汎用プログラミング環境を用いた GPGPU に関する研究
大島 聡史
電気通信大学 大学院情報システム学研究科 博士 ( 工学 ) の学位申請論文
2009 年 3 月
汎用プログラミング環境を用いた GPGPU に関する研究
博士論文審査委員会
主査 本多 弘樹 教授
委員 曽和 将容 教授
委員 多田 好克 教授
委員 吉永 努 准教授
委員 近藤 正章 准教授
著作権所有者 大島 聡史
2009 年
Study of GPGPU Using Commodity Programming Environment Satoshi OHSHIMA
Abstract
GPU (Graphics Processing Unit) is suitable for parallel processing and has high performance than existing CPU (Central Processing Unit), so GPU is now being used for various applications. Many applications are getting speed-up using GPGPU (General-Purpose computation using GPUs), while the difficulty of GPU program- ming is under problem.
Application programmer must use special programming languages and libraries for GPGPU programming to create programs running on GPUs, but using such languages and libraries are difficult for programmers because it is necessary to learn GPU’s architecture, execution model of GPU, and programming language’s spec- ification. Therefore it is a challenge of GPGPU to make GPGPU programming easy.
In this paper, two approaches which make using GPGPU easy with commodity parallel programming environments are proposed.
The first approach is a “parallel computation library” which hides parallel pro- gramming from application programmers by offering parallelized computation ker- nels. This library has APIs similar to CPU’s libraries and computes using CPUs and GPUs. To get a high performance in anytime, this library divides the prob- lem and executes them in parallel using CPUs and GPUs when problem size is big enough and a balance between CPU’s performance and GPU’s performance is suitable, and uses an only CPU in other cases with appropriate balance suggested by a tuning-script and a divide-module. “GPUPC GEMM Library” is a parallel matrix-matrix multiplication library based on this approach. This library can get a high performance with GPGPU systems without parallel programming.
The second approach is a “parallel programming environment” which offers a par- allel programming environment like as existing parallel programming environments used on CPU. “OMPCUDA” is an OpenMP implementation for CUDA based on
this approach. OMPCUDA can execute parallel regions of OpenMP programs on a GPU, so that programmers can execute parallel programs on a GPU without learning and writing GPU-specific parallel programs.
Contributions of this study are proposal of new approaches which make using GPGPU easy for many application programmers and evaluation of the effectiveness of approaches by implementing a library (GPUPC GEMM Library) and a system (OMPCUDA). Results of this study are significant from the perspective of indicating how easy-to-use environment for application programmers in computing systems having GPU should be.
汎用プログラミング環境を用いた GPGPU に関する研究 大島 聡史
概要
GPU (Graphics Processing Unit) は既存のCPU (Central Processing Unit) と比 べて並列処理による高い演算性能を持つため,画像処理以外の処理を含めた様々な 用途への利用が進められている.GPUを用いた汎用演算GPGPU (General-Purpose computation using GPUs) により様々なアプリケーションの高速化が行われている 中,GPUプログラミングの難しさが問題となっている.
現在アプリケーションプログラマがGPU上で動作するプログラムを作成するに は,GPU (GPGPU)専用のプログラミング言語やライブラリ(プログラミング環境) を用いる必要があり,GPUのアーキテクチャやGPU向けのプログラミング環境で 利用される実行モデルについて理解する必要がある.このようにアプリケーション プログラマにとってGPGPUプログラミングは難しく手間がかかるため,GPGPU を容易に利用できるようにすることはGPGPUの大きな課題である.
本研究では,現在CPUを対象とした並列化プログラミングに利用されている汎 用プログラミング環境をGPGPUでも利用可能としアプリケーションプログラマに
対するGPGPUの利用を容易にすることを提案する.
また提案に対する具体的なアプローチとして“並列計算ライブラリによるアプロー
チ”と“並列プログラミング環境によるアプローチ”の2つのアプローチを挙げ,そ
れぞれのアプローチに基づきライブラリや処理系を実装して有効性の検証を行った.
各アプローチの概要と得られた成果は以下の通りである.
1. 並列化された計算カーネルを提供することで並列化プログラミング自体を隠 蔽する並列計算ライブラリ (並列計算ライブラリによるアプローチ)
• CPU単体で実行されるライブラリと同様のAPIを持つGPU向けのライ ブラリを提供し,GPUに関する知識がないアプリケーションプログラマ でもGPUの持つ高い並列演算性能を活用可能とすることを目的とした.
• 既存のGPU向け並列計算ライブラリには“CPU単体で実行されるライ ブラリと同様のAPIを持つGPU向けのライブラリを提供するだけでは
対象問題のデータ規模やCPU-GPU間での負荷分散に関する課題があり 良い性能が得られない可能性がある”という問題点があることを指摘し た.また解決のために“CPU単体で実行されるライブラリと同様のAPI を持ちながら,対象問題のデータ規模が小さい場合にはCPUのみで演算 を行い,データ規模が大きい場合にはCPUとGPUの性能バランスにあ わせてCPUとGPUで適切な問題分割・並列実行を行う機構を持つ並列 計算ライブラリ” を提案し,実装方法や実装上の問題についての検討を 行った.
• 提案に基づき行列積和計算を対象としたライブラリ“GPUPC GEMM Li-
brary”を実装し,テストプログラムやベンチマークプログラムを用いて
実装の手間と性能について評価を行った.
• 評価の結果,GPUPC GEMM Libraryが備えるチューニングスクリプト およびスクリプトの出力結果にあわせて適切に問題分割を行う問題分割 機構によって,本ライブラリを利用するアプリケーションプログラマが GPUに関する知識や実行対象計算機システムのCPUとGPUの性能バ ランスを気にする必要なくGPUの持つ高い並列演算性能を常に容易に利 用できることを確認した.
2. 並列計算アルゴリズムを実装するための並列化プログラミング言語や並列化プ ログラミング用のライブラリ (並列化プログラミング環境によるアプローチ)
• CPUを対象とした並列化プログラミング環境をGPUプログラミングに も利用できるようにすることで,アプリケーションプログラマにとって
GPGPU専用のプログラミング環境の習得などの手間を削減し,GPGPU
を容易に利用可能にすることを目的とした.
• 既存のCPU向け並列化プログラミング環境をGPGPUプログラミング にも利用可能とすることを提案し,典型的なGPUのハードウェア構成と 既存のCPU向け並列化プログラミング環境との対応付けを検討した.さ らにGPGPU環境の1つであるCUDAに対してより具体的な対応付けを 検討した.
• 検討に基づきCUDA向けのOpenMP処理系“OMPCUDA”を実装し,テ
ストプログラムを用いて利用の手間と性能について評価を行った.
• 評価の結果,OMPCUDAはOpenMPの典型的な問題であるループの並 列化に対して,OpenMPを用いた簡単な並列化記述によってGPU上の多 数の演算器を有効に利用することで高い性能が得られることを確認した.
以上の2つのアプローチにより,汎用プログラミング環境を用いてGPGPUを利 用可能とすることで,アプリケーションプログラマに対する手間を増加させること
なくGPGPUの高い並列演算性能を容易に利用可能とできることを示した.
本研究の今後の課題としては,アプリケーションプログラマにとっての手間の増 加と得られる性能とのトレードオフに関する課題と,本研究の成果をGPU以外の ハードウェア (GPU以外のSIMD型アクセラレータ) やOpenCLと比較することを 挙げた.
本研究の貢献は,GPGPUを多くのアプリケーションプログラマが容易に活用で きるようにするアプローチを提案し,提案に基づいてライブラリや処理系の実装を 行い有効性を実証した点にある.この成果は,今後さらに普及が広がると考えられ るGPUを搭載した計算機システムにおけるアプリケーションプログラマにとって 使いやすい利用環境のあり方を示すものとして意義がある.
