原 著
多施設共同臨床試験における極端なプロファイルを持つ施設
の検出と影響力診断の方法
Detection of outlying centers and influence diagnostics for
the analysis of multicenter clinical trials
中村理恵*1, *2,野間久史*3
Rie Nakamura*1, *2, Hisashi Noma*3
*1株式会社コーセー 研究所
*2総合研究大学院大学複合科学研究科統計科学専攻
*3統計数理研究所データ科学研究系
*1KOSÉ Corporation ResearchLaboratories
*2Department of Statistical Science, School of Multidisciplinary Sciences, The Graduate University of
Advanced Studies
*3Department of Data Science, The Institute of Statistical Mathematics e-mail : [email protected]
In multicenter clinical trials, the assessment for heterogeneity of various relevant factors across participating centers is a relevant issue because it can cause inconsistency of the treatment effects. Especially, outlying centers withextreme profiles can influence the overall conclusions of these trials. In this article, we propose quantitative methods to detect the outlying centers and to assess their influences in multicenter clinical trials. We proposed four effective methods based on (1) a studentized residual obtained by a leave-one-out analysis, (2) a model-based significance test to detect an outlying trial using a mean-shifted model, (3) a relative change measure for the variance estimate of the overall treatment effect estimator, and (4) a relative change measure for the heterogeneity variance estimate in a random-effects model. In addition, we provide parametric bootstrap algorithms to assess the statistical variability of their influential measures. We also demonstrate the practical effectiveness of these proposed methods via applications to two clinical trials for benign prostatic hyperplasia and cardiovascular heart disease.
Key words: multicenter clinical trial, heterogeneity, outlier detection, influence diagnostics, bootstrap.
1.はじめに
多くの臨床試験は,参加者のリクルートの効率性と試験の実施可能性を高めるため,複数の施 設による多施設共同試験として行われる.多施設共同臨床試験は,さまざまな条件の異なる複数 の施設において試験治療の評価を行うことができるため,結果の一般化可能性を高めることも期 待できる(ICH E9 Expert Working Group, 1999).しかしながら,これらの試験では,参加する施 設ごとに,患者の背景・特徴や,治療の方法,スタッフの訓練レベル,データの測定・記録方法 など,さまざまな要因が異なることがあり,それらが,施設間での参加者のアウトカムの異質性 を生じさせることが知られている(Agresti and Hartzel, 2000;Biau, Porcher and Boutron, 2008; Kahan and Harhay, 2015;Kahan and Morris, 2013;Localio et al., 2001;Munda and Legrand, 2014).
施設間の異質性が大きな試験では,その施設間差を適切に考慮した統計解析を行うことで,施 設内での治療の割り付けの不均衡の調整や検出力の向上などの利点があることが知られており, 変量効果モデルなどを用いた解析方法が用いられる(Kahan, 2014;Kahan and Harhay, 2015; Kahan and Morris, 2013;Kahan and Morris, 2012a, b).一方で,このように異質性が大きな事例 では,これらの統計モデルで適切にモデル化することができる範囲を超えて,極端なプロファイ ルを持つ施設が存在する可能性もある.これは,古典的な回帰分析における「外れ値(outlier)」 の問題(Belsley, Kuhand Welsch, 1980)に対応することになるが,これらの極端なプロファイル を持つ施設は,試験全体での統計解析の結果に強い影響を及ぼす可能性がある.そのバイアスや 誤った結論を避けるため,統計的な誤差を適切に考慮した,外れ値となる施設を同定することと その影響力解析は,治療効果の評価を行う上で重要な問題となる.しかしながら,多施設共同試 験を対象としたこれらの方法論は,フォーマルには Canner, Huang and Meinert(1981a, b)など による試験ごとの要約統計量をプロットしたグラフによる視覚的な評価や,全集団の結果から各 施設の乖離度を評価する程度の単純な方法しか議論されていない.これらの方法は,解析者の主 観によって,結果が左右される可能性もあるため,実践上,従来の影響力解析のような定量的な 統計的評価方法の枠組みも必要となる. 本研究では,これらの枠組みのもとで,統計的な誤差を適切に考慮した,多施設共同試験にお ける極端なプロファイルを持つ施設の検出と影響力解析の方法を提案する.まず,第 1 の方法と して,回帰分析で用いられる dfbeta に類似した影響力診断の指標として,施設を単位とした leave-one-out(LOO)解析によって得られるスチューデント化残差を用いる方法を提案する.第 2 の方法として,特定の施設における治療効果の指標(平均値の差,リスク比,ハザード比など) が全集団から異なることをモデル化した平均シフトモデル(mean-shifted model)を用いた,モデ ルに基づく有意性検定を提案する.加えて,変量効果モデルに基づく 2 つの影響力診断の指標を 提 案 す る.変 量 効 果 モ デ ル に は,施 設 ご と の 治 療 効 果 の 指 標 の 推 定 量 を モ デ ル 化 し た DerSimonian-Laird 式の変量効果モデル(DerSimonian and Laird, 1986)を用いる.このモデルの 枠組みのもとで,第 3,第 4 の方法として,LOO 解析によって,個々の施設が,(1)治療効果の 指標の推定量の分散と,(2)変量効果の分布の分散の推定量に,それぞれどの程度の影響を与え るのかを定量的に評価する影響力統計量を提案する.いずれの方法も,ブートストラップ法を用 いて,統計的な誤差を定量的に評価し,個々の施設がどの程度の極端なプロファイルとなってい
るのかを評価する方法を与える.これらの手法は,近年,メタアナリシスの領域で開発され,ス タンダードな方法として普及している外れ値の検出と影響力解析の方法(Gumedze and Jackson, 2011;Hedges and Olkins, 1985;Matsushima et al., 2020;Negeri and Beyene, 2019;Noma et al., 2020;Viechtbauer and Cheung, 2010)をもとにしており,多施設共同試験にこれを用いる動機 は,施設ごとの影響力を,施設単位の要約統計量によって定量的に評価することができるという 点にある.多施設共同試験の統計解析では,個人レベルのデータをモデル化した解析を行うこと が一般的であるが,施設を単位とした影響力の評価においては,施設ごとに情報を要約した指標 により定量的に評価を行うことができたほうが,非統計家にもその解釈は明確になる.近年のメ タアナリシスの方法論の進展によって,このクラスタごとの要約統計量を単位とした解析と,個 人レベルのデータを単位とした解析から得られる推定量は,実質的に同等の漸近分布を持つこと が理論的に示されたため(Chen et al., 2020;Lin and Zeng, 2010;Zeng and Lin, 2015),多施設共同 試験の統計解析に,この枠組みを適用することが正当化される.本研究では,また,前立腺肥大 症(Gormley et al., 1992;Gould, 1998)と冠動脈心疾患(Aitkin, 1999;Yusuf et al., 1985)の 2 つの 多施設共同試験の事例解析を通して,提案する方法の有用性を示す.
