外れ値検出のための多変量時系列データからの特徴抽出
Feature Extraction from Multivariate Time Series
for Outlier Detection
松江 清高
1,2,3∗杉山 麿人
1,2,4Kiyotaka Matsue
1,2,3Mahito Sugiyama
1,2,41
国立情報学研究所
1
National Institute of Informatics
2
総合研究大学院大学複合科学研究科
2
The Graduate University for Advanced Studies, SOKENDAI
3
東芝インフラシステムズ株式会社
3
Toshiba Infrastructure Systems & Solutions Corporation
4
独立行政法人科学技術振興機構, さきがけ
4
JST,PRESTO
Abstract: Although several feature extraction algorithms have been developed for time series data, most of them cannot be directly applied to multivariate time series. In particular, only few studies attempted for extracting correlation or relationship between multivariate time series of different features. Here we develop an algorithm that extract features from multivariate time series. We examine the effectiveness of the extracted features under the unsupervised outlier detection scenario. We evaluate the proposed algorithm, called feature extraction using kernel and stacking (FEKS), on artificial and real-world data sets.
1
はじめに
時系列データからの特徴抽出手法は幅広く研究され ているが, その多くは単変量時系列データを対象として おり, 多変量時系列データに対する特徴抽出手法に関 する研究は未だ少ない. そこで本稿では, 多変量時系列 データに対する特徴抽出方法を提案し, この手法を外れ 値検出に適用したときの評価結果について示す. 昨今の AI 及び IoT 技術の普及に伴い, 複数機器で 構成されたシステムから得られるセンサー情報などの 時系列データの入手や分析が可能となり, システムの 異常や部品交換の必要性など, CBM (condition based maintenance) などのメンテナンス時期最適化に役立て られることが分かってきた [5]. しかし異常検出の研究は以前から行われているもの の, その多くは時系列データに適していない手法であっ たり, また時系列データ向けの検出手法であったとして も単変量時系列データの検出手法であるケースが多く, 複数の時系列データ間の組合せによって生じる異常の ∗連絡先:国立情報学研究所 〒 101-8430 東京都千代田区一ツ橋 2-1-2 E-mail: [email protected] 検出は難しい. 近年では, オートエンコーダなどの深層 学習技術を用いた異常検出手法の研究も進んでおり, 多 変量時系列データも扱うことができるようになってき ているが, 深層学習を用いた手法は, ネットワーク構造 を決定するためのハイパーパラメータの数が多いこと や, モデル作成に時間を要するという欠点などが存在す るため, 教師ラベルが手に入らない状況での異常検出に は向かない. そこで本稿では, 各時系列データからカーネル法に よって特徴抽出を行い, さらにそれを変数の数だけ組合 せることにより変数間の組合せ効果を考慮した特徴ベ クトル抽出手法 FEKS(feature extraction using kernel and stacking) を提案する. 特徴抽出した多変量時系列 データを各部分時系列の特徴量として扱うことで, 多 次元空間上の集合とみなすことができる. これによっ て目的の問題を多次元データ上で解くことが可能とな る. すなわち, 多くの研究成果がある多次元データに対 する外れ値検出手法を用いて多変量時系列データの外 れ値検出ができるようになる. 本手法は, 教師なし学習 と教師あり学習のどちらにも適用することが可能であ り, 様々な分野への応用が期待できる. 人工知能学会研究会資料 SIG-FPAI-B902-01 - 1 -2
関連研究
時系列データに対する特徴抽出により外れ値を検出す る研究は以前から行われている. 例えば DTW (dynamic time warping) [9, 2] は, 時系列データ間の距離を各時 点について総当たりで計算することで, 周期が異なる時 系列であってもそれらの類似度を求めることができる. しかし,DTW を多変量時系列データに拡張することは 難しく, また計算コストが高いという課題がある. また 時系列データをカーネル法で特徴表現してページラン クによって異常を検出する手法 [4] や, 時系列データを グラフ表現することで異常を検出する手法 [7], 時系列 データのスパース表現によって特徴抽出を行い異常を 検出する手法 [10], 時系列データの特徴量を組み合わせ て外れ値を検出する手法 [11] などが研究されている. し かしいずれの手法においても外れ値の検出精度が不十 分であったり, 多変量時系列データには適さないなど, 未だ課題が残されている. 一方で, 時系列データではない通常の多次元データの 外れ値検出手法は数多く研究されており, 代表的な手 法に LOF (local outlier factor), κthNN(κth-nearest neighbor) [6], ORCA [1],OCSVM(one-class support vector machine) [8], iForest(isolation forest) [12] など が存在する. しかしいずれの手法も時系列データに適 用することは難しいという課題が存在する.また近年では深層学習による外れ値検出手法も研究 されており, 時系列データからカーネル法に基づく特徴 表現を獲得し, ConvLSTM (convolutional long-short term memory) を用いて得られた結果から再構成誤差 を計算することで異常検出する手法なども研究されて いる [13]. しかし, 深層学習を用いた外れ値検出は調 整すべきハイパーパラメータが多いという課題が存在 する. 以上で述べたように, 多変量時系列データの外れ値検 出には未だ多くの研究課題が残されている.
