DEIM Forum 2016 D3-5
クエリへ適応的に構築される木構造によるデータ集約処理の高速化
小山田昌史
†中台
慎二
†† 日本電気株式会社 情報・ナレッジ研究所 〒 211-8666 神奈川県川崎市中原区下沼部 1753
E-mail:
†[email protected], ††[email protected]
あらまし 本稿は,RDBMS におけるデータ集約処理の高速化方式である部分集約法のさらなる高速化方式を提案す
る.部分集約法は,テーブルからレコード集合のグループを取り出して各グループで集約値を事前に計算し,その後
の集約処理では各グループで事前に計算した集約結果を再利用する方式群である [9, 13, 19] .本稿は,実際のデータ分
析でよく見られる「ユーザがアクセスするデータ領域に偏りがある場合」に部分集約法が高い性能を示すグループ作
成方法である APA
木 (Adaptive Partial-Aggregation Tree) を提案する.APA 木はセグメント木をユーザのクエリに対し
て適応的に成長・縮退させることにより,ユーザが頻繁にアクセスするデータ領域については細かく,あまりアクセ
スされないデータ領域については粗く,グループを作成して集約値を計算し保持する.本稿は APA 木の管理方法と,
APA
木と部分集約法を利用した集約処理について述べる.そして実験により,APA 木が水平分割方式と比べ高性能で
あることを見せる.
キーワード 集約処理,マテリアライズドビュー,適応的,セグメント木,キャッシュ置換アルゴリズム
1.
背
景
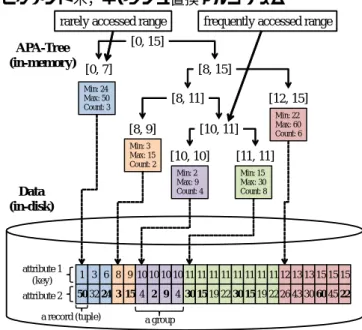
Min: 3 Max: 50 1 3 6 50 32 24 8 3 9 15 10 4 10 2 10 9 10 4 11 30 11 15 11 19 11 22 11 30 11 15 11 19 11 22 12 26 13 43 13 30 15 60 15 45 15 22 attribute 1 (key) attribute 2 a record (tuple) Data (in-disk) SMA (in-memory) a group Min: 2 Max: 30 Min: 30 Max: 15 Min: 19 Max: 43 Min: 22 Max: 60 図 1 水平分割方式 [9, 13, 19] データの最大値や標準偏差などの集約値を計算するデータ集 約処理は,データベースシステムにおける重要な処理である. データ集約処理は古典的なOLAPにおける基礎的な処理である が,近年では機械学習処理の入力データ整形処理にも多用され るなど,複雑なデータ分析処理に必須の処理となっている.特 に,機械学習処理を含むようなデータ分析処理では,分析処理 は一度の集約処理で終了することはなく,データ分析者はイン タラクティブに集約処理やその後の分析結果を吟味しながら, 何度もデータの集約処理を繰り返す.効率的にデータ分析のサ イクルを回すためにはデータ集約処理で瞬時に結果を得られ ることが望ましく,データ集約処理の高速化は重要な課題とい える. RDBMSにおいてデータ集約処理を高速化する方針のひとつ は,テーブルからレコード集合のグループを取り出して各グ ループで集約値を事前に計算し,その後の集約処理では各グルー プで事前に計算した集約結果を可能な限り再利用するもので Min: 24 Max: 50 Count: 3 Min: 3 Max: 15 Count: 2 Min: 22 Max: 60 Count: 6 Min: 2 Max: 9 Count: 4 Min: 15 Max: 30 Count: 8 [0, 15] [0, 7] [8, 15] [12, 15] [8, 11] [8, 9] [10, 11] [11, 11] [10, 10] 1 3 6 50 32 24 8 3 9 15 10 4 10 2 10 9 10 4 11 30 11 15 11 19 11 22 11 30 11 15 11 19 11 22 12 26 13 43 13 30 15 60 15 45 15 22 attribute 1 (key) attribute 2 a record (tuple) Data (in-disk) APA-Tree (in-memory) a groupfrequently accessed range rarely accessed range
図 2 APA木 (提案方式)
ある[9, 13, 19].代表的なものに,MoerkotteによるSMA(Small
Materialized Aggregates) [13]や,GraefeらによるZone Filter [9] がある.本稿では,この方針にもとづく手法群を部分集約法 (Partial-Aggregation Method)と呼ぶ.これまで提案されてきた 部分集約法[9, 13, 19]は,グループを作成する際,図1のよう に,テーブル内のレコード群をキー属性でソートするなど特定 の順序で並べ,一定数のレコードを先頭から順に取り出してグ ループとしてきた(注 1).本稿はこのグループ作成方法を水平分 割方式(Horizontal-Partitioning Approach)と呼ぶ. 本稿は実際のデータ分析でよく見られる「ユーザがアクセス するデータ領域に偏りがある場合」に水平分割方式よりも高 (注 1):RDBMS ではテーブルをパーティションへと水平分割し,各パーティショ ンで各属性毎に集計値を計算することに対応する.
