問題の解き直しの学業成績への効果
——
階層線形モデルによるビッグデータの分析
——
菱
山
完
∗,伊
藤
徹 郎
∗∗,岡 田
謙 介
∗The Effect of Re-solving Questions to Academic Achievement: Analysis of Big Educational Data Using Hierarchical Linear Models
Kan Hishiyama∗, Tetsuro Ito∗∗and Kensuke Okada∗
Iterative learning of simple assignments such as memorization of letters and words have shown to improve students’ test scores of the learned assignments. Meanwhile, existing studies have mixed results as to whether simple repetitive learning improve the general academic performance or not. Using educational big data collected from more than four hundred thousand high-school students thorough crowd system, the current study investigated the effect of re-solving questions to the general academic achieve-ment. Although descriptive statistics have not revealed steady tendencies, the results of hierarchical linear models that controlled for heterogeneity of schools, grades and individuals showed consistent positive effects of iterative learning towards general aca-demic performance. The results suggest the importance of iterative learning, as well as controlling for the heterogeneity in large-scale educational dataset.
Key words: Re-solving, big data, hierarchical linear model
キーワード:解き直し,ビッグデータ,階層線形モデル 1. 目 的 復習は,学習した知識やスキルの定着を図るための 重要な方法と考えられる.その効果については,古く はEbbinghaus (1913)のよく知られた忘却曲線の研 究をはじめ,多くの定量的な研究がなされてきた.例 えば,Gay (1973)は米国の中学生120人に代数と幾 何の公式を学習させ,その後の異なる時点で復習を行 わせた実験群3群と,復習を行わなかった統制群1群 ∗東京大学
(The University of Tokyo)
連絡先:〒113–0033 東京都文京区本郷 7–3–1 E-mail:[email protected] 注) 菱山完の現所属は株式会社コンピュータマインドで ある. ∗∗Classi 株式会社 (Classi Corp.) 連絡先:〒163–0415 東京都新宿区西新宿 2–1–1 新宿 三井ビルディング 14 階 の間で,提示した公式を利用する問題の得点を比較し た.その結果,復習を行った群ではいずれも,復習を していない群よりも高い平均テスト得点が得られた. 本研究では復習の方法の中でも,同じ問題を繰り返 し解き直すことの効果について主眼をおく.寺澤・吉 田・太田(2008) および寺澤(2016) は,英単語や漢 字といった反復して記憶に定着させることが有効と考 えられる学習課題について,記憶学習の反復回数が英 単語や漢字のテスト成績にどのような影響を与えるか を,15名の高校生のデータを用いて実証的に検討し た.その結果,1日に1回から4回までの反復学習は, 回数に比例して英単語等のテスト成績を向上させた. こうした結果から,英単語や漢字のような比較的単純 な記憶のメカニズムによって説明できる学習に関して は,反復の効果が示されていると考えられる. その一方で,反復学習が単純に実力テストで測られ るような一般の学業成績を向上させるとは言えない可 能性の指摘も,先行研究ではなされている.例えば, 堀野・市川(1997) は高校生250人に対し,英語の学
