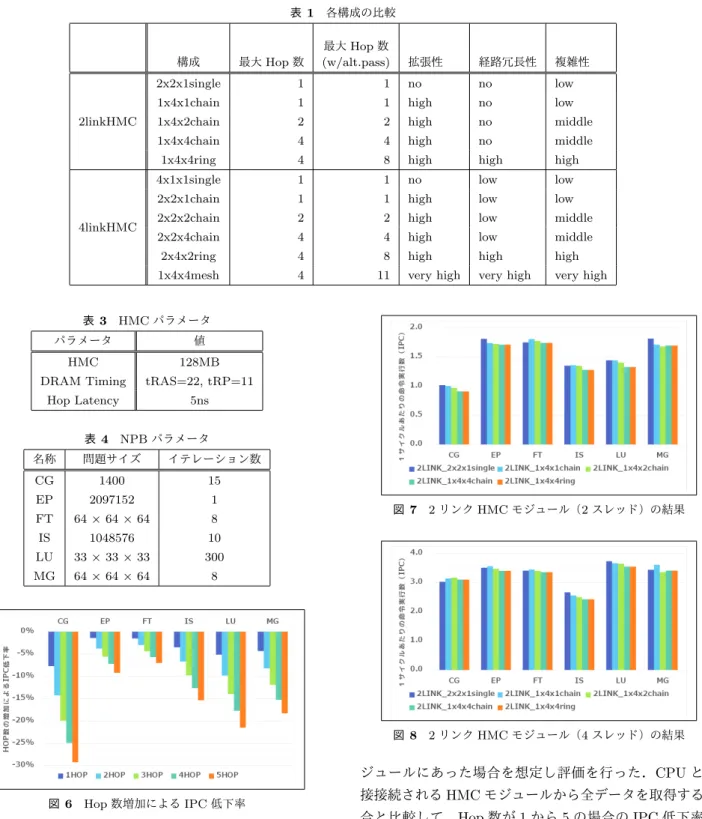
(5) Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. 情報処理学会研究報告 IPSJ SIG Technical Report 表 1. 最大 Hop 数. 最大 Hop 数 (w/alt.pass). 拡張性. 経路冗長性. 複雑性. 2x2x1single. 1. 1. no. no. low. 1x4x1chain. 1. 1. high. no. low. 1x4x2chain. 2. 2. high. no. middle. 1x4x4chain. 4. 4. high. no. middle. 1x4x4ring. 4. 8. high. high. high. 4x1x1single. 1. 1. no. low. low. 2x2x1chain. 1. 1. high. low. low. 2x2x2chain. 2. 2. high. low. middle. 2x2x4chain. 4. 4. high. low. middle. 2x4x2ring. 4. 8. high. high. high. 1x4x4mesh. 4. 11. very high. very high. very high. 構成. 2linkHMC. 4linkHMC. 表 3. 各構成の比較. HMC パラメータ. パラメータ. 値. HMC. 128MB. DRAM Timing. tRAS=22, tRP=11. Hop Latency. 5ns. 表 4 NPB パラメータ 名称. 問題サイズ. イテレーション数. CG. 1400. 15. EP. 2097152. 1. FT. 64 × 64 × 64. 8. IS. 1048576. 10. LU. 33 × 33 × 33. 300. MG. 64 × 64 × 64. 8. 図 7. 2 リンク HMC モジュール(2 スレッド)の結果. 図 8. 2 リンク HMC モジュール(4 スレッド)の結果. ジュールにあった場合を想定し評価を行った.CPU と直 図 6 Hop 数増加による IPC 低下率. 4.2 Hop 数と IPC の関係. 接接続される HMC モジュールから全データを取得する場 合と比較して,Hop 数が 1 から 5 の場合の IPC 低下率を 図 7 に示す.. メモリネットワーク構成において,メモリアクセス時に. 図より,全ベンチマークで Hop 数の増加と比例して IPC. 中継する HMC モジュールの数,すなわち Hop 回数が多い. が低下していることが確認できる.影響の大きさはプログ. ほど,スイッチングやシリアル・デシリアライズなどによ. ラム毎に異なり,CG で Hop 数が 5 と設定した場合の IPC. る遅延のためにメモリアクセス時間が増加し,IPC が低下. 低下率が 29% で最も大きく,最も影響が小さな FT でも. することが予測される.その影響を評価するために,デー. 7%弱の IPC 低下が見られる.このことから,Hop 数の大. タが置かれている HMC までの Hop 数を変化させ,IPC に. きなモジュールへのアクセスを減らすための適切なデータ. 与える影響を評価した.本実験では CPU コア数を 2 つと. 配置やキャッシュ機構の導入が重要であることがわかる.. 設定した. 実際の Hop 数はデータの配置に依存するが,ここでは 全てのデータが,該当 Hop 数でアクセスされる HMC モ. c 2014 Information Processing Society of Japan ⃝. 4.3 ネットワーク構成と IPC の関係 次に,種々のネットワーク構成の場合の IPC を評価す. 5.