い性能を示すグループ作成方法であるAPA木(Adaptive Partial-Aggregation Tree)を提案する.APA木はセグメント木をユーザ のクエリに対して適応的に成長・縮退させることにより,ユー ザが頻繁にアクセスするデータ領域については細かく,あまり アクセスされないデータ領域については粗く,グループを作成 して集約値を計算し保持する(図2).この場合,頻繁にアク セスされる領域については水平分割方式と比べ細粒度のグルー プを作成することができ,その結果として集約結果の再利用性 が向上する.本稿はAPA木の管理方法と,APA木と部分集約 法を利用した集約処理についても述べ,ユーザがアクセスする データ領域に偏りがある場合にAPA木が水平分割方式と比べ 効率的となることを見せる. 本稿の構成は次のとおりである.2.節で部分集約法について 述べる.3.節でAPA木について述べる.4.節で実験結果につ いて述べる.5.節で関連研究について紹介したあと,6.節でま とめる.
2.
部分集約法
はじめに,本稿で高速化に取り組む部分集約法の基本アイ ディアについて述べる. 部分集約法の基本的な発想は,二次記憶やリモートノード (クラウド)などのアクセスコストの高い領域に格納されてい るテーブルについて事前に集約計算をおこない,その集約結果 のみをアクセスコストの低い主記憶などに保持し,その後の集 約処理では事前計算結果を可能な限り使い回すことで,アクセ スコストの高いテーブルへのアクセスを削減しようというもの である[9, 13, 19].この際,より多くのクエリで結果が使いま わせるように,データ全体に対して集約値を計算するのではな く,図1のようにテーブルを複数のグループに水平分割し,各 グループで属性の最大値や最小値などの集約値を計算する.そ して,以降の集約処理では集約演算が持つ性質を利用し,各グ ループ毎に計算した集約値を組み合わせて再利用することで, 最終的な集約結果を算出する. 本節の以降では,部分集約法の高速化対象となる集約演算と クエリについて説明する. 2. 1 部分集約法により高速化できる処理 まず,部分集約法が高速化できる集約演算の持つ性質を以下 で定義する. 定義2.1 (部分計算可能) 集約演算 f : R(A1, ..., An) → D,リ レーションB=∪mi=1Bi∈ R(A1, ..., An)について, f (B)= g( f (B1), ..., f (Bm)) となるg : Dm → Dが存在するとき,集約演算 f は部分計算 可能(partially computable)であるという.また,このときgを f のコンバイナ(combiner)と呼ぶ.なお,R(A1, ..., An)は属性 A1, ..., Anを持つリレーションRのスキーマである. す な わ ち ,部 分 集 約 可 能 な 演 算 と は ,Max(Maxage(B1)∪Maxage(B2)) = Maxage(B1∪ B2)のように,リレーションを複
数のグループに分割して別々に算出した集約値から,元々のリ レーションに対する集約値を算出できる演算をいう.部分集約 Algorithm 1:部分集約法での水平分割方式による選択演算 と集約演算の実行アルゴリズム Input: B グループ (リレーション R の被覆であり B= {Bi}i∈I, R =∪i∈IBi) Input:σC 選択演算 Input: f 集約演算 Input: g 集約演算 f のコンバイナ Data: a1, . . . , a|B| 事前に計算された集約結果 (ai= f (σC(Bi))) Data: p1, . . . , p|B| コンバイナに渡すためにつかわれる,グループ ごとの集約結果を格納する変数 Output: f (σC(R)) 集約結果 1 foreach Bi∈ B do 2 ifσC(Bi)= ∅ then 3 (Skip)グループ Bi内のタプルはひとつも集計対象にな らないため処理をスキップ 4 pi← 0 5 else ifσC(Bi)= Bithen 6 (Reuse)グループ Bi内の全てのタプルが集計対象となる ため,事前にグループ Biについて計算した集約結果を再 利用することができる 7 pi← ai 8 else 9 (Read)グループ Bi内のいくつかのタプルが集計対象に なるため,グループ Bi内のデータを読み込んで集約結果 を算出する必要がある 10 pi← f (σC(Bi)) 11 集約結果 f (σC(R))を各グループの集約値 p1, . . . , p|B|から計算(再 集約にコンバイナ g を利用) 12 return g(p1, . . . , p|B|) 可能な演算の例としては,リレーションの属性に関する最大値・ 最小値,和,標準偏差,平均,ヒストグラム,の計算があげら れる.他方,部分計算可能でない演算の例としてはリレーショ ンの属性のカーディナリティ計算(一意な値の数)がある. 部分集約法は,上記の部分計算可能な集約演算に選択演算が 加わったクエリを高速化する.例えば,以下のレンジ集約クエ リが部分集約法により高速化可能である.
Sumincome(σ20<=R.age<=40(R))
2. 2 水平分割方式のアルゴリズム 次に,部分集約法での水平分割方式による集約値計算の具体 的なアルゴリズムについて述べる. アルゴリズム1は部分集約法での水平分割方式による選択演 算と集約演算の実行アルゴリズムをあらわす.水平分割方式は リレーションRの各グループBiについて,下記の三つのパター
ン(Skip, Reuse, Read)で部分的な集約結果p1, . . . , p|B|を取得
する.
(1) Skip:σC(Bi)= ∅ならば,グループBi内のタプルはひ
とつも集計対象にならないため処理をスキップできる. (2) Reuse:σC(Bi)= Biならば,グループBi内の全てのタ
した集約結果を再利用できる. (3) Read: それ以外ならば,グループBi内のいくつかの タプルのみ集計対象になるため,事前に集約した結果が使いま わせず,グループBi 内のデータを実際に読み込んで集約結果 を算出する必要がある. そして,水平分割方式はこれらの部分的な集約結果をコンバイ ナgによって再集約することで,最終的な集約結果 f (σC(R))を 算出する.
