【経済系機能編】単変量時系列分析
Stataには時系列データを分析するためのコマンドが一式用意されています。ts系コマンドと呼ばれるもの がそれですが、本解説書では単変量時系列分析に関係するものを中心に、その機能と用法を記述しました。 • 単変量時系列分析の概要 • 時系列データの初期設定 • 自己回帰移動平均(ARMA)モデル • コレログラム • ARCH/GARCH系モデル • 単位根検定目 次
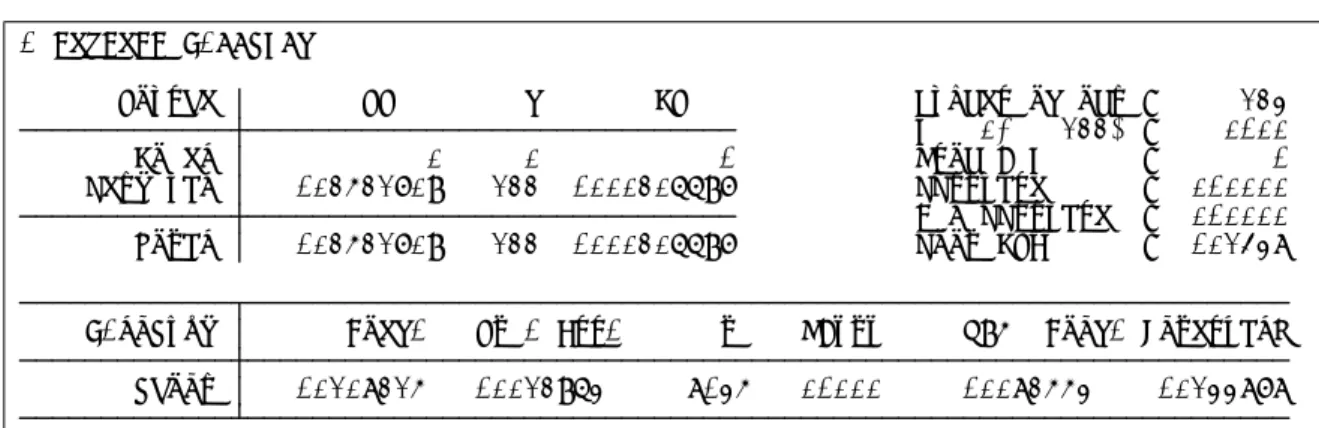
コマンド whitepaperタイトル ページ mwp番号 − 単変量時系列分析 3 mwp-083 arch ARCH系モデル 11 mwp-051 arch postestimation機能 27 mwp-056 arima ARMA(自己回帰移動平均)モデル 35 mwp-003 arima postestimation機能 49 mwp-055 corrgram/ac/pac コレログラムの作成 56 mwp-009 dfgls 単位根検定(DF-GLS検定) 62 mwp-053 dfuller 単位根検定(ADF検定) 67 mwp-052 pperron 単位根検定(P-P検定) 73 mwp-054 tsset 時系列データの初期設定 77 mwp-002 − 日付/時間情報の入力 83 mwp-001 本解説書はStataCorp社の許諾のもとに作成したものです。 c ⃝ 2011 Math工房 一部 ⃝ 2011 StataCorp LPcMath工房 web: www.math-koubou.jp
mwp-083
単変量時系列分析
Stataには単変量時系列データを分析するための機能としてarima, arch等のコマンドが用意されていま
す。それぞれの機能/用法については別にwhitepaperを用意していますが(mwp-003 , mwp-051 , 等)、前 提となる基本的事項については別途整理しておいた方が良いと考え、本whitepaperを作成しました。なお、 VAR/VEC等の多変量時系列分析機能に関する同様のイントロについてはmwp-084 をご参照ください。 1. 定常性 2. 時系列モデル 3. 定常性と反転可能性の条件 4. コレログラム 5. 非定常過程と単位根 6. ARCH系モデル 7. tsset
1.
