コグニティブ・コンピューティングに向けたニューロモーフィック・
デバイスと今後の実装技術
山道新太郎
†a)堀部
晃啓
†末岡
邦昭
†青木
豊広
†久田
隆史
†中村
英司
†安田
岳雄
†細川
浩二
†森
裕幸
†折井
靖光
†Neuromorphic Device and Packaging Technologies for Cognitive Computing
Shintaro YAMAMICHI
†a), Akihiro HORIBE
†, Kuniaki SUEOKA
†, Toyohiro AOKI
†,
Takashi HISADA
†, Eiji NAKAMURA
†, Takeo YASUDA
†, Kohji HOSOKAWA
†,
Hiroyuki MORI
†, and Yasumitsu ORII
†あらまし ビッグデータ時代のコンピューティングに向けた現状と課題,及び機械学習を駆使したコグニティ ブ・コンピューティングについて述べる.ビッグデータから有益な洞察を見出す「Watson」では,クラウド上で のサービスが始まる一方で,今後はそのシステム動作時の消費電力低減が重要となり,人間の脳機能に着目した ニューロモーフィック・デバイスの研究が活発化している.本論文ではその一例として,TrueNorth チップや不 揮発性メモリを用いた研究の取り組みについて述べる.更に,高度な処理をハードウェアレベルで実行するため には,チップレベルでの低消費電力化とともに,チップ間やチップと基板間での接続・実装技術が重要なカギと なる.超微細接合用のバンピング基本技術として検討を進めているIMS 技術と,多段積層チップの接続コスト を大幅に低減できる可能性があるViaS 技術について述べる. キーワード コグニティブ,ニューロモーフィック,微細接合,TSV
1.
ま え が き
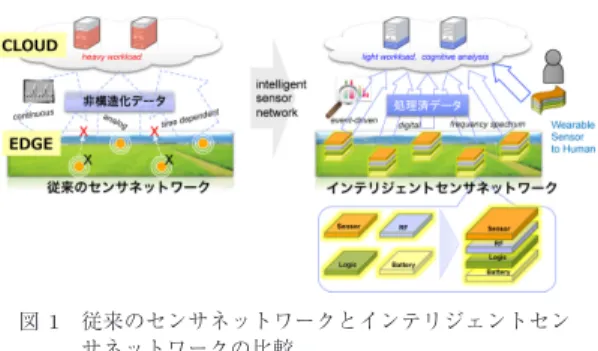
ビッグデータ時代の本格的な到来の中で, Informa-tion Technology (IT)分野におけるアプリケーション やサービスが本質的な変化を遂げつつある.個人が保 有するモバイル端末の豊富な計算リソースを活用した 様々なアプリケーションや,ネットワークの高速化・ 大容量化に支えられたクラウドサービスの普及に伴い, 人類が1年間に生み出すデジタルデータの量は2010 年には1ZB(ゼタバイト)の単位を越え,2020年には 40ZBまで爆発的に増大すると予測されている[1].こ の急激なデータの増大は,今後数年間は特にInternet of Things (IoT)と称せられるセンサネットワークの 中で,多数配置されたセンサが生み出すデータが主要 †日本アイ・ビー・エム株式会社東京基礎研究所,川崎市IBM Research -Tokyo, IBM Japan, Ltd., 1001 NANOBIC, 7–7 Shinkawasaki, Saiwai-ku, Kawasaki-shi, 212–0032 Japan a) E-mail: [email protected] 因となり,2020年には全データの42%がセンサ起因 のデータとなるという予測もある. ビッグデータの量的な変化とともに,もう一つ大き な変化が起こっているのが質的な変化である.従来の IT業界で扱われてきたデータは,フォーマットが決 まり,変化の頻度が小さく,真偽を客観的に判別しや すい構造化されたデータが主であった.しかしながら, ビッグデータ時代には,フォーマットがばらばらで, 動的で変化が激しく,真偽の判別や何を意味するのか の判断すら難しいようなあいまいなデータの割合が 急激に増え,2016年時点で80%以上がこれら非構造 化データであると言われている[2].すなわち,IT分 野においては,メインフレームの時代,クライアント &サーバの時代,現在のクラウド&モバイルの時代を 経て,新たにデータが情報処理の中心となり,データ の周辺,すなわちエッジ側でインテリジェントな情報 処理を行うことがますます重要となってくる時代に突 入していると言える.図1にこれまでのセンサネット
図 1 従来のセンサネットワークとインテリジェントセン サネットワークの比較
Fig. 1 Concept comparison of current sensor network and intelligent sensor network.