部分集約法の中では各グループBiがSkip, Reuse, Readのど
れになるかを,グループの中に含まれているデータにアクセス することなく,判定する必要がある.[19]はこの問題に取り組 み,グループの持つ集約値のみを用いて効率的にSkip, Reuse, Readの判定をおこなう方式を提案している.
3.
APA
木
前節で,部分集約法の概要と,そのグループ作成方式のひとつ である水平分割方式について述べた.本節は,ユーザのアクセス するデータ領域に偏りがあった場合に水平分割方式よりも効率 的となるグループ作成方式APA木(Adaptive Partial-Aggregation Tree)を提案する.(注 2) APA木は水平分割方式と同様に,部分集約法におけるデータ の集約単位であるグループを作成し,集約値を管理する方式で ある.APA木は水平分割方式と比較すると, (1) 水平分割方式がデータを均等のサイズでグループ化す るのに対し,APA木は頻繁にアクセスされるデータ領域ほど細 かなグループ(=再利用できる可能性が高い)を作成するため, ユーザのアクセスするデータ領域に偏りがあった場合に集約値 の再利用性が高く効率的である. (2) 水平分割方式が集約計算時に全てのグループの集約値 を集計し再集約しなければならないのに対し,APA木はグルー プを木構造で管理するため,再集約計算時に計算に影響しない グループの枝刈りがおこなえ,再集約計算が効率的である. という違いを持つ. 3. 1 APA木の構造 APA木はデータのキー属性を用いてデータをグループ化し, グループ内での集約値をインメモリで管理する木構造である. 図3にAPA木の例を示す.APA木はセグメント木と同様,ノー ドがキー属性の値域を再帰的に二分割してゆき(各ノードが キー属性のある範囲を担当し),葉となるノードがその範囲に 属すデータ(グループ)へのポインタと,グループ内のデータ について計算した集約値(属性の最大値,最小値,グループ内 のデータ数)を保有するような二分木である.図3ではキー属 性の値域[0, 15]が再帰的に分割されてグループが作成され,集 約値が各グループについて計算されている様子が確認できる. (注 2):なお,APA 木は,リレーションがある属性についてソートされており, ユーザのクエリがその属性に対するレンジクエリである場合に特に有用である. 近年のデータ分析で一般的なタイムスタンプ付き実績データの分析が,これに該 当する.例えばクラウド型 DWH のひとつである Treasure Data [2] では,データ は時刻情報によりパーティショニングされており,ユーザのクエリには基本的に 時刻属性に対するレンジ条件が含まれることが想定されている. Min: 24 Max: 50 Count: 3 Min: 3 Max: 15 Count: 2 Min: 22 Max: 60 Count: 6 Min: 2 Max: 9 Count: 4 Min: 15 Max: 30 Count: 8 [0, 15] [0, 7] [8, 15] [12, 15] [8, 11] [8, 9] [10, 11] [11, 11] [10, 10] 1 3 6 50 32 24 8 3 9 15 10 4 10 2 10 9 10 4 11 30 11 15 11 19 11 22 11 30 11 15 11 19 11 22 12 26 13 43 13 30 15 60 15 45 15 22 attribute 1 (key) attribute 2 a record (tuple) Data (in-disk) APA-Tree (in-memory) a group 図 3 APA木の構造 APA木は セグメント木とは異なり,バランスされた完全二 分木ではない.セグメント木が値域をまんべんなく再帰的に二 分割してゆくのに対し,APA木はユーザに頻繁にアクセスされ る領域をより細かく分割し(その範囲のリーフノードは深くな り),あまりアクセスされない領域は粗く分割する(その範囲 のリーフノードは浅くなる).このアクセス頻度に応じた分割 は,ユーザのクエリに応じて適応的に木が成長・縮小すること で実現される.図3のAPA木は,[0, 7]の領域にあまりアクセ スせず,[8, 15]の領域,中でも[10, 11]の領域に頻繁にアクセ スした結果となっている.APA木は細分化する領域を頻繁にア クセスされる領域に限定するため,セグメント木と比べてノー ド数が少なくなり,消費メモリ量も少なく済む. 3. 2 APA木と部分集約法によるレンジ集約クエリの評価 Algorithm 2:evalRangeAggregationQuery(query): 部分集約 法でのAPA木によるレンジ集約クエリの評価アルゴリズム Input: query:レンジクエリ Output:レンジクエリ query の対象となるデータに対する集約結果 Data: rootNode: APA木のルートノードData: TREE SIZE LIMIT: APA木のノード数上限値 1 // 集約値を計算
2 aggregations← computeAggregationForNode(rootNode, query) 3 while rootNode.treeSize> TREE SIZE LIMIT do
4 // (木の縮小)最もアクセスされていないノードを探し,その 兄弟ノードとマージ 5 leastAccessedLeaf← rootNode.findLeastAccessedLeaf() 6 leastAccessedLeaf.parent.mergeChildren() 7 return aggregations 値の追加や削除によって成長・縮小する木構造と異なり,APA 木はレンジ集約クエリを評価するたびに成長・縮小する.以下, APA木と部分集約法によるレンジ集約クエリの評価の流れを説 明し,APA木が処理のなかでいかに成長・縮小してゆくかにつ いて述べる.
