Gated recurrent unit の局所安定化による勾配爆発の抑制
金井 関利
†,††a)藤原 靖宏
†岩村 相哲
†††足立 修一
††Training of Gated Recurrent Units Constrained to Locally Stable to Prevent the Gradient Exploding
Sekitoshi KANAI
†,††a), Yasuhiro FUJIWARA
†, Sotetsu IWAMURA
†††, and Shuichi ADACHI
††あらまし 本研究では,gated recurrent unit(GRU)の学習において勾配爆発を防止する学習法を提案する.
GRUは,recurrent neural network(RNN)のモデル構造の一つであり,学習させることで時系列データの処 理を高精度に行うことができる.しかしRNNでは学習に使用する勾配が急激に増大する勾配爆発という現象が 生じるため,その学習は困難である.この勾配爆発は学習によって状態の挙動が大きく変化する分岐を起こすと きに生じるため,本研究ではGRUの状態の挙動を解析し,分岐が生じないように局所的に安定に制約した学習 法を提案する.そして実験として言語と音楽のモデリングを行い,提案法が既存法より効果的に勾配爆発を防げ ることを示す.
キーワード 機械学習,深層学習,Gated recurrent unit,非線形動的システム
1.
ま え が き機械翻訳や音声認識などにおいて高精度にデータ を処理できるモデルとして
recurrent neural network
(
RNN
)が注目を集めている[1]
〜[3]
.RNN
はニュー ラルネットワークのノードの出力(あるいは中間の計 算結果)を状態として次の時刻のノードの入力とする ことで,時系列データの過去の情報を効率的に扱うこ とができる.RNN
の学習はタスクに応じた目的関数を 設定し,確率的勾配降下法(SGD
)によってこれを最 適化することで行われる.SGD
に必要な勾配の計算は フィードフォワード型のニューラルネットワークと同 様に逆誤差伝搬を用いるが,RNN
は時刻方向の結合が あるためback propagation through time
(BPTT
)†NTTソフトウェアイノベーションセンタ,武蔵野市
NTT Software Innovation Center, 3–9–11 Midori-cho, Musashino-shi, 180–8585 Japan
††慶應義塾大学理工学部,横浜市
Faculty of Science and Technology, Keio University, 3–14–1 Hiyoshi, Yokohama-shi, 223–8522 Japan
†††北海道大学産学・地域協働推進機構,札幌市
Institute for the Promotion of Business-Regional Collabo- ration, Hokkaido University, North 21, West 11, Kita-ku, Sapporo-shi, 001–0021 Japan
a) E-mail: [email protected] DOI:10.14923/transinfj.2018JDP7082
と呼ばれる
RNN
を時間方向に展開した逆誤差伝搬が 用いられる.しかし,勾配の掛け合わせによる勾配消失や勾配爆 発という現象により
BPTT
によるRNN
の学習は困 難であることが知られている[4], [5]
.BPTT
は数十か ら数百時刻の時間方向への勾配伝搬が行われるため,小さな勾配が何度も掛け合わされるとその勾配は非常 に小さな値となる.この現象は勾配消失と呼ばれ,こ れが生じると
RNN
が過去の情報を学習できなくなる.この問題を回避するために,モデルにゲート構造を もたせた
long short-term memory
(LSTM
)が提案 された[6]
.更に精度を保ちつつLSTM
を簡素化したgated recurrent unit
(GRU
)が提案されている[7]
.GRU
は二つのゲートのみの簡素な構造をしているにも かかわらず,LSTM
と同程度の精度を達成できる[8]
.一方,勾配爆発は勾配が非常に大きな値となる現象 であり,これが生じるとパラメータが非常に大きな値 となり学習が失敗してしまう.そこで勾配のノルムが あるしきい値を超えた場合に,勾配の大きさを小さく する勾配クリッピング(
gradient clipping
)が提案さ れた[4]
.これは簡単でタスクによらず使用できるが,ヒューリスティックな方法なのでしきい値を試行錯誤 的に調整しなければならない.
本論文では,より効果的に勾配爆発を抑制して
GRU
を学習する方法を提案する(注1).勾配爆発は,小さな パラメータ変化によってRNN
の状態のダイナミック スが劇的に変化する分岐(bifurcation
)によって生じ る.そこでGRU
のダイナミックスを解析し,分岐点 の一つを明らかにする.この分岐点を回避するため,GRU
の重み行列に制約をつけた学習法を提案し,更 にそれを効率的に行う手法を考案する.RNN
の性能 評価によく用いられる言語と音楽のモデリングの実験 でこれを評価し,この手法によって勾配爆発が抑えら れること,精度が同等以上であることを確認した.2.
背 景2. 1 Gated Recurrent Unit
時系列データは過去のデータの値や直近の時刻の データに複雑に依存しており,そうした長期的なデー タの傾向や短期的な変化を表現するためにはモデルは 適切に過去の情報の保持,あるいは忘却をしなければ ならない.そこで
GRU
は過去の情報を更新ゲート,リセットゲートと呼ばれる二つのゲートを使って調節 する(図
1
).時刻t
における更新ゲートz
t∈ R
n×1はz
t= sigm( W
xzx
t+ W
hzh
t−1)
,(1)
である.ここでx
t∈ R
m×1は入力を,h
t∈ R
n×1は 状態を表す.W
xz∈ R
n×mとW
hz∈ R
n×nは重み行 列であり,sigm(·)
は要素ごとのシグモイド関数であ りsigm( x ) = 1 / (1 + exp( −x ))
である.一方,リセットゲート
r
t∈ R
n×1はr
t= sigm( W
xrx
t+ W
hrh
t−1)
,(2)
図1 GRUの概略図
(注1):国際会議で過去に速報的に発表した論文[9]に対し,本論文は 追加の実験と考察を加えてジャーナルにした正式版である.