2.方 法
2. 1 モデルと記法
本論文では,前述の通り,施設ごとの治療効果の指標の要約統計量(平均値の差,リスク比, ハザード比など)を単位とした解析方法を議論する.(Chen et al., 2020;Lin and Zeng, 2010; Zeng and Lin, 2015).
まず,i 番目の施設のサブグループ解析から得られた要約統計量を yii=1,⋯, とする.この 要約統計量を用いた解析方法として,最も単純な方法が,「対象となった k 施設における治療効果 の大きさは共通である」という仮定に基づく固定効果モデル(fixed-effect model)である.この 共通の治療効果の指標を θ と表記することにすると,大標本近似による yi のモデルは, y~N (θ,σ), と表される.σ は施設ごとの要約統計量の分散を表す.通常は,適当な推定値を Plug-in した近 似モデルを用いる.以降の議論では,σは所与のものであるとした統計モデルを用いる.このモ デルのもとでは,共通効果の指標 θ の漸近有効な一致推定量は,逆分散重み付き平均推定量 (Higgins and Thomas, 2019)などによって与えられる.しかしながら,このモデルは,施設間の 異質性を適切にモデル化したものにはなっていないため,共通効果の仮定が誤っている場合には, θ の推測の結果は,共通効果の推定値,信頼区間などとして解釈することはできない.
施設間の異質性を考慮したモデルとして,広く用いられているのが,一般化線形混合効果モデ ルや Frailty モデルなどの変量効果モデルである(Agresti and Hartzel, 2000;Biau et al., 2008; Kahan and Harhay, 2015;Kahan and Morris, 2013;Localio et al., 2001;Munda and Legrand, 2014). これらのモデルについても,施設ごとの要約統計量に対しての統合解析を行うことで,同等の推 測を行うことができる.以下の DerSimonian-Laird 式のモデル(DerSimonian and Laird, 1986)
が,最も広く用いられるモデルである.
y~N θ,σ, (1)
θ~N (μ,τ),
μ は対象となった k 施設における平均的な治療効果を表す指標であり,τは施設間の異質性を表
す分散である.μ, τは,モーメント法,最尤法,制限付き最尤法(restricted maximum likelihood
[REML]estimation)などの方法によって推定することができる(Higgins and Thomas, 2019). 本論文では,一貫して REML 法を用いた議論を行うが,他の推定方法を用いた場合にも,以降の 議論は同様に適用することができる.また,前者の固定効果モデルは,変量効果モデル(1)の施 設間分散 τが 0 である特殊なケースに相当することから,以降の 2.2, 2.3 節では,主として変量 効果モデルをもとにして説明を行う.τ=0 という制約をつければ,固定効果モデルでの議論に 一致する. 2. 2 スチューデント化残差を用いた影響力診断 施設ごとの影響力診断の方法として,まず,従来の回帰分析でも広く用いられているスチュー デント化残差に基づく方法を提案する.変量効果モデル(1)における i 番目の施設のスチューデ ント化残差は,以下のように定義される. r= y−μ
Var
y−μ
, Var
y−μ
=w−
w
w=
τ+σ
μ, τは,変量効果モデル(1)における μ, τの REML 推定量を表す.スチューデント化残差 r は,i 番目の施設における治療効果の指標の推定値 yと,全集団における推定値 μ の間の残差を, その標準誤差によって標準化することによって定義される.従来の回帰分析と同様,形式的には, 単純に,このスチューデント化残差によって,個々の施設の影響力を評価することができる. しかしながら,このスチューデント化残差 rは,残差を定義する際に,当該施設の治療効果の 推定値 y を含めた全集団の推定値 μ からの乖離度を評価するものとなっており,仮に,yが極 端なプロファイルを持つ外れ値であった場合には,その影響を受けた μ からの残差を影響力診断 に用いることとなってしまう.そこで,影響力診断の対象となる i 番目の施設のデータを除いた 集団に対して,変量効果モデル(1)の LOO 解析によって得られる治療効果の推定量 μ, τ を用いた標準化残差によって,影響力診断を行うことを考える.すなわち,影響力診断の指標と して,以下の外的スチューデント化残差を用いる. t= y−μ
Var
y−μ
,Var
y−μ
=
w
+
w
w=
τ+σ
