2004 年度卒業論文
MPI プログラムの簡易実行による
実行時間予測手法における通信予測の効率化
提出日: 2005 年 2 月 2 日 指導:山名早人助教授 早稲田大学理工学部情報学科
学籍番号: 1G01P053-1
杉田 秀
概 要
近年PCクラスタやグリッドの普及により、並列プログラムに対しての注目度が 増してきている。しかし、並列プログラムでは、使用するProcessing Unit(PU)数 を多くすれば単純に実行性能が上がるというわけではない。また、計算機やネッ トワークの構成を変えれば、実行性能は変化するのが一般的である。つまり、最 高の実行性能を得るためには、最適な計算機構成を選択することが重要となる。
最適な計算機構成を選択するために、並列プログラムの実行時間を予測する手 法が提案されている。従来の方法としては、シミュレータを用いる方法や、ソー スプログラムを静的に解析する方法が提案されている。前者は予測にかかる時間 が実際の実行時間よりも長くなってしまう問題が、後者は前者に比較して予測精 度が悪いという問題がある。
そこで、上記で示したような問題に対して、並列プログラムの簡易実行による 実行時間予測手法が提案されている。簡易実行による実行時間予測手法では、プ ログラムソースレベルで計算や通信部分をブロック化し、ブロック部分の実行時 間の計測を簡略化することにより、短時間でプログラムの実行時間を予測するこ とが可能である。計測の簡略化には、計測時に必要のないブロックをコメントア ウトし、プログラムのループ部分に対してループ回数を削減する。しかし、ルー プ回数をどのくらい削減するかを静的に決めてしまっているので、予測対象プロ グラムによっては十分な精度を得ることができない。
本稿では、並列プログラムの簡易実行による実行時間予測手法における、計算・
通信予測に必要なループ回数の考察と、通信予測の効率化手法について述べる。評 価方法は、2〜128台のPUに関して姫野ベンチマークを用いて行った。その結果、
従来の簡易実行による実行時間予測手法に比べて、16〜64PU数において1/100〜
1/10程度にループ回数を減らすことができ、予測にかかる時間を1/20に減らすこ とができた。
目 次
第1章 はじめに 1
第2章 従来研究 3
2.1 シミュレータを用いた予測手法 . . . . 3
2.1.1 久保田等の手法[1] . . . . 3
2.1.2 Dickens等の手法[4]. . . . 4
2.1.3 Prakash等の手法[5] . . . . 5
2.2 ソースプログラムの静的解析による予測手法 . . . . 6
2.2.1 Yarrow等の手法[6] . . . . 6
2.2.2 Rothberg等の手法[7] . . . . 6
2.3 簡易実行による予測手法 . . . . 7
2.3.1 岩渕等の手法[8]. . . . 7
2.3.2 水谷等の手法[9]. . . . 7
2.4 プログラムのモデル化による予測手法 . . . . 9
2.4.1 Marin等の手法[10] . . . . 9
2.5 従来手法のまとめ . . . . 10
第3章 簡易実行による実行時間予測手法[8]と提案手法 11 3.1 プログラムのブロック分割方法 . . . . 11
3.2 基礎パラメータの取得 . . . . 13
3.2.1 計算ブロックの基礎パラメータの取得 . . . . 13
3.2.2 通信ブロックの基礎パラメータの取得 . . . . 13
3.2.3 各ブロック実行回数の取得 . . . . 14
3.3 各ブロックの実行時間予測手法 . . . . 15
3.3.1 計算ブロック予測 . . . . 15
3.3.2 通信ブロック予測 . . . . 15
3.3.3 全実行時間予測 . . . . 15
3.4 提案手法 . . . . 16
3.4.1 基礎パラメータの取得 . . . . 17
3.4.2 通信ブロック予測 . . . . 17
第4章 姫野ベンチマークを用いた提案手法の評価 18