習方法についての質問を行い,教員の協力によって収 集された中間テスト成績とあわせて分析した.その結 果,単語間の関連を意識する体制化方略は学業成績に 対して有意な正の回帰係数を示していたものの,繰り 返しの学習を重視する反復学習方略の学業成績に対す る有意な効果は見られなかった.また,松沼(2009) は106名の高校生を対象とした調査データのパス解析 に基づき,出題範囲が限定されるテストには暗記方略 の効果が見られても,より広い範囲から出題される実 力テストには暗記の有意な効果は見られず,より深い 意味理解を伴う学習が求められることを報告した.こ うした研究からは,単なる反復学習そのものというよ りも,もしくはそのもの以上に,反復して学習に取り 組む過程において学習内容が体制化され,精緻化され ることの重要性が示唆されている. しかしながら,上述の堀野・市川(1997) や松沼 (2009) をはじめとする従来のわが国の教育心理学の 先行研究は,その多くが数十人から数百人規模の比較 的少人数のデータに基づいている.したがって,復習 が実力テストで測られるような一般的な学力に与える 効果が小さくても確固として見られるものであった場 合,サンプルサイズの小ささによりその効果を検出で きていない可能性がある. 現代においてはコンピューターやスマートフォンを 活用した学習システムが多く提供されており,個人の 学習状況に関してもそれらのシステムに蓄積された ビッグデータを活用することで,より多くの情報が得 られると考えられる.そこで本研究では,解き直す行 為にのみに着目し,近年わが国で導入が進んでいるク ラウド型学習サービスの数十万件におよぶビッグデー タを用いて,復習の効果を検討することを目的とした. 2. 方 法 2.1. データ 本研究では,2019年5月時点において全国2,500 を超える多数の高等学校に導入されている,Classi株 式会社が提供する学校向けICT教育プラットフォー ムの生徒による利用状況データにおける問題の解き直 し行動と,民間企業が進学に向けた学力を測定するた めに実施している全国有数規模の模擬試験模成績との 関連を検討した. 前者のデータについて,本研究で分析に利用したの は,ICTを利用した生徒の学習支援のためのアプリ ケーション・クラウドサービスのWebテストの学習 履歴である.Webテストは,ある単元や章が終わる ごとに,教員によって生徒に配信され,生徒がそれ をWebで解いて復習のために利用することができた. システム上にはどの生徒がいつ,どの問題を解いたか が記録された.こうした仕組みのため,単元や章の学 習が終わり,教師によって配信されるまでは当該の問 題を解くことはできないものの,一度課されれば何度 でも解き直すことができた.また後者のデータについ ては,本研究では実力テストに類する学力を測定する 変数として,年に3回高校生を対象に実施されている, 学習到達度を測る全国規模の模擬試験(模試)の成績 を分析対象とした.本研究で分析に用いた模試データ は2017年の春から2018年の春までの間に高校1, 2 年生を対象に実施された,計3回分であった.また, Webテストの利用履歴データも,模試の時期と対応す る形で,2017年春から2018年春までのものを使用し た.両者のデータは個人IDによって紐づけられ,分 析対象となった.分析の対象となった生徒は,我が国 の高校生のうち,分析対象時期に学習支援サービスが 導入され,模試を受験する高校の対象学年に属してい た,全国711校の427,588人,706,179件のデータで あった.分析対象内の各学年ごとの時期内の受験人数 を表1に示した.なお,学年および時期の詳細な定義 については次節を参照してほしい. 2.2. 分析に用いた変数 本研究において用いた変数は以下の通りである. 模試得点 模試得点は本研究における目的変数で ある.個人情報保護の観点から素点の提供は許可 されなかったため,試験の実施企業より提供を受 けることができた,模試の総合得点を標準化した 上で1から15までの15段階に区分された変数 を分析に使用した.この変数は正規分布に近い分 布形状をしており,連続変数として扱われた. 表 1. 学年および時期ごとの分析対象人数 時期 学年 17 春 17 秋 18 春 1 0 0 141,161 2 141,955 85,576 133,395 3 131,744 72,348 0