目 次 i
目 次
1 序論 1
1.1 本研究の背景と目的 . . . . 1
1.2 本研究のアプローチ . . . . 3
1.3 本論文の構成 . . . . 6
2 GPUに関する技術動向と本研究の位置づけ 8 2.1 GPUのアーキテクチャとプログラミング環境 . . . . 8
2.1.1 GPUとGPGPU . . . . 8
2.1.2 GPGPUプログラミング環境 . . . . 10
2.2 SIMD型アクセラレータとしてのGPU . . . . 15
2.3 プログラミング環境に関する研究の動向 . . . . 20
2.3.1 GPU向けのプログラミング環境 . . . . 20
2.3.2 CPU向けのプログラミング環境 . . . . 25
2.4 SIMD型アクセラレータやプログラミング環境に関する研究と本研究 との関係 . . . . 27
3 並列計算ライブラリによるアプローチ 31 3.1 CPUとGPUを用いて問題分割・並列実行を行うライブラリの提案 . 31 3.2 CPUとGPUを用いて問題分割・並列実行を行うライブラリの実装 . 35 3.2.1 CPUとGPUを用いた並列処理の実装 . . . . 35
3.2.2 CPUとGPUによる適切な問題分割を行うための仕組み . . . 36
3.2.3 複数のCPUや複数のGPUを搭載した計算機システム向けの 実装 . . . . 40
3.3 GPUPC GEMM Library : CPUとGPUを用いて問題分割・並列実 行を行う行列計算ライブラリ の設計と実装. . . . 47
3.3.1 ライブラリが対象とする範囲 . . . . 47
3.3.2 ライブラリの設計と実装 . . . . 49
3.4 GPUPC GEMM Libraryの評価 . . . . 59
3.4.1 単純な行列積和計算を用いた性能確認 . . . . 59
目 次 ii
3.4.2 HPLベンチマークを用いた性能確認 . . . . 70
3.4.3 利用の手間と得られる性能に関する評価 . . . . 75
4 並列化プログラミング環境によるアプローチ 77 4.1 既存のCPU向け並列化プログラミング環境を用いたGPGPUプログ ラミングの提案 . . . . 77
4.1.1 既存のCPU向け並列化プログラミング環境とGPGPU . . . . 78
4.1.2 既存のCPU向け並列化プログラミング環境とCUDA . . . . . 83
4.2 OMPCUDA : CUDA向けOpenMP の提案と実装 . . . . 98
4.2.1 全体の構成 . . . . 98
4.2.2 プログラム変換機構の実装 . . . . 103
4.2.3 実行時ライブラリの実装 . . . . 105
4.3 OMPCUDAの評価 . . . . 111
4.3.1 行列積を用いた性能確認 . . . . 111
4.3.2 円周率の計算(グレゴリ級数)を用いた性能確認 . . . . 115
4.3.3 実装の手間や記述の容易性に関する評価 . . . . 122
5 結論 125 5.1 研究成果の概要 . . . . 125
5.2 今後の課題 . . . . 132
謝辞 135
参考文献 136
A 付録1: CUDAを用いた実装のソースコード 148
図 目 次 iii
図 目 次
1 既存のCPU向けプログラミング環境とGPU . . . . 4
2 画像処理と並列計算 . . . . 9
3 画像描画処理と汎用演算 . . . . 11
4 単純な配列加算プログラムの例(一部抜粋) . . . . 13
5 CSXのハードウェア構成図 . . . . 16
6 Cellのハードウェア構成図 . . . . 18
7 ストリーミング言語の概念 . . . . 21
8 BrookGPUを用いたプログラムの例. . . . 22
9 RapidMindを用いたプログラムの例 . . . . 23
10 SPRATを用いたプログラムの例 . . . . 24
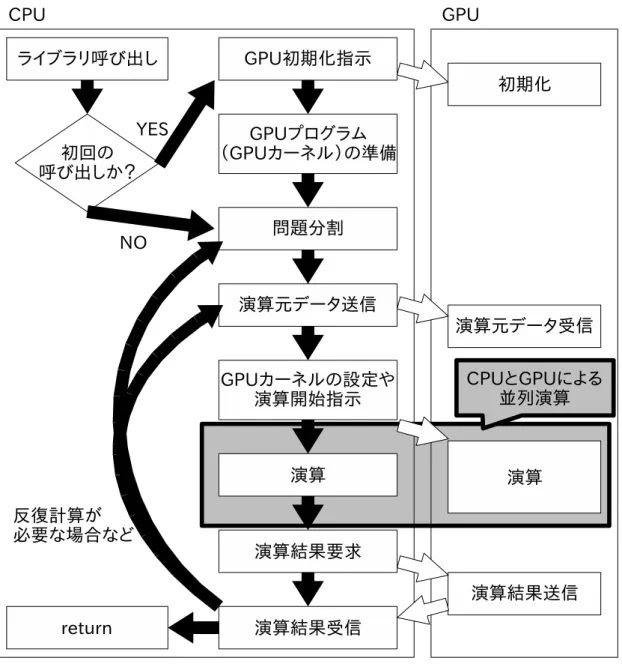
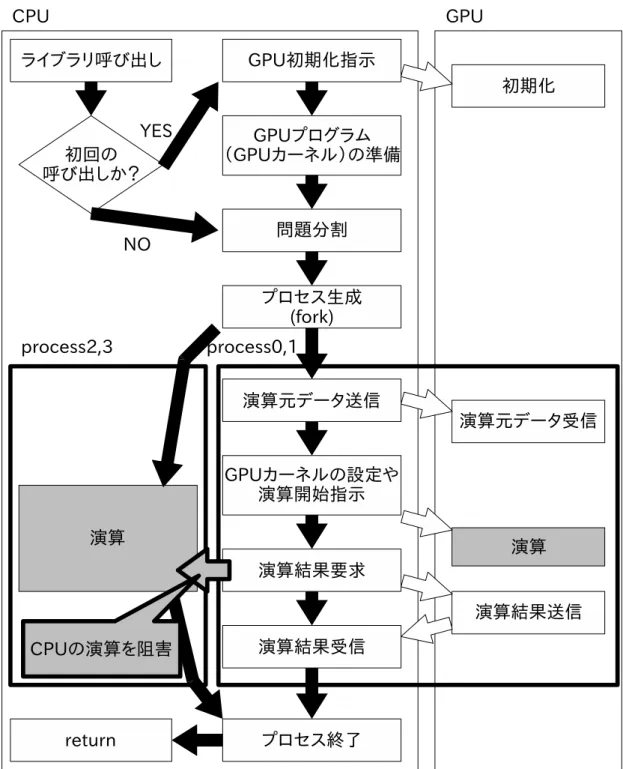
11 典型的なGPGPUプログラムの処理手順 . . . . 32
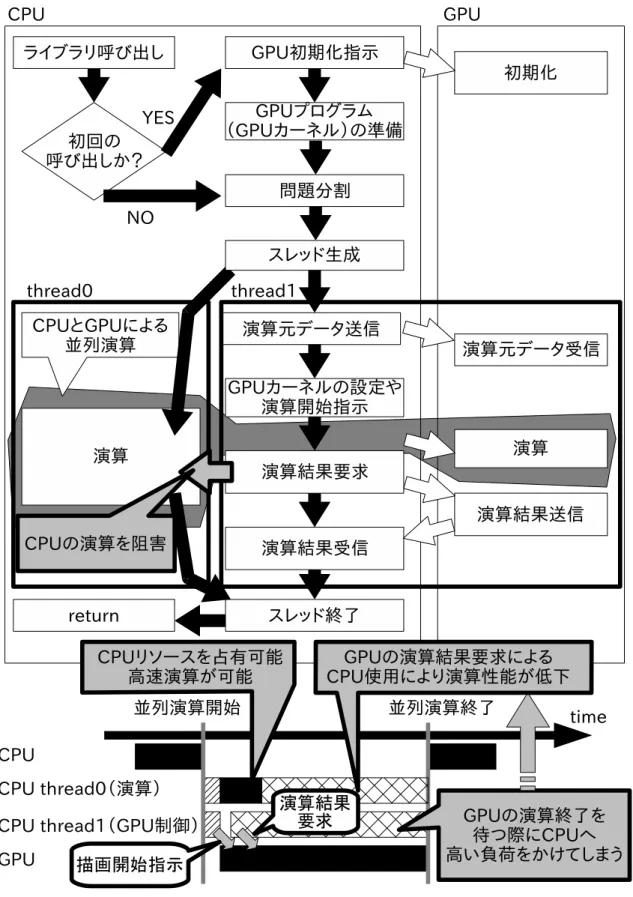
12 スレッドを用いた並列実行の失敗例 . . . . 37
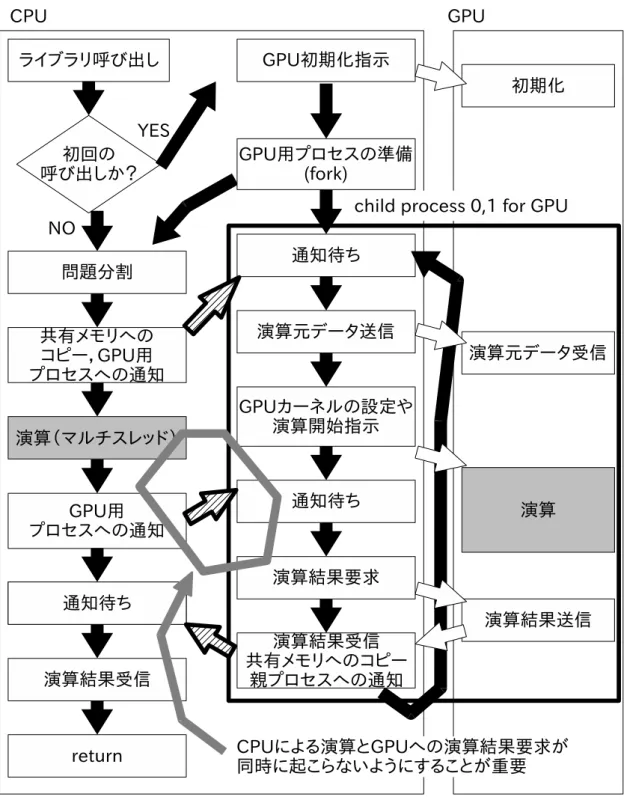
13 提案するライブラリの構造 . . . . 38
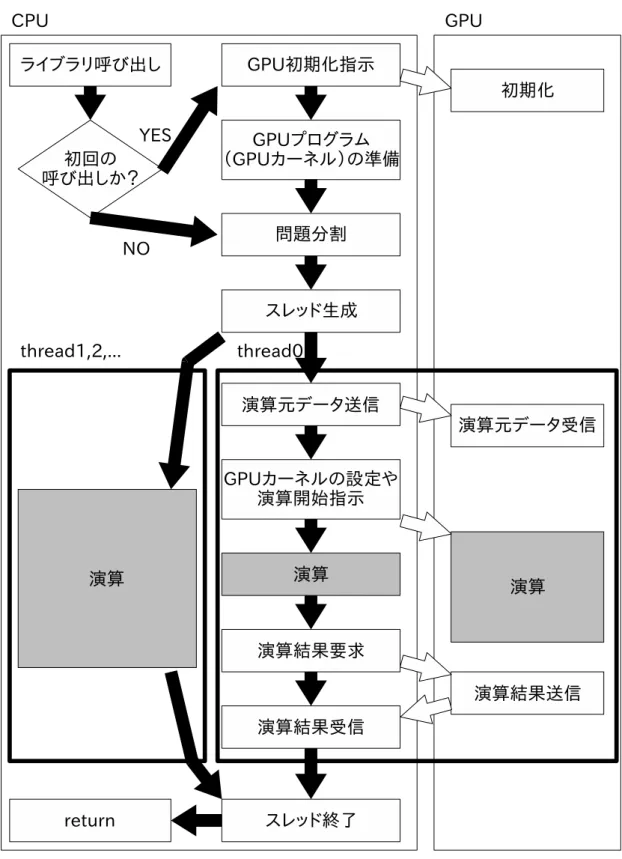
14 複数CPUを用いた実装の例 1 . . . . 42
15 複数CPUを用いた実装の例 2 . . . . 43
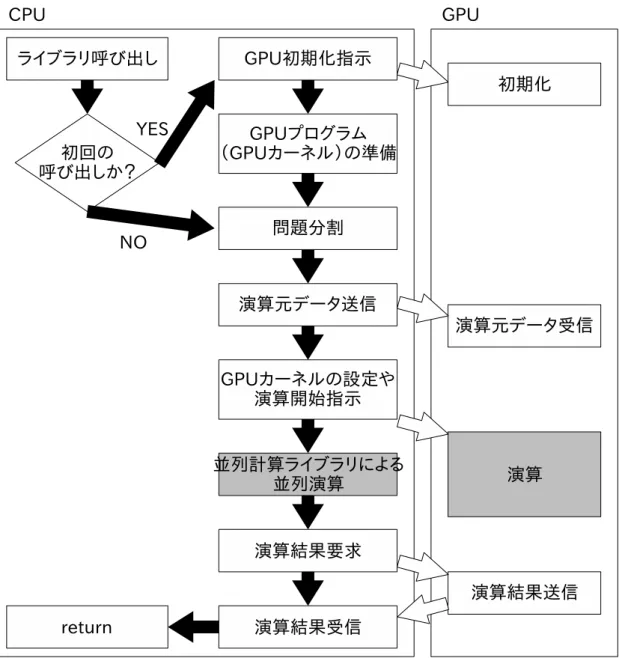
16 複数CPUと複数GPUを用いた実装の例 1 . . . . 45
17 複数CPUと複数GPUを用いた実装の例 2 . . . . 46
18 BLASにおけるGEMMの関数定義 . . . . 48
19 ベクトル演算を利用した行列積の例 . . . . 51
20 ベクトル演算が利用できない行列積の例 . . . . 52
21 問題分割方法 . . . . 53
22 ライブラリの設計 . . . . 54
23 複数CPU・複数GPU対応版GPUPC GEMM Libraryの構造 . . . . 57
24 各問題サイズに対する実行時間とCPUに対する実行時間比(環境1) . 61 25 各問題サイズに対する実行時間とCPUに対する実行時間比(環境2) . 62 26 各問題サイズに対する実行時間とCPUに対する実行時間比(環境3) . 63 27 各問題サイズに対する実行時間とCPU に対する実行時間比(環境 1:DGEMM) . . . . 65
図 目 次 iv
