1.は じ め に
本 稿 で は, 人 工 神 経 回 路 網(Artificial Neural Network:ANN)を中心的対象とするアクセラレー タ(計算加速装置)の展望を述べる.神経回路網をター ゲットとする専用の回路システム研究─ Neuromorphic computing─には長い歴史がある [Mead 90].特に神経 の特性が比較的単純な微分方程式で表すことができ,同 質なものの集積であることから,アナログコンピュータ を用いた実装が多く行われてきた.これらは基本的に実 際の神経回路網を摸倣したモデルのシミュレーションを 行うことが主たる目的で開発されている [Dias 04, Liao 01, Misra 10]. 一方,人工神経回路網を対象にする専用計算システ ムについても,非ノイマン型の並列情報処理のモデル としての重要性から“Parallel Distributed Processing” などのキーワードのもとに追求されてきた [Rumelhart 86].一時は汎用計算システムの高性能化もあって下火 になったが,近年再度注目を集めつつある.その理由は 主として以下の二点である.第一に,深層学習(Deep Learning)の発展により,大規模な人工神経回路網に 対する計算需要が高まってきていることがある.それ以 前は,大規模な ANN は学習が困難なためその利用が進 んでいなかった.小規模あるいはアルゴリズムの研究段 階であればわざわざ専用回路を構築する必要はなく,汎 用計算機で計算すればよい.このため,大規模化の需要 はこれまで脳のシミュレーションのほうが中心であった が,最近ではこれが逆転して ANN のほうが大規模化・ 高速化の要求が高まっている.第二の要因としては,半 導体の性能向上の鈍化がある.半導体の性能は,永らく Mooreの法則に従って向上してきた.計算機の性能も この恩恵を受け,およそ 5 年で 10 倍のペースで成長を 続けてきた.しかし,近年では微細加工技術が進展した としても,CMOS デバイスの特性から電源電圧を 0.8 V 近辺からさらに下げるのが難しく,消費電力が性能の上 限を決める大きな要因になっている.またこれと関連す るが,半導体の動作周波数を 3 GHz 近辺から上げるこ とが難しく,その分の性能向上を並列化によって補うよ うになってきたことがある.例えば京コンピュータでは 全体のコア数が 64 万にも及ぶが,こうした高い並列度 を性能向上に結び付けるのは容易ではない.こうした背 景から,一部の計算のみを,それを得意とするアクセラ レータで実行する複合的な計算システムが,特に科学 技術計算を中心に一般化しつつある.これは著者らが専 用計算機で始めた計算モデルであるが [Makino 98, Taiji 88],近年では汎用画像処理プロセッサ(General-Purpose Graphical Processing Unit:GPGPU)などで頻繁に利 用されるようになった. 神経回路網も,こうした専用化による加速・省電力化 の可能性が大きい.例えばまず計算精度を落とすことで 電力を削減できる.また,人工神経回路はそもそも並列 情報処理の代表的なモデルとしても発展してきたもので もあり [Rumelhart 86],並列性の活用は得意である.並 列処理の活用では GPGPU や Intel メニーコアプロセッ サの応用も進んでいるが,専用化によりさらなる性能向 上が期待できる. ハードウェアの観点から神経回路網のモデルを考える と,脳のシミュレーションで中心的に用いられる積分発 火モデルと ANN で用いられる発火率モデルでは実装が 異なってくる.前者では,ニューロン(計算ノード)か ら低頻度で生じるスパイクを,発生したときだけ効率良 く他のニューロンに伝えるネットワークが重要である. 後者では,各ニューロンからの出力は基本的に毎ステッ プ伝達することになるので,より汎用の並列システムに 近い構成となる. 以下では,まず積分発火モデル向けのアクセラレータ を簡単に概観した後,ここ数年急速に研究開発が進んで きた発火率モデルベースの ANN 向けの専用加速装置に ついて中心的に紹介する.また,ディジタルかアナログ かという点では,近年開発が進んでいるディジタル回路 を用いたハードウェアアクセラレータについて中心的に 述べる.著者はアナログ計算については,実際の脳のシ ミュレーションには有効かもしれないが,ANN 向けに人工神経回路網のためのアクセラレータ
Accelerators for Artificial Neural Network
泰地 真弘人
理化学研究所 生命システム研究センターMakoto Taiji RIKEN QBiC-Quantitative Biology Center. [email protected]
Keywords:
artificial neural network, neuromorphic computing, special-purpose computer, accelerator, FPGA. 「脳神経系シミュレーション」はあまり有効ではないのではないかと考えている.複数 のアルゴリズムに対応できる汎用性が低くなること,動 作周波数・実装効率が低く,特に ANN のような単純化 されたニューロンの場合には,ディジタル回路に比べて 速度的・電力的なメリットがないこと,ANN で用いら れるさまざまな学習方法を実装することの難しさが主た る理由である.ただし一部アナログ的な動作を取り込む ことは有効かもしれない.