3
問題設定
本節では, 時系列データに対する特徴抽出問題を, 多 変量時系列データに対する外れ値検出の問題と関連さ せて導入する. 本稿で扱うデータは機器から得られるセ ンサデータなどの時系列データを対象とする. 例えばオ フィスビルの室内の温度や湿度, サーバーマシンの CPU 使用率, 心電図波形, タクシーの乗車人数,Web ページ の閲覧数などが該当する. 各変数 p∈ {1, 2, ..., P } に対 して時刻 1 から T までの時系列データ x(p)∈ RT を以 下のように表す. x(p)= (x(p)1 , x(p)2 , ..., x(p)T ). (1) 図 1: 二変数の時系列データにおける特徴抽出問題. 図 1 に, 多変量時系列データにおける異常値の例を示 す. 図 1 には二変数の時系列データがプロットされて おり, いずれの変数も sin 波形と直線の組み合わせで構 成されている. それぞれの sin 波形には平均 0, 標準偏 差 0.1 の正規分布に従うノイズを加えている. 図中の 赤線枠を付けた 4 箇所の部分時系列データに着目する. 図 1 の上図は 4 回の直線が表れているのに対して, 下 図においてはそれが 3 回しか現れていない. すなわち 左から 3 番目の時刻 150 付近の赤実線枠内の部分時系 列データのパターンは他の 3 箇所のパターンと異なっ ている. しかし, それぞれの時系列を単変量時系列デー タとみなして異常検出を行うと, この部分のみを検出す ることはできない. このような組合せ外れ値を CMO (combinatorial outlier) と呼び, CMO を検出する問題 を考える.4
提案方法
本稿で示す多変量時系列の特徴抽出アルゴリズムを FEKS (feature extraction using kernel and stacking) と呼ぶ. 最初に単変量時系列データにおける特徴抽出 のアルゴリズムを説明し, その後, それを多変量時系列 データに拡張した FEKS について説明する.
4.1
単変量時系列データの特徴抽出と外れ
値検出
単変量時系列データの特徴抽出と外れ値検出は以下 の 2 ステップで構成される. 1. 単変量時系列データの特徴抽出 2. 多次元データの外れ値検出ステップ 1 ではページランクを用いた外れ値検出の 論文 [4] に記載の方法を用いる. 単変量時系列データか ら二つの部分時系列データを抽出し, それらの関係を RBF (radial basis function) カーネルを用いて特徴空 間へ写像する. 時刻 1 から時刻 T までの時系列デー タ x が与えられた時, この単変量時系列データの特徴 量 K ∈ RT−s+1×T −s+1を以下のように定義する. 各 i, j∈ {1, 2, ..., T − s + 1} に対して K の各要素 kijは kij := exp { − ∑s−1 δ=0(xi+δ− xj+δ) 2 σ2 } . (2) すなわち K はカーネル行列であり非負の正方行列と なる. 式 (2) の s は部分時系列の長さを表すウィンドウ サイズ, σ は部分時系列データに対する重みを表し, い ずれもパラメータである. RBF カーネルは時刻 i から 始まる部分時系列データと時刻 j から始まる部分時系 列データの関係を表現している. このカーネル行列を外れ値検出に適用する際は, カー ネル行列の各行を T− s + 1 次元のデータとみなし,T − s + 1 次元データが T− s + 1 個存在するときの外れ値 検出問題を解くことを考える. すなわち時系列データ を通常の多次元データに対する外れ値検出問題に置き 換えることにより, 従来より研究されてきた多次元外 れ値検出手法を適用することが. 例えば, 多次元外れ値 検出の代表的な手法の一つである κthNN (κth-nearest neighbor) を適用すると, 各時刻 i に対する外れ値スコ ア qκthNN(i) は特徴ベクトル kiから κ 番目に近い点ま での距離 dκを用いて以下のように表すことができる. qκthNN(i) := dκ(ki), (3) 多次元外れ値検出手法は κthNN 以外に LOF (local outlier factor), OCSVM (one-class support vector ma-chine) なども存在し, いずれの手法も適用可能である. つまりカーネル行列を用いて時系列データから特徴量 を抽出した後は, 汎用的な多次元外れ値検出手法を適用 できることがこのアルゴリズムの特徴の一つである.
