推薦論文● SPA2005
値間依存性に基づくポイントカット記述のための
バイトコード変換
大根田 裕一 増原 英彦 米澤 明憲
AspectJ における新しいポイントカット dflow の実現のための Java バイトコード変換を提案する.dflow とは,値 間の動的な依存関係を特定できるポイントカットである.dflow ポイントカットを使うことで,ポイントカット中の 変数が指す値の間の依存関係の有無によってアドバイスの実行を制御できる.本変換は,AspectJ コンパイラが生 成した Java バイトコードに対し,値間の依存関係を動的に記録する命令を追加する.本変換はまず静的に変数間の 依存性を解析し,その解析結果を用いることで必要最低限の命令を追加する.そのため,解析を行わない単純な変換 手法よりもオーバーヘッドの小さいバイトコードを生成できる.dflow ポイントカットの使用例に基づいてバイト コードを変換し,変換後コードのオーバーヘッドを測定した結果,本変換の有用性を確認できた.
We present a Java bytecode translation scheme for implementing dflow pointcut, which is an extension of aspect-oriented language AspectJ. With dflow pointcut, the programmer can concisely specify join points based on data dependency. Our translation inserts bytecode instructions into bytecode generated by the AspectJ compiler in order to keep track of dependency between values at runtime. By using a static anal-ysis on data dependency, our scheme inserts instructions for the dependencies that can not statically be predicted. Therefore, our translation can generate less overhead in output code than a naive translation method that doesn’t use any static analysis would do. Our experiments, which compared overheads between the code translated by our scheme and by a naive scheme, demonstrated the effectiveness of our scheme.
1 はじめに
近年アスペクト指向プログラミング[5]が広まりつ つある.アスペクト指向プログラミングとは,複数 のモジュールにまたがってしまう処理をアスペクトと いう単位でモジュール化するプログラミングである. そのための代表的な処理系として,Javaを拡張した AspectJ[4]がよく知られている.AspectJのアスペA Bytecode Translation for Pointcut Description Based on Data Dependency.
Yuichi Oneda, 東京大学大学院情報理工学系研究科, Grad-uate School of Information Science and Technology, Univ. of Tokyo.
Hidehiko Masuhara, 東京大学大学院総合文化研究科, Graduate School of Arts and Sciences, Univ. of Tokyo.
Akinori Yonezawa, 東京大学大学院情報理工学系研究科. Graduate School of Information Science and Tech-nology, Univ. of Tokyo.
コンピュータソフトウェア, Vol.24, No.2 (2007), pp.27–40. [論文] 2006 年 6 月 26 日受付. クトは,プログラムの動作時点を特定するポイント カットと呼ばれる記述と,その時点で追加されて,あ るいは置き換わって実行されるアドバイスと呼ばれる プログラム片から成る. AspectJのポイントカットは柔軟にモジュール中の 時点を特定できるものの,ポイントカットに現れる変 数が指す値の間の動的な依存関係に基づいて時点を特 定できない.言い換えれば,「値が過去にどのように して生成されたか」,つまり「値のコンテキスト」に 基づいたアドバイス処理を記述できない.この点に着 目し,第2著者らはdflowと呼ばれる値間の依存性を 簡潔に指定できるポイントカットを提案している[7]. dflowは2つの変数(x, y)と1つのポイントカット (q)を引数として受け取るポイントカットプリミティ ブであり,他のポイントカット(p)と共に主に次のよ うな形で使われる(ここで,xはp中に,yはq中に 現れるとする).
before(String x) :
call(void Strm.print(String)) && args(x) &&
dflow[x, String y] ( call(String Db.lookup(int)) && returns(y) ){ log.info(thisJoinPoint + ": " + x);
}
図 1 dflow を使ったアドバイス記述例
1 ...
2 int id = in.readInt();
3 String name = db.lookup(id);
4 ... 5 strm.print("<h1>Hello, "); 6 strm.print(name.toUpperCase()); 7 strm.print("</h1>"); 8 ... 図 2 ベースプログラム例 このポイントカットは, • p時点,かつ • その時のxの値が,過去のある時点qでのyの 値に依存する時点 を示す.つまり,dflow[x, y](q)という指定が,値 の依存関係に基づく条件でpを限定する. 例えば図1では,ポイントカット記述で「lookup の返り値に依存する値を実引数としてprintを呼び 出す時点」を指定し†1,その直前でログを取るという 処理をアドバイスにより実現している.このアドバ イスは,図2のプログラムでいえば,6行目のprint 呼び出しの直前に実行される.5, 7行目のprint呼 び出しに関しては,実引数は明らかにlookupの返り 値に依存していないため,アドバイスは実行されな い.「xの値がyの値に依存する」の意味については 2章で説明する.ここでは,「xから参照を辿って到達 可能な値に,yから到達可能だった値またはその値を 使って作られた値が含まれる状態」と考える. 1. 1 dflowポイントカットの応用例 値間の「依存」を上記のように定めた上で,dflowは 1. 開発者自身の書いたコードが不用意な情報漏え いをしていないか動的にチェックするアスペクト 2. クロスサイトスクリプティングやSQL injection †1 returns とは,dflow のために設けた「返り値で変数 を束縛する」ポイントカットプリミティブである [7]. を防ぐために行うサニタイジング処理をモジュー ル化するアスペクト[7] [13] [6] などを記述する場合に用いられることを想定してい る.7章で述べるように,現在のdflowの「依存」の 定義では他人によって書かれた悪意あるコードが起こ すセキュリティ上の問題を完全に防ぐことはできない が,それでもなおdflowによってアスペクト記述がよ り簡潔になりモジュール性が高くなる応用例は少なく ないと考える. 上記の1の記述例を詳しく示す.開発者が,自身 が書いたJavaプログラムに対しローカルファイルの 読み込みとネットワークへの接続を認めている時に, ローカルファイルの中身を直接ネットワークに漏えい しないかチェックしようとしている状況を考える.こ の状況はJava標準のセキュリティ仕様だけでは解決 できない[10].また,ネットワーク関連の処理はプロ グラムの複数の箇所に記述されている可能性がある. 従ってこの状況では,アスペクトの記述により,ネッ トワークに文字列を出力する時点でその文字列のコン テキスト,つまり「その文字列がローカルファイルか ら読み取った文字列か否か」,をチェックするように プログラムの動作を変えるのが適切である.図3に, このためのアスペクトをdflowポイントカットを用 いて記述した例を示す†2. 図 3の 1–3行 目 の 記 述 で は ,ポ イ ン ト カット atFileReadingを「ファイルから文字列を読み取っ た時点」と定め,そのときの文字列でinstrを束縛す るようにしている.より詳細に記述内容を説明する. • 2行目の記述で「“Reader”で終わるクラスのオ ブジェクトに対し“read”で始まるメソッドを呼 び出す時点」を指定し,呼び出し対象のオブジェ クトでtを,返り値でinstrを束縛する. †2 あくまでも説明のために記述を単純化している.