ワークと,今後のインテリジェントセンサネットワー クの比較図を示す.従来のセンサネットワークでは, 決まった時間間隔で大量のデータをハブやクラウドに 送信するためクラウド側の負担も大きく,また失われ るデータも多い.今後はセンサデータをエッジ側にて リアルタイムに解析し有効なデータのみをクラウド側 に送信することで,より多くの連続したデータを扱う とともに,エッジ側のアクチュエータに即座に指示を 出すような“反射神経系”の情報処理が必要となって くる.この場合,特にバッテリ駆動を考えると,エッ ジ側の情報処理を担うロジックデバイスには超低消費 電力なデバイスが必要となってくる. また,このような大きなデジタル環境の変化の中で, ビッグデータを有効に活用し,ユーザにとって役に立 つ情報を見つけ出す上で,従来型の逐次プログラミン グによる情報処理ではなく,効率的なアルゴリズムに よる機械学習によって,データを超多並列に処理する 試みが活発となっており,中でも人間の脳の信号処理 にヒントを得たニューラルネットワークの研究が,深 層学習の提案とともに,第3回目のブームとして大い に注目を集めている[3].
2.
コグニティブ・コンピューティング
このような非構造化データが大部分であるビッグ データを扱う新しいコンピューティングとして提案さ れているのがコグニティブ・コンピューティングであ る.すなわち,計算するためのハードウェアを設計・ 製造し,計算というアプリケーションのみが動いてい た計算機の時代を第1世代,プロセッサとメモリがバ スで接続されるフォンノイマンアーキテクチャでハー ドウェアをほぼ固定し,ソフトウェアを切り替えるこ とで様々なアプリケーションを動作させている現在の 図 2 ITの第 3 世代としてのコグニティブ・コンピュー ティングとそれを支えるデバイス技術Fig. 2 Cognitive Computing as the 3rdIT paradigm, and device evolution to support the transfor-mation. プログラミング・コンピューティングの時代を第2世 代と呼ぶと,コグニティブ・コンピューティングは第 3世代の全く新しいコンピューティングであると言え る.図2にコンピューティングの変遷と,それを支え るデバイスの進化について示す.本論文の3.で述べ るニューロモーフィック・デバイスは,既存の集積回 路(IC, LSI)を置き換えるものではなく,相補的な位 置づけとして共存していくと考えられる. コグニティブ・コンピューティングとは,あらかじ め決められたアルゴリズムに従い,コンピュータ自ら が大量のデータの中から各データ間の相関を経験に より学習し求められるタスクに対して仮説を立て,最 も適切な回答を判断し,また新たに記憶するような機 能を実現するコンピューティングである.自然言語を 用いたインタフェースを実装することで,人間とコン ピュータがより自然な形でインタラクティブにやりと りできるようになる. そのコグニティブ・コンピューティングの例として 現在活用が始まっているシステムが「Watson」であ る[4].質問応答システムとして,まずWatsonはク イズ番組にてクイズに答えるというタスクに挑戦し, 2011年2月に米国の人気クイズ番組「Jeopardy!」に て人間のチャンピオンに勝利するという結果を得た. その後,Watsonは自然言語処理と機械学習によるテ クノロジー・プラットホームとして発展し,様々な業界 において,ビッグデータから有益な洞察を見出すシス テムとして,緊急の質問応答,大量の資料から主要な 情報を素早く取り出す検索,データの相関関係明確化 などで活用されている.またこれらのアプリに向けた
