CUDA による高速な磁束クリープ・フローモデルの 数値計算と性能評価
松下研究室 石橋 知裕
平成 23 年 2 月 18 日
電子情報工学科
目次
第 1 章 序章 1
1.1 はじめに . . . . 1
1.2 CUDA . . . . 2
1.2.1 CUDA とは . . . . 2
1.2.2 プログラムの構成 . . . . 2
1.2.3 CUDA のアーキテクチャ . . . . 3
1.3 NDIVIA の GPU の構造 . . . . 3
1.4 SPMD 演算 . . . . 4
1.5 SIMD 演算 . . . . 4
1.6 磁束クリープフローモデル . . . . 5
1.6.1 磁束ピンニング . . . . 5
1.6.2 磁束クリープ . . . . 5
1.6.3 磁束フロー . . . . 8
1.6.4 磁束クリープ・フローモデル . . . . 12
1.7 Simpson 法 . . . . 14
1.7.1 計算誤差を確かめる . . . . 14
1.8 遺伝的アルゴリズム . . . . 15
1.8.1 概要 . . . . 15
1.8.2 個体操作 . . . . 15
1.8.3 実数値 GA . . . . 17
1.8.4 島モデル . . . . 17
1.9 目的 . . . . 18
第 2 章 実験 19 2.1 実験環境 . . . . 19
2.2 磁束クリープ・フローモデルの並列計算の最適手法 . . . . 19
2.2.1 手法 A(simpson) . . . . 19
2.2.2 手法 B(E-J) . . . . 19
2.3 GA による磁束クリープ・フローモデルのピンニングパラメータ探
索プログラムの高速化 . . . . 20
第 3 章 結果と考察 21 3.1 磁束クリープ・フローモデルの並列計算の最適手法 . . . . 21 3.2 磁束クリープ・フローモデルの並列計算の最適手法 . . . . 21 3.2.1 手法 B . . . . 22 3.3 GA による磁束クリープ・フローモデルのピンニングパラメータ探
索プログラムの高速化 . . . . 22 3.3.1 計算時間 . . . . 22
第 4 章 まとめ 23
4.1 まとめ . . . . 23 4.2 今後の課題 . . . . 23
参考文献 25
図 目 次
1.1 NVIDIA の GPU の構造 . . . . 3
1.2 SIMD 演算 . . . . 4
1.3 磁束バンドルの位置とエネルギーの関係 . . . . 6
1.4 磁束線が平衡位置から変位したときの (a) ピン力密度および (b) ピ ンニング・エネルギー密度の変化 . . . . 10
1.5 磁束バンドルの形状 . . . . 11
1.6 Simpson 法の分割数と誤差 . . . . 14
1.7 BLX-α . . . . 18
3.1 コア数に対する処理速度の関係 . . . . 21
表 目 次
1.1 メモリの種類 . . . . 3
2.1 実験環境 . . . . 19
3.1 CPU と GPU の処理時間 . . . . 22
第 1 章 序章
1.1 はじめに
GPU(Graphics Processing Units) は一般的に画像処理を専門とする演算装置で あり、多くの場合、CPU(Central Processing Unit) と呼ばれる主演算装置の制御 の下で用いられる動画信号生成専用の補助演算用 IC(Integrated Circuit) である。
画像処理の実時間内での生成は高負荷な演算能力が要求されるが、その多くが定 式化された単純な演算の繰り返しであるためハードウェア化に向いており、GPU を製造している半導体メーカー数社からは、高速なメモリ・インターフェース機 能と高い画像演算能力を備えた IC 製品のシリーズがいくつも製造・販売されてい る。特に 1990 年代中盤以降は 3D 描画性能が劇的に向上し、それに伴い行列演算 を中心とした SIMD(Single Instruction Multiple Data) 演算機の色彩が強くなって きた。2000 年代に入ると、表現力の向上を求めて GPU がシェーダ機能を強化す るにつれ、OpenGL や Direct3D といった主なグラフィックライブラリは API に専 用のプログラマブル(プログラム可能)なシェーディング機能(プログラマブル シェーダ)を備えるようになり、演算の自由度が飛躍的に増した。そこでプログラ マブルシェーダをグラフィック・レンダリングのみならず、他の数値演算にも利用 するのが GPGPU(General-purpose computing on graphics processing units) の コンセプトである。
GPU の浮動小数点演算能力は 2005 年頃に 100GFLOPS をオーバーした一方で、