28 各問題サイズに対する実行時間とCPU に対する実行時間比(環境
2:DGEMM) . . . . 66
29 各問題サイズに対する実行時間とCPU に対する実行時間比(環境 3:DGEMM) . . . . 67
30 2CPU+2GPUでの性能評価(SGEMM) . . . . 69
31 HPLの性能パラメタ(括弧内は初期値) . . . . 71
32 CPUによるHPLの性能調査:問題サイズと性能(環境1) . . . . 72
33 CPUによるHPLの性能調査:ブロックサイズと性能(環境1) . . . . 72
34 GPUPC GEMM Libraryを用いたHPLの実行結果(環境1) . . . . 74
35 典型的なGPUのハードウェア構成 . . . . 79
36 CUDAのハードウェアモデル . . . . 85
37 CUDAのメモリモデル . . . . 88
38 SIMDプログラミングとCUDAとの対応付け . . . . 90
39 スレッドライブラリを用いたマルチスレッドプログラミングとCUDA との対応付け . . . . 92
40 OpenMPを用いた並列化プログラミングとCUDAとの対応付け . . . 94
41 通信ライブラリを用いたマルチプロセスプログラミングとCUDAと の対応付け . . . . 96
42 OpenMPとOMPCUDAの実行モデルとの対応付け . . . . 100
43 OmniとOMPCUDAの関係およびOMPCUDAの構成 . . . . 101
44 プログラム変換機構の処理手順 . . . . 104
45 OMPCUDAにおけるforループのスケジューリング例 . . . . 107
46 行列積のソースコード1 (3重ループ) . . . . 113
47 行列積のソースコード2 (2重ループ) . . . . 113
48 行列積の実行時間 1 (問題サイズ 1024) . . . . 114
49 行列積の実行時間 2 (問題サイズ 1024) . . . . 116
50 円周率計算のソースコード . . . . 116
51 円周率の求解の実行時間 1 (問題サイズ 0x10000000) . . . . 118
52 円周率の求解の実行時間 2 (問題サイズ 0x10000000) . . . . 120
53 円周率の求解の実行時間 3 (問題サイズ 0x10000000) . . . . 121
表 目 次 v
表 目 次
1 SIMD型アクセラレータの基礎的なデータ . . . . 15
2 評価環境 1 . . . . 59
3 評価環境 2 . . . . 111
4 行列積のプログラム行数とGPUに関する知識の必要性 . . . . 122
5 円周率求解のプログラム行数とGPUに関する知識の必要性 . . . . . 124
1
1 序論
1.1 本研究の背景と目的
気象,医療,宇宙など様々な分野において,高性能な計算機を用いた計算が必須 となっている[1, 2, 3].これらの分野では高速,高精度,大規模な計算が要求され るため,より高性能な計算機が必要とされている[4, 5, 6, 7, 8].また近年では個人 ユースのパーソナルコンピュータ (PC) においても動画像処理など計算量の多い処 理を行う機会が増加し,高性能な計算機の要求が高まっている.
計算機の演算性能に大きな影響を与えるプロセッサ(CPU) の性能に注目すると,
従来はプロセスの微細化とクロック周波数の向上によりその性能を向上させてきた ことがわかる.例えば1993年のPentiumプロセッサが800nmプロセスルール・ク ロック周波数60MHzだったのに対して,2005年のPentium4プロセッサ (Prescott コア)は90nm プロセスルール・クロック周波数3.80GHzに達している[9].
しかしながら今日のプロセッサにおいては,微細化が進むとリーク電流が増加し 消費電力が増加してしまうことや,微細化が原子の大きさによる物理的限界に近づ きつつあるため微細化そのものが難しくなっていること,またクロック周波数の向 上が発熱量や消費電力の増加につながることなどが問題となっている.その結果,
2008年末の時点で利用されているCPUのプロセスルールは2005年のプロセスルー ルの半分である45nmにとどまっており,またクロック周波数についても,適切な 冷却機構の元で運用されるサーバ向けCPUが5GHz以上の周波数を達成している [10] ものの,コンシューマ向けの多くのCPUでは4GHz未満の周波数にとどまって いるのが現状である.
今日におけるCPUの性能への関心は,これまでのシングルコアCPUによるシン グルスレッドの性能から,複数のコアを1パッケージに収めたマルチコアCPUの性 能へと向けられている.2008年末の時点では,2つから4つのコアを搭載したマル チコアCPU (デュアルコアCPU・クアッドコアCPU)が主流となっており,主要な CPUベンダーは4つ以上のコアを搭載したCPUの開発・リリースに注力している [11, 12].
一方で,既存のCPUと比べてより高い並列度を持ち理論演算性能や電力あたり 性能が高い新しいハードウェアへの注目が高まっている.その中でも,主にPCI-
1.1 本研究の背景と目的 2
Express接続のビデオカードとして提供されている画像処理用のハードウェア“GPU (Graphics Processing Unit)” は,既存のCPUと比べて多数の演算を同時に実行可 能であり高い理論演算性能を持つため注目されている.特に,ハイエンドモデルの GPUでは同時に200以上の演算が可能であり,また最大理論演算性能は1TFLOPS に達している[13, 14].近年ではGPUを用いた汎用演算“GPGPU (General-Purpose computation using GPUs)” [15, 16, 17, 18] によりプログラムの高速化を行った旨の 報告が相次いでいる[19, 20, 21, 22, 23].