2.積分発火モデル向けアクセラレータ
2・1 IBM TrueNorth まず積分発火モデルに基づく神経回路向けのアクセラ レータの代表選手として,IBM が開発した TrueNorth について避けて通るわけにはいかない [Merolla 11, Merolla 14].TrueNorth は他のアプローチに比べて少 し特別で,スパイクニューロンの特定のモデル(離散化 された Integrate and Fire モデル)を高速に扱うことが できる専用度の高いプロセッサである.具体的には V(t+1)=V(t)i -Li+ Aj × × j (t) Wji Si G j の形の式の計算をディジタル回路で高速に行う.A(t) は {0, 1} のスパイク入力,Wjiは {0, 1} の結合,Liはリー ク,SiGjはシナプス結合係数(Gjは 3 種までのシナプス 結合の種別を表すインデックス),V(t)≧ 0 は膜電位に 相当するもので,V(t)がしきい値を超えると発火して スパイクを出す. TrueNorthでは,それぞれ 256 個のシナプス結合入 力をもつニューロン 256 個を 1 コアとし,その中ではク ロスバ接続により高速に演算を行う.このコアを 4 096 個集積し,コア間をオンチップネットワークで接続する ことで 100 万ニューロンを実現したものが TrueNorth チップである. TrueNorthで行える計算は上述の形に限られているた め,これだけでは学習ができない.そのため,別の計算 機でオフライン計算を行ってその結果として得られたも のを計算している.このため,ANN でしばしば問題に なる学習過程の計算量は解決できず,利用目的としては 画像処理などを行う装置にこのチップを埋め込んで使う ことになる. そうすると,TrueNorth のポイントはその消費電力に なり,論文でもそこが強調されている.400×240 ピク セル,30 フレーム / 秒のカラー動画の画像認識処理での 消費電力は 63 mW と小さい.シナプスイベント当たり の消費エネルギーは 26 pJ となっている.同等の 28 nm プロセスでつくられた NVIDIA 社の GPU Kepler K40 は単精度 4.3 TFLOPS(TFLOPS は 1 秒当たり 1 兆演 算を行う性能,FLOP は 1 浮動小数点演算に相当)で 235 Wであるから,1 FLOP 当たりの消費電力は 55 pJ となる.上記のシナプスイベントを少し多めに 10 演算 に相当すると考えると,その差は 21 倍となり思ったよ り小さい. 上記の電力見積もりでは,ニューロン当たりのスパ イク発生頻度は平均 20 Hz としている.1 ニューロンの 処理が 256 kHz ということなので,これを基準にする と動作率は 0.1%以下になる.TrueNorth の意義として は,スパイクニューロンを用いてイベント駆動的に動作 させることで,低い稼働率でも高い電力効率が得られる ことを示したのが重要な点である.一方,脳のモデルと してはともかく,実際の問題を解くのに必要なニューロ ン数・イベント数はモデルに依存するので,TrueNorth のニューロン数と ANN 向けプロセッサの Processor Element(PE)数は直接比較できない.なお,論文中 で汎用機より 176 000 倍良い電力効率というのは,汎 用機で TrueNorth の論理エミュレーションを行った場 合と比べてということなので,意味がない.同じ課題 を最適化して実行した条件で比べるべきであろう.な お,制限付きボルツマンマシン(Restricted Boltzmann Machine:RBM),果てはサポートベクタマシンまでが TrueNorth上で同じアルゴリズムで動作すると書いてあ るが,論文では詳しく議論されていない. 2・2 SpiNNakerSpiNNaker(Spiking Neural Network Architecture) は Human Brain Project の一環としてマンチェスター 大学で開発を進めている計算機である [Furber 14].ス パイクニューロンのシミュレーションをターゲットにし たディジタルシステムであるが,TrueNorth より汎用的 なアプローチで脳回路のシミュレーションを行うことを 目指している. このために英 ARM 社の開発した軽量の汎用プロセッ サコア ARM9(200 MHz,整数演算のみ.速度は違うが, Nintendo DSでも使われている)を 18 個と,専用のネッ トワークを乗せたプロセッサを開発した.汎用プロセッ サベースでプログラム可能なので,さまざまなモデルに 対応できる.SpiNNaker の特徴はネットワークにあり, 二次元の三角格子ネットワーク上で,マルチキャスト通 信によりスパイク情報を効率良く伝達する.48 チップ を乗せたボード 1 枚で 25 万ニューロン・ 8 000 万シナ プスを「実時間」で計算できる. 2・3 HICANN HICANNはハイデルベルグ大学で開発が進められ ているアナログ─ディジタル混合のシステムであり,こ ちらも Human Brain Project で開発が進められている [Schemmel 10].主要素はアナログ回路で組まれてお り,Exponential Integrate and Fire モデルを「連続時