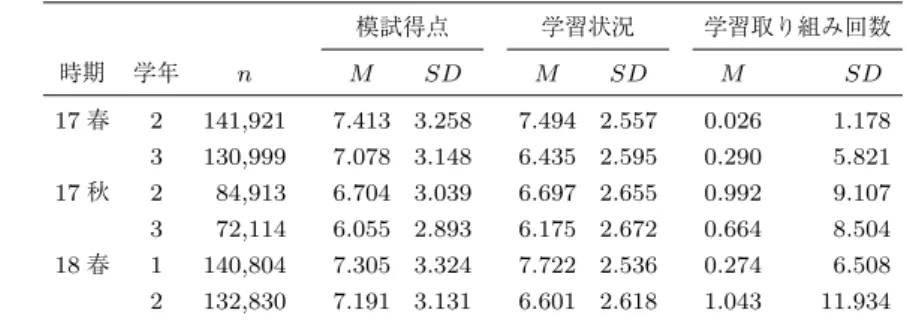
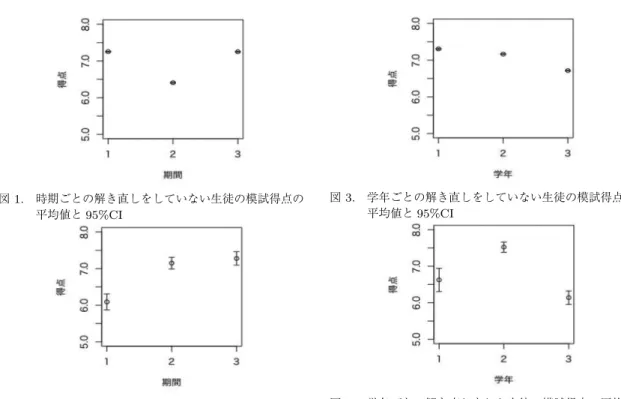
学習状況 学習状況は,模試と同時に測定され た,生徒の毎日の自主学習や授業への取り組みな どについて尺度化し測定した変数であり,値が高 くなるほど積極的に学習に取り組んでいることを 表す.この変数も模試の得点と同様に,得点を偏 差値化したうえで1から15までの15段階に区分 した上で,連続変数として扱い分析に使用した. 所属する学校 生徒の所属する学校を表す変数で ある.先述のとおり711水準からなるカテゴリカ ル変数であった. 個人ID 生徒個人を識別する変数である.先述 のとおり427,588水準からなるカテゴリカル変数 であった. 時期 模試が実施された時期を表すカテゴリカル 変数である.今回分析で使用した模試のデータは 2017年春(17春),2017年秋(17秋),2018年 春(18春)の3回分(3カテゴリ)であった.模 試の日時は各校の事情によって学校ごとに異なっ ており,春の模試は2月から6月,秋の模試は7 月から1月までの時期に実施された.そのため, 表1に明らかなように,学年1の生徒は高校入学 以前である17春と17秋の模試は受験していな い.また,学年3の生徒は17春と17秋のみ受 験した. 学年 生徒の学年を表すカテゴリカル変数であ る.この変数は2018年度時点での学年を表して おり,例えば2017年度に1年生だった生徒の学 年は学年“2”のカテゴリ,2018年度に1年生だっ た生徒の学年は学年“1”のカテゴリのようにダ ミー変数によってコーディングした. 学習取り組み回数 学習取り組み回数は,ある生 徒が1つの時期内にWebテストに取り組んだ回 数を示す計数変数である.学習意欲や学力を反映 する変数である可能性が考えられることから,本 研究では共変量としてモデルに投入した. 解き直しの有無 解き直しの有無は,ある生徒が 1つの時期内にWebテストで同一の問題を複数 回解いたか否かを示す2値変数であり,本研究の モデルにおける説明変数である.模試が実施され てから,次の模試が行われるまでの時期に同一の 問題を2回以上解いていた場合は“1”,そうでな い場合は“0” とコーディングした.本変数と学 習取り組み回数を比較すると,学習取り組み回数 には学校から課題として課せられて解いた問題数 が含まれており,必ずしも主体的な学習状況を反 映していない.一方,解き直しの有無は同一問題 を複数回解いたか否かで判定される変数であり, 一般的に課題として同一問題を複数回課すことは ない.そのため,解き直しの有無は,生徒が主体 的に問題を解き直すことを反映した変数と考えら れる. 2.3. 分析計画 本研究では,1変数の記述統計量(平均・標準偏差) および2変数間の記述統計量(順位相関係数)を確認 したのち,異質性を考慮するために学校および個人に よって2層から3層に階層化された階層線形モデル を用いて,解き直しの有無の模試得点への効果を検討 した.階層線形モデルはいずれも模試得点を目的変数 とした.学校および個人変数は階層化にのみ使用し, 説明変数・共変量としては投入しなかった.それ以外 の学習状況,時期,学年,学習取り組み回数はすべて のモデルにおいて共変量として投入した.モデルの階 層化について,2階層モデルでは,学校によって階層 化を行ったモデルと,個人によって階層化したモデル を検討した.同様に,3階層モデルでは学校と個人に よる階層化を行った.この3通りの各階層モデルに おいて,まず説明変数を含まず切片だけからなるnull モデルでの推定を行い,次に説明変数を投入したモデ ルでの推定を行った.解き直しの有無の効果は学校に よって異なることが想定されたため,上記モデルのう ち学校での階層化を行ったモデルにおいてはランダム 切片モデルとランダム係数モデルを推定し,個人のみ で階層化を行ったモデルにおいてはランダム切片モデ ルのみ推定した.さらに各モデルにおいてAICおよ びBICを算出し,これら情報量規準を用いてモデル の当てはまりを比較した.分析にはR version 3.5.1 (R Core Team, 2018)とそのパッケージを使用した. 3. 結 果 3.1. 1変数の記述統計量 表2に解き直しをしていない生徒,表3に解き直し をした生徒の,それぞれ期間および学年ごとの人数と 模試得点,学習状況,学習取り組み回数の平均値と標 準偏差を示した.人数に関しては,解き直しをした生 徒に比べ解き直しをしていない生徒のほうが,はるか に多いことがわかる.今回分析で取り扱ったWebテ