4.1 予測対象プラットフォームと予測対象プログラム . . . . 18
4.1.1 実行環境 . . . . 18
4.1.2 姫野ベンチマーク . . . . 20
4.2 姫野ベンチマークの予測結果 . . . . 21
4.2.1 実行時間予測 . . . . 22
4.2.2 予測誤差 . . . . 26
4.2.3 予測にかかる時間 . . . . 32
4.2.4 岩渕等の手法との比較 . . . . 33
4.3 まとめ . . . . 38
第5章 おわりに 39
第 1 章 はじめに
近年PCクラスタやグリッドの普及により、並列プログラムに対しての注目度が 増してきている。しかし、並列プログラムでは、使用するProcessing Unit(PU)数 を多くすれば単純に実行性能が上がるというわけではない。また、計算機やネッ トワークの構成を変えれば、実行性能は変化するのが一般的である。つまり、最 高の実行性能を得るためには、最適な計算機構成を選択することが重要となる。
最適な計算機構成を選択するために、並列プログラムの実行時間を予測する手 法が提案されている。従来の方法としては、シミュレータを用いてアセンブラコー ドレベルのトレースを行い計算時間の予測を行う手法[1]や、シミュレーションを 行わずソースプログラムを静的に解析して実行時間の予測を行う手法[6][7]が提案 されている。前者は、キャッシュヒット率やネットワークレイテンシ、バンド幅の 変化に対応した挙動の解析が可能である反面、予測にかかる時間に、実際の実行時 間に対し数倍から数十倍の時間を要する。後者は、コンパイラ最適化やキャッシュ 効果、ネットワーク性能を考慮することが困難であり、前者に比較して予測精度 が悪い。
上記で示したような問題に対して、並列プログラムの簡易実行による実行時間 予測手法[8]が提案されている。[8]の手法では、プログラムソースレベルで計算 や通信部分をブロック化し、各ブロック1回分の実行時間(ブロック基礎データ)
及びブロック実行回数を取得することで、プログラム全体の実行時間を予測する。
予測の際は、ブロック部分の実行時間の計測を簡略化することにより、シミュレー タを用いる予測手法よりも、短時間でプログラムの実行時間を予測することが可 能である。計測の簡略化には、計測時に必要のないブロックをコメントアウトし、
プログラムのループ部分に対してループ回数を削減する。しかし、ループ回数を どのくらい削減するかを静的に決めているので、予測対象プログラムによっては 十分な精度を得ることができない可能性がある。
本稿では、MPI[11]を用いた並列プログラムの簡易実行による実行時間予測手法 における、計算・通信予測に必要なループ回数の考察と、通信予測の効率化手法に ついて述べる。並列プログラムでは、ネットワークコンテンションの発生が通信 時間に大きな影響を与えるため、ループ内の通信部分の予測にはある程度ループ を回して、正確な通信ブロック基礎データを取る必要がある。そこで、コンテン ションの影響を受けるデータを、受けないデータと区別して取得することで、通 信に必要な通信回数を削減する手法を提案する。
これより、第2章では従来提案されてきた実行時間予測手法について述べる。つ
づいて第3章では簡易実行による実行時間予測手法[8]、及び提案手法についての 説明をし、第4章で提案手法を姫野ベンチマーク[14]で評価した結果を示し、[8]
の手法との比較を行う。最後に、第5章でまとめを行う。
第 2 章 従来研究
本章では、これまでに提案されてきた、並列プログラムの実行時間予測手法を 紹介する。2.1でシミュレータを用いる予測手法[1][4][5]、2.2でソースプログラム を静的に解析する予測手法[6][7]、2.3で簡易実行による予測手法[8][9]、2.4でプロ グラムのモデル化による予測手法[10]について述べる。そして、最後に2.5で従来 手法のまとめを行う。
2.1 シミュレータを用いた予測手法