間で」積分し,実際の神経回路の動作速度に比べ 103∼ 5
倍の速度で動作する.シナプス可塑性についても,短 期的シナプス抑圧(STD)・スパイクタイミング依存性
シナプス可塑性(STDP)が回路として実装されてい る.アナログ回路なので実装密度は低く,1 チップ当た り 512 ニューロン,ニューロン当たりのシナプス数は 224である.通常の LSI 製造では大きな半導体ウェーハ から小さな LSI を切り出して良品だけを用いるが,不良 箇所があってもよい場合は大きなウェーハをそのまま使 うこともできる.HICANN では 20 cm のウェーハをそ のまま利用して,ウェーハ上で LSI 間の接続を行うこと で,配線の問題を緩和しつつニューロン数を増やしてい る.1 ウェーハ上には 352 個のチップが載っているので, 1ウェーハ当たり 18 万ニューロン,4 000 万シナプスが 実現できる.
このほか,Cambridge 大学の FPGA(Field Program-mable Gate Array,書換え可能なゲートアレー)ベース のマシン Bluehive [Moore 12],Stanford 大学のアナロ グ─ディジタル混合の Neurogrid [Benjamin 14] なども 開発されている.
3.発火率モデル向けアクセラレータ
本章では,発火率モデルに基づく ANN 向けの加速装 置開発の現状について述べる.この分野は特に近年日進 月歩で開発が進んでいる.まず専用化にあたって一つの キーポイントになる計算精度について議論し,その後 FPGAを用いたシステム・LSI を用いたシステムについ て概観する. 3・1 計 算 精 度 ANNの場合,出力関数にシグモイド関数やステップ 関数などを用い,入力の情報量を 0/1 に近い形に落とす ため,計算精度を下げても問題ないと考えられる.計算 精度は,ハードウェアの性能に大きなインパクトをもつ. 精度が倍になると,乗算器の大きさはおよそ 4 倍,加算 器は倍になる.また,数値表現も重要な要素である.特 に浮動小数点加算器は,固定小数点の場合に比べ倍以上 の大きさと遅延を有する.これらのことから,ANN に どの程度の計算精度が要求されるのかの研究が行われて いる. 前述の TrueNorth では,スパイクニューロンという こともあるが,入力は 1 ビット,シナプス強度などは 9 ビット整数で実装しており,非常に精度が低い [Merolla 11]. 誤差逆伝搬法など,学習を行うことを前提とするとも う少し精度が必要になる.多くの研究があるが,だいた い固定小数点では 16 ∼ 20 ビット程度で十分との結果が 得られている [Holi 93, Savich 07].ここでは近年いくつ か論文が発表され始めている深層学習(Deep Learning) での精度評価について紹介する.中国国防科学技術大学 の Jiang らは MNIST の文字認識課題をさまざまな演算 精度での深層学習で実行した際の認識率を評価し,19 ビット(6 ビット整数部+13 ビット小数部)でよいとの 結論を得た [Jiang 14].また IBM の Gupta らは確率的 数値丸め付きの固定小数点を使って,同じ課題に対し深 層学習を行い,16 ビット固定小数点と 32 ビット浮動小 数点はほぼ同じ性能であることを示した [Gupta 15].モ ントリオール工科大学の Courbaniaux らは複数の問題 を複数のフォーマットで扱い,また伝搬・微係数に関す るパラメータとその他で精度を変える混合精度計算の評 価を行っている [Courbariaux 14].結果として,浮動小 数点では半精度(16bit)でよいこと,また特殊なフォー マットとして動的な固定小数点の評価を行い,この場合 伝搬・微係数については 10 ビット,その他 12 ビットで 十分なことを示した.これらはいずれもハードウェアア クセラレータの可能性を示す結果である.今後さらに大 きな問題に対する評価,混合精度の詳細な解析などを行 う必要があるだろう. 3・2 FPGA を用いた実装 FPGAの特徴は,回路を自由に書き換えられ,開発コ ストが安い(代わりに単価は高い)こと,動作速度・回 路規模は専用 LSI に比べて劣ることである.FPGA は その開発当初から専用計算システムへの応用が研究され てきた.