(6) Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. 情報処理学会研究報告 IPSJ SIG Technical Report. 4 リンクモジュールでは,ほとんどの場合で,アクセスの 際の Hop 数が多い HMC モジュール追加に応じて IPC 低 下が確認できる.特に,2 リンクモジュールでは IPC に差 があまりなかった CG でもネットワーク構成ごとの IPC 差 が大きくなっている.また,2 リンクと 4 リンクモジュー ルの結果を比較すると,多くのベンチマークプログラムで は,最大 Hop 数が大きくない構成ではほとんど差がないも のの,最大 Hop 数が増加するにつれ,2 リンクモジュール 図 9. 4 リンク HMC モジュール(2 スレッド)の結果. を利用した場合と比較して 4 リンクモジュールの IPC が 低下している.この理由の解析は今後の課題である.. 4.4 キャッシュ手法の評価 CPU からの最大 HMC モジュール距離が 2 以上のトポ ロジに対して,HMC 上に簡易なキャッシュ機構を実装し た場合のメモリアクセスレイテンシの削減の効果を評価 した.本評価では,キャッシュサイズは,1 つの HMC モ ジュールの 4 分の 1 とした.通常のメモリネットワークに 対し,本手法を適用した場合の IPC 向上比のグラフを図 図 10. 4 リンク HMC モジュール(4 スレッド)の結果. る.2 リンク HMC モジュールを利用した場合において,. 11 に示す. 図より,ほとんどの場合でキャッシュ手法を利用する ことで IPC 向上が確認できる.ただし,図 7 の結果にあ. スレッド数が 2 と 4 の場合を評価した.本評価では,接続. るように,EP や FT は Hop 数増加による影響をあまり受. される全ての HMC モジュールに対して 8KB 毎にデータ. けておらず,キャッシュ手法による効果が非常に小さい.. をインターリーブして配置した.それぞれの評価結果を図. 一方で,CG,LU,MG では,Hop 数が最大で 4 になる. 7,図 8 に示す.. 1x4x4chain,2x2x4chain において,1%∼2%程度の IPC 向. 全ての HMC が直接 CPU に接続される 2x2x1single,お. 上効果があることがわかる.. よび 1x4x1chain の IPC が高く,Hop 数が多い HMC モ. 今回用いたベンチマークプログラムは,データセットが. ジュール数が多いほど IPC が低下していく傾向があること. それほど大きくなく,再利用性の高いデータはチップ上の. がわかる.また,2 スレッドの場合ではほとんどのベンチ. L2 キャッシュヒットとなることが多いため,大きな効果. マークで 2x2x1single が最も IPC が高いが,4 コアの場合. が見られなかった.しかし,HPC アプリケーションのよ. では 1x4x1chain の IPC が高いアプリケーションが見られ. うに,データセットが大きい場合はキャッシュ手法の有用. る.特に CG の 4 スレッドの場合では,1x4x2chain の IPC. 性はより高くなると考えられる.. が最も高くなっている.これは,スレッド数が増え,同時 メモリアクセス数が増加すると,メモリコントローラ数や. 5. 関連研究. バンク数がモジュール数に比例して増加することから,メ. 半導体回路の微細化による製造コストの増加,配線遅. モリレベル並列性をより活用できるためと考えられる.当. 延やデータ移動の電力増加といった問題への対処,また. 然ながら 1x4x4chain と 1x4x4ring はデータ配置や Hop 数. 異なるプロセスで製造された種々の機能を持つチップを. に違いがないため,同じ IPC になっている.. 集積できるという利点から,近年では 3 次元積層 LSI が. なお,IS や LU では,スレッド数によらず,Hop 数増. 注目されており,種々の研究が進んでいる.従来から基. 加による IPC 低下が確認できる.例えば IS の場合では,. 板上に複数のチップを並べて集積する MCM(Multi-Chip. 2x2x1single に比べ,1x4x4 の構成では 2 スレッドで 5.5%,. Module)や,パッケージ化されたチップを積層する技術. 4 スレッドで 9.1%の IPC 低下が見られる.これらのベン. は実用化されていたが [7], [8],特に最近では,チップ同士. チマークに対して,アクセス回数が多いデータの配置場所. を ThroughSilicon Via (TSV) [9], [10], [11] や誘導結合に. を CPU 近接 HMC へ移動することで IPC の向上が期待で. よる無線リンク [12], [13] により接続し,より緊密にチップ. きる.. を積層する 3 次元実装技術が注目されている.. 次に,4 リンク HMC モジュールを利用した場合の 2 ス. 従来から,プロセッサコアに SRAM や DRAM をキャッ. レッドの評価結果を図 9 に 4 スレッドの評価結果を図 10. シュとして積層する研究が多く行われている.Black らは,. に示す.. プロセッサコアと SRAM や DRAM を積層した際の IPC. c 2014 Information Processing Society of Japan ⃝. 6.