CPU の浮動小数点演算能力は頭打ち状態にあり、 2007 年時点で数十 GFLOPS の水 準に留まっている。GPU は構成が単純であるために浮動小数点演算での効率がよ く、 GPU 専用にローカル接続されたメモリ IC とのメモリバンド幅を広く備えるた めに、CPU と比べて性能比で安価かつ成長の伸び率が高い。また主な使途がパソ コンゲームと動画再生で、ゲームをしないユーザーにとって余り気味の資源という こともあって注目されている。 DirectX 9.0 の登場以降、 NVIDIA 社による GPGPU 専用の統合開発環境「CUDA(Compute Unified Device Architecture)」や、AMD 社の「ATI Stream」が現われ、 GPGPU 活用の幅が広がりつつある。また NVIDIA 社は自社の GPU「G80」をベースにした HPC(High-Performance Computing) 向
け GPGPU「Tesla」を投入するなど、従来のベクトル計算機からの置き換えを視
野に置いた市場展開を行っている。
苦手だった GPU は倍精度の浮動小数点演算も、GPU から派生して新たに開発
された GPGPU 用の IC では、倍精度浮動小数点演算やより広いメモリ空間に対応
したものがあり、これらは広範な科学技術計算への利用が期待される。
1.2 CUDA
1.2.1 CUDA とは
CUDA(Compute Unified Device Architecture)とは、NVIDIA 社が提供する GPU 向けの C 言語の統合開発環境であり、コンパイラやライブラリなどから構成 されている。
1.2.2 プログラムの構成
スレッド
SP 上で動作するプログラムの最小単位
ブロック
スレッドをまとめたもの 1 ブロック内の最大スレッド数は 512 最大 3 次元まで拡 張できる
グリッド
ホスト側から GPU がカーネル関数で実行された時、指定されたブロックを制 御する。ブロックをまとめたもの。1 グリッド内の最大ブロック数は 65535 最大 2 次元まで拡張できる 1 グリッドあたりの最大スレッド数は,65535x65535x512=
2198956147200。
プログラミング
プログラムには、 CUDA の特性に合わせた数値解析の最適化をするために、メモ リの最適化と、スレッドの最適化をした。メモリの最適化とは、 GPU 上にある複数 のメモリの特性に合わせた活用をしてメモリアクセス回数、メモリの使用量を減ら すことである。次にスレッドの最適化とは、CUDA の場合ウォープ (32 スレッドで 1ウォープ) 毎に条件分岐の判断し、 SIMD 演算をするので、 1 ウォープ中に分岐が 起きるとウォープ・ダイバージェントが発生し処理速度の低下の原因となる。つま り、ブロック単位では複数の命令と複数のデータを扱い、同時に処理を行う SPMD
(Single Program/Multiple Data)演算を行う。スレッド単位では複数のデータをベ
クトルとして扱い、同時に処理を行う SIMD(Single Instruction/Multiple Data)
演算を行うように構成した。
1.2.3 CUDA のアーキテクチャ
1.3 NDIVIA の GPU の構造
GPU は実際に演算を行う SP(Scalar Processor)。プログラムを取得し、プロセッ サが理解できる形式に変更し、SP に伝える SM(Streaming Multi-processor) と用 途の違う複数のメモリで構成されている。
図 1.1: NVIDIAのGPUの構造
表1.1: メモリの種類
メモリの種類
ホスト側の アクセス
デバイス側の アクセス
アクセス時間
[Clock] スコープ 容量 場所
Register N/A R/W 1 スレッド 8192[bit] チップ上
Shared Memory N/A R/W 4〜16 ブッロク 16[kB] チップ上
Constant Cache N/A R 1 スレッド - チップ上
Texture Cache N/A R 4〜16 スレッド - チップ上
Global Memory R/W R/W 100〜 グリッド 128[MB]〜2[GB] チップ外
Local Memory N/A R/W 100〜 グリッド - チップ外
Constant Memory W R - グリッド - チップ外
Texture Memory W R - グリッド - チップ外
※ N/A:アクセス不可、R:読み込み可能、W:書き込み可能
※アクセス時間・容量は、GTS250 の性能
1.4 SPMD 演算
SPMD (Single Process、 Multiple Data) は、複数のプロセッサが同時並行的に同 じプログラムを実行する。ただし、 SIMD や MISD (Multiple Instruction 、 Multiple
Data) のように同じ箇所ではなく、それぞれ別の箇所を実行し、別々のデータを
使用する。
1.5 SIMD 演算
