Data Guard REDO 転送とネットワーク
のベスト・プラクティス Oracle Database
10g Release 2
Oracle Maximum Availability Architecture ホワイト・ペーパー
2007 年 1 月
Maximum
Availability
Architecture
Data Guard REDO 転送とネットワークの
ベスト・プラクティス
Oracle Database 10g Release 2
はじめに ... 3
概要 ... 3
本番データベースのパフォーマンスに与える影響の最小化 ... 3
最高レベルのデータ保護... 4
スイッチオーバーとフェイルオーバーの高速化 ... 4
REDO 転送のベスト・プラクティス... 4
十分な帯域幅について... 5
ARCH REDO 転送... 6
LGWR ASYNC REDO 転送... 6
LGWR SYNC REDO 転送... 7
すべての REDO 転送... 7
ネットワーク・チューニングのベスト・プラクティス... 8
Oracle Net のセッション・データ・ユニット(SDU)サイズ ... 8
TCP ソケットのバッファ・サイズ... 9
ネットワーク・デバイスのキュー・サイズ ... 10
スタンバイ I/O チューニングのベスト・プラクティス... 11
REDO 転送サービスのパフォーマンス・チューニング ... 12
本番データベースのパフォーマンス評価 ... 12
Data Guard に関連する待機イベント ... 13
LGWR SYNC チューニングの例... 15
LGWR ASYNC チューニングの例... 18
ARCH パフォーマンスの最適化... 20
ネットワーク・パフォーマンス問題の診断 ... 21
付録 A - REDO 転送の拡張... 22
LGWR ASYNC の拡張... 22
ARCH の拡張... 23
ネットワーク送信サイズの拡張 ... 23
付録 B – REDO 転送のパフォーマンス・テスト ... 24
ネットワーク送信サイズ - ネットワーク利用率の向上... 24
ARCH 転送 - リモート・アーカイブの迅速化... 25
LGWR ASYNC - 本番データベースのオーバーヘッドの軽減 ... 25
LGWR ASYNC - データ保護の強化... 26
LGWR SYNC - ネットワークの待機時間による影響 ... 28
付録 C - COMMIT NOWAIT と COMMIT WAIT の比較 ... 29
Data Guard REDO 転送とネットワークの
ベスト・プラクティス
Oracle Database 10g Release 2
はじめに
『Oracle Data Guard』構成[1]のパフォーマンス・チューニングを行う際に考慮すべ き領域が 2 つあります。1 つは、本番データベースで生成されたREDOデータを、 ローカルまたはリモートのスタンバイ・データベースに送信する、REDO転送サー ビスです。もう 1 つは、REDOデータをスタンバイ・データベースに適用する、 ログ適用サービスです。この『Maximum Availability Architecture (MAA)』[2] ホワイト・ペーパーでは、REDO転送サービスのパフォーマンスを最適化するた めのベスト・プラクティスに焦点を当てます。『REDO Apply』[3]を使用したフィ ジカル・スタンバイ・データベースへのログ適用サービスと、『SQL Apply』[4] を使用したロジカル・スタンバイ・データベースへのログ適用サービスのベスト・ プラクティスについては、別のMAAホワイト・ペーパーで説明します。MAAホワ イト・ペーパーは、Oracle Technology Network (OTN:
http://www.oracle.com/technology/index.html)および、OTN-Japan (http://otn.oracle.co.jp/)から入手できます。
また、このホワイト・ペーパーでは、オラクルの MAA テストの結果を記載して います。テスト結果は、構成を正しくチューニングすれば、パフォーマンスが向 上できることを示しています。以前のリリースの Data Guard を使い慣れている ユーザーには、Oracle Data Guard 10g Release 2 (10.2.0.2)で導入された REDO 転 送の拡張機能についての説明が含まれています。
注:このホワイト・ペーパーでは、読者がOracle Data GuardのREDO転送サービス に精通しており、『Oracle Data Guard概要および管理』[5]について把握している ことを前提としています。
概要
Oracle Data Guard 10g Release 2 では、さまざまなネットワーク環境とアプリケー ション・ワークロードにおいて、リカバリ・ポイント目標とリカバリ時間目標が 大幅に強化されました。オラクルの Maximum Availability Architecture (MAA)開 発チームが実施したテスト(後述)では、以下のメリットが明らかになりました。
本番データベースのパフォーマンスに与える影響の最小化
以下は、MAA テスト結果に基づいた十分なネットワーク帯域幅がある現実的な構 成のシナリオです。
• 同期転送モードを使用した、ニューヨークとモントリオール間(最大距 離 330 マイル、RTT10ms)の Data Guard 環境で、最大 4MB/秒の速度で REDO データを生成する本番データベースに与えるパフォーマンスの影 響を最小限に抑えて(5%未満)、データ損失ゼロを実現することが可能。 • 非同期転送モードを使用した、ボストンとロンドン間(最大距離 3,300 マ
イル、RTT10ms)の Data Guard 環境で、最大 20MB/秒の速度で REDO デー タを生成する本番データベースに与えるパフォーマンスの影響を 5%未 満に抑えることが可能。
最高レベルのデータ保護
データベース・パフォーマンスへの影響を最小化することで、ユーザーは、Data Guard を使用してデータ保護レベルを飛躍的に向上させることができます。 • さまざまなアプリケーション・ワークロードや、本番サイトとスタンバ イ・サイトの距離が最大数百マイルに及ぶネットワーク・トポロジに対 して、同期型のデータ損失ゼロの保護を利用できます。 • より長距離の環境や、ネットワークの待機時間がさらに長い Data Guard 環境では、非同期転送モードが利用できます。たとえば、REDO 速度 2MB/ 秒(高スループットのアプリケーション標準)の非同期転送モードを香 港とシンガポール間で使用した場合、データ損失の危険性を 3 秒未満に 抑えることができます(最大距離 1,600 マイル、RTT50ms)。 • ARCH REDO 転送の機能強化によって、拡張ネットワークやスタンバイ・ システムの停止が発生した後の本番データベースとスタンバイ・データ ベース間の再同期速度が向上しました。たとえば、ARCH を使用した 1GB のログ・ファイル転送に必要な時間は、最大 55%短縮されています。本 番データベースとスタンバイ・データベースを迅速に再同期することに よって、重要なデータを素早く保護状態に戻します。スイッチオーバーとフェイルオーバーの高速化
• Oracle Data Guard 10g Release 2 では、非同期モードの機能強化によって、 スタンバイ・データベースへのデータの転送および適用に必要な時間が 短縮されます。スタンバイ・データベースと本番データベースの同期が より頻繁に実行されるため、スタンバイ・データベースから本番データ ベース・ロールへのロール移行は数秒で完了します[6]。
ここからは、ネットワークとシステム環境に最高レベルのデータ保護を実現する、 Oracle Data Guard の REDO 転送とネットワークのベスト・プラクティスについて 詳しく説明していきます。
REDO 転送のベスト・プラクティス
Oracle Data Guard では、REDO 転送を行う方法として、ARCH、LGWR ASYNC、お よび LGWR SYNC の 3 つがあげられます[5]。次の項では、それぞれの REDO 転送 方法に適用するネットワーク要件と構成のベスト・プラクティスの決定における 検討事項について説明します。
十分な帯域幅について