本節では、シミュレータを用いて実行時間を予測する手法を述べる。本手法は プログラムを解析し、実行に際しての詳細な情報を得てシミュレーションを行う ことで、精度良く予測をすることができる。
しかし、一般にシミュレーションの精度が高いほど、予測に必要な時間は比例し て大きくなる。また、並列プログラムの予測には、PU毎の挙動予測の他に、PU 間における通信のシミュレーションも行う必要があり、予測に必要な時間はさら に大きくなる。
2.1.1 久保田等の手法 [1]
1998年、久保田等は、計算部分にEXCIT[2]、通信部分にINSPIRE[3]を利用し て、データ並列プログラムの実行時間を予測する手法[1]を提案した。計算部分と は2つの通信関数に挟まれた部分を指し、通信部分とは通信関数部分を指す。ま た、データ並列プログラムは、通信の内容によって処理内容が変化しないプログ ラムを前提としている。
EXCITは、ソースコードに付加的な情報取得のためのコードを埋め込み、プロ
グラム実行時にデータを収集するツールであり、計算部分の実行に必要なクロッ ク数を、CPUのシミュレータを用いて算出する。INSPIREは、クロックレベルで ネットワークのシミュレーションを生成するツールであり、本手法では通信トレー スファイルを用いたシミュレーションで通信時間を予測する。
図2.1に、EXCITとINSPIREを用いたシミュレーション全体の構成を示す。
図 2.1: EXCITとINSPIREによるシミュレーションの流れ([1]より抜粋)
処理の流れは以下の通りである。
(1) オリジナルの並列プログラム(Prog#0〜Prog#3に分割)をEXCITに通して、
計算区間計測用コードProg”#0、及び通信トレースファイル生成用コード Prog’#0〜Prog’#3を得る。
(2) Prog”#0を実行することで並列プログラムの計算時間を求める。
(3) Prog’#0〜Prog’#3を個別に実行し、プログラム毎に通信トレースファイルを
生成する。通信トレースファイルをシミュレーションすることで並列プログ ラムの通信時間を得る。
実験では、Sun Ultra-1 1台を用いて、NAS Parallel BenchmarksのMGプログ ラム、問題サイズclass Bの実行時間を予測している。16PUを用いた際の実行時 間予測誤差は、10%以内に抑えられている。しかし、実際のプログラム実行時間に 比べて、Prog”#0の実行には数十倍の時間がかかり、プログラムの通信トレース ファイルの作成には20分程度かかる。
2.1.2 Dickens 等の手法 [4]
1996年、Dickens等は、LAPSEというシミュレータを利用し、並列プログラム の実行時間予測を行った。LAPSEは、並列計算機Intel Paragonでのみ動作する シミュレータである。
LAPSEでは、計算部分に関しては、予測対象システム上で実際に計算させるこ
とにより、計算時間を予測する。なお、予測対象計算機のPU数以下で計算部分の
予測を行う場合は、他の計算機で複数の計算部分を測定する必要がある。その際、
予測を行う計算機では、常に予測対象計算機1PU分の計算部分の測定のみを行う ようにすることで、正確な計算時間の測定を行う。
また、通信部分に関しては、それぞれのPUで算出した予測時間の同期をとり、
メッセージサイズに比例した通信時間を想定することで、予測を行う。LAPSEで は、それぞれのPUの実行時間は、別々に予測が行われているため、あるPUの受 信の実行時間を予測する場合は、送信するPUの送信が行われる実行時間を求める 必要がある。そのために、複数のPU間の予測時間の同期をとるために、WHOAと いう通信同期プロトコルを利用する。WHOAを用い、全てのプロセスにおいて通 信関数が呼ばれる時間を予測し、通信の同期をとることで通信時間の予測を行う。
[4]では、SOR(Successive OverRelaxation法)、BPS(Bramble、Pasciak、Schatz により提案された領域分割法)、APUCS(連続時間マルコフ離散事象シミュレー ション)、PGL(Parallel Graphic Library)という4つのアプリケーションを対象 に、実行時間予測を行っている。全てのアプリケーションにおいて、予測の誤差は