SIMD(Single Instruction Multiple Data) とは、演算装置において 1 回の命令で 複数データに対する処理を同時に行うもの。演算装置設計手法の 1 つ。例えば、通 常 32 ビットのデータを受け付けるプロセッサなら 128 ビットのデータを 4 回のク ロックで計算するが、128 ビットのデータを受け付けるプロセッサは、 1 回のクロッ クで処理が済む。ただ多くの場合、128 ビットを使い切るデータはあまりなく、一 般に 128 ビットを 2 分割し 64 ビットとして使うか、4 分割して 32 ビットとして使 うが、結局それぞれ 1 回のクロックで 2 倍、4 倍のデータ処理が可能になり、結果 として相対的に低いクロックでも高い性能を引き出しやすい。
図1.2: SIMD演算
1.6 磁束クリープフローモデル
1.6.1 磁束ピンニング
直流電気抵抗無しで超伝導状態である超伝導体に流すことができる最大の電 流を I
c、電流密度を J
cという。J
cは超伝導体の特性を評価する上で重要な値であ り、J
cを決定する基本的な機構は磁束ピンニングである。
磁界中で超伝導体に電流を流すと、内部の磁束線に Lorentz 力 F
Lが働く。 Lorentz 力 F
Lは、超伝導体に流れる電流密度を J 、超伝導体内部に侵入した磁束線の磁 束密度を B とすると F
L= J × B と書ける。磁束線が F
Lによって速度 ν を持つ と、電磁誘導によって E = B × ν の誘導起電力が発生して損失が生じる。した がって、誘導起電力を発生させないために、磁束線の運動を止めなければならな い。その作用が磁束ピンニングである。磁束ピンニングは転移、常伝導析出物、空 隙、結晶粒界面など、あらゆる欠陥や不均質部分で起こる。こうした欠陥などを ピンニング・センターと呼ぶ。磁束ピンニングにより、Lorentz 力がある値を超え るまで磁束線の動きを止めることで、損失なしに超伝導電流を流すことが可能と なる。単位体積あたりのピンニング・センターが磁束線に及ぼす力をピン力密度 F
pとすると、超伝導体に流れる電流密度が誘導起電力が発生し始める臨界電流密 度 J
cのとき、磁束線には単位体積あたり J
cB の Lorentz 力が働いており、これが ピン力密度とつりあっているので、
J
c= F
pB (1.1)
の関係があることがわかる。F
pは超伝導体に固有な特性ではなく、もっと巨視的 な構造によって決まる後天的な特性である。そのため、ピンニング・センターを 導入して F
pを強くすることで、大きな臨界電流密度を得ることが可能となる。
1.6.2 磁束クリープ
磁束クリープとは、ピンニング・センターに捕まった磁束線が熱振動によって
ある確率でピンニング・センターから外れてしまう磁束線の運動のことである。磁
束線が移動するとき、磁束線は何本かまとまった集団で移動すると考えられ、こ
の磁束線の集団を磁束バンドルという。磁束クリープの影響が現れるのは、超伝
導永久電流の緩和である。理論的には、外部環境が変わらなければ超伝導体に流
れる電流は減衰しないと考えられる。しかし、実際に超伝導体試料の直流磁化を
長時間にわたって測定すると減衰することが確認できる。即ち、外部環境が一定
であっても遮蔽電流が時間とともに減衰しており、ピンニングに基づく超伝導電
流が真の永久電流ではないことを示している。高温になると熱活性化運動がより
盛んになるため、電流の減衰が著しくなり、臨界電流密度がゼロになってしまう
ことようなことが起こる。これは特に高温超電導体でよく見られ、臨界電流密度
がゼロとなる時の磁界を不可逆磁界と呼ぶ。
いま、電流が流れている状態で 1 つの磁束バンドルを考える。その磁束バンド
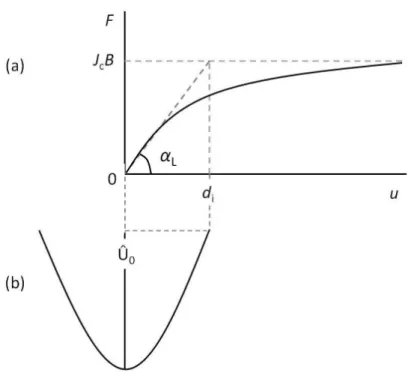
ルを Lorentz 力の方向に仮想的に変位させていった場合のエネルギー変化は図 1.1
のようになると考えられる。ただし、Lorentz 力は図 1.1 において右向きであると 仮定している。エネルギーが全体として右下がりになっているのは Lorentz 力の仕 事を考慮しているからである。図の谷の部分 (点 A, 点 C) は磁束バンドルがピン止 めされている状態である。磁束バンドルがピン止めされた状態から外れるために は、点 B のエネルギー・バリアを超える必要がある。熱振動が無ければ磁束バン ドルは動くことがないので、この図の状態で安定である。
図1.3: 磁束バンドルの位置とエネルギーの関係
熱エネルギー k
BT (k
Bは Boltzman 定数) がエネルギー・バリア U よりも十分小 さければ、磁束バンドルがこのバリアを超える確率は Arrhenius の式 exp( − U/k
BT ) で与えられる。また、この U を活性化エネルギーという。磁束バンドルが磁束線 格子間隔 a
fだけ変位すると、ほぼ元の状態に戻ると予想されるので、磁束バンド ルが磁束クリープを起こして一度に移動する距離は磁束線格子間隔 a