1 pointcut atFileReading(String instr) :
2 target(t) && call(* *Reader.read*(..)) && returns(instr) &&
3 dflow[Object t, FileInputStream fis]( call(* FileInputStream.new(..)) && returns(fis) );
4
5 pointcut atInetWriting(String outstr) :
6 target(t) && call(* *Writer.write*(String)) && args(outstr) &&
7 dflow[Object t, OutputStream os]( call(* Socket.getOutputStream()) && returns(os) );
8
9 before(String w, String r) : atInetWriting(w) && dflow[w, r]( atFileReading(r) ){
10 logger.warning(thisJoinPoint + ": " + w); 11 } 図 3 dflow の実用例 • 3行目の括弧内の記述で「FileInputStreamク ラスのコンストラクタを呼び出す時点」を指定 し,その時の返り値でfisを束縛する. • 2, 3行目全体で,「“Reader”で終わるクラスのオ ブジェクトに対し“read”で始まるメソッドを呼 び出す時点であり,かつ呼び出し対象のオブジェ クト(t)がFileInputStreamクラスのオブジェ クト(fis)に依存する時点」を指定し,返り値で instrを束縛する. 5–7行目の記述では,ポイントカットatInetWriting を「ネットワークに文字列を出力する時点」と定め, そのときの文字列でoutstrを束縛するようにして いる.9–11行目では,定義したatFileReadingと atInetWritingを使って,「ファイルから読み取った 文字列をネットワークに出力する時に,ログに警告を 出力する」というアドバイス処理を記述している. 1. 2 本研究の概要 先行研究ではJava言語上でのdflowの実現方針が 示されているが[7] [13],そのための手法は詳細には示 されておらず,また現実的な処理系も作成されていな い.本研究は,先行研究で示された実現方針を基に, Java言語上でのdflowの実現方式を提案,実装する. 具体的には,AspectJコンパイラに前処理と後処理 を付加することで,dflowの機能を提供するAspectJ 言語を実現する. 前処理と後処理の概略を次に示す. • 前処理は,dflowポイントカットを含むアスペ クトをもとに,依存関係の発生元と依存関係の 有無をチェックする場所を特定する.例えば図1 のアスペクト記述でいえば,依存関係の発生元 はDb.lookupを呼び出した直後の返り値,依存 関係の有無をチェックする場所はStrm.printを 呼び出す直前と特定される. • 後処理は,前処理が生成した依存関係に関する 情報を元に,バイトコードに,依存関係を動的に 管理する命令を追加する.またその際,依存関係 の動的な管理によるオーバーヘッドをできるだけ 抑えるために,事前に静的解析を行うことで不必 要な命令の挿入を防ぐ. 本論文では前処理の詳細には立ち入らず,後処理であ るバイトコード変換の実現手法に焦点を当てる. 後処理の実現での課題は,いかにして動的な依存関 係の管理を実現するかにあると同時に,その上でいか にして効率的なコードを生成するかにある.変換後 コードの効率を得るために,上述したように本バイト コード変換は静的解析に基づいている.我々は実験に よりその解析の有用性を確認した. 本論文では以降,簡単のため「dflowポイントカッ トは変換の入力にただ1つしか現れない」と仮定し て説明を行う.これは説明を簡略化するためであり, 実際には我々の作成した実装は複数のdflowポイン トカットを扱える.このことに関して,8章で振り返 る.以降は,2章でdflow実現のための基本的なアイ デアを述べる.3章ではAspectJコンパイラ拡張の 全体像を示すとともに,その全体像における本変換の 位置づけを示す.4章と5章で本バイトコード変換の 実現手法を説明する.6章で実験結果を示し,7章で 関連研究を述べ,8章と9章でまとめる.
set(y) = set(y,{}); set(y, visited) =
if(y is in visited) return;
add y to visited;
if(y points to a primitive value p)
associate flag with p;
else if(y points to a non-array object o)
associate flag with o;
for(each field fd of o) set(o.fd, visited); else if(y points to an array a)
for(each i of 0 ≤ i < a.length)
set(a[i], visited);
check(x) = check(x,{}); check(x, visited) =
if(x is in visited) return F;
add x to visited;
if(x points to a primitive value p) if(flag is associated with p) return T; else if(x points to a non-array object o)
if(flag is associated with o) return T; else
for(each field fd of o)
if(check(o.fd, visited)) return T; else if(x points to an array a)
for(each i of 0 ≤ i < a.length) if(check(a[i], visited)) return T; return F; 図 4 フラグの set, check
2 dflow の実現の基本アイデア
dflowを含むポイントカット記述が実行時にどの ように時点を特定するのかを概念的に説明する.基 本的なアイデアは先行研究で既に述べられているが [7] [13],そのアイデアをJava言語に適用するために より詳細な説明を行う. 基本的なアイデアは,実行時において「値v1が, ある時点である変数によって指されていた」ことを v1にフラグを対応付けることで表す,ということで ある[7] [13].図1の例で言えば,次の動作を実行時に 行う. • Db.lookupを呼び出した直後,その返り値の文 字列にフラグを立てる. • Strm.printを呼び出す直前で,実引数の文字列 にフラグが立っているか調べる.フラグが立って いればアドバイスを実行する.一般的に述べると,p && dflow[x, y](q)の示す時 点を特定するために実行時に以下の動作を行う. • フラグのset qが示す時点では,yから参照を伝って到達可能 な値全てにフラグを対応付ける.具体的には,図 4左に示されているset(y)を実行する.値を再 帰的に辿る際に無限ループに陥らないよう,一 度訪れた値を集合のデータ構造visitedに記録 する. • フラグの伝搬 プリミティブ値のコピーや演算(+,-等)が実行 される時点では,いずれかのオペランドにフラグ が対応付けられている場合,結果として得られる 値にフラグを対応付ける.特に,プリミティブ変 数を実引数/返り値とする関数の呼び出し/復帰 の際には,それらプリミティブ値に対応するフラ グを伝搬する必要がある. • フラグのcheck pが示す時点では,xから参照を再帰的に辿って 到達可能な値にフラグが対応付けられているか 調べる(図4右).そして,checkが真を返して
くる時点をp && dflow[x, y](q)が指定する時 点と定める. 以上の3つの操作を,以降フラグ管理と呼ぶ.なお 現状のフラグ管理では,特に有用性を確認できないた め,配列オブジェクトそのものに対してはフラグを対 応付けない. dflowでの変数間の依存関係はフラグ管理の動作 によって定められるとする.ここで,dflowでは変
図 5 AspectJ 拡張の構成 数間の依存関係として制御依存によるものは考慮 されないことに注意する.例えば,プログラム片 if(a == 0) ++b;においてaとbは一般に制御依存 関係にあるが,dflowでは依存関係にあるとはみなさ ない. 2. 1 依存関係の明示的な指定 dflowにはpropagate宣言という,変数間の依存 関係を明示的に指定する記述が用意されている[7].本 論文では詳細は述べないが,例えばアスペクト中に次 のように記述することで, declare propagate :
call(StringBuffer StringBuffer.append(*)) && args(s1) && target(s2) && returns(s3) :
from s1, s2 to s3; appendの呼び出し時に「s1とs2に対しフラグの checkを行い,どちらかがtrueを返せばs3に対し フラグのsetを行う」動作がなされるようになる. propagate宣言は主に,システムクラスメソッドの 呼び出しにおいて引数と返り値の間に依存関係を定 めたい場合に用いる.