Application Programming Interface (API)がクラウ ド上で提供され[5],最近ではロボットとWatsonを組 み合わせたサービスについても検討が始まっている. このように,既にコグニティブ・コンピューティン グの時代はスタートしていると言え,日本国内でデー タ活用に取り組んでいる企業・団体への調査結果では, コグニティブ・コンピューティングという言葉を知っ ていると回答した割合が75%を越え,医療,金融,保 険,小売りなどの業種が活用に積極的であることが分 かっている. しかしながら,この段階までのコグニティブ・コン ピューティングの実現は,ひとえにソフトウェア技術 の進化によるものであり,Watsonの機能を提供して いるハードウェアに視点を移した場合,それは既存 のサーバであって,ハードウェアとしてのブレイクス ルーはまだ報告されていない.ここで,今後ますます エッジ側でのインテリジェントなデータ処理や洞察が 重要となる流れの中で,一つ重要な課題が発生する. それは,システム全体の低消費電力化である. 図1に示したインテリジェントなセンサネットワー クにおいて,現在のサーバに必要な数十∼数百kWも の電力をエッジ側で消費することは許容されない.す なわち,既存のシステムの消費電力を桁違いに小さく することこそが,コグニティブ・コンピューティング 時代においてハードウェア技術者が実現すべき最も重 要な課題であり,その際,自然環境の中で約10W程 度の消費電力で信号処理を行っていると言われている 人間の脳に着目した新しいハードウェアの実現を目指 すことは,極めて自然な流れといえる.
3.
ニューロモーフィック・デバイス
ここでは,人間の脳の信号処理機能をハードウェア に実装することを目指したニューロモーフィック・デ バイスの現状と今後の課題について紹介する. 3. 1 SyNAPSE「TrueNorth」The Systems of Neuromorphic Adaptive Plastic Scalable Electronics (SyNAPSE)と名付けられたデ バイスは,米国国防省高等研究計画局の助成金を受け て開発されたニューロモーフィック・デバイスであり, SRAMを主体としたCMOS回路で実現されている. 人間の脳細胞であるニューロンや,その部位であるア クソンやシナプスが有する機能を電子回路で置き換え たものであり,第一世代は256個のニューロン回路と, 約26万個のシナプスが搭載されたチップであった[6]. 図 3 TrueNorthのチップ内コアレイアウトとコア内で のスパイク信号経路の概念図 [7]
Fig. 3 Images of core layout in TrueNorth and spike signal input/output routine in one core [7].
入力は並列のスパイク信号の形で供給され,あらかじ め学習した結果を,重みとしてロードしておいたシナ プス結合に基づいて,ニューロン回路内でポテンシャ ルが計算される.ニューロン回路では,ポテンシャル がしきい値を越えると出力スパイクがアクソン配線を 通じて次段に伝達される.このとき,このチップ内で のスパイク信号処理はイベントドリブンの非同期で行 われ,従来の高速クロックを有する計算ユニットと比 べて,極めて低い消費電力での信号処理が可能となる. 更にこの第一世代のチップを一つのコア回路として, それを4096個並列に1チップ内に集積化したものが 第二世代の「TrueNorth」と呼ばれるチップである[7]. 図3にTrueNorthのコアレイアウト及びコア内での スパイク信号経路の概念図を示す.このTrueNorth は100万個のニューロンに相当する回路と,2億5600 万個のシナプスを有し,1スパイクあたりの消費エネ ルギーは26pJにすぎない.超多並列入力に対する信 号処理を低消費電力で実行できることが特徴であり, 400× 240 pixel, 30fpsの画像処理をわずか63mWで 実行した結果も得られている. 3. 2 NVM-based device 前節のTrueNorthはSRAMをベースにしたニュー ロモーフィック・デバイスであるため,SRAMに記憶 したシナプスの重みは電源切断と同時に消滅する.ま た,タスクを実行する前の学習はデバイスとは別の 通常のコンピュータを用いたオフラインシステムで 実行し,学習結果のみをSRAMにロードする必要が
あった.