定常性
(1)定常性の定義 具体的な時系列データy1, y2, . . . , yT は基盤となる確率過程(stochastic process) {yt}∞−∞= {. . . , y−1, y0, y1, . . .} (1) の実現値の集合ととらえることができるわけですが、その際、その過程が定常的であるかどうかは重要なポイ ントとなります。確率過程{yt}∞−∞に対して次の3つの条件が成り立つとき、{yt}は定常的(stationary)で あると言います(より厳密性を期する意味で弱定常的(weakly stationary) または共分散定常的(covariance stationary)という表現を用いることもあります)。(i) 平均E(yt)がすべてのtに対して一定である。 (ii) 分散V (yt)がすべてのtに対して一定である。
(iii) 自己共分散Cov(yt, yt−s)がtには依存せず、時点の差であるs(s > 0)のみに依存する。
c
(2)ホワイトノイズ 定常的確率過程の中で最も基本的なものがホワイトノイズ (white noise) です。{ut}をホワイトノイズとす るとそれは次の条件を満足します。 E(ut) = 0 (2a) V (ut) = σ2 (2b) Cov(ut, us) = 0, t ̸= s (2c) すなわちホワイトノイズは、期待値が0、分散が一定(σ2)、自己相関を持たない確率過程であると言えます。
2.
時系列モデル
計量経済等の分野で良く用いられる時系列モデルには次のようなものがあります。 (1) AR(p)モデル 次数pの自己回帰過程(autoregressive process)で、被説明変数の過去の値を用いて次のように表現さ れます*1。 yt= ϕ1yt−1+ ϕ2yt−2+ · · · + ϕpyt−p+ ϵt, ϵt∼ WN(whitenoise) (3) (2) MA(q)モデル次数qの移動平均過程 (moving average process)で、ホワイトノイズの線形結合として次のように表 現されます。
yt= ϵt+ θ1ϵt−1+ · · · + θqϵt−q, ϵt∼ WN (4) (3) ARMA(p, q)モデル
次数(p, q)の自己回帰移動平均過程 (autoregressive-moving average process) で、AR(p)モデルと
MA(q)モデルの組合せとして次のように表現されます。
yt= ϕ1yt−1+ ϕ2yt−2+ · · · + ϕpyt−p+ ϵt+ θ1ϵt−1+ · · · + θqϵt−q, ϵt∼ WN (5)
今、ラグ演算子をL、その多項式を
ϕ(L) = (1 − ϕ1L − ϕ2L2− · · · − ϕpLp) (6a) θ(L) = (1 + θ1L + θ2L2+ · · · + φqLq) (6b)
と定義すると、AR(p), MA(q), ARMA(p, q)各モデルはそれぞれ次のように表現することもできます。
AR(p)モデル: ϕ(L)yt= ϵt (7a)
MA(q)モデル: yt= θ(L)ϵt (7b)
ARMA(p, q)モデル: ϕ(L)yt= θ(L)ϵt (7c)
*1定数項は省略してあります。また[TS] arima p54 に記載されている数式では ϕ の代りに ρ というギリシャ文字が使用されて います。
3.
定常性と反転可能性の条件
評価版では割愛しています。4.
コレログラム
評価版では割愛しています。5.