(j=1,2,…,). この標準化残差は,i 番目の施設を除いた集団における治療効果の予測値 μからの y の乖離 度を測ったものと解釈することができ,前述の単純なスチューデント化残差とは異なり,その乖 離度の評価に対しての “optimism” を排除することができている. 施設ごとの影響力の大きさを評価するためには,tの大きさそのものを定量的に評価すればよ い.0 に近い値をとるほどその影響力は小さく,絶対値が大きくなるほどその影響力は大きい. 参照的な閾値としては,標準正規分布の閾値を用いればよく,例えば,上側と下側の 2.5 % クォン タイル ±1.96 を用いれば,それを超える施設は,参照分布における 95 % のランダムな誤差の範 囲を超える極端なプロファイルを持つものと考えることができる.以上の方法は,単変量メタア ナリシスの枠組みにおいて,Viechtbauer and Cheung(2010)も議論している.一方,この正規 近似に基づく閾値は,十分にサンプルサイズが大きいことを前提とした大標本近似に基づくもの となるため,そうでない場合には,統計的な誤差を評価する上で,不適切な参照値となり得る. そこで,本研究では,パラメトリックブートストラップ法を用いて,tの標本分布の推定を行う ことを提案する.tのブートストラップ分布とそのパーセンタイルの推定は,以下のアルゴリズ ムによって行うことができる. アルゴリズム 1(外的スチューデント化残差 tiの標本分布の推定) 1. 変量効果モデル(1)において,LOO 解析によって得られる REML 推定値 μ, τを計 算する. 2. 変量効果モデル(1)における母数 μ, τに μ, τを plug-in した分布から,B 回のパラ メトリックブートトラップを行い,y, y,…,y(b=1,2,…,B) をリサンプリングする. 3. ブ ー ト ス ト ラ ッ プ サ ン プ ル y, y,…,yか ら,外 的 ス チ ュ ー デ ン ト 化 残 差 t (i=1,2,…,;b=1,2,…,B)を計算する. 4. t,t,…,tの経験分布が,tの標本分布のブートストラップ推定値となる.適切なクォ ンタイルを閾値に設定する. 前述の閾値と同じ基準を用いるのであれば,このブートストラップ分布の上側と下側の 2.5 % クォンタイルを,外れ値を検出するための閾値として設定すればよい.以上の方法は,変量効果 モデル(1)における異質性分散を,τ= 0 と制約づければ,共通効果の仮定を置いた固定効果モ デルでの解析にそのまま適用することができる. 2. 3 平均シフトモデルに基づく有意性検定 ネットワークメタアナリシスなどにおける影響力診断においては,Noma et al.(2020),Negeri and Beyene(2020)が,平均シフトモデルに基づく有意性検定による評価方法を提案している.本研究では,この方法を多施設共同試験の影響力解析に応用することを提案する.2.1 節に示し た変量効果モデル(1)は,すべての施設の要約統計量 yがそれぞれ共通のモデル(1)に従って いると仮定しているが,この方法では,その平均パラメータとなる μ が ζ(≠0)だけシフトした 試験が混在していると仮定した平均シフトモデルを設定する.すなわち,j 番目の施設の平均パ ラメータがシフトした平均シフトモデルとは,以下のモデルとなる. θ~N (μ+ζ,τ), 一方,この施設以外の残りの −1 施設では,平均パラメータがシフトしていない変量効果モデ ル(1)を仮定する. θ~N (μ,τ) (i≠j). j 番目の施設が,それ以外の施設との間に系統的な差がないかどうかは,平均シフトモデルのパ ラメータ ζ についての有意性検定によって評価することができる.すなわち,以下の仮説に対し ての検定問題を考える. 帰無仮説 H: ζ=0 vs. 対立仮説 H: ζ≠0 この検定により,帰無仮説 Hが棄却された場合,j 番目の施設は,全集団から乖離したプロファ イルを持つ可能性があり,影響力の大きな外れ値の候補となると考えられる. 有意性検定は,尤度比検定によって構成することができる.帰無仮説のもとでの対数尤度関数 は,変量効果モデル(1)から,以下のように書くことができる. lμ,τ=−12
log 2π(σ+τ)+y−μ σ+τ
. 一方,対立仮説のもとでの対数尤度関数は,以下のように書くことができる. lμ,τ,ζ=−12
log 2π(σ+τ)+y−μ−ζ σ+τ
− 1 2
log 2π(σ +τ)+y−μ σ+τ
. これらの対数尤度関数により,前述の検定の尤度比統計量は,次式のように与えられる. T=−2
l
μ,τ
−l
μ,τ,ζ
, μ, τは,帰無仮説のもとでの l μ,τ についての最尤推定値,μ,τ,ζは対立仮説のもとでの lμ,τ,ζ についての最尤推定値であり,それぞれ上記の対数尤度関数を最大化することによっ て得られる.帰無仮説のもとで,この尤度比統計量 Tは,自由度 1 の χ分布に従うこととな るので,これによって P 値を計算すればよい.有意水準両側 5 % の検定を行うのであれば,その 上側 5 % 点が閾値となる.また,対象となる施設の分散 σは,アウトカム指標の種類によって は,帰無仮説・対立仮説下で異なることもあり得るが,ここでは,双方において,単純な不偏/ 最尤推定量をその推定量に用いることを提案する.最終的な推測に与える影響については,3 節 のシミュレーション実験において評価をしているが,概ね軽微なものであると考えられる.なお, 単変量メタアナリシスにおいては,Viechtbauer and Cheung(2010)などの既存研究でも,この方法はこれまでに議論されていない.