10%以内であった。しかし、APUCSアプリケーションにおいて、8PU実行時の予
測を行うためには、実際の実行時間と比べて、2PUを利用すると約30倍、40PU を利用しても約12倍の処理時間が必要となる。
2.1.3 Prakash 等の手法 [5]
Prakash等は、MPI-SIMというシミュレータを利用し、並列プログラムの実行
時間予測を行った。
MPI-SIMでは、LAPSEと同様に、計算時間の予測は、予測対象機と同じ計算
機構成の計算機で実際に実行することで行う。また、通信時間の予測は、同期プ ロトコルを利用することで、異なるPUの予測時間の同期をとることで行う。ま た、[5]では、同期を必要としない通信を、ランタイム時、コンパイル時に解析す ることで、同期プロトコルによる通信によるオーバヘッドを軽減する手法を提案 している。
評価を行うために、並列計算機IBM SP2を用いて、NAS Parallel Benchmarks のMG・LU・SP・BTを用いて実行時間の予測を行っている。これらプログラムの 実行時間予測誤差は5%から20%であった。しかしSP、BT において、16PU実行 時の予測を行うためには、実際に実行する時間と比べて、2PUで約16倍、16PU を利用しても約4倍の処理時間が必要である。
2.2 ソースプログラムの静的解析による予測手法
並列プログラムを静的に解析することで、並列プログラムを実行した際の性能 を予測する手法が提案されている。
本手法は予測にかかる時間が少ないことが特徴である。しかし、静的な解析のみ では、コンパイラの最適化、キュッシュ効果、ネットワーク性能を考慮に入れた、
様々なアーキテクチャに対応した予測をすることができない。また、2.1の予測手 法に比べて予測精度が悪いという問題点がある。
2.2.1 Yarrow 等の手法 [6]
Yarrow等は、NAS Parallel BenchmarksのLUのプログラムの持つキャッシュ ヒット率・通信コストの計算を静的に行う手法を提案した。実験では、IBM SP2 を用い、LUプログラムのCLASS A及びBでの実行時間予測を行い、その結果、
実際の実行時間との誤差が30%以内で予測ができている。
2.2.2 Rothberg 等の手法 [7]
Rothberg等は、キャッシュサイズやPUの処理能力のプログラムへの影響と、通信
時間を静的に予測している。予測はLU分解、CG(Conjugate Gradient)、FFT(Fast Fourier Transform)、Barnes-Hut(階層的機構増を持った並列N-bodyシミュレー ション)、レイトレーシング法を利用したボリュームレンダリングの、5つの並列 アルゴリズムに関して行われている。実際に実機との比較をしていないため、予 測精度は分からないが、すべてのプログラムにおいて、キャッシュサイズが32KB 以上の場合、キャッシュヒット率は90%得られると予測している。
2.3 簡易実行による予測手法
プログラムを解析し、簡易的に実行することで、実行時間を予測できる手法が 提案されている。本手法では、プログラムをすべて実行するのではなく、何らか の省略をすることによって、実際の実行時間よりも短時間で予測をすることが可 能になる。
2.3.1 岩渕等の手法 [8]
岩渕等の手法では、プログラムソースレベルで計算や通信部分をブロック化し、
各ブロック1回分の実行時間(ブロック基礎データ)、及びブロック実行回数を取 得することで、プログラム全体の実行時間を予測する。予測の際、ブロック部分 の実行時間の計測を簡略化することにより、シミュレータを用いる予測手法より も、短時間でプログラムの実行時間を予測することが可能である。計測の簡略化 には、計測時に必要のないブロックをコメントアウトし、プログラムのループ部 分に対してループ回数を削減する方法を用いる。しかし、ループ回数をどのくら い削減するかを静的に決めてしまっているので、予測対象プログラムによっては 十分な精度を得ることができない可能性がある。
