Phylogenetic Estimation Using Variants
of Chapter Titles:
The Case of the Xianyu jing in Tibetan
I
SHIDAKatsuyo
1. Introduction
The transmission of the Tibetan Kanjur has been studied for each indi-vidual sutra. In many cases variants of texts are used. The two kinds of variants are given as follows:<D1>: variants of the text body, <D2>: variants of the chapter titles.
<D1> is commonly used. <D2> is often explained by stemma. Conversely, the phylogenet-ic estimation using <D2> itself has not yet been performed. It is the purpose of this paper to verify whether a phylogenetic tree can be made from only <D2>. When using variants, there are two methods in terms of weighting to them:
<M1>: weighting specific variants, <M2>: giving variants equal weight.
<M1> is a commonly used method, but external information on history or language is neces-sary for weighting, and there is a problem that subjectivity is necessarily included in the se-lection of external information. <M2> uses information only of the variants and does not re-quire other information, so it is possible to conduct a replication study if the variants and the statistical method are specified, and if a phylogenetic tree can be estimated mechanically.
To sum up, there are four combinations of <D1> or <D2> as data and <M1> or <M2> as method. In the previous studies, the combination of <D1> and <M1> is commonly used. I have already reported the results of the phylogenetic estimation by <M2> based on <D1> (Ishida 2011, Ishida 2013). In order to verify whether a phylogenetic tree can be estimated only on the basis of chapter titles, I have adopted <D2> and <M2> in this paper.
2. Texts Utilized
The fourteen texts of the Tibetan Xianyu jing (Sutra of the Wise andis located.
Tshal pa group Them spangs ma group Independent group C: Cone L: London manuscript F: Phu brag manuscript D: Derge S: Tog Palace manuscript Mixed group
J: Lithang T: Tokyo manuscript H: Lhasa U: Urga Z: Shey Palace manuscript N: Narthan
Y: Yongle Other group
K: Beijing Sch: Schmidt 1845
3. Data and Methods
3.1. Chapter Titles
The chapter title is at the beginning of the chapter and at the end of the chapter. The chap-ter title at the end was adopted most often. In some cases I have also referred to the chapchap-ter title at the beginning. The chapter title includes a chapter number. I omitted the description of the chapter number.
Example) dpe sna tshogs bstan pa i le u ste dang po o /
I omitted ste dang po o and adopted only dpe sna tshogs bstan pa i le u.
There are 51 chapters (LF: 52). F Chapter 7 corresponds to L Chapter 52. F Chapter 7 is regarded as Chapter 52, and after F Chapter 8, each chapter was shifted by a single chapter, one by one. I did not use Chapter 52 for phylogenetic estimation.
3.2. A Statistical Tool
As the process of transferring manuscripts is similar to that of living things, phylogenetic estimation methods of biological phylogeny can be used in philology (Minaka 1997). As a quantitative method, I used SplitsTree4 which is a statistical tool of biological phylogeny. There are already examples of its application in Canterbury Tales and The Tale of Genji. I also used it for phylogenetic estimation (Ishida 2011, Ishida 2013).
4. Results
4.1. Comparison of Chapter Titles
Comparing the chapter titles for each chapter, I gathered variants. The chapters with no variants are as follows. There are 20 chapters, about 40% of the total chapters.
1, 5, 7, 8, 9, 10, 11, 13, 16, 17, 20, 21, 27, 28, 29, 31, 33, 35, 43, 48
Common examples of variants are as follows:
·Proper noun (e.g., gang gā da ra / gam ga da ra ) ·Synonym (e.g., dbyug pa / dbyig pa )
·Function word (e.g., presence or absence of genitive particle) ·Title notation (e.g., presence or absence of zhes bya ba )
The following are some examples of the chapter titles.