である.ここで
W
xr∈ R
n×mとW
hr∈ R
n×nは重 み行列である.状態h
tはh
t= z
th
t−1+ ( 1 − z
t) ˜ h
t,(3)
によって更新される.ただし1
は全ての要素が1
のベ クトルであり,は要素ごとの積を表す.式
(3)
をみ ると,更新ゲートz
tが一時刻前の状態h
t−1と要素ご とにかけられている.z
tの要素は0
から1
の値をと るため,z
tが1
に近いと状態の更新がされず,0
に近 いと新しい状態h ˜
tに更新される.この新しい状態の 候補h ˜
tはh ˜
t= tanh( W
xhx
t+ W
hh( r
th
t−1))
,(4)
で計算される.ただしtanh(·)
は要素ごとのハイパボ リックタンジェントでW
xh∈ R
n×mとW
hh∈ R
n×n は重み行列である.式(4)
においてもリセットゲートr
tとh
t−1がかけられており,同様に次の状態をどの 程度,過去の状態に依存させるかを調節している.な お本研究ではバイアスは全て0
であるものとする.状 態h
tの初期値は一般に全て0
,h
0= 0
とする.その ためh
tが0
になるとGRU
が過去の情報を全て忘却 したことに対応する.GRU
を含むRNN
の学習は一般に次の最適化問題 となる.min
θ1 N
N j=1C ( x
(j), y
(j); θ )
,(5)
ここで
θ
はW
hhなどのモデルの全てのパラメータを 並べたベクトルであり,x
(j)とy
(j)はそれぞれj
番 目の教師データの入力と出力である.C ( x
(j), y
(j); θ )
は交差エントロピーなどの損失関数であり,N
はデー タ数である.式
(5)
の最適化は一般に確率的勾配降下法(SGD
) によって解かれる.SGD
はランダムにサンプリング されたミニバッチの勾配に従ってパラメータを反復更 新する.τ
回目のパラメータ更新はθ
(τ)= θ
(τ−1)− η∇
θ1
|D
τ|
(x(j),y(j))∈Dτ
C
(j),(6)
である.ただしD
τ はミニバッチで|D
τ|
はそのサ イズを表し,η
はSGD
の学習率,C
(j)= C ( x
(j),
y
(j); θ )
である.勾配クリッピングでは勾配のノルム
∇
θ 1|Dτ|
(x(j),y(j))∈Dτ
C(x
(j), y
(j); θ)
をあらか じめ指定したしきい値でクリップする.α
をGRU
層 以外のパラメータ数とすると,重み行列W
h∗のサイ ズn × n
,W
x∗のサイズn × m
から全パラメータθ
の要素数は3( n
2+ mn ) + α
であり,勾配クリッピン グの計算量はO(n
2+ mn + α)
となる.2. 2
動的システムと勾配爆発RNN
は次の非線形な動的システムh
t= f ( h
t−1, θ )
,(7)
とみなせる.ここでh
tはt
時刻の状態ベクトルでθ
は パラメータ,f
は非線形関数である.もし状態がある 時刻t
∗においてh
t∗= f ( h
t∗, θ )
を満たすと,外部か ら入力が与えられない限り状態は変化せず,そうした 点h
∗は平衡点と呼ばれる.状態が平衡点h
∗近傍で平 衡点に収束するか離れるかはf
とθ
に依存し,これは 安定性と呼ばれる重要な特性である[10]
.初期値h
0が||h
0−h
∗|| < ε
を満たすときにlim
t→∞||h
t−h
∗|| = 0
となるような定数ε
が存在するとき,平衡点h
∗は漸 近安定と呼ぶ.一方,h
∗が安定でなければ,この平衡 点は不安定である.安定性や状態h
tの平衡点近傍で の振る舞いはθ
の滑らかな変化で大きく変化する.こ の現象は分岐と呼ばれ,分岐を起こすパラメータ点は 分岐点と呼ばれる[10]
.[4], [11], [12]
は分岐によってRNN
の学習が失敗す ることを示した.SGD
によってパラメータが更新さ れ分岐点に達すると,状態の振る舞いが急激に変化す る.この不連続な振る舞いの変化によって損失関数が この点において不連続となる.その結果として分岐点 で勾配が非常に大きな値となり,勾配に基づくSGD
による学習は失敗する.2. 3
関 連 研 究[13]
は勾配爆発を防ぐために,RNN
のダイナミッ クスを状態が安定となるように制約する学習法を提 案した.一方,[14]
はリアプノフ関数から安定となる 学習率を求める学習法を提案している.しかしこれら の方法はJordan
型やElman
型の単純なRNN
であ り,GRU
のような複雑で長期記憶可能なモデルに対 して直接適用することは難しい.更に,これらの方法 では平均2
乗誤差を損失関数として仮定しているが,我々の方法は
GRU
を対象とし損失関数に依存しない.[11]
はBPTT
によって分岐が生じて勾配爆発が発生 することを示し,勾配爆発の起こらないBPTT
に代 わるreal-time recurrent learning
(RTRL
)という学習法を提案した.しかし
RTRL
はu
を出力ユニット 数とすると各反復ごとにO((n + u)
4)
という大きな計 算量を必要とする[15]
.最近では勾配爆発と勾配消失 を防ぐためにRNN
の重み行列をユニタリ行列に制約 する方法[16]
が提案されているが,実問題にはこの制 約が強すぎることが示されている[17]
.[18]
はRNN
の 再帰的な結合に対する重み行列を特異値分解後のユニ タリ行列と対角行列の形でパラメータを割り当て学習 させる方法を提案した.単純な
RNN
のダイナミックスに関しては様々な解 析が行われている[19]
〜[23]
が,GRU
のような最近 のモデルに対する解析はいまだ少ない.[24]
はReLU
を使ったRNN
のダイナミックスを解析し,[25]
は実験 的にLSTM
とGRU
がカオス的な振る舞いを起こす ことを示して安定な新しいモデルを提案している.[26]
では
LSTM
やGRU
の重みと状態の局所的な安定性 との関係について解析されている.後述するように本研究では
GRU
の重み行列の最 大特異値(スペクトルノルム)を制約する.そのよう なスペクトルノルムを制約した学習法の研究がcon- volutional neural network
などのフィードフォワー ド型のニューラルネットに対して行われており,この ことにより画像認識の汎化性能やロバスト性の向上,generative adversarial networks
の学習が安定するこ とが報告されている[27]
〜[30]
.3.
局所安定化による勾配爆発の抑制2.
