甲南大学大学院 自然科学研究科 知能情報学専攻 修士論文No. 179
Web
ニュースを用いた漫才台本自動生成に
基づくコミュニケーションロボット
Manzai Robots: Automatic Generation of Manzai Scenario
from Web News
2016
年
3
月
真下 遼
要旨
ロボット工学の技術が急速な進歩に伴いロボットが人の生活に深く浸透していく一方で,人 とロボットのスムーズなコミュニケーションは未だ実現していない.これまでにも我々は,人と ロボットとのコミュニケーションの抵抗の緩和を目指した漫才ロボットに,漫才を実演させる ための漫才台本をWebニュースから自動で生成する手法を提案してきた.本論文では,漫才ロ ボットのおもしろさとわかりやすさの向上を目指して漫才台本自動生成の手法を改善する.お もしろさの向上において,文の持つ感情情報に着目して笑いを喚起する対話文の生成を行う.わ かりやさの向上では例え表現に着目し,Webニュースの情報を価値とユーザの興味に合わせて 表現する手法を提案する.Summary
Communication robots start to become deep relationship to people’s lives by the development of robotics. However, it is difficult for robots to communicate smoothly with people. We have proposed a system that generates humorous dialogue scenarios automatically to“Manzai“ robots aiming at that people to communicate smoothly with robots. In this thesis, we improve automatic generation system to advance the funny and understandability. In improvement of funny, we propose sentiment mistake gaps. Futuremore we propose the method of automatic generation of paraphrasing sentences from web news that user support of understanding of news articles.
目 次
1 はじめに 1 2 関連研究 3 3 漫才ロボットのシステム 4 3.1 システムの概要 . . . . 4 3.2 漫才ロボット . . . . 5 4 漫才台本自動生成 6 4.1 XML形式の漫才台本 . . . . 6 4.2 つかみ . . . . 7 4.3 本ネタ . . . . 9 4.3.1 言葉遊びボケ . . . . 10 4.3.2 ノリツッコミ . . . . 11 4.3.3 対立ボケ. . . . 11 4.3.4 過剰ボケ. . . . 12 4.3.5 感情ボケ. . . . 12 4.4 オチ . . . . 15 5 例え表現 16 5.1 例え表現の定義 . . . . 17 5.2 価値の推定 . . . . 18 5.3 ものの価値の決定 . . . . 19 5.4 例え表現自動生成手順 . . . . 19 6 実験 23 6.1 システム評価実験 . . . . 23 6.2 コンテンツの比較実験 . . . . 27 6.3 メディアの比較実験 . . . . 32 7 まとめと今後の課題 35 8 謝辞 36 9 研究業績 36図 目 次
1 おかしみの構造図 . . . . 2 2 漫才台本自動生成システムの流れ . . . . 5 3 漫才ロボットあいちゃん(左)とゴン太(右). . . . 6 4 感情に合わせたロボットの表情 . . . . 6 5 「ノーベル」をお題として自動生成する漫才台本(xml)のつかみ部分 . . . . . 8 6 ニュース記事の感情抽出の流れ . . . . 9 7 「ノーベル」をお題として自動生成する漫才台本の本ネタ部分 . . . . 10 8 ノーベル」をお題として自動生成する漫才台本の感情ボケ . . . . 13 9 漫才台本のオチ部分と謎かけ. . . . 15 10 例え表現生成イメージ . . . . 17 11 例え表現自動生成システムフロー . . . . 20 12 実験に用いたニュース記事 . . . . 23 13 図12(2)の記事に対してシステムが自動生成した漫才台本 . . . . 24 14 つかみ,本ネタ,オチの評価結果 . . . . 26 15 ボケとツッコミの評価結果 . . . . 27 16 評価項目(5)-(8)の評価結果 . . . . 28 17 ラグビーワールドカップに関するニュース記事. . . . 29 18 図17の記事に対してシステムが自動生成した漫才台本 . . . . 30 19 漫才ロボットとニュースを読むロボットの評価結果 . . . . 31 20 漫才ロボットとニュースを読むロボットの比較による評価結果 . . . . 32 21 TVMLによるCGキャラクターのイメージ. . . . 33 22 漫才ロボットとCGキャラクターの評価結果 . . . . 34 23 漫才ロボットとCGキャラクターの比較による評価結果 . . . . 35表 目 次
1 漫才台本生成に適さないニュース本文中の語 . . . . 4 2 三段構成による漫才の概要 . . . . 7 3 ニュース記事に対する感情値算出結果. . . . 9 4 キーワードと共起する形容詞. . . . 11 5 キーワードに関して取得した対立語 . . . . 13 6 例え表現に用いる語とその定義条件 . . . . 17 7 将棋棋士に属する語とその価値 . . . . 21 8 日本のテニス選手に属する語とその価値 . . . . 21 9 漫才ロボットとニュースを読むロボットの評価結果のt検定 . . . . 32 10 漫才ロボットとCGキャラクターの評価結果のt検定 . . . . 331
はじめに
近年,ロボット工学の技術が発展し,「日本再興戦略」の重点政策の1つにロボット関連政策1 が挙げられている.また,2015年にはソフトバンクグループスより感情認識パーソナルロボッ トPepper2が比較的安価な値段で一般に販売され話題となった.Pepperに代表されるように人 とロボットが積極的にコミュニケーションを図ることを目的としたコミュニケーションロボッ トの研究開発は,近い将来にロボットがより身近な存在となって我々人との生活に密着し共存 する社会の実現を予期させる.しかしながら,ロボットの急速な社会への浸透に反して,人が ロボットをコミュニケーションの対象と捉えるには未だ抵抗が残り,人とロボットのインタラ クションの活性化は重要な課題であると考えられるこの問題点において神田ら[1]は,ロボット 同士の対話観察に着目し,人がロボット同士の対話を観察することが人とロボットのコミュニ ケーションの活性化に繋がるなることを実験を通して実証している.そこで本論文ではロボッ ト同士の対話に着目し,ロボット同士の対話から人が容易にロボットとのコミュニケーション ギャップの解消ができることを目的とするコミュニケーションロボットの開発を行う. 本論文では,ロボット同士の対話の中でも,娯楽性が高く今日でも老若男女問わず親しみの ある対話であると考えられる漫才に着目する.さらに対話から構成される漫才が,情報提供の 役割を持つことにも着目すると,ユーザにはより理解しやすく親しみのある情報提供が望まし いと考えられる.元お笑い芸人であり作家の松本哲也氏は「時事ネタで漫才を作るのは,一番 お客さんの共感を得られやすい」[2]と述べている.一方で,今日のインターネットの普及によ りWeb上には多くの知識が溢れている.同時にWebマイニング技術およびテキストマイニング 技術の発展により,Web上から多種多様な情報を抽出し利用することが可能になってきている. 本論文では,時事情報としてWebニュース記事を基にし,おもしろおかしい対話からなる漫 才台本をインターネットから様々な知識を取得することでリアルタイムで自動生成する手法を 提案する.さらに,自動生成した漫才台本を用いて2体のロボットが漫才を演じる漫才ロボッ トを提案する.即ち,本論文で提案する漫才ロボットは,コンテンツとしてWebニュースを用 い,その提供媒体としてロボットを利用した新たな受動型情報提供メディアである.本論文で 提案する漫才ロボットの利点を以下に述べる. • ロボットに対する発話理解や親しみが向上する. ロボットが行う漫才による対話を通じてユーザは受動的に負担なくロボットとのインタラ クションが活性化する. • ニュース離れの克服を期待できる. 漫才ロボットでは笑いを交えて情報を提供することで,堅苦しく難しい内容の多いニュー ス記事であってもユーザは親しみを持って,ロボットの漫才を観るという受動的な行為だ けで容易に情報を得ることが可能である. • 情報視野の拡大が見込める. 漫才台本自動生成では,ボケやツッコミ等の対話生成のためにWeb上あるいはコーパス 上から様々な知識を取得してユーザに提示する.これによりただニュース記事を読むだけ では得られない情報の獲得が行える. 1「日本再興戦略」改訂2014https://www.kantei.go.jp/jp/singi/keizaisaisei/pdf/honbun2JP. pdf 2Pepper http://www.softbank.jp/robot/special/pepper/図1:おかしみの構造図 一方で,漫才台本の生成において笑いによるおもしろさと情報提供メディアとしてのわかり やすさの向上は最重要事項と考えられる. おもしろさに関して,安倍[3]はおかしみを笑いの現象を喚起する1つの要因と位置づけ,お かしみは異なる2つの概念の対比関係にによって生まれるという考えのもと図1 (1)のようなお かしみの構造図を提唱している.本論文ではこのおかしみの構造図に着目し,安倍のおかしみ の構造図を漫才台本自動生成用に独自に対応させた図1 (2)に示すようにおかしみの構造図を定 義する.本論文で提案するおかしみの構造図において,安倍のおかしみの構造図における共通 の条件は,Webニュース記事本文の一文が対応する.さらにそのWebニュース記事本文に出現 するある単語が概念Aとして設定する.ここからおかしみを生成するために,本論文では,概 念Aの単語と対比した単語を概念Bとして抽出する.この時,対比の要素として本論文では感 情に着目する.Webニュース記事本文から感情を抽出し,その抽出した感情と逆の感情を持つ 文を新たに生成する手法を提案する. わかりやすさの向上に関して本論文では,例え表現に着目した.本論文で提案する例え表現 とは,あるニュース記事に関して知識のないユーザに対して,ニュース記事のタイトルをユー ザの興味に例えることである.これによりユーザのニュースに対する興味喚起及び内容理解支 援を図る.例え表現は,例える元の単語と価値が同等な単語に変換することにより,よりわか りやすい例え表現になることに着目し,本論文ではものの価値を考慮した例え表現の自動生成 手法を提案する. 以下,第2章では関連研究について,第3章では漫才ロボットのシステムについて,第4章 では漫才台本自動生成について,第5章では例え表現にについて,第6章では実験についてを 述べる.最後に第7章では,まとめと今後の課題についてを述べる.
