DEIM Forum 2016 C8-4
単語のコミュニティ性に基づいたクエリの関連語推薦
岡崎
伸也
†風間
一洋
†篠田
孝祐
††大向
一輝
††††
和歌山大学 システム工学部
〒 640–8510 和歌山県和歌山市栄谷 930
††
電気通信大学 大学院情報システム学研究科
〒 182-8585 東京都調布市調布ケ丘 1 丁目 5 番地 1
†††
国立情報学研究所 コンテンツ科学研究系
〒 101-8430 東京都千代田区一ツ橋 2-1-2
E-mail:
†{
s171013,kazama
}
@center.wakayama-u.ac.jp,
††
[email protected],
†††
[email protected]
あらまし 本稿では,単語のコミュニティ性に基づいた重み付け指標である TF-ICF を用いて,論文検索に用いたク
エリの関連語を提示する手法を提案する.ICF は,論文の共著関係ネットワークから抽出した著者コミュニティ群に
おける単語の分布から計算される.実際に,人工知能学会全国大会の 13 年分の書誌情報を対象に,出現頻度の異なる
2
種類のクエリ集合から求めた関連語の被覆率・重複率を既存手法と比較して有効性を示す.さらに,CiNii のアクセ
スログから実際に検索結果の絞り込みに使用されたキーワードを分析することで,TF-ICF による関連語が検索支援
の場面で有効であることを示す.
キーワード TF-ICF,コミュニティ性,文献検索,情報推薦,関連語
1.
は じ め に
近年,研究開発の競争の激化に伴い,様々な技術の創出だけ でなく,陳腐化も早まってきている.そのような技術動向を追 うためには,例えばCiNiiやACM Digital Libraryのような 論文検索システムで検索を繰り返すことで,研究開発の現状を ある程度まで調べることができるが,クエリはユーザ自身が入 力する必要があるので,未知の分野を調べることは難しい.そ こで,システムが自動的に抽出した関連語をユーザに提示でき れば,論文探索の有益な手がかりになると考えられる. 例えば,重要語の抽出にはTF-IDFが用いられるが,論文の 題名や概要などの書誌情報しか利用できない場合は,限られた 長さのテキストで単語の重複を避けて記述するために重要語の 出現数が少なくなり,従来手法では良い結果が得られなかった. そこで石橋らは,単語のコミュニティ性に基づく重み付け指 標であるTF-ICFを提案した[1].ICFは,論文の共著ネット ワークから抽出した著者コミュニティ群における単語分布から 計算されるために,書誌情報のような限られたデータの場合に, 従来手法よりも良い結果が得られることが期待できる. 本稿では,論文検索におけるクエリの関連語を,TF-ICFで 選択して提示する手法を提案する.さらに,人工知能学会全国 大会の13年分の書誌情報を対象に,出現頻度が異なる2種類 のクエリ集合とその関連語を用いて,被覆率・重複率などの観 点からTF-IDFと比較する.また,CiNiiのアクセスログから 抽出した実際に検索結果の絞り込みに使用された2語で構成さ れるクエリを用いて分析することで,TF-ICFによる関連語が 検索支援として有効であることを示す.2.
関 連 研 究
2. 1 履歴ベースの関連語推薦 大塚らはWebの大規模アクセスログを解析し,検索に使用 されたクエリ間の関連度を,クエリ入力後に閲覧されたWeb ページ,あるいはWebページのリンク構造から抽出したWeb コミュニティに対する閲覧数などを用いて算出し,あるクエリ に関連するクエリを提示するシステムを提案した[2]. 近藤らは,ユーザのWeb閲覧履歴中のWebページから単語 群を見出し語とするWikipediaのページの重要度を,HITSを 改良したアルゴリズムを用いて求めて,その上位の語をユーザ に提示するシステムを提案した[3]. 堀らは,ユーザのWeb閲覧履歴中のWebページから抽出し た単語群を自己組織化マップでクラスタリングし,クエリと類 似する単語を関連語として提示する手法を提案した[4]. ただし,履歴ベースの手法では十分な履歴がなければ有用な 推薦ができないコールドスタート問題が存在し,本稿では利用 できない. 2. 2 コンテンツベースの関連語推薦 安辺川らは,書誌検索の絞り込みに使用する関連語をユーザ に推薦するために,文献の書誌情報から得られるテキスト中の 単語群に対してTF-IDFやBM25,TermExtractによるラン ク付け手法を検討し,BM25が最も被験者からの評価が高くな る関連語を推薦できることを示した[5]. 榊らは,Web上のテキスト情報を利用して,クエリ拡張など に応用できる関連語のシソーラスを自動的に構築する手法を提 案した[6]. これらの研究は単語の出現頻度や単語間の関連度を用いるが, 本稿では文書の著者とその共著者の関係から求めた著者コミュ ニティを利用して単語のコミュニティ性を考慮するという点が 異なる.3.