f程度である と考えられる。したがって、磁束バンドルの熱振動周波数を ν
0とすると Lorentz 力方向の平均の磁束線の移動速度 ν
+は以下のようになる。
ν
+= a
fν
0exp
(− U k
BT
)
(1.2) ただし、クリープの際の磁束バンドルの振動周波数 ν
0は以下の形で与えられる。
ν
0= ζρ
fJ
c02πa
fB (1.3)
ここで ζ はピンの種類に依存する定数であり、点状ピンの場合は ζ ≃ 2π、サイズ が a
f以上の非超伝導粒子の場合は ζ = 4 であることが知られている。また、ρ
fは フロー比抵抗であり、J
c0は磁束クリープがない場合の仮想的な臨界電流密度であ る。Lorentz 力とは逆方向の平均の磁束線の移動速度を考慮すると、全体としての 平均の磁束線の移動速度 ν は以下のようになる。
ν = a
fν
0[
exp
(
− U k
BT
)
− exp
(
− U
′k
BT
)]
(1.4) ただし、U
′は Lorentz 力と逆方向の運動に対する場合の活性化エネルギーである。
したがって、E = B × ν の関係から、生じる電界の大きさは以下のようになる。
E = Ba
fν
0[
exp
(
− U k
BT
)
− exp
(
− U
′k
BT
)]
(1.5) 磁束線がピンニング・センターに捕まった状態は一時的な安定状態であり、真 の平衡状態ではないため、真の平衡状態への緩和、すなわち遮蔽電流の減衰が生 じる。つまり、遮蔽電流の減衰は磁束クリープによる磁束線の運動によって、磁 束密度の勾配が減少することに対応している。このため、遮蔽電流が時間ととも に減少し、磁化の緩和が起こる。さらに磁束クリープが激しくなると、遮蔽電流 がなくなる、すなわち真の平衡状態になるまで磁化の緩和が続く。
磁束クリープにより発生する電界は (1.5) 式で与えられる。一般的には、磁束バ ンドル位置に対するエネルギーの変化は図 1.1 のようなポテンシャルで近似的に与 えられる。このポテンシャルを以下のように正弦的なものであると仮定する。
F (x) = U
02 sin(kx) − f x (1.6)
ここで、 U
0/2 はポテンシャルの振幅、 k = 2π/a
fはポテンシャルの周期、 f = J BV
は Lorentz 力の傾きを表していて、V は磁束バンドルの体積である。また、x は磁
束バンドル中心の位置である。
磁束バンドルが平行位置にあるときを x = − x
0とし、x = x
0のときのエネル ギーが極大となる、つまりそれぞれの位置でのエネルギー変化率はゼロとなるの で、F
′(x) = 0 となる。これより
x
0= a
f2π cos
−1(
f a
fU
0π
)
(1.7) が求まる。図 1.1 からエネルギー・バリア U は U = F (x
0) − F ( − x
0) で与えられる ので、
U = U
0sin
[
cos
−1(
f a
fU
0π
)]
− f a
fπ cos
−1(
f a
fU
0π
)
= U
0
1 −
(
2f U
0k
)2
1 2
− 2f U
0k cos
−1(
2f U
0k
)
(1.8)
と表される。ただし、ここで sin(cos
−1(x)) = √
1 − x
2を用いており、また k = 2π/a
fと置いている。もし熱振動がなければ、U = 0 となる理想的な臨界状態が達成さ れるはずである。このためには、2f /U
0k = 2J
c0BV /U
0k = 1 とならなければなら ない。このとき J = J
c0となることから、一般に
(
2f U
0k
)
= J
J
c0= j (1.9)
の関係が得られる。j は規格化電流密度である。また、J
c0はクリープがないと仮 定したときの仮想的な臨界電流密度であり、経験的に、
J
c0= A
(
1 − T T
c)m
B
γ−1(
1 − B B
c2)2
(1.10) と表現できる。A、m、γ はピンニング・パラメータである。これより (1.8) 式は
U (j ) = U
0[(1 − j
2)
1/2− j cos
−1j
](1.11) となる。また、k = a
f/2π および (1.9) 式から
U
′(j) ≃ U + f a
f= U + πU
0j (1.12)
となる。この関係を用いて磁束クリープにより発生する電界 (1.6) 式を整理すると、
E = Ba
fν
0exp
[
− U (j) k
BT
] [
1 − exp
(
− πU
0j k
BT)]
(1.13) のように求まる。
1.6.3 磁束フロー
磁束フローとは、磁束クリープ状態からさらに電流を流したときに、磁束線
が受ける Lorentz 力がピン力を超えてしまい、すべての磁束線が連続的に運動し
ている状態である。図 1.1 で磁束フロー状態を説明すると、図に示す状態よりさら