で述べたように分岐が勾配爆発を生じさせる.こ の節ではGRU
のダイナミックスの解析を通して分岐 を回避し勾配爆発を防ぐ方法を提案する.3. 1
状態を安定に制約し勾配爆発を防ぐ学習法 この項では提案する学習法を特異値に関する制約付 き最適化問題として定式化する.簡単のため一層のGRU
の学習法を説明し,その後,複数層の場合に拡 張する.3. 1. 1
一層GRU
GRU
の学習は式(5)
のような最適化問題として定 式化されるが,前述のようにBPTT
とSGD
を使った 学習は勾配爆発を起こす.そこで勾配爆発を防ぐため に一層のGRU
の学習を次の制約付き最適化min
θ1 N
N j=1C
(j),s . t . σ
1( W
hh) < 2
,(8)
で行う方法を提案する.ここで
σ
i( · )
は行列のi
番目に大きな特異値であり
σ
1(·)
はスペクトルノルムと呼 ばれる.式(8)
の最適化は次の定理のようにGRU
を 局所的に安定に保ち,この平衡点の安定性の変化によ る勾配爆発を防ぐことができる:[定理
1
] もしσ
1( W
hh) < 2
ならば,一層のGRU
の平衡点h
∗= 0
は安定である.この定理は式
(8)
による学習法が平衡点h
∗= 0
の 安定性を変化させないことを示している.そのため提 案法はh
∗の安定性の変化による勾配爆発を起こさな い.この定理を証明するため次の三つの補題を用い る(注2):[補題
1
] 一層のGRU
はh
∗= 0
に平衡点をもつ.[補題
2
]I
をn × n
の単位行列としλ
i( · )
をi
番目 に絶対値の大きな固有値とし,J =
14W
hh+
12I
とす る.もしスペクトル半径(注3)|λ
1( J ) | < 1
であるなら ば,入力のない一層のGRU
はh
t= 0
近傍で次のよ うに線形近似できる:h
t= Jh
t−1.(9)
そしてこのとき平衡点h
∗= 0
は安定である.補題
2
は|λ
1(
14W
hh+
12I ) | < 1
という条件を用い れば,平衡点の安定性を変化させないことができるこ とを示している.この制約は固有値に対する制約であ り,半正定値計画問題などで解くことも考えられるが,制約の範囲での学習率の探索などは計算量が大きく困 難である.そこで次の補題により式
(8)
のような特異 値制約とする:[補題
3
]σ
1( W
hh) < 2
であるならば|λ
1(
14W
hh+
1
2
I ) | < 1
が成り立つ.補題
1
〜3
を用いると定理1
は次のように証明で きる:証明 補題
1
より,平衡点h
∗= 0
が一層のGRU
に存 在する.この平衡点は補題2
より|λ
1(
14W
hh+
12I)| < 1
の と き 安 定 で あ り,補 題3
よ りσ
1(W
hh) < 2
で あれば|λ
1(
14W
hh+
12I ) | < 1
が成り立つ.よってσ
1( W
hh) < 2
であれば,一層のGRU
の平衡点h
∗= 0
は安定な平衡点である.
2
補題
1
は1
層のGRU
が平衡点をもつことを示し,補題
2
はその平衡点を安定に保つ条件を示す.補題3
は固有値に関する制約の代わりに特異値を使用できる ことを示し,これらの補題によって定理1
が証明され(注2):本論文中の補題の証明は全て付録に示す.
(注3):スペクトル半径とは最も大きな絶対値をもつ固有値の値である.
た.この定理は提案法が平衡点の不安定化による勾配 爆発を防ぐことを示している.
提案法で注目する平衡点は
h
∗= 0
である.この平 衡点は通常,状態の初期値として設定される値であり,2.
で説明したように0
にリセットされることでGRU
は完全に過去の情報を忘却する.もしh
∗= 0
が安 定であれば,0
近傍の状態が漸近的に0
に収束する.これは,入力なしに十分に時間がたてば
GRU
が過去 の情報を完全に忘却できることを示している.一方,|λ
1( J ) |
が1
よりも大きいと0
の平衡点は不安定とな る.これはh
tが自動的に0
となることがなく,人為 的にリセットしなければGRU
が過去の情報を完全に 忘却できないことを示している.また[25]
は状態が0
に収束する安定なRNN
のモデルがLSTM
やGRU
な どに匹敵する性能を達成することを示しており,GRU
をh
∗= 0
が安定となるように学習することは有効だ と考えられる.3. 1. 2
多層のGRU
提案法を多層の
GRU
に拡張する.L
層のGRU
をh
1,t= f
1( h
1,t−1, x
t) , h
2,t= f
2( h
2,t−1, h
1,t)
,. . . , h
L,t= f
L(h
L,t−1, h
L−1,t)
,とする.ここで
h
l,t∈ R
nl×1は長さn
lのl
層の状態 であり,f
lはl
層のGRU
(式(1)
〜(4)
)である.一 層のGRU
と同様にh
t= [h
T1,t, . . . , h
TL,t]
T= 0
は平 衡点であり,次の補題が成り立つ.[補題
4
] もしl = 1 , . . . , L
について|λ
1(
14W
l,hh+
1
2
I ) | < 1
であれば,多層に接続したGRU
の平衡点h
∗= 0
は安定である.補題
3
よりσ
1(W
l,hh) < 2
のとき|λ
1(W
l,hh+
1
2
I)| < 1
が成り立つ.そこで提案法をmin
θ1 N
N j=1C
(j), s . t . (10)
σ
1( W
l,hh) < 2 , σ
1( W
l,xh) ≤ 2 for l = 1 , . . . , L
. とする.ここでσ
1( W
l,xh) ≤ 2
という制約を加えた のは,入力によって状態が平衡点h
∗= 0
の吸引領域 を出ないように制約するためである.上記の学習法に よって多層のGRU
を安定に保った学習ができる.3. 2
アルゴリズム式
(8)
の最小化問題を解くためには{W
hh|W
hh∈
R
n×n, σ
1( W
hh) < 2 }
を満たす領域で解を探索しなけ ればならない.そこでSGD
を修正し,θ
(τ−W)hh= θ
(τ−W−1)hh− η∇
θC
Dτ( θ ) ,
W
hh(τ)= P
δ( W
hh(τ−1)− η∇
WhhC
Dτ( θ ))
,(11)
としてパラメータを更新する方法を提案する.ここでC
Dτ(θ)
は|D1τ|
(x(j),y(j))∈Dτ
C
(j)であり,θ
−W(τ)hh はW
hh(τ)を除く全てのパラメータである.式(11)
に おいてP
δ( · )
は次の手順で計算する:Step 1. W ˆ
hh(τ):= W
hh(τ−1)− η∇
WhhC
Dτ(θ)
を特 異値分解により分解する.W ˆ
hh(τ)= U ΣV
.(12) Step 2.