単語のコミュニティ性
3. 1 コミュニティ性 コミュニティ性は,ある単語がどのような著者達のコミュニ ティで活用されているかについての性質である.例えば,専門 用語であれば,少数の関連する専門家のコミュニティで頻繁に(a)単語–論文の 2 部グラフ (b)単語–論文–著者の 3 部グラフ 図1: 単語と論文のn部グラフ構造 使われるが,一般用語であれば多数のコミュニティで広く使わ れるなど,その単語の性質に応じて出現分布パターンに固有の 特徴があると考えられる.石橋らは,このようなコミュニティ 性に基づいて単語の専門性を定量化する指標ICFと,それを 用いた単語のスコアの計算法TF-ICFを提案した.
3. 2 ICF(Inverse Community Frequency)
ICFは,「専門用語とは,特定の専門家達の間で共有される言 葉である」という前提に基づいて,著者のコミュニティ群から 求めた単語の専門性の指標である. 例えばTF-IDFは,単語–文書(論文)という2部グラフ構 造(図1a)から求められる.しかし,論文アーカイブの場合 は,共著者情報を加えて単語–文書(論文)–著者という3部グ ラフ構造(図1b)に拡張できる.さらに,論文は複数人の著者 によって書かれることが多いことから,文書–著者の部分を変 換した共著ネットワークは,頻繁に共同研究している著者達の コミュニティに分割できる.つまり,単語が決まれば,その単 語を使用している著者のコミュニティの集合が決定される. 例えば,一般的に著者の論文生産性には大きな差があること から,一人の著者だけが用いる専門用語の頻度は,グラフ構造 の論文のレベルでは大きく異なることになるが,著者のレベル では同一となる.さらに,同じ専門分野の著者が共同研究する チームとして多数の論文を書く場合にも,論文のレベルでは差 が出ても,共著ネットワークでは,一つのコミュニティに集約 されることになる.つまり,専門用語であれば少数のコミュニ ティに出現し,一般用語であれば多数のコミュニティに出現す るので,ICFでは,コミュニティ集合における単語の出現確率 を定量化することで単語の専門性を判定する. 3. 3 ICFの計算 単語wiのICFの値ICF (wi)(1 <= i <= K)は以下のように 計算する.Kは総単語数である. (1) データセットに含まれる全論文に対して,同一の論文 を執筆した著者同士にエッジを張ることで,共著関係ネット ワークを構築する.なお,小規模コミュニティの増加による性 能低下を避けるために,Jaccard係数やSimpson係数は使用し ない. (2) 共著ネットワークをClausetらのCNM法[7]を用い てコミュニティに分割し,著者と所属コミュニティの関係を取 得する. 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 6 8 10 r(wi) ICF ( wi ) 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 6 8 10 r(wi) ICF ( wi ) 0.0 0.2 0.4 0.6 0.8 1.0 0 2 4 6 8 10 r(wi) ICF ( wi ) α =1 α =2 α =3 図2: r(wi),ICF (wi)とαの関係 (3) データセット中の単語wiに関して,単語wiが出現す る論文の筆頭著者の集合を取得する. (4) 単語wiが出現する論文の筆頭著者の集合から,単語 wiが出現するコミュニティ集合を求めて,そのコミュニティ数 をc(wi)とする. (5) 単語wiのコミュニティ集合における出現率r(wi)(0 <= r(wi) <= 1)を求める. r(wi) = c(wi) C (1) ここで,Cはクラスタリングによって得られた全コミュニティ 数である. (6) 単語wiのICFの値ICF (wi)を計算する. ICF (wi) = (log( 1 r(wi) ))α (2) ここで,αは定数である. すなわち,図1b上で考えると,単語レベルから論文レベル, 論文レベルから著者レベルに写像した上で,共著関係ネット ワークにおける該当コミュニティを求めていることになり,こ の過程において個人やグループのアクティビティの差が除去さ れ,著者のレベルからみた専門性をより忠実に反映させること が可能となる. ここでr(wi)の逆数の対数をα乗する理由は,r(wi)の値の 大小に対して,コミュニティに写像されることで小さくなりが ちなICF (wi)の効果を調節するためである.r(wi),ICF (wi) とαの関係を図2に示す.これから,αの値を増やすほど, ICF (wi)の変化が大きくなる. 3. 4 TF-ICF TF-IDFは情報探索やテキストマイニングなどの分野で利 用され、文書中に出現した単語がどのくらい特徴的である かを識別するための指標である[8].単語wiのTF-IDFの値 T F -IDF (wi)は,ある文書に単語が出現する度合いを表すTF (Term Frequency)の値T F (wi)と,単語が文書全体に出現
する度合いの逆数であるIDF(Inverse Document Frequency)
の値IDF (wi)の積で与えられる. T F (wi) = n(wi) ΣK k=1n(wk) (3)
IDF (wi) = log D d(wi) (4) T F -IDF (wi) = T F (wi)× IDF (wi) (5) ここで,n(wi)は単語wiの出現回数,Dは総ドキュメント数, d(wi)は単語wiを含むドキュメント数である.