特に神経回路網の計算は上述のように精度が 低くても済み,計算手法もまだ変動があるので,FPGA を用いた評価に向いており,これまでも多くの開発が なされてきた [Omondi 06].さらに近年では,深層学 習の発展により,実用的なシステムの開発に向けた取 組みが進んでいる.アナログ回路向けの FPAA(Field Programmable Analog Array)もあるが,まだ NN に適 応できるようなものではないので,以下はすべてディジ タル実装になる. アプローチとしては,特に画像処理などでの適用例 が多い畳込みニューラルネットワーク(Convolutional Neural Network:CNN)について多くの検討がなされ ている.画像処理ではリアルタイム性が要求され,ハー ドウェア化の利点が大きいこともある.FPGA では,任 意のネットワークを問題ごとに生成することもできるの だが,小規模な NN ならともかく大規模な NN の計算を 繰返し計算で行うという場合には一々再構成するわけに もいかない.CNN では入力数に制限のあるネットワー クを繰り返し使えばよいので,実装が考えやすい(逆に 全結合の場合には,始めから繰返しベースで設計できる ので,そちらも設計指針は立てやすい). CNNの FPGA に よ る 実 装 は ニ ュ ー ヨ ー ク 大 学 の LeCunグループの Farabet らが開発した CNP(ConvNet Processor)に始まる [Farabet 09].ローエンドの FPGA Xilinx Spartan-3を使いながら,512×384 ピクセルの 白黒画像での顔認識を 10 フレーム / 秒で実行し,その 実用性を実証した.CNP ではオンチップネットワーク 上でデータフローに沿った計算を行うことができ,柔軟な処理を行える.NEC の Cadambi らは,FPGA(Xilinx Virtex-5 SX240T)上に実装した 512 ユニットのプロセッ サ MAPLE 上で CNN を動かし,GPU(NVIDIA Tesla C870)の 1.4 倍の性能を報告した [Cadambi 10].
Purdue大学の Gokhale らは,モバイル機器のプロセッ
サをターゲットとした CNN による画像処理向けのアー キテクチャ nn-X の検討を行っている.Xilinx の Zynq (ARM Cortex-A9 コア入りの FPGA)を利用し CNN 向 けの畳込みエンジン・出力関数・max-pooling 用の回路を 並列にネットワークで接続し,240 Gops(ops は演算 / 秒) 相当の性能を実現した.電力性能は 55 Gops/W 以上で あり,GPU・CPU に比べ約 10 倍である.
Ovtcharovら [Ovtcharov 15] は,Microsoft が 検 索 エンジン Bing の加速に使用している FPGA システム Catapult(FPGA は Altera Stratix V D5)を使用して
CNNのベンチマークを行い,GPGPU Tesla K40 に比 べ約 1/4 ∼ 1/6 の性能,1.5 ∼ 2.5 倍の電力性能を報告し ている. このほか北京大学・UCLA の Zhang らによる,CNN 実装の最適化研究も興味深い [Zhang 15].CNN 以外に も,制限ボルツマンマシンの実装 [Kim 14],再帰ニュー ラルネットの実装 [Li 15] などが行われている. こ れ ら の FPGA は さ ら に 大 規 模 化 で き る の で, GPGPUと同等かそれ以上の性能でより高い電力性能 が実現可能である(ただし,コスト面の問題はある). 今後 Intel などのプロセッサメーカから,汎用 CPU と FPGAを密接に組み合わせたシステムの商品化が検討さ れており,FPGA ベースのシステムをより簡易に利用で きるようになると思われる.性能的には GPU と同等程 度であるので,小規模の開発には向かないかもしれない が,その電力効率の高さから大規模な利用においてはメ リットがあるだろう. 3・3 専用 LSI を用いた実装 FPGAには長所も多いが,精度などアーキテクチャ上 の工夫で汎用機に比べ性能を 10 倍にできても,通常の LSIとの性能の開きは大きい.数百 MHz での動作がやっ とであり,半導体面積当たりの回路規模も 1/10 程度で ある.GHz 帯で動作する GPGPU を大きく超えるには, やはり専用の LSI が必要である.前述の SpiNNaker や TrueNorthもこのような例であるが,ここでは特に深 層学習に対応した計画について述べる.こちらも基本は ディジタル回路に基づく実装がほとんどである.