表 2. 解き直しをしていない生徒の時期および学年ごとの模試得点,学習状況,学習取り組み回数の 平均値および標準偏差 模試得点 学習状況 学習取り組み回数 時期 学年 n M SD M SD M SD 17 春 2 141,921 7.413 3.258 7.494 2.557 0.026 1.178 3 130,999 7.078 3.148 6.435 2.595 0.290 5.821 17 秋 2 84,913 6.704 3.039 6.697 2.655 0.992 9.107 3 72,114 6.055 2.893 6.175 2.672 0.664 8.504 18 春 1 140,804 7.305 3.324 7.722 2.536 0.274 6.508 2 132,830 7.191 3.131 6.601 2.618 1.043 11.934 表 3. 解き直しをした生徒の時期および学年ごとの模試得点,学習状況,学習取り組み回数の平均値 および標準偏差 模試得点 学習状況 学習取り組み回数 時期 学年 n M SD M SD M SD 17 春 2 34 7.971 3.672 7.265 2.767 62.118 57.251 3 745 6.005 3.043 5.668 2.561 767.145 833.086 17 秋 2 663 7.356 2.407 6.412 2.501 339.293 176.719 3 234 6.564 2.430 6.436 2.565 79.017 62.752 18 春 1 357 6.625 3.067 6.852 2.731 626.888 474.191 2 565 7.688 2.593 6.703 2.611 269.467 154.840 ストは授業の復習として教師が配信するものであった ため,課題として課されることもあった.そのため, 課題として課されれば一度は解くものの,それ以降に 自主的に解き直すことはしない生徒が多数を占めてい たと考えられる.また,模試得点と学習状況に関して は,解き直しをしなかった生徒とした生徒のいずれか のほうが高いといった傾向は見られず,学年と期間に よって異なっていた.さらに,学習取り組み回数の観 点からは,解き直しをしなかった生徒はWebテスト に取り組む回数がかなり少なく,また解き直しをした 生徒でも標準偏差が大きいなど,本データセット上の 学習取り組み回数には大きな個人差が見られた. 図1と図2には学年について周辺化した,解き直 しをしていない生徒とした生徒の時期ごとの平均値と 95%信頼区間(Confidence Interval, CI)をそれぞれ 示した.また,図3と図4には時期について周辺化し た上で,それぞれ解き直しをしていない生徒とした生 徒の学年ごとの平均値と95%CIを示した.学年につ いて周辺化し時期ごとに比較した場合も,17春では 解き直しをしなかった生徒のほうが平均値が高いもの の,17秋では解き直しをした生徒のほうが高く,18 春ではほぼ同点であった.サンプルサイズの大きさの ために95%CIの幅は狭いものの,一貫した関係は見 られず,共変量を考慮しない単純な分析においては解 き直しの効果は一貫しないものであった.時期につい て周辺化し,学年ごとに比較した場合においても同様 であり,学年1では解き直しをした生徒のほうが得点 は低いものの,学年2と3では解き直しをした生徒の ほうがわずかに高かった. 3.2. 変数間の相関 表4に,学校と個人IDを除いた6変数間のスピア マンの順位相関係数rs を示した.これらの中では, 時期と学年の相関rs=−.6301,学習取り組み回数と 解き直しの有無の相関rs= .5067の2つが比較的大 きな相関であった.学年1は17春および17秋に参 加しておらず,学年3は18春に参加していない.ま た,学習取り組み回数と解き直しの有無は同じWeb テストの回答データから作成しており,解き直しの有 無が1の生徒は学習取り組み回数が必ず2以上であ る.高い相関はこうしたこうしたデザイン上の理由に よるものと考えられる.