本稿では,IDFをICFに置き換えたTF-ICFを用いる.単
語wiのTF-ICF値であるT F -ICF (wi)は次のように定義さ れる. T F -ICF (wi) = T F (wi)× ICF (wi) (6) なお,TF-ICFでは,一般的な単語や特定のコミュニティしか 使わない固有名詞を低く評価することを目的とするが,この際 のバランスは定数αで調整できる.
4.
TF-ICF
を用いたクエリの関連語の抽出
4. 1 関連語推薦による検索支援 本稿では,論文検索のクエリの関連語を,検索結果の絞り込 みに用いる状況を想定する.例えば,検索結果と同時にクエリ と関連語の一覧を表示し,調べたい内容を示す関連語をクリッ クするだけでAND検索できれば,複数の関連語を切り替える ことで膨大な検索結果を効率よく調べることができる. このような状況では,表示される関連語はクエリが表すメイ ントピックのサブトピックを表す専門用語であることが望まし い.例えば,一般的な関連語で絞り込んでも,検索結果数があ まり変わらなかったり,表現の多様性から検索漏れが生じたり して,検索結果を効率よく調べることはできない. さらに,クエリが表すメイントピック空間のなるべく広い範 囲に,関連語を使い分けることで効率よくアクセスできること が望ましい.例えば,すべての関連語を使っても検索結果のご く一部しか見れないとか,異なる関連語でも絞り込み結果があ まり変わらなければ,有用性は低い. そこで,各コミュニティの持つトピックを反映した専門用語 を抽出できるTF-ICFを用いて,上記の性質を満たすような関 連語推薦を試みる. 4. 2 関連語の抽出法 クエリの関連語は,以下の手順で抽出する. (1) クエリの検索結果に含まれる全単語のTFを算出する. (2) パラメータαを指定して事前計算したICF値を用い て,各単語のTF-ICF値を計算する. (3) TF-ICF値の上位N件の単語を関連語として抽出する. なお,パラメータαは抽出される単語の特性に影響する.例 えば,αが小さいほどTFの効果が高くなるために,より一般 的な単語が,αが大きいほどICFの効果が高くなるために,よ り専門的な単語が抽出される.5.
単語集合による評価
5. 1 JSAIデータセット 人工知能学会は毎年全国大会を開催しており,発表プログ ラムと論文のPDFを参加者にCD-ROMで配布すると共に, Webで公開している.この発表プログラムには,すべての発 図3: 論文探索システムの実行例 表の時刻,演題番号,題目,著者に加えて概要も掲載されてい ることから,2003年から2015年までの13年間のHTML形 式の発表プログラムを収集し,書誌情報とキーワードを抽出し た.これをJSAIデータセットと呼び,5570件の発表と33914 語のキーワード,6393名の著者が含まれる. 5. 2 JSAI全国大会論文検索システム 石橋らは,JSAIデータセットを対象に,キーワードと著者 を手掛かりに単語—論文—著者という3部グラフ構造を辿って 論文を探索できるシステムを,PythonとMongoDBを用いて 作成した[1].図3に示すように,このシステムでは著者名また はキーワードを入力すると,検索結果に含まれる複数の論文を 著者グループごとに表示し,さらに論文の探索に有効な主要著 者と関連語を提示する.本稿では,このシステムに手を加えて 評価に使用した. 5. 3 評価用単語集合の作成 さらにJSAIデータセットから出現文書数が50∼99件または 100∼150件の単語を抽出し,その2種類の単語集合Q1,Q2 を評価に用いた.|Q1| = 276,|Q2| = 97である.Q1の単語は 専門的な用語が,Q2の単語は論文で比較的良く用いられる一 般的な用語が多く含まれていた. 5. 4 被覆率の評価 ある単語の検索結果に対して求めた各関連語を使ってAND 検索した場合に,元の検索結果のどの程度の割合の論文を閲覧 できるかを,被覆率(Coverage Ratio)[9]を使って評価した. ある単語qで検索したM件の論文Dm(m = 0, . . . , M− 1)に 対して,スコアの上位N件の関連語wn(n = 0, . . . , N− 1)を 提示する場合に,被覆率CR(q, N )は以下の式で求める. CR(q, N ) = |{Dm|wn∈ Dm}| M (7)Q1とQ2の単語を使って求めたTF-IDFとTF-ICFの関連 語の被覆率の平均値を,図4に示す.なお,Nは5, 10, 15, 20 のいずれかの値とし,TF-ICFのαは1.0から3.0まで変化 させた.まず,全体的にTF-IDFの方が被覆率が高い.ただ し,図4aのようにα = 1付近でTF-ICFが上回っているが, ICFは文書をより少ない数のコミュニティに集約するために, αが小さいとIDFよりもスコアに対する影響も小さいからで ある.Nの増加に伴って,どちらも被覆率は向上するが,特に TF-IDFはN = 10の時にQ1で0.905,Q2で0.914と全体的 に高い被覆率を示す.TF-ICFの被覆率はαの増加につれて低 下するが,これは関連語の専門性が高くなり,該当する論文が 少なくなるからである.