今日のGPUは高速・高解像度な画面出力および動画再生支援機能などの要求に ともない多くのPCに搭載されており,広く普及が進んでいるハードウェアである.
そのためGPGPUを利用可能な計算機システムの普及が進んでいる一方,GPGPU
プログラミングの難しさがGPGPUの普及における大きな問題となっている.現在 提供されているGPGPU向けのプログラミング言語やライブラリ(以下本論文では,
プログラミング言語やライブラリをまとめてプログラミング環境と呼ぶ) は,GPU のハードウェアアーキテクチャと強く関連づけられた言語仕様や,既存のプログラ ミング手法とは異なる新たな実行モデルを習得しなければ利用できないため,アプ リケーションプログラマにとっては利用に手間がかかり,大きな負担となっている.
現在のGPUは,ハードウェアアーキテクチャやプログラミング言語など新たな知 識や技術を習得し,手間のかかる実装を行うことではじめて高い性能を達成するこ とが可能なハードウェアである.手間をかけずにGPUの性能を活用するのは難し い一方で,かけた手間に対して性能が得られないことも少なくはない.アプリケー ションプログラマが現実的にかけられる手間には限度があるうえに,特定のハード ウェアでのみ有効な知識や技術の習得は活用できる範囲が限られるという理由で敬 遠される可能性もある.そのためGPUの性能を活用できるユーザは一部のパワー ユーザに限られており,一般の多くのアプリケーションプログラマにとってGPUの 利用は難しいのが現状である.
そこで本研究では,既存のCPU向けプログラミングに利用されている汎用プロ グラミング環境を用いてGPGPUを利用できるようにすることで,アプリケーショ ンプログラマがGPGPUを容易に活用可能とすることを目指す.
1.2 本研究のアプローチ 3
1.2 本研究のアプローチ
アプリケーションプログラマにとってGPGPUの利用が難しい原因として,GPGPU を利用するためにハードウェアアーキテクチャと強く結びついた言語やライブラリ を利用する必要があることが挙げられる.
既存のCPU向けプログラミングにおいては,多くのアプリケーションプログラマ は機械語やアセンブラ言語といった低級言語ではなく,C/C++やJavaなどの高級 言語を利用している.高級言語はハードウェアアーキテクチャとの結びつきが弱い ため,アプリケーションプログラマは対象とする計算機システムの詳細なハードウェ アアーキテクチャの知識がなくてもプログラムを記述し動かすことができる.また,
多くのコンパイラやインタプリタは複数のCPUアーキテクチャに対応しているた め,アプリケーションプログラマはCPUの違いを気にせずプログラミングを行う ことが可能であり,最適化コンパイラによって同一のソースコードから対象CPUご とに最適化された実行ファイルを得ることもできる.
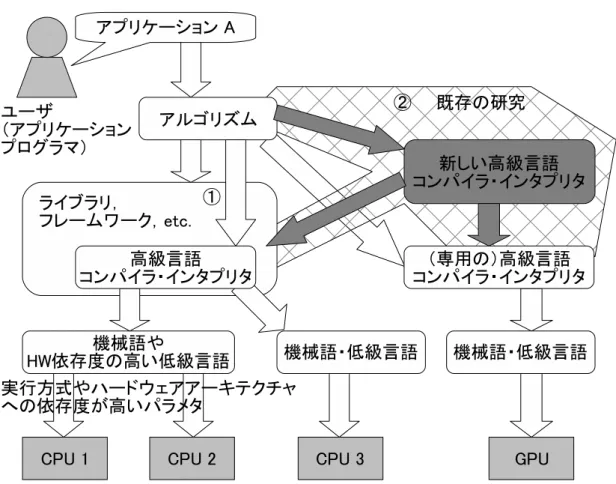
さらに,ソースコードを再利用するためやアルゴリズムを実装する手間を削減す るため,そして最適化プログラミングの手間を削減するために,様々なライブラリ が利用されている(図1-°1 ).
一方で現在GPGPU向けに提供されているプログラミング環境は,GPGPU専用 の言語やライブラリ,もしくは新しい実行モデルのプログラミング環境である(図 1-°2 , 2章) .これらを用いてGPGPUプログラミングを行うには,GPUのハード ウェアアーキテクチャに関する知識や,新しいプログラミング言語の言語仕様や実 行モデルの理解が必要であるため,アプリケーションプログラマにとって手間がか かり負担が大きいことが問題となっている.
これらの問題に対して本研究では,GPUが並列処理による高い演算性能を持つ ハードウェアであることから,現在CPU向けの並列化プログラミングに利用され ている汎用プログラミング環境がGPGPUプログラミングにも利用できれば,アプ リケーションプログラマがGPGPUを容易に利用できると考えた.そこで現在CPU 向けの並列化プログラミングに利用されている汎用プログラミング環境として“並 列化された計算カーネルを提供することで並列化プログラミング自体を隠蔽する並 列計算ライブラリ (並列計算ライブラリ)”と“並列計算アルゴリズムを実装するた
1.2 本研究のアプローチ 4
図 1: 既存のCPU向けプログラミング環境とGPU
1.2 本研究のアプローチ 5
めの並列化プログラミング言語や並列化プログラミング用のライブラリ (並列化プ ログラミング環境)”の2つを挙げ,これらを用いてアプリケーションプログラマが
GPGPUを容易に利用可能とする方法を提案する.
なお本研究で対象とする計算機システムは,シングルコアまたはマルチコアのCPU が1個とGPUが1枚から数枚搭載された1台の計算機からなる計算機システムとす る.複数台の計算機からなる計算機システムについては,基本的には各計算機の性 能がGPUにより向上したものとみなした上で複数台の計算機向けの手法を用いる ことで対応できると考えられるため,本研究では扱わない.
アプローチ1 : 並列計算ライブラリ
アプリケーションプログラマに対して容易にGPUの並列演算性能を利用できる ようにする方法として,GPU向けに並列化された計算カーネルを提供する並列計算 ライブラリを作成し,GPU向けの並列化プログラミングを行わなくてもGPUの持 つ並列演算性能を利用できるようにするという方法が考えられる.この方法では並 列化プログラミング自体を隠蔽することができるため,アプリケーションプログラ マはAPIさえ理解していればGPUの持つ並列演算性能を利用することが可能とな り,アルゴリズムの実装やGPGPUプログラミング習得の手間を大きく削減できる と期待できる.
しかしながら,単にGPU上での並列計算とCPU-GPU間でのデータ転送やGPU の制御処理をまとめただけのライブラリでは,対象問題のデータ規模が小さい場合 などいくつかの場合に高い性能が得られない可能性が生じてしまう.
そこで本アプローチでは,こうした性能が得られないという問題を解決し常に高 い性能を得ることができる並列計算ライブラリの提案と設計を行う.また提案した アプローチに基づいてCPUとGPUを用いて問題分割・並列実行を行う数値計算ラ イブラリ“GPUPC GEMM Library”を実装し,テストプログラムやベンチマークを 用いて利用の手間や性能の面から提案アプローチの評価を行う.
1.3 本論文の構成 6
アプローチ2 : 並列化プログラミング環境
並列計算ライブラリにより並列化プログラミング自体を隠蔽するアプローチ1は,
対象プログラムが典型的なアルゴリズムの組み合わせなどライブラリ化に適した処 理により支配的な場合に特に有効である.しかしながら全てのアプリケーションが これに該当するわけではなく,アプリケーションプログラマが自ら詳細なアルゴリ ズムの実装を行う必要があることも少なくない.
一方で既存のGPGPUプログラミング環境は,GPUのアーキテクチャや新しいプ ログラミング言語の言語仕様などを理解しなくては利用できないため,アプリケー ションプログラマにとって容易に利用できるとは言い難い.しかしもし既存のCPU 向けプログラミング環境を用いてGPGPUプログラムを記述することができれば,
アプリケーションプログラマはGPUのアーキテクチャや新しいプログラミング言 語の言語仕様などを習得する手間をかけずにGPGPUを利用可能となることが期待 できる.
そこで本アプローチでは,既存のCPU向けの並列化プログラミング環境を用いた
GPGPUプログラミングを提案する.また提案したアプローチに基づいてGPGPU
環境の1つであるCUDA向けのOpenMP処理系“OMPCUDA”を実装し,テスト プログラムを用いて利用の手間や性能の面から提案アプローチの評価を行う.
1.3 本論文の構成
本論文は5つの章により構成される.
第1章は本章であり,本研究の背景やアプローチについて述べた.
第2章ではGPUに関する技術動向やGPGPU向けのプログラミング環境につい ての研究を整理し,またしばしばGPUと性能やハードウェアアーキテクチャを比 較されるいくつかのハードウェアについての確認やプログラミング環境に関する研 究についての確認を行い,本研究の位置づけを明確にする.