しかしながら,このカイ二乗分布は,サンプルサイズが十分に大きいもとでの近似的な分布で あり,相対的にサンプルサイズが小さい事例では,その近似が不正確になることが知られている (Noma, 2011;Noma et al., 2018).このような条件下では,ブートストラップ法を用いることで,
より近似精度の高い参照分布を推定することができる(Noma et al., 2018).本研究では,以下の パラメトリックブートストラップ法を用いた検定方法を,1 つの方法として提案することとする. アルゴリズム 2(尤度比統計量の標本分布の推定) 1. 変量効果モデル(1)のもとでの全集団における REML 推定値 μ, τを計算する. 2. 変量効果モデル(1)における母数 μ, τに μ, τを plug-in した分布から,B 回のパラメト リックブートトラップを行い,y, y,…,y(b=1,2,…,B) をリサンプリングする. 3. ブートストラップサンプル y, y,…,yから,帰無仮説,対立仮説のモデルのもとでの最 尤推定値 μ ,τおよび μ ,τ,ζを計算する.これによって尤度比統計量 T=−2
l
μ ,τ
−l
μ,τ,ζ
. (b=1,2,…,B)を計算する. 4. T,T,…,Tの経験的分布が,尤度比統計量 Tの帰無仮説のもとでの標本分布のブー トストラップ推定値となる.この分布を用いて P 値を計算することができる. また,この方法も,前節と同様,τ=0 とすることで,固定効果モデルにもそのまま適用すること が可能である.このアルゴリズムは,多変量メタアナリシスのモデルに対して,Noma et al. (2020),Negeri and Beyene(2020)においても同様のものが提案されている.2. 4 平均パラメータの推定量の分散の推定値に基づく影響力診断
ここまでは,平均パラメータの乖離に基づく影響力診断の方法について議論してきたが,影響 力の大きな外れ値がある場合には,平均パラメータの推定量の分散の推定値も大きく変動するこ とがあり,それに基づく影響力診断も,実践的に有用なものとなる.DerSimonian-Laird 式のモ デルに対しては,Viechtbauer and Cheung(2010)が提案した,以下の分散比の統計量をそのま ま用いることができる. VRATIO=Var [μ ] Var [μ] = w w , 分母は,全集団において推定される平均パラメータの推定量 μ の分散の推定値であり,分子は, j 番目の施設を除いたデータセットに対しての LOO 解析から推定される平均パラメータの推定 量 μ の分散の推定値である.すなわち,VRATIOは j 番目の施設が,治療効果の推定における 推定精度に,どの程度影響を及ぼすかを定量的に評価するための指標であるといえる. VRATIOの実現値が 1 に近い場合には,j 番目の施設が除外されることによる分散の変化がほと
んどないことを意味する.すなわち,j 番目の施設が,治療効果の推定における推定精度に与え る影響は小さいことが示唆される.また,VRATIOが 1 よりも大きくなる場合には,j 番目の施 設を除外することによって,推定量の分散が大きくなることを意味する.すなわち,j 番目の施 設を加えることで,治療効果の推定精度が向上することとなり,また,j 番目の施設を除くこと で,それ以外の施設の間での異質性は大きくなることが示唆される.この場合,j 番目の施設は, 全集団の中で,外れたプロファイルを持つ施設とは解釈されない.一方,VRATIOが 1 よりも 小さくなる場合には,j 番目の施設を除外することによって,推定量の分散が小さくなることを 意味する.すなわち,j 番目の施設を除外することで,サンプルサイズが小さくなるのに,治療効 果の推定精度が向上することとなり,また,j 番目の施設を除くことで,それ以外の施設の間での 異質性は小さくなることが示唆される.この場合,j 番目の施設は,推定量の精度や施設間の異 質性に影響を与える,全集団の中での外れたプロファイルを持つ施設と解釈されることになる. 具体的に,どの程度の影響を与えるものであるかは,VRATIOの大きさそのものを定量的に評 価すればよい.
外れ値であるかどうかを判定するための閾値を設定するためには,Viechtbauer and Cheung (2010)では議論されていないが,本論文において,2.2 節で与えたアルゴリズム 1 を用いて, VRATIOの標本分布をブートストラップ法によって推定するという方法が考えられる.すなわ ち,アルゴリズム 1 における tを VRATIOに置き換えれば,VRATIOの標本分布の推定値を 得るためのアルゴリズムとすることができる.閾値の設定は任意であるが,例えば,2.1 節と同等 の 95 % の誤差の範囲をひとつの基準にするのであれば,このブートストラップ分布の下側 5 % 点を閾値に用いればよい.なお,このブートストラップ法を用いた評価方法は,多変量メタアナ リシスのモデルに対して,Noma et al.(2020),Negeri and Beyene(2020)において同様のものが 提案されている. また,この方法では,固定効果モデルを解析に用いる場合には,VRATIOは,単純に,個々の 施設の情報量(概ね,サンプルサイズに比例する)を反映した指標となるため,外れ値の検出や 影響力の評価尺度としては適切ではない.したがって,変量効果モデルに対してのみ,有用な方 法であるといえるだろう. 2. 5 異質性分散の推定値に基づく影響力診断 前節の VRATIOと同様,変量効果モデル(1)のもとでは,影響力の大きな外れ値となる施設 がある場合,施設間の異質性分散 τの推定値も大きく変動することがある.したがって,この異 質性分散の推定値に対して,VRATIOと同様の影響力診断の指標を考えることもできる
(Viechtbauer and Cheung, 2010).同じく,j 番目の施設を除いたデータセットに対しての LOO 解析による分散比の統計量として, TRATIO=τ τ を用いることが考えられる.分母は,全集団において推定される異質性分散の推定値であり,分 子は,j 番目の施設を除いたデータセットに対しての LOO 解析から推定される異質性分散の推定
値である. TRATIOの解釈は,VRATIOと概ね同様である.1 付近に値をとった場合には,異質性分散 の推定値に j 番目の施設はそれほど影響力を持たず,1 より大きな値をとった場合にも,その施 設が加えられることによって,施設間の異質性は小さくなると見なすことができる.また, TRATIOが 1 よりも小さな値をとった場合には,j 番目の施設を除外することで,施設間の異質 性が小さくなり,全集団の中で極端なプロファイルをもつ外れ値と見なすことができる. 外れ値の閾値の設定には,前節と同様,パラメトリックブートストラップ法を用いて, TRATIOの標本分布の推定値を用いればよい.この方法は,Viechtbauer and Cheung(2010)
などの既存研究では議論されていないが,多変量メタアナリシスのモデルに対して,Noma et al.