Algorithm 3:computeAggregationForNode(node, query):ノー
ドnode以下のデータに対する部分集約法でのAPA木によ
るレンジ集約クエリの評価アルゴリズム
Input: node:集約値の計算対象ノード Input: query:レンジクエリ
Output: node下の query 対象となるデータについての集約結果 1 // この node 下のデータが query の範囲内 / 範囲外にあるのかを
compare関数をつかって確認する 2 answer← compare(node.range, query) 3 if answer= OUTSIDE QUERY then
4 // node 下のデータは query の範囲外なので,それ以上の探索は しない
5 return null
6 if answer= ALL DATA IN QUERY then
7 // node 下のすべてのデータが query の範囲内なので,事前に計 算した集約値を再利用
8 return node.getPrecomputedAggregations() 9 if answer= PART DATA IN QUERY then
10 // node 下のいくつかのデータが query の範囲内のとき 11 if node.isLeafNode() then 12 (木の成長)リーフノードまで探索したが,再利用はでき なかった.今後,この区間で再利用ができるように,ノー ドを分割してより細かな粒度で集約値を計算 13 node.split(query) 14 // 自身の子の集約値を再利用するため,再帰的に探索 15 leftAggregations= computeAggregationForNode(node.leftChild, query) 16 rightAggregations= computeAggregationForNode(node.rightChild, query) 17 // 両方の子から得た集約値を部分集約法で併合して返却 18 return leftAggregations.merge(rightAggregations) APA木と部分集約法をつかったレンジ集約クエリの評価アル ゴリズムをアルゴリズム2とアルゴリズム3に示す.アルゴリ ズム2は,APA木をルートノードから再帰的に探索し,レンジ 集約クエリを評価する.あるノード以下のデータに対する集約 値の計算は,アルゴリズム3がおこなう.アルゴリズム3は, ノードが • 「すべてのデータがレンジ集約クエリの範囲外 (OUT-SIDE QUERY)」 • 「 い く つ か の デ ー タ が レ ン ジ 集 約 ク エ リ の 範 囲 内 (PART DATA IN QUERY)」
• 「 す べ て の デ ー タ が レ ン ジ 集 約 ク エ リ の 範 囲 内 (ALL DATA IN QUERY)」
のどれになるかを判定し(注 3),そのノードに対する集約値を下 記のように取得する. (1) も し「 す べ て の デ ー タ が ク エ リ の 範 囲 外 (OUT-SIDE QUERY)」であれば,そのノード以下のノードはクエ リの対象外であり,探索しても無駄であるため,そのノードよ (注 3):単純なレンジのオーバーラップ判定である. りも下位のノードの探索を打ち切る(Skip) (2) も し「 い く つ か の デ ー タ が ク エ リ の 範 囲 内
(PART DATA IN QUERY)」であれば,そのノードの粒度では
集約値の再利用はできない.このとき(a)そのノードが子ノー ドを持つならば,下位のノードはより細粒度に統計値を計算し ており再利用できる場合があるため,下位ノードについて再帰 的に探索を続ける.(b)それ以外のとき(そのノードがリーフ ノードである場合)は,集約値の再利用ができないため,将来 同様のクエリが来た場合に集約値が再利用できるようにその ノードを分割し,各ノードの集約値を二次記憶のデータを読み 込んで計算する(Read) (3) も し「 す べ て の デ ー タ が ク エ リ の 範 囲 内
(ALL DATA IN QUERY)」であれば,そのノードの関するデー
タはすべてクエリの対象となっているため,ノード下のグルー
プに対して事前に計算した集約値を使いまわす(Reuse)
以上のように,APA木は木を再帰的にたどりながら部分集約
法のSkip,Reuse,Readをおこなうため,クエリに関係のない
ノード(グループ)の探索を枝刈りすることができ,全てのグ ループを走査する水平分割方式と比べ効率的である.また,あ るクエリでReadが発生した場合,APA木は次にそのクエリが 来た場合にReadが発生しないよう,木を成長させる.そのた め,ユーザがアクセスするデータ領域に偏りがある場合,Read が発生せず,水平分割方式と比べ効率的となる. 3. 3 キャッシュ置換アルゴリズムによるAPA木の肥大化防止 木を成長させるとReadが発生する確率は減るが,ノード数 が増え,ストレージコストと探索コストが肥大する(注 4).そこ
で,APA木は最大のノード数TREE SIZE LIMITを設け,その 制限下で最適な木を構築しようとする.ここでの最適な木とは, 「最もアクセスされる領域が最も深く,最もアクセスされない領 域が最も浅い木」をいう.このため,APA木は木を成長させた あとにノード数が制限を超えた場合,キャッシュ置換アルゴリ ズムにもとづいて「最もアクセスされていないリーフノード」 を探し,その葉ノードを兄弟ノードとマージする(アルゴリズ ム2).これは近年提案されたレンジクエリ向けBloom Filterで
あるARF (Adaptive Range Filter) [5]と同じ発想である.具体的
なキャッシュ置換アルゴリズムとしては,例えば軽量で管理情 報の少ないCLOCK [17]の利用が考えられる[5]. 3. 4 APA木の成長と縮小処理 上で,APA木ではクエリの実行時に木の成長・縮小を必要に 応じておこなうと述べた.ここでは,具体的なAPA木の成長・ 縮小処理にいて説明する. a ) リーフノードの分割処理(木の成長) リーフノードの分割処理は,あるリーフノードの担当する キー属性値の領域を二つに分割し,元のリーフノードの配下に あったデータをキー属性の値に応じて両領域に分配した上で, それらの統計値を再計算し,新たなリーフノードを作成する. 例えば 図4のAPA木において,[0, 49]の年齢を担当するリー (注 4):あらゆるクエリで Read が発生しないような APA 木の構築にはデータ数 nに対し O(n log n) の空間が必要となり,これを主記憶に置くことは困難である.