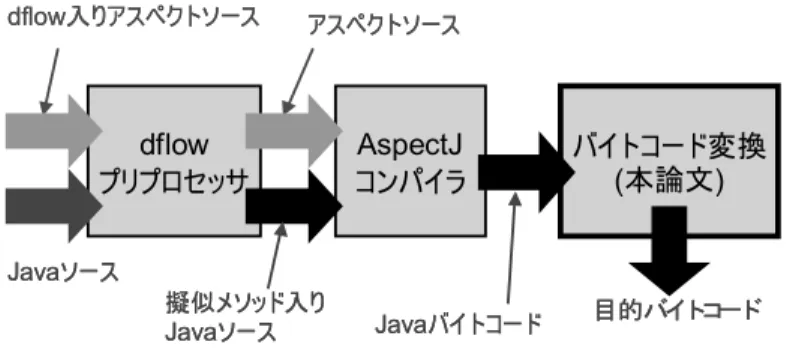
3 dflow 処理系の構成
dflowポイントカット実現のためのAspectJコンパ イラの拡張方式を示す.拡張は,前処理のdflowプリ プロセッサと後処理のバイトコード変換から成る(図 5). プリプロセッサは,入力となるアスペクトに含ま れているdflowポイントカットを基に,フラグの set/checkをソースコード中の(1)どこで,(2)どの ... 1 int id = in.readInt(); 2String name = db.lookup(id); 3
set$(name); 4 ... 5 String s1 = "<h1>Hello, "; 6 if(check$(s1)) log.info(...); 7 strm.print(s1); 8 String s2 = name.toUpperCase(); 9 if(check$(s2)) log.info(...); 10 strm.print(s2); 11 String s3 = "</h1>"; 12 if(check$(s3)) log.info(...); 13 strm.print(s3); 14 ... 15 図 6 プリプロセッサの生成するソースコード例. set$, check$は擬似的なメソッド 変数に対して実行すべきかを,ソースコード中に擬 似的なメソッド(set$/check$とする)を挿入するこ とで記録する.ここで「擬似的な」とは,単に上述の (1), (2)の情報を記録する目的にのみ使われるもので あって関数本体は空である,という意味である.同時 に,checkが成功した時に実行すべきアドバイスも ソースコード中に挿入する†3.以上の処理により,入 力となるアスペクトに含まれるdflowは全て取り除 かれる.例として,プリプロセッサに図1のアスペク トと図2のベースコードを与えた場合,プリプロセッ サは図6のソースコードを生成する. AspectJコンパイラは,dflowを含まないアスペク トと擬似的なメソッドを含むソースコードを受け取 り,アスペクトをソースコードにweave[5]する. †3 正確には,アドバイスは 1 つのメソッドに変換され るため,そのメソッドの呼び出しが挿入される.
バイトコード変換は,AspectJコンパイラが出力し た,擬似的なメソッド呼び出しを含むバイトコードを 入力とする.そして,その入力バイトコードに含まれ ているset$/check$に従って,動的にフラグ管理を 行うコードを挿入する.この際,1. 2節で述べたよう に,静的解析に基づくことで不必要なフラグ管理の コードはできるだけ挿入しないようにする.図6の ソースコードでいえば, • set$/check$の位置に素直に図4のset/check を挿入し, • 2行目でidが指すint値を操作する箇所(iload, istore等)すべてにフラグ伝搬を挿入する ことはたしかに1つの正しい変換である.しかし例 えば,図2の5, 7行目のprintの実引数にフラグが 対応しない,つまり図6の7, 13行目のcheck$での checkは失敗すると静的に分かれば,それを実行時に 省略できる.また,idの指していた整数値にフラグ が対応しないと静的に分かれば,その値を操作する命 令前後でのフラグ伝搬を省略できる.これらにより, 変換後バイトコードのオーバーヘッドが削減される.