これらの課題を克服した次世代のニューロモーフ ィック・デ バ イ ス と し て ,相 変 化 型 メ モ リ (Phase-change memory (PCM))や抵抗変化型メモリ
(Resis-tive RAM (ReRAM))の記憶素子をシナプスとして利
用する,不揮発性デバイスの研究が活発化している[8]. 研究の方向性は大きく以下の二つがある.一つは,実 際の脳の記憶メカニズムの一つと言われているスパイ クタイミング依存可塑性(Spike-Timing-Dependent Plasticity (STDP))を素子レベルの基本アルゴリズ ムとし,チップ全体でSTDP実現を目指す方向であ り,もう一つは,図4 に示すように,クロスバー配 線の交点に不揮発性メモリ素子を配置する構造を用い て,誤差逆伝搬法を用いた人工ニューラルネットワー ク(ANN)そのものをチップレベルで実現することを 目指す方向である. 前者については,PCM素子を前段のニューロン回 路と後段のニューロン回路の間に設け,両ニューロン のパルス印加タイミングをずらすと,STDPと類似 した応答特性として素子の導電率を変化させること ができることが報告されている[9].後者については, ReRAM素子を用い,導電率の増加と減少のパルス
依存性が非対称の場合のArtificial Neural Network
(ANN)の性能に与える影響をシミュレーションによ り評価した結果が報告されている[10].同一形状のパ ルス印加では,現状のReRAM素子ではオンからオ フへスイッチングする場合,導電率は急激に減少する. 図 4 クロスバー配線と抵抗変化素子を用いた素子レイア ウトと ANN との比較 [9]
Fig. 4 Cell image layout with resistive elements and cross-bar interconnect, compared with ANN topology [9]. 印加パルスの強度やパルス幅を調整することで導電率 の増加と減少を対称的に制御したとき,ANNの性能 が最も高くなることが示された.
4.
ニューロモーフィック時代に必要な実装
技術
ここまでは,SRAMや不揮発性メモリであるPCM, ReRAMを用いたニューロモーフィック・デバイスの チップ内部での動作について議論してきたが,生物の 脳におけるニューロン細胞やシナプス結合の数,すな わち集積度を考えた場合,実はTrueNorthチップで実 現されているニューロン数(100万個)は,蜂の脳と 同程度である.哺乳類であるネコの脳はその100倍の 約1億個,ヒトは更にネコの1,000倍である約1,000 億個のニューロンをもつと言われている.すなわち, 一つの半導体チップの中でいくら並列処理を行って低 消費電力化を達成できたとしても,チップ外部の配線 でエネルギーを消費したり,並列性が崩れたりする可 能性が高い. ニューロモーフィック・デバイスを用いたシステム を考えた場合,このオフチップのインタコネクトが非 常に大きな課題となり,これまでのデジタルデバイス に向けた実装技術をはるかに上回り,半導体前工程のBackend of Line (BEOL)に近い微細接合や微細配 線が必要とされる世界となる.更に,多数のニューロ モーフィック・デバイスを集積化する場合,インタコ ネクトのコストをいかに低減できるかも大きな課題で ある.以下,ニューロモーフィック・デバイスを用い たシステムの実現に向けて,必要となる先端実装技術 を紹介する. 4. 1 IMS 将 来 の 超 微 細 接 合 技 術 と し て 有 望 な Injection
Molded Solder (IMS)技術について述べる.現在,
微細フリップチップ接続にはCuピラーを用いたはん だ接合が主に用いられているが,はんだ部分の形成手 法は電気めっき法が大半である.しかしながら,電気 めっき法によるSn系のはんだ形成には,めっき装置 やめっき液の成分管理に初期投資やコストがかかるこ と,実質的にめっき組成が2元系までに限定されるこ と,ウエハ面内での成膜速度にばらつきが発生するこ と,パターン依存性が大きいこと,等の課題がある. IMS法はこれらの課題を解決する乾式のめっき形成 手法であり,高耐熱性を有するフォトレジストでめっ き形成部を開口させ,溶融したはんだをヘッドに供給
しながらヘッドをレジストパターン上でスキャンする ことにより,薬液を用いることなくめっきパターンを 形成することができる手法である[11], [12].図5に Cuピラー上にIMSにてはんだめっきを形成する際の プロセスフロー図を示す.Cuめっきに用いたレジス トパターンをそのまま使用してIMSによりはんだを 供給する.また図6にはウエハ面内にサイズの異なる バンプを形成した例を示す[11]. IMSの特徴は,乾式であり装置の状態維持が電気 めっきと比較して容易であること,溶融するはんだで あれば多元系組成を簡単に扱えること,フラックスフ リーのクリーンなプロセスであること,ウエハ面内依 存性やパターン依存性がなく,異なるサイズのパター ンを同時に形成できること,等が挙げられる.また高 温ヘッドをスキャンさせながらはんだを供給するため, 図 5 IMS法による Cu ピラーバンピングプロセスフ ロー [12]
Fig. 5 Cu pillar bumping process flow using IMS technology [12].