図 1. 時期ごとの解き直しをしていない生徒の模試得点の 平均値と 95%CI 図 2. 時期ごとの解き直しをした生徒の模試得点の平均値 と 95%CI さらに,模試得点と学習状況の間にはrs = .3065 と中程度の相関が見られた.模試得点と学習状況は同 じタイミングで測定された変数だったため,相関が高 かった可能性がある.上述以外の相関は総じて小さな 値であった.本研究が主眼を置いている解き直しの有 無に関しても,上述の学習取り組み回数以外との相関 はいずれも低い値であり,模試得点と解き直しの有無 の相関に関してもrs =−.0048 とほぼ無相関であっ た.このように,共変量を考慮しない記述統計レベル では,解き直しの効果が見られるとは言えなかった. 表 4. 2 変数間のスピアマンの順位相関係数 1 2 3 4 5 6 1 模試得点 - .3065 −.0005 −.0691 −.0172 −.0048 2 学習状況 - .0339 −.1782 −.0221 −.0149 3 時期 - −.6301 .0225 .0020 4 学年 - −.0221 −.0149 5 学習取り組み回数 - .5067 6 解き直しの有無 -図 3. 学年ごとの解き直しをしていない生徒の模試得点の 平均値と 95%CI 図 4. 学年ごとの解き直しをした生徒の模試得点の平均値 と 95%CI しかし,これは学校や学年の違いといった,異質性の 原因となる変数を分析上適切に考慮していないためで ある可能性が考えられる.そこで次節では,こうした 異質性を考慮できる階層線形モデルによる分析を行っ た結果を報告する. 3.3. 階層線形モデルによる分析 表5に階層化を行わない線形モデル,表 6に学校 で階層化した2階層モデル,表7に個人で階層化した 2階層モデル,表8に3階層モデルによる分析結果を
示した.なお,偏回帰係数はすべて標準化解である. 分析はパッケージlme4 (Bates, Mächler, Bolker, &
Walker, 2015)を用いて行った. 分析の結果,異質性と共変量を考慮したことによ り,前節で述べた単純な分析とは異なる傾向が見出さ れた.まず,階層化を行わない線形モデルでは,解き 直しの有無の偏回帰係数はβ = 0.2390であり,学習 状況に次いで大きかった.しかし,AIC,BICの情 報量規準の観点からは,階層モデルのほうがより支持 された.階層モデルにおいては,いずれの場合におい ても変数投入モデルがnullモデルよりも情報量規準 の観点から支持された.解き直しの有無の偏回帰係数 は,学校階層モデルにおいてはランダム切片モデルで β = 0.2479,ランダム係数モデルでβ = 0.2525,個 人階層モデルではβ = 0.0848,3階層モデルにおいて はランダム切片モデルでβ = 0.1143,ランダム係数 モデルでβ = 0.1040と,検討した各モデルにおいて 一貫して正の効果を示した.また,AIC,BICのいず れの情報量規準においても,階層が増えるにしたがっ てモデルの適合度が向上しており,本データにおいて 異質性を考慮することが適当かつ重要であると解釈で きる. 表 6. 学校で階層化した 2 階層モデルの推定結果 null モデル 変数投入モデル ランダム切片モデル ランダム係数モデル 説明変数 β SE β SE β SE 切片 −0.0194 0.0276 −0.0610 0.0263 −0.0592 0.0263 学習状況 0.1891 0.0009 0.1889 0.0009 17 秋 −0.0193 0.0024 −0.0198 0.0024 18 春 −0.0009 0.0026 −0.0014 0.0026 学年 2 0.0626 0.0028 0.0619 0.0028 学年 3 0.0215 0.0036 0.0206 0.0036 学習取り組み回数 −0.0062 0.0012 0.0120 0.0021 解き直しの有無 0.2479 0.0194 0.2525 0.0924 学校切片分散 0.5404 0.4813 0.4814 学校係数分散 0.1757 残差分散 0.5248 0.4920 0.4918 AIC 1,536,969 1,491,891 1,491,604 BIC 1,537,003 1,492,006 1,491,741 表 5. 