4.2
多変量時系列データの特徴抽出と外れ
値検出
多変量時系列データの特徴抽出および外れ値検出も 単変量時系列データと同様に 2 ステップで構成される. 単変量時系列データの外れ値検出では部分時系列デー タ間の関係をカーネル行列を用いて特徴表現した. 多 変量時系列データの場合は, 変数ごとにカーネル行列を 作成し, それを列方向に結合することで部分時系列デー タにおける変数間の特徴を表現する. 単変量時系列デー タの特徴量であるカーネル行列を変数毎に K(1), K(2), ..., K(P )と定義すると, 多変量時系列データにおける 特徴量のカーネル行列 Kmlt ∈ R(T−s+1)×(T −s+1)P は 以下のように得られる. Kmlt= [K(1), K(2), ..., K(P )]. (4) ここで P は変数の個数である. したがって, 各時刻 i に 対する特徴ベクトル kmlt i ∈ R(T−s+1)P は, Kmltの i 行 目と一致し以下のように表される. kmlti = (ki1, ki2, ..., ki(T−s+1), ki(T−s+2), ..., ki(T−s+1)P). (5) このようにして作成したカーネル行列 Kmltを単変 量時系列データの時と同様に一般的な多次元外れ値検 出手法に適用することで, 多変量時系列データの外れ値 を検出する. 一方, ページランクを用いている [4] では多変量時系 列データの特徴量を式 (6) を用いてカーネル行列を表 現している. kij := exp { − ∑P p=1 ∑δ=s−1 δ=0 (xp,i+δ− xp,j+δ)2 σ2 } , (6) i, j∈ {1, ..., T − s + 1}. (7) 式 (6) では, 各変数の部分時系列データの特徴量を RBF カーネルを用いて加算している. これは, ページラ ンクを用いて外れ値検出をするために, 正方行列の特徴 量が必要なためと考えらえる. しかしこの特徴表現を用 いる場合, 各変数の部分時系列データの特徴量を加算 しているため, 変数毎の特徴量が失われてしまう欠点が ある.5
実験
ここでは人工的に作成したデータと実環境で得られ た多変量時系列データに提案手法 FEKS を適用して特 徴量を抽出し, その特徴量を用いて外れ値検出した実験 結果について説明する. また,FEKS による外れ値検出 を評価するために, カーネル法とページランクの組合せ による外れ値検出アルゴリズム [3] と比較する. [3] で は, 式 (6) を用いて, 多変量時系列データの特徴量を得 る. この特徴量は部分時系列データ間の関係の強さを表 している. 部分時系列データ間の関係が強い場合 (つま り値が類似している正常な部分時系列) は大きな値を取 り, 関係が弱い部分時系列 (つまり値が異なる異常な部 分時系列) は小さな値を取る. そこでこの関係の強さを ページランクに当てはめる. 各部分時系列データをノー ドと見立て, それらのノードを i, j∈ {1, ..., T − s + 1} で表すと, ノード i からノード j への状態遷移確率 sij - 3 -図 2: 人工データ (一般). 0.0 0.2 0.4 0.6 0.8 1.0 Recall 0.0 0.2 0.4 0.6 0.8 1.0 Precision
ROC curve
kNN (auprc = 1.00) PR (auprc = 0.66) 図 3: ROC 曲線 (一般). は式 (8) で表すことができる. sij := kij ∑T−s+1 i=1 kij . (8) 全データに占める外れ値データの割合は少ないと仮定 すると, 外れ値データを含んだノードへの状態遷移確率 は低くなることからページランクにより外れ値検出が 可能となる.5.1
人工データ
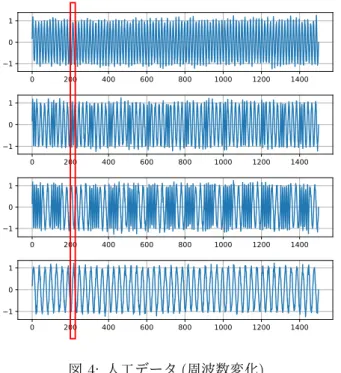
図 2 に示したデータは sin 波形と直線の組み合わせ で構成されており, それぞれの時刻に平均 0, 標準偏差 0.1 の正規分布に従うノイズを加えている. 上図の変数 は値 0 を取る直線が周期的に現れているのに対して, 下 図は時刻 150 付近において, 上図には存在する直線が存 在しない (赤実線枠内). この時刻を外れ値として検出 することを試みる.FEKS を用いてカーネル行列を作成 し κthNN により多次元多変量時系列データの外れ値検 出した結果と, 既存手法であるカーネル行列とページラ 図 4: 人工データ (周波数変化). ンクの組合せによる外れ値検出の結果を AUPRC(area under precision recall curve) の値で評価する. その結 果を図 3 に示す. なお図中の PR はページランクを示す. 