age (key): [0, 100]
age (key): [0, 49]
weight: {max: 92.0, min: 45.0, mean: 66.3, sum: 398.0, count: 6.0} height: {max: 185.0, min: 162.0, mean: 171.7, sum: 1030.0, count: 6.0}
[0, 50)
age (key): [50, 100]
weight: {max: 93.0, min: 45.0, mean: 71.5, sum: 286.0, count: 4.0} height: {max: 160.0, min: 140.0, mean: 148.5, sum: 594.0, count: 4.0}
[50, 100] age (key): 10,18,20,25,30,38 weight: 78,92,64,45,51,68 height: 165,163,162,185,179,176 age (key): 50,65,70,75 weight: 45,86,93,62 height: 145,160,149,140 図 4 深さが 1 の APA 木の例 age (key): [0, 100] age (key): [0, 49] [0, 50) age (key): [50, 100]
weight: {max: 93.0, min: 45.0, mean: 71.5, sum: 286.0, count: 4.0} height: {max: 160.0, min: 140.0, mean: 148.5, sum: 594.0, count: 4.0}
[50, 100]
age (key): [0, 24]
weight: {max: 92.0, min: 64.0, mean: 78.0, sum: 234.0, count: 3.0} height: {max: 165.0, min: 162.0, mean: 163.3, sum: 490.0, count: 3.0}
[0, 25)
age (key): [25, 49]
weight: {max: 68.0, min: 45.0, mean: 54.7, sum: 164.0, count: 3.0} height: {max: 185.0, min: 176.0, mean: 180.0, sum: 540.0, count: 3.0}
[25, 49] age (key): 10,18,20 weight: 78,92,64 height: 165,163,162 age (key): 25,30,38 weight: 45,51,68 height: 185,179,176 age (key): 50,65,70,75 weight: 45,86,93,62 height: 145,160,149,140 図 5 図 4 の APA 木で左のリーフノードを分割した後の APA 木 フノードを分割すると, 図5のように[0, 24]の年齢を担当す るリーフノードと,[25, 49]の年齢を担当するリーフノードの 二つが生成される. b ) リーフノードの併合処理(木の縮小) リーフノードの併合処理は,二つの隣接する(同じ親ノード を持つ)リーフノードの担当する領域を併合して新たなリーフ ノードを作成し,親ノードを新たなリーフノードで置き換え る.この際,新たなリーフノードの集約値を計算する必要があ るが,これは元々のリーフノード二つの持つ集約値を部分集約 法によって集約することで計算できる.すなわち,実際のデー タをスキャンして集約値を再計算する必要はない.
4.
実
験
本節では,実験によってAPA木と 水平分割方式を比較する. 4. 1 実 装 実験ではAPA木と 水平分割方式をそれぞれ実装し用いた. APA木でマージ対象のリーフを選ぶアルゴリズムとしてはLRU ポリシーの効率的な近似アルゴリズムであるCLOCK [17]を用 いた. 4. 2 データセット 実験ではMembers(age INT, height DOUBLE, weight DOUBLE) なる,3つの属性を持つ人工データを生成して用いた.このう ちage属性をクラスタ索引として用いた.各属性の値は一様分 布から生成した.全ての実験を通して,データセットのレコー ド数は100Kとした. 4. 3 ワークロード 本稿で提案するグループ方式APA木は「ユーザがアクセス するデータ領域に偏りがある」場合に効果的となる.このこと を確認するため,実験では以下の二種類のワークロードを人工 的に生成し用いた. (1) ワークロード(a)は,まんべんなくデータがアクセス されるケースを再現する.このワークロードは,次の手順で一 様分布から生成されたキー属性ageに対するレンジ集約クエリ [l, l + w]群からなる:まず,レンジの左端lを一様分布から生成 する.次に,レンジクエリのレンジ幅wを,正規分布N(µ, σ2) から生成する. (2) ワークロード(b)∼(d)は,アクセスされるデータが 偏っているケースを再現する.このワークロードは,次の手順 でZiphianに従うよう生成されたキー属性ageに対するレンジ集 約クエリ[l, l + w]群からなる:まず,レンジの左端lを,Ziphian に従うよう生成する.次に,レンジクエリのレンジ幅wを,正 規分布N(µ, σ2)から生成する.アクセスするデータの偏りの強 さをコントロールするZiphianのパラメータsについては,偏 りの強さが結果に与える影響を見るため,s= 2, s = 3, s = 4の 三通りを選び,異なるワークロードとする. それぞれのワークロードは,上記の手順で生成された100個の クエリから構成した.なお,上記のワークロード生成において, レンジ幅を生成する正規分布のパラメータはµ = 5, σ2= 10に 固定した. 図6は,上記の手順で生成された各ワークロードのアクセス するデータ領域の分布をあらわした図である.図6から,一 様分布がまんべんなくデータ領域全体へアクセスすることと, Ziphianがパラメータsの値が大きくなるほど特定のキー領域 へ集中的にアクセスすることが確認できる.本節の以降では, これらのワークロードを提案方式であるAPA木と従来方式で