2
関連研究
ロボットを用いた漫才に関する研究として,林ら[4]は2体のヒューマノイドロボットを用 いた漫才を新たな社会的受動メディアと位置付け,人間の漫才とロボット漫才との比較実験を 行い,その結果エンターテインメントとしてのロボット漫才の有用性を示した.林らの提案す るロボット漫才ではロボットの動作や振る舞いを人間の漫才に近づけることに着目しているが, 本論文では漫才の内容である台本に着目することで情報提供メディアとしての漫才ロボットの 有用性を求めている点で異なる. 漫才台本の自動生成に関する研究では吉田ら[5][6]の対話文自動生成システムが挙げられる. これは,ある文書を与えると,文書の各文に対して単語の置き換えによりボケを生成し,同時 にその誤りを訂正する文を挿入することを繰り返すことで漫才台本の生成を行うシステムであ る.また,漫才技法にも着目し,「例えツッコミ」や「かぶせ」といった技法の自動生成手法も 提案している.さらに,生成した漫才台本を用いて2体のヒューマノイドロボットに発話や動 作を通して漫才を実演させている.本論文では,漫才台本生成の対象の文書をニュース記事に 絞っており,台本の構成方法等が異なる.さらに,本論文で提案する感情ボケのように生成す るボケの種類や手法が異なる. ニュース記事を基にした漫才台本自動生成の有用性の1つにニュースの理解力向上を挙げて いるが,同様にニュースの理解力向上に着目した研究として,北山ら[7]は,ユーザが閲覧し ているニュースに関連した比較ニュースをアーカイブから的確に検索する検索方式を提案した. Souneil[8]らは,NewsCubeと呼ばれるアスペクトに着目したニュース記事閲覧サービスを開発 し,Media Biasによる読者の偏った考えや情報操作の緩和において有用性があることを実証し た.田中ら[9]は,ニュース記事の理解において重要となる背景知識をエンティティに着目して Web上のリソースから抽出する方法を提案した.平田ら[10]はニュース記事内に記述されてい るイベント情報を抽出しユーザの興味に合わせた系列を構成して提示することでニュース記事 の閲覧を支援するシステムを提案した.張ら[11]はニュース記事の印象に着目して,ニュース の印象をユーザに提示することでニュースサイトの報道傾向を視覚的に比較できるようにした. 石井ら[12]はニュースによる事象間の因果関係をSVOの文法構造に着目してネットワーク構造 で表現す手法を提案した.また情報理解支援という点では,西原ら[13]は,Webページの検索 結果をクラスタリングすることで,情報の難易度と学習順序を検出し,難易度と学習順序の組 合せにより未知語の理解支援を行った.本論文では,ユーザの興味に合わせた例え表現による補 足情報を用いることで,閲覧記事への親しみの向上による理解支援を目指している点が異なる. 本論文では,ユーザが閲覧するニュース記事自体を娯楽性のある対話形式に変換することによ り,ニュース記事への親しみをユーザに持たせることで理解力向上を目指している点で異なる. 本論文では,漫才台本の自動生成に感情を取り入れる手法を提案している.感情の情報を利 用した既存研究は様々あり,Chambersら[14]はメール等の文書に対して感情分析を行いポジ ティブ,ネガティブ,ニュートラルを判別し感情に合わせて色で表現するスマートフォンアプ リケーションStress@Workを開発している.Johan[15]らは感情と株価との関連性に着目して, TwitterのTweetから感情を取得しダウ・ジョーンズ工業株化平均の変化の予測を行っている. Nakamura[16]らはニコニコ動画の動画のコメントの感情情報を抽出し,それをインデックスと して利用した新たな検索ランキング手法を提示している.いずれの利用方法においても感情を 情報判断の重要な要素としており,同時に感情は直感的にも人間に把握しやすい情報であると 考えられる.本論文でもそれらの特徴に着目してニュース記事本文の感情を取得し,おかしみの構造図を構成する要因として利用している. また,本論文で提案する例え表現のような言い換え表現の自動生成に関する研究[17]も様々 あるが,言い換え表現とは,ある言語表現の意味を保ったまま表現を変換するのに対して,本論 文で提案する例え表現では意味ではなく価値観を保つことが重要となる.山根ら[18]Nグラム と印象を用いて、単語の長さに基づいくことわざの生成を提案している.滝沢ら[19]は駄洒落 の自動生成を提案している.提案手法では、Webニュース記事から漫才形式の対話生成を行っ ている点が異なる. 本論文で提案する例え表現の自動生成において価値に着目しているが,同じく価値の検出に 関する研究として木虎ら[20]は,ユーザが持っている価値観と閲覧するWebページには関連が あるという仮説に基づいて,Webアクセス履歴からユーザの価値観を分類した.奥ら[21]は, ユーザの嗜好及びその時のユーザの状況を表すユーザコンテキストに着目し,これらを考慮し た独自の価値判断基準モデルを定義した.また,定義したモデルを用いてユーザに推薦候補と するアイテムのランキングを行っている.本論文で提案する例え表現に用いる価値では,ユー ザが未知としている単語に対して近似している価値の単語を提示するため,ユーザ固有の価値 観ではなく客観的・社会的価値観を類推する必要がある.