第3章では,汎用プログラミング環境を用いてGPGPUを容易に利用可能とする ための手法として,並列計算ライブラリによるアプローチを提案し,提案に基づく ライブラリを実装して利用の手間や性能についての評価を行う.
1.3 本論文の構成 7
第4章では,汎用プログラミング環境を用いてGPGPUを容易に利用可能とする ための手法として,並列化プログラミング環境によるアプローチを提案し,提案に 基づく処理系を実装して利用の手間や性能についての評価を行う.
第5章では,本研究の結言として研究成果と今後の課題についてまとめ,本研究 の意義を述べる.
8
2 GPU に関する技術動向と本研究の位置づけ
本章では,本研究が対象とするGPUのアーキテクチャおよび現在GPGPUに用 いられているプログラミング言語やライブラリなどのプログラミング環境について 確認・整理する.さらに,GPUと共通点を持ちしばしば“SIMD型アクセラレータ”
としてGPUとともに扱われる他のハードウェアや,マルチコアCPUやSIMD型ア クセラレータを対象として開発されているプログラミング環境について確認し,本 研究の位置づけを明確にする.
2.1 GPU のアーキテクチャとプログラミング環境
2.1.1 GPUとGPGPU
GPUは画像処理用のハードウェアである.狭義にはグラフィックスカード上の LSIやチップセットに統合されたグラフィックスチップがGPUであり,広義にはグ ラフィックスカードそのもの,すなわちLSIのみではなくLSIに接続されたメモリ
(DRAM) やデコーダチップなどグラフィックスカード上に搭載されたモジュールな
どもまとめてGPUと呼ばれている.また,GPUの持つ演算性能をGPU本来の目 的である画像処理に限らず様々な処理(汎用演算:General-Puspose computation) に も活用するのがGPGPU (General-Purpose computation using GPUs)である.
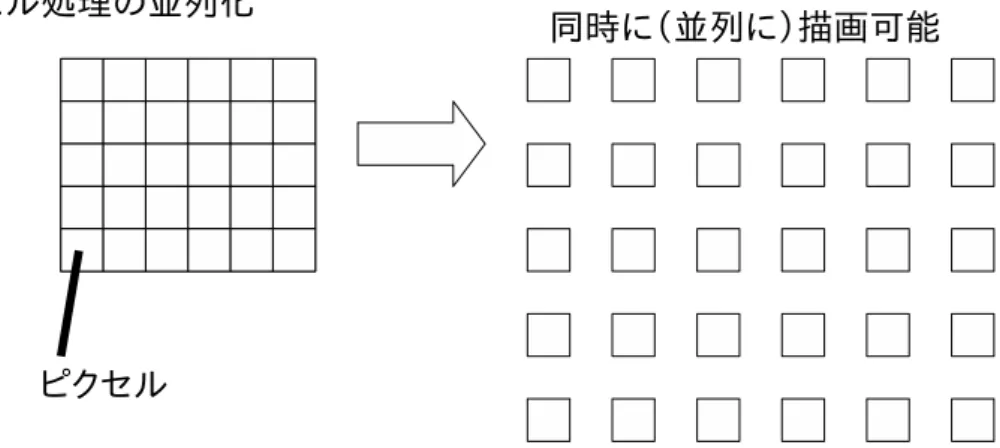
本来GPUに求められていた画像処理とは,古くは多色・高速・高解像度な2次元 の画像描画処理であり,現在ではより複雑な3次元の画像描画処理へと変化してき ている.これらの画像描画処理は頂点やピクセルを単位として多数同時に処理でき る(図2)ことから,GPUはCPUと比べて並列演算性能を重視した性能向上が行わ れてきた[24].
3次元物体の陰影を表現する際などには複雑で多彩なアルゴリズムの実装が要求 されるが,アルゴリズムをハードウェアレベルで実装する場合,新たな描画アルゴ リズムに対応するにはハードウェアを変更しなくてはならない.そこで,GPUが行 う描画処理の内容をソフトウェアプログラムによって変更可能とする機構“プログ ラマブルシェーダ”が利用されるようになった.
以上の結果現在のGPUは,既存のCPUと比較すると制限が多いものの様々なア
2.1 GPUのアーキテクチャとプログラミング環境 9
図 2: 画像処理と並列計算
2.1 GPUのアーキテクチャとプログラミング環境 10
ルゴリズムを実装できるだけのプログラマビリティを持ち,またハードウェアレベ ルでの高い並列性を持つため,並列性の高い問題に対してはCPUを大きく上回る 性能を発揮可能なハードウェアとなっている.そのためGPUは,画像処理以外に も様々な演算に対して高い性能が得られる可能性を見いだされ,GPUを用いた汎用
演算GPGPUが注目されるようになった.
現在のGPUは,本来の用途である高度な画像処理[25, 26]だけではなく,各種の シミュレーション[23, 19, 27, 28]や,LU分解[21, 22]やFFT[29, 30]などの様々な数 値計算問題[31, 32, 33, 34, 35],動画像変換等のマルチメディア処理[36]など,様々 な分野で高い性能を発揮している.さらにGPUベンダもGPUの汎用演算性能を重 視した製品開発や発表などを行っており[13, 14],今後も多くの分野でGPGPUの 活用が進むことが考えられる.
2.1.2 GPGPUプログラミング環境
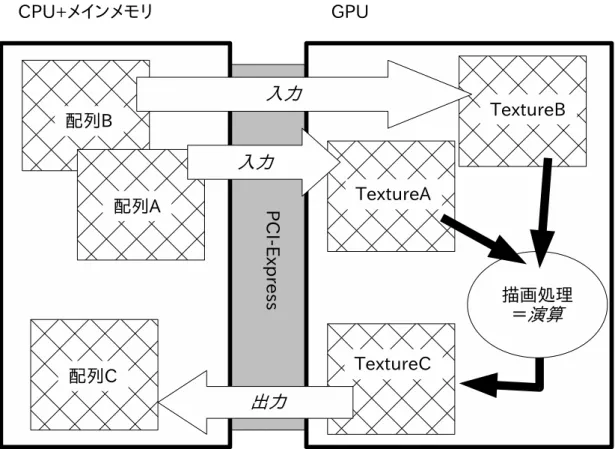
初期のGPGPUでは,画像描画処理の手続きと演算とを対応付けて利用していた.
すなわち,CPUからGPU上のメモリ (主にテクスチャ) へのデータセットを入力,
プログラマブルシェーダを用いた画像描画処理を演算,GPUからCPUへのデータ の書き戻し (描画結果の取得) を出力とみなして処理を行っていた(図3).
一方,GPUを用いて画像描画処理を行うプログラムを作成するには,GPUの動 作タイミング制御やCPU-GPU間の通信などを行うCPU上で実行されるプログラ ムを記述するためにDirectX[37]やOpenGL[38]といったグラフィックスAPIが,ま たGPU内部の処理ユニットが行う処理を記述するためにGPU向けのアセンブリ言 語やHLSL,GLSL,Cg[39]といった専用の高級言語(シェーダ言語)が用いられて きた.
初期のGPGPUにおけるプログラム作成にはこれら画像描画処理向けのプログラ
ミング環境が利用された.グラフィックスAPIやシェーダ言語は標準化が進んでお り対応GPUも多く,画像描画処理との親和性が高い.そのため画像描画処理向け のプログラミング環境を用いたGPGPUは,現在でも画像描画処理関係のGPGPU プログラミングでは広く用いられている.しかし,画像描画処理向けのプログラミ ング環境を用いて汎用的な演算を記述するには,対象問題を画像描画処理プログラ ミングに対応させる独自のプログラミング手法を習得し利用する必要がある.
2.1 GPUのアーキテクチャとプログラミング環境 11
図 3: 画像描画処理と汎用演算
2.1 GPUのアーキテクチャとプログラミング環境 12
ここでGPGPUプログラミングの例として,画像描画処理を用いた単純な配列の
加算を考える.配列の加算を実現するために必要な処理とその手順は以下の通りで ある.
1. CPU側では,入力データとして用いるための配列を2つと,出力データを格
納するための配列を1つ用意する.
2. GPU側では,入力データを格納するためのテクスチャを2つと,描画結果を
格納するための出力用バッファ (書き込み可能設定を施されたテクスチャ) を 1つ用意する.
3. 入力データ配列に格納されているデータをCPUからGPUへ送信し,GPU上 のテクスチャメモリへ配置する.
4. 描画処理の出力先をフレームバッファ(書き込まれた内容が画面表示に反映さ れるバッファ)から2で用意した出力用バッファへと変更し,テクスチャデー タの読み出しと加算処理が記述されたシェーダプログラムを用いて描画処理を 行う.
5. 出力用バッファの内容をGPUからCPUへ読み出し,出力データ配列に格納 する.
これら一連の処理に対応するOpenGLとGLSLを用いたプログラムの例 (ソース コードの一部抜粋)を図4に示す.このように,GPGPUプログラムを作成するには 対象アプリケーションのアルゴリズムに加えて画像処理のためのプログラミング手 法やGPUアーキテクチャについての知識が必要であり,その上プログラムの記述 量も多く,アプリケーションプログラマにとって大きな負担となってきた.