すべての Data Guard 構成における目的は、リカバリ時間目標とリカバリ・ポイン ト目標を達成する速度で、リモートの障害リカバリ・サイトへの REDO データ転 送を行うことにあります。必要な容量を処理するための帯域幅が不足していれば、 どんなにチューニングを行ってもこの目的を達成することはできません。必要な 帯域幅を知るために、本番データベースで生成される REDO データの量を見積も ることから開始します。データ量を測定できる既存の本番アプリケーションかテ スト環境で実行されるアプリケーションがあれば理想的です。 REDO データ量についてのアプリケーション・スループットを決定するための もっとも簡単な方法は、通常のワークロードとピークのワークロードにおける AWR レポートを収集して、本番データベースが生成する REDO データの 1 秒あ たりのバイト数を測定することです。たとえば、ピーク時にアプリケーションが 3MB/秒の REDO データを生成する場合、プライマリ・データベースとスタンバ イ・データベース間のネットワーク・リンクには、最低でも 3MB/秒の送信ネット ワーク帯域幅が必要です。ネットワーク帯域幅は、メガビット/秒(Mbps)で表さ れます。変換すると、3MB/秒は 25.2Mbps のネットワーク・スループットになり ます(1MB = 1048576 バイト、1 バイト = 8 ビット、100 万ビット = 1 メガビット であるため、25.2Mbps になります)。この容量は、T1/DS1 リンクの処理能力(帯 域幅 1.544Mbps)を超えており、T3/DS-3 リンク(帯域幅 44.7Mbps)の範囲にな ります。 また、実際に達成されるスループットに影響を及ぼす、ネットワークや基盤とな る TCP/IP プロトコルのさまざまな特性について考慮する必要があります。これら には、ネットワークの肯定応答や、ネットワークの待機時間、その他の要因によっ て発生するオーバーヘッドが含まれます。これらの影響はそれぞれのワークロー ドやネットワークによって異なり、達成可能な実際のネットワーク・スループッ トを低下させます。 注:通常、待機時間と距離には直接的な相関関係があり、一般的な目安としては 33 マイル(53km)あたり 1 ミリ秒のRTTになります。この数字は目安であり、ネッ トワーク構成によって異なります。距離(伝播遅延)は待機時間に影響を与え、 待機時間はネットワークのRTTに影響を与えます。ただし、リピーターの数、ネッ トワーク・トラフィック、貧弱なシステム・パフォーマンス、ネットワークの混 雑など、ネットワークのRTTに影響を及ぼす要因は他にもあります。したがって、 このホワイト・ペーパーに含まれるMAAテスト結果では、距離に対するネット ワーク待機時間の比率ではなく、ネットワークのRTTを使用しています。ネット ワークRTTは‘Trace Route’ユーティリティを使用して簡単に測定でき、ネット ワークRTTの基準値が他の環境と比較する際の基盤となります。 帯域幅要件を決定するための追加の考慮事項として、使用する Data Guard の保護 モードと転送サービスがあげられます。たとえば、Data Guard の LGWR SYNC 同 期転送は、REDO データの生成速度に対応できる十分な帯域幅がない場合、本番 データベースのパフォーマンスに影響を与えます(これは、すべての同期転送方 式に該当します)。Data Guard の LGWR ASYNC 転送では、オンラインの REDO ログを使用してピーク時の REDO 生成をバッファに格納することで、本番データ ベースのパフォーマンスに影響を与えることなく、一時的にネットワークの最大 スループットを越えられるようにします。Data Guard の ARCH 転送では、ローカル・アーカイブ・ログをバッファとして使用することによって同様の結果をも たらします(ただし、潜在的なデータ損失の危険性は LGWR ASYNC より高くな ります)。 このホワイト・ペーパーの説明に従って、REDO データ量とネットワーク帯域幅 の初期評価を行うことを推奨します。取得したデータを出発点として、期待され る本番環境を代表する環境(システム・リソースとネットワーク・リソース、ネッ トワークの待機時間、Data Guard の保護モード)でワークロードをテストします。 テストでは、このホワイト・ペーパーで説明するチューニングの推奨事項とベス ト・プラクティスを必ず実装してください。 プライマリ・データベースとスタンバイ・データベースの間に必要な帯域幅を決定 したら、それぞれの転送タイプごとに以下のベスト・プラクティスを実装します。
ARCH REDO 転送
• ARCn プロセスの数を増やすことを検討します。データベース作成時の ARCn プロセスの数は、デフォルトで 2 です。初期化パラメータ LOG_ARCHIVE_MAX_PROCESSES によって、ARCn プロセスの最大数が 制御されます。Oracle Database 10g Release 2 では、このパラメータは最大 で 30 まで設定できます。以前のリリースでの最大値は 10 でした。 ARCn プロセスの数を増やすと、拡張ネットワークやスタンバイ・データ ベースの停止中に発生するアーカイブ・ログのギャップを迅速に解消で きます。また、ARCn プロセスに大きい数字を指定することによって、リ モートのアーカイブ並列処理がサポートされます。これは、次の項で説 明する MAX_CONNECTIONS 属性を使用して有効にできます。 注:LOG_ARCHIVE_MAX_PROCESSESに高い値を設定すると、同じネッ トワーク・リソースを使用する他のアプリケーションとの競合が増加す る場合があります。したがって、LOG_ARCHIVE_MAX_PROCESSESに最 適な値を決定する場合、他のアプリケーションへの影響を考慮してくだ さい。最適値は、それぞれの環境で、大きなアーカイブ・ログのギャッ プを含むシナリオをテストすることによってのみ決定できます。 • すべての宛先に対して、MAX_CONNECTIONS 属性を 2 以上に設定します (LOG_ARCHIVE_DEST_n 初期化パラメータを使用)。これによって、リ モートのアーカイブ並列処理が有効になり、アーカイブ・ログの転送に 必要な時間が大幅に短縮できます。MAX_CONNECTIONS に設定できる最 大値は 5 です。LGWR ASYNC REDO 転送
• Oracle Database 10g Release 2 から、LNS が本番データベース上のオンライ ン REDO ログを読み取る I/O に、十分な I/O 帯域幅を確保する必要があり ます。どのくらい読取りが増加するかはワークロードによって異なるた め、パフォーマンス・テストを実施して判断してください。
LGWR SYNC REDO 転送
• NET_TIMEOUT 属性の値を減らすことによって、ネットワークの停止が本 番データベースのパフォーマンスに与える影響を軽減します。この属性 によって、本番データベース上の LGWR がリクエストに対する Oracle Net Services からの応答を何秒待つかを指定できます。Oracle Database 10g Release 2 では、NET_TIMEOUT のデフォルト値は 180 秒です[5]。最小値 として 1 を設定できますが、スタンバイ・データベースの不要な切断を 避けるため、最小値は 10 秒を推奨します。 注:この値を 10 秒より低く設定する場合は、ご使用の環境を理解してか ら最適値を決定してください。たとえば、この値を 2 秒に設定し、3 秒間 の一時停止がたびたび発生するネットワークをご使用の場合、タイムア ウトが頻発し、データ保護レベルに影響を及ぼします。 • LGWR SYNC を使用する場合、トランザクションの REDO がローカルの プライマリ・データベースとリモートのスタンバイ・データベースに書 き込まれるまで、コミットはフォアグラウンドに返されません。オプショ ンの COMMIT NOWAIT パラメータを使用すると、REDO がディスクに書 き出されるのを待つことなく、コミットがアプリケーションに返されま す。したがって、アプリケーションやトランザクションで COMMIT NOWAIT を利用すると、デフォルトの COMMIT WAIT を利用した場合と 比較して、応答時間とデータベースのスループットが飛躍的に向上しま す。詳しくは、このホワイト・ペーパーの付録 C を参照してください。
すべての REDO 転送
• スタンバイの REDO ログの I/O をチューニングして効率化します。これ によって、本番データベース上の送信プロセス(LNS と ARCH)速度を 低下させることなく、RFS プロセスはスタンバイ・データベースへの書 込みを行うことができます。RFS は、スタンバイ・データベース上の Data Guard プロセスであり、REDO データを受け取って、スタンバイの REDO ログに書き込みます。• スタンバイの I/O サブシステムをチューニングするための代表的な領域 には次が含まれます。
• ストレージ・アレイの単一 I/O リクエストとして、1MB の I/O が発行 されるようにシステムを設定します。Linux の構成についての詳細は、 『Best Practices for Creating a Low-Cost Storage Grid for Oracle
Databases』[7]を参照してください。