非定常過程と単位根
評価版では割愛しています。6. ARCH
系モデル
評価版では割愛しています。7. tsset
評価版では割愛しています。 ¥mwp-051
arch - ARCH系モデル
archコマンドはARCH, GARCH等、種々のARCH系モデルに対応した推定コマンドで、ボラティリティ
(volatility)をモデル化する機能を提供します。 1. ARCH系モデル 2. ARCH/GARCH 3. ARCH/GARCH – ARMA過程を伴うモデル 4. EGARCH –非対称効果 5. 非対称PGARCH 6. 誤差分布
1. ARCH
系モデル
ARCH (autoregressive conditional heteroskedasticity)系モデルに関する一般式の基本形は[TS] arch p12 (1)式に記載されているようなもので、ytに関する条件付平均式(conditional mean equation) の他に、σ2t に関する条件付分散式(conditional variance equation) を含む点に特徴があります。この条件付分散式に含
まれるA項、B 項の規定の仕方によってARCH, GARCH等、種々のモデルが構成される他、[TS] arch
p12-13 (2)式、(3)式のような拡張型のモデル式を想定することにより、さらに多様なモデルが構成されま
す。archコマンドはこれらすべてのモデル(約20種)に対応した包括的なコマンドです。
2. ARCH/GARCH
ここではExampleデータセットwpi1.dtaを用いてARCH/GARCHモデルのフィットを行います。 . use http://www.stata-press.com/data/r11/wpi1*1
このデータセット中には米国の卸売物価指数(wholesale price index)に関するデータが1960q1から1990q4
にわたり四半期ごとに記録されています。なお、変数ln wpiの表す値はln(wpi)を意味します。
c
⃝ Copyright Math 工房; 一部 c⃝ Copyright StataCorp LP (used with permission)
*1メニュー操作:File ◃ Example Datasets ◃ Stata 11 manual datasets と操作、Time-Series Reference Manual [TS] の arch の項よりダウンロードする。
. list if n <= 4 | n >= ( N - 3), separator(4)*2 124. 116.2 1990q4 4.755313 123. 112.8 1990q3 4.725616 122. 110.8 1990q2 4.707727 121. 111 1990q1 4.70953 4. 30.7 1960q4 3.424263 3. 30.7 1960q3 3.424263 2. 30.8 1960q2 3.427515 1. 30.7 1960q1 3.424263 wpi t ln_wpi ここでD.ln wpi(ln wpiの1階差分)についてプロットしてみましょう。 . twoway (line D.ln wpi t), yline(0)*3
このプロットより価格変動(ボラティリティ)の大きい時期と比較的平穏な時期が混在していることが見て取 れます。
ところで時系列データに対し線形モデルをフィットさせた場合、そのpostestimation機能としてestat
archlmコマンドが利用できるようになります([R] regress postestimation time series参照)。このコ マンドはEngleのLM検定(Lagrange Multiplier test)機能を実行するもので、残差中にARCHの効果が存
在するかどうかをチェックします。そこでまずD.ln wpiのデータに対し定数項のみからなるモデルをフィッ
トさせます。
*2メニュー操作:Data ◃ Describe data ◃ List data
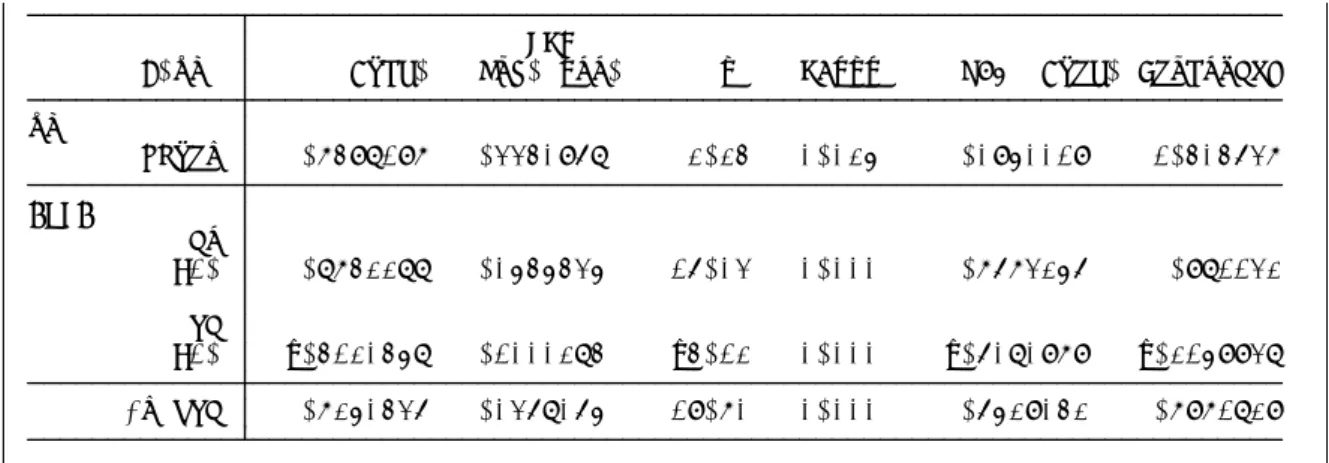
. regress D.ln wpi*4
_cons .0108215 .0012963 8.35 0.000 .0082553 .0133878 D.ln_wpi Coef. Std. Err. t P>|t| [95% Conf. Interval] Total .02521709 122 .000206697 Root MSE = .01438 Adj R-squared = 0.0000 Residual .02521709 122 .000206697 R-squared = 0.0000 Model 0 0 . Prob > F = . F( 0, 122) = 0.00 Source SS df MS Number of obs = 123 . regress D.ln_wpi