LeCunグループの Pham らは,前述した FPGA ベー
スの CNP を拡張し,メニーコアプロセッサ neuFlow を 開発した [Pham 12].NN 向けの演算命令・演算ユニッ トをもつプロセッサをオンチップネットワークで接続 し,データフローグラフに沿った処理を行う.現在の 実装は試験的なもので,チップ面積は 12.5 mm2(IBM 45 nm SOI)とまだ小さい.4 個の畳込み演算器を備 えたコア 100 個をもち,400 MHz で動作する.ピーク 性能は 320 Gops,消費電力は 0.6 W なので,ピーク電 力性能は 490 Gops/W になる.これで GPU(NVIDIA GTX480)と同等の実効性能を約 1/360 の消費電力で実 現している.同アーキテクチャを FPGA に実装した場 合との比較では,性能で倍,電力性能で 22 倍である. これはシミュレーション上の値ではあるが,レイアウト を行ったうえでの評価であるので精度は高いと考えられ る.この延長線で考えると,TrueNorth より汎用性が高 いうえに,性能的にもより有望であろう. 変わり種としては,テネシー大学の Lu らによるアナ ログ回路を用いたアプローチで深層学習を行うプロセッ サがある [Lu 15] .これはまだ研究的な要素が強く,回 路上の工夫により学習も可能にしている点が興味深い. 電力性能としては 1 Tops/W の性能を達成している. KAISTの Park らは,深層学習向けのプロセッサ K-Brainを開発した [Park 15].こちらは 8 並列 /24 並 列の SIMD 型ユニットをもつなど,かなり処理単位の 大きな複合型コアを並列につないだものである(現在の 論文からはまだ詳細な使い方不明).また推論用に独自 のコアをもっており,物理乱数発生による確率的 Leaky Integrate and Fireモデルの計算を行える.200 MHz で 動作し,411.3 Gops の性能を 0.21 W で達成している. ピーク電力性能は 1.93 Tops/W である.画像認識に適用 した結果は GPU(機種不明)の 1.3 倍の速度となって いる. チューリッヒ工科大学の Cavigelli らは,CNN 向けの プロセッサ“Origami”を開発した [Cavigelli 15].より 現実的な高解像画像処理の実現に向け,入力帯域の削減 などの工夫を行っている.これもまだテスト実装の段階 で 3 mm2(UMC 65 nm CMOS)と小さなチップである が,実効性能で 203 Gops,電力性能で 369 Gops/W の 性能を実現している.このほかにも中国科学院で開発さ れている DianNao シリーズ [Liu 15] などがある. 以上の LSI・FPGA での実装結果をまとめたものが以 下の表 1 である.研究段階の技術と GPU などの実用レ ベルのものは本来単純に比較できない点には注意すべき である.上記で見たように,現在はまだ LSI による深層 学習の実装はトライアルレベルであるが,今後より実用 的なシステムの開発が続くと期待される.