(2020),Negeri and Beyene(2020)において同様のものが提案されている.アルゴリズム 1 の t
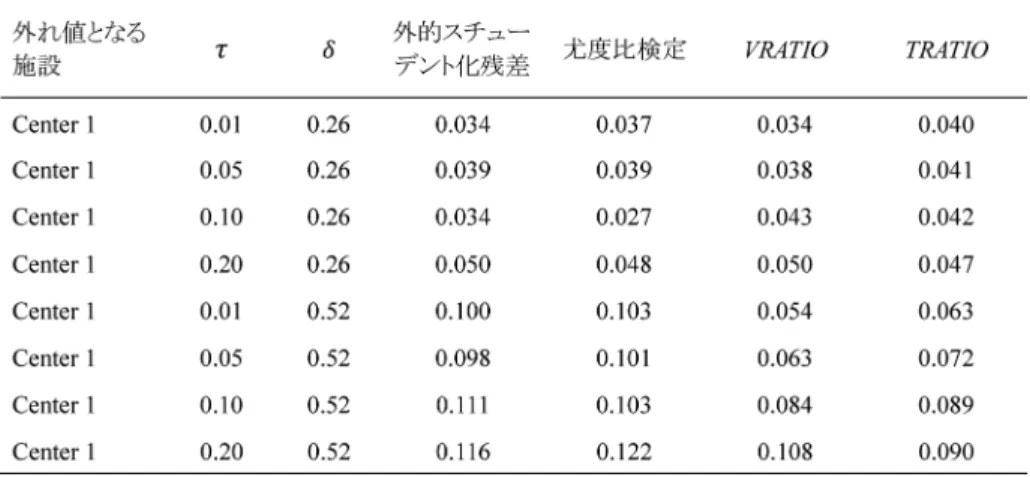
を TRATIOに置き換えれば,TRATIOの標本分布の推定値を得ることができる.前節と同様 の基準で閾値を設定するのであれば,このブートストラップ分布の下側 5 % 点を閾値にすればよ い.なお,TRATIOは,変量効果モデルのもとでのみ定義することができ,固定効果モデルによ る解析には用いることができない. 3.シミュレーション実験 提案した方法の性能を評価するために,シミュレーション実験を行った.4 節の冠動脈心疾患 の臨床試験(Aitkin, 1999;Yusuf et al., 1985)をモデルとして,22 の施設による多施設臨床試験の データを生成した.それぞれの施設におけるサンプルサイズは,同試験と同数に設定した.プラ セボ群のイベント発生率は,同試験における 22 施設のプラセボ群のイベント発生率の範囲をも とに,一様分布 U(0.022, 0.211)から発生させた.施設ごとの対数リスク比 θは,変量効果とし て,θ~N (μ,τ) から生成させるものとした.施設間の異質性については,τ=0.01, 0.05, 0.10, 0.20 の 4 通りの設定を考慮した.外れ値となる施設は,4.2 節の解析の結果から,影響力の強い施設の 候補となった施設 14, 7 の 2 施設と,最も小規模な施設 1 とした.施設 1 の設定は,少数例の施設 が極端なプロファイルを持つときに,提案する方法で,どの程度の正確性でこれを検出すること ができるかを評価するためのものである.それぞれ対数リスク比の真値を δ シフトさせ,θ+δ とした.施設 14 を外れ値にする場合には,δ=0.00, 0.50, 0.70,施設 7 を外れ値にする場合には, δ=0.00, −0.22, −0.44 のそれぞれ 3 通りのシナリオを検討した.δ=0.00 のシナリオは,対象と なった施設が外れ値でない設定となるが,この条件下で,提案する方法での検出率がどの程度に なるかを評価することを目的としている.施設 1 を外れ値にする設定では,δ=0.26, 0.52 の 2 シ ナリオを検討した.それぞれのシナリオにおいて,1000 回のモンテカルロ実験を行った.ブート ストラップ法によるリサンプリングの回数は,一貫して 1000 回とした. 4 つの提案法による,外れ値となる施設の検出率を表 1, 2 に示した.δ=0.00 のシナリオでは, いずれの方法も,概ね検出率は 5 % 程度になった.δ≠0.00 のシナリオでは,全般的な傾向として, 異質性が大きいほど,いずれの方法も,検出率は低くなり,外れ値となる施設の効果サイズが大 きいほど,検出率は高くなる傾向が見て取れた.外的スチューデント化残差による方法と,平均 シフトモデルによる尤度比検定では,検出率は概ね同等であり,シナリオによって,それらの優
劣関係はわずかながら異なることがわかった.同様に,VRATIO と TRATIO による方法の検出 率も,概ね同等であり,シナリオによって,わずかではあるが,優劣関係は変動するという結果 になった.4 つの方法を比較した全般的な傾向としては,外的スチューデント化残差による方法 と尤度比検定が,VRATIO と TRATIO による方法と比べて,高い検出率を示す傾向があった. しかしながら,一部のシナリオでは,VRATIO による方法が,前者の方法よりも高い検出率を示 していた.一方,小規模な施設 1 を外れ値に設定した場合には,検出率は大幅に低下した.これ 表 1. シミュレーション実験の結果:外れ値の候補となる施設の検出率(施設 14, 7 が外れ値であ る設定)
らの小規模な施設は,全集団における治療効果の統計的推測に与える影響も小さく,影響力解析 の手法では検出されにくいと考えられる.
4.事例解析
本節では,2 つの多施設共同臨床試験の事例解析を通して,提案する 4 つの方法の有用性につ いて示す.