そこで近年では,画像描画処理向けのプログラミングを必要とせずにGPGPUプ ログラミングを行える新しい言語やライブラリの研究が進められている.例えば米 NVIDIA社のCUDA[40]や米AMD社のCTM[41]およびStream[42]は,GPUベン ダが提供するGPGPU向けのプログラミング環境である.これらのプログラミング 環境を用いることで画像描画処理向けのプログラミング環境と比べて直接的なプロ グラミングが可能となるとともに,GPUのアーキテクチャに適した実装を行うこと で高い性能を得ることが可能となる.
2.1 GPUのアーキテクチャとプログラミング環境 13
// GPUによる処理 (描 画 内 容 の 記 述)
u n i f o r m samplerRECT t e x U n i t 0 , t e x U n i t 1 ; void main (void){
v e c 2 TexA = v e c 2 ( 0 . 0 , 0 . 0 ) ; v e c 2 TexB = v e c 2 ( 0 . 0 , 0 . 0 ) ; TexA . x= g l F r a g C o o r d . x ; TexA . y= g l F r a g C o o r d . y ;
TexB . x= g l F r a g C o o r d . x ; TexB . y= g l F r a g C o o r d . y ;
g l F r a g C o l o r = texRECT ( t e x U n i t 0 , TexA ) + texRECT ( t e x U n i t 1 , TexB ) ; }
// C P Uによる処理 ( G P Uの 制 御 な ど の 記 述)
g l u t I n i t (& a r g c , a r g v ) ; g l u t I n i t W i n d o w S i z e ( 6 4 , 6 4 ) ; // OpenGL初期化 glutCreateWindow ( ‘ ‘ GpgpuArrayAdd ’ ’ ) ; g l e w I n i t ( ) ;
glGenFramebuffersEXT ( 1 , &f b ) ; // T e x t u r eの 生 成 な ど glBindFramebufferEXT (GL FRAMEBUFFER EXT, f b ) ;
g l G e n T e x t u r e s ( 4 , nTexID ) ; g l B i n d T e x t u r e ( opt1 , t e x i d ) ; g l T e x P a r a m e t e r i ( opt1 , GL TEXTURE MIN FILTER , GL NEAREST ) ; g l T e x P a r a m e t e r i ( . . . ) ;
glTexImage2D ( opt1 , 0 , opt2 , w, h , 0 , GL RGBA, GL FLOAT, 0 ) ; glMatrixMode (GL PROJECTION ) ;
g l L o a d I d e n t i t y ( ) ; gluOrtho2D ( 0 . 0 , nTexCX , 0 . 0 , nTexCY ) ; glMatrixMode (GL MODELVIEW ) ;
g l L o a d I d e n t i t y ( ) ; g l V i e w p o r t ( 0 , 0 , nTexCX , nTexCY ) ; glUseProgramObjectARB ( programObject ) ;
g l B i n d T e x t u r e (TEX OPT1, nTexID [ 0 ] ) ; // T e x t u r eへ の デ ー タ セ ッ ト glTexSubImage2D (TEX OPT1, . . . , GL FLOAT, fDataA ) ;
glTexEnvi (GL TEXTURE ENV, GL TEXTURE ENV MODE, GL REPLACE ) ;
glFramebufferTexture2DEXT (GL FRAMEBUFFER EXT, . . . , nTexID [ 2 ] , 0 ) ; g l A c t i v e T e x t u r e (GL TEXTURE0 ) ;
g l B i n d T e x t u r e (TEX OPT1, nTexID [ 0 ] ) ; glUniform1iARB ( t e x U n i t 0 , 0 ) ; g l A c t i v e T e x t u r e (GL TEXTURE1 ) ; glUniform1fARB ( . . . ) ;
g l D r a w B u f f e r (GL COLOR ATTACHMENT0 EXT ) ; // 描 画 処 理
g l B e g i n (GL QUADS ) ; g l T e x C o o r d 2 f ( 0 . 0 , 0 . 0 ) ; g l V e r t e x 2 f ( 0 . 0 , 0 . 0 ) ; g l T e x C o o r d 2 f ( nTexCX , 0 . 0 ) ; g l V e r t e x 2 f ( nTexCX , 0 . 0 ) ;
g l T e x C o o r d 2 f ( nTexCX , nTexCY ) ; g l V e r t e x 2 f ( nTexCX , nTexCY ) ; g l T e x C o o r d 2 f ( 0 . 0 , nTexCY ) ; g l V e r t e x 2 f ( 0 . 0 , nTexCY ) ; glEnd ( ) ; g l R e a d B u f f e r (GL COLOR ATTACHMENT0 EXT ) ; // 結 果 の 取 得
g l R e a d P i x e l s ( 0 , 0 , nTexCX , nTexCY , GL RGBA, GL FLOAT, f D a t a R e s u l t ) ;
図 4: 単純な配列加算プログラムの例 (一部抜粋)
2.1 GPUのアーキテクチャとプログラミング環境 14
しかしながら,GPUのハードウェアアーキテクチャは製品によって異なる部分 も多い.現在GPGPUに利用されている主なGPUとして,NVIDIA社のGeForce・ Quadro・TeslaシリーズとAMD社のRadeon・FireStreamシリーズが挙げられる.
これらのGPUはいずれもGPU上に多数の演算器や複数種類のメモリを搭載するな ど共通の特徴を持ってはいるものの,各演算器の性能やメモリの種類と性能などの 詳細なハードウェア構成は異なっている.さらにCUDAやCTMおよびStreamと いったプログラミング環境は言語仕様や実行モデルがGPUのアーキテクチャと強く 関連しているため,これらのプログラミング環境を利用するユーザはGPUのアー キテクチャについて理解する必要があり,また利用可能なGPUが限られているた め実行環境に合わせてプログラミング環境を習得して利用せねばならない.以上か ら,GPUベンダの提供するプログラミング環境はアプリケーションプログラマに対
してGPGPUプログラミングの難しさや手間を解消できているとは言い難い.
GPUは多くのPCに搭載されており,GPGPUを利用可能な計算機システムは広 く普及していると言える.しかしながらGPGPUプログラムの作成が難しいため多 くのGPUは演算性能を活用されておらず,GPGPUが広く普及し有効に活用され るには,GPGPUプログラムを容易に作成することが可能な仕組みが必要である.
2.2 SIMD型アクセラレータとしてのGPU 15
2.2 SIMD 型アクセラレータとしての GPU
GPU以外にも,既存のCPUと比べてより高い並列度を持ち,理論演算性能や電力 あたり性能が高い新しいハードウェアの開発や普及が進みつつある.特にClearSpeed 社の浮動小数点アクセラレータカード (以下CSX) [43]や,SCEI・東芝・IBMが共 同開発したCell Broadband Engine およびCell Broadband Engineの強化版である IBMのPowerXCell 8i (以下Cell) [44]は,しばしばGPUと対比される.これらの ハードウェアはいずれも,既存のCPUと比べて単純なコアを複数搭載することで演 算性能を高めているため,SIMD (Single Instruction Multiple Data) 処理やMIMD (Multiple Instruction Multiple Data)処理などの並列処理に適しており,また対象ア プリケーションの中でも特に並列度の高い部分を重点的に高速化するアクセラレー タとして利用されている.そのため本論文ではGPUを含めたこれらのハードウェ アを“SIMD型アクセラレータ”と呼び,本節ではSIMD型アクセラレータのハード ウェアアーキテクチャやプログラミング環境について概観する.
なお,各SIMD型アクセラレータの動作周波数や理論演算性能などの基礎的な性 能データとアプリケーションプログラマに対して提供されているプログラミング環 境については,表1の通りである.
表 1: SIMD型アクセラレータの基礎的なデータ
CPU (比較用) GPU CSX Cell
製品モデル Xeon X5482 GeForceGTX280 e720 GigaAccell 180
演算器(コア)数 4 240 192 1(PPU)+8(SPU)
クロック周波数 3.20GHz 602MHz(Core) 250MHz 2.8GHz
1296MHz(SP) (PPU,SPU共通)
搭載メモリ容量 ー 1GB 8GB max 4GB
メモリ帯域幅 12.8GB/s 141.7GB/s 96GB/s 25.6GB/s
最大消費電力 150W 236W 25W 150W
CPUとの接続 ー PCIe x16(Gen2) PCIe x16(Gen1) EIB†
プログラミング環境 ー CUDA Cn C/C++
orシェーダ言語 with専用SDK 理論演算性能(単精度) 51.2GFLOPS 933GFLOPS 96GFLOPS 180GFLOPS 出典 PlatformBrief[45] TechnicalBrief[46] ProductBrief[47] 製品カタログ[48]
†ホストPCとの接続はPCIe x16
2.2 SIMD型アクセラレータとしてのGPU 16
CSX
CSXは,ClearSpeed社が浮動小数点アクセラレータカードとして開発している ClearSpeed Advanceアクセラレータカードであり,PCI-ExpressまたはPCI-X接続 の拡張カードとして提供されているハードウェアである.東京工業大学が所有する スーパーコンピュータTSUBAMEに搭載されているアクセラレータとして知られ ている[5].(ただし実際にTSUBAMEに搭載されているのは表中のe720より1世 代前の製品である.)