しきい値2 − δ
以上の特異値をしきい値に 置換する.Σ ¯ = diag(min(σ
1, 2 − δ), . . . , min(σ
n, 2 − δ))
.(13)
ここでσ
1, . . . , σ
nはW ˆ
hh(τ)の第一特異値から第n
特 異値である.Step 3. W
hh(τ)をU
とV
,Σ ¯
により再構築する.W
hh(τ)← U ΣV ¯
.(14)
この手順によってW
hh は2 − δ
以下のスペクトルノ ルムをもつことが保証される.δ
を0 < δ < 2
となる ように設定すれば,提案法のσ
1(W
hh)
が2
より小さ いという制約が満たされる.P
δ(·)
はSGD
によって パラメータが実行可能集合の外に出た場合に,実行可 能集合に戻すアルゴリズムであり,次の補題に示すよ うに実行可能集合への最適な射影である[31]
.[補題
5
]P
δ(·)
によって得られるW
hh(τ)は最適化問題min
Whh(τ)
|| W ˆ
hh(τ)− W
hh(τ)||
2F, s . t . σ
1( W
hh(τ)) ≤ 2 − δ
, の解である.ここで|| · ||
2F はフロベニウスノルムで ある.補題
5
は提案法が最小のパラメータの変化でW
hhを実行可能集合に戻すことを示し,
P
δ( · )
が損失関数 の最小化に最小の影響を与えることを示している.な お提案法は学習率の設定法によらず,Adam [32]
など ともに使用することも可能である.3. 3
提案法の計算量の低減化n
を状態h
tの大きさとすると,特異値分解にはO ( n
3)
の計算量が必要である.この節では計算量の低 減化を考える.まずP
δ( · )
の計算方法について再考する.式
(12)
〜(14)
はW
hh(τ)= ˆ W
hh(τ)−
s i=1σ
i( ˆ W
hh(τ)) − (2 − δ )
u
iv
iT,(15)
とみなすことができる.ここでs
は2 − δ
より大き な特異値の数であり,u
iとv
iはi
番目の左右の特異 ベクトルである.式(15)
は提案法が計算しなければ ならない特異値,特異ベクトルがσ
i( ˆ W
hh(τ)) > 2 − δ
を満たすs
個のみでよいことを示す.そこで計算コ ストを減らすため高速にトップs
の特異値,特異ベ クトルを計算できる特異値分解[33]
を用いる(以後,truncated SVD
と呼ぶ).この方法はs
個の特異値をO ( n
2log( s ))
時間で計算可能である.ただし事前にs
が必要なため,σ
i( ˆ W
hh(τ)) > 2 − δ
である特異値の数 を見積もらなければならない.そこで次の補題による 上限を使ってs
を効率的に見積もる.[補題
6
]W ˆ
hh(τ)の特異値はσ
i( ˆ W
hh(τ)) ≤ σ
i( W
hh(τ−1))+
|η|||∇
WhhC
Dτ( θ ) ||
F によって上から抑えられる.この上界を使うことにより,更新前のパラメータ の 特 異 値 と 勾 配 が わ か れ ば ,
2 − δ
よ り 大 き な 特 異値の数s
の値を推定できる.なおこの上界の計 算量は∇
WhhC
Dτ( θ )
のサイズがn × n
であり,τ
ス テップ でσ
i( W
hh(τ−1))
が 既 に 得 ら れ て い る た め ,O(n
2)
で あ る .も しτ − K
ス テップ か らτ − 1
ス テップ ま で 過 去 の 特 異 値 を 計 算 し な かった 場 合 は,σ
i( W
hh(τ−K−1)) +
Kk=0
|η|||∇
WhhC
Dτ−k( θ ) ||
Fとして
σ
i( ˆ W
hh(τ))
の上界を計算する.なお,もとも と の 制 約 がσ
1( W
hh(τ)) < 2
で あ る こ と か ら ,s
をσ
i( ˆ W
hh(τ)) > 2 − δ
の代わりにσ
i( ˆ W
hh(τ)) ≥ 2
を満 たす特異値の数とすると更に速度を向上できる.以上 より提案法は毎ステップO ( n
2)
でs
の大きさを見積 もる.そしてs
が1
以上のときだけ,O ( n
2log( s ))
の 計算量で特異値分解を行う.4.
実 験4. 1
実 験 条 件提案法を評価するため,言語モデリングの実験と音 楽のモデリングの実験を行った.