4. 1 前立腺肥大症の臨床試験(Gormley et al., 1992;Gould, 1998)
図 1 は,前立腺肥大症の治療薬であるリナステリドの有効性と忍容性を評価することを目的と して,アメリカとカナダの計 30 の施設で実施された多施設共同臨床試験(Gormley et al., 1992; Gould, 1998)の結果をフォレストプロットで示したものである.参加者は,尿路閉塞の症状を伴 う 895 人の男性であり,プラセボ,リナステリド 1 mg,リナステリド 5 mg のいずれかを無作為 に割り付けられている.主要アウトカムは,泌尿器症状の評価尺度である Boyarsky スコアの ベースライン時点からの変化量であった.ここでは,特に,リナステリド 1 mg 群とプラセボ群 の比較について考える.図 1 には,それぞれの施設における Boyarsky スコアの変化量の平均値 の差と 95 % 信頼区間を示している.固定効果モデルを用いた解析においては,平均値の差が -0.36(95 % 信頼区間:− 1.10〜0.38)となり,有意な差は認められなかった.また,変量効果モ デルを用いた解析においても,平均治療効果 μ の推定値は-0.63(95 % 信頼区間:− 1.66〜0.40) であり,有意差は認められなかった.一方,施設間の異質性分散の推定値は,τ=3.23(p<0.01; Q 検定)であった. 表 3 に,この試験における施設ごとの外的スチューデント化残差を示す.絶対値の大きな上位 10 施設の結果を示している.固定効果モデル,変量効果モデルの両方において施設 5 の外的ス チューデント化残差 tは,ブートストラップ分布の下側 2.5 % 点を下回っていた.固定効果モデ ルにおいては,さらに 4 つの施設がブートストラップ分布の上側もしくは下側 2.5 % 点を超える 表 2. シミュレーション実験の結果:外れ値の候補となる施設の検出率(小規模な施設 1 が外れ 値である設定)
結果となった.次に,表 4 に,平均シフトモデルによる尤度比検定の結果を示す.ブートストラ プ法による P 値が小さな順に,10 施設の結果を示している.外的スチューデント化残差を用い た解析と同様に,施設 5 は固定効果モデル,変量効果モデルの両方において有意となり,また固 定効果モデルにおいては,さらに 4 つの施設が有意となった.加えて,表 5 に,VRATIO, TRATIOによる影響力解析の結果を示す.いずれの指標においても,施設 5 が,ブートストラッ プ分布の下側 5 % 点を下回るという結果になった.施設 5 を除くことで,10 % の精度の減少,ま た,26 % の異質性分散の減少が認められた.総合的に判断して,施設 5 は,極端なプロファイル を持つ影響力の大きな施設であることが示唆される.個々の施設の詳細についての情報は,今回 図 1. 前立腺肥大症の臨床試験(Gormley et al., 1992;Gould, 1998)における施設ごとの平均値の差につい
表 3. 前立腺肥大症の臨床試験における外的スチューデント化残差
は,事後的に得ることができなかったが,実践においては,このように検出された施設の詳細な 評価を行い,もしもなんらかの影響力を与え得る要因があるのであれば,試験全体の結果の解釈 や考察に生かすことができるであろう.なお,ブートストラップにおけるリサンプリングの回数 は,一貫して 2400 回とした. 最後に,施設 5 を除いた感度解析を実施した結果,平均値の差の推定値は,固定効果モデルで -0.23(95 % 信頼区間:− 0.98〜0.51),変量効果モデルで-0.42(95 % 信頼区間:− 1.39〜0.55)と なった.異質性分散の推定値は τ=2.32(P=0.03;Q 検定)となった.感度解析の結果,1 つの 施設を除いただけで,治療効果の推定値は大幅に小さくなり,また,施設間の異質性も大幅に軽 減された.実際に,これらの結果を見ても,提案する方法で検出された施設は,全集団の解析結 果に強い影響を与える施設であるということができると考えられる.原著論文(Gormley et al., 1992)では,この施設で認められた,特に大きな群間差とその影響に関しては言及されていなかっ たが,実際には,詳細な評価・解釈を行う必要があったであろうと思われる.ただし,検定の多 重性の問題などもあるため,これらの結果だけから,検出された施設を外れ値と断定することは 避けるべきである.
4. 2 冠動脈心疾患の臨床試験(Aitkin, 1999;Yusuf et al., 1985)
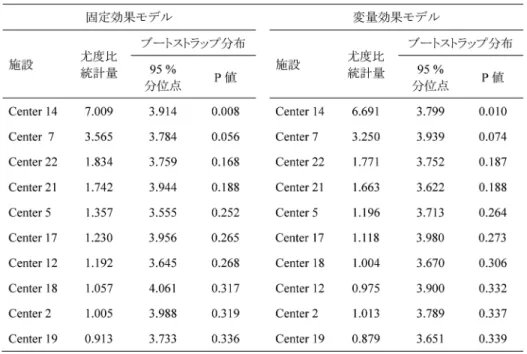
図 2 は,Aitkin(1999),Yusuf et al.(1985)による β 遮断薬の心筋梗塞の二次予防効果を評価 した多施設共同臨床試験のデータをフォレストプロットにしたものである.この試験は,22 の施 設による多施設共同試験であり,20,312 人の心筋梗塞発症後の患者に対して,β 遮断薬の長期投 与の有無がランダムに割り付けられた.アウトカムは遅発性の死亡であり,治療効果の指標には, ここではリスク比(risk ratio;RR)を用いた.固定効果モデルによるリスク比の推定値は,0.79 表 5. 前立腺肥大症の臨床試験における分散比統計量
(95 % 信頼区間:0.72〜0.86)であり,有意差が認められた.また,変量効果モデルによる推定値 も,0.80(95 % 信頼区間:0.72〜0.88)であり,異質性分散の推定値は 0.005 であった.施設間の 異質性は,それほどに大きくはなく,固定効果モデルと変量効果モデルで概ね類似した治療効果 の推定値が得られた. 表 6 に,施設ごとの外的スチューデント残差を示す.固定効果モデル,変量効果モデルともに, 施設 14 における外的スチューデント化残差が,ブートストラップ分布の下側 2.5 % 点を超える結 果となった.表 7 に,平均シフトモデルによる尤度比検定の結果を示している.同様に,施設 14 のみ,固定効果モデル,変量効果モデルのいずれにおいても,P<0.05 となった.加えて,表 8 に,VRATIO,TRATIOによる影響力解析の結果を示した.ここでも,施設 14 がブートスト ラップ分布の下側 5 % 点を下回るという結果になった.特に,施設 14 についての TRATIOの 実現値を見てみると,ほとんど 0 となっており,この施設を除くことで,変量効果モデルによる 異質性分散の推定値はほとんど 0 になることが示されている.この意味で,この施設 14 が,変量 図 2. 冠動脈心疾患の臨床試験(Aitkin, 1999;Yusuf et al., 1985)における施設ごとのリスク比についての