また,αを増加させると,最初はQ2 の被覆率の平均値の方が高くても途中で逆転する.これは一般 的な単語であるQ2で検索した方が検索結果数が多くなること から,αが小さく相対的にTFの効果の方が高い段階ではQ2 の方が一般的な関連語を提示するために被覆率が高く,αが大 きく相対的にICFの効果の方が高くなると関連語が専門的にな り,検索結果の範囲が広いQ2の方が絞り込まれるからである. 5. 5 重複率の評価 検索結果中で,関連語がどの程度重複しているかを重複率 (Overlap Ratio)を用いて評価した.ある単語qで検索したM 件の論文Dm(m = 0, . . . , M− 1)に対して,スコアの上位N 件の関連語wn(n = 0, . . . , N− 1)を提示する場合に,qに対す る上位N件の関連語の重複率OR(q, N )を以下の式で求める. OR(q, N ) =
∑
M−1 i=0 (|{wn|wn∈ Di}| − 1) |{Dm|wn∈ Dm}| × (N − 1) (8) なお,0 <= OR(q, M ) <= 1である.例えば,N = 5の場合は, 重複率が0なら各論文に関連語が1語,0.25なら平均2語,1 ならすべての関連語が含まれることを意味し,Nが増えるほど 出現する関連語数が多くなる.すなわち,値が1に近いほど関 連語間の重複が大きくなり,異なる関連語を使っても検索結果 があまり変わらなくなることから,被覆率と反対で0に近いほ ど良いことに注意が必要である.なお,一般に被覆率と重複率 は相反する関係があり,被覆率を良くすれば重複率が悪くなり, 重複率を良くすれば被覆率が悪くなりやすい傾向がある. Q1とQ2の単語を使って求めたTF-IDFとTF-ICFの関連 語の重複率の平均値を,図5に示す.なお,Nは5, 10, 15, 20 のいずれかの値とし,TF-ICFのαは1.0から3.0まで変化さ せた.これから,TF-IDFは比較的高い重複率を持ち,被覆率 が高いことも考慮すると,比較的一般的な単語が関連語として 抽出されていることがわかる.これに対して,TF-ICFはαの 増加と共に重複率が低下し,比較的低い値を取る.また,αが 1.5から2.0を過ぎると大きく変化しなくなるが,これは関連 語の出現コミュニティ数が最小値の1に近くなるからだと考え られる. 5. 6 上位20件の関連語の比較 実際に,Q1 の「モデリング」とQ2の「コミュニティ」で 検索した時のTF-IDFとTF-ICFの上位20件の関連語を求 めて,表1と表2に示す.ここで,|C|は単語の出現コミュニ ティ数,|F |は単語の検索結果中の出現頻度,τはTF-IDFと TF-ICFで順位付けしたすべての関連語のケンドールの順位相 関係数[10]の値である.ここで,関連語の総数をn,2つの関 連語の順位の大小関係が一致する組の数をPとして,ケンドー ルの順位相関係数を次の式で求めた. τ = 4P n(n− 1)− 1 (9) TF-ICFのαは1.0, 2.0, 3.0とした.「モデリング」と「コミュ ニティ」の検索結果数は,それぞれ70件と121件であった. TF-IDFの関連語は|C|と|F |の両方が大きい値になってい るのに対して,TF-ICFはαが2.0,3.0となるにつれ|C|と |F |の両方が小さな値になる傾向があることがわかる.この傾 向は出現頻度が大きくなるほど顕著である.さらに,τもαが 1の場合も0.9を下回り,さらに増加するほど低くなることか ら,上位20件に限らず,関連語の順位が全体的に大きく異なっ ていることがわかる. 具体的な検索語を調べると,どちらの場合もTF-IDFでは 「研究」,「手法」などの論文でよく用いられる単語が含まれる. また,表1では「適用」,「表現」,「条件」,表2では「分析」, 「共有」,「情報」,「形成」などの一般的な単語が含まれているこ とがわかる.これらの単語は,TF-ICFでαが2.0,3.0の場合 には上位に出現しない.すなわち,TF-IDFは特に論文で使わ れることが多いが比較的一般的な単語が,TF-ICFでは特定少 数のコミュニティで頻繁に使われる専門用語が上位に来ること が確認できる.なお,表2の「人起点」は複合語抽出の誤りで 生じた単語である. ここで,α = 2とα = 3の場合を比較すると,表1ではどち らも|C|の値は1に近いがα = 3の|F |の値がさらに小さくな り,表2では|C|の値もα = 3の方が小さくなっていることが わかる.TF-ICFで抽出したい関連語は,特定少数のコミュニ ティで頻繁に用いられる単語であるので,α = 3の値をあまり 大きくすることは適切でないと考えられる.6.