この状態でestatコマンドが有効となるのでestat archlmを実行します。
• Statistics ◃ Postestimation ◃ Reports and statisticsと操作
• estatダイアログ: Reports and statistics: Test for ARCH effects in the residuals (archlm) Specify a list of lag orders to be tested: 1
図1 estat archlmダイアログ
H0: no ARCH effects vs. H1: ARCH(p) disturbance
1 8.366 1 0.0038 lags(p) chi2 df Prob > chi2 LM test for autoregressive conditional heteroskedasticity (ARCH)
. estat archlm, lags(1)
結果からするとp値が0.0038であるので、ARCH効果なしとする帰無仮説は棄却されることになります。
ARCH効果の存在が確認できたところでGARCH(1, 1)モデルのフィットを行ってみます。D.ln wpiをyt と書いた場合、ARCH(1)モデルは { yt= xtβ + ϵt σ2 t = γ0+ γ1ϵ2t−1 (M1) のように記述されるのに対し、GARCH(1, 1)モデルは { yt= xtβ + ϵt σ2 t = γ0+ γ1ϵ2t−1+ δ1σ2t−1 (M2) のように表現されます。このためGARCH(1, 1)モデルの方がより一般性の高いモデルであると言えます。な
お、ARCHモデルとGARCHモデルの一般式については[TS] arch p24-25 をご参照ください。
• Statistics ◃ Time series ◃ ARCH/GARCH ◃ ARCH and GARCH modelsと操作
• Modelタブ: Dependent variable: D.ln wpi
Specify maximum lags: ARCH maximum lag: 1 GARCH maximum lag: 1
_cons .0000269 .0000122 2.20 0.028 2.97e-06 .0000508 L1. .4544606 .1866605 2.43 0.015 .0886126 .8203085 garch L1. .4364123 .2437428 1.79 0.073 -.0413147 .9141394 arch ARCH _cons .0061167 .0010616 5.76 0.000 .0040361 .0081974 ln_wpi
D.ln_wpi Coef. Std. Err. z P>|z| [95% Conf. Interval] OPG
Log likelihood = 373.234 Prob > chi2 = .
Distribution: Gaussian Wald chi2(.) = .
Sample: 1960q2 - 1990q4 Number of obs = 123
ARCH family regression
Iteration 10: log likelihood = 373.23397 Iteration 9: log likelihood = 373.23394 Iteration 8: log likelihood = 373.23277 Iteration 7: log likelihood = 373.18939 Iteration 6: log likelihood = 373.11099 Iteration 5: log likelihood = 372.41702 (switching optimization to BFGS)
Iteration 4: log likelihood = 370.42566 Iteration 3: log likelihood = 369.652 Iteration 2: log likelihood = 366.89266 Iteration 1: log likelihood = 365.64589 Iteration 0: log likelihood = 355.2346 (setting optimization to BHHH)
. arch D.ln_wpi, arch(1/1) garch(1/1)
archコマンドの出力より、(M2)式中のパラメータは次のように推定されたことになります。
平均式:β0= 0.0061
分散式:γ0= 0.000 γ1= 0.436 δ1= 0.454
3. ARCH/GARCH – ARMA
過程を伴うモデル
評価版では割愛しています。4. EGARCH –
非対称効果
評価版では割愛しています。5.
非対称
PGARCH
評価版では割愛しています。6.