NAS Parallel Benchmarks ver2.3の全プログラムに適用した結果、2PUで予測 をした場合、実際の実行時間の1/10〜1/1000の時間で予測ができ、CG・ISを除 くプログラム6つの32PUまでの実行で、予測誤差を10%以内に抑えることがで きている。また、ISプログラムに対して、実際のPU台数と同じ台数使用して予 測をした場合、実際の実行時間に比べて1/3の時間で予測することが可能であっ た。そして、すべてのPU数において予測誤差を15%以内に抑えることが可能で あった。
本手法は、第3章で詳しい説明をする。
2.3.2 水谷等の手法 [9]
水谷等は、不均一な並列計算環境における、マスタスレーブ型並列プログラム の実行時間予測を行う手法を提案している。本手法では、プロセッサ集合をマス タとスレーブに分けてタスクの処理を行う。そして、一部のタスクを実行するこ とにより、残りのタスク実行時間を線形補完し、全体の実行時間を予測する。 図 2.2に、部分実行と線形補完によるタスクの実行時間の推定の様子を示す。横軸は タスク名、縦軸は予測実行時間を表す。
図 2.2: 部分実行と線形補完によるタスクの実行時間の推定([9]より抜粋)
予測対象問題にはマンデルブロ集合探索を用いている。その結果、予測の誤差
8%以内で、かつ実際の実行時間に対して1/8の時間で予測をすることができてい
る。ただし、この実験は、均一な計算機環境でのみ行われているので、不均一な 計算機環境での予測精度は不明である。
2.4 プログラムのモデル化による予測手法
2.4.1 Marin 等の手法 [10]
Marin等は、アプリケーションの静的・動的な特徴をモデル化し、プログラムの
実行性能を半自動的に予測するツールを提案した。本手法では、プログラムの実 行時間に影響を与えるデータをいくつかサンプリングし、データサイズを変えた ときのプログラムの挙動を予測する。予測時の環境と予測対象環境が異なっても 予測をすることができる。図2.3に示すとおり、オブジェクトコードを静的・動的 に解析し、その結果を用いL1・L2のキャッシュミス率やTLBミス率を計算する ことで、実行性能を予測する。
図 2.3: 予測の流れ([10]より抜粋)
処理の流れは以下の通りである。
(1) アプリケーションのバイナリコードを静的解析し、制御流れグラフ(CFG:Control Flow Graph)やループ構造などを得る。
(2) 実行時にしか分からない情報を解析するために、コードに解析のための情報 を追加し、実行する。
(3) (1)(2)で集めたデータをもとに、対象プログラムの挙動を予測する。
実験は、Sun UltraSPARC II上で行われ、対象プログラムはASCI Sweep3D、
NPB2.3-serialのBT・SP、及びNPB3.0のBT・LU・SPの、6つのアプリケーション である。予測対象計算機は、分散共有メモリ型であるOrigin 2000 System(16 CPU) である。結果は、NPB2.3のSP、NPB3.0のBT・LU・SPにおいて、ほぼ実際の 実行時間どおりに予測できている(具体的数値は不明)。また、NPB2.3のBT、及
びSweep3Dにおいても、誤差20%以内を実現している。ただし、予測にかかる時
間に関しては触れていない。また、現時点では並列アプリケーションに関しては 未対応である。
2.5 従来手法のまとめ
これまでに提案されている手法を表2.1に示す。
表 2.1: 従来の実行時間予測手法の比較
1予測対象計算機とPU数、及び予測対象プログラム
2n台の予測をするのに必要なPU数
3実際の実行時間に対しての、予測にかかる時間の比率
第 3 章 簡易実行による実行時間予測 手法 [8] と提案手法
本章では、並列プログラムの簡易実行による実行時間予測手法、及び通信予測 の効率化手法について述べる。