• スタンバイの REDO ログが、高速ディスク・グループ内に正しく配 置されていることを確認します。
• スタンバイの REDO ログを多重化しないでください。余分な書込み を避けるため、追加のスタンバイ REDO ログ・メンバーを削除します。
ネットワーク・チューニングのベスト・プラクティス
この項では、すべての REDO 転送方法にあてはまり、Data Guard の REDO 転送パ フォーマンスを飛躍的に向上させる可能性のあるネットワーク・チューニングに ついて説明します。オラクルの MAA テストで測定されたパフォーマンス向上の 例については、後述します。次の項以降に示すサンプル・コマンドは Linux 向け であり、プラットフォームによって異なります。詳しくは後述しますが、一般に、 ネットワーク・チューニングには以下が含まれます。 • スタンバイ・ロケーションに転送する REDO データの量に十分対応でき る帯域幅であることを確認します。
• Oracle Net の RECV_BUF_SIZE と SEND_BUF_SIZE パラメータを、帯域 幅遅延積(BDP)の 3 倍に設定します。これによって、ネットワーク・ スループットの伸び率を最大にできます。
• Oracle Net のセッション・データ・ユニット(SDU)サイズを 32767 に設 定します。 • ネットワーク・デバイスに設定された送信キューと受信キューのデフォ ルト・サイズを増やします。Linux の場合、ifconfig コマンドを使用して 送信側の TXQUEUELENGTH インタフェース・オプションを増やし、受信 側では NET_DEV_MAX_BACKLOG カーネル・パラメータを増やします。将 来のロール移行への事前対策として、本番データベースとすべてのスタ ンバイ・データベースで両方のパラメータを変更しておくことを推奨し ます。
• Oracle Net の TCP_NODELAY パラメータが YES(デフォルト値)に設定さ れていることを確認します。
Oracle Net のセッション・データ・ユニット(SDU)サイズ
ネットワーク上にデータを送信する際、Oracle Net はセッション・データ・ユニッ ト(SDU)で指定されたサイズのユニットごとに、データをバッファに格納しま す。大量のデータを送信する場合やメッセージ・サイズが一貫している場合、SDU バッファのサイズを増やすことでパフォーマンスとネットワークの利用効率を向 上させることができます。SDU サイズは、Oracle Net の接続記述子内で設定する ことも、sqlnet.ora を使用してグローバルに設定することも可能です[8]。 Oracle Data Guard Broker の構成においては、sqlnet.ora ファイルの DEFAULT_SDU_SIZE パラメータを設定してください。
DEFAULT_SDU_SIZE=32767
Oracle Data Guard Broker 以外の接続記述子を使用する構成においては、プライマ リ・データベースの sqlnet.ora ファイルで現在の設定を変更できます。接続記述子 を使用して SDU サイズを設定する場合、動的なサービス登録は DEFAULT_SDU_SIZE で定義されたデフォルトの SDU サイズを使用するため、静 的 SID を使用する必要があります。接続記述子の記述リストに SDU パラメータを 指定します。 sales.us.acme.com=
(DESCRIPTION= (SDU=32767) (ADDRESS=(PROTOCOL=tcp) (HOST=sales-server) (PORT=1521)) (CONNECT_DATA= (SID=sales.us.acme.com)) )
スタンバイ・データベースでは、listener.ora ファイルの SID_LIST で SDU を 設定します。 SID_LIST_listener_name= (SID_LIST= (SID_DESC= (SDU=32767) (GLOBAL_DBNAME=sales.us.acme.com) (SID_NAME=sales) (ORACLE_HOME=/usr/oracle)))
TCP ソケットのバッファ・サイズ
TCP ソケットのバッファ設定によって、ネットワーク回線上で使用できる帯域幅 に関係なく、使用可能なネットワーク帯域幅が制御されます。使用可能な帯域幅 の利用効率を向上させるには、ソケットのバッファ・サイズをデフォルト値から 増やす必要があります。ネットワークの待機時間が高い値を示す場合、ソケット のバッファ・サイズを増やしてネットワーク帯域幅を十分に活用する必要があり ます。 最適なソケット・バッファ・サイズは、帯域幅遅延積(BDP)の 3 倍です。BDP を算出するには、リンクの帯域幅とネットワークのラウンド・トリップ時間(RTT) が必要です。RTT は、ネットワーク通信が本番データベースからスタンバイ・デー タベースへ伝わり、さらに元へ戻るために必要な時間であり、ミリ秒(ms)で測 定されます。次の例では、25 ミリ秒の RTT を持つギガビット・ネットワーク・リ ンクを想定しています。 BDP= 1,000 Mbps * 25msec (.025 sec) 1,000,000,000 * .025 25,000,000 Megabits / 8 = 3,125,000 bytes この例では、送信および受信ソケットの最適なバッファ・サイズは以下のとおり に計算されます。 ソケット・バッファ・サイズ= 3×帯域幅×遅延 = 3,125,000 * 3 = 9,375,000 バイト ソケットのバッファ・サイズは、オペレーティング システム・レベルまたは Oracle Net レベルで設定できます。ソケットに必要なバッファ・サイズは非常に大きくな ることがあるため(ネットワークの状態による)、Oracle Net レベルでの設定を推 奨します[8]。そうすることで、telnet などの通常の TCP セッションで余分なメモ リが使用されることを回避します。すべての送信および受信ソケット・バッファ の最大サイズを指定するパラメータが含まれているオペレーティング システムがあることに注意してください。Oracle Net でより大きいソケット・バッファ・サ イズを使用できるように、これらの値を調整する必要があります。
Oracle Data Guard Broker または Oracle Enterprise Manager の構成では、
sqlnet.ora ファイルを使用して、必要な送信および受信バッファ・サイズを指 定します。例:
RECV_BUF_SIZE=9375000 SEND_BUF_SIZE=9375000
Oracle Data Guard Broker 以外の接続記述子を使用する構成において、特定のプロ トコル・アドレスまたは記述に対してバッファ領域パラメータを指定します。次 の例では、送信および受信ソケットのバッファ・サイズを、クライアント側の sqlnet.ora ファイル内で特定の接続記述子の記述属性として指定しています。 standby = (DESCRIPTION= (SEND_BUF_SIZE=9375000) (RECV_BUF_SIZE=9375000) (ADDRESS=(PROTOCOL=tcp) (HOST=hr1-server)(PORT=1521)) (CONNECT_DATA= (SERVICE_NAME=standby))) ソケット・バッファ・サイズは、Data Guard 構成内すべてのサイトで設定する必 要があります。スタンバイ・データベースでは、sqlnet.ora ファイルまたは listener.ora ファイルを使用して指定できます。 listener.ora ファイルでは、特定のプロトコル・アドレスまたは記述に対して、 バッファ領域パラメータを指定できます。 LISTENER= (DESCRIPTION= (ADDRESS=(PROTOCOL=tcp) (HOST=sales-server)(PORT=1521) (SEND_BUF_SIZE=9375000) (RECV_BUF_SIZE=9375000)))
ネットワーク・デバイスのキュー・サイズ
カーネル・ネットワーク・サブシステムと、ネットワーク・インタフェース・カー ドのドライバとの間のキュー・サイズを調整できます。すべてのキューには、ロー カル・バッファのオーバーフローによる損失を発生させないようなサイズを指定 する必要があります。したがって、それぞれのネットワーク接続に最適なキュー・ サイズを設定するには、慎重にチューニングを行う必要があります。高帯域幅の ネットワークの場合は特に注意が必要です。 ローカル・キューに損失が発生すると、TCP が混雑制御を始めることによって TCP の送信速度が制限されるため、これらの設定は、特に TCP にとって重要です。 Linux の場合、インタフェース送信キューとネットワーク受信キューの 2 つの キューについて考慮する必要があります。送信キューのサイズは、ネットワーク・ インタフェース・オプションの txqueuelen を使用して設定します。ネットワー ク受信キューのサイズは、カーネル・パラメータの netdev__max_backlog を 使用して設定します。例:echo 20000 > /proc/sys/net/core/netdev_max_backlog echo 1 > /proc/sys/net/ipv4/route/flush