ある 水平分割方式で処理し,クエリのアクセスするデータ領域 の偏りがこれら方式に与える影響を見る. 4. 4 I/O量の比較 提案方式APA木の有効性を確認するため,上述の100Kの レコードからなるデータセットについて,グループ作成方式と してAPA木と 水平分割方式を選んで上述のワークロードを実 行した際の,部分集約法のI/O量(注 5)を計測した.APA木は データをクエリに応じて定められたグループ数の制限のなかで 動的にグループ分けし,水平分割方式はデータを指定されたグ ループ数で静的に分割する.水平分割方式はグループ数が大き くなるほどI/O量が減るため[18],APA木との比較のために, 実験ではグループ数(APA木ではグループ数の上限)が,32, 64, 128, 256であるときの四通りについてワークロード実行時 のI/O量を計測した. 図7,図8,図9,図10の各図は,グループ数が32, 64, 128, 256であるときに,前述のワークロード内のクエリを順に実行 した際の累積I/O量をあらわしている.図中,APA-Treeは提案 方式,SMAは従来方式[9, 13, 19]に対応する.図の横軸は順に 実行されたワークロード内のクエリをあらわし,縦軸はクエリ 実行時のI/O量の積み上げ値をあらわす.すなわち,右端にお ける縦軸の値は,ワークロード内のクエリを全て実行し終えた 時点での,トータルのI/O量をあらわす.この値が小さいほど, 方式は有効であるといえる. 4. 4. 1 データ領域の偏りが与える影響 はじめに,ユーザのアクセスするデータ領域の偏りが提案方 式と従来方式に与える影響を見る.図7は,グループ数が32 であるときの実験結果をあらわしている.図7から,全ての ワークロードで,提案方式APA木が従来方式である水平分割 方式よりも少ないI/O量でワークロードを実行できたことがわ かる.また,(a)∼(d)を比較することで,アクセス領域の偏り が強くなる(Zipfianのパラメータsの値が大きくなる)ほど, そのI/O量の差が大きくなることが分かる.以上から,提案方 式APA木が水平分割方式と比べ高性能であり,その性能差が ユーザのアクセスするデータ領域に偏りがあるほど大きくなる ことがいえる. 4. 4. 2 グループ数が与える影響 つぎに,グループ数が提案方式と従来方式に与える影響を見 る.図7∼図10を比較すると,グループ数を増やすほど両方式 での総I/O量が小さくなることが分かる.また,グループ数を 増やすほどAPA木と水平分割方式の性能差は縮まり,グループ 数が256の場合では全てのワークロードでAPA木よりも水平 分割方式の方が有効となることが分かる.これは前述のとおり, 水平分割方式ではグループ数がグループ分けの基準となる属性 の一意な値の数に近づくほど,I/O量が減るためである[18](注 6). しかし,水平分割方式ではグループ数Nに対して集約値の再集 約の計算量がO(N)であるため(注 7),グループ数を大きくする (注 5):本稿では I/O 量として,参照されたレコード数を用いる. (注 6):究極的には,グループ分けの基準となる属性値で Group-by し,グループ ごとに集約値を持つことで,I/O 量は最小となる.
(注 7):APA 木の計算量は最良 O(log N),最悪 O(N) であり,水平分割方式より
ことがそのまま性能向上に繋がるわけではない.また,グルー プ作成数を増やすと管理すべき集約値の数も増え,主記憶を圧 迫する.以上から,グループ作成につかわれる属性の一意な属 性値が小さい場合は従来方式水平分割方式が有効であるという ことがいえる.
5.
関 連 研 究
5. 1 Data Skipping テーブルを複数のグループへ水平分割しグループ毎に軽量イ ンデックスを持つという試みは,問合せの実行時にグループの スキャンを省いて高速化を図るData Skippingの領域で研究され てきた[15, 16].これらData Skipping技術は軽量インデックス を,選択演算σCでスキャン対象のブロックBのスキャン処理 をスキップすることができるか,すなわちσC(B)= ∅となるか を判定するために利用する.これに対し,部分集約法では軽量 インデックスを,対象のグループの結果が選択演算により全て 選択され部分計算結果が再利用できるか,すなわちσC(B)= B となるかの判定に活用する.Data Skippingの分野では近年グ ループのスキップ効率を高めるためのレコードの並び順を求め る試み[16]があり,これは部分集約法で部分計算結果の再利用 効率を高めるために利用することができると考えられる. 5. 2 SQL-on-Hadoopにおけるファイルフォーマット SQL-on-Hadoopは分散ファイルシステムHDFS上に置かれた データを問合せ対象とし,CSVをはじめとする様々なファイル 形式のデータに対し直接SQLの問合せを実行することができ る.このとき,システムの定めるファイル形式にデータを変換 することで問合せを高速化することも可能であり,特に集約処 理をはじめとするデータ分析タスクは列指向的であるため,列 指向のファイルフォーマットがよく用いられている[1, 10, 12]. 近年注目を集めている列指向のファイルフォーマットに,Hiveで用いられているORC File [12]と,Impalaで用いられている
Apache Parquet [1]がある.これらは列指向のファイルフォー
マットであるが,同じ行に属す値ができるだけ同じノードに
格納されるようにデータを分割してHDFSへ分散配置するた
め(注 8),行単位でのアクセスも効率的であるという特徴を持つ.