GRU
を学習させ,学 習の成功率と検証データに対する損失の平均と分散を 評価した.学習の成功は,初期化したモデルに対する 検証損失を各エポック終了後の検証損失が一度も超え ることなく全エポック終了することとした.各実験条 件は以下のとおりである.4. 1. 1 Language modeling
本 実 験 で は
Penn Treebank
(PTB
)[34]
とWikiText-2 dataset
(WT2
)[35]
という二つのデー タセットを用いて言語モデリングの実験を行った.こ れらのデータセットはRNN
の性能評価に広く用いら れている.PTB
はtraining
とvalidation
,test
セット にわかれ,それぞれ約930k
,74k
,80k
単語である.語 彙数は10k
とし,語彙にない単語については特別な単 語< UNK >
を割り当てた.一方,WT2
はtraining
が 約2100k
単語,validation
が220k
単語,そしてtest
が250k
単語からなり,語彙数は33,278
単語である.実験条件は既存研究の
[36]
をもとに設定した.モデ ルの一層目を650 × 10 , 000
のバイアスなしの線形層(
embedding layer
)とした.提案法で入力が大きすぎ ると平衡点近傍から状態が離れてしまうことが考えら れるので一層の出力に0.01
倍した.次の層は650
ユ ニットのGRU
層とし,出力にソフトマックス関数を 用いた.50%
のドロップアウトをGRU
の再帰的な結 合を除く各層に適用した[36]
.学習には予備実験にお いてAdam
とRMSprop
の性能がSGD
に劣ったた め,SGD
を用いた.まず重み行列の初期化として
W
hhを除く全ての行 列を正規分布N (0 , 1 / 650)
から生成した.W
hh は乱 数生成した行列を特異値分解し,得られた特異ベク トルを用いることで直交行列となるように初期化し た[7], [37]
.ミニバッチの大きさを20
,SGD
の学習率 は1
とし,最初の10
エポックの後は毎ステップ1.1
で 除算して75
エポックまで学習させた.なお学習時に は再帰的な結合の途中で逆誤差伝搬を打ち切るtrun- cated BPTT
を使用し,35
時間ステップで打ち切った.提案法において
δ
を[0.2, 0.5, 0.8, 1.1, 1.4]
としてそ れぞれ学習させ,一方,勾配クリッピングでは[4]
の勾 配のノルムの平均に注目するというヒューリスティク スに従って平均を調べたところPTB
が約10
,WT2
が約7
であったので,それをもとにPTB
ではしきい 値を[5, 10, 15, 20]
,WT2
では[3.5, 7.0, 10.5, 14]
とした.各エポックの後に
validation
データに対する 損失(以後,validation loss
と呼ぶ)を評価し,75
エ ポックの間で最も小さなvalidation loss
となったモデ ルを用いてtest
データで評価した.4. 1. 2 Polyphonic Music Modeling
この実験では,音楽の
MIDI
データに対して過去の ノート番号から次に出てくるノート番号を予測する実 験を行った.なお言語モデリングと異なりノート番号は各時刻で複数出力される.データセットには
1200
のフォーク音楽で構成されるNottingham
データセッ ト[38]
を用いた.なおデータセットはPTB
と同様にtraining
とvalidation
,test
セットに分かれる.実験 条件は[8]
をもとに設定した.各時刻のノート番号を93
次元のバイナリベクトルで表現した.モデルの一層 目をバイアスなしの200 × 93
の線形層(embedding layer
)とし,言語モデルと同様に出力を0.01
倍した.2
層と3
層を200
ユニットのGRU
層とし,出力は ロジスティック関数とした.50%
のドロップアウトをGRU
の再帰的な結合をのぞく各層に適用した.学習は言語モデルと同様に
SGD
を使用し,初期化はW
hhを除く全ての行列を正規分布N (0 , 10
−4/ 200)
か ら生成し,W
hhは同様の手順で直交行列となるように 初期化した.ミニバッチの大きさを20
,BPTT
の打ち 切りを35
とし,SGD
の学習率は0.1
として10
エポッ ク連続してvalidation loss
の低下がみられないとき1.25
で除算した.この手順で学習率が10
−4以下となる まで学習させた.提案法はδ
を[0 . 2 , 0 . 5 , 0 . 8 , 1 . 1 , 1 . 4]
とし,勾配クリッピングは勾配のノルムの平均が約
30
であったため[15, 30, 45, 60]
とした.各エポックの後 にvalidation
データに対する損失(以後,validation loss
と呼ぶ)を評価し,最も小さなvalidation loss
と なったモデルを用いてtest
データで評価した.4. 2
成功率と精度表
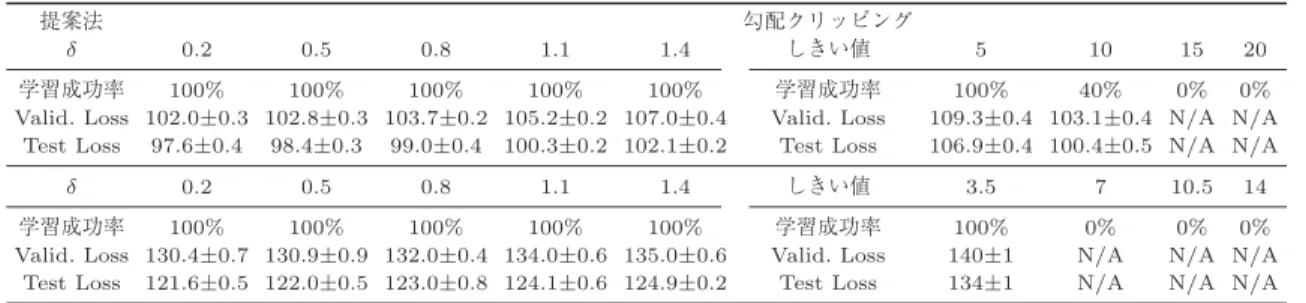
1
と2
に言語モデルと音楽モデル,それぞれの 学習成功率とvalidation
データとtest
データに対す る損失の平均と標準偏差を示す.表
1
より,言語モデリングにおいて勾配クリッピン グは勾配のノルムの平均10
(PTB
)や7
(WT2
)に しきい値を設定しても学習が失敗していることがわか る.しきい値を平均の0.5
倍とすることで学習は成功 するが,PTB
の場合,しきい値を平均とした結果よ りperplexity
が大きくなった.表2
の音楽のモデリン グでは勾配クリッピングにより学習が失敗していない が,しきい値を60
に設定すると非常に標準偏差が大き い.一方,提案法は言語データで学習が失敗しておら ず,perplexity
,負の対数ゆう度ともに勾配クリッピ ングよりも小さい.提案法において制約により解空間 が小さくなっているにもかかわらずGRU
の性能が向 上したのは状態が安定であるためと考えられる.例え ば[39]
において安定化したRNN
が複数のタスクで性 能が向上することが示されている.また[5]
では安定 な平衡点近傍に状態があるとき,ノイズに対してロバ表1 言語モデルの結果:成功率とperplexity.上段はPTBの結果,下段はWT2の結 果でありValid.はValidationを表す.