3
漫才ロボットのシステム
3.1
システムの概要
本論文で提案する漫才ロボットの概要を以下と図2に示す. 1. ユーザが漫才のお題(キーワード)を入力する. 2. システムは入力されたキーワードを検索クエリとして関連するWebニュースを最新のも のから,無作為に1記事を抽出する.本論文ではYahoo!ニュースサイト3を用いる. 3. 抽出した記事部分から様々なボケやツッコミの対話文を生成し漫才台本を自動生成する. 4. 自動生成した漫才台本を2体のロボットが演じる. 漫才台本自動生成システムではまず,ユーザがどのような内容に関する漫才をロボットに行っ て欲しいかのお題(キーワード)を入力する.ここで,ユーザが入力として想定するキーワー ドは,例えば「ノーベル賞」のような1語であったり,あるいは「ノーベル賞 日本人」といっ たように複数語の組み合わせでも構わない.または,キーワードとして漫才台本に変換したい ニュース記事のURLを直接指定することも可能である.次にシステムは,ユーザのクエリによ り取得した記事のタイトルと本文の抽出を行う.この時,記事の本文の長さは記事によって大 表1:漫才台本生成に適さないニュース本文中の語ストップワード
死
殺
亡
災
訃報
暴行
乱暴
脱線
墜落
未曾有
図2:漫才台本自動生成システムの流れ きく異なるが,本論文の漫才はロボットが漫才を演じる時間を一般にテレビ等で漫才師が行う4 分以内と収めるため,抽出する記事の本文の文字数を経験的に400文字以下に制限する.ただ し,記事の概要を損なう本文の抽出を避けるために本文の抽出を段落単位で行う.通常ニュー ス記事は内容理解に重要な項目順に構成される4ため,第1段落から順に400字の文字制限が 超えない範囲まで段落単位で本文を抽出する.また,漫才の題材に人の死や不幸を用いるのは 不謹慎であると考え,「死」や「殺」等をストップワードとし(表1参照),記事タイトル及び本 文中にこれらが含まれている場合は台本生成に不適切な記事として記事の選出をやり直す.そ して,提案手法により漫才台本を自動生成する.漫才台本の生成はキーワードを入力したその 場でユーザがリアルタイムに約2∼3分程度で行う.本論文では漫才台本をXMLのファイル形 式で生成する.最後に出来上がった台本を基に2体のロボットが漫才を演じる.
3.2
漫才ロボット
本論文で提案する漫才台本を演じるロボットは図3に示す2体のロボットである.背の高い 方のあいちゃん(高さ:100cm×幅:52cm×奥行き:60cm)がツッコミ役,背の低い方のゴン 太(高さ:55cm×幅:50cm×奥行き:50cm)がボケ役をそれぞれ担当する.漫才は音声合成 を用いて台本の内容を発話する.2体のロボットには本体背部にPCを搭載しており,無線LAN により2台のパソコンが通信によって漫才台本の発話終了を互いに感知する.また,あいちゃ んに搭載されているPCはインターネットにアクセスしており記事の取得や漫才台本の自動生 成を行うサーバとなっている.2体のロボットはいずれも手足等のインタフェースが存在しない 4ウィキニュース スタイルマニュアルhttp://ja.wikinews.org/wiki/図3:漫才ロボットあいちゃん(左)とゴン太(右) 図4:感情に合わせたロボットの表情 ため,モーターでの回転動作でツッコミの動作を表現する.目の表情は,2つの有機ELディス プレイに図4のような画像を移すことで表現する.画像の種類は50種類あり,台本に合わせた 様々な感情を表現することが可能である.
4
漫才台本自動生成
漫才台本自動生成にあたり,台本をある程度形式化する必要がある.本論文では灘本ら[22] が提案した漫才台本自動生成の枠組みを使用し,漫才台本をつかみ,本ネタ,オチに分割した 三段構成の流れでの漫才台本の生成を行う.また,種々ある漫才スタイルのうち「しゃべくり 漫才」と呼ばれる話芸のみで統一されたボケ役とツッコミ役の2体のロボットの対話形式で行 う.つかみ,本ネタ,オチの役割の概要および各部で本提案システムが自動生成するボケを表2 に示す.4.1
XML 形式の漫才台本
お題を「ノーベル賞」とした時に,提案手法により出力する漫才台本図5に示す.本論文で用 いる漫才台本はロボットが内容を処理しやすいようにxmlのファイル形式で出力する.漫才台 本には台詞以外に細かい動きや表情の変化等を記述し,タグによる命令処理を1行毎に上から 下に台本を読み込んで実行し,漫才ロボットによる漫才を実演する.タグ中の「cast」が発話, 「look」が回転動作による視点移動,「PEmo」が表情の変化の命令処理を表し,命令対象は「A」 があいちゃん,「G」をゴン太でそれぞれ指定する.例えば,図5の「<cast name=”A”>どもー、表2:三段構成による漫才の概要 構成名所 役割 本システムで自動生成するボケ とツッコミ つかみ 挨拶を兼ねた最初の笑いと本ネタへ の話題提供 表情ボケ 本ネタ 漫才の主軸となる部分であり,ニュー ス記事を読み上げてユーザに記事の 内容を説明しながら様々なボケとツッ コミで笑いを取る 言葉遊びボケ ノリツッコミ 過剰ボケ 対立ボケ 感情ボケ オチ 記事のまとめと最後の笑い 謎かけ あいちゃんでーす</cast>」はあいちゃんが「どもー、あいちゃんでーす」と発話する命令処理 である.<look name=”G”, what=”A”/>はゴン太があいちゃんの方に向かって視点移動する命令 処理である.視点移動には<look name=”G”, what=”audience”/>のように観客の方向に視点移動 する命令処理も存在する.<PEmo name=”G”>PE47/>はゴン太を47番の表情(この場合は悲し い表情)に変更する命令処理である.これらの命令を1つずつ順番に処理し,最後の</script> に到達すると漫才は終了となる.
4.2
つかみ
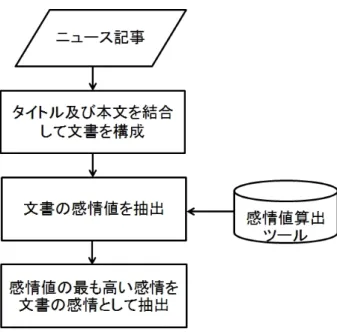
つかみでは,図5に示すように挨拶を兼ねた最初の笑いと本ネタへの話題提供を行う.挨拶は 自動生成時の月の行事に関する身近な話題を行う.次に,つかみでの最初の笑いとして表情ボ ケを行う.表情ボケとは,台詞に対して反対の印象を持つ目を表示する事によりボケる手法で ある.例えば,図5に表示するように楽しい台詞の時にわざと悲しい表情をする事である(図 4参照).また,本ネタへの話題提供は台本生成の題材となったニュース記事のタイトルを読み 上げて記事の詳しい内容に触れる対話の流れを作る.この時,ニュース記事のタイトルと共に ニュースの雰囲気情報を加味して表現する.ニュースには朗報や悲報に代表されるように,基本 的に出来事の嬉しい事柄や悲しい事柄について記述されている.そこで本論では,ニュースの 雰囲気を表現するのに感情が適していると考え,ニュースの文の感情を抽出して提示すること でュースの雰囲気を伝える.感情を抽出して提示することで,ニュースの概要をユーザが直感 的に把握することができるため,以降の本文の内容理解を容易にすることが可能と考えられる. 感情抽出手法 本論文でのニュース記事の感情の抽出手法の流れを図6と以下に示す. 1. ニュース記事のタイトル及び本文を結合して1つの文書を生成する. 2. 感情値算出ツールを用いて文書の感情値を算出する. 3. 値を調整した各感情値の絶対値を取り,最も値の高い感情をニュース記事の感情値とする. 本論文で用いる感情抽出には,熊本ら[23]の感情値算出ツールを用いて感情値を算出する.熊 本らの感情値算出ツールは,新聞記事データを対象に,定義している感情語群との共起から単図5:「ノーベル」をお題として自動生成する漫才台本(xml)のつかみ部分 語の感情値を数値化することで感情辞書を構築し,その感情辞書に基づいて感情値を算出する ものである.熊本らは新聞記事の感情を表現するのに適した感情軸として楽しい⇔悲しい,嬉 しい⇔怒り,のどか⇔緊迫の 3軸を設定している.本論文でもこれら3軸の感情を用いてニュー ス記事の感情を分類する.分類した感情を漫才台本中に台詞として挿入することでニュースの 雰囲気を伝える.同時に,ロボットの目の画像を対応する感情に合わせて切り替えることで,視 覚的にもユーザに情報を伝える.図5を例にすると,「<cast name=”A”>ほな地球ではこんな嬉 しいニュースあったん知ってるか?</cast>」の「嬉しい」の部分に抽出した感情の台詞を挿入 している.また,直前の<PEmo name=”A”>PE44/>で嬉しい表情に目の画像を切り替えている. つかみで提示したい感情は,ニュース内容全体の感情であるため感情を抽出する対象はニュー ス記事全体である.そこで本論文での感情抽出では,まずニュース記事のタイトル及び本文を 結合して文書を作成し,この文書の感情抽出を行う.感情値算出ツールによって,各3つの軸毎 にそれぞれ値を算出する.この値は0∼1の範囲で算出され,感情値が1に近い場合,各軸毎に 楽しい,嬉しい,のどかの感情を意味する.逆に単語の感情値が0に近い場合,各軸毎に悲し い,怒り,緊迫を意味する.最終的には最も感情値の高い感情を抽出したいが,感情値はニュー トラルがおよそ0.5となっており感情の比較が行いにくい.そこで式(1)を用いて感情値の値の