(7) Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 11. キャッシュ手法適用による IPC の変化. と発熱への影響を検討し,積層アーキテクチャにより IPC. Hop 数が大きい場合には,IPC 低下を引き起こすことが分. を 15%向上させることができるが,コア上でピークの発. かった.例えば,最大 Hop 数が 1 から 4 に増加すると IPC. 熱が上昇することを明らかにしている [14].また,DRAM. が 9.1%低下するアプリケーションが確認できた.. キャッシュを積層する際のアーキテクチャの検討も多く行. さらに,メモリネットワーク利用の際に,HMC モジュー. われている [15], [16].プロセッサコアとともに,MRAM. ルにキャッシュ機能を搭載することで,Hop 数増加による. や PRAM といった異なるプロセスで製造されたチップを. IPC 低下を緩和する手法を提案し,評価を行った.Hop 数. 積層する際のハードウェア構成やアーキテクチャの検討に. が大きい場合に IPC 低下の影響が大きいプログラムでは,. 関する研究も行われている [17].. 最大 2%の IPC 向上が期待できることがわかった.. 一方で,HMC と同様に主記憶 DRAM を 3 次元で実装. 今後,さらにキャッシュ機構のアーキテクチャを詳細に. し,プロセッサと接続するための技術や規格もいくつか開. 検討する他,複数 CPU を持つ場合のメモリネットワーク構. 発されており,実用化されつつある.Wide I/O[1] はプロ. 成での評価を行う予定である.また,あるメモリモジュー. セッサや SoC に直接メモリを集積するもので,特に,モバ. ルが故障した際の迂回ルートを利用した信頼性向上に関す. イル分野において,DRAM アクセスの消費電力削減と性. る検討も今後の課題である.. 能ボトルネックとなりやすい DRAM アクセスの高速化が 期待されている.. 謝辞 本研究の一部は,JSPS 科研費 24680004,ならび に科学技術振興機構・戦略的創造研究推進事業 (CREST). JEDEC で次世代のメモリとして規格策定中の HBM. の研究プロジェクト「ポストペタスケールシステムのため. (High Bandwidth Memory)[18] は,Wide I/O と同じく,. の電力マネージメントフレームワークの開発」の助成によ. 3 次元実装をベースとしたメモリアーキテクチャである.. り行われたものである.. TSV インターポーザ上に CPU と 3 次元に積層メモリを積 層する 2.5 次元 LSI 構造をとり,ピンあたりの転送レート. 参考文献. が 1Tbps 以上と広帯域のメモリバンド幅を目指して設計. [1]. されている.. HMC を前提としたメモリネットワークに関する研究も. [2]. なされている.Kim らの研究 [19] では,HMC のネット. [3]. ワークリンク機能を用いて,プロセッサの帯域幅を有効活 用するアーキテクチャやネットワークトポロジーを提案し. [4]. ている. [5]. 6. おわりに [6]. 本稿では,3 次元実装メモリの容量のスケーラビリティ を向上させるための 1 手法として,HMC 同士のネットワー ク接続を検討し,その性能評価を行った.シミュレーショ. [7]. ン評価より,データが存在するメモリモジュールまでの [8]. c 2014 Information Processing Society of Japan ⃝. S. Dumas, “Mobile Memory Forum: LPDDR3 and WideIO”, JEDEC Mobile Forum, 2011. J.T. Pawlowski, “Hybrid memory cube (HMC)” HotChips 23, 2011. Hybrid Memory Cube Consortium, “Hybrid Memory Cube Specification 1.0”, http://www.hybridmemorycube.org/, 2013. FUJITSU LIMITED, “Next-Generation PRIMEHPC”, 