に Lorentz 力が増加すると、それに伴ってエネルギー・バリア U が減少する。す
ると、U が負の値をとる状態になり (J > J
c0)、磁束バンドルが感じるエネルギー 変化において安定状態を示す場所 (図 1.1 の点 A のような谷部分) が消失してしま うために、磁束バンドルが連続的に移動するようになる。ここで、U = 0 となる 状態が臨界状態であると考えられ、そのときの電流密度が仮想的な臨界電流密度 J
c0で与えられる。
超伝導体に電流が流れており、そこに外部磁界が加わっているときに単位体積
の磁束線に働く Lorentz 力は J × B で与えられる。一方、ピン力密度は Lorentz
力とは反対方向に働く。Lorentz 力方向の単位ベクトルを δ = ν/ | ν | とすると、静
的つりあいがとれる場合、すなわち仮想的な静的状態 (J < J
c0) でのつりあいの式 は、以下のようになる。
J × B − δF
p= 0 (1.14)
ここから J = F
p/B = J
c0の関係が得られる。
一方、J > J
c0となると、磁束フローを起こるので粘性力が働き、それを考慮し たつりあいの式は以下のようになる。
J × B − δF
p− B
ϕ
0ην = 0 (1.15)
ここで ϕ
0は量子化磁束であり、η は粘性係数である。これに J
c0= F
p/B および E = B × ν の関係を用いて J について解くと、
J = J
c0+ R
ρ
f(1.16)
となる。ここで ρ
f= Bϕ
0/η はフロー比抵抗である。(1.16) 式を E について整理す ると、磁束フローにより発生する電界が以下のように求まる。
E = ρ
f(J − J
c0) (1.17)
ここでは磁束クリープ現象において最も重要なパラメータであるピン・ポテン シャル U
0を理論的に見積もる。ピン・ポテンシャルは磁束線の単位体積あたりの 平均化したピン・ポテンシャルエネルギー U ˆ
0と磁束バンドルの体積 V で表され、
U
0= ˆ U
0V (1.18)
となる。
磁束線の単位体積あたりに平均化したピン・ポテンシャル U ˆ
0は Labusch パラ メータ α
Lと相互作用距離 d
iを用いて、
U ˆ
0= α
Ld
i22 (1.19)
と表せる。ここで α
Lおよび d
iは磁束クリープがないときの仮想的な臨界電流密度 J
c0と以下のような関係がある。
J
c0B = α
Ld
i(1.20)
こうした変位によるピン力密度およびピンニング・エネルギー密度の変位を図 1.2
に示す。変位が相互作用距離 d
i以内であれば、磁束線の運動はほぼピン・ポテン
シャル内に限られるため可逆であるが、d
iを超えると現象は不可逆となり、ピン
力密度は一般に知られた値に飽和していく。
図 1.4: 磁束線が平衡位置から変位したときの(a)ピン力密度および(b)ピンニング・エネルギー 密度の変化
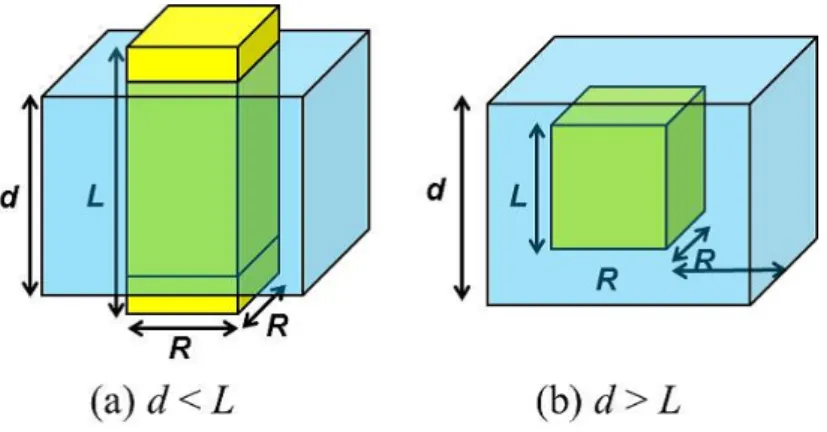
一方、磁束バンドルの形状は図 1.3 のように表される。1.3(a) のようにピンニ ング相関距離 L よりも超伝導体の厚さ d が小さい場合は、縦方向の磁束バンドル のサイズは d によって制限を受ける。ここで、超伝導体の厚さ d が L よりも大き いとき、縦方向のバンドルサイズ L はクリープがないと仮定したときの磁束線の 長さ方向の理想的な弾性相関距離 l
44なので、
L = l
44=
(
C
44α
L)1/2
=
(
Bα
Lζµ
0J
c0)1/2
(1.21) 同様に、磁束線の横方向の弾性相関距離 R は l
66となり、
R = l
66=
(
C
66α
L)1/2
(1.22) ここで、C
66と C
44は曲げおよびせん断のひずみに対する弾性定数で、C
44は
C
44= B
2µ
0(1.23)
で与えられる。一方、C
66は磁束線の格子状態によって大きく変化し、完全な三角 格子の場合には
C
66= B
cB 4µ
0B
c2(
1 − B B
c2)2
= C
660(1.24)
図 1.5: 磁束バンドルの形状
で与えられる。これは格子が乱れるにつれて小さな値となり、融解した状態では ゼロとなる。したがって、C
66は磁束線格子の状態によって変化し、C
66の実際の 値は 0 から C
660の間で値を取り得るが、決定論的には決まらない。また、ζ は相互 作用距離 d
iと磁束線格子間隔 a
fを使って、
d
i= a
fζ (1.25)
と表したときの定数である。
以上より、超伝導体の大きさが L、R より大きい場合の磁束バンドルの体積は
V = LR
2(1.26)
と表され、ピン・ポテンシャルは U
0= a
f2ζ J
c0BR
2L (1.27)
と表せる。
超伝導体のピンが極端に弱い場合を除いて、横方向磁束バンドルサイズ R は磁 束線格子間隔 a
f程度かその数倍程度であると考えられる。ピンがとても強い場合 には理論的には横方向磁束バンドルサイズ R は a