図6:ニュース記事の感情抽出の流れ 範囲を-1∼1に正規化し0をニュートラルとして,値の絶対値により比較を行い最も高い感情を 抽出する. Eji = 2(Eji− 0.5) (1) ここでEjiは文 jにおける感情軸i番目の感情値の感情値を示す. 表3に「ノーベル賞:日本人3氏が受賞 家族も見守る」のニュース記事に対して,記事のタ イトル及び本文を結合して生成した文書から感情値算出ツールを用いて算出した感情値の値と それに式(1)を適用した値を示す.表3より感情軸2の0.262122の感情値の絶対値が最も高く, このニュース記事全体の感情は嬉しいという感情が抽出できる.これにより,図5のような感 情の情報を付加した漫才台本を自動生成する. 表3:ニュース記事に対する感情値算出結果
算出値
感情軸 1
楽しい⇔悲しい
感情軸 2
嬉しい⇔怒り
感情軸 3
のどか⇔緊迫
感情値
0.559142
0.631061
0.467091
式 (1) 適用
0.118284
0.262122
-0.065818
4.3
本ネタ
本ネタでは,ニュース記事の内容を読み上げてユーザに説明しながら,同時に様々なボケと ツッコミを挿んで笑いを誘う.本ネタは漫才において最も主軸となる部分であり,漫才全体の 中で最も長く,ボケの回数も最も多く挿入される.ボケの挿入は,記事の構造をユーザが把握 できるように,文単位で行い,1文に付き最大で1ボケを挿入する.ただし,ニュース記事の 最初の1文は記事の概要が顕著に現れるためボケの挿入は行わない.また,ボケが作成されな い1文であっても,ツッコミは相槌を行うことで対話を生成する.本論文で自動生成するボケ図7:「ノーベル」をお題として自動生成する漫才台本の本ネタ部分 とツッコミの手法は,感情ボケ,言葉遊びボケ,ノリツッコミ,対立ボケ,過剰ボケの5種類で ある.「1つの漫才の中には,いろんな種類のボケが入っていた方がいい」[2]とのことから,本 文中にはこれらの種類のボケを可能な限り満遍なく自動生成する.図7にお題を「ノーベル賞」 とした時の漫才台本の本ネタ部分を示す. 4.3.1 言葉遊びボケ 言葉遊びボケとは,ボケ役がニュース記事本文の単語を別の単語と読み間違うというボケで ある.例えば図7では 「電力(でん-りょく)」という単語を「権力(けん-りょく)」という単語 と読み間違えるといったものである.この場合元の単語となる「電力(denryoku)」をローマ字 で処理し,そのローマ字の一部を置換することで別単語の「権力(kenryoku)」を抽出する.また 対話文におけるツッコミでは,その単語をタイトルとするWikipediaの記事を利用することで, 間違えた単語の説明を補足させる.補足情報としてWikipedia記事の最初の1文がそのタイトル の概要を顕著に表している[24]ことから,その最初の1文を用いる.例えば,「権力」の説明に は,「一般にある主体が相手に望まない行動を強制する能力」といった1文が抽出される.金水 [25]は漫才における笑いの発生は漫才の対話がGrice[26]の提案した言語表現の果たす機能であ る協調の原理からズレるために生じると述べている.言葉遊びボケでのツッコミの正しい単語 への訂正の補足情報としてWikipedia記事の文を用いることは,多くの場合訂正文としては余 分的印象を受ける.しかし,余分的な文は協調の原理の4つの公理の内の「量の公理」[26]に 反する内容であるため,ツッコミの訂正文を笑いが生じる1つの要因にできる利点があるので 漫才においては有用であると考えられる.
4.3.2 ノリツッコミ ノリツッコミとは,通常のツッコミと異なりツッコミ役が一度ボケの内容に同調し(のっか り)話題を展開した後に,改めて正しいツッコミを行うというものである.ノリツッコミでは, ツッコミ役が一時的にボケ役に転じることからツッコミでありながら同時にボケにもなるとい う特徴がある.本論文で提案するノリツッコミでは,ボケ役の言葉遊びボケに対して適用し,読 み間違えた別の単語の間違えにツッコミ役が同調し,その後ツッコミ役が自らその間違えを訂 正するといった流れで行う.単語に同調する要素には様々あるが,本論文ではその単語の印象を 用いる.ここで印象の抽出を簡略化するために,本論文では印象とはある単語を一つの形容詞 によって表現したものとする.ある単語とは先の言葉遊びボケにおいて,読み間違えた単語の ことである.先の例の場合「電力」という単語に対して読み間違えた「権力」という単語がこ れに当たる.即ち,ノリツッコミの生成時の印象の抽出とは読み間違えた単語に関連した形容 詞を抽出する.具体的には,印象を抽出する単語と共起する形容詞を検索結果のスニペットか ら抽出し,共起頻度の高い形容詞をその単語の印象とする.抽出された形容詞の例を表4に示 す.例えば,「権力」というキーワードに対しての印象は表4より,最も共起頻度の多い「強い」 という形容詞が権力の印象となる.結果的に「権力はホント強いなー」という対話を生成する. 表4:キーワードと共起する形容詞
キーワード
1st adjective
2nd adjective
3rd adjective
権力
強い
恐い
高い
豆腐
おいしい
美味しい
やわらかい
子猫
かわいい
可愛い
心地よい
漫才
面白い
うまい
熱い
パソコン
薄い
軽い
楽しい
4.3.3 対立ボケ 対立ボケとは,ある単語に関して対照的な関係にある語を対立語と定義し,その対立語に対 してボケる手法である(図7対立ボケ参照). 本論文で提案する対立語は,例えば「東京」に対して「大阪」,「野球」に対しては「サッカー」 のように2つの語同士が互いに対照的な関係性にある語のことを指す.2つの語の関係性に着 目すると「東京」と「大阪」は共に日本の都市,「野球」と「サッカー」は共に球技のように語 同士が共通の上位概念を持っていることがわかる.そこで本論文では共通の上位概念を持つ語 の中に対立語が含まれていると考え,これらを考慮した対立語抽出手法を提案する.以下,共 通の上位概念語を持つ語のことを同位語と呼ぶ.また,「野球」の同位語として「サッカー」と 「フットサル」が挙げられるが,「サッカー」と「フットサル」では競技人口に大きな差があり, 「野球」と同程度に認知されている「サッカー」の方が対立語として適切であると考えられる. これらを踏まえて本論文では対立語を,キーワードの同位語であり,且つ同程度の認知度を持 つ語と定義する.そこで,ニュース記事本文に含まれるある単語1つをキーワードとして,そ のキーワードの対立語を発見し抽出する手法を提案する.提案手法では,大きく以下の2つに 分けて対立語を発見する.(1)関連語に基づく同位語群の取得 同位語の取得にはWikipediaの階層構造をコーパスとして用い,キーワードの上位語を取得 する.例えば,東京の上位語の場合は「日本の都市」や「就航地」の他に「曲」や「作品」と いった11語の上位語が取得できる.得られた上位語を同じく上位語に持つ語をキーワードの同 位語として取得する.この時,取得できる同位語の数は非常に膨大な数になるため対立語の選 出が困難になる.そこで同位語郡にキーワードの関連度に関してのランキング付けを行う.関 連度の指標として,まず共通の上位語を多く持つ同位語の方がキーワードとの関連度が強いと 考えられる.また,どのような上位語で同位語となっているかも考慮する必要がある.例えば, 東京の上位語である「作品」は120257語の下位概念語を持ち,同様に東京の上位語である「日 本の都市」は24語の下位概念語を持つが,同じ上位語でも少数の概念だけに含まれる上位語の 方がより重要性が高いと考えられる.したがって,キーワードの上位語にそれぞれ重みの値を 与え,取得した同位語に共通上位語の数の対応した重みを全て加算することにより同位語の関 連度を求めてランキングを行う.上位語の重みSta(si)は,以下の式(2)で与える. Sta(si) = 1− logn N (2) ここで,siは上位語,nは上位語の下位概念語数,Nはコーパスの概念語総数を表す.今回用い たコーパスではNは2,931,465語である.結果的にキーワードと各同位語eiの関連度Rel(ei)は 以下の式(3)で求められる。 Rel(ei) = n