2014. T. Shimizu, “Fujitsu HPC Roadmap Beyond Petascale Computing”, 2013. ALTERA ホワイトペーパー, “次世代メモリ要件に適合す るアルテラ FPGA と HMC テクノロジ”, WP-01214-1.0, 2014. F. Carson, “B3D SiP developments and trends in 3D Packag”, International Conference and Exhibition on Device Packaging, 2007. M. Dreiza, A. Yoshida, K. Ishibashi, and T. Maeda,. 7.
(8) 情報処理学会研究報告 IPSJ SIG Technical Report. [9]. [10]. [11]. [12]. [13]. [14]. [15]. [16]. [17]. [18]. [19]. Vol.2014-ARC-213 No.12 Vol.2014-HPC-147 No.12 2014/12/9. “High Density PoP (Package-on-Package) and Package Stacking Development”, Proc. 57th Electronic Components and Technology Conference (ECTC 2007), pp.1379–1402, 2007. R. Islam, C. Brubaker, P. Lindner and C. Schaefer, “Wafer Level Packaging and 3D Interconnect for IC Technology”, Proc. 13th Advanced Semiconductor Manufacturing Conference, pp.212–217, 2002. N. Tanaka, T. Sato, Y. Yamaji, T. Morifuji, M. Umemoto, and K. Takahashi, “Mechanical effects of copper through-vias in a 3D die-stacked module”, Proc. Electronic Components and Technology Conference, pp.473– 479, 2002. W.R. Davis, J. Wilson, S. Mick, J. Xu, H. Hua, C. Mineo, A.M. Sule, M. Steer, and P.D. Franzon, “Demystifying 3D ICs: The Pros and Cons of Going Vertical”, IEEE Design and Test of Computers, vol.22, no.6, pp.498–510, 2005. K. Kanda, D.D. Antono, K. Ishida, H. Kawaguchi, T. Kuroda, and T. Sakurai, “1.27-Gbps/pin, 3mW/pin Wireless Superconnect (WSC) Interface Scheme”, Proc. Int’l Solid-State Circuits Conf. (ISSCC’03), pp.186–187, 2003. N. Miura, H. Ishikuro, T. Sakurai, and T. Kuroda, “A 0.14pJ/b Inductive-Coupling interChip Data Transceiver with Digitally- Controlled Precise Pulse Shaping”, Proc. Int’l Solid-State Circuits Conf.(ISSCC’07), pp.358–359, 2007. B. Black M. Annavaram, N. Brekelbaum, and J. DeVale, “Die Stacking (3D) Microarchitecture”, Proc. 39th International Symposium on Microarchitecture (MICRO’06), pp.469–479. 