f以下になるが、実際には量子化 磁束 1 本より小さくなることはないので、横方向磁束バンドルサイズを
R = ga
f(1.28)
のように表す。ここで、g
2は横方向の磁束バンドルサイズの大きさを表す磁束バ ンドル中の磁束線数である。したがって g
2は (1.22) 式、(1.28) 式から
g
2= C
66ζJ
c0Ba
f(1.29)
と表せる。また、完全な 3 次元的な三角格子の場合は g
e2= C
660ζJ
c0Ba
f(1.30)
となり、g
2の最大値を与える。上に述べた理由から C
66と同様に g
2も決定論的に 定まらない。そこで、熱力学的な方法を用いて g
2の値は磁束クリープ下で臨界電 流密度が最大となるように決定する。したがって、(1.27) 式のピン・ポテンシャ ルは
U
0= 0.835k
Bg
2J
c01/2ζ
3/2B
1/4(1.31)
となる。
ここで図 1.3(a) のように超伝導体の厚み d が L よりも小さい場合における超伝 導体のピン・ポテンシャルについて考える。この場合、(1.26) 式は
V = dR
2(1.32)
で与えられる。つまり、長さ方向の磁束バンドルの大きさが厚み d によって制限 される。したがって、この場合の超伝導体のピン・ポテンシャルは
U
0= 4.23g
2k
BJ
c0d
ζB
1/2(1.33)
となる。本実験の解析では、ピンの形状は点状ピンであるとして、1.3.2 節で述べ たように ζ は 2π を使用する。
1.6.4 磁束クリープ・フローモデル
ここまで述べたように、超伝導体には磁束クリープおよび磁束フローにより 電界が発生する。磁束クリープによる電界成分 E
crは以下のようになる。
E
cr= Ba
fν
0exp
[
− U (j) k
BT
] [
1 − exp
(
− πU
0j k
BT)]
(J < J
c0)
(1.34)
= Ba
fν
0[
1 − exp
(
− πU
0k
BT
)]
(J ≥ J
c0)
一方、磁束フローによる電界成分 E
ffは以下のようになる。
E
ff= 0 (J < J
c0)
(1.35)
= ρ
f(J − J
c0) (J ≥ J
c0)
したがって、全体の電界 E
′は
E
′= (E
cr2+ E
ff2)
1/2(1.36)
のように近似的に与えられるとする。これは J < J
c0の場合は E = E
crとなり磁 束クリープのみの電界、J ≫ J
c0のときには E ≃ E
ffとなりほぼ磁束フロー状態 になることを示している。
また、(1.10) 式から U
0の温度および磁界依存性が決定される。しかし、臨界温 度 T
cやピンニングの強さは空間的に一様ではなく、分布していると予想される。
そこで、簡潔に (1.10) 式中で磁束ピンニングの強さを表す A のみが f(A) = K exp
[
− (log A − log A
m)
22σ
2]
(1.37) のように分布すると仮定する。ここで、K は規格化定数であり、σ
2は分布広がり を表すパラメータである。また A
mは A の最頻値である。このような A の分布を 考慮に入れると、全体の電界は
E(J) =
∫ ∞
0
E
′f(A)dA (1.38)
で与えられ、E − J 特性を評価することが可能となる。
1.7 Simpson 法
Simpson 法とは積分を数値積分するための手法である。被積分関数 f (x) を用い
て以下の手順で積分値を近似していく。
∫ b
a
f(x)dx ≃ h
3 [f (x
0) + 2
N 2−1
∑
n=1
f (x
2n) + 4
N
∑2
n=1
f (x
2n−1) + f (x
N)] (1.39)
x
n= a (1.40)
h = b − a
N (1.41)
N は積分区間の分割数。 N が大きくなるにつれ、積分区間を細かく足し合わ せる。
1.7.1 計算誤差を確かめる
手計算できる積分と Simpson 法を用いた数値積分とを比較するために次の関数 を用意する。
f(x) =
∫ π
0
sin(x) (1.42)
手計算では積分値は 2 とする。 数値積分した結果から 2 を引いた値をプロット する。
図 1.6: Simpson法の分割数と誤差
およそ、分割個数 N =1000 で誤差は 10
−12程度となり、誤差は h
4程度である。
1.8 遺伝的アルゴリズム
1.8.1 概要
遺伝的アルゴリズム (以下 GA) とは 1975 年にミシガン大学の John Henry Holland によって提案された近似解探索のアルゴリズムである。このアルゴリズムはメタ ヒュースティックアルゴリズムであり、特定の問題に依存しない、近似解の精度の 保証がないという特徴がある。選択、交叉、突然変異といった生物の遺伝を模し た操作を行うことによって、解の探索を行っていくものである。これらの内容に ついては 1.4.2 節以降で説明する。