∑
i=0 Sta(si) (3) ここで,nはキーワードと同位語の共通上位語の総数を表す. (2) 同位語郡の認知度による対立語の決定キーワードと近い認知度を持つ同位語が対立語にな るとの考えから,語の認知度を語の検索結果数と見なし,Web検索の検索結果数と捉え,以下 の式(4)を用いてキーワードと同位語の検索結果数を比較する。Con(key, ei) = 1− log |Cog(key) −Cog(ei )| max(Cog(key),Cog(ei)) (4) ここで,Cog(key)はキーワードの検索結果数,Cog(ei)は同位語の検索結果数をそれぞれ表す. この時,Con(key, ei)の値が1に近いほどキーワードと同位語の認知度は近いことを表し,逆に, Con(key, ei)の値が0に近ければ認知度に格差があると言える. 最後に,キーワードに対する各同位語を式(3)で取得したRel(ei)の値と式 (4)で取得した Con(key, ei)の値の相乗平均によりランキングし,値が最も大きくなった語を対立語として取得 する.キーワードに関して提案システムにより抽出される対立語の例を表5に示す. 4.3.4 過剰ボケ 過剰ボケとは,ある値あるいは単位を実際よりも誇張して表現するボケである.文中に数値 が含まれるときその数値の桁を増加させてボケる.(図7過剰ボケ参照) 4.3.5 感情ボケ 感情ボケとは,図8に示すようにあるニュース記事本文の1文の感情に着目し,その文の感 情とは対照的な感情の文をボケとして挿入し,間違えるボケである.感情ボケは図1のおかし
表5:キーワードに関して取得した対立語
キーワード
対立語
東京
大阪
日本
中国
ストックホルム
モントリオール
野球
サッカー
チェス
オセロ
イチロー
松井秀喜
バラク・オバマ
ジョージ・ワシントン
紫式部
清少納言
マイクロソフト
東芝
エベレスト
阿里山
図8:ノーベル」をお題として自動生成する漫才台本の感情ボケ みの構造図の構造に着目してボケを生成する.おかしみが異なる概念の対比によって生まれる という安倍の考えに基づいて,感情ボケの対比関係にはユーザが直感的に把握しやすい感情を 情報として用いる.以下に感情ボケの生成手法を示す. 1. ニュース記事本文の各文毎に感情値算出ツールを用いて感情値を算出する. 2. 算出した全感情値の総和の内,感情値が最も高い文Aとその文の最も値の高い感情情報 Aeを抽出する. 3. 抽出した文A中の単語の内Aeの感情値が高い単語を取得し,その単語の対義語または反 義語をコーパス上から取得する. 4. 取得した対義語または反義語を文Aの取得した単語と入れ替えて新たな文Bを生成する. 感情ボケの生成では,ニュース記事本文の1文を対象に,その1文を改変することでボケを 実現する.最初に対象とする文を決定する必要がある.この時,感情ボケでは文の感情を用いるため対象となる文も感情が明確なものが望ましいと考えられる.そこで,ニュース記事の文 毎の感情値を算出し,最も感情値が高い値を持つ文を対象の文Aとする.ただし,ニュース記 事本文の最初の1文は一般的に,記事の概要を顕著に表す傾向があるので,ボケに用いると内 容理解の阻害に繋がることが危惧されるため除外する.感情値の算出には,4.2.1章で述べた感 情抽出と同様に熊本らの感情値算出ツールを用いる.そして式(1)を適用して文の感情値を算出 する.図8 (2)の例では,「青色発光ダイオードを開発し,物理学賞に選ばれた赤崎勇・名城大終 身教授、天野浩・名古屋大教授,中村修二・米カリフォルニア大サンタバーバラ校教授の3氏 が、メダルと証書を受け取った」が表3における感情軸2で高い値を持ち,これが文Aとなる. そして文Aの感情値から感情情報Aeとして「嬉しい」の感情を取得する.次に,文Aの感情情 報を逆転させて,文Bの生成を試みる.先の例の場合,Aeの嬉しいに対してその逆の感情情報 である怒りの感情を持つ文Bを生成する.文Bの生成は,熊本らの感情辞書からAeの感情値 を高く持つ単語を抽出し,その単語の対義語または反義語を発見し入れ替えることで感情の対 比を実現する.熊本らの感情辞書は,単語またはその組み合わせ毎に感情値が振られた辞書で あり,感情値算出ツールもこの辞書を基にして感情値を算出している.先の文Aの場合,感情 辞書より「証書を受け取った」の文に対して「証書」「受け取った」の単語の組み合わせが「嬉 しい」の感情において高い値を持つためこれらを抽出する.次に取得した単語の対義語または 反義語をコーパス上から発見する.「証書」の対義語または反義語はコーパス上からは見つから ないため,「受け取った」の反義語である「差し出した」を取得する.ここで「証書を差し出し た」という「怒り」の文が生成される.最後に,取得した対義語または反義語と文Aで取得し た単語を置換にすることで文Bを生成する.先の文Aに対しては,「青色発光ダイオードを開発 し,物理学賞に選ばれた赤崎勇・名城大終身教授、天野浩・名古屋大教授,中村修二・米カリ フォルニア大サンタバーバラ校教授の3氏が、メダルと証書を差し出した」が文Bとなる. 対話文の生成 安倍らはフリボケツッコミの概念を効果的におかしみを伝達する過程を段階的に把捉できるも のとしており,各々を以下のように定義している. • 「フリ」-ボケの先行部分でおかしみを効果的に伝達する表現. • 「ボケ」-おかしみの構造図を完成させる表現. • 「ツッコミ」-ボケの後続部分でおかしみを効果的に伝達する表現. そこで本論文では,この「フリ」「ボケ」「ツッコミ」の概念に着目することで,よりおもしろく わかりやすい対話文の生成が可能と考え,感情ボケにおいても,これらの概念を踏まえて対話 文を生成する.まず,本論文で提案する感情ボケにおいて「ボケ」は文Bとする.次に,「フリ」 に関しては「ボケ」の台詞の前に挿入する必要があり,役割としては「ボケ」となる文Bの対 比関係を強調できる文Aをユーザが想起できる文が望ましいと考えられる.そこで,「フリ」の 対話文には,文Aの持つ情報の内,容易に把握可能と考えられる感情に着目し,Aeを話題とし た対話文を生成する.図8の例では,「にしても、これは本当嬉しい話だよなー」が「フリ」の 対話文となり,嬉しい話という感情情報を用いることで文Aの想起を促す.最後の「ツッコミ」 においては,「ボケ」を強調する効果が期待されるため,文Aと文Bの相違点を指摘,訂正する 対話文を生成する.図8の例では,「おいおい!差し出したってどっちかっていうと悲しいわ! 証書を差し出したちゃうくて証書を受け取ったやろ!」が「ツッコミ」の対話文となる.挿入 改変した単語の訂正及び感情情報の付加により文Aと文Bの対比を強調している.以上の流れ
図9:漫才台本のオチ部分と謎かけ によりフリボケツッコミの概念に沿った感情ボケの対話文を生成する.この時,対話文の用い た感情に対応するロボットの目の切り替え命令も台本に合わせて加える.