4.今 後 の 展 望
今後さらに人工神経回路網を用いた人工知能技術が発 展するにつれ,そのためのハードウェア加速の研究・開 発は加速するものと思われる.著者らも ANN の加速を 主な目的に据えた「脳型コンピュータ」の提案を行って いる.著者らはこれまで粒子シミュレーション専用計算 機 GRAPE シリーズ,FPGA を用いたおそらく世界で ほぼ最初の再構成可能な専用計算機 m-TIS II(イジングモデルのモンテカルロシミュレーション専用計算機だ が,ボルツマンマシンにも拡張可能)などを開発してき た.基本的な考え方は LeCun らのマシンなどと大きく 変わるものではないが,汎用性の高い低精度コアに乱数 発生器・多入力の加算器・出力関数などの専用回路群を 接続したユニットをオンチップネットワークで並列化さ せる.アプリケーションを考えるうえでは,ネットワー クの構成が最も重要な要素になるだろう. 今後特に重要なのは,さらなる低消費電力化に向け, エラー許容型のハードウェアを実装することである. ディジタル回路は,通常トランジスタがオンになるしき い値電圧(0.4 ∼ 0.7 V 程度)以上で動作させる.しか し,しきい値電圧以下でも全く電流が流れないわけでは ない.現在,さらなる低消費電力を実現するために,し きい値電圧以下の「サブスレッショルド領域」で動作さ せる半導体の研究が進んでいる.残念ながら動作速度自 体も大きく低下してしまうが,消費電力を電源電圧に 対し指数関数的に減らすことができるので,特に組込み 用途や自律システムなどで有効である.研究レベルでは Intelから 0.28 V で動作可能な IA32 互換プロセッサが 発表されている [Gregory 13].サブスレッショルド領域 では,ソフトエラーの多発や素子ばらつきの影響の大き さなどが重要な問題となる.しかし,ANN ではこれら の問題はそれほど深刻ではなく,エラーがあっても問題 なく進められることが期待される.そもそも人間の脳は エラーを前提に動作していると考えられるし,素子の特 性ばらつきについても,学習過程で素子の特性を含めた 学習を行えば問題がないと期待される.こうしたエラー の存在下での ANN の動作についてはまだ端緒についた ところであるが,研究結果がすでに出始めている. イリノイ大学の Deka は,MNIST 課題の RBM によ る学習をターゲットに,学習後の重みに人為的にエラー を注入してその影響を調べた [Deka 13].結果として,1 標準偏差の大きさのエラーであれば 10 ∼ 20%のエラー があっても結果は変わらず,10 標準偏差のエラーでも 1%のエラーが許容できることが示唆された.また,第 1層では,エラーの場所が検出できるなら,エラー箇所 の値を周囲のノード値の平均に置き換えることで 20 ∼ 30%の 1 標準偏差エラーまで許容できることを示した. 本研究はまだ追求すべきことも多く,例えば計算プロセ ス全体へのエラーの導入,ディジタル誤差の特性の考慮 などが必要であるし,エラー訂正手法についても今後さ らに検討が求められる.また多値論理の利用など一部ア ナログ的な動作も検討の余地がある. このような低電圧動作が可能になれば,LSI の消費電 力は 1 W 近くに抑えることができると期待される.現在 の汎用プロセッサはその発熱量から三次元積層実装が難 しいが,消費電力が小さければ三次元積層を利用し,脳 のような結合を達成できる.半導体素子は,その速度や 集積度においては十分に脳で使われている神経の性能を 上回るはずである.アルゴリズム・ソフトウェアの進歩 と相まって,これらの技術進化の先に,脳レベルの情報 処理を脳と同等の 20 W で実装できる可能性は高く,そ の実現に向けた努力が求められる.
◇ 参 考 文 献 ◇
[Benjamin 14] Benjamin, B. V., Gao, P., McQuinn, E., Choudhary, S., Chandrasekaran, A. R., Bussat, J-M., Alvarez-Icaza, R., Arthur, J. V., Merolla, P. and Boahen, K.: Neurogrid: A mixed-analog-digital multichip system for large-scale neural simulations, Proc. IEEE, Vol. 102, No. 5, pp. 699-716(2014) [Cadambi 10] Cadambi, S., Majumdar, A., Becchi, M.,
Chakradhar, S. and Graf, H. P.: A programmable parallel accelerator for learning and classification, Proc. 19th Int. Conf.
on Parallel Architectures and Compilation Techniques, pp.
273-284, ACM(2010)
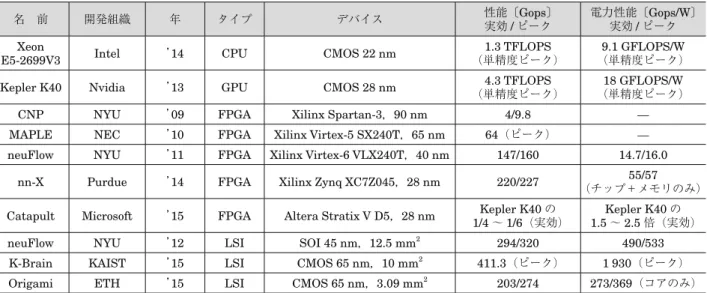
[Cavigelli 15] Cavigelli, L., Gschwend, D., Mayer, C., Willi, S., Muheim, B. and Benini, L.: Origami: A convolutional network 表 1 FPGA・LSI による ANN 向けアクセラレータの現状のまとめ.