ifconfig eth0 txqueuelen 10000 txqueuelen のデフォルト値である100 は、長距離の高スループット・ネットワー ク回線には不十分です。たとえば、待機時間が 100 ミリ秒であるギガビット・ネッ トワークの場合、txqueuelen に少なくとも 10000 を指定する必要があります。 待機時間に応じたキュー・サイズの設定については、オペレーティング システム のベンダーに問い合わせてください。 次の表に、MAA テストにおける、TCP ソケットのバッファ・サイズとネットワー ク・デバイスのキュー・サイズを調整することで得られたネットワークの改善結 果を示します。 表 1:TCP/IP のチューニング効果 テスト段階 テスト時間(秒) 転送データ量 達成されたネット ワーク・スループッ ト(メガビット/秒) 変化率 チューニング前 60 77.2MB 10.8Mbps 該当なし ネットワーク・ソ ケットのバッファ・ サイズを、デフォル トの 16K から 3× BDP に変更した後 60 5.11GB 731.0Mbps チューニング前 のベースライン に対して 665%の 改善 上記の調整を行った 上で、デバイス・ キューの長さをデ フォルトの 100 から 1,000 に増やした後 60 6.55GB 937.0Mbps 28%の改善
スタンバイ I/O チューニングのベスト・プラクティス
REDO データは、スタンバイで受信された後にディスクに書き込まれます。構成 によっては、REDO を受信した肯定応答をプライマリに送り返す前に、ディスク への書込みを行う必要があります。したがって、スタンバイの I/O を最適化する ことが重要です。スタンバイの I/O パフォーマンスを向上させるには、以下のベ スト・プラクティスを検討してください。1. Oracle データベースが ASYNC I/O を利用できることを確認します。Oracle データベースは、デフォルトで非同期 I/O を使用するように設定されてい ます。また、オペレーティング システム、Host Bus Adapter(HBA)ドラ イバ、およびストレージ・アレイを正しく設定する必要があります。 2. I/O スタックのすべてのレイヤーで、I/O 書込みサイズを最大化します。 レイヤーには次のうちの 1 つ以上が含まれます。オペレーティング シス テム(非同期書込みサイズを含む)、デバイス・ドライバ、ストレージ・ ネットワーク転送サイズ、ディスク・アレイ。 3. SRL を配置する ASM ディスク・グループには、プライマリのオンライン
REDO ログのある ASM ディスク・グループと同じ、またはそれ以上のディ スクを備えてください。 4. スタンバイの REDO ログを多重化しないでください。 5. 通常、RAID5 構成の RAID コントローラは、ミラーリング構成の場合と比 べて、書込みのパフォーマンスが低下します。SRL への書込みプロセスが ボトルネックになっている場合は、RAID 構成の変更を検討してください。
REDO 転送サービスのパフォーマンス・チューニング
上述のとおり、Data Guard 構成のパフォーマンスに影響を及ぼす要因には、保護 モード、選択した転送オプション、ネットワークの帯域幅と待機時間、およびオ ンライン REDO ログとスタンバイ REDO ログに対する I/O パフォーマンスが含ま れます。この項では、これらの要因が本番データベースのパフォーマンスに影響 を与える可能性を評価する方法と、この影響を最小限に抑えるための設定の チューニング方法を示します。本番データベースのパフォーマンス評価
すべてのパフォーマンス・チューニング作業における第一歩は、良いベースライ ンを集めることです。Data Guard の転送サービスを実装する前に、通常時ワーク ロードとピーク時ワークロードについての AWR レポートを収集します。AWR の 自動スナップショット間隔を 10~20 分に短く設定して、ストレス・テスト中のパ フォーマンス・ピークやピーク・ロードを取得します。通常の運用では、60 分間 隔で十分です。 本番データベースのスループットやパフォーマンスの良い指標を得るための、ベー スラインとなる AWR レポート内で調査すべき主な項目は、以下のとおりです。 • REDO データ量 - このレポート中に生成された REDO データのバイト数 • トランザクション - レポートに対する TPS • REDO 書込み数 - このレポート中に実行された REDO の書込み数 'REDO データ量'を'REDO 書込み数'で割った数が、REDO 書込みサイズの平均バイ ト数になります。分析しているパフォーマンスが、LGWR SYNC または LGWR ASYNC (後述)を使用している場合、これは重要な基準値になります。 AWR レポートから得られたデータの使用に加えて、V$SYSMETRIC_HISTORY ビューを調べることで、本番データベースの応答時間を測定できます。このビュー に含まれる情報は、ユーザー・クエリーへの応答時間の良い指標となります。こ のビューを調べる場合、次の基準値について検討してください。 • トランザクションあたりの応答時間 - トランザクションに対する応答時間 • SQL サービス応答時間 - ユーザー・コールあたりの応答時間(センチ秒) • 1 秒あたりのデータベース時間 - DB 時間(センチ秒)/経過時間(秒) 適切なベースラインを得た後で Data Guard 機能を有効にして、通常運用とピーク 運用における AWR レポートを収集します。これらの AWR レポートをベースライ ンと比較することで、Data Guard 機能を有効にした場合の本番データベースのパフォーマンスを導き出します。このプロセスの詳細については後述します。
Data Guard に関連する待機イベント
本番データベースからスタンバイ・データベースへの REDO データ送信にかかる 時間は、主にネットワークを横断する時間とスタンバイ・ホスト上のディスクに 書き込む時間の 2 つに分類されます。合計時間を収集する待機イベントは本番 データベース上で取得しますが、I/O にかかる時間はスタンバイ・データベース上 で参照します。以下の待機イベントは、ARCH もしくは LGWR(SYNC または ASYNC)プロセスを 使用して、本番データベースからスタンバイ・データベースへ REDO データを送 信するプロセスで発生するイベントです。これらの待機イベントは、本番データ ベースから取得されます。
表 2:プライマリ・データベース上の主要な Data Guard 待機イベント
イベント名 プロセス 説明
ARCH wait on ATTACH ARCH この待機イベントは、すべてのアーカイバ・プロセスが新し
い RFS 接続を作成するために費やす時間を監視します。
ARCH wait on SENDREQ ARCH
この待機イベントは、すべてのアーカイバ・プロセスがロー カル・ディスクとリモートにアーカイブ・ログを書き込むた めに費やす時間を監視します。
ARCH wait on DETACH ARCH この待機イベントは、すべてのアーカイバ・プロセスが RFS
接続を削除するために費やす時間を監視します。 LNS wait on ATTACH LGWR この待機イベントは、すべての LNS プロセスが新しい RFS 接続を作成するために費やす時間を監視します。 LNS wait on SENDREQ LGWR この待機イベントは、すべての LNS プロセスが受信 REDO をディスクに書き込む時間と、リモートのアーカイブ REDO ログの開いて閉じる時間を監視します。 LNS wait on DETACH LGWR この待機イベントは、すべての LNS プロセスが RFS 接続を 削除するために費やす時間を監視します。 LGWR wait on LNS LGWR この待機イベントは、ログ・ライター(LGWR)プロセスが LNS プロセスからのメッセージを受信するために待機する時 間を監視します。 LNS wait on LGWR LGWR この待機イベントは、LNS プロセスがログ・ライター(LGWR) プロセスからのメッセージを受信するために待機する時間を 監視します。 LGWR-LNS wait on channel LGWR この待機イベントは、ログ・ライター(LGWR)プロセスま たは LNS プロセスがメッセージを受信するために待機する 時間を監視します。