4.4
オチ
オチでは,図9に示すようにまとめとして台本生成の題材となったニュース記事の内容を1 つのキーワードで簡潔に表現し,最後にそのキーワードをお題に自動生成した謎かけで笑いを とり締める. 謎かけ 謎かけとは,「X とかけてY と解く.その心は,どちらもZ(Z′)がつきものです」といった 形式で行われる一種の言葉遊びである.ここで,ZとZ′は互いに同音異義語の関係を持つ.謎 かけの自動生成にはX,Y,Z,Z′の4つの語を抽出する必要がある.以下に抽出手法を示す. 1. X を台本生成の題材となったニュース記事のタイトル中から任意の1語を抽出する. 2. X と共起する単語をXをクエリとした検索結果のスニペットから抽出し,共起頻度の高い 単語をZに設定する. 3. Zの同音異義語を小学生の国語辞典コーパス中から抽出しZ′を設定する. 4. Z′と共起する単語を検索結果のスニペットから抽出し,共起頻度の高い単語をY に設定 する. Xは謎かけにおいて主題となる部分である.漫才台本の自動生成においてもオチの役割である ニュースのまとめの意味合いを担うことを考慮して,X にはニュースの主題を設定することにより,謎かけを通してニュースの概要をユーザに印象付ける効果が期待される.そのためニュー スの主題が顕著に現れるニュース記事のタイトル中からXを設定する.図9の謎かけの例では 「ノーベル賞 日本人3氏が受賞、家族も見守る」というニュース記事のタイトルから「ノーベ ル賞」をXに設定する.次に,謎かけの定型句よりXとZが互いに連想関係にあることに着目 してZを取得する.取得手法としてはX と共起する単語を検索結果のスニペットから抽出し, 共起頻度の高い単語をXから連想される語としてZを抽出する.「ノーベル賞」の共起頻度の高 い単語には「受賞」,「物理」,「学賞」,「科学」等の語が抽出される.Zに最も共起頻度の高い単 語を設定した後,同音異義語を小学生の国語辞典コーパス中から抽出しZ′を設定する.ここで 小学生の国語辞典をコーパスとして用いているのはユーザへのわかりやすさを考慮したためで ある.同音異義語であるかどうかの判定は,Zをローマ字に変換して同じくローマ字の綴りが 一致する語を同音異義語とする.Zの同音異義語がコーパス中から発見できない場合は,共起 頻度が次いで高い単語からZを再設定する.先の抽出の場合「受賞(jusyou)」や「物理(buturi)」 は同音異義語がコーパス上から見つからない.「学賞(gakusyou)」に対しては「楽章(gakusyou)」 が抽出されるため結果的にZには「学賞」,Z′には「楽章」がそれぞれ設定される.最後に,Y とZ′がXとZの関係と同様に互いに連想関係にあることに着目してX からZを抽出した方法 と同様の方法でZ′からY を取得し設定する.「楽章」の共起頻度の高い単語には「交響」が抽出 されるのでYには「交響」を設定する.
5
例え表現
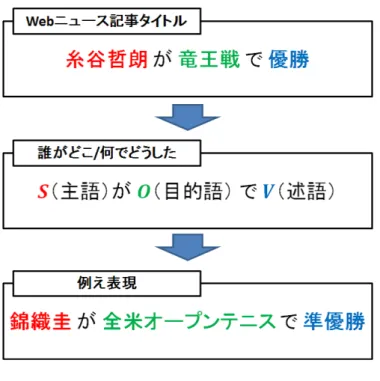
ここまで本論文で提案したボケやツッコミはロボット間の対話におかしみを加えることを目 的として行ってきた.しかしながら,先に述べたように本論文で提案する漫才ロボットには, ニュースをユーザに伝える役割を担っている.そのため,ユーザにとってわかりやすく,かつ ユーザの興味を惹く対話でニュースの伝える手法が必要であると考えた.本論文では,ニュー ス記事への根本的な興味喚起および理解支援の手法としてユーザ自身の興味を考慮した例え表 現に着目した.例え表現とは,広義には「ある物事を別の似ている物事で表現すること」であ る.本論文ではこの例え表現をWebニュース記事をもとに生成することを考える.例えば「羽 生善治が竜王戦で三冠」というタイトルのWebニュース記事を例にすると,テニスに関する知 識や興味のあるユーザには「錦織圭が全米オープンで準優勝」と例えて提示することで記事の 重要性がより直感的に理解できると考えられる.そこで本論文では,例え表現を行う対象とし てニュースのタイトルに着目し,例え表現を生成する手法を提案する.ニュースのタイトルを 対象にしたのは,ニュース記事の性質上タイトル中に重要な語が出現するといった点を考慮し たからである.例え表現を自動生成するに当たり,タイトルが「「羽生善治が竜王戦で三冠」と いったように「“誰/何 ’’が“どこ/何 ’’で“どうした ’’」の「S(主語)がO(目的語)にV(述 語)した」となっていることに着目する.先のテニスでの例え表現では,S(主語)の羽生善治 を錦織圭で表現し,同様にO(目的語)の竜王戦を全米オープンで表現している.この時,錦 織圭の部分および全米オープンの部分はユーザの興味のあるテニスに関連していることがわか る.また,同じテニスでも「錦織圭が“全米オープン ’’で準優勝」と例えるのと「錦織圭が“毎 日テニス選手権 ’’で準優勝」で例えるのとでは勝利の価値に開きが生じ,記事内容の理解を妨 げる恐れがある.この場合では,元の記事の竜王戦と大会の権威的価値がある程度近似してい る全米オープンで例える方が比較的相応しいと考えられる.そのため,例え表現を生成におい て例える対象であるものの価値が各々の分野においてある程度同等である必要があると考える.図10:例え表現生成イメージ 以上を踏まえて,本論文で提案する例え表現は,Webニュース記事のタイトルをもとに「ユー ザの興味」と「ものの価値」を考慮して行う.最終的には,生成した例え表現から対話を生成 し漫才台本に適用することを目的とする. 表6:例え表現に用いる語とその定義条件
例え表現語
定義条件
S
1ユーザの知識や興味のカテゴリに属する語
閲覧記事タイトルの S
0と価値が近似している語
O
1ユーザの知識や興味のカテゴリに属する語
閲覧記事タイトルの O
0と価値が近似している語
V
1S
1と O
1に対して文脈的繋がりを持つことができる語
閲覧記事タイトルの V
0と意味が類似している語
5.1
例え表現の定義
例え表現の自動生成のために例え表現をある程度形式的に捉える必要がある.先に述べたよ うに本論文では,Webニュースのタイトルが,「羽生善治が竜王戦で三冠」のように,「“誰/何 ’’ が“どこ/何 ’’で“どうした ’’」の「S(主語)がO(目的語)にV(述語)した」となっている ことに着目する.ここで,変換元となるユーザが閲覧中の記事タイトルの各「S(主語)」,「O (目的語)」,「V(述語)」に出現する単語をそれぞれS0,O0,V0とすると,「羽生善治が竜王戦で 三冠」はS0が「羽生善治」でO0が「竜王戦」,V0が「三冠」と表せる.さらに,例え表現中の 各「S(主語)」,「O(目的語)」,「V(述語)」をそれぞれをS1,O1,V1とすると,先の例をテニスで例えた場合の「錦織圭が全米オープンで準優勝」はS1が「錦織圭」であり,O1は「全米 オープン」となる.つまりは,「羽生善治→錦織圭」,「竜王戦→全米オープン」に変換されてい る.変換された単語同士は,各々単語の示す価値が類似しているこ必要がある.即ち,S0とS1, O0とO1の価値が類似している方が,元の記事の重要性がよりわかりやすいと考える.本論文 では,この単語の価値をものの価値とする.最後に,文の結論を示す役割にあたる述語のV0と V1は意味が類似している語が望ましいと考えられる.例えば,「錦織圭が全米オープンで敗退」 と例えた場合元の記事の示す内容を大きく損なうものとなる.例え表現生成のために必要な単 語S1,O1,V1の定義条件をまとめたものを表6に示す.以上より,本論文ではニュースのタイ トルを構成する単語S0,O0,V0に着目すると共に,例え表現に用いる単語S1,O1,V1をものの 価値と意味の類似を考慮して取得して,対応する語同士を置換することで例え表現を生成する.