表 7. 冠動脈心疾患の臨床試験における平均シフトモデルによる尤度比検定 表 6. 冠動脈心疾患の臨床試験における外的スチューデント化残差
効果モデルによって説明される異質性分散の推定値に強く寄与していたことがわかる.これらの 結果から,総合的に判断して,施設 14 は影響力の強い極端なプロファイルを持つ施設であると考 えることができるであろう. 検出された施設 14 を除いた感度解析を実施してみても,変量効果モデルによるリスク比の推 定値は,0.77(95 % 信頼区間:0.70〜0.84),異質性分散の推定値は 0.000 となった.リスク比の推 定値は,わずかではあるが小さくなっており,95 % 信頼区間は,1 施設分の情報量の低下がある ものの,狭くなっている.実際の試験実施時点での解析で,この提案法による解析が可能であっ たならば,施設 14 がこのようなプロファイルを持っていた理由について,適切な考察・説明が必 要であったものと考えられる.なお,この事例解析においても,ブートストラップにおけるリサ ンプリングの回数は,一貫して 2400 回とした. 5.考 察 現在,医薬品・医療機器の開発,医療技術評価のために行われる臨床試験のほとんどは,多施 設共同臨床試験として行われている.施設間の異質性が,主要な結果・結論に影響を及ぼす可能 性については,既に十分に研究が進められており,詳細なガイダンスなども出されているが (Agresti and Hartzel, 2000;Biau et al., 2008;Kahan and Harhay, 2015;Kahan and Morris, 2013;
Localio et al., 2001;Munda and Legrand, 2014),本研究で提案したような極端なプロファイルを 持つ施設の検出や影響力解析について,詳細な方法論的枠組みは,これまでに十分に整備されて いなかった.変量効果モデルなどの施設間異質性を適切に説明するモデルを用いることで,一定 の理論的仮定のもとでの治療効果の推定の不偏性に関しては保証されるが,それを逸脱したプロ ファイルを持つ施設が混在する場合,その保証が崩れてしまう可能性は十分にあり得る.また,
統計学的な不偏性のみではなく,仮に,そのような極端なプロファイルを持つ施設があった場合, 試験の主要な統計解析の結果を解釈する上では,それに起因する系統的な要因について十分に精 査する必要があるであろう.これについては,4 節の 2 つの事例解析から明快な示唆が得られた ものと思われる. 提案する方法は,原則として,得られた結果をもとに,個々の施設の影響力などを精査するた めの方法であり,主要な統計解析に用いることは想定していない.外れ値の候補として検出され た施設を除外した解析も,基本的には,感度解析という位置づけで,主要な解析に対する補助的 なツールとして用いることを想定している.また,治療と施設の交互作用を検出するための方法 として,Gail-Simon 検定(Gail and Simon, 1985)のような交互作用検定なども広く用いられてき たが,これらの方法は,参加施設すべてを対象とした交互作用の有無についての検定であり,仮 に有意な結果が得られたとしても,どの施設が極端なプロファイルを持つ施設であるかについて の直接的な情報は得られない.本研究によって提案した方法は,個々の施設のプロファイルの外 れ具合や影響力を直接的に評価するための方法である点が,これらの方法と大きく異なる.また, 本研究では,回帰分析における影響力診断の方法(Belsley et al., 1980)などをもとに,多施設臨床 試験における評価方法を開発することを目的としたが,外れ値となる施設が複数あるような条件 下においては,同様に,ロバスト推定などの議論を行うことも可能であると思われる. また,多施設共同試験の施設ごとの解析においては,一般論として,一定以上の参加者がいな くては,安定的な統計的推測を行うことは困難であることが知られている(Kahan and Harhay, 2015).今回の影響力解析の方法においては,参加者数が極端に少ない施設においても,外れ値と 判定される確率(検出力)が低くなってしまうことは懸念される.ただし,その場合,参加者数 が極端に少ない施設は,全集団の解析への影響力も相対的に小さくなるため,実際に,検出され ない場合には,点推定値としては極端なプロファイルを持っていたとしても,全集団の解析結果 への影響力は小さいと解釈することができる.4 節の事例解析においても,いくつかそのような 施設を見て取ることができる(例えば,4.2 節の事例における施設 1).ただし,それらの施設に は,少数ながらも,特別なプロファイルを持った患者が集積している可能性もあるため,提案し た方法によって検出されなかったとしても,慎重に評価を行う必要がある. 従来の方法論によって議論されてきた,(1)施設間の異質性の有無とその定量的な評価,(2) 異質性があるもとで治療効果を不偏に推定するための方法に加えて,本研究で提案した,極端な プロファイルを持つ施設の検出や影響力解析は,これらの臨床試験の統計解析に有益な情報を与 えてくれるものと思われる.本研究で議論した方法は,施設ごとの要約統計量をもとに,比較的 簡便なモデルで計算を実行することができるため,実務家にとっても実装は容易であり,また, その結果の解釈は,非統計家にも容易であると思われる.ただし,臨床家とのコミュニケーショ ンにおいては,施設ごとのサンプルサイズや背景要因の分布など,施設間差の解釈のために必要 な情報を併せて提示することが有用であると考えられる.メタアナリシスとは異なり,多施設共 同臨床試験の解析においては,個人レベルのデータをもとに,検出された施設における参加者ご との背景やアウトカムについて精査することも可能である.また,個人レベルの共変量の情報を もとに,特定の患者集団でのサブグループ解析や調整解析を行うこともできる.本論文によって
提案した方法によって,多施設共同臨床試験の統計的エビデンスをより詳細に評価するための有 益な情報を新たに提供することができるものと考える.