提案法 勾配クリッピング
δ 0.2 0.5 0.8 1.1 1.4 しきい値 5 10 15 20
学習成功率 100% 100% 100% 100% 100% 学習成功率 100% 40% 0% 0%
Valid. Loss 102.0±0.3 102.8±0.3 103.7±0.2 105.2±0.2 107.0±0.4 Valid. Loss 109.3±0.4 103.1±0.4 N/A N/A Test Loss 97.6±0.4 98.4±0.3 99.0±0.4 100.3±0.2 102.1±0.2 Test Loss 106.9±0.4 100.4±0.5 N/A N/A
δ 0.2 0.5 0.8 1.1 1.4 しきい値 3.5 7 10.5 14
学習成功率 100% 100% 100% 100% 100% 学習成功率 100% 0% 0% 0%
Valid. Loss 130.4±0.7 130.9±0.9 132.0±0.4 134.0±0.6 135.0±0.6 Valid. Loss 140±1 N/A N/A N/A Test Loss 121.6±0.5 122.0±0.5 123.0±0.8 124.1±0.6 124.9±0.2 Test Loss 134±1 N/A N/A N/A
表2 音楽データのモデリング結果:学習成功率と負の対数ゆう度
提案法 勾配クリッピング
δ 0.2 0.5 0.8 1.1 1.4 しきい値 15 30 45 60
学習成功率 100% 100% 100% 100% 100% 学習成功率 100% 100% 100% 100%
Validation Loss 3.46±0.05 3.47±0.07 3.59±0.1 4.58±0.2 4.64±0.2 Validation Loss 3.57±0.01 3.61±0.2 3.88±0.2 5.26±3 Test Loss 3.53±0.04 3.53±0.04 3.64±0.2 4.56±0.2 4.62±0.2 Test Loss 3.64±0.04 3.64±0.2 3.89±0.2 5.36±3
ストになることが指摘されており,
GRU
のLSTM
に 対する優位点であるノイズにロバストという利点[40]
が提案法により強調されたと考えられる.
4. 3 δ
の大きさと状態の収束表
2
より,δ
を1.1
あるいは1.4
に設定するとGRU
の性能が落ちる.これはδ
が大きいほど状態の平衡点 への収束速度が上がり長期的な依存関係を捉えられな くなるためと考えられる.提案法においてW
hhのス ペクトルノルムは2 − δ
以下である.これはスペクト ル半径|λ
1( J ) |
の上界であり,|λ
1( J ) |
は線形化したGRU
(式(9)
)の収束性を決める.そのためh
t= 0
近傍の状態はδ
が2
に近いほど速く平衡点に収束する と考えられる.実際に状態の収束性を確認するため,簡単なシミュ レーションを行った.提案法のそれぞれ
δ = 0 . 2 , 0 . 8 , 1 . 4
で学習 したモ デルのGRU
層 に 時 刻1
で 正 規 分布N (0 , 0 . 01 I )
に従うノイズを入力として加え,その後 入力を全く与えずに状態を時間変化させて各時刻の状 態のノルム||h
t||
2を計算した.また特定の入力に対す る結果とならないように同様の実験を50
回行った.各時刻の状態ベクトルの
l
2ノルムを50
回の試行に 対して平均した結果を図2
に示す.図2
より,提案 法のGRU
は状態のノルムが0
に指数関数的に収束し てh = 0
が安定であるとともに,δ
が大きくなるに 従いその収束が速くなっている.よって提案法はδ
の 値によって状態の収束性を調整できることがわかる.収束が速いほど過去のノイズの影響が小さくなりロバ ストであると考えられるが,一方で
GRU
が過去の情図2 時刻1で入力を与え,その後入力を与えずに状態を 更新させたときのGRUの状態のノルムの時間変化
報を長期間にわたって記憶できなくなる.こうした特 性を考慮してノイズの多いデータには大きな
δ
を,長 期間の依存性があるデータには小さなδ
を使用する.なお同様の実験を勾配クリッピングで学習したモデル で行ったところ,勾配のノルムはほとんど変化せず約
4.7
となり,提案法と比べ非常に大きな値となった.以上のように提案法の調整パラメータはモデルへの 影響が解釈しやすく,また
0 < δ < 2
という範囲に制 限されている.一方で勾配クリッピングのしきい値は モデルにどのような影響を与えるかの解釈が困難であ り,その範囲も制限されず調整が難しい.4. 4
勾配とスペクトル半径の関係提案法は状態の平衡点の安定性の変化が勾配爆発を 引き起こすという仮説のもとで状態を安定に制約し ている.本節ではこの仮説を検証するため,学習の最 初の
500
反復の間の安定性を決めるJ
のスペクトル図3 言語モデルにおいて学習中の勾配爆発
半径の時間変化と勾配のノルムの時間変化(勾配ク リッピングの結果はクリップ前の勾配)を図
3
に示す.図
3 (a)
はしきい値5
の勾配クリッピングを使用した 学習の結果で図3 (b)
はδ
を0.2
に設定した提案法の 学習の様子である.なお勾配のノルムは最大が1
とな るように正規化しており,正規化前の提案法の値は勾 配クリッピングと比べ非常に小さい.図3 (a)
より,勾 配のノルムは平衡点が不安定化するスペクトル半径が1
を横切るときに非常に大きな値になっている.また 勾配が非常に大きくなったのちに,スペクトル半径は1
以下となっており,勾配爆発が生じた際の勾配の方 向がスペクトル半径を小さくする方向に動いているこ とがわかる.一方,提案法は図3 (b)
より明らかなよ うに,W
hhのスペクトルノルムを制約することによ りスペクトル半径が1
よりも小さくなるように制約さ れており,勾配爆発を起こさずに学習が進んでいる.なお提案法で
δ
を負の値とすると,提案法の制約は スペクトル半径が1
より大きくなることを許すが,実 際にδ = − 0 . 2
で実験させたところ勾配が非常に大き な値となり学習が失敗することを確認した.4. 5
計算時間の比較PTB
の言語モデルの実験において計算時間を比較 した結果を表3
に示す.この表は提案法に通常の特 異値分解(naive SVD
)とtruncated SVD
を用いて それぞれ学習させた計算時間,そして勾配クリッピン表3 言語モデル(PTB)の計算時間(δ0.2,
しきい値5)
計算時間(s)
Naive SVD Truncated SVD 勾配クリッピング 5.02×104 4.55×104 4.96×104
表4 状態数1300としたPTBの言語モデルの結果
(δ0.2,しきい値5)
Valid. Loss Test Loss 計算時間(s)
Truncated SVD 108.0±0.2 104.2±0.4 10.7×104 勾配クリッピング 116.5±0.9 115.0±0.6 7.02×104
グの計算時間である.表より
naive SVD
を用いた提 案法が勾配クリッピングと同程度の計算時間であり,truncated SVD
を用いた提案法が最も速かった.2. 1
で述べたように勾配クリッピングでは,モデル全体の パラメータに対する勾配のノルムを計算するため,言 語モデルにおいて語彙数に依存した入出力層の大きな パラメータ数が計算時間に影響をあたえる.一方,提 案法はGRU
の状態ベクトルのサイズのみに依存し,更に
3. 3
のように制約を超える特異値が存在しなけれ ば高速に計算できる.結果として提案法と勾配クリッ ピングの計算時間は同程度となった.4. 6
モデルサイズによる計算時間と精度の変化 これまで[36]
をもとに,状態数650
のGRU
による 言語モデルによって提案法を評価した.しかし[41]
で はより大きなサイズのLSTM
のモデルで言語モデル の実験を行い高い精度の結果を示している.そこで本 節ではより大きなモデルサイズに設定した際の提案法 の評価を行う.PTB
の言語モデルにおいてGRU
の 状態数を前節までの実験の倍の1300
として実験し,精度と計算時間を評価した結果を表
4
に示す.なお状 態数以外の実験条件は変更せずδ = 0 . 2
,しきい値5
での結果である.表4
より,モデルサイズが大きい場 合にも提案法が勾配クリッピングより高い精度を達成 していることがわかる.ただしこれらは状態数650
のGRU
の結果より精度が低い.一方,計算時間は提案 法が約1.5
倍ほど長い.これは提案法の特異値分解の 計算量は状態数n
に対してO ( n
2log( s ))
であることが 原因である.以上より提案法はGRU
の状態数の増加 によって勾配クリッピングより計算時間が長くなるが,今回の実験では計算時間が勾配クリッピングを大きく 上回るような状態数は必要とせず,また精度において 提案法の有効性は状態数の増加によって変化しない.