4 動的なフラグ管理の実現
本章と次章では,前章で示したバイトコード変換 の具体的な手法について説明する.本章で,2章で示 したようなフラグの動的管理の実現方法を示す.次章 で,動的なフラグ管理によるオーバーヘッドを減らす ための解析について述べる. なお本手法は,システムクラスのコードをフラグ 管理の挿入や解析の対象としない.なぜなら,システ ムクラスのコードの改変は現実的でないからである. 2. 1節で述べたappendの例のように,システムクラ スのメソッドをまたがるような依存関係を指定したい 場合,つまりシステムクラスメソッドの中で生成され たオブジェクトに対し何らかの依存関係を指定したい 場合は,プログラマはpropagate宣言を使えばよい. 4. 1 フラグ値の確保 まず,各値に対し,「その値にフラグが対応付けら れているか否か」を表す真偽値(フラグ値)を対応付 ける.値の種類により,フラグ値の確保の仕方は次の 図 7 ローカル変数の拡張 ように異なる. • ユーザ定義クラスのオブジェクトのフラグ値は, クラス定義にbooleanフィールドを付け加えた 上で,その値として確保する. • システムクラスのオブジェクトのフラグ値は, 当オブジェクトとそのフラグ値の対応をハッシュ 表に記録することで,確保する.これは,ユー ザ定義クラスの場合と異なり,システムクラス のクラス定義を書き換えることは現実的でな いためである.ハッシュ表としては,参照同値 性によって同値性を判断するように書き換えた java.util.WeakHashMapを用いる. • ローカル変数,オペランドスタック上のプリミ ティブ値のフラグ値を確保するために,図7の ように,これらのフラグ値を保存するローカル変 数を追加する†4.ローカル変数の数とオペランド スタックの最大の深さはJavaコンパイラによっ てメソッドごとに静的に決定されるため,このよ うなローカル変数の拡張は容易である. • ユーザ定義クラスのオブジェクトが持つプリミ ティブ型フィールドのフラグ値は,そのクラス定 義にbooleanフィールドを付け加えた上で,そ の値として確保する.システムクラスオブジェク トのプリミティブ型フィールドに対するフラグ値 の確保は,現状の実装では実現していない. †4 実際は,4. 2. 2 項で述べるフラグ伝播コードを正しく 動作させるために,オペランドスタックも拡張する.• 1次元プリミティブ型配列上の各プリミティブ値 のフラグ値は,当配列と同じ長さのboolean型 の配列により確保する.これらの2つの配列間 の対応はハッシュ表によって保持する. 4. 2 フラグ管理コード 4. 2. 1 フラグのset, checkの実現 プリミティブ変数pに対するsetは,pのフラグ値 を1に書き換える操作として実現する.同様に,プリ ミティブ変数pに対するcheckは,pのフラグ値が 1か0かを確認する操作として実現する.また,参照 変数に対するset/checkは,図4のそれぞれの仕様 に従う関数を呼び出すことで実現する.フィールドや 配列要素を再帰的に辿る操作はリフレクションAPI で実現する. 4. 2. 2 フラグ伝搬の実現 プリミティブ値の移動,演算,コピーを伴う命令の 前後には,操作されるプリミティブ値に対応するフラ グ値を扱う命令を挿入する.挿入した命令により,プ リミティブ値の移動に対応するフラグ値の移動が実行 時に行われるようにする.これにより,フラグ伝搬が 実現できる. • フレーム(ローカル変数とオペランドスタック) のプリミティブ値を扱う命令(iload, istore, iadd, dup等)の直後では,フレームの要素間で のプリミティブ値の移動に伴って,対応するフラ グ値も移動させる.フラグ値の移動はオペラン ドスタックを経由して行う.例えば,図7のフ レームを持つ関数においてstack[1]に値を置く
“iload 2”命令の直後には,“iload 5; istore
7”の2命令を挿入する.各命令の前後でのオペ ランドスタックの深さは静的に決定されるため, 挿入すべき命令列も静的に決定できる. • オブジェクトや配列上のプリミティブ値をロード する命令(getfield, iaload)の直後では,ロー ドするプリミティブ値に対応するフラグ値を,オ ペランドスタックの先頭に対応するフラグ値とし てロードする.getfield命令の直後では,ロー ド対象のプリミティブフィールドに対応するフ ラグ値用フィールドの値をロードする.iaload 図 8 関数間のフラグ伝搬 の直後では,ハッシュ表からロード元の配列に対 応するフラグ値用のboolean型配列を取り出し, ロード対象のインデクスと同じインデクスに格 納されているフラグ値をロードする. • オブジェクトや配列上にプリミティブ値をスト アする命令(putfield, iastore)の直後には, getfield, ialoadの直後に挿入する操作と反対 の操作を挿入すればよい. • プリミティブ変数を引数とする関数呼び出しの際 は,実引数に対応するフラグ値を仮引数に対応す るフラグ値として呼び出される側に移動する.まず 当関数を呼び出す直前に,引数のフラグ値をスレッ ド固有のオブジェクト(java.lang.Threadlocalク ラスのオブジェクト)に書き出す(図8の(1)). そして当関数を呼び出す.呼び出された側で,関 数本体を実行する前にそのオブジェクトからフラ グ値をロードし,仮引数に対応するフラグ値とし て保存する(図8の(2)). • プリミティブ変数を返り値とする関数復帰の際 は,返り値に対応するフラグ値を呼び出した側に 移動させる.つまり,復帰直前に返り値のフラグ 値をスレッド固有のオブジェクトに書き出し(図 8の(3)),復帰直後にそのフラグ値をロードし, 返り値に対応するフラグ値として保存する(図8 の(4)).