実クエリ集合を用いた評価
6. 1 CiNiiデータセットCiNii (Citation Information by NII)は,国立情報学研究所 が提供している学術論文や図書,雑誌などの学術情報データ ベースである.CiNiiのWebサーバ群の2013年4月1日から 2015年3月31日までの2年間のアクセスログから,論文検索 であるCiNii Articlesで実際に検索に使用された29,351,579種 類のクエリ文字列の集合を抽出した.これをCiNiiデータセッ トと呼ぶ. 6. 2 評価用クエリ集合の抽出 CiNiiデータセットから,ユーザが実際に使用した2語の AND検索のクエリを抽出して,1番目の単語で検索した時に2 番目の単語を関連語として推薦することが妥当であると仮定し て,検索語の評価に使用する. まず,クエリ文字列を単語に分割し,2個の単語で構成され, かつ1番目の単語で検索した際に2番目の単語も検索結果に含 まれる単語の組を120,222組抽出した.
(a) N = 5 (b) N = 10 (c) N = 15 (d) N = 20 図4: 被覆率の平均値 (a) N = 5 (b) N = 10 (c) N = 15 (d) N = 20 図5: 重複率の平均値
表1: Q1の「モデリング」の関連語の順位の比較 順位 TF-IDF TF-ICF |C| |F| α = 1.0 |C| |F| α = 2.0 |C| |F| α = 3.0 |C| |F| 1 モデル化 51 16 モデル化 51 16 ハイブリッドシステム 1 4 ハイブリッドシステム 1 4 2 モデル 83 18 モデル 83 18 HydLa 1 4 HydLa 1 4 3 モデリング手法 4 4 研究 272 33 離散変化 1 4 離散変化 1 4 4 HydLa 1 4 ハイブリッドシステム 1 4 連続変化 1 4 連続変化 1 4
5 連続変化 1 4 HydLa 1 4 HydLa処理系 1 3 HydLa処理系 1 3
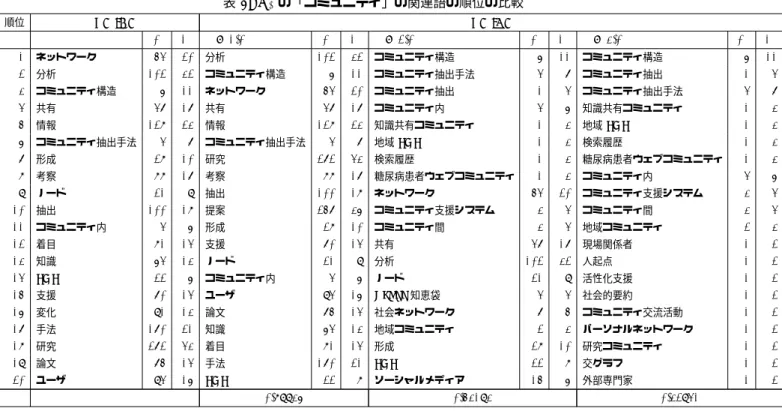
6 ハイブリッドシステム 1 4 離散変化 1 4 事故予防 1 3 事故予防 1 3 7 離散変化 1 4 連続変化 1 4 ハイブリッドシステムモデリング言語 1 3 ハイブリッドシステムモデリング言語 1 3 8 研究 272 33 モデリング手法 4 4 モデリング手法 4 4 価値判断 2 3 9 適用 98 9 HydLa処理系 1 4 モデル化 51 16 学問 2 3 10 表現 90 9 事故予防 1 3 価値判断 2 3 モデリング言語 1 2 11 手法 170 14 ハイブリッドシステムモデリング言語 1 3 学問 2 3 フロアフィールドモデル 1 2 12 シミュレーション 38 6 手法 170 14 モデリング言語 1 2 LS 1 2 13 発表 109 10 発表 109 10 フロアフィールドモデル 1 2 医療行為 1 2 14 条件 30 5 表現 90 9 LS 1 2 スパースモデリング 1 2 15 HydLa処理系 1 3 価値判断 2 3 医療行為 1 2 確率的モデリング 1 2 16 価値判断 2 3 学問 2 3 スパースモデリング 1 2 渋滞学 1 2 17 学問 2 3 事故 9 4 確率的モデリング 1 2 モデリング手法 4 4 18 ハイブリッドシステムモデリング言語 1 3 枠組み 37 6 渋滞学 1 2 ユーザモデリング手法 2 2 19 枠組み 37 6 シミュレーション 38 6 モデル 83 18 医療サービス 2 2 20 事故 9 4 適用 98 9 事故 9 4 グラフィカルモデリング 2 2 τ 0.89477 0.61954 0.46303 表2: Q2の「コミュニティ」の関連語の順位の比較 順位 TF-IDF TF-ICF |C| |F | α = 1.0 |C| |F | α = 2.0 |C| |F | α = 3.0 |C| |F | 1 ネットワーク 54 20 分析 102 32 コミュニティ構造 6 11 コミュニティ構造 