謝 辞
本研究は,日本学術振興会科学研究費補助金(課題番号:19H04074)の助成を受けました.
参考文献
Agresti, A., and Hartzel, J.(2000).Strategies for comparing treatments on a binary response withmulti-centre data. Statistics in Medicine 19, 1115-1139.
Aitkin, M.(1999).Meta-analysis by random effect modelling in generalized linear models. Statistics in Medicine 18, 2343-2351.
Belsley, D. A., Kuh, E., and Welsch, R. E. (1980). Regression Diagnostics. New York: Wiley.
Biau, D. J., Porcher, R., and Boutron, I.(2008).The account for provider and center effects in multicenter interventional and surgical randomized controlled trials is in need of improvement:a review. Journal of Clinical Epidemiology 61, 435-439.
Canner, P. L., Huang, Y. B., and Meinert, C. L.(1981a).On the detection of outlier clinics in medical and surgical trials:I. Practical considerations. Controlled Clinical Trials 2, 231-240.
Canner, P. L., Huang, Y. B., and Meinert, C. L.(1981b).On the detection of outlier clinics in medical and surgical trials:II. Theoretical considerations. Controlled Clinical Trials 2, 241-252.
Chen, D. G., Liu, D., Min, X., and Zhang, H. (2020). Relative efficiency of using summary versus individual data in random-effects meta-analysis. Biometrics, DOI: 10.1111/biom.13238.
DerSimonian, R., and Laird, N. M.(1986).Meta-analysis in clinical trials. Controlled Clinical Trials 7, 177-188. Gail, M., and Simon, R.(1985).Testing for qualitative interactions between treatment effects and patient
subsets. Biometrics 41, 361-372.
Gormley, G. J., Stoner, E., Bruskewitz, R. C., et al.(1992).The effect of finasteride in men with benign prostatic hyperplasia. The Finasteride Study Group. New England Journal of Medicine 327, 1185-1191. Gould, A. L.(1998).Multi-centre trial analysis revisited. Statistics in Medicine 17, 1779-1797.
Gumedze, F. N., and Jackson, D.(2011).A random effects variance shift model for detecting and accommodating outliers in meta-analysis. BMC Medical Research Methodology 11, 19.
Hedges, L. V., and Olkins, I. (1985). Statistical Methods for Meta-Analysis. New York, NY: Academic Press. Higgins, J. P. T., and Thomas, J. (2019). Cochrane Handbook for Systematic Reviews of Interventions, 2nd
edition. Chichester: Wiley-Blackwell.
ICH E9 Expert Working Group.(1999).ICH Harmonised Tripartite Guideline. Statistical principles for clinical trials. Statistics in Medicine 18, 1905-1942.
Kahan, B. C.(2014).Accounting for centre-effects in multicentre trials with a binary outcome - when, why, and how? BMC Medical Research Methodology 14, 20.
Kahan, B. C., and Harhay, M. O.(2015).Many multicenter trials had few events per center, requiring analysis via random-effects models or GEEs. Journal of Clinical Epidemiology 68, 1504-1511.
Kahan, B. C., and Morris, T. P.(2012a).Improper analysis of trials randomised using stratified blocks or minimisation. Statistics in Medicine 31, 328-340.
Kahan, B. C., and Morris, T. P.(2012b).Reporting and analysis of trials using stratified randomisation in leading medical journals:review and reanalysis. BMJ 345, e5840.
Kahan, B. C., and Morris, T. P.(2013).Analysis of multicentre trials withcontinuous outcomes:when and how should we account for centre effects? Statistics in Medicine 32, 1136-1149.
Lin, D. Y., and Zeng, D.(2010).On the relative efficiency of using summary statistics versus individual-level data in meta-analysis. Biometrika 97, 321-332.
Localio, A. R., Berlin, J. A., Ten Have, T. R., and Kimmel, S. E.(2001).Adjustments for center in multicenter studies:an overview. Annals of Internal Medicine 135, 112-123.
Matsushima, Y., Noma, H., Yamada, T., and Furukawa, T. A.(2020).Influence diagnostics and outlier detection for meta-analysis of diagnostic test accuracy. Research Synthesis Methods 11, 237-247. Munda, M., and Legrand, C.(2014).Adjusting for centre heterogeneity in multicentre clinical trials with a
time-to-event outcome. Pharmaceutical Statistics 13, 145-152.
Negeri, Z. F., and Beyene, J.(2020).Statistical methods for detecting outlying and influential studies in meta-analysis of diagnostic test accuracy studies. Statistical Methods in Medical Research 29, 1227-1242. Noma, H.(2011).Confidence intervals for a random-effects meta-analysis based on Bartlett-type corrections.
Statistics in Medicine 30, 3304-3312.
Noma, H., Gosho, M., Ishii, R., Oba, K., and Furukawa, T. A. (2020). Outlier detection and influence diagnostics in network meta-analysis. Research Synthesis Methods, 11, 891-902.
Noma, H., Nagashima, K., Maruo, K., Gosho, M., and Furukawa, T. A.(2018).Bartlett-type corrections and bootstrap adjustments of likelihood-based inference methods for network meta-analysis. Statistics in Medicine 37, 1178-1190.
Viechtbauer, W., and Cheung, M. W.(2010).Outlier and influence diagnostics for meta-analysis. Research Synthesis Methods 1, 112-125.
Yusuf, S., Peto, R., Lewis, J., Collins, R., and Sleight, P.(1985).Beta blockade during and after myocardial infarction:an overview of the randomized trials. Progress in Cardiovascular Diseases 27, 335-371. Zeng, D., and Lin, D. Y.(2015).On random-effects meta-analysis. Biometrika 102, 281-294.