比較のため,汎用 CPU・汎用 GPU のピーク性能も提示している.演算量について,積和演算が整数では 1 命令(op),浮動小数 点では 2 演算(FLOP)に換算される点に注意
名 前 開発組織 年 タイプ デバイス 性能〔Gops〕実効 / ピーク 電力性能〔Gops/W〕実効 / ピーク Xeon
E5-2699V3 Intel ’14 CPU CMOS 22 nm (単精度ピーク)1.3 TFLOPS (単精度ピーク)9.1 GFLOPS/W Kepler K40 Nvidia ’13 GPU CMOS 28 nm (単精度ピーク)4.3 TFLOPS (単精度ピーク)18 GFLOPS/W
CNP NYU ’09 FPGA Xilinx Spartan-3,90 nm 4/9.8 ̶ MAPLE NEC ’10 FPGA Xilinx Virtex-5 SX240T,65 nm 64(ピーク) ̶ neuFlow NYU ’11 FPGA Xilinx Virtex-6 VLX240T,40 nm 147/160 14.7/16.0
nn-X Purdue ’14 FPGA Xilinx Zynq XC7Z045,28 nm 220/227 (チップ+メモリのみ)55/57 Catapult Microsoft ’15 FPGA Altera Stratix V D5,28 nm 1/4Kepler K40∼ 1/6(実効)の 1.5Kepler K40∼ 2.5 倍(実効)の neuFlow NYU ’12 LSI SOI 45 nm,12.5 mm2 294/320 490/533
K-Brain KAIST ’15 LSI CMOS 65 nm,10 mm2 411.3(ピーク) 1 930(ピーク)
accelerator, Proc. 25th edition on Great Lakes Symp. on VLSI, pp. 199-204, ACM(2015)
[Courbariaux 14] Courbariaux, M., Bengio, Y. and David, J-P.: Low precision arithmetic for deep learning, arXiv preprint, arXiv:1412.7024(2014)
[Deka 13] Deka, B.: Towards a Low Power Hardware Accelerator for Deep Neural Networks, https://courses.engr. illinois.edu/ece544na/fa2013/writeups/deka.pdf (2013)
[Dias 04] Dias, F. M., Antunes, A. and Mota, A. M.: Artificial neural networks: A review of commercial hardware,
Engineering Applications of Artificial Intelligence, Vol. 17, No.
8, pp. 945-952(2004)
[Farabet 09] Farabet, C., Poulet, C., Han, J. Y. and LeCun, Y.: Cnp: An fpga-based processor for convolutional networks,
Proc. Int. Conf. on Field Programmable Logic and Applications
(FPL), pp. 32-37, IEEE(2009)
[Furber 14] Furber, S. B., Galluppi, F., Temple, S. and Plana, L.: The spinnaker project, Proc. IEEE, Vo. 102, No. 5, pp. 652-665 (2014)
[Gregory 13] Gregory, R., Saurabh, D., Shailendra, J., Surhud, K. and Sriram, R. V.: IA-32 processor with a wide-voltage-operating range in 32-nm CMOS, IEEE Micro, Vol. 33, No. 2, pp. 28-36(2013)
[Gupta 15] Gupta, S., Agrawal, A., Gopalakrishnan, K. and Narayanan, P.: Deep learning with limited numerical precision, Proc. 32nd Int. Conf. on Machine Learning, Lille, France, JMLR Workshop and Conf. Proc.(2015)
[Holi 93] Holi, J. L. and Hwang, J-N.: Finite precision error analysis of neural network hardware implementations, IEEE
Trans. on Computers, Vol. 42, No. 3, pp. 281-290(1993)
[Jiang 14] Jiang, J., Hu, R., Mikel, L. and Dou, Y.: Accuracy evaluation of deep belief networks with fixed-point arithmetic,
Computer Modelling & New Technologies, Vol. 6, pp. 7-14
(2014)
[Kim 14] Kim, L-W., Asaad, S. and Linsker, R.: A fully pipelined FPGA architecture of a factored restricted boltzmann machine artificial neural network, ACM Trans. on Reconfigurable
Technology and Systems(TRETS), Vol. 7, No. 1, Article 5
(2014)
[Li 15] Li, S., Wu, C., Li, H. H., Li, B., Wang, Y. and Qiu, Q.: FPGA acceleration of recurrent neural network based language model, Proc. 23rd IEEE Int. Symp. on Field-Programmable
Custom Computing Machines, Vancouver, Canada, IEEE
(2015)
[Liao 01] Liao, Y.: Neural networks in hardware: A survey, http://dator8.info/2010/32.pdf(2001)
[Liu 15] Liu, D., Chen, T., Liu, S., Zhou, J., Zhou, S., Teman, O., Feng, X., Zhou, X. and Chen, Y.: Pudiannao: A polyvalent machine learning accelerator, Proc. 20th Int. Conf. on
Architectural Support for Programming Languages and
Operating Systems, pp. 369-381, ACM(2015)
[Lu 15] Lu, J., Young, S., Arel, I. and Holleman, J.: A1 TOPS/W analog deep machine-learning engine with floating-gate storage in 0.13 µm CMOS, IEEE J. Solid-State Circuits, Vol. 50, No. 1, pp. 270-281(2015)
[Makino 98] Makino, J. and Taiji, M.: Scientific Simulations with
Special-Purpose Computers: The GRAPE Systems, Chichester;
New York, Wiley(1998)
[Mead 90] Mead, C.: Neuromorphic electronic systems, Proc.