6 11 2 分析 102 32 コミュニティ構造 6 11 コミュニティ抽出手法 4 7 コミュニティ抽出 1 4 3 コミュニティ構造 6 11 ネットワーク 54 20 コミュニティ抽出 1 4 コミュニティ抽出手法 4 7 4 共有 47 17 共有 47 17 コミュニティ内 4 6 知識共有コミュニティ 1 3 5 情報 128 23 情報 128 23 知識共有コミュニティ 1 3 地域 SNS 1 3 6 コミュニティ抽出手法 4 7 コミュニティ抽出手法 4 7 地域 SNS 1 3 検索履歴 1 3 7 形成 28 10 研究 272 43 検索履歴 1 3 糖尿病患者ウェブコミュニティ 1 3 8 考察 88 17 考察 88 17 糖尿病患者ウェブコミュニティ 1 3 コミュニティ内 4 6 9 ノード 21 9 抽出 100 18 ネットワーク 54 20 コミュニティ支援システム 3 4 10 抽出 100 18 提案 257 36 コミュニティ支援システム 3 4 コミュニティ間 3 4 11 コミュニティ内 4 6 形成 28 10 コミュニティ間 3 4 地域コミュニティ 2 3 12 着目 81 14 支援 70 14 共有 47 17 現場関係者 1 2 13 知識 64 13 ノード 21 9 分析 102 32 人起点 1 2 14 SNS 22 6 コミュニティ内 4 6 ノード 21 9 活性化支援 1 2 15 支援 70 14 ユーザ 94 16 Yahoo!知恵袋 4 4 社会的要約 1 2 16 変化 91 13 論文 75 14 社会ネットワーク 7 5 コミュニティ交流活動 1 2 17 手法 170 21 知識 64 13 地域コミュニティ 2 3 パーソナルネットワーク 1 2 18 研究 272 43 着目 81 14 形成 28 10 研究コミュニティ 1 2 19 論文 75 14 手法 170 21 SNS 22 8 交グラフ 1 2 20 ユーザ 94 16 SNS 22 8 ソーシャルメディア 15 6 外部専門家 1 2 τ 0.89936 0.53193 0.32941
ただし,本稿で用いたシステムには人工知能分野の論文だけ を用いたのに対して,CiNiiデータセットには人工知能以外に も,社会学,数学,生物学,医学などの他の分野の論文を探す ために使われたクエリ文字列が多く含まれている.そこで,人 工知能分野だけに絞り込むために,情報処理学会の論文誌用の 和文キーワード(注 1) のうち,人工知能分野を示す大項目「知能 グループ」に属しているキーワードを抽出した.なお,「・」や 「/」などで併記形式で記述されている場合は2つのキーワー ドに分割し,文章として書かれている場合はそこからキーワー ドとして妥当な名詞部分だけを抽出した. さらに,1番目の単語にこれらのキーワードを含む単語の組 だけを抽出した結果,4,973組の単語の組が抽出できた.以降 は,これを実クエリ集合と呼び,1番目の単語を検索語,2番 目の単語を絞り込み語と呼ぶ. 6. 3 平均逆順位の評価 抽出した実クエリ集合の検索語と絞り込み語の組み合わせ が,検索に用いる単語とその関連語の組み合わせとして妥当 であると仮定して,検索語で検索した時に,それからTF-ICF とTF-IDFで求めた関連語リストで絞り込み語がどの程度高い 順位になっているかを調べるために,MRR(Mean Reciprocal Rank)を用いて評価した.MRRは,検索語集合をQとし,そ のi番目の絞り込み語がTF-ICFまたはTF-IDFで求めた関連 語リストに現れる順位をrankiとした時に,次の式で求めた. M RR = 1 |Q| |Q|
∑