2006. G. H. Loh, “3D-Stacked Memory Architectures for Multi-Core Processors”, Porc. 35th International Symposium on Computer Architecture (ISCA’08), pp453– 464, 2008. D.H. Woo, N.H. Seong, D.L. Lewis, and H-H.S. Lee, “An Optimized 3D-Stacked Memory Architecture by Exploiting Excessive, High-Density TSV Bandwidth”, Proc. 16th International Symposium on High Performance Computer Architecture, (HPCA 2010). pp.1–12, 2010. G. Sun, X. Dong, Y. Xie, J. Li, and Y. Chen, “A Novel Architecture of the 3D Stacked MRAM L2 Cache for CMPs”, Proc. 15th International Symposium on High Performance Computer Architecture, (HPCA 2009). pp.239–249, 2009. JEDEC SOLID STATE TECHNOLOGY ASSOCIATION, “JEDEC STANDARD High Bandwidth Memory (HBM) DRAM”, JESD235, http://www.jedec.org/standardsdocuments/results/jesd235, 2013. G. Kim, J. Kim, J.H. Ahn, and J. Kim, “Memorycentric System Interconnect Design with Hybrid Memo ry Cubes”, Proc. PACT2014, pp.145–155, 2014.. c 2014 Information Processing Society of Japan ⃝. 8.
(9)
図
+3
![図 11 キャッシュ手法適用による IPC の変化 と発熱への影響を検討し,積層アーキテクチャにより IPC を 15% 向上させることができるが,コア上でピークの発 熱が上昇することを明らかにしている [14] .また, DRAM キャッシュを積層する際のアーキテクチャの検討も多く行 われている [15], [16] .プロセッサコアとともに, MRAM や PRAM といった異なるプロセスで製造されたチップを 積層する際のハードウェア構成やアーキテクチャの検討に 関する研究も行われている [17] .](https://thumb-ap.123doks.com/thumbv2/123deta/5852333.1542274/7.892.131.767.96.364/アーキテクチャアーキテクチャプロセッサコアアーキテクチャ.webp)
関連したドキュメント
Kitabayashi, “Electrochemical Properties of RuO 2 Catalyst for Air Electrode of Lithium Air Battery“, ECS Transactions, (2014), Submitted. Saito, “Electrochemical properties of
70年代の初頭,日系三世を中心にリドレス運動が始まる。リドレス運動とは,第二次世界大戦
次世代電力NW への 転換 再エネの大量導入を支える 次世代電力NWの構築 発電コスト
Adjustable soft--start: Every time the controller starts to operate (power on), the switching frequency is pushed to the programmed maximum value and slowly moves down toward
• Adjustable Soft−Start: Every time the controller starts to operate (power on), the switching frequency is pushed to the programmed maximum value and slowly moves down toward
b2) the second Mlower pulse with on−time longer than previous Mupper driver pulse period is placed in case that the ON−time comparator output is high in the end of regular
IMO/ITU EG 11、NCSR 3 及び通信会合(CG)への対応案の検討を行うとともに、現行 GMDSS 機器の国内 市場調査、次世代
FSIS が実施する HACCP の検証には、基本的検証と HACCP 運用に関する検証から構 成されている。基本的検証では、危害分析などの