5.
む す び本論文では
GRU
の状態の振る舞いを解析し,勾配 爆発を防ぐ新たな学習法を提案した.言語モデルと音 楽モデルの実験において提案法が勾配クリッピングと 同程度の計算時間で勾配爆発を抑制し,更に勾配ク リッピングより高い精度を達成できることを示した.勾配クリッピングは試行錯誤的にそのしきい値を調整 する必要があるが,しきい値がモデルに与える影響は 不明瞭であり,またその調整の範囲も限定されていな い.一方,提案法の
δ
も多少の調整を必要とするが,その効果は解釈しやすく,またその範囲も
0 < δ < 2
に限定されるためにGRU
を使ったモデル構築にかか る試行錯誤を削減できる.文 献
[1] A. Graves, A.-R. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,”
Proc. IEEE International Conf. on Acoustics, Speech, and Signal Processing, pp.6645–6649, May 2013.
[2] T. Mikolov, Statistical Language Models Based on Neural Networks, PhD thesis, Brno University of Technology, 2012.
[3] A. Graves and J. Schmidhuber, “Offline handwriting recognition with multidimensional recurrent neural networks,” Proc. Annual Conf. on Neural Informa- tion Processing Systems, pp.545–552, Dec. 2009.
[4] R. Pascanu, T. Mikolov, and Y. Bengio, “On the dif- ficulty of training recurrent neural networks,” Proc.
International Conf. on Machine Learning, pp.1310–
1318, June 2013.
[5] Y. Bengio, P. Simard, and P. Frasconi, “Learning long-term dependencies with gradient descent is diffi- cult,” IEEE Trans. Neural Netw., vol.5, no.2, pp.157–
166, Jan. 1994.
[6] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol.9, no.8, pp.1735–
1780, Nov. 1997.
[7] K. Cho, B. Van Merri¨enboer, C. Gulcehre, D.
Bahdanau, F. Bougares, H. Schwenk, and Y. Ben- gio, “Learning phrase representations using RNN encoder–decoder for statistical machine translation,”
Proc. Conf. on Empirical Methods in Natural Lan- guage Processing, pp.1724–1734, Oct. 2014.
[8] R. Jozefowicz, W. Zaremba, and I. Sutskever, “An empirical exploration of recurrent network architec- tures,” Proc. International Conf. on Machine Learn- ing, pp.2342–2350, July 2015.
[9] S. Kanai, Y. Fujiwara, and S. Iwamura, “Preventing gradient explosions in gated recurrent units,” Proc.
Annual Conf. on Neural Information Processing Sys- tems, pp.435–444, Oct. 2017.
[10] S. Wiggins, Introduction to applied nonlinear dy- namical systems and chaos, vol.2, Springer Science
& Business Media, 2003.
[11] K. Doya, “Bifurcations in the learning of recurrent neural networks,” Proc. IEEE International Sympo- sium on Circuits and Systems, vol.6, pp.2777–2780, May 1992.
[12] P. Baldi and K. Hornik, “Universal approximation and learning of trajectories using oscillators,” Proc.
Annual Conf. on Neural Information Processing Sys- tems, pp.451–457, Dec. 1996.
[13] C.-M. Kuan, K. Hornik, and H. White, “A con- vergence result for learning in recurrent neural net- works,” Neural Computation, vol.6, no.3, pp.420–
440, May 1994.
[14] W. Yu, “Nonlinear system identification using discrete-time recurrent neural networks with stable learning algorithms,” Inf. Sci., vol.158, pp.131–147, Jan. 2004.
[15] H. Jaeger, Tutorial on training recurrent neural net- works, covering BPPT, RTRL, EKF and the “echo state network” approach, GMD-Forschungszentrum Informationstechnik, 2002.
[16] M. Arjovsky, A. Shah, and Y. Bengio, “Unitary evolution recurrent neural networks,” Proc. Inter- national Conf. on Machine Learning, pp.1120–1128, June 2016.
[17] E. Vorontsov, C. Trabelsi, S. Kadoury, and C. Pal,
“On orthogonality and learning recurrent networks with long term dependencies,” Proc. International Conf. on Machine Learning, pp.3570–3578, Aug.
2017.
[18] J. Zhang, Q. Lei, and I. Dhillon, “Stabilizing gra- dients for deep neural networks via efficient SVD parameterization,” Proc. International Conf. on Ma- chine Learning, vol.80, pp.5806–5814, July 2018.