i=1 1 ranki (10) つまり,検索語に対して絞り込み語を関連語として高い順位に 推薦するほど,MRRの値は高くなる.ただし,使用する検索 語と絞り込み語の組み合わせが必ずしも最適解ではないことか ら,順位の逆数を取るMRRでは,正解集合を用いる場合より も,かなり低い値になりやすいことに注意が必要である. 実クエリ集合を使ってTF-ICFとTF-IDFで求めた平均逆 順位を算出した結果を図6aに示す.TF-ICFのMRRの値は α = 1.0ではわずかに高いが,αの増加に伴って減少し, TF-IDFよりかなり悪い値になることがわかる.この原因として, 実際に使われた検索語と絞り込み語の組み合わせは,我々の予 測と大きく異なっていた可能性が考えられる. 6. 4 実クエリ集合の分析 CiNiiのユーザがどのような単語を絞り込みに使っているの かを知るために,評価に用いた実クエリ集合における出現頻度 の上位20件の絞り込み語を表3に示す.これらの絞り込み語 を見ると,単語集合を用いた評価でTF-IDFで得られる関連語 と傾向が類似していることがわかる.特に頻度が多い「研究」, 「評価」,「分析」は,すでに述べたように論文でよく使われる 単語であり,これは論文の題名の最後に用いられることが多い. つまり,特に最近雑誌の記事などの論文以外のデータ量が激増 しているCiNiiで,論文だけに絞り込むための裏技として活用 されている可能性が高い.これ以外の,単語も確かに技術系文 (注 1):https://www.ipsj.or.jp/prms/office/show_keyword.do 書に多く使われると思われるが,それらを用いたとしても被覆 率も重複率も高いことから適切に絞り込めるとは限らない.さ らに,専門用語でないことから表現が統一されておらず,例え ば「抽出」なら,「取得」,「獲得」などの表現を用いている論文 は検索から漏れることとなり,情報探索行動に悪影響を与える 可能性が高い. 実クエリにこのような一般的な単語が多用される理由は,い くつか考えられる.1番目の理由は,「知識の共有」のような文 章から,ユーザが単語を抽出して検索していることである.こ のような場合には,2番目の単語として一般的な動名詞が来る 可能性が高くなる.2番目の理由は,ユーザは出現頻度の高い 単語を思いつきやすい傾向があるということである.そして, 3番目の理由は,ユーザが検索したい論文の内容は必ずしも既 知でないことが多いことから,そもそもユーザにとって絞り込 みに適したキーワードを思いついて使用することが困難なタス クであるということである.この場合は,TF-ICFのような特 定少数のコミュニティで頻繁に使用されているような専門用語 をシステム側から提示することは,非常に重要であると考えら れる. 6. 5 高頻度の絞り込み語を持つクエリを除いた平均逆順位 の評価 次に,論文に限定するための裏技や情報探索に問題を生じる 一般的な単語を除いた時に,TF-ICFの性能がどう変化するか を分析する.実クエリ集合のうち,JSAIデータセットの出現文 書数が多い上位200件の単語が絞り込み語として出現するクエ リを取り除いた.この結果3,483組,2.9%と大幅に減少した. なお,上位1∼5位の単語は「研究」,「提案」,「手法」,「利用」, 「システム」,196∼200位は「判断」,「観測」,「設定」,「動き」, 「行為」であったことからわかるように,今回削除対象にした絞 り込み語の大部分は特に専門性がない一般的な単語であった. 実クエリ集合から高頻度の絞り込み語を持つクエリを除い てから平均逆順位を算出した結果を図6bに示す.αが1.0か ら増加するにつれてTF-ICFの平均逆順位は緩やかに上昇し, α = 1.6でピークを迎えた後で,緩やかに下降し,α = 2.0ま での大部分の区間でTF-IDFよりも良い性能を示すことがわ かった. 表3: 出現頻度上位20件の絞り込み語 順位 単語 頻度 順位 単語 頻度 1 研究 1392 11 コミュニケーション 724 2 評価 1368 12 変化 723 3 分析 1252 13 論文 689 4 学習 970 14 モデル 661 5 情報 936 15 効果 660 6 システム 902 16 環境 643 7 影響 856 17 課題 600 8 行動 797 18 ロボット 584 9 支援 772 19 開発 580 10 比較 742 20 実験 564(a)実クエリ集合を用いた場合 (b)高頻度の絞り込み語を持つクエリを除いた場合 図6: MRR
7.