5.2
価値の推定
本論文では,ものの価値を考慮し,例え表現を自動生成する.そこで,まずものの価値を推 定により定量化し,定量化した価値の値を比較することで価値が類似している語を発見し取得 する.ものの価値の定量化を行う場合,経済的側面での数値評価を利用することが考えられる が,ものの価値は対象によって様々な指標や視点により決まるため定量化は困難である.また, 本論文で提案する例え表現においては経済的側面での評価が行われないものも評価対象とする ため,経済的側面での価値の評価は行えない.そのため本論文では,ものの価値を判断する指 標として以下の2つの仮説を立てる. • 価値あるものには価値あるものが関わる. • 価値が時間的に持続しているものはより価値がある これらの2つの仮説を組み合わせてものの価値を定量化する. 価値あるものには価値あるものが関わる 例えば,権威ある賞の歴代受賞者には多くの著名人が受賞し名誉を得ている.同時に各著名人 達が受賞者として関わることで賞自体もその権威を高めていると考えられる.これは賞に限っ たものではなく,大会や人間関係等様々なものにおいても同様の関係が見られる.これらのこ とから,例え表現におけるものの価値を定量化するために汎用性の高い指標の一つとしてこの 仮説は有用であると考えた.この仮説に基づく指標の定量化としてPageRankアルゴリズム[27] を用いる.PageRankアルゴリズムはWebのハイパーリンク構造を用いてWebページを順位付 けするアルゴリズムであるが,PageRankアルゴリズムの根本的な考え方として,多くの良質な ページからリンクされているページはやはり良質なページであるという考えがある.この考え 方に基づき,「価値あるものには価値あるものが関わる」としてPageRankアルゴリズムを用い る.本論文では,価値を定量化する対象の語tiのWikipedia記事Wiとその記事間のリンク関係 を用いて以下の式(5)によりtiの価値PR(ti)を算出する. PR(ti) = (1− d) + d n∑
j=1 PR(Pj) C(Pj) (5) ここで,nは記事Wiへリンクしている記事の総数,C(Pj)が記事Wiと記事Pj以外の記事への リンクする記事の総数であり,PR(Pj)が記事Wiにリンクしているj番目の記事のページランク を表す.また,dはダンピングファクターで,通常用いられるようにここでは0.85を設定する.なお,記事データおよびそのリンク構造は日本のWikipedia情報ダウンロードページ5から11 月1日に取得したものを用いる.本論文では,PR(ti)の値が高い語tiほど,ものの価値が高い語 とみなす. 価値が時間的に持続しているものはより価値がある 流行や風化といった言葉が表すように,物事の価値は日々時間の影響を受けながら変化してい き一定ではないと考えられる.本論文での例え表現がニュースを対象としてた理解支援の目的 があることを考えると,流行や風化といった突発的に価値を有しているものよりも,継続的に 価値を有しているものをユーザに提示する方が望ましいと考えられる.そこで本論文では,時 間的な情報も加味して価値の評価を行うことを考える.具体的には,Wikipedia記事の閲覧回数 がその記事の社会的関心を表しているものと仮定して,価値を評価する対象の語tiのWikipedia 記事の閲覧回数を利用する.対象の記事の現在から過去5年間に及ぶ月毎の閲覧回数を取得し, その中央値を価値評価の評価指標とする.中央値の値が高い語ほど,価値が高い語と見なす.
5.3
ものの価値の決定
上記2つの仮説の元,単語tiの価値Val(ti)を以下の式(6)にて決定する . Val(ti) = PR(ti) + log T D(ti) (6) ここで,PR(ti)は,1つ目の仮説に基づいてWikipedia記事のリンク関係からPageRankアルゴ リズムにより取得する単語tiの関係性の価値を意味する.T D(ti)は,2つ目の仮説に基づいて, 月毎の閲覧回数により取得する単語tiの時間性を考慮した価値を意味する.最終的に式2によ り単語の価値を算出し定量化したものがその単語のものの価値とする.Val(ti)の値が高い語ti ほど,ものの価値が高い語とみなす.5.4
例え表現自動生成手順
本論文で提案する例え表現の生成の全体の流れを図11に示す.また,例え表現の生成の流れ の概要を以下に示す. 1. ユーザは自身の興味T を入力する.同時にシステムは閲覧中のWebニュース記事のタイ トルを取得する. 2. 取得したWebニュース記事タイトル中からS0,O0,V0をそれぞれ取得する. 3. 例え表現の主語S1を取得する. 4. 例え表現の目的語O1を取得する. 5. 例え表現の述語V1を取得する. 6. 取得したS1,O1,V1を用いて例え表現Pを生成しユーザに提示する. 5http://download.wikimedia.org/jawiki/latest/本論文で提案する例え表現生成では,ユーザの興味に合わせて例えるため,まずユーザの興味を キーワードにより入力する.入力として想定しているユーザの興味は,例えば「テニス」や「IT」 といったカテゴリを表すような1単語を想定しており,ここで入力したT を以降ユーザの興味 とする.次に,例え表現生成のために置換するべき語となるS0,O0,V0を閲覧中のWebニュー ス記事のタイトル中から係り受け解析を行い取得する.ここで,係り受け解析にはCaboCha6を 用いた.S0,O0,V0の取得を行った後,例え表現生成に必要となるS1,O1,V1を順に取得す る.最後に,取得したS1,O1,V1を用いて閲覧中のWebニュース記事のタイトルの例え表現 を生成する.以降,S1,O1,V1の取得手法について詳しく述べる. 表7:将棋棋士に属する語とその価値
将棋棋士 Val(t
i)
正規化 (Val(t
i))
大山康晴
0.00861
1.0
羽生善治
0.00703
0.81694
谷川浩司
0.00457
0.53141
中原誠
0.00359
0.41728
小菅剣之助
0.00331
0.38497
表8:日本のテニス選手に属する語とその価値日本のテニス選手 Val(t
i)
正規化 (Val(t
i))
杉山愛
0.00544
1.0
錦織圭
0.00436
0.80147
国枝慎吾
0.00214
0.39468
クルム伊達公子
0.00197
0.36369
原田夏希
0.00160
0.29455