誤差分布
評価版では割愛しています。 ¥mwp-003
arima - 機能概要と用例
arimaは擾乱が自己回帰移動平均(ARMA: autoregressive moving-average) 過程として表現される単変量モ
デルのフィットを行います。arimaは従属変数の自己回帰項のみによって記述されたARMAモデルのみなら ず、独立変数を含む形のARMAXモデルにも対応しています。 1. ARMA過程 2. arimaの用例 2.1 ARIMA(1,1,1)モデル 2.2加法的季節変動モデル 2.3乗法的季節変動モデル 2.4 ARMAXモデル 補足1
1. ARMA
過程
ARMA過程に関するモデル式については[TS] arima のセクション“Introduction” p54 に記述されてい
ます。最初にARMA(1, 1)過程に関するモデル式が記載されていますが、その本質は構造方程式中の擾乱項 µtの中に自己相関項ρµt−1と移動平均項θϵt−1を含む点です。すなわち周期tにおける擾乱は単なる白色ノ イズϵt以外に1期前のµt, ϵtの影響を引きずった構造となっています。その影響の度合いはパラメータρと θによって規定されるわけです。 自己相関による影響をp期まで、移動平均による影響をq期までの範囲に拡張したモデルがARMA(p, q)過 程であり、そのモデル式がマニュアル上に示されているわけですが、それはARMA(p, q)を µt= yt− xtβ (M1) µt= ρ1µt−1+ · · · + ρpµt−p+ θ1ϵt−1+ · · · + θqϵt−q+ ϵt (M2) と表現したとき、(M2)式に(M1)式を順次代入して行くことにより誘導できます。それはラグ演算子Lを用 いることによって、マニュアルに記載されているようなよりコンパクトな一般式表記に改めることができるわ けです。 c
ARMA過程と言った場合、従属変数のみからなる、すなわち独立変数xtを含まないモデルを対象にすること が多いわけですが、ここではARMA(1, 1)過程とARMA(2, 2)過程について具体的なモデル式を誘導してお きます。 (1) ARMA(1, 1)モデル ARMA(p, q)過程の一般式より (1 − ρ1L)(yt− β0) = (1 + θ1L)ϵt ラグ演算子を適用すると yt− β0− ρ1(yt−1− β0) = ϵt+ θ1ϵt−1 従って yt− β0= ρ1(yt−1− β0) + θ1ϵt−1+ ϵt (M3) というのがARMA(1, 1)過程のモデル式となります。 (2) ARMA(2, 2)モデル 同様にARMA(2, 2)過程のモデル式は yt− β0= ρ1(yt−1− β0) + ρ2(yt−2− β0) + θ1ϵt−1+ θ2ϵt−2+ ϵt (M4) となります。 用例の中にはARIMA(p, d, q)過程という表現が出てきます(Iはintegratedの略)が、それはd 階差分の時系列がARMA(p, q)過程に従うことを意味します。
2. arima
の用例
2.1 ARIMA(1,1,1)
モデル
ここでは米国の卸売物価指数(wholesale price index)に関するExampleデータセットwpi1.dtaを使用し ます。
. use http://www.stata-press.com/data/r11/wpi1*1
この中には1960q1から1990q4に至る期間中のデータが四半期ごとに記録されています。
. list wpi t if n <= 4 | n >= ( N - 3), separator(4)*2
*1メニュー操作:File ◃ Example Datasets ◃ Stata 11 manual datasets と操作、Time-Series Reference Manual [TS] の arima の項よりダウンロードする。
124. 116.2 1990q4 123. 112.8 1990q3 122. 110.8 1990q2 121. 111 1990q1 4. 30.7 1960q4 3. 30.7 1960q3 2. 30.8 1960q2 1. 30.7 1960q1 wpi t
次に示すのはwpiとD.wpi(wpiの1階差分)についてのプロットです。 . twoway (line wpi t), title(wpi)*3
. twoway (line D.wpi t), yline(0) title(D.wpi)
このグラフから明らかなように原系列wpiは定常とは言えないので、ここでは階差系列D.wpiを解析対象と
します。