以下にアルゴリズムの流れの例を示す。
1. 個体数 N を格納できる配列を2つ用意する。これらを現世代を格納する配列 (以下 now) と次世代を格納する配列 (以下 next) とする。
2. 現世代の配列にランダムな遺伝子を持つ個体を格納する。
3. 事前に用意した任意の評価関数に従って配列 now の各個体の評価を行い、適 応度を計算する。
4. 確率的に選択、交叉、突然変異を行う。
5. 4 の動作を配列 next の個体数が N になるまで繰り返す。
6. 配列 next の個体を配列 now にコピーする。
7. 3 以降の動作を最大世代まで繰り返し、最終的な配列 now の個体の中で適応 度が最も高いものを解とする。
1.8.2 個体操作
GA では選択、交叉、突然変異といった操作を行うことによって、解の探索を行っ ていく。この節ではこれらの説明を行う。
選択
この操作は自然淘汰をモデルとしたものである。適応度を用いたアルゴリズ ムに従い、個体を操作する。例をいくつか示す。
ルーレット選択
個体数 N のある世代を対象に選択を行うとする。この時に個体 i が選ば れる確率を P
i、i の適応度を f
iとすると
P
i=
∑Nfi k=1fkとなるように選択を行っていく方法である。適応度をスケーリングして
用いる場合もある。
ランキング選択
各個体を適応度の高い順に順位付けし、一位は確率 P
1、二位は P
2のよう にあらかじめ順位に対して決まった確率を用いて選択する方法である。
エリート選択
その世代の個体の中で適応度が最も高い、もしくは上位から任意の個体 数を保存し、確実に次世代に引き継ぐ操作である。選択により最適解が 悪化することを防げる反面、解の多様性が失われる可能性がある。
交叉
この操作は交配をモデルとしたものであり、各個体が持つ変数の値を入れ替 える操作である。例をいくつか示す。以下の例では遺伝子長 10、遺伝子表現 はバイナリ形式の以下の 2 個体間での交叉を行うものとする。
個体 A:1001001100 個体 B:0101011010
なおこの章でこれ以降に|が出てきた際は交叉点を示す。
一点交叉
任意の一点 (通常ランダムで選ばれる) を交叉点とし、それ以降のデータ を入れ替える。
個体 A:100100|1100 → 100100|1010 個体 B:010101|1010 → 010101|1100 二点交叉
任意の二点を交叉点とし、これらに挟まれた部分のデータを入れ替える。
個体 A:10|01001|100 → 10|01011|010 個体 B:01|01011|010 → 01|01001|100 一様交叉
各変数それぞれをランダムに 1/2 の確率で入れ替える。
個体 A:1001001100 → 1101001010 個体 B:0101011010 → 0001011100
突然変異
この操作は突然変異をモデルとしたものであり、事前に決めた突然変異率に
従い確率的に変数を変化させるものである。局所解への収束を防ぐ効果が期
待できるが、突然変異率が高すぎると乱数解析に近づき解の収束に影響が出
てくる。
1.8.3 実数値 GA
前節で説明した操作は個体のもつ遺伝子がビット形式で表現される際のもので ある。実際の数値解析に用いる際には遺伝子を実数で表現するほうが扱いやすい ため、交叉や突然変異のような処理を実数型で考える必要がある。ここではその ために用いられるアルゴリズムを示す。
選択
この操作はビット形式の GA の場合と基本的には同じでよい。
交叉
アルゴリズムとしてブレンド交叉 (BLX-α)、単峰性正規分布交叉 (UNDX)、
シンプレックス交叉 (SPX) などが知られている。以下では今回の実験で用い た BLX-α の説明を行う。
2 次元関数 A、 B があり、それらの変数の値をそれぞれ A = X
1, Y
1、 B = X
2, Y
2とする。また X
1< X
2、Y
1< Y
2とする。この際に生成される子の遺伝子を X
3、Y
3とすると
X
1− α(X
2− X
1) ≤ X
3≤ X
2+ (X
2− X
1) Y
1− α(Y
2− Y
1) ≤ Y
3≤ Y
2+ (Y
2− Y
1)
のように選ぶ方法である。すなわち図 1.7 に示すような両親の各変数を頂点 とする多次元直方体を両側に α 倍拡張したものの内部から選択するという方 法である。
突然変異
一様突然変異と境界突然変異という2種のアルゴリズムが知られている。 0 ≤ X ≤ 10 の範囲内での解析を行っていると仮定した場合、一様突然変異はこ の範囲内から一様に実数値を生成する。これに対して境界突然変異は 0 若し くは 10 が発生する乱数となる。境界突然変異は前述の交叉により発生しにく い、変数の許容範囲の境界線上の値を持つ個体を生成するために用いられる。
1.8.4 島モデル
島モデルは分散 GA の手法の一つである。母集団を分散させることにより、遺伝
子の多様性を保つことが可能となり、初期収束に陥る可能性を減らすことができ