線形モデルの推定結果 説明変数 β SE 切片 −0.0226 0.0043 学習状況 0.3061 0.0012 17 秋 −0.2053 0.0030 18 春 0.0060 0.0035 学年 2 0.0967 0.0037 学年 3 0.0551 0.0047 学習取り組み回数 −0.0215 0.0015 解き直しの有無 0.2390 0.0244 残差分散 0.8948 AIC 1,904,245 BIC 1,904,348 4. 考 察 本研究では,Webテストの学習履歴と模試成績を紐 づけた全国規模の大規模データを用いて,解き直しの 学業成績への効果について検討した.異質性を考慮し ない単純な記述統計では,2変数間に関連は見られな かった.しかし,学校などの異質性を考慮した階層線 形モデルでの分析では,いずれのモデルにおいても, 解き直しの有無は一貫して正の効果を示した.こうし
表 7. 個人で階層化した 2 階層モデルの推定結果 null モデル 変数投入モデル 説明変数 β SE β SE 切片 0.0355 0.0015 0.0403 0.0030 学習状況 0.1750 0.0010 17 秋 −0.0541 0.0013 18 春 −0.0174 0.0014 学年 2 0.0402 0.0037 学年 3 −0.0316 0.0040 学習取り組み回数 −0.0034 0.0008 解き直しの有無 0.0848 0.0133 個人切片分散 0.8965 0.8158 残差分散 0.0602 0.0606 AIC 1,603,252 1,565,753 BIC 1,603,286 1,565,867 表 8. 3 階層モデルの推定結果 null モデル 変数投入モデル ランダム切片モデル ランダム係数モデル 説明変数 β SE β SE β SE 切片 −0.0267 0.0277 −0.0259 0.0266 −0.0253 0.0266 学習状況 0.1413 0.0008 0.1412 0.0008 17 秋 −0.0336 0.0013 −0.0336 0.0013 18 春 −0.0203 0.0014 −0.0203 0.0014 学年 2 0.0321 0.0027 0.0318 0.0027 学年 3 −0.0217 0.0031 −0.0223 0.0031 学習取り組み回数 −0.0010 0.0008 0.0020 0.0015 解き直しの有無 0.1143 0.0128 0.1040 0.0423 学校切片分散 0.5432 0.4977 0.4978 学校係数分散 0.1309 個人切片分散 0.3903 0.3632 0.3630 残差分散 0.0678 0.0672 0.0672 AIC 1,300,545 1,269,271 1,269,153 BIC 1,300,591 1,269,397 1,269,302 た結果の相違が見られた理由としては,学校や個人な ど,異質性の要因となる変数を分析上考慮することの 重要性によるものと考えられる.単純な記述統計にお いては学校などの違いが考慮されていなかったが,階 層線形モデルではそれらの変数による異質性をラン ダム切片の形でモデルに導入し,階層化に用いた.解 き直しが学業成績に与える効果は,集団全体で単一と いうよりも,学校や個人に依存してばらつきがあると するほうが自然な設定だと考えられる.学校の異質性 を考慮した階層線形モデルでは,階層性の設定によら ず,一貫して解き直しの正の効果が得られていた.こ うしたことから,異質性を考慮した階層線形モデルに 基づく,解き直しによる学力への正の効果は妥当なも のと考えられる.