ARMAモデルをarimaに対し指定する場合、arima(p,d,q)という略式指定を用いる方法とar(), ma()指
定による方法の2種類が選択できます。モデルに含めるべきラグ次数がAR項については1からp、MA項に
ついては1からqと連続している場合には略式指定を用いることができます。これに対し指定すべきラグ次数
が1と4といった形で不連続な場合には、numlistが指定できるar(), ma()インタフェースを用いることに なります。
なお、arima(p,d,q)インタフェースを用いた場合には差分の次数dを明示することができます。その場合、
例えばarima(1,1,1)という形でモデルを規定したとするなら、従属変数として指定するのはD.wpiではな
くwpiとなる点に注意する必要があります。
最初にarima(p,d,q)インタフェースを用いてarimaの実行を行ってみます。この場合、従属変数としては
wpiを指定します。
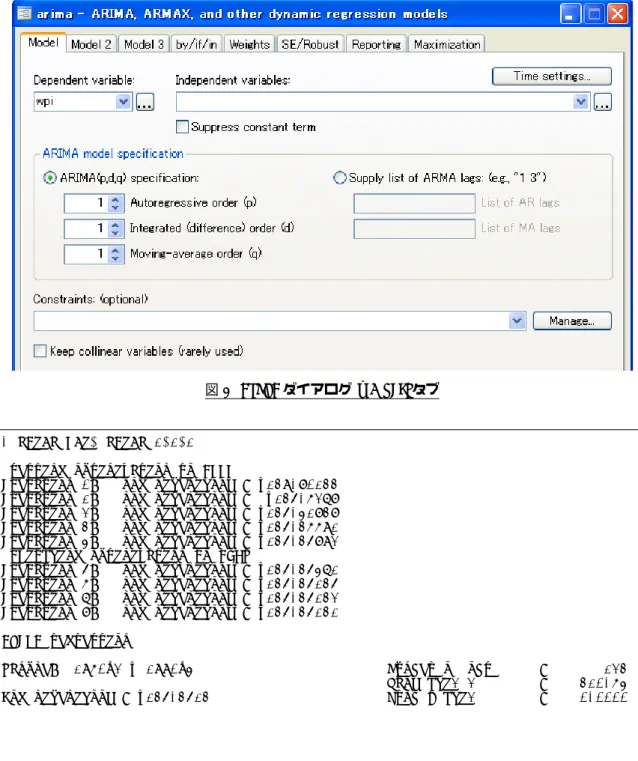
• Statistics ◃ Time series ◃ ARIMA and ARMAX modelsと操作
• Modelタブ: Dependent variable: wpi
ARIMA(p,d,q) specification: p = d = q = 1
図1 arimaダイアログ– Modelタブ
Log likelihood = -135.3513 Prob > chi2 = 0.0000
Wald chi2(2) = 310.64
Sample: 1960q2 - 1990q4 Number of obs = 123
ARIMA regression
Iteration 8: log likelihood = -135.35131 Iteration 7: log likelihood = -135.35132 Iteration 6: log likelihood = -135.35135 Iteration 5: log likelihood = -135.35471 (switching optimization to BFGS)
Iteration 4: log likelihood = -135.35892 Iteration 3: log likelihood = -135.36691 Iteration 2: log likelihood = -135.41838 Iteration 1: log likelihood = -135.6278 Iteration 0: log likelihood = -139.80133 (setting optimization to BHHH)
/sigma .7250436 .0368065 19.70 0.000 .6529042 .7971829 L1. -.4120458 .1000284 -4.12 0.000 -.6080979 -.2159938 ma L1. .8742288 .0545435 16.03 0.000 .7673256 .981132 ar ARMA _cons .7498197 .3340968 2.24 0.025 .0950019 1.404637 wpi
D.wpi Coef. Std. Err. z P>|z| [95% Conf. Interval] OPG
結果が意味するところは(M3)式より次のようになります。
∆wpit− 0.750 = 0.874 · (∆wpit−1− 0.750) − 0.412 · ϵt−1+ ϵt
なおsigmaとして0.725とレポートされていますがこれはホワイトノイズ擾乱ϵの標準偏差推定値を意味し
ます。
今度はar(), ma()インタフェースを用いてarimaの実行を行ってみます。この場合、従属変数として指定す
るのはD.wpiとなります。
• Statistics ◃ Time series ◃ ARIMA and ARMAX modelsと操作
• Modelタブ: Dependent variable: D.wpi
Supply list of ARMA lags: List of AR lags: 1 List of MA lags: 1
この場合、生成されるコマンドは . arima D.wpi, ar(1) ma(1)
であり先の場合とは異なったものとなりますが、出力結果は同一のため省略します。
なお、ここでフィットされたARIMA(1, 1, 1)モデルに基づく予測については[TS] arima postestimation (mwp-055 )をご参照ください。