プライマリ・データベースで監視する必要のある、重要な I/O 関連の待機イベン トには次が含まれます。
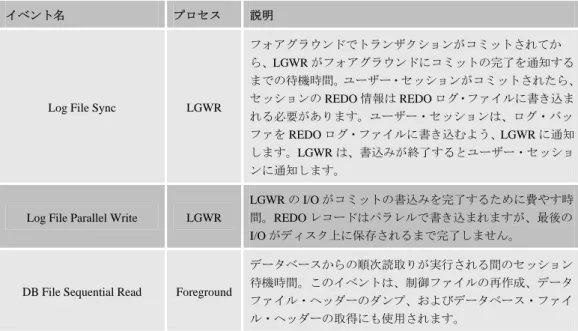
表 3:Data Guard に関連する主要なデータベース待機イベント
イベント名 プロセス 説明
Log File Sync LGWR
フォアグラウンドでトランザクションがコミットされてか ら、LGWR がフォアグラウンドにコミットの完了を通知する までの待機時間。ユーザー・セッションがコミットされたら、 セッションの REDO 情報は REDO ログ・ファイルに書き込ま れる必要があります。ユーザー・セッションは、ログ・バッ ファを REDO ログ・ファイルに書き込むよう、LGWR に通知 します。LGWR は、書込みが終了するとユーザー・セッショ ンに通知します。
Log File Parallel Write LGWR
LGWR の I/O がコミットの書込みを完了するために費やす時 間。REDO レコードはパラレルで書き込まれますが、最後の I/O がディスク上に保存されるまで完了しません。
DB File Sequential Read Foreground
データベースからの順次読取りが実行される間のセッション 待機時間。このイベントは、制御ファイルの再作成、データ ファイル・ヘッダーのダンプ、およびデータベース・ファイ ル・ヘッダーの取得にも使用されます。 ログ転送サービスに関連するスタンバイの I/O 待機イベントの参照は、スタンバ イ上で実行します。I/O 待機イベントは、フィジカル・スタンバイとロジカル・ス タンバイの両方で変わりませんが、収集方法は異なります。スタンバイがロジカ ル・スタンバイである場合、AWR レポートを使用して待機イベントを参照します。 スタンバイがフィジカル・スタンバイである場合、SQL クエリーを使用して情報 を取得します。フィジカル・スタンバイでは、次のクエリーを使用できます。
SQL> SELECT EVENT, TOTAL_WAITS,
ROUND(TIME_WAITED/100) "TIME(S)", AVERAGE_WAIT*10 "AVG(MS)",
TO_CHAR(SYSDATE, 'DD-MON-YYYY HH:MI:SS') TIME FROM V$SYSTEM_EVENT 次の待機イベントは、スタンバイ上で I/O の実行に費やされる時間を示します。 表 4:スタンバイ・データベース上の主要な Data Guard 待機イベント イベント名 プロセス 説明 RFS Write RFS スタンバイ REDO ログまたはアーカイブ・ログへの書込みに 費やされる時間と、REDO ブロックのチェックサム検証など、 I/O 以外の処理に費やされる時間。
RFS random i/o RFS スタンバイの REDO ログへの書込みに費やされる時間。
上記の待機イベントに費やされる時間は、平均的な書込みサイズとストレージ・ア レイの I/O 容量に依存します。チューニングに関するアドバイスについては、この ホワイト・ペーパーの"スタンバイ I/O チューニングのベスト・プラクティス"の項 を参照してください。
LGWR SYNC チューニングの例
Data Guard に関するドキュメント[5]で説明されているとおり、LGWR SYNC の REDO 転送は同期プロセスであり、以下のアクションが完了するまで、ユーザー・ コミットに対するデータベースの肯定応答は送られません。 1. LGWR によって、本番データベースのオンライン REDO ログに REDO が 書き込まれる(LGWR SYNC が使用されていない場合は、この手順が完了 すると、ユーザー・コミットに肯定応答が返されます。ただし、付録 C に 説明されている COMMIT NOWAIT パラメータが使用されている場合を除 きます)。 2. 本番データベース上の Data Guard LNS プロセスが、スタンバイ・データ ベース上の Data Guard RFS プロセスにネットワーク送信を実行する。 REDO 書込みサイズが 1MB を超える場合、LNS はスタンバイ上の RFS プ ロセスに複数のネットワーク送信を発行します。 3. RFS プロセスが LNS によって送信された REDO を受信し、スタンバイの REDO ログへの I/O を完了する。 4. REDO が受信され、ディスクに書き込まれたことを知らせる肯定応答が、 RFS プロセスから LNS に送り返される。 5. スタンバイですべての REDO が正しく受信され、ディスクに書き込まれ たことが LNS から LGWR に通知される。
本番データベース上で手順 1 にかかる時間は、"Log File Parallel Write"待機イベン トで示されます。手順 2~5 にかかる時間は、待機イベント"LNS wait on SENDREQ" で示されます。"LNS wait on SENDREQ"待機イベントは、スタンバイ上で取得さ れる"RFS write"待機イベントの時間を差し引くと、ネットワーク時間と RFS の I/O 時間に分割できます。これらの待機イベントをスタンバイ上で算定するには、上 述の"Data Guard に関連する待機イベント"の項に説明されているクエリーを使用 するか(フィジカル・スタンバイの場合)、AWR レポートを使用します(ロジカ ル・スタンバイの場合)。 "RFS write"待機イベントは、I/O と RFS 処理の実行に必要な時間を示します。実 際の RFS I/O 時間は、"RFS random i/o"待機イベントを調べることで算定できます。 次の LGWR SYNC チューニングの例は、待機時間が 10 ミリ秒のギガビット・ネッ トワークを使用して、1 秒あたり 152KB の REDO を生成する OLTP アプリケーショ ンに基づいたものです。ベースラインとなる AWR レポートを取得した後に、フィ ジカル・スタンバイが作成され、本番データベースは LGWR SYNC AFFIRM を使 用してスタンバイに REDO を転送するよう設定されました。 注:AFFIRMでは、スタンバイ・データベースでREDOが受信されて、スタンバイ REDOログへの書込みが終了するまで、RFSは本番データベースへ肯定応答を送信 しません。これはLGWR SYNCのデフォルト設定です。
ネットワークと I/O のチューニングを実行する前に、アプリケーションが実行さ れ、AWR レポートが収集されました。AWR レポートを分析した後で、このホワ イト・ペーパーで説明されたチューニングの推奨事項が実行され、再度 AWR レ ポートが収集されました。 LGWR SYNC を有効にして行ったそれぞれのテストにおけるロード・プロファイ ルは、以下のとおりです。 表 5:LGWR SYNC でのロード・プロファイル
ロード・プロファイル Data Guard 非使用時 Data Guard 使用時
REDO 速度 152,057 バイト/秒 145,993 バイト/秒 REDO 書込み数 137 114 REDO 書込みサイズ 1,109 バイト 1,280 バイト 次の表に、テストの各段階における重要な待機イベントを示します。I/O とログ・ ファイルの同期は、アプリケーション・パフォーマンスの良い指標となるので重 要です。 表 6:LGWR SYNC の待機イベント
待機イベント Data Guard 非使用時 Data Guard 使用時
log file sync 12 17
db file sequential read 19 17
log file parallel write 1 1
LNS wait on SENDREQ 該当なし 13
RFS random i/o 該当なし 2
注:待機イベントは、ミリ秒で表示されています。LNS wait on SENDREQ待機イ ベントとRFS random i/o待機イベントは、Data Guard機能が有効でない場合のベー スラインとしては適していません。
log file sync 待機イベントは、よく調べる必要のある重要な待機イベントです。log file sync(LFSY)待機イベントは、REDO がフラッシュされてコミットが永続的 になるまでの、フォアグラウンドが待つ時間です。log file sync 待機イベントは、 以下に分かれます。 1. LGWR のウェイクアップ(アイドル状態にある場合) 2. LGWR による、書き込み対象の REDO の収集と I/O の発行 3. ログ書込み I/O の完了にかかる時間 4. LGWR I/O の後処理 5. LGWR からフォアグラウンドへの書込み完了通知 6. フォアグラウンドのウェイクアップ