図 6 IMS法によるウエハ面内での異種サイズバンプ形成
後の外観写真と Cu ピラー形成例 (挿入図) [11] Fig. 6 Photo image of wafer bumping with different
diameters, and cross-sectional image of Cu pil-lars (inserted) [11]. 高耐熱性と微細可能性を両立させたフォトレジストも 重要な要素技術となる[12].IMS技術を用いることで. 将来的にはサブミクロン級の接合部形成が可能となり, ニューロモーフィック・デバイスからの多端子取り出 しに貢献できると考えられる. 4. 2 ViaS 二次元方向の高密度接続に加えて,ニューロモー フィック・デバイスを三次元方向に積層してニューロ ン数を増やすことも重要なアプローチの一つである. この際,Through Silicon Via (TSV)を用いたチップ 多段接続が最も有効な手段であると言えるが,この場 合の課題がプロセスコストである.TSVそのものの 形成では,TSV内部を充てんするCuめっきがプロセ スコストの主因子であり,またチップ間の接続のため のバンプ形成や高精度な接合プロセスも高コストの原 因となっている. ここで,ニューロモーフィック・デバイスの多段積 層を想定した場合,チップ内は基本的にはメモリベー スのマルチコアレイアウトとなっているため,TSVの 配置レイアウト上,複数チップを貫通する位置にTSV を設けやすい.またニューロモーフィック・デバイス そのものが低消費電力なため,チップ多段積層におけ る放熱の問題は回避できる.
Vertical integration after Stacking (ViaS)技術は,
各ウエハにTSVを形成する前に,先にウエハ間のボ ンディングを行い,後から複数のチップを貫通するよ うにTSVを形成して多段の回路を接続する技術であ り,ニューロモーフィック・デバイスの三次元積層の 低コスト化に有利なプロセスである[13].ViaSの形成 プロセスフローと従来のvia-Middle型TSVの形成フ ローの比較を表1に示す.ウエハボンディングは両工 法で存在するが,特殊な材料や追加プロセスを必要と するtemporary bonding工程はViaSには必要ない.
またCuめっきの代わりにIMSによるはんだめっき を,ライナーとしてALDやCVDの代わりに蒸着重 合ポリマー成膜(VDP)を用いるなど,低コストプロ セスが多く採用されている.またCMPや裏面バンピ ングが本質的に不要であり,全体としてプロセスコス トを大幅に低減可能である. 図7にViaSプロセスにより形成したTSVの断面 構造を示す.2枚のSi層を貫通して基盤のSi層に到 達しているが,この際,各Si層の電極とTSVが電気 的に導通していることが特徴である.またTSV内部 は前節のIMS法によりはんだが埋め込まれている.
表 1 ViaSと via-Middle 型 TSV のプロセス比較 [13] Table 1 Process flow comparison of ViaS and
via-Middle TSV [13].