[19] B. Doyon, B. Cessac, M. Quoy, and M. Samuelides,
“Destabilization and route to chaos in neural net- works with random connectivity,” Proc. Annual Conf. on Neural Information Processing Systems, pp.549–555, Dec. 1993.
[20] N.E. Barabanov and D.V. Prokhorov, “Stability analysis of discrete-time recurrent neural networks,”
IEEE Trans. Neural Netw., vol.13, no.2, pp.292–303, March 2002.
[21] J.A. Suykens, B. De Moor, and J. Vandewalle, “Ro- bust local stability of multilayer recurrent neural networks,” IEEE Trans. Neural Netw., vol.11, no.1, pp.222–229, Jan. 2000.
[22] R. Haschke and J.J. Steil, “Input space bifurcation manifolds of recurrent neural networks,” Neurocom- puting, vol.64, pp.25–38, 2005.
[23] H. Nakahara and K. Doya, “Dynamics of attention as near saddle-node bifurcation behavior,” Proc. An- nual Conf. on Neural Information Processing Sys-
tems, pp.38–44, Dec. 1996.
[24] S.S. Talathi and A. Vartak, “Improving performance of recurrent neural network with relu nonlinearity,”
arXiv preprint arXiv:1511.03771, 2015.
[25] T. Laurent and J. von Brecht, “A recurrent neural network without chaos,” Proc. International Conf. on Learning Representations, April 2017.
[26] D.M. Stipanovi´c, B. Murmann, M. Causo, A. Leki´c, V.R. Royo, C.J. Tomlin, E. Beigne, S. Thuries, M.
Zarudniev, and S. Lesecq, “Some local stability prop- erties of an autonomous long short-term memory neu- ral network model,” Proc. IEEE International Sym- posium on Circuits and Systems, pp.1–5, May 2018.
[27] Y. Yoshida and T. Miyato, “Spectral norm regu- larization for improving the generalizability of deep learning,” arXiv preprint arXiv:1705.10941, 2017.
[28] M. Cisse, P. Bojanowski, E. Grave, Y. Dauphin, and N. Usunier, “Parseval networks: Improving robust- ness to adversarial examples,” Proc. International Conf. on Machine Learning, pp.854–863, Aug. 2017.
[29] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida,
“Spectral normalization for generative adversarial networks,” arXiv preprint arXiv:1802.05957, 2018.
[30] H. Sedghi, V. Gupta, and P.M. Long, “The singu- lar values of convolutional layers,” arXiv preprint arXiv:1805.10408, 2018.
[31] S. Lefkimmiatis, J.P. Ward, and M. Unser, “Hes- sian Schatten-norm regularization for linear inverse problems,” IEEE Trans. Image Process., vol.22, no.5, pp.1873–1888, May 2013.
[32] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” Proc. International Conf.
on Learning Representations, May 2015.
[33] N. Halko, P. Martinsson, and J. Tropp, “Finding structure with randomness: Stochastic algorithms for constructing approximate matrix decompositions,”
arXiv preprint arXiv:0909.4061, 2009.
[34] M.P. Marcus, M.A. Marcinkiewicz, and B. Santorini,
“Building a large annotated corpus of English: The Penn treebank,” Computational Linguistics, vol.19, no.2, pp.313–330, June 1993.
[35] S. Merity, C. Xiong, J. Bradbury, and R. Socher,
“Pointer sentinel mixture models,” Proc. Interna- tional Conf. on Learning Representations, April 2017.
[36] W. Zaremba, I. Sutskever, and O. Vinyals, “Recur- rent neural network regularization,” arXiv preprint arXiv:1409.2329, 2014.
[37] A.M. Saxe, J.L. McClelland, and S. Ganguli, “Ex- act solutions to the nonlinear dynamics of learning in deep linear neural networks,” Proc. International Conf. on Learning Representations, April 2014.
[38] N. Boulanger-Lewandowski, Y. Bengio, and P.
Vincent, “Modeling temporal dependencies in high- dimensional sequences: Application to polyphonic music generation and transcription,” Proc. Interna-
tional Conf. on Machine Learning, pp.1159–1166, June 2012.
[39] D. Krueger and R. Memisevic, “Regularizing RNNs by stabilizing activations,” Proc. International Conf.
on Learning Representations, May 2016.
[40] Z. Tang, Y. Shi, D. Wang, Y. Feng, and S. Zhang,
“Memory visualization for gated recurrent neural networks in speech recognition,” Proc. IEEE Inter- national Conf. on Acoustics, Speech, and Signal Pro- cessing, pp.2736–2740, March 2017.
[41] Z. Yang, Z. Dai, R. Salakhutdinov, and W.W. Cohen,
“Breaking the softmax bottleneck: A high-rank RNN language model,” Proc. International Conf. on Learn- ing Representations, April 2018.
[42] G. Strang, Calculus (2nd ed.), Wellesley-Cambridge Press, 2010.
[43] R.A. Horn and C.R. Johnson, Matrix analysis (2nd ed.), Cambridge University Press, 2012.
[44] R.A. Horn and C.R. Johnson, Topics in matrix anal- ysis, Cambridge University Press, 1991.
付 録
1.
補題1
の証明証明 入力
x
t= 0
と状態h
t−1= 0
を式(1)
と(2)
に 代入すると,更新ゲートがz
t=
12 となり,リセット ゲートはr
t=
12 となる.そしてx
t= 0
とh
t−1= 0
,r
t=
12 を式(4)
に代入すると˜ h
t= 0
となる.最後にh
t−1= 0
とz
t=
12,h ˜
t= 0
を式(3)
に代入すると新 たな状態がh
t= 0
となり,したがってh
t−1= h
t= 0
が成り立つため,GRU
は平衡点h
∗= 0
をもつ.2
2.
補題2
の証明証明 局所的な安定性は平衡点近傍で線形化したシス テムの安定性の解析によって判断できる
[10]
.入力が ないとき,h
∗= 0
で線形化したGRU
はテイラー展 開[42]
によってh
t= Jh
t−1,(A · 1)
となる.式(A · 1)
でJ
はh
tの,h
t−1= 0
とx
t= 0
におけるh
t−1に関するヤコビ行列でありJ = ∂h
t∂h
t−1ht−1=0,xt=0