図 3 より,FEKS による特徴抽出と κthNN による外 れ値検出を行った我々の手法では AUPRC が 1.0 とい う結果となり確実に外れ値を検出できているのに対し, PR では 0.66 という結果にとどまっている. 次に周波数が変化したデータの外れ値検出を試みる. 図 4 に 4 変数の時系列データを示す. 上から 3 段目の データの時刻 200 から 219 の外れ値 (赤実線枠内) を FEKS および κthNN を用いて検出することを試みる. その結果を図 5 に示す. 図 5 に示すように, AUPRC は 0.27 と比較的低い値となった. この理由は外れ値の定義 の仕方にある. 今回の実験では時刻 200 から 219 を外 れ値に設定しているが, FEKS を用いる場合, 部分時系 列データをカーネル表現するため, 時刻 200 以前のデー タにもこの特徴量が含まれ, 外れ値と判定してしまうこ とになる. よってその部分時系列データも外れ値とみな せば AUPRC はより高い値を取る. 次にデータの振幅を変化させた 2 変数の時系列デー タのサンプルを図 6 に示す. 振幅が 1 と 2 を持つ二種 類の sin 波にノイズを付加したデータを作成し, 100 点 毎に振幅を変化させたデータを二つ作成した. 外れ値 は時刻 230 から 239 の部分 (赤実線枠内) としており, 上段のデータは当該箇所の振幅が 1 であるのに対して 下段のデータは 2 となっている. この外れ値検出の結 果を図 7 に示す. 図 7 より, AUPRC は 0.93 となり, 振 幅の変化を検出できた. 以上の結果をまとめると表 2 のようになり, いずれ0.0 0.2 0.4 0.6 0.8 1.0 Recall 0.0 0.2 0.4 0.6 0.8 1.0 Precision
ROC curve
kNN (auprc = 0.27) PR (auprc = 0.04) 図 5: ROC 曲線 (周波数変化). 図 6: 人工データ (振幅変化). も従来手法を上回る結果が得られた.5.2
実環境データ
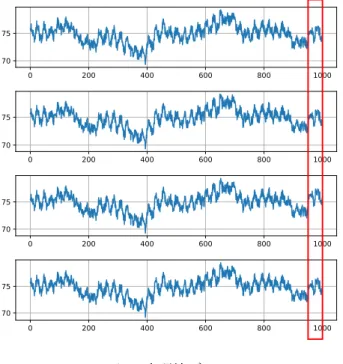
次に, 温度計測データ1を用いて実験した結果につい て示す. 入手した単変量時系列データからある連続し た部分時系列データ 1000 点を切り取り, それに対して 平均 0, 標準偏差 0.1 の正規分布に従うノイズを加えた データを 4 系列作成し, その中の 3 番目のデータの時 刻 950 から 1000 までのデータに対して 1.0 のオフセッ トを加えた外れ値データ (赤実線枠内) を作成した. 温 度センサにドリフト異常が生じたケースを想定してい る. その様子を図 8 に示す. これらのデータに対して FEKS および κthNN を適 用した結果を図 9 に示す. 前節同様に AUPRC で評価 1https://github.com/numenta 0.0 0.2 0.4 0.6 0.8 1.0 Recall 0.0 0.2 0.4 0.6 0.8 1.0 PrecisionROC curve
kNN (auprc = 0.93) PR (auprc = 0.30) 図 7: ROC 曲線 (振幅変化). 表 1: AUPRC による外れ値検出結果 (人工データ). κthNN PR 一般 1.00 0.66 周波数変化 0.27 0.04 位相変化 0.93 0.30 した結果, 提案手法は 0.88 という結果を得た.6
結論
多変量時系列データから特徴を抽出するために単変 量時系列データのカーネル行列を作成し, それを列方向 に結合した行列を作成する手法 FEKS を提案した. そ してこの行列の各行を多次元ベクトルとみなすことで, 既存の多次元外れ値検出アルゴリズムを用いて多変量 時系列データの外れ値検出ができることを人工データ および実環境データを用いて示した.謝辞
本研究は,JSPS 科研費 JP16H02870(MS) の助成を受 けたものです.参考文献
[1] Stephen D. Bay and Mark Schwabacher. Mining distance-based outliers in near linear time with ran-domization and a simple pruning rule. KDD ’03
Pro-ceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining,
pp. 29–38, 2003.