図 7 ViaSプロセスにより形成した 2 層 Si 貫通ビアの
断面図 [13]
Fig. 7 Cross-sectional SEM image of TSV prepared through two layres of Si by ViaS process [13].
4. 3 歩留まりの影響考察 チップtoウエハ積層と比較して,ウエハtoウエハ 積層の場合,ウエハ面内の不良チップを積層時に組み 込んでしまう歩留まり低下の課題が本質的に存在する. 従来のデジタルメモリの場合,不良チップはそのまま モジュール全体のパフォーマンス(メモリ容量)低下 につながった. しかし,機械学習を用いた認識では正解率は常に 100%とは限らず,ANNをマッピングしたニューロ モーフィック・デバイスの場合,ある程度の不良チッ プを内包しながらも,タスク実行時のパフォーマンス を低下させないようなアルゴリズムを作ることも期待 できる. 図 8 3層パーセプトロンによる MNIST 認識率の隠れ層 ノード数依存性
Fig. 8 Node number of the hidden layer dependence on pattern recognition of MNIST for three layer perceptron. ここでは,3.2で述べたニューロモーフィック・デバ イス,すなわち,クロスバー配線の交点に配置した不 揮発性メモリ素子アレーをANNのノードに対応させ る場合を想定して,簡単なモデル計算を行った.この 場合,メモリ素子のビット不良がANNのノード数減
少に相当することになる.Mixed National Institute of Standards and Technology database (MNIST)の
手描き文字認識において,3層パーセプトロンの中間 層のノード数を変化させて,画像認識の正解率を評価 した.このときの入力層と出力層のノード数はそれぞ れ,784個と10個(ラベル層)であり,中間層のノー ド数を300,200,100個と変化させた.その結果を 図8に示す.500回のepoch数における正解率はいず れの場合も98%を越え,中間層のノード数が300個 から100個まで1/3に減少したとしても,正解率には それほど大きな影響を与えないことが分かる. 今回はMNIST文字認識の簡単な例で考察したが, ニューロモーフィック・デバイスの性能指標や歩留ま りの定義そのものは,今後の重要な研究テーマであり, 新しいハードウェアとしての動作の詳細が明らかにな るとともに,適切に定義されていくと考えられる.
5.
む す び
ビッグデータ時代の新しいコンピューティングであ るコグニティブ・コンピューティングの現状について Watsonを例に述べた.エッジ側でのリアルタイムか つ超多並列な信号処理に向けて,人間の脳機能を模し たニューロモーフィック・デバイスの報告例が相次ぎ, 実際の画像認識においてmW級の超低消費電力での 処理が実証されている.しかしながら,チップ上での学習や不揮発性などの性能向上に向けては,基本素子 の構造や,重みを記憶するための可塑的な材料など, まだまだ解決すべき課題が山積している. 更にチップの外のインタコネクトも,従来の延長線 上をはるかに超える超微細接合,高密度三次元実装へ の要求が見えつつあり,まさに材料からチップ,パッ ケージ,システムに至るまで,新たなアルゴリズム実 現に向けた斬新なアイデアとその検証が多数求められ る“ニューロモーフィック”の時代に足を踏み入れたと 言える.今後はこれら新しいハードウェアによるコグ ニティブ・コンピューティングの更なる発展に向けて, 様々なアプリケーションの探索と技術デモンストレー ションを推進していかなければならない.そのために も,個別技術分野に留まらず,他分野・異業種との積 極的なオープンイノベーションを推進していくことも ますます求められている. 文 献 [1] 喜連川優,“情報爆発のこれまでとこれから,”信学誌,
vol.94, no.8, pp.662–666, Aug. 2011.