CSXは,電力あたりの演算性能が高いことが特徴である.200近い多数の演算器 を低速に動作させることで,低い消費電力と高い演算性能を達成している.
CSXの構成の1つであるe720のハードウェア構成を図5に示す[49, 50, 47].e720 はアクセラレータカード上にアクセラレータチップと大容量メモリ (DRAM) を搭 載しており,アクセラレータチップ上には96の浮動小数点演算ユニットが搭載され たコアが2つ搭載されている.
図 5: CSXのハードウェア構成図
2.2 SIMD型アクセラレータとしてのGPU 17
CSXを利用する方法としては,ベンダによって提供されている並列計算ライブラ リを利用する方法と,CSX用のプログラミング環境を用いてプログラムを作成する 方法とが提供されている.
CSXではベクトル計算や行列計算,FFTなど,典型的な演算に関する並列計算ラ イブラリがベンダによって提供されている.そのためこれらの問題を高速化したい 場合には,CSXのアーキテクチャや実行モデルなどを知らずとも,提供されている ライブラリを利用することで容易に高速化を行うことができる.
一方,アプリケーションプログラマがCSX上で動作するプログラムを作成した い場合には,専用のプログラミング言語であるCn言語[51]を利用する必要がある.
Cn言語はC/C++言語をCSXのメモリモデルにあわせて拡張した言語である.Cn 言語にはpolyとmonoという変数宣言時に利用可能な予約語があり,これらを用い ることでCSX上でのメモリ配置を明示的に指定することができる.さらに,CSX を制御するためのAPIを利用可能にするライブラリが提供されており,これを用い
ることでCPU-CSX間のデータ送受信等を行うことができる.Cn言語を用いたプロ
グラミングにおいては,CPU上で動作するホストプログラムとCSX上で動作する デバイスプログラムを個別のソースコードとして記述し,各々のソースコードから 個別の実行ファイルを生成する.実行時にはCSX上でデバイスプログラムを実行し ておき,CPU上のホストプログラムからデバイスプログラムに対して演算対象デー タの送信や演算結果の取得等を行うという実行の流れとなる.
Cell
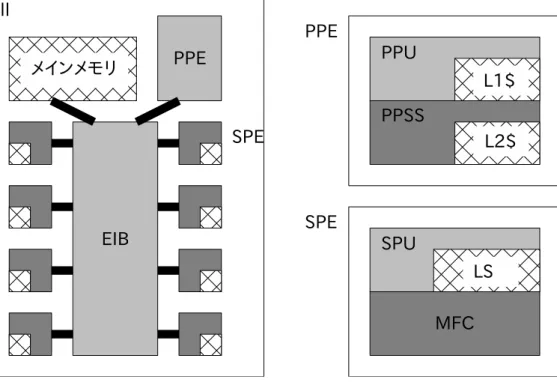
Cellは,SCEI・東芝・IBMが共同開発した,既存のCPUと同程度の機能を持つ制御 用コアPPEと演算専用のより単純なコアSPEを組み合わせたマイクロプロセッサで ある.PLAYSTATION3のプロセッサとしてや,米Los Alamos National Laboratory が所有するスーパーコンピュータRoadrunnerが備えるアクセラレータカードに搭載 されているプロセッサとして[52]知られている.また,SPEのみを搭載したメディ ア処理用のアクセラレータカードSpursEngineとしても利用されている[53].
Cellのハードウェア構成を図6に示す.CellはLSI上に1つのPPEと8つのSPE (PLAYSTATION3では1つが無効化されており7つのSPEが利用可能となってい る),さらにDRAMを搭載している.PPE (PowerPC Processor Element)は,Power
2.2 SIMD型アクセラレータとしてのGPU 18
アーキテクチャを基にした2スレッド同時実行可能なインオーダ型のプロセッサPPU (PowerPC Processor Unit) を核とする,SPEの制御や外部デバイスへの入出力制 御等を受け持つ汎用プロセッサである.SPE (Synergistic Processor Element)は演 算専用のシンプルなプロセッサであり,核となる演算用ユニットSPU (Synergistic Processor Unit),SPUごとのローカルメモリLS (Local Store),メインメモリや他 のSPEとの通信を行うMFC (Memory Flow Controller)から構成されている.PPE とSPEはEIB (Element Interconnect Bus) と呼ばれる高速なリングバスで接続さ れている.こうしたハードウェア構成から,Cellは異なる種類のコアを混載した“ 非対称型マルチコアプロセッサ”の一種であると言える.PPEとSPEをあわせて
200GFLOPS程度の単精度浮動小数点演算性能を持つ.
図 6: Cellのハードウェア構成図
Cellに搭載されたPPEは既存のCPUに近いハードウェアであるため,Linuxな どのOSを動作させることが可能であり,またPPEのみを用いるプログラムであれ ば,既存のPowerPCアーキテクチャCPU向けプログラムと同様に作成し実行する ことができる.しかしながらCellの持つ高い演算性能を得るには,SPEを効果的に 活用できるようにプログラムを作成する必要がある.
2.2 SIMD型アクセラレータとしてのGPU 19
SPEを活用したプログラムを作成するには,C/C++言語と各コアの制御等を行 う専用のライブラリ (SDK) を用いる.CSXと同様に,PPE上で動作するプログラ ムとSPE上で動作するプログラムを個別のソースとして記述し,各々のプログラム から個別の実行ファイルを生成する.実行時にはPPEプログラムからSPEプログ ラムを起動して利用する.
PPEと複数のSPEとの間のデータ転送を考慮したプログラミングの難しさや手間 を削減し,またPPE向けのプログラムとSPE向けのプログラムを個別に記述する手 間を削減するために,Cell向けのコンパイラやライブラリについての研究がいくつか 行われている.IBMのXL C/C++ for Multicore Acceleration for Linux[54]は,マル チコアCPUやCellに対応したコンパイラであり,OpenMPを用いたシングルソー スによるCellプログラム開発も可能となっている.西Barcelona Supercomputing CenterのCell Superscalar (CellSs)[55]も,OpenMPとは異なるが指示子の挿入によ るシングルソースでのCellプログラム開発を可能としている.また電気通信大学で はPOSIXスレッドを用いてシングルソースによるCellプログラム開発を可能とす るプログラム変換ツールを提案している[56].
2.3 プログラミング環境に関する研究の動向 20
2.3 プログラミング環境に関する研究の動向
GPUを用いることにより高い演算性能が得られる一方で,アプリケーションプロ グラマにとってGPGPUプログラミングが難しく手間がかかることは広く認識され ており,これまでにGPGPUプログラミングを容易にするためのプログラミング環 境に関する研究がいくつか行われてきた.またマルチコアCPUが普及し,今後さら に多数のコアを搭載したCPUの普及が見込まれていることから,高い並列性を持 つプログラムの容易な記述に向けた新しい並列化プログラミング環境に関する研究 も行われている.本節ではこれらのプログラミング環境について確認する.
2.3.1 GPU向けのプログラミング環境
GPGPUプログラミングが難しい大きな要因として,ハードウェアアーキテクチャ
への依存性が高い専用の言語やライブラリを用いる必要があることが挙げられる.
ハードウェアアーキテクチャや言語仕様について学習する手間を削減しGPGPUを 容易に利用できるようにするには,ハードウェアアーキテクチャへの依存性が低く 汎用性・抽象度の高いプログラミング環境が必要である.そこで近年では,ハード ウェアアーキテクチャに依存しない新たなプログラミング環境に関する研究がいく つか行われている.これらの研究の中から本項では,ストリームプログラミング言 語,OpenCL,コンピュータビジョンアプリケーション用のプログラミング環境の3 つについて確認する.
ストリームプログラミング言語
ストリームプログラミング言語とは,“「ストリーム(stream)と呼ばれる入力デー タ」に対して「カーネル(kernel)と呼ばれる演算操作」を作用するものとみなすス トリーミングモデル” (図7)に基づく処理 (ストリーム処理)を記述するためのプロ グラミング言語である.近年,GPUに適しておりGPGPUによる高速化が期待で きる問題としてストリーム処理が注目されており,GPU向けストリームプログラミ ング言語の研究が行われている.以下にストリームプログラミング言語の例をいく つか挙げる.
米Stanford UniversityのBrookGPU [57] は,既存のC言語を元に拡張を加えた 言語仕様といくつかのライブラリ関数を提供するオープンソースのストリーミング
2.3 プログラミング環境に関する研究の動向 21
図 7: ストリーミング言語の概念
言語である.BrookGPUを用いたプログラムの例を図8に示す.この例では,GPU 上で実行される並列計算部 (カーネル) が関数として独立に記述されていることや,
カーネルの実行前後でstreamReadおよびstreamWriteという関数を用いて明示的 に入出力の指定が行われていることが確認できる.図中のカーネルでは2つの変数 を加算してもう1つの変数への代入を行っているが,各変数は配列であり,配列の 各要素に対する演算がGPU上の多数の演算器によって独立に並列処理される.