例え表現の主語S1の取得 例え表現の主語S1の抽出手法とその流れを以下に示す. 1. S0の価値の算出 S0の価値を求めるために,S0の上位概念語をWikipediaコーパス上から取得し,その上位 概念語の下位概念語であるS0の兄弟語群S0iを取得する.そして,S0とS0iの価値を本論 文で提案する手法を用いて求める. 2. 例え表現の主語S1の候補群S1 jの取得 例え表現の主語S1の候補群S1 jをT の下位概念とみなし,Wikipediaコーパスを用いてT の全ての下位概念語を取得する. 3. 例え表現の主語の候補群S1 jの価値の算出 取得したS1 jのすべての価値を本論文で提案する手法を用いて求める. 6http://chasen.org/ taku/software/cabocha/4. 例え表現の主語S1の決定 この時,ユーザの興味によっては単純に求めた値を比較するだけでは,S0と価値が近似 しているS1自体が存在しない場合も考えられる.そこで本論文では,S0i(i = 1, . . . , n)と S1 j ( j = 1, . . . , m)のそれぞれで最小値が0,最大値を1として0-1の範囲で値を正規化す る.正規化した値同士を比較し,値の差が小さい語を例え表現の主語S1として一意に決 定する. 表7に羽生善治の上位概念語「将棋棋士」の兄弟語群S0i,表8に錦織圭の上位概念語「テニス 選手」の兄弟語群S1の提案手法により取得した価値の値および正規化した値の一部をそれぞれ 表記する.表7の「羽生善治」のVal(ti)を正規化した値0.81694に最も値が近似するS1 jの語 は表8より0.80147の「錦織圭」であり,この例ではS1として「錦織圭」を取得する. 例え表現の目的語O1の取得 O1の取得においてもO0と近似している価値の語を取得することが本論文で提案する例え表現 の生成には望ましいと考えられる.ただしO1を例え表現に用いる場合,すでに取得しているS1 との文脈的な繋がりを考慮して取得を行わなければ最終的な例え表現の意味が破綻してしまう 可能性がある.そこでO1の決定には,O1の候補語群O1lをS1との文脈的関係性を考慮してS1 の検索スニペットから取得する.その後,S1の決定方法と同様の手法で,O1lとO0の兄弟語群 O0kの価値の値によるランキングとその順位によりO1lを一意に決定する.次に例え表現の目的 語O1の抽出手法とその流れを以下に示す. 1. O0の価値の算出. O0の価値を求めるために,S0の価値を求めたのと同様の手法で,O0の兄弟語群O0kを取 得し,提案手法により価値を求め,同時に正規化を行う. 2. 例え表現の目的語O1の候補群O1lの取得. 取得したS1を用いて「S1が」をクエリとした検索を行う.検索結果上位100件のスニペッ トの中で出現頻度が閾値以上であり,Wikipediaに記事が存在する単語をO1の候補語群と して取得する. 3. 例え表現の目的語の候補群O1l の価値の算出. 取得したO1lのすべての価値を本論文で提案する手法を用いて求め,同時に正規化を行う. 4. 例え表現の主語O1の決定. O0とO1lの正規化した価値の値を比較し値の差が小さい語を例え表現の目的語O1とする. 先の「羽生善治が竜王戦で三冠」を例にすると,O0は「竜王戦」となる.そして竜王戦の上位 概念語「将棋のタイトル」に含まれる語に対して価値の算出および正規化を行う.次に,先の 抽出によりS1は「錦織圭」となってるため,「錦織圭が」で検索を行いO1の候補群O1lを取得 する.ここでのO1lには,「ATPツアー」,「全米オープン」,「全仏オープン」等が取得され,こ れらに対して価値の算出および正規化を行う.最後に,「竜王戦」のVal(ti)を正規化した値に最 も値が近似するO1 jの語として今回は「全米オープン」をO1とする. 例え表現の述語V1の取得 例え表現の述語V1の取得は,意味的類似性と文脈的つながりを考慮して行う.現段階では,文 脈的つながりを考慮することが結果的に意味的類似性がある程度類似すると仮定して取得を行 う.具体的には「“S1がO1で ’’」をクエリとして検索を行い,検索結果上位1000件のスニペッ
図12:実験に用いたニュース記事 トの中で「“S1がO1で ’’」に続く名詞あるいは動詞の内最も共起頻度の高い語をV1として取 得する.先の例の場合,S1が「錦織圭」,O1が「全米オープン」となっているため「“錦織圭が 全米オープンで ’’」をクエリとして検索を行い,最も共起頻度の高い単語として「準優勝」が 取得され,これをV1する. 以上によりS1が「錦織圭」,O1が「全米オープン」,V1が「準優勝」となり,これらを閲覧 ニュース記事タイトル中のS0,O0,V0と置換することで例え表現Pを生成する.結果的に,「羽 生善治が竜王戦で三冠」に対する例え表現Pは「錦織圭が全米オープンで準優勝」となる. 提案手法により例え表現を自動生成することができたが,生成した例え表現を漫才台本に対 話として取り入れる手法はまだ確立しておらず今後の課題となる.また,本論文で提案した例 え表現の生成手法にはユーザの興味T をユーザ自身が入力する必要があるが,本論文で提案す る漫才ロボットのシステムでは初めにニュース記事選出のためにお題となるキーワードを入力 していることから,例え表現の生成のために再度キーワードの入力を行うのはユーザにとって 負担が大きいと考えられる.将来的にはWeb閲覧などのログ情報からユーザの興味を推測して 抽出する手法を考案し,システムでのユーザの負担を軽減する必要があると考えられる.
![図 1: おかしみの構造図 一方で,漫才台本の生成において笑いによるおもしろさと情報提供メディアとしてのわかり やすさの向上は最重要事項と考えられる. おもしろさに関して,安倍 [3] はおかしみを笑いの現象を喚起する 1 つの要因と位置づけ,お かしみは異なる 2 つの概念の対比関係にによって生まれるという考えのもと図 1 (1) のようなお かしみの構造図を提唱している.本論文ではこのおかしみの構造図に着目し,安倍のおかしみ の構造図を漫才台本自動生成用に独自に対応させた図 1 (2) に示すようにおか](https://thumb-ap.123doks.com/thumbv2/123deta/8608819.938562/7.892.222.603.125.559/のわかりおもしろさおかしみによってかしみおかしみおかしみ.webp)
![図 3: 漫才ロボットあいちゃん(左)とゴン太(右) 図 4: 感情に合わせたロボットの表情 ため,モーターでの回転動作でツッコミの動作を表現する.目の表情は, 2 つの有機 EL ディス プレイに図 4 のような画像を移すことで表現する.画像の種類は 50 種類あり,台本に合わせた 様々な感情を表現することが可能である. 4 漫才台本自動生成 漫才台本自動生成にあたり,台本をある程度形式化する必要がある.本論文では灘本ら [22] が提案した漫才台本自動生成の枠組みを使用し,漫才台本をつかみ,本ネタ,オチ](https://thumb-ap.123doks.com/thumbv2/123deta/8608819.938562/11.892.224.651.123.408/ロボットあいちゃん合わせロボットモーターツッコミネタオチ.webp)


![図 7: 「ノーベル」をお題として自動生成する漫才台本の本ネタ部分 とツッコミの手法は,感情ボケ,言葉遊びボケ,ノリツッコミ,対立ボケ,過剰ボケの 5 種類で ある. 「 1 つの漫才の中には,いろんな種類のボケが入っていた方がいい」 [2] とのことから,本 文中にはこれらの種類のボケを可能な限り満遍なく自動生成する.図 7 にお題を「ノーベル賞」 とした時の漫才台本の本ネタ部分を示す. 4.3.1 言葉遊びボケ 言葉遊びボケとは,ボケ役がニュース記事本文の単語を別の単語と読み間違うというボケで ある.例](https://thumb-ap.123doks.com/thumbv2/123deta/8608819.938562/15.892.148.729.120.560/ノーベルお題としてボケノリツッコミはいろんなノーベルニュース.webp)