これはPAX [4]やRCFile [10]の考えにもとづく.また,ORC
File/Parquetは列方向のデータ圧縮やファイル内に格納された軽
量のインデックスを利用して問合せ時の計算量やI/O量を削減
し,大幅な問合せの高速化を実現する[7].
5. 3 ARF (Adaptive Range Filter)
σC(B)= ∅の判定については,Cがレンジクエリである場合
に利用できるデータ構造Adaptive Range Filter (ARF)が近年提
案されている[6].ARFは,問合せの条件としてある属性の範
囲が指定された場合,グループ内にその条件を満たすレコー ド群がひとつも存在しないかどうかを効果的に判定すること
ができる.Bloom filterのように,条件を満たすレコードがひ
も小さい.
(注 8):ORC File では同じ行に属す値は必ず同じノードに格納されるが,Parquet では異なるノードに格納されてしまうことがある.
0 20 40 60 80 100120140 Accessed key 0 100 200 300 400 500 Fre qu en cy
Uniform
(a)一様分布 0 20 40 60 80 100 120 140 Accessed key 0 100 200 300 400 500 Fr eq ue nc y Zipf (s = 2) (b) Zipfian (s=2) 0 20 40 60 80 100 120 140 Accessed key 0 100 200 300 400 500 Fr eq ue nc y Zipf (s = 3) (c) Zipfian (s=3) 0 20 40 60 80 100 120 140 Accessed key 0 100 200 300 400 500 Fr eq ue nc y Zipf (s = 4) (d) Zipfian (s=4) 図 6 各ワークロードでの,クエリのアクセスするレコードのキー値のヒストグラムを算出した もの.Zipfian からクエリを生成した場合,パラメータ s の値が大きくなるほど,アクセス する領域に偏りが生まれることが確認できる. 0 20 40 60 80 Queries 0 100000 200000 300000 400000 500000 # of rea d ( cu mu lat ive ) APA-Tree SMA (a)一様分布 0 20 40 60 80 Queries 0 100000 200000300000 400000500000 600000 # of rea d ( cu mu lat ive ) APA-Tree SMA (b) Zipfian (s=2) 0 20 40 60 80 Queries 0 100000 200000 300000 400000 500000 600000 # of rea d ( cu mu lat ive ) APA-Tree SMA (c) Zipfian (s=3) 0 20 40 60 80 Queries 0 100000 200000 300000 400000500000 600000 # of rea d ( cu mu lat ive ) APA-Tree SMA (d) Zipfian (s=4) 図 7 APA木と 水平分割方式で 100K のレコードに対して 32 個のグループを作成し,各ワーク ロード内のクエリを順に実行した際の累積 I/O 量. 0 20 40 60 80 Queries 0 50000 100000 150000 200000 250000 300000 # of rea d ( cu mu lat ive ) APA-Tree SMA (a)一様分布 0 20 40 60 80 Queries 0 20000 40000 60000 80000 100000 120000 140000 160000 180000 # of rea d ( cu mu lat ive ) APA-Tree SMA (b) Zipfian (s=2) 0 20 40 60 80 Queries 0 20000 40000 60000 80000 100000 120000 140000 160000 # of rea d ( cu mu lat ive ) APA-Tree SMA (c) Zipfian (s=3) 0 20 40 60 80 Queries 0 50000 100000 150000 200000 250000 300000 350000 # of rea d ( cu mu lat ive ) APA-Tree SMA (d) Zipfian (s=4) 図 8 APA木と 水平分割方式で 100K のレコードに対して 64 個のグループを作成し,各ワーク ロード内のクエリを順に実行した際の累積 I/O 量. 0 20 40 60 80Queries 0 20000 40000 60000 80000 100000 120000 140000 160000 180000 # of rea d ( cu mu lat ive ) APA-Tree SMA (a)一様分布 0 20 40 60 80Queries 0 10000 2000030000 4000050000 6000070000 80000 # of rea d ( cu mu lat ive ) APA-Tree SMA (b) Zipfian (s=2) 0 20 40 60 80Queries 0 10000 20000 30000 40000 50000 60000 # of rea d ( cu mu lat ive ) APA-Tree SMA (c) Zipfian (s=3) 0 20 40 60 80Queries 5000 10000 15000 20000 25000 30000 35000 40000 # of rea d ( cu mu lat ive ) APA-Tree SMA (d) Zipfian (s=4) 図 9 APA木と 水平分割方式で 100K のレコードに対して 128 個のグループを作成し,各ワーク ロード内のクエリを順に実行した際の累積 I/O 量. とつも存在しないにも関わらず,存在すると判定してしまう False-positive性を持つのが特徴である.なお,[8]はARFの対 象とした問題を理論的に解析し,指定したFalse-positive率を得 るためのデータ構造の理論的最小サイズなどについて議論して いる. 5. 4 OLAP Hoらは多次元OLAPキューブにおけるレンジ集約計算の高 速化のため,レンジ上のPrefix-SumやPrefix-Maxを計算して 保持するデータ構造を提案している[11].彼らの提案するデー タ構造はアクセス頻度を考慮せず,全領域について均等に事前 計算をおこなうという点で,本研究とはコンセプトが異なる. 