手順 2 および手順 3 は、"REDO 書込み時間"統計情報に累積されます。手順 3 は、 "log file parallel write"待機イベントです。システム負荷が増加すると、手順 5 およ び手順 6 の値は非常に大きくなります。これは、フォアグラウンドに通知が送ら れた後も、OS が実行をスケジューリングするのに時間がかかる場合があるからで す。‘log file sync’待機イベントに高い値が確認される場合、合計待機時間を個々 のコンポーネントに分類してから、時間のかかるコンポーネントのチューニング を行ってください。 同時実行性の高いアプリケーションの場合、ネットワークの待機時間が長くなっ てもデータベース全体のスループットに与える影響はごくわずかですが、個別の トランザクションの応答時間は増加する場合があります。同時実行性の高いアプ リケーションの待機時間が増加すると、LGWR の平均書込みサイズも増加すると 考えられます。チューニングを実行した後、本番データベースのスループットに 与える影響は 4%にまで下がりました。実行したチューニングには、以下の項目が 含まれます。 • スタンバイ・システム上で、/proc/sys/fs/aio-max-size を、デフォルトの 131072 から 1048576 に増加 • スタンバイのログ・ファイル・グループから 2 番目のログ・ファイル・ メンバーを削除 • スタンバイ上の ASM ディスク・グループにディスクを追加 • RECV_BUF_SIZE および SEND_BUF_SIZE を帯域幅遅延積の 3 倍に設定 • ネットワーク・インタフェースに付随するデバイス・キュー・サイズを デフォルトの 100 から 10,000 に増加 この例では、REDO 書込みサイズが小さかったため、ネットワークの送信および 受信バッファ・サイズを増加しても、LNS のスループットへの大幅な効果は得ら れませんでした。バッファ・サイズの増加が効果を発揮するのは、REDO 書込み サイズを増やしている場合です。REDO 書込みサイズが小さい場合、もっとも大 きいチューニングのメリットは、スタンバイ上の I/O の最適化から得られます。 また、LGWR SYNC が発行するスタンバイへのネットワーク送信の最大サイズは、 REDO 書込みサイズには関係なく、デフォルトで 1MB であることに注意が必要で す。これによって、REDO 書込みサイズが 1MB を超えるアプリケーションでは、 ネットワークのラウンド・トリップが複数発生します。この動作は Oracle Database 10g (10.2.0.4)で変更されており、1MB より大きい REDO 書込みサイズに対応 するよう変更されました。Oracle Database 10g (10.2.0.4)より以前のバージョン を使用していて、REDO 書込みサイズが 1MB を超える場合、バージョンごとの最 適化方法に関する詳細は、MetaLink ノート 404985.1 を参照してください。 LGWR SYNC による本番データベースのパフォーマンスへの影響を大幅に軽減す る必要がある場合、アプリケーションまたはその一部で COMMIT NOWAIT また は非永続コミットが利用できるかどうかを確認します。COMMIT NOWAIT IMMEDIATE を使用している場合、フォアグラウンド・プロセスは LGWR にログ I/O の実行を通知しますが、REDO が書き込まれるまで待つことはありません。 COMMIT NOWAIT BATCH の場合、フォアグラウンドはそのままアプリケーショ ンに返されます。両方のケースにおいて、フォアグラウンドはローカルの LGWR 書込みの完了や、スタンバイでの REDO の受信を待たずに処理を再開できます。
LGWR SYNC を有効にした場合、Oracle Real Application Clusters を使用したサンプ ルの OLTP ワークロードにおいて、COMMIT NOWAIT BATCH を使用すると、デ フォルトの COMMIT IMMEDIATE WAIT と比較して次の結果が確認されました。
• 10~35%の本番 REDO 速度の向上 • 10~35%のユーザー・コール速度の向上 • 10~33%の本番トランザクション速度の向上 • 92%のユーザー・コール応答時間の短縮 • 90%のトランザクション応答時間の短縮 インスタンスまたはデータベースの障害時に非永続コミットを容認できる場合は、 この選択肢が最適です。このようなタイプのアプリケーションの例には、ショッ ピング・カート・アプリケーションがありますが、購入トランザクション、動向 のサンプリング/追跡システム、データ・ウェアハウス・アプリケーションやデー タ・マート・アプリケーションには適していません。詳しくは、付録 C を参照し てください。
LGWR ASYNC チューニングの例
LGWR ASYNC は、REDO がリモートに送信されるのを待つことなく、ユーザー・ コミットを実行できる非同期転送サービスです。LGWR ASYNC を効率的にチュー ニングするには、以下について考慮してください。 1. LGWR が、本番データベースのオンライン REDO ログに REDO を書き 込む。2. 本番データベース上の Data Guard LNS プロセスが、オンライン REDO ロ グを読み取り、スタンバイ・データベース上の Data Guard RFS プロセスに ネットワーク送信を実行する。 3. RFS プロセスが、LNS によって送信された REDO を受信する。 4. RFS プロセスが、REDO が受信されたことを知らせる肯定応答を LNS に 送り返す。 5. RFS プロセスが、スタンバイの REDO ログに REDO を書き込む。 手順 2~4 は、本番データベース上の待機イベント、"LNS wait on SENDREQ"で示 されます。手順 5 は、上述のクエリーを使用してスタンバイから取得された"RFS write"で示されます。実際の RFS 書込み時間は、"RFS random i/o"(スタンバイの REDO ログへの書込み)または"RFS sequential i/o"(アーカイブ・ログ・ファイル への書込み)で示されます。"RFS write"待機イベントは、I/O と追加の RFS 処理 の実行に必要な時間を表します。これらの待機イベントをスタンバイ上で算定す るには、上述の"Data Guard に関連する待機イベント"の項に説明されているクエ リーを使用するか(フィジカル・スタンバイの場合)、AWR レポートを使用しま す(ロジカル・スタンバイの場合)。 次の LGWR ASYNC チューニングの例は、1 秒あたり 5.5MB を超える REDO を生 成する OLTP アプリケーションです。ベースラインとなる AWR レポートを取得 した後に、フィジカル・スタンバイが作成され、本番データベースは LGWR ASYNC を使用してスタンバイに REDO を転送するよう設定されました。ネットワークや
I/O のチューニングを実行する前に、アプリケーションが実行され、新しい AWR レポートが収集されました。次に、このホワイト・ペーパーで説明されたチュー ニングの推奨事項が実行され、再度 AWR レポートが収集されました。 LGWR ASYNC を有効にして行った 3 つのテストにおけるロード・プロファイル は、以下のとおりです。 表 7:LGWR ASYNC でのロード・プロファイル
ロード・プロファイル Data Guard 非使用時 Data Guard 使用時
REDO 速度 5.66MB/秒 5.49MB/秒 REDO 書込み数 741 746 上の表が示すとおり、LGWR ASYNC を有効にしたことによる影響は約 4%でした。 この影響は、本番データベース上のオンライン REDO ログで、LNS が追加のディ スク読取りを実行したことに起因すると考えられます。 実行したチューニングには、以下の項目が含まれます。 • スタンバイ上で、/proc/sys/fs/aio-max-size をデフォルトの 131072 から 1048576 に増加 • スタンバイのログ・ファイル・グループからログ・ファイル・メンバー を削除 • スタンバイ上の ASM ディスク・グループにディスクを追加 • RECV_BUF_SIZE および SEND_BUF_SIZE を帯域幅遅延積の 3 倍に設定 • ネットワーク・インタフェースに付随するデバイス・キュー・サイズを 増加 LGWR ASYNC を使用した場合、本番データベースのオーバーヘッドとチューニ ングによる影響はごくわずかに見えますが、スタンバイへのネットワーク転送を 効率化して、REDO 転送における遅延を防止することは重要です。これによって、 データ損失が発生する可能性を最小限に抑えます。ネットワーク・チューニング のメリットは、以下の表に示す待機イベントについて調べると、より明らかにな ります。 表 8:LGWR ASYNC の待機イベント
待機イベント Data Guard 非使用時 Data Guard 使用時