5 効率的なフラグ管理のための解析
不必要な動的なフラグ管理によるオーバーヘッドを 避けるために,前章で述べたフラグ管理コードの挿入の前に,次の手順で静的解析を行う. 1. フラグ値の解析 挿入されているset$を元に,各変数の指し得る 値に対応するフラグ値をなるべく静的に求める. 2. checkされ得るかの解析 フラグ値が静的に分からなかった値を指し得る 変数が,実行時にcheck$の対象となり得るか調 べる. 以上の手順により,「フラグ値が静的に分からず,か つcheck$され得る」値を指し得る変数が求められる. 我々の変換は,このような変数を操作する命令の前 後にのみ,適切なフラグ管理のためのコードを挿入 する. 例として,図9の一番左のバイトコード片の変換を 考える.このコード片は,ローカル変数0と1にあ る値を加算し,その結果をローカル変数0に保存す るものである.今このコード片に,4. 2. 2項で述べた 方法に基づき単純にフラグ管理コードを挿入すると, 図9の中央のコード片が生成される.一方で,例え ば,解析によって加算前のローカル変数1の値には実 行時に絶対にフラグが対応しないと分かったとする. この解析結果に基づくことで,加算前のローカル変数 1を扱う命令の前後でのフラグ管理を省略でき,結果 として図9左のコード片を生成できる.このコード 片にも冗長なロード/ストア命令が残るが,これらは HotSpotコンパイラ等によって最適化されることを 期待し,本変換ではあえてこれ以上の最適化を行わ ない. 5. 1 フラグ値の解析 フラグ値の解析では,各変数が指し得る値に対応す るフラグ値を静的に決定する.フラグ値の解析値は次 のいずれかと定める. • 1: 実行時に必ずフラグが対応している • 0: 実行時に絶対にフラグが対応していない • ?: 不定 5. 1. 1 プリミティブ値の解析値 プリミティブ変数の指す値の解析値は各命令の番地 ごとに求められる.アルゴリズムは前向きのデータフ ロー解析に基づいている.つまり,各命令の直前での 図 9 バイトコード片に対するフラグ管理コード挿入例: 一番左が元のコード, 中央が単純な変換手法による コード, 一番右が我々の変換によるコード. 解析値を基にしてその命令の直後での解析値を計算 する.これを全ての命令前後の各解析値が変化しなく なるまで反復する.以下細かい点を述べる. • プリミティブ演算(iadd等)の各オペランドの 解析値がav1,av2であるとき,演算結果として 得られる値の解析値をav1 ◦ av2とする.ここ で◦は,図10左のルールを満たす解析値の演算 である. • 2つのコントロールフローが合流する点では,各 プリミティブ変数について,2つのフローの合流 前の解析値がそれぞれav1,av2であるとき,合 流後の解析値をav1 ∨ av2とする.ここで∨は, 図10右のルールを満たす解析値の演算である. • 各関数の先頭命令直前では,プリミティブ型の仮 引数の解析値は未定(解析値が1とも0とも?と も決定していない)とする.具体的には,プリミ ティブの仮引数値に対して解析値としてユニーク な変数(解析値変数)を割り当て,その上で解析 を前方向に進める.例えば次の関数mayaddone の解析を考える. int mayaddone(int x){ if(...) return x + 1;
◦ 1 0 ? 1 1 1 1 0 1 0 ? ? 1 ? ? ∨ 1 0 ? 1 1 ? ? 0 ? 0 ? ? ? ? ? 図 10 解析値間での演算 else return x; } 引数xに解析値変数Xを割り当てて解析を進め た時,if文then節のreturnの引数の解析値は X◦ 0と計算され,またelse節のreturnの引数 の解析値はXと計算される. 関数内のいずれかのreturnの引数の解析値が計 算された時点で,その解析値を当関数の返り値に 対応する解析値と一時的に定めることができる. 例えば,mayaddoneのif文then節のreturn
の引数の解析値がX◦ 0と計算された時点で,返 り値の解析値もX◦ 0と一時的に定めることがで きる.後にelse節のreturnの引数の解析値が Xと計算された時,mayaddoneの返り値の解析値 は(X◦ 0) ∨ Xと更新される. • プリミティブ値を返す関数呼び出しの直後では, その関数の返り値の解析値が既に計算されてい る場合,その解析値を利用して戻り値の解析値を 計算する.例えば,mayaddoneの呼び出し場所 で実引数の解析値が1であり,かつmayaddone の返り値の解析値がX◦ 0と計算されている時, 呼び出し側での戻り値の解析値はX◦ 0にX = 1 を代入した結果,つまり1と計算される†5.後 にmayaddoneの返り値の解析値が(X◦ 0) ∨ Xと 更新された時,戻り値の解析値も再計算する(た だしこの例では戻り値の解析値は1から変化し ない). まだ呼び出す関数の返り値の解析値が計算されて いない場合は,そこで解析を一時的に中断する. 呼び出す関数の返り値の解析値が計算された後, その場所からの解析を進めることができる. 以上の反復が終了した時点では解析値変数が解析結 果に残るため,次に各解析値変数に適切な解析値を割 †5 実際には,ここで関数呼び出しの多態性を考慮する. り当てる.ある関数のプリミティブ型仮引数に割り当 てた解析値変数をVar,その関数呼び出しの実引数値 の解析値(もしくは解析値変数)をそれぞれV1, . . . , Vn とすると†6,Var = V1∨ . . . ∨ VnかVar =?のいずれ かが満たされるべきである.すべての解析値変数につ いてこのような制約を生成しそれらをまとめて解く ことで,各解析変数に割り当てる解析値を求める. 最終的な解析結果において,関数の呼び出された 側で返す値の解析値と呼び出した側で受け取る値の 解析値は必ずしも一致しないことに注意する.例え ば,前述したmayaddoneを解析値が0の実引数で呼 び出す箇所と,解析値が1の実引数で呼び出す箇所 があったとする.この時,Xに割り当てられる解析値 は?となり,それに伴いmayaddoneが返す値の解析値 も?と決定する.しかし一方,反復が修了した時点で 既にmayaddoneの呼び出し側での戻り値の解析値は それぞれ0, 1と決定しており,返す値の解析値が?と 決定したことの影響を受けない. 5. 1. 2 オブジェクトの解析値 オブジェクトに関しては,オブジェクトそのものに 対応するフラグ値と各プリミティブ型フィールドに 対応するフラグ値を解析対象とする.図11のプログ ラム片でいえば,Sの解析値,S.valueの解析値,T の解析値,T.valueの解析値が計算対象となる.ここ でS, Tは,オブジェクトをnewする箇所(allcation site)の識別子である. フラグ解析の前にプログラム全体に対しポインタ 解析を行い,全ての参照変数について,その変数が プログラム中のどのallocation siteで生成されるオ ブジェクトを実行時に指し得るかを求める.ポイン タ解析のアルゴリズムとしては,文献[1]に記され ているものを用いた.このポインタ解析により,ど の参照変数がどのallocation siteで生成されたオブ ジェクトを実行時に指す可能性があるかが,参照変数 とallocation siteの組み合わせ,または,allocation
siteと参照フィールドとallocation siteの3つ組と
して求められる.このポインタ解析はフロー非依存, つまり参照変数に対する代入が起こる順番を考慮し
†6 実際には V1, . . . , Vnには解析値変数やそれらが◦ や
... 1
Node n1 = new Node(); : S 2
n1.value = 1; 3
Node n2 = new Node(); : T 4
n2.value = 2; 5 n1.next = n2; 6 ... 7 Node n3 = n1; 8 ... 9 図 11 参照変数を含むプログラム片. Node の定義は class Node { int value; Node next; } とする.