Chapter 1
Title①: dpe sna tshogs bstan pa i le u / (all texts) Variants: 0
Chapter 18
Title①: dbul mos ras phul ba i le u / (DJCUHSch) Title②: dbul mos ras byin pa i le u / (YKNTLSZF) Variants: 1 (phul / byin)
Chapter 39
Title①: khyim bdag dbyug pa can zhes bya ba i le u / (DJNCUHSch) Title②: khyim bdag dbyig pa can zhes bya ba i le u / (YK) Title③: khyim bdag dbyig pa can gyi le u / (TLSZ) Title④: bram ze dbyig pa can zhes bya ba i le u / (F)
Variants: 3 (khyim bdag / bram ze, dbyug pa / dbyig pa, zhes bya ba i le u / gyi le u) Chapter 44
Title①: sangs rgyas thog ma byams pa i thugs bskyed pa i le u / (DJCUHFSch) Title②: sangs rgyas thog ma byams pa i sems bskyed pa i le u / (YKNTLSZ) Variants: 1 (thugs / sems)
4.2. Results of Phylogenetic Estimation
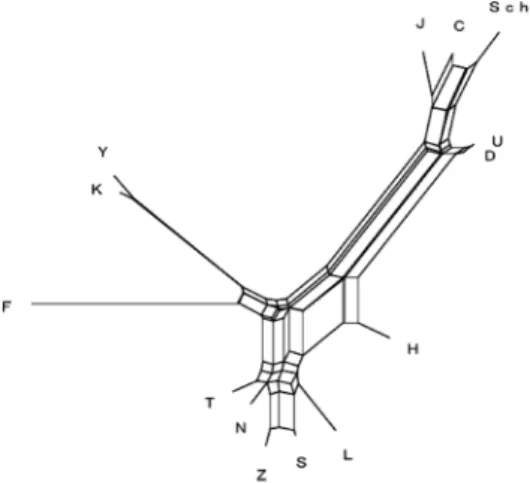
Fig. 1 shows the result of phylogenetic estimation applying SplitsTree4 to the 78 variants of the chapters. As there is contamination in the process of transferring various texts, the estimation result is represented by a network (unrooted tree) rather than a tree (rooted
tree). For convenience, a network is called a tree in this paper. In Fig. 1, it can be seen that they are roughly divided into the following five groups:
(JCUDSch): the Tshal pa group (TNZSL: the Them spangs ma group (YK): close to the Them spangs ma group (F): close to the Them spangs ma group (H): close to the Them spangs ma group
5. Discussion
For comparison, the result of the estimation by <D1> is shown in Fig. 2. The number of variants is 348, which is much more than in the case of Fig. 1 (78 variants). The two sets of texts utilized in the two phylogenetic trees are slightly different. Fig. 1 shows almost the same result as Fig. 2. Both are similar to the transmission of the Kanjur shown by the previous studies (Ishida 2011). In previous research, (YK) is often classified as the Tshal pa group, but in Fig. 1 (YK) is close to the Them spangs ma group. A more de-tailed examination of (YK) using <M1> calls for further study.In order to obtain a detailed relationship like a parent-child relationship, the approach of <M1> may be necessary, but <M2> is enough to construct a rough phylogenetic tree.
There is a possibility that the phylogenetic estimation by <D2> may differ from the phylo-genetic estimation by <D1>. This is not a problem. Because <D2> can be collected easily, it
Fig. 1 A phylogenetic tree of SWF
can be a preliminary study before starting full-scale work, such as textual criticism. Even if a phylogenetic tree cannot be obtained because of insufficient information, <D2> becomes useful data in subsequent work. For example, it becomes data that estimate a more optimal dendrogram together with <D1>. For this reason, collecting <D2> is not wasted work.
6. Conclusion
Phylogenetic estimation can be performed by <D2> and <M2> in SWF. <D2> has less information than <D1>, but the phylogenetic tree made from <D2> is almost similar to the one made from <D1>. I point out two reasons for this. First, there is sufficient information for phylogenetic estimation in the <D2> of SWF. Second, <M2>, especially SplitsTree4 has the ability to properly extract information and estimate a phylogenetic tree. BibliographyIshida Katsuyo 石田勝世. 2011. Tōkeikaiseki no seibutsugakuteki shuhō niyoru tekisuto no keitōju sakusei: zōyaku Hannyashinkyō wo chūshin ni 統計解析の生物学的手法によるテキストの系統樹 作成:蔵訳『般若心経』を中心に. IBK 60 (1): 414–411.
̶. 2013. Seibutsu keitōgaku no tōkei shuhō wo riyōshita zōyaku Kengukyō no keitō suitei 生物
系統学の統計手法を利用した蔵訳『賢愚経』の系統推定. IBK 62 (1): 471–467.
Minaka Nobuhiro 三中信宏. 1997. Seibutsukeitougaku 生物系統学. Tokyo: University of Tokyo Press. Schmidt, Isaak Jakob 1843–1845. Dzangs blun, oder der Weise und der Thor. 2 Vols. St. Petersburg: Gräff.
Key Words phylogenetic trees, statistical analysis, Kanjur, Xianyu jing, variants
(Research Student, Kyushu University)
Fig. 2 A phylogenetic tree of SWF Chapter 2