図 8: 実環境データ.
表 2: AUPRC による外れ値検出結果 (実環境データ). κthNN PR
温度センサー 0.88 0.10
[2] Donald Berndt and James Clifford. Using dy-namic time warping to find patterns in time se-ries. Workshop on Knowledge Knowledge Discovery
in Databases, Vol. 398, pp. 359–370, 1994.
[3] Haibin Cheng, Pang Ning Tan, Christopher Potter, and Steven Klooster. Detection and characterization of anomalies in multivariate time series. Proceedings
in 9th SIAM International Conference on Data Min-ing 2009, Vol. 1, pp. 409–420, 2009.
[4] Haibin Cheng, Pang-Ning Tan, Christopher Potter, and Steven Klooster. Detection and Characterization
of Anomalies in Multivariate Time Series. Society
for Industrial & Applied Mathematics (SIAM), dec 2013.
[5] Andrew K.S. Jardine, Daming Lin, and Dragan Ban-jevic. A review on machinery diagnostics and prog-nostics implementing condition-based maintenance.
Mechanical Systems and Signal Processing, Vol. 20,
No. 7, pp. 1483–1510, 2006.
[6] Edwin M Knorr, Raymond T Ng, and Vladimir Tu-cakov. Distance-based outliers : algorithms and ap-plications. The VLDB Journal, Vol. 8, pp. 237–253, 2000.
[7] Jongsun Lee, Hyun Soo Choi, Yongkweon Jeon, Yongsik Kwon, Donghun Lee, and Sungroh Yoon. De-tecting System Anomalies in Multivariate Time Se-ries with Information Transfer and Random Walk. In
Proceedings - 5th IEEE/ACM International Confer-ence on Big Data Computing, Applications and Tech-nologies, BDCAT 2018, pp. 71–80, jan 2018.
[8] Junshui Ma Perkins and Simon. Time-series Novelty Detection Using One-class Support Vector Machines.
0.0 0.2 0.4 0.6 0.8 1.0 Recall 0.0 0.2 0.4 0.6 0.8 1.0 Precision
ROC curve
kNN (auprc = 0.88) PR (auprc = 0.10) 図 9: ROC 曲線 (実環境データ).Proceedings of the International Joint Conference on Neural Networks, Vol. 3, pp. 1741–1745, 2003.
[9] Thanawin Rakthanmanon, Bilson Campana, Abdul-lah Mueen, Gustavo Batista, Brandon Westover, Qiang Zhu, Jesin Zakaria, and Eamonn Keogh. Searching and mining trillions of time series subse-quences under dynamic time warping. Proceedings
of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 262–270,
2012.
[10] Naoya Takeishi and Takehisa Yairi. Anomaly detec-tion from multivariate time-series with sparse repre-sentation. In Conference Proceedings - IEEE
Interna-tional Conference on Systems, Man and Cybernetics,
pp. 2651–2656, 2014.
[11] Mingyan Teng. Anomaly Detection on Time Series, 2010.
[12] Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation Forest. ICDM ’08 Proceedings of the 2008
Eighth IEEE International Conference on Data Min-ing, pp. 413–422, 2008.
[13] Chuxu Zhang, Dongjin Song, Yuncong Chen, Xinyang Feng, Cristian Lumezanu, Wei Cheng, Jingchao Ni, Bo Zong, Haifeng Chen, and Nitesh V. Chawla. A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data. Proceedings of the AAAI
Confer-ence on Artificial IntelligConfer-ence, Vol. 33, pp. 1409–1416,