ない.その結果,例えば図11のプログラム片だと {(n1, S), (n2, T), (n3, S), (S, next, T)}という組み 合わせの集合(points-to set)が解析結果として得ら れる. ポインタ解析の結果を利用することで,基本的に は,オブジェクトに関する解析値の計算は,5. 1. 1項 で述べた反復アルゴリズムに自明に組み込むことが できる.ただし,解析値の初期値や更新方法について 次の点を考慮する. • 反復の前に,各allocation site Sについて,も しSがプログラム中のset$の引数となるいずれ かの参照変数から(得られたpoints-to setにお いて)到達可能ならば,S, S.pf1, S.pf2, ... の 解析値を?と初期化する.そうでなければ,S, S.pf1, S.pf2, ... の解析値を0と初期化する.こ こで,pf1, pf2, ...はSで作られるオブジェク トが持つプリミティブ型のフィールドであると する.また,points-to setP Sにおいて alloca-tion site Sが参照変数r から到達可能であると は,次のようなS0, ..., Snが存在することを指す: S = Snかつ,(r, S0)∈ P S, ..., (Si, fi, Si+1)∈ P S, ..., (Sn−1, fn−1, Sn)∈ P S. • 反復の際は,参照変数rを通してオブジェクト のプリミティブフィールドpfに値pをストア する箇所(r.pf = p;)では,ポインタ解析で得ら れたP Sにおいて(r, S) ∈ P SなるSについて, S.pfの解析値av1を,pの解析値av2を使って, av1 ∨ av2に更新する. 5. 2 checkされ得るかの解析 フラグ解析値の決定後は,解析値が?である値を指 し得る変数がcheckの対象となり得るか解析する. プリミティブ変数に対する解析のアルゴリズムは 後ろ向きのデータフロー解析に基づく.プリミティブ 変数pに対するcheck$の直前で,もしpの解析値が ?ならば,pに「checkされ得る」ということを示す マークを付ける.そしてその箇所からコントロールフ ローを逆順に辿りながら,マークを伝搬させていく. pの解析値が?でなくなった箇所で伝搬をやめる. オブジェクトに対するアルゴリズムもプリミティブ 変数に対するそれに準じるが,5. 1. 2項で述べたよう な反復の際の考慮が同様に必要である.
6 実験
我々は4章と5章で示した変換を実装した.そし て我々の変換が,解析を用いない単純な変換手法解 析を事前に行わないで各命令前後にフラグ管理コー ドを挿入する手法) と比較してどの程度有効かを調 べるため,それぞれの変換によって生成したバイト コードのオーバーヘッドを測定した.測定は,CPU がPentium4(1.7GHz)でメモリが256MByte,OSが Windowsのマシンにて,JDK1.4.2を用いて行った. ベンチマークとして利用したプログラムは,行列 計算(Linpack),ファイルの圧縮と伸張(Compress), レイトレース(Mtrt),データベース操作(Db)の4つである.なお,LinpackはLinpack Benchmarkの
ものを,CompressとMtrtとDbはSPECjvm98の ものを利用したが,例外処理やアプレット操作を適当 に除いた. dflowを用いたアドバイスとしては,デバッグの際 の使用例を想定して,「コンストラクタ内で初期化さ れてないプリミティブフィールドが,関数の計算結果 に影響を与えるかを調べる」ものを使用した.なお, このようなデバッグの仕方はAspectJの機能だけで は実現できない.現段階ではdflowの前処理部分が完 成していないため,次のようなコード片を直接ベンチ マークプログラムに挿入することで本変換の入力と なるバイトコードを作成した. • 各クラスのコンストラクタの終了直前に,プリ
ミティブフィールドとプリミティブ配列型フィー ルドに対し,フラグをset$する. • 返り値が非voidである関数のreturn直前に,返 り値に対しフラグをcheck$する. 6. 1 実験結果 6. 1. 1 命令数の変化 我々はまず,バイトコードに対して追加された命令 の数を調べた.その結果が表1である.表1の一番 上の行は変換前の命令数,中央の行は解析を用いない 単純な変換後の命令数,一番下の行は本研究による変 換後の命令数を表す.表1では,フラグ値配列に対す るフラグ値のロード/ストアや,関数間のフラグの伝 搬,参照変数に対するset/checkを実現するメソッ ドの定義は追加分として含めていない(ただし,これ らのメソッドを呼び出すコードは含めている).なお, 変換時間はLinpackとCompressとDbではポイン タ解析も含めて1.5秒以下,Mtrtでも同様7秒以下 であった. 表1から,解析を用いない変換の後の命令数は 2倍弱から3倍程度に増加していることが分かる. 一方,我々の変換の場合,最も増加の大きい場合で Compressの1.2倍弱の増加であることが分かる.こ の結果より,命令数の観点から我々の変換の有効性が 確認できた. LinpackとDbに関してはフラグ管理コードは一切 挿入されなかった.ここで,それぞれのソースコード を目で追ってみると次のことが確認された. • Linpackにはdoubleフィールドが複数存在する が,これらは実行時間の多くを占めると思われる 行列計算では全く使われないものであり,何らか の関数の返り値となることもない. • Dbにはbooleanフィールド,intフィールドが 存在する.booleanフィールドは主計算の後の処 理での条件判定にのみ使われる.intフィールド は2つ存在するが,どちらもデータ列のインデ クスを保持するために使われ,またその値が関数 の返り値となることもない. これらの性質を静的に解析できた事が,前述の結果に つながったと考えられる. 表 1 命令数の変化
1480
6602
1948
1117
我々の変換後2805
14000
4441
3345
解析無し変換後1480
6212
1685
1117
変換前Db
Mtrt
Compress
Linpack
1480
6602
1948
1117
我々の変換後2805
14000
4441
3345
解析無し変換後1480
6212
1685
1117
変換前Db
Mtrt
Compress
Linpack
表 2 実行時間比1.00
61.84
16.21
0.99
我々の変換後1.70
206.98
36.43
63.99
解析無し変換後1.00
1.00
1.00
1.00
変換前Db
Mtrt
Compress
Linpack
1.00
61.84
16.21
0.99
我々の変換後1.70
206.98
36.43
63.99
解析無し変換後1.00
1.00
1.00
1.00
変換前Db
Mtrt
Compress
Linpack