本研究と彼らの提案するデータ構造は相互補完的な関係にあり, 彼らの提案するデータ構造に本研究で用いたアクセス頻度に応 じた成長と併合処理を組み合わせることで,多次元OLAPにお ける集計値データのサイズを縮小できると考えられる.0 20 40 60 80 Queries 0 20000 40000 60000 80000 100000 120000 140000 160000 180000 # of rea d ( cu mu lat ive ) APA-Tree SMA (a)一様分布 0 20 40 60 80 Queries 0 10000 2000030000 4000050000 6000070000 80000 # of rea d ( cu mu lat ive ) APA-Tree SMA (b) Zipfian (s=2) 0 20 40 60 80 Queries 0 5000 10000 15000 20000 25000 30000 35000 40000 45000 # of rea d ( cu mu lat ive ) APA-Tree SMA (c) Zipfian (s=3) 0 20 40 60 80 Queries 5000 10000 15000 20000 25000 30000 35000 # of rea d ( cu mu lat ive ) APA-Tree SMA (d) Zipfian (s=4) 図 10 APA木と 水平分割方式で 100K のレコードに対して 256 個のグループを作成し,各ワー クロード内のクエリを順に実行した際の累積 I/O 量. 5. 5 サンプリングによる集約処理の高速化 集約演算の高速化アプローチのひとつは,データのサンプリ ングである.BlinkDB [3]はHiveを拡張し,HDFS上の処理対 象データをサンプリングし近似結果を算出することで,集約演 算を含んだ問合せへの応答時間を短縮している.BlinkDBは問 合せへの応答時間と近似による誤差のトレードオフ関係をシス テマティックに扱い,ユーザの要求する応答時間から,結果に 生じる最大誤差を算出することができる.[14]にも同様の試み がある.
6.
結
論
本稿は,実際のデータ分析でよく見られる「ユーザがアク セスするデータ領域に偏りがある場合」に部分集約法が高い 性能を示すためのグループ作成方法として,APA木(AdaptivePartial-Aggregation Tree)を提案した.APA木はセグメント木を ユーザのクエリに対して適応的に成長・縮退させることにより, ユーザが頻繁にアクセスするデータ領域については細かく,あ まりアクセスされないデータ領域については粗く,グループを 作成して集約値を計算し保持する.本稿はAPA木の管理方法 と,APA木と部分集約法を利用した集約処理について述べた. そして,実験により,ユーザがアクセスするデータ領域に偏り がある場合APA木が水平分割方式と比べ効率的となることを 見せた. 文 献 [1] Parquet. http://parquet.io/.
[2] Treasure Data. https://www.treasuredata.com/.
[3] S. Agarwal et al. BlinkDB: queries with bounded errors and bounded response times on very large data. In EuroSys, pages 29–42. ACM, 2013.
[4] A. Ailamaki et al. Weaving Relations for Cache Performance. In
VLDB, pages 169–180, 2001.
[5] K. Alexiou, D. Kossmann, P. Larson. Adaptive Range Filters for Cold Data: Avoiding Trips to Siberia. PVLDB, 6(14):1714–1725, 2013. [6] A. Eldawy, J. J. Levandoski, P. Larson. Trekking Through Siberia:
Managing Cold Data in a Memory-Optimized Database. PVLDB, 7(11):931–942, 2014.
[7] A. Floratou, U. F. Minhas, F. ¨Ozcan. SQL-on-Hadoop: Full Circle Back to Shared-Nothing Database Architectures. PVLDB,
7(12):1295–1306, 2014.
[8] M. Goswami et al. Approximate Range Emptiness in Constant Time and Optimal Space. In SODA, pages 769–775, 2015.
[9] G. Graefe, H. A. Kuno. Fast Loads and Queries. TLDKS, 2:31–72, 2010.
[10] Y. He et al. RCFile: A fast and space-efficient data placement struc-ture in MapReduce-based warehouse systems. In ICDE, pages 1199–
1208, 2011.
[11] C. Ho et al. Range Queries in OLAP Data Cubes. In SIGMOD, pages 73–88, 1997.
[12] Y. Huai et al. Major technical advancements in apache hive. In
SIG-MOD, pages 1235–1246. ACM, 2014.
[13] G. Moerkotte. Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing. In VLDB, pages 476–487, 1998. [14] S. Nirkhiwale, A. Dobra, C. M. Jermaine. A Sampling Algebra for
Aggregate Estimation. PVLDB, 6(14):1798–1809, 2013.
[15] V. Raman et al. DB2 with BLU Acceleration: So Much More than Just a Column Store. PVLDB, 6(11):1080–1091, 2013.
[16] L. Sun et al. Fine-grained partitioning for aggressive data skipping. In SIGMOD, pages 1115–1126, 2014.
[17] A. S. Tanenbaum. Modern Operating Systems. Prentice Hall Press, Upper Saddle River, NJ, USA, 3rd edition, 2007.
[18] 小山田昌史 et al. データの部分集約による高速かつ正確なデータ 集計処理の実現. Technical Report 19, nov 2014.
[19] 小山田昌史 et al. PA-Proxy: SQL-on-Hadoop におけるデータ集 計処理を精度の劣化なく高速化するフレームワーク. In DEIM, 2015.