BrookGPUはカーネルを実行するバックエンドとしてDirectX9,OpenGL,CPU,
CTMに対応している.AMD社がBrookGPUを元にして自社のGPU向けのストリー ミング言語Brook+[58]を開発しているが,これはBrookGPUのCTMをバックエ ンドとした実装をベースにしていると考えられる.
加RAPIDMIND社のRapidMind[59]は,加University of Waterlooで開発された オープンソースのメタプログラミング言語Sh[60]を元にしたストリーミング言語で ある.RapidMindを用いたプログラムの例を図9に示す.RapidMindもBrookGPU と同様にカーネルとカーネルへの入出力を明示的に指定していることが確認できる 一方で,BrookGPUによるカーネルの記述が既存のC/C++言語における関数の記 述に似た形式で行われていたのに対して,RapidMindによるカーネルの記述はより 独特な記述によって行われていることがわかる.
RapidMindの特徴として,実行環境としてCPUやGPUだけではなくCellにも 対応している点が挙げられる.そのため単一の言語を用いてCPU・GPU・Cell向け のプログラムを記述可能であり,アプリケーションプログラマにとっては実行環境 ごとにプログラミング言語を習得し直すという大きな手間が削減できると言える.
東北大学のSPRAT[61]は,実行時環境に特徴があるストリーミング言語である.
本研究のアプローチ1 (3章) で述べているように,GPGPUにおいては対象問題の
2.3 プログラミング環境に関する研究の動向 22
// カ ー ネ ル
k e r n e l void k f u n c (f l o a t x<>, f l o a t y<>, out f l o a t z<>){ z = x + y ;
}
i n t main ( ){ f l o a t a<100>;
f l o a t b<100>;
f l o a t c<100>;
// 入 力 ス ト リ ー ム の 指 定 streamRead ( a , d a t a 1 ) ; streamRead ( b , d a t a 2 ) ;
// カ ー ネ ル の 実 行 k f u n c ( a , b ) ;
// 出 力 ス ト リ ー ム の 指 定 s t r e a m W r i t e ( c , r e s u l t ) ; return 0 ;
}
図 8: BrookGPUを用いたプログラムの例
2.3 プログラミング環境に関する研究の動向 23
i n t main ( ){ // カ ー ネ ル
Program k f u n c=BEGIN{ In<V a l u e 3 f>x , y ; Out<V a l u e 3 f>z ; z = x + y ; }END;
// 入 出 力 ス ト リ ー ム の 指 定 Array<1 , V a l u e 3 f>a ( 5 1 2 ) ; Array<1 , V a l u e 3 f>b ( 5 1 2 ) ; Array<1 , V a l u e 3 f>c ( 5 1 2 ) ;
// カ ー ネ ル の 実 行 c = k f u n c ( a , b ) ; return 0 ;
}
図 9: RapidMindを用いたプログラムの例
計算量や並列度と,CPUとGPUの性能バランスによって,対象問題をCPUで実 行した方が高い性能が得られる場合とGPUで実行した方が高い性能が得られる場 合とがある.SPRATの実行時環境はカーネルをCPUとGPUのどちらで実行した 方がより高い性能が得られるかを性能モデルや実測値から判断し,より高い性能が 得られるハードウェアを選択して実行するという機構を有している.SPRATのプ ログラム記述方法はBrookGPUに近いものとなっている (図10).
OpenCL
OpenCL Working Groupが策定を行っているOpenCL[62]は,C言語をベースと した並列処理向けのプログラミング環境である.OpenCLはGPUだけではなくや マルチコアCPU,Cell,DSP (Digital Signal Processor)など様々なハードウェアに おける並列処理を統一的に記述可能とすることを目指している.
OpenCLは新しいプログラミング環境であり本論文執筆時点では対応するハード
ウェアがまだ存在していないが,主なGPUベンダであるNVIDIA社とAMD社が それぞれCUDAとStreamによるOpenCLへの対応を表明している.そのためアプ
2.3 プログラミング環境に関する研究の動向 24
// カ ー ネ ル
k e r n e l k f u n c ( i n stream<f l o a t> x , i n stream<f l o a t> y , out stream<f l o a t> z ){
z = x + y ; }
i n t main ( ){
stream<f l o a t> s a ( 1 0 0 ) , sb ( 1 0 0 ) , s c ( 1 0 0 ) ; f l o a t a [ 1 0 0 ] , b [ 1 0 0 ] , c [ 1 0 0 ] ;
// 入 力 ス ト リ ー ム の 指 定 i n i t a r r a y ( a , b ) ; streamRead ( sa , a ) ; streamRead ( sb , b ) ;
// カ ー ネ ル の 実 行 k f u n c ( sa , sb , s c ) ;
// 出 力 ス ト リ ー ム の 指 定 s t r e a m W r i t e ( s c , c ) ; return 0 ;
}
図 10: SPRATを用いたプログラムの例
2.3 プログラミング環境に関する研究の動向 25
リケーションプログラマはOpenCLを用いることにより様々なGPU向けのプログ ラムをC言語に近い単一のプログラム記述によって行うことが可能となり,習得や 利用の手間と難しさが削減されることが期待できる.
コンピュータビジョンアプリケーション用のプログラミング環境
GPUの用途の1つとして,コンピュータビジョンアプリケーションにおける新 たな表現手法の実装や高速化[63] が挙げられる.この分野のアプリケーションは GPU本来の処理である画像描画に関する処理を多く含むが,処理内容が高度化して いるため,汎用演算と同様に習得や実装の手間や難しさが問題となっている.そこ で,コンピュータビジョンアプリケーションの開発を支援するシステムの研究開発 が行われている.研究開発されたシステムの例としては,北陸先端技術大学院大学 のEasyGPU[64]や,加University of TorontoのOpenVIDIA[65],仏University of LyonのGPUCV[66]などが挙げられる.いずれのシステムも,フィルタ処理などコ ンピュータビジョンアプリケーションで利用される処理を容易に記述可能とするこ とで,アプリケーションプログラマに対するGPUプログラミングの習得や利用の 手間と難しさの削減を可能としている.
2.3.2 CPU向けのプログラミング環境
近年ではマルチコアCPUの普及やマルチコアCPUに搭載されるコア数の増加
(メニーコア化) が進んでいる.そのためマルチコアCPU上で高い性能を得られる
プログラムの作成方法や,マルチコアCPUに適したプログラムを容易に作成する ためのプログラミング環境に関する研究が盛んに行われている.
マルチコアCPU向けの並列化プログラミング環境に関する研究の例は多く存在 するが,特に,計算機を提供するベンダーが策定や提供に影響力を持つ言語(IBM のX10[67],CrayのChapel[68],SunのFortress[69]) や広く普及している既存のプ ログラミング言語に対する拡張仕様など(C言語に対するUnified Parallel C[70]や,
Fortranに対するHigh Performance Fortran[71]やCo-Array Fortran[72])は他の言語 と比べると多くの利用者を獲得し今後の並列化プログラミングにおける主流となる 可能性が高く,また並列化プログラミングのトレンドに影響を及ぼす可能性がある.
例えば,これらのマルチコアCPU向け並列化プログラミング環境のいくつかは,
スレッドとメモリとの対応付けをアプリケーションプログラマが明示的に記述する
2.3 プログラミング環境に関する研究の動向 26
Partitioned Global Address Space (PGAS)モデルを採用している.PGASモデルを 採用したプログラミング環境では,変数や配列などのデータに対して,そのデータ をスレッド (プロセス)ごとに独立して持つものとして扱うべきか,スレッド間で共 有して持つものとして扱うかを,コンパイラに対する指示子や専用の変数宣言を用 いて指定する.これらの指定により,アプリケーションプログラマはデータの分散 配置や通信を容易に指示することが可能となり,またコンパイラや実行時環境によ る高度な最適化も可能となることが期待されている.
さらに,メモリの分散配置を記述するプログラミング環境としては,共有メモリ 型並列計算機向けのプログラミング環境であるOpenMPに対してメモリの分散配置 に関する記述が行えるように拡張を行ったOpenMPD[73]なども挙げられる.
一方,対象問題の持つ並列性を容易に記述するための並列化プログラミング環境 についての研究も行われている.
スケルトン並列プログラミングは,並列スケルトンと呼ばれる並列処理における 頻出計算パターンを抽象化したライブラリ関数の組み合わせによる並列化プログラ ミング手法である.スケルトン並列プログラミングの利点としては,アプリケーショ ンプログラマに対して低レベルの並列化実装を隠蔽することが可能であり,並列計 算の知識を持たなくても高性能な並列処理プログラムを作成できることなどが挙げ られている[74].スケルトン並列プログラミング環境の例としては,東京大学の助っ 人 (SkeTo) [75]などが挙げられる.
配列の各要素に対する処理や繰り返し処理を記述しやすい言語仕様を持つ並列化 プログラミング環境に関する研究も行われている.近年の研究例としては,東芝社 の配列切り出し演算子を備えた配列処理向け言語[76]等が挙げられる.これらのプ ログラミング環境の利点としては,ループ記述を行うことなく繰り返し処理を表現 できるため多重ループ処理の可読性が高いことや,最適化に用いる情報を抽出しや すく抽象度の高い言語仕様としているため最適化が行いやすいことなどが挙げられ ている.