6. 1. 2 変換後バイトコードのオーバーヘッド 変換後バイトコードのオーバーヘッドを測定した結 果を表2に示した.表2では,変換前バイトコード の実行時間を基準(1.00)にして,解析を用いない変 換の後の実行時間比と,本研究による変換の後の実行 時間比を示している. まず,LinpackとDbの結果を見る.解析を用いな い変換の後には,それぞれ64倍,1.7倍のオーバー ヘッドが生じている.特に,Linpackの大きいオー バーヘッドの原因は,フラグ配列に対するフラグ値 のload/storeであることを確認した.一方,表1か ら明らかであるが,我々の変換は全くオーバーヘッド をもたらしていない. 次にCompressとMtrtの結果を見る.解析を用 いない変換の後にはそれぞれ36倍,206倍ものオー バーヘッドが生じているが,我々の変換はそれをそれ ぞれ16倍,61倍程度にまで抑えている.とはいえ, 我々の変換によるオーバーヘッドも小さいとはいえ ない.我々は,これらの変換後プログラムのオーバー ヘッドが関数間のフラグ伝搬,プリミティブ配列操作 時のフラグ伝搬,参照変数に対するset/checkから 成りたっていると近似し†7,オーバーヘッドの内わけ を測定した(表3). Compressに関しては,我々の変換によるオーバー ヘッドの2/3近くが配列操作時のフラグ伝搬による †7 4. 2 節で述べたように,これらの操作は ThreadLocal クラス,WeakHashMap クラス,リフレクション API 等の重たい標準ライブラリによって実現しているから.表 3 オーバーヘッドの内わけ (上は Compress, 下は Mtrt. 解析無し変換によるオーバーヘッド全体を 100 とした時の, 解析無し変換/我々の変換後の 各フラグ管理によるオーバーヘッド比) 31.53 93.82 参照変数に対するcheck 32.71 100 計 0.00 0.00 参照変数に対するset 0.00 0.44 配列操作時のフラグ伝搬 1.18 5.67 関数間のフラグ伝搬 我々の 変換後 解析無し 変換後 31.53 93.82 参照変数に対するcheck 32.71 100 計 0.00 0.00 参照変数に対するset 0.00 0.44 配列操作時のフラグ伝搬 1.18 5.67 関数間のフラグ伝搬 我々の 変換後 解析無し 変換後 0.00 0.00 参照変数に対するcheck 40.30 100 計 0.68 0.68 参照変数に対するset 28.60 45.77 配列操作時のフラグ伝搬 11.03 53.55 関数間のフラグ伝搬 我々の 変換後 解析無し 変換後 0.00 0.00 参照変数に対するcheck 40.30 100 計 0.68 0.68 参照変数に対するset 28.60 45.77 配列操作時のフラグ伝搬 11.03 53.55 関数間のフラグ伝搬 我々の 変換後 解析無し 変換後 ものだと分かる(表3上).また,解析なしの変換の後 のオーバーヘッドと比較した時の減少が小さい.実は Compress中のいくつかのクラスはプリミティブ配列 型のフィールドを持っているが,我々の解析は配列の 各要素をあたかも1つのフィールドに「つぶして」解 析するため,これらの配列型フィールドの各要素に対 する精度が悪くなる.このことが大きなオーバーヘッ ドが依然として残っている原因だと考えている. Mtrtでは,解析を用いない変換の後でも我々の変 換の後でも,オーバーヘッドの大部分は参照変数に対 するcheck操作であることが分かる(表3下).参照 変数に対するset/checkは,リフレクションAPIを 使って各フィールドにアクセスする.Mtrtの大きな 性能低下は,リフレクションAPIの頻発によるもの だと考えられる.
7 関連研究
AspectJには,cflowという制御フローに基づい て時点を指定するポイントカットが存在する.一方で dflowは“データフロー”に基づいて時点を指定する ポイントカットであり[7] [13],cflowと対照的である. Perlにはtaint-check[11]と呼ばれるセキュリティ 機能がある.この機能の下では,プログラム外部から 与えられるデータに対して「汚染されている」という マークが付けられる.そして,「汚染された」データ がファイルやプロセス等を操作するコマンドの引数 として用いられる時,エラーが発生するようになる. dflowは値間の依存性に基づく処理を一般的に記述で きる一方で,taint-checkはPerlの言語機能に組み込 まれているものであり,この機能をセキュリティ保持 以外のことに使用するのは難しいと考えられる.例え ば「汚染」マークを付ける場所を変更することは出来 ないし,エラーが発生した際に適切な処理をして実行 を継続することもできない. 情報流解析は,機密度の高いデータがプログラムの 外に漏れないことを検査する枠組みである.1. 1節で 示したような情報流に基づく処理の記述はdflowの重 要な応用の1つであり,その意味でdflowは情報流解 析の多くの研究[10]と関連する.しかし,dflowのよ うにアスペクト指向に基づいた枠組みは過去には見 受けられない.情報流に基づく処理をアスペクトとし て記述する利点の1つはモジュラリティーの向上にあ る.dflowは依存関係に関する情報をアスペクトとし て一箇所に記述できるが,例えばSlam[3]やJFlow [8]のような静的な型に基づくシステムでは,プログ ラマはプログラム全体にわたって型に対しその情報を 付加しなくてはならない. 一方で,多くの静的な情報流解析の研究と異なり, dflowは変数間の制御依存による関係を認めていない. 我々は1. 1節でdflowの応用例として,ローカルファ イルの内容をネットワークに直接流してしまうことを 検知するアスペクトを記述したが(図3),残念ながら これは制御依存による情報漏えいを防ぐことはでき ない.例えば次の関数cut dflow void cut_dflow(int k){ int d = 0; for(int i = 0; i < 32; i++){ int bit = 1 << i;if ((k & bit) != 0) d |= bit; }
... // ネットワークに d を出力 }
にローカルファイルから読んだ値を実引数として与え て実行した時,明らかにローカルファイルから読んだ
値と等しい値がネットワークに流れてしまうが,その ことは図3のアスペクトにより検知されない. 我々は,開発者自身が上記のような関数を通じて不 注意に機密度の高い情報を漏えいするケースは少な いと考えている.しかし仮にdflowでの依存の定義に 制御依存を含めるならば,それにともなう動的フラ グ管理や解析の拡張においては,バイトコード上の 基本ブロック間の支配関係に近い概念が有用と考え る[14].ただし,dflowの応用は情報漏えいの検知に 限らないため[7] [13],実際に制御依存を導入する際に はアスペクト記述の容易性や実行効率などの点から の検討も必要になる. Javaバイトコードの静的解析は数多く提案されて おり,スタックアロケーションや同期の除去など応用 も多い[9] [12] [2].我々の変換で用いた静的解析の特徴 はあくまでdflowを応用とする点である.特に我々の フラグ値の解析は,解析値変数を導入することで関 数間をまたがって移動するプリミティブ値の解析値の 劣化を防いでいる.具体的には,解析値変数の導入 により,関数を呼び出した側で受け取るプリミティブ 値の解析値と呼び出された側で返す値の解析値を独 立して求めることが可能になった.これにより,例え ば5. 1. 1項で挙げたmayaddoneの解析結果のように, 呼び出された側で返す値の解析値が?に劣化した場合 でも,呼び出した側で受け取る値の解析値を0また は1に留めることができる.これは,解析値変数を 用いないで大域的に反復して解析値を決定する方法 の場合,呼び出された側で返す値の解析値が?となっ た時,呼び出した側で受け取る値の解析値もすべて? となってしまうことと対照的である.本手法でのフラ グ値解析は,関数間のフラグ値伝搬のオーバーヘッド の大きいdflowにとって重要な解析だと考えている.