IEEE, Vol. 78, No. 10, pp. 1629-1636(1990)
[Merolla 11] Merolla, P., Arthur, J., Akopyan, F., Imam, N., Manohar, R. and Modha, D. S.: A digital neurosynaptic core using embedded crossbar memory with 45 pJ per spike in 45 nm, Proc. Custom Integrated Circuits Conf.(CICC),pp. 1-4, IEEE(2011)
[Merolla 14] Merolla, P. A., Arthur, J. V., Alvarez-Icaza, R., Cassidy, A. S., Sawada, J., Akopyan, F., Jackson, B. L., Imam, N., Guo, C. and Nakamura, Y.: A million spiking-neuron integrated circuit with a scalable communication network and interface, Science, Vol. 345, No. 6197, pp. 668-673(2014) [Misra 10] Misra, J. and Saha, I.: Artificial neural networks
in hardware: A survey of two decades of progress,
Neurocomputing, Vol. 74, No. 1, pp. 239-255(2010)
[Moore 12] Moore, S. W., Fox, P. J., Marsh, S. J. T. and Mujumdar, A.: Bluehive-a field-programable custom computing machine for extreme-scale real-time neural network simulation, Proc.
20th Annual Int. Symp. on Field-Programmable Custom
Computing Machines(FCCM), pp. 133-140, IEEE(2012)
[Omondi 06] Omondi, A. R. and Rajapakse, J. C.: FPGA
Implementations of Neural Networks, Springer(2006)
[Park 15] Park, S., Bong, K., Shin, D., Lee, J., Choi, S. and Yoo, H-J.: A1.93 TOPS/W scalable deep learning/inference processor with tetra-parallel MIMD architecture for big-data applications, IEEE Int. Solid-State Circuits Conference (ISSCC),Digest of Technical Papers, pp. 80-82, IEEE(2015) [Pham 12] Pham, P-H., Jelaca, D., Farabet, C., Martini, B., LeCun, Y. and Culurciello, E.: NeuFlow: Dataflow vision processing system-on-a-chip, Proc. 55th Int. Midwest Symp. on
Circuits and Systems(MWSCAS), pp. 1044-1047, IEEE(2012)
[Rumelhart 86] Rumelhart, D. E., McClelland, J. L. and Group PDPR: Parallel Distributed Processing, Vols. 1 and 2, Cambridge, MA: The MIT Press(1986)
[Savich 07] Savich, A.W., Moussa, M. and Areibi, S.: The impact of arithmetic representation on implementing MLP-BP on FPGAs: A study, IEEE Trans. on Neural Networks, Vol. 18, No. 1, pp. 240-252(2007)
[Schemmel 10] Schemmel, J., Bruderle, D., Grubl, A., Hock, M., Meier, K. and Millner, S.: A wafer-scale neuromorphic hardware system for large-scale neural modeling, Proc. IEEE
Int. Symp. on Circuits and Systems(ISCAS), pp. 1947-1950,
IEEE(2010)
[Taiji 88] Taiji, M., Ito, N. and Suzuki, M.: Special purpose computer-system for ising-models, Review of Scientific
Instruments, Vol. 59, No. 11, pp. 2483-2487(1988)
[Zhang 15] Zhang, C., Li, P., Sun, G., Guan, Y., Xiao, B. and Cong, J.: Optimizing FPGA-based accelerator design for deep convolutional neural networks, Proc. 2015 ACM/SIGDA Int.
Symp. on Field-Programmable Gate Arrays, pp. 161-170, ACM
(2015) 2015年 6 月 29 日 受理