[2] 濱田誠司,中山章宏,“テキスト・データの活用—最適な行動 につながる知見を導く,” ProVISION, no.78, pp.46–51, Summer 2013. [3] 松尾 豊,人口知能は人間を超えるか ディープラーニング の先にあるもの,KADOKAWA/中経出版,東京,2015. [4] 武田浩一,金山 博,“質問応答システム Watson が示す 未来—質問応答技術がもたらす情報処理の新たな世界,”
ProVISION, no.70, pp.69–75, Summer 2011. [5] IBM Watson Developer Community,
https://developer.ibm.com/watson/
[6] P. Merolla, J. Arthur, F. Akopyan, N. Imam, R. Manohar, and D.S. Modha, “A digital neurosynap-tic core using embedded crossbar memory with 45pJ per spike in 45nm,” Proc. IEEE Custom Integrated Circuits Conference (CICC), pp.1–4, San Jose, 2011. [7] P. Merolla, J. Arthur, R. Alvarez-Icaza, A. Cassidy, J. Sawada, F. Akopyan, B. Jackson, N. Imam, C. Guo, Y. Nakamura, B. Brezzo, I. Vo, S. Esser, R. Appuswamy, B. Taba, A. Amir, M. Flickner, W. Risk, R. Manohar, and D.S. Modha, “A million spiking-neuron integrated circuit with a scalable com-munication network and interface,” Science, vol.345, no.6197, pp.668–673, Aug. 2014.
[8] S. Eryilmaz, D. Kuzum, S. Yu, and H. Wong, “Device and system level design considerations for analog-non-volatile-memory based neuromorphic architec-tures,” Proc. IEEE Int. Electron Devices Meeting, pp.64–67, Washington D.C., Dec. 2015.
[9] D. Kuzum, R. Jeyasingh, B. Lee, and H. Wong, “Nanoelectronic programmable synapses based on phase change materials for brain-inspired comput-ing,” Nano Letters, vol.12, no.5, pp.2179–2186, 2012.
[10] J. Jang, S. Park, G. Burr, H. Hwang, and Y. Jeong, “Optimization of conductance change in Pr1−xCaxMnO3-based synaptic devices for neuro-morphic systems,” IEEE Electron. Devices Lett., vol.36, no.5, pp.457–459, May 2015.
[11] J. Nah, J. Gelorme, P. Sorce, P. Lauro, E. Perfecto, M. McLeod, K. Toriyama, Y. Orii, P. Brofman, T. Nauchi, A. Takaguchi, K. Ishiguro, T. Yoshikawa, D. Daily, and R. Suzuki, “Wafer IMS (injection molded solder)- A new fine pitch solder bumping technol-ogy on wafers with solder alloy composition flexibil-ity,” Proc. IEEE Electronic Components and Tech-nol. Conf. (ECTC), pp.1308–1313, Orlando, May 2014.
[12] T. Aoki, K. Toriyama, H. Mori, Y. Orii, J. Nah, S. Takahashi, J. Mukawa, K. Hasegawa, S. Kusumoto, and K. Inomata, “IMS (injection molded solder) tech-nology with liquid photoresist for ultra fine pitch bumping,” Proc. International Sympsium on Micro-electronics, pp.713–717, San Diego, Oct. 2014. [13] A. Horibe, K. Sueoka, T. Aoki, K. Toriyama, K.
Okamoto, S. Kohara, H. Mori, and Y. Orii, “Through silicon via process for effective multi-wafer integra-tion,” Proc. IEEE Electronic Components and Tech-nol. Conf. (ECTC), pp.1808–1812, San Diego, May 2015. (平成 28 年 3 月 31 日受付,6 月 28 日再受付, 10月 11 日公開) 山道新太郎 (正員) 1987京都大学・工卒.1989 同大大学院 修士課程了.2002 同大工学博士.1989 日 本電気 (株) 入社.1997 カリフォルニア大 学バークレー校客員研究員.2010 ルネサ スエレクトロニクス (株) 転籍.2013 日本 IBM (株) 入社.現在,ニューロモーフィッ ク技術の研究企画に従事. 堀部 晃啓 (正員) 1993慶應義塾大学・理工卒.1997 日本 学術振興会特別研究員採択.1997 同大助 手.1998 同大大学院博士課程了.1998 日 本 IBM (株) 入社.2004 同社東京基礎研 究所異動.2007 米国 IBM ワトソン研究 所訪問研究員.現在,ニューロモーフィッ ク・インタコネクションの研究に従事.