本研究では,問題の解き直しが学力に正の効果を与 えると考えられることを,異質性の原因となる変数を 考慮したビッグデータの分析によって示した.しかし ながら,本研究にはいくつかの限界も指摘できる. 第一に,本稿冒頭で紹介した教育心理学の先行研究 は,いずれも研究対象を英単語学習や漢字学習に絞 り,記憶のメカニズムを前提とした,反復学習とし ての解き直しの効果を主たる検討対象としたもので あった.それに対して本研究では,ICT教育プラット フォーム上の多数の問題について,科目や内容による 制約を設けることなく解き直しの効果を検討した.こ の両者は,どちらも同じ問題を繰り返し解き直すとい う点で共通性しており,また制限を設けずに解き直し の効果を示した本研究には意義があると考えられる. 一方で,各問題を解く上で求められる認知的処理や負 荷が,本研究と先行研究で同じとは必ずしも言えない ため,今後のより精緻な検討が望まれる. 第二に,本研究で学業成績の指標として利用できた 模試の得点は,模試の総合得点を標準化し,15段階 に分けた総合学力の指標であった.問題の解き直しが 学業成績に与える影響は教科ごとに異なることが考え られるが,本研究で用いた指標ではそういった教科ご との違いは明らかにできていない.教科ごとに考える と,より大きな効果が見られた可能性がある.また, 素点を標準化したうえで15段階に分けたことによっ て,情報の損失が起こっているため,素点を分析する ことによって,より大きな効果が検出できる可能性が ある. 第三に,これは第一の点とも関連するが,分析に含 めた共変量数が少なかったことが挙げられる.問題の 解き直しと学業成績の関連を考えたとき,交絡する変 数が無数にあると思われるが,本研究では入手できた 変数を可能な限り分析に含めて検討したものの,すべ ての交絡変数の要因を統制しきれたとは言い難い.利 用できる共変量が多ければ,Rubinの統計的因果推論 (Rubin, 1974)のような統計的手法を用いて,より強 固な結果を導き出せた可能性もある.今後は生徒の家 庭環境や学校の授業に関する情報などを分析に含める ことで,より実態に即した解き直しの効果を明らかに することが望まれる. 利益相反の開示 本研究はClassi株式会社の共同研究費による助成 を受けた.伊藤はClassi株式会社に所属する. 参 考 文 献
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67, 1–48. Ebbinghaus, H. (1913). Memory: A contribution to
experimental psychology (H. A. Ruger & C. E. Bussenius, Trans.).: Teachers College Press.
Gay, L. R. (1973). Temporal position of reviews and its effect on the retention of mathematical rules.
Journal of Educational Psychology, 64, 171–182.
堀野緑・市川伸一 (1997). 高校生の英語学習における学 習動機と学習方略教育心理学研究, 45, 140–147. R Core Team (2018). R: A Language and
Environ-ment for Statistical Computing., R Foundation
for Statistical Computing Vienna, Austria. Rubin, D. B. (1974). Estimating causal effects of
treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66, 688–701. 寺澤孝文 (2016). 教育ビッグデータから有意義な情報を 見いだす方法, 教育システム情報学会誌, 33, 67–83. 寺澤孝文・吉田哲也・太田信夫 (2008). 英単語学習にお ける自覚できない学習段階の検出, 教育心理学研究, 56, 510–522. 松沼光泰 (2009). 英語の定期テスト高成績者が実力テス トで成績が振るわないのはなぜか?, 心理学研究, 80, 9–16. (2020 年 4 月 8 日受理,2020 年 8 月 3 日採択) (この間審査 3 回・審査期間合計 73 日)