LNS wait on SENDREQ 該当なし 179 ミリ秒 RFS random i/o 該当なし 21 ミリ秒 注:待機イベントの平均値は、ミリ秒で表示されています。Data Guardが有効では ないので、ベースラインとしては適さない待機イベントもあります。 上の表が示すとおり、LNS がネットワーク送信を実行するのに必要な時間は、ス タンバイ上の I/O とネットワーク・ソケットのバッファ・サイズによって大幅に 影響を受けます。LNS によって送信されるデータ量は、ワークロードによって異
なる場合があることに注意してください。LNS 送信サイズが分かれば、ネットワー クと I/O のテストを行って、それぞれの段階で費やされた時間が妥当であるかど うかを確認できます。LNS のネットワーク送信サイズを決定するには、本番デー タベース上で次のクエリーを実行します。
SQL> SELECT OPEN_COUNT, CLOSE_COUNT, WRITE_COUNT, MINIMUM_WRITE, MAXIMUM_WRITE, TOTAL_WRITE, LOGS_SKIPPED,TERMINATIONS
FROM X$KCRRASTATS WHERE TOTAL_WRITE > 0;
LNS 書込みサイズの平均値を取得するには、TOTAL_WRITE を WRITE_COUNT で 割ります。
ARCH パフォーマンスの最適化
どの REDO 転送を選択するかに関係なく、常に 1 つの ARCH プロセスが、オンラ イン REDO ログのローカル・アーカイブ用に使用されます(Oracle Data Guard 10g 以上)。ARCH REDO 転送サービスが設定されている場合、はじめにローカル・ アーカイブを完了してから、次のロジックを使用して、別の ARCH プロセスによっ てリモート・アーカイブが開始されます。
1. ローカル・アーカイブ・ログから 10MB を読み取り、スタンバイ上の RFS プロセスにネットワーク送信を発行する。
2. RFS プロセスが ARCH プロセスによって送信された REDO を受信し、Data Guard の構成方法に応じて、スタンバイの REDO ログまたはアーカイブ REDO ログへの I/O を実行する。 3. I/O が完了したら、RFS が ARCH へ肯定応答を送り返す。 4. ARCH が次の 10MB を読み取り、上記プロセスを繰り返す。 リモートのアーカイブ先に MAX_CONNECTIONS 属性が設定されている場合、1 つ のアーカイブ・ログのリモート送信に最大で 5 つの ARCH プロセス(設定により 異なる)を使用できます。実際の RFS 書込み時間は、"RFS random i/o"(スタンバ イの REDO ログへの書込み)または"RFS sequential i/o"(アーカイブ・ログ・ファ イルへの書込み)で示されます。
ARCH wait on SENDREQ 待機イベントを調べて ARCH のパフォーマンスを判断す ると、結果を誤る可能性があります。これは、ARCH の ping メカニズム(スタン バイの可用性の定期的なチェック)によるネットワーク・アクティビティが、こ の待機イベント内で取得されているため、誤った数字の原因となる場合があるか らです。ARCH のパフォーマンスを評価する方法としてもっとも信頼性が高いの は、log_archive_trace のレベルを 128 に設定して、アラート・ログに表示される追 加メッセージを取得することです。タイムスタンプとアーカイブ・ログのファイ ル・サイズを使用して、全体的なスループットが算出できます。
LGWR SYNC または LGWR ASYNC では、スタンバイ上のディスクI/O とプライマ リのフラッシュ・リカバリ領域を効率化するとともに、ネットワーク・ソケット のバッファ・サイズを適切にすることが重要です。ASYNC に対して実行した チューニング項目は、ARCH に対しても実行する必要があります。これらのチュー ニング項目に加えて、リモート宛先の MAX_CONNECTIONS 属性に 5 を設定する必 要があります。これによって、ARCH 転送の並列処理が有効になり、個々のアー
カイブ・ログ・ファイルの全体的なスループットが改善されます。
また、LOG_ARCHIVE_MAX_PROCESSES 初期化パラメータは最高で 30 に設定す ることができ、最大で 30 個の ARCH プロセスを有効にします(ローカル・アー カイブ専用に 1 個、ローカルまたはリモートのアーカイブ用に 29 個)。Oracle Database 10g Release 2 では、デフォルト値は 2 です。Data Guard を使用する場合、 このデフォルト値を増やすことを推奨します。ネットワークやスタンバイ・デー タベースの停止によって、スタンバイで発生したアーカイブ・ログ・ギャップが 解決されると、ARCH プロセスはローカル・アーカイブによって消費されます。 また、REDO 転送サービスがアーカイバ・プロセスを利用するように設定されて いる場合は、通常のリモート・アーカイブによって消費されます。 MAX_CONNECTIONS に設定した値に対応するため、最低限の必要な値を LOG_ARCHIVE_MAX_PROCESSES に設定します。追加のREDO ストリームをサ ポートする帯域幅がある場合、LOG_ARCHIVE_MAX_PROCESSES に、ネットワー クが対応できる最大値を設定することを検討してください。これによって、複数 のアーカイブ・ログをパラレルで送信できるため、ピーク時のワークロードの処 理や、ネットワークやスタンバイの障害によるログのアーカイブ・ギャップの迅 速な解決が可能になります。
ネットワーク・パフォーマンス問題の診断
はじめに、ネットワーク・チューニングの項に記載されているすべての項目が対 応済みであることを確認します。問題が続く場合、OS レベルの標準的な診断手法 を使用して、ネットワーク・パフォーマンスの問題とボトルネックを調査します。 OS ユーティリティを使用して、以下の項目について調べます。 1. CPU アクティビティ 2. メモリ使用率 3. ネットワークのエラーと衝突 4. iperf などのツールを使用したネットワーク・スループット[9] 5. TCP パケットのダンプ(sniffer トレース) OS レベルのボトルネックを取り除き、データベースのアラート・ログとデータ ベースのダンプ出力先である bdump、udump、cdump を調べて、エラーが発生し ていないことを確認します。LGWR SYNC REDO 転送サービスを使用している場 合、エラーが頻繁に発生したり、スタンバイの RFS プロセスが切断されたりする と、本番データベースのオーバーヘッドが増加する場合があります。付録 A - REDO 転送の拡張
REDO 転送サービスは、本番データベースからローカルまたはリモートのスタンバ イ・データベースの宛先に REDO データを送信します。リモートの送信先には、次 のいずれかのタイプが含まれます。Data Guard のスタンバイ・データベース(フィ ジカル・スタンバイ・データベースおよびロジカル・スタンバイ・データベース)、 アーカイブ REDO ログ・リポジトリ、Oracle Change Data Capture のステージング・ データベース、Oracle Streams のダウンストリーム取得データベース。Oracle Database 10g Release 2 には、以下の REDO 転送サービスの拡張が含まれます。
LGWR ASYNC の拡張
パフォーマンスの向上:Oracle Database 10g Release 2 より以前のバージョンでは、 ネットワーク・サーバー・プロセス(LNSn)は、ネットワークI/Oを発行した後、 ネットワークI/Oの完了を待っていました。それぞれのLNSnプロセスには、ユー ザー設定可能なメモリ内バッファが含まれ、LGWRプロセスから送信REDOデータ を受け入れます。LNSnプロセスの処理が追いつかずに(ピーク時のREDOデータ 量が、使用可能なネットワーク帯域幅を超えた場合など)バッファがFULLになっ た場合、ネットワーク送信の完了やタイムアウトの発生によって十分なバッファ 領域が確保されるまで、LGWRプロセスは停止します。この一時的な停止は、本 番データベースのスループットに影響を与える場合があります。