末岡 邦昭 (正員) 1983九州大学・工卒.1985 同大大学院 修士課程了.1993 同大工学博士.1985 日 本 IBM (株) 入社.現在,実装技術分野の 研究に従事. 青木 豊広 1998大阪大学・基礎工卒.2000 同大大 学院修士課程了.2000 日本 IBM (株) 入 社.現在,半導体実装分野の研究開発に 従事. 久田 隆史 1992大阪大学・理卒.2014 同大工学博 士.1992 日本 IBM (株) 入社.Low-k デ バイスのチップ接合技術やロジック・RF デ バイスのパッケージ開発に従事.現在,超 微細接合や超微細配線の応用研究に従事. 中村 英司 2013東京大学・工卒.2015 同大大学院 修士課程修了.2015 年日本 IBM (株) 入 社.現在は半導体実装技術の研究に従事. 安田 岳雄 1988京都大学・工卒.1990 同大大学院 修士課程了.2001 同大情報学博士.1990 日本 IBM (株) 入社.2005–06 JEITA 標 準化定電圧 IC 小委員会主査.2011–12 IEEE Computer Society Kansai Chap-ter Chairperson歴任.現在,ニューロモー フィック・デバイス及び回路分野の研究に従事. 細川 浩二 1983広島大学・工卒.同年日本 IBM (株) 入社,電算機製品,製品技術部配属.1990 野洲研究所半導体設計部に配属.1996– 1998米国 IBM 赴任,256Mb DRAM 開 発参画.2002 日本 IBM マイクロエレク トロニクス ASIC デザインセンター担当. 2012東京基礎研究所ニューロモーフィック・デバイス担当. 森 裕幸 1990武蔵工業大学大学院修士課程了.日 本 IBM (株) 入社.野洲研究所にてフリッ プチップ実装技術,応用製品の開発に従事. 2012東京基礎研究所にて超高密度実装技 術のニューロモーフィック・デバイス分野 への応用研究に従事. 折井 靖光 (正員) 1986大阪大学・基礎工卒.2012 同大工 学博士.1986 日本 IBM (株) 野洲事業所入 社.大型コンピュータの実装技術からノー トブックコンピュータ,ハードディスクな どのモバイル製品のフリップチップを中心 とした実装の生産技術・開発に従事.2009 東京基礎研究所に異動.三次元積層デバイスの研究をリード. 2012サイエンス&テクノロジーを統括し,光インタコネクト, 先進実装技術,脳型デバイスの研究開発をリード.2015 IMAPS Fellow.2016 IEEE CPMT Region 10 Director.エレクト ロニクス実装学会,電気学会,IEEE,IMPAS 各会員.
![Fig. 3 Images of core layout in TrueNorth and spike signal input/output routine in one core [7].](https://thumb-ap.123doks.com/thumbv2/123deta/8141744.1269238/3.774.405.705.98.375/images-layout-truenorth-spike-signal-input-output-routine.webp)
![Fig. 4 Cell image layout with resistive elements and cross-bar interconnect, compared with ANN topology [9]](https://thumb-ap.123doks.com/thumbv2/123deta/8141744.1269238/4.774.71.368.676.907/cell-image-layout-resistive-elements-interconnect-compared-topology.webp)
![図 6 IMS 法によるウエハ面内での異種サイズバンプ形成 後の外観写真と Cu ピラー形成例 (挿入図) [11]](https://thumb-ap.123doks.com/thumbv2/123deta/8141744.1269238/5.774.70.367.696.907/IMSによるウエハ面内異種サイズバンプ形成外観写真ピラー形成挿入.webp)
![Table 1 Process flow comparison of ViaS and via-Middle TSV [13].](https://thumb-ap.123doks.com/thumbv2/123deta/8141744.1269238/6.774.65.374.144.641/table-process-flow-comparison-vias-middle-tsv.webp)