る。島同士の個体の交換は移住という操作で行う。この操作は任意の世代ごとに
任意の個体数を他の島に移住させるという操作である。この際に移住先を決める
操作は複数考えられるが、今回は Fisher-Yates 法を用いたランダムリングを形成
することにより行っている。矢印は移住先と移住方向を示す。矢印が自分の島を
指している場合は、今回はこの島からの移住はないという意味である。
x
y
αx αx
αy
αy
親 1
親 2
図 1.7: BLX-α
1.9 目的
近年、GPU はプログラマブル・シェーダへの進化と共に汎用演算に適用され始 め、GPU の高い処理能力、値段の安さ、導入が簡単な点と合わさり、個人で行え る少規模で高速並列演算資源として期待されている。
磁束クリープ・フローモデルとは、超伝導体のピンニング特性を解析する際に用 いるモデルの一つだが、解析を行う際に、5 つのピンニングパラメータ全てが合わ さる解を求めなければならず、経験則がなければ、解析時間に多大な時間がかか る。このような時に、GPU を用いて高速計算できれば後々の解析を円滑に行うこ とができる。
本実験では、CUDA による磁束クリープ・フローモデルの計算を並列化し、高
速な数値計算の実現し、超伝導体のピンニング特性の解析を円滑にするのが本研
究の目的である。
第 2 章 実験
2.1 実験環境
表 2.1: 実験環境
Intel Core-i7 870 GeForceGTS250
コア数 4 SM 4 SP 128
動作周波数 2.93 [GHz] 738 [MHz]
RAM 4 [GB] 512 [MB]
2.2 磁束クリープ・フローモデルの並列計算の最適手法
Simpson の分割数 90 E-J を求める回数 10,000
磁束クリープ・フローモデルを並列化する最適なパターンを求める。最適解の評 価は実行速度、汎用性の点から評価する。
2.2.1 手法 A(simpson)
磁束クリープ・フローモデルのプログラム中の数値積分を行う Simpson 法を並 列化した。1 つの電界 E を求める。
CPU と GPU で分割数 N を変化させながら実行速度の比較を行なう。
また GPU のコア数による処理時間を試す。
2.2.2 手法 B(E-J)
複数の電流密度 J からそれぞれの E を求める。
1 スレッドで E-J を求める。
1 度のカーネルで複数の E-J が求められる。
実行時間は求める E-J 特性、Simpson 法の分割数 N、変数に指定するピンニング
パラメータの数に依存。
スレッドごとにピンニングパラメータの設定が必要。
2.3 GA による磁束クリープ・フローモデルのピンニングパラメー タ探索プログラムの高速化
試行回数 50 世代数 100 島 10 個体数 20
データ数 180 (20・25・30[K],1・2・3・4・5・6[T], 各 10 個) Simpson の分割数 90
(実験 2.2) の結果から最適な手法で磁束クリープ・フローモデルの並列計算を GA によるピンニングパラメータの探索プログラムを組み込み高速化を行う。
GA によるピンニングパラメータの探索プログラムを並列化するに当たって、依 存性のない範囲とで並列化するしなければならない。1 世代毎にのピンニングパラ メータに対する E-J 特性の数値計算、
島 * 個体 * データ数 = 36,000 個
を数値計算する。
第 3 章 結果と考察
3.1 磁束クリープ・フローモデルの並列計算の最適手法
図 3.1 は、手法 A、手法 B で E-J を 10,000 個求めた時のコア数ごとの処理速 度の依存性を示している。ため磁束クリープ・フローモデルの計算の最適な並列 化は手法 B である。
0 100
0 2 4
処理速度
処理速度[103 x Number of data/sec]
コア数[個]
手法B(E−J) 手法A(simpson)
図 3.1: コア数に対する処理速度の関係
3.2 磁束クリープ・フローモデルの並列計算の最適手法
手法A
手法 A の結果においてはコア数を 8 から 16 に増やすと処理速度も比例し ているが、コア数を 32 から 128 に増やしても処理速度が向上していない。手法 A の場合、1 スレッドの処理内容が少ないため実行までの準備に時間かからないが、
1 回の実行で 1 つの計算結果しか求めることができず、複数の計算結果を求める場
合に GPU の呼び出す回数が増える。
3.2.1 手法 B
手法 B の場合は、コア数を 8 から 128 に増やした場合は、処理速度も比例して 向上している。手法 B は 1 スレッドの処理内容が多いため GPU の準備に時間がか かるが、一度の実行で複数の計算結果をまとめて導出する
3.3 GA による磁束クリープ・フローモデルのピンニングパラメー タ探索プログラムの高速化
表3.1: CPUとGPUの処理時間
CPU GPU
720[min] 25[min]