8 複数の dflow ポイントカットを扱うための
拡張
本論文では,説明の都合上,使われるdflowポイ ントカットが1つのみであることを仮定して話を進め たが,複数のdflowを扱うことは困難ではない.実 際に現時点では,我々の実装は32個までのdflowポ イントカットを処理できる. 複数のdflowポイントカットを扱うためには,フ ラグの動的な管理においては,dflowポイントカット と同じ数だけフラグの種類(ID)を設け,各IDごと にフラグを管理すればよい[7].このためにはまず,各 値に対してフラグ値そのものを対応付けるのではな く,各IDのフラグ値を要素とする配列を対応付ける ようにする.また,動的なフラグのset/checkの際 には,「どのIDのフラグをset/checkするか」の情 報を与えるようにし,フラグの伝搬の際には全ての IDのフラグを伝搬させるようにする. 解析の際には,各IDごとにフラグ値を解析すれば よい.つまり,解析値を静的なフラグ値(1, 0, ?)の (IDの数と同じだけの)組みとした上で,解析を行う ようにする.解析の手順を変える必要はない.9 おわりに
本論文では,値の依存関係に基づくポイントカット 記述dflowの実現のためのバイトコード変換を提案, 実装した.本バイトコード変換は静的解析に基づく. 我々は実装した変換器でベンチマークプログラムを 変換し,変換後バイトコードでの依存関係の動的な 管理によって生じるオーバーヘッドを測定した.いく つかのベンチマークアプリケーションに対してデバッ グに関するアスペクトで用いられるdflowポイント カットを適用した場合,最も良い場合でオーバーヘッ ドは0に抑えられた.一方,アプリケーションによっ ては約60倍ものオーバーヘッドが確認されたが,そ の場合でも静的な依存性解析を用いずに単純にコード を挿入する手法に比べるとオーバーヘッドは1/3以 下に抑えられていることが分かった.以上の結果から 本変換手法の有用性を確認できた. 今後の一番の目標はdflow処理系の前処理部分を 構築することである.また本バイトコード変換アルゴ リズムの改良として,より優れたポインタ解析の導入 や,リフレクションAPIをできる限り使わない動的 なフラグのset/checkの実現を計画している.謝辞
東京大学米澤研究室およびPOPLミーティングの 方々,東京大学の河内一了氏からは研究を進めるにあたって様々なアドバイスをいただきました.また,査 読者の方々からは本論文に対する有益なコメントをい ただきました.ここに感謝します.
参 考 文 献
[ 1 ] Berndl, M., Lhotak, O., Qian, F., Hendren, L. and Umanee, N.: Points-to analysis using BDDs, in Proc. of the 2003 PLDI, 2003, pp. 103–114. [ 2 ] Blanchet, B.: Escape Analysis for Object
Ori-ented Languages, in Proc. of the 14th OOPSLA, 1999, pp. 20–34.
[ 3 ] Heintze, N. and Riecke, J. G.: The SLam cal-culus: programming with secrecy and integrity, in Proc. of the 25th POPL, 1998, pp. 365–377. [ 4 ] Kiczales, G., Hilsdale, E., Hugunin, J., Kersten,
M., Palm, J. and Griswold, W.: An overview of As-pectJ, in Proc. of the 15th ECOOP, 2001, pp. 327– 355.
[ 5 ] Kiczales, G., Lamping, J., Menhdhekar, A., Maeda, C., Lopes, C., Loingtier, J. and Irwin, J.: Aspect-Oriented Programming, in Proc. of the 11th ECOOP, 1997, pp. 220–242.
[ 6 ] Martin, M., Livshits, B. and Lam, M.: Finding Application Errors and Security Flaws Using PQL: a Program Query Language, in Proc. of the 20th
OOPSLA, 2005, pp. 365–383.
[ 7 ] Masuhara, H. and Kawauchi, K.: Dataflow Pointcut in Aspect-Oriented Programming, in Proc. of the 1st APLAS, 2003, pp. 105–121.
[ 8 ] Myers, A. C.: JFlow: Practical mostly-static in-formation flow control, in Proc. of the 26th POPL, 1999, pp. 228–241.
[ 9 ] Rountev, A., Milanova, A. and Ryder, B. G.: Points-to Analysis for Java Using Annotated Con-straints, in Proc. of the 16th OOPSLA, 2001, pp. 43–55.
[10] Sabelfeld, A. and Myers, A.: Language-Based Information-Flow Security, IEEE J. on Selected Ar-eas in Communications, Vol. 21, No. 1(2003), pp. 5– 19.
[11] Wall, L. and Schwartz, R.: Programming Perl, O’Reilly and Associates, 1991.
[12] Whaley, J. and Rinard, M.: Compositional Pointer and Escape Analysis for Java Programs, in Proc. of the 14th OOPSLA, 1999, pp. 187–206. [13] 河内一了, 増原英彦: アスペクト指向プログラミン グにおけるデータフローポイントカット, 第 3 回 SPA サマーワークショップ, 2004. [14] 小林直樹, 白根慶太: 低レベル言語のための情報流 解析の型システム, コンピュータソフトウェア, Vol. 20, No. 2(2003), pp. 2–21.