考
察
単語集合を用いた評価では,TF-ICFを用いることで, TF-IDFよりも専門性が高い単語を推薦できることがわかった.さ らに,重複率の平均値がTF-IDFよりかなり低いことから,特 定少数のコミュニティで頻出する語を比較的うまく抽出できて いることがわかった.ただし,被覆率の平均値がTF-IDFより かなり悪いことから,推薦する関連語数Nは比較的大きく設 定した方がよいと考えられる. 実クエリ集合を用いた評価では,現実のユーザが用いるクエ リの種類はいくつかあり,さらに必ずしも論文検索として妥当 なクエリを入力しているとは限らない可能性と,その理由が論 文検索の絞り込みに使うために適切な専門用語を思いつくこと が困難なタスクである可能性が示唆された.実際に,検索の裏 技に使われる単語や妥当とは思えない絞り込み語を除いた場合 に,TF-ICFの方が良い性能を示すことを確認した. αの値については,αを増加させると重複率がある時点から あまり変わらなくなること,表2の「人起点」のような,複合 語抽出処理の誤りにより生じたほとんど出現しない単語まで推 薦されてしまう可能性があること,そして関連語の出現コミュ ニティ数|C|と出現頻度|F |が小さくなりすぎて,想定してい た「特定少数のコミュニティで頻繁に使われる単語」から離れ てしまうために,あまり大きな値を用いるのは適切ではないこ とがわかった.さらに詳細な分析が必要だが,重複率の変化や 高頻度の絞り込み語を持つクエリを除いた実クエリ集合の分析 結果から,αの値は1.5から2.0程度にするのが適切ではない かと推測している.8.
お わ り に
本稿では,TF-ICFを用いることで,論文検索システムにお いてクエリの関連語を推薦する手法を提案した.TF-ICFは単 語のコミュニティ性に着目しているため,特に論文の題名と 概要などの限られた情報しか扱えないような場合に,従来の TF-IDFに代表される文書ベースの手法と比較して,専門性が 高い用語を推薦できることを,単語集合や実クエリ集合を用い た評価で確認した. ただし,論文検索システムであるCiNiiで用いられた実クエ リを簡単に分析した結果,我々が想定していたような専門用語 を絞り込み語に用いる以外のクエリパターンがあり,さらにそ の中に論文を探索するという行動においてあまり適切でない クエリパターンも多く存在する可能性が示唆された.今後は, CiNiiの検索履歴を用いてユーザの実際の検索行動を詳細に分 析し,論文検索サービスにおけるユーザ側の問題点と,それを 支援するために必要とされる技術を明らかにする予定である. また,本手法は,例えばソーシャルメディアの発言のような, 情報のテキスト長は短くても,その情報を生成した人間関係 ネットワークを持つようなデータに対しても有効だと思われる.謝
辞
本研究は,国立情報学研究所公募型共同研究「学術情報サー ビスのユーザ履歴データの分析」の助成を受けた. 文 献 [1] 石橋 和樹, 南出 直樹, 風間 一洋, 篠田 考祐. 単語のコミュニティ 性に基づいた専門用語の抽出. 人工知能学会全国大会論文集, 第 28巻, pp. 1–4, 2014. [2] 大塚 真吾, 喜連川 優. 大規模アクセスログを用いた検索支援システム. 日本データベース学会 Letters, Vol. 5, No. 1, pp. 13–16, 2006. [3] 近藤 光正, 森田 哲之, 田中 明通, 内山 匡. PC 上の Web 閲覧 履歴からのクエリ抽出技術を用いたモバイル情報検索システム. 人工知能学会全国大会論文集, 第 22 巻, pp. 1–4, 2008. [4] 堀 幸雄, 今井 慈朗, 中山 堯. ユーザの Web 閲覧履歴を用いた検 索支援システム. 情報知識学会誌, Vol. 17, No. 2, pp. 95–100, 2007. [5] 安辺川 武, 高野 明彦. 書誌検索における関連語表示法の検討. 言 語処理学会年次大会発表論文集, 第 16 巻, pp. 102–105, 2010. [6] 榊 剛史, 松尾 豊, 内山 幸樹, 石塚 満. Web 上の情報を用いた関 連語のシソーラス構築について. 自然言語処理, Vol. 14, No. 2, pp. 3–31, 2007.
[7] Aaron Clauset, M. E. J. Newman, and Cristopher Moore. Finding Community Structure in Very Large Networks.
Physical Review E, Vol. 70, No. 6, 2004.
[8] Karen Sp¨arck Jones. A Statistical Interpretation of Term Specificity and its Application in Retrieval. Journal of
Doc-umentation, Vol. 28, No. 1, pp. 11–21, 1972.
[9] Ricardo Baeza-Yates and Berthier Ribeiro-Neto. Modern
Information Retrieval. Addison Wesley, 1999.
[10] 土方 喜徳. 推薦システムのオフライン評価手法. 人工知能学会