Oracle Database 10g Release 2 では、新しいLGWR ASYNCの動作によって、本番デー タベースを停止させる可能性を排除します。LOG_ARCHIVE_DEST_n初期化パラ メータでLGWR属性とASYNC属性が指定されている場合、ログ・ライター・プロセ スは、ASYNCバッファに書き込むことなく、ローカルのオンラインREDOログ・ ファイルに書込みを行います。LGWRがオンライン・ログへの書込みを完了すると、 LSNnプロセスはオンラインREDOログを読み取り、スタンバイ・データベースに REDOを転送します。この方法では、LGWRプロセスの書込みはLNSnのネットワー ク書込みとは完全に切り離されています。LGWRを使用した非同期REDO転送は、 もはや、ASYNCバッファ・サイズによって制約されることはありません。オンラ インREDOログ・ファイルがいっぱいになると、ログの切り替えが発生し、従来ど おり、アーカイバ・プロセスがローカルでログ・ファイルをアーカイブします。 データ保護の拡張:Oracle Database 10g Release 1 では、上述のようにバッファが FULLになる場合を除いて、潜在的なデータ損失はASYNCバッファ・サイズに制約 されていました。バッファがFULLになると、LNSは現在のREDOストリームのス タンバイ・データベースへの転送を中止し、ARCHプロセスが実行されます。この 場合、潜在的なデータ損失の危険性は、現在のオンライン・ログのサイズ、また はData Guardがスタンバイ・データベースと再同期してLNSが転送を再開するまで に、遅延していたログ・ファイルの数によって決定されます。
Oracle Database 10g Release 2 で使用されている新しいASYNCモデルでは、潜在的な データ損失は、LNSnプロセスが現在のLGWRプロセスからどれだけ遅れているかに よって測定されます。LNSnプロセスが完了する前に、LGWRが新しいオンライ ン・ログ・ファイルに切り替わると、LNSnは現在のログ・ファイルを引き続きリ モートにアーカイブします。LNSnプロセスが最初のログ・ファイルを処理してい る間に、LGWRがさらに新しいオンラインREDOログ・ファイルに切り替わると、 LNSnプロセスがアーカイブを開始していないログ・ファイルは、ARCHプロセスに
よってリモートにアーカイブされます。LNSnは、最初のログ・ファイルのアーカ イブを完了すると、LGWRの現在のログ・ファイルのアーカイブを開始します。
ARCH の拡張
Oracle Database 10g Release 2 では、複数のARCnプロセスを使用して、1 つのアー カイブREDOログにネットワーク経由でREDOを送信する機能が導入されました。 この機能によって、1 つのアーカイブ・ログをリモートの宛先に転送するために 必要な時間が短縮されます。以前のリリースのOracle Databaseでは、特定のログ・ ファイルから同時にREDOをアーカイブできるのは、1 つのARCnプロセスのみで した。宛先へのアーカイブをパラレルで実行するために使用するネットワーク接続の 最大数は、LOG_ARCHIVE_DEST_n初期化パラメータのMAX_CONNECTIONS属性を 使用して制御されます。LOG_ARCHIVE_MAX_PROCESSES初期化パラメータは、 最高で 30 まで設定できます(以前の最大値は 10 でした)。 REDO 転送サービス、LGWR、ARCn、LNSn のバックグラウンド・プロセス、関 連する初期化パラメータにおけるそれぞれの詳細は、『Oracle Data Guard 概要お よび管理』[3]を参照してください。
ネットワーク送信サイズの拡張
Oracle Database 10g Release 2 より以前のリリースでは、ログ転送サービスは、 REDO 情報を 1MB に分割してネットワークに送信していました。
Oracle Database 10g Release 2 では、ネットワーク送信サイズは 1MB から 10MB に 増加されました。このサイズが大きいと、所定量の REDO 転送ごとに RFS のネッ トワークの確認を待つ時間が全体で短縮されるため、ネットワークのアイドル時 間が最小限に抑えられます。
付録 B – REDO 転送のパフォーマンス・テスト
オラクルでは、LGWR ASYNC REDO 転送サービスと最大パフォーマンス・モー ドを使用した、代表的な Data Guard 構成についていくつかの MAA パフォーマン ス・テストを実施しました。このテストでは、REDO 転送とネットワーク・チュー ニングのベスト・プラクティスを適用することで、どの程度、本番データベース のオーバーヘッドを抑え、潜在的なデータ損失を軽減できるかを測定しました。 次のパフォーマンス・プロファイルについて考慮してください。 • 構成 1:1MB/秒をわずかに下回る平均速度でREDOデータを生成するアプ リケーション。この速度では、500MBのオンライン・ログが 8 分ごとに 切り替えられます。これは、実際に使用されている大部分のアプリケー ションを代表するデータ量です。スタンバイ・データベースは、RTTが 25 ミリ秒である広域ネットワーク(WAN)内に配置されています。 影響:フェイルオーバーが突然発生した場合、本番データベース・パ フォーマンスへの影響は 5%未満、潜在的なデータ損失は約 5 秒間分。 • 構成 2:2MB/秒の平均速度でREDOデータを生成するアプリケーション。 この速度では、500MBのオンライン・ログ・ファイルが 4 分ごとに切り 替えられます。スタンバイ・データベースは、RTTが 25 ミリ秒であるWAN 内に配置されています。 影響:フェイルオーバーが突然発生した場合、本番データベース・パ フォーマンスへの影響は 5%未満、潜在的なデータ損失は約 7 秒間分。 • 構成 3:20MB/秒の非常に高い平均速度でREDOデータを生成するアプリ ケーション。この速度では、500MBのオンライン・ログ・ファイルが 25 秒ごとに切り替えられます。スタンバイ・データベースは、RTTが 6 ミリ 秒であるWAN内に配置されています。 影響:フェイルオーバーが突然発生した場合、本番データベースへの影 響は 10%未満、潜在的なデータ損失は 40 秒間分。
ネットワーク送信サイズ - ネットワーク利用率の向上
図 1 では、1GB のアーカイブ REDO ログ・ファイルをさまざまなネットワーク待 機時間で送信した場合に、ネットワーク送信サイズを 1MB から 10MB に増やすこ とで、経過時間が短縮されることを示しています。ネットワークの待機時間 1GB のロ グ ・フ ァ イルの 送信 に かか る 時間( 秒) ネットワーク送信サイズ 10gR2 vs.以前のバージョン 10gR2 以前のバージョン 10gR2 以前のバージョン 図1:ネットワーク送信サイズがネットワークのアイドル時間に与える効果
ARCH 転送 - リモート・アーカイブの迅速化
図 2 では、MAX_CONNECTIONS 属性の値を 5 まで増やすことで、1GB のログ・ファ イルの送信にかかる時間が 55%短縮されることが示されています。 MAX_CONNECTIONS の値 1G B の ログ・フ ァイル の送信に かか る時間( 秒 ) パラレル・アーカイブ 時間 図2:複数のARCnネットワーク接続によるパラレル・アーカイブLGWR ASYNC - 本番データベースのオーバーヘッドの軽減
Oracle Database 10g Release 2 では、REDO 速度が上がり、ネットワークの待機時間 が増加しても、本番データベースへ与える影響は大きくならず、比較的一定のま ま維持されます。たとえば、REDO 速度が 2MB/秒以内である場合、RTT が 0 ミリ 秒から 100 ミリ秒までのさまざまな待機時間のネットワークにおいて、本番デー タベースへの影響(ベースラインに対する REDO バイト数/秒の変化で測定)は
5%未満に抑えられます。
ワークロードが大幅に増加した場合も、同じ関係が当てはまります。図 3 では、 本番データベースの REDO 速度が約 20MB/秒に上がった場合、Oracle Database 10g Release 1 と Release 2 で使用される ASYNC モデル間の差異が著しく大きくなるこ とが示されています。 注:テストでは、1GBのネットワークを使用して、さまざまな待機時間のシミュ レーションが行われました。 ネットワークの待機時間 影響の 割合 プライマリ・データベースへの影響 10gR2 vs. 10gR1 20MB/秒の REDO 図3:20MB/秒のREDO速度における本番データベースへのパフォーマンスの影響
LGWR ASYNC - データ保護の強化
新しい LGWR ASYNC モデルを使用した場合の、Oracle Data Guard 10g Release 2 の拡張による潜在的なデータ損失において、危険性への影響を測定するため、 MAA のテストを実施しました。最初のテスト・シナリオでは、正しくチューニン グされたギガビット・ネットワーク上で、ワークロードを 2MB/秒に維持したまま、 1GB のオンライン REDO ログ・ファイルを使用して、さまざまなネットワークの 待機時間のシミュレーションが行われました。図 4 に示されているとおり、ネッ トワークの待機時間が最大で 50 ミリ秒までの場合、REDO 転送は、潜在的なデー タ損失の危険性を最小限に抑えたままで、本番データベースの REDO 生成速度を 維持できることが確認されました。