[8]の手法では、MPI[11]プログラムをソースレベルで計算部分と通信部分にブ ロック化し、各ブロック1回分の実行時間(ブロック基礎データ)及びブロック 実行回数を取得することで、プログラム全体の実行時間を予測する。また、計測 には必要のないブロックをコメントアウトし、プログラムのループ部分に対して ループ回数を削減することで、予測にかかる時間の短縮を図る。
これより、3.1でプログラムのブロック分割方法、3.2で基礎パラメータの取得 方法、3.3で基礎パラメータを用いた実行時間予測の方法、3.4で提案手法につい て述べる。
3.1 プログラムのブロック分割方法
本節では、プログラムを複数の「計算ブロック」・「通信ブロック」に分割する方 法を述べる。計算ブロックとはプログラムの最内ループボディを構成する実行文 のことであり、通信ブロックとはMPI通信関数のことである。分割方法を以下に 示す。
(1) ループ構造を持たない部分は、繰返し回数が1回のループとする。
(2) 最内ループのループボディを1つの「計算ブロック」とする。
(3) (2)で得られた計算ブロック内でMPI 通信関数が宣言されている場合は、MPI
通信関数の前後で2つの「計算ブロック」に分割し、さらに、MPI 通信関数 を含む文を「通信ブロック」とする。
図3.1にプログラムをブロックへ分割する例を挙げる。
図 3.1: プログラム分割の例
(1)(2)によりIを計算ブロックとする。また、II・III・IVは最内ループのループ ボディ であるため、(2)により計算ブロックとする。V・VI・VIIは1つのループ ボディだが、間にMPI通信関数を 含むため、(3)によりV・VIIを計算ブロック、
VIを通信ブロックとする。
3.2 基礎パラメータの取得
予測に必要な、計算・通信ブロックの基礎パラメータ及び各ブロックの実行回 数の定義と取得方法を述べる。短時間で予測をするために、基礎パラメータを取 得する際には、各ループのループ回数を減らして実行を行う。この方法を簡易実 行と呼ぶ。
3.2.1 計算ブロックの基礎パラメータの取得
計算ブロックの基礎パラメータは、各計算ブロックが1回実行されるときの実 行時間である。これより、計算ブロックの基礎パラメータの表現方法と取得方法 を示す。
• T b comp(p, i):計算ブロックiの基礎パラメータ
(ただし、1≤i≤N 、
N は計算ブロックの個数であり、pは実行PU 台数である。)
T b comp(p, i)を求めるためには、まず3.1で述べた方法により、ソースプログ
ラムをN個の計算ブロックに分割する。その後、各計算ブロックの基礎パラメー タを取得するためのソースプログラムを、オリジナルのMPIプログラムに挿入す る。基礎パラメータの時間計測にはMPI Wtime()を使用した。
ここで、コンパイラの最適化及びキャッシュ効果を考慮したT b comp(p, i)を得 るため、当該計算ブロックのみをループボディとして持つループ全体の実行時間を
計測し、T b comp(p, i)とする。例えば、図3.1でのIVの基礎パラメータを得る場
合、L3及びL4のforループ全体の実行時間を計測し、T b comp(p,IV)を求める。
3.2.2 通信ブロックの基礎パラメータの取得
通信ブロックの基礎パラメータは、各通信ブロックが1回実行されるときの実 行時間である。これより、通信ブロックの基礎パラメータの表現方法と取得方法 を示す。
• T b comm(p, j):通信ブロックjの基礎パラメータ
(ただし、1≤j ≤M 、
M は通信ブロックの個数であり、pは実行PU 台数である。)
T b comm(p, j)を求めるためには、まず3.1で述べた方法により、ソースプログ
ラムをM個の通信ブロックに分割する。その後、各通信ブロックの基礎パラメー タを取得するためのソースプログラムを、オリジナルのMPIプログラムに挿入す る。基礎パラメータの時間計測には、計算ブロック同様MPI Wtime()を使用した。
ここでは、ネットワークの性能や負荷を考慮したT b comm(p, j)を得るために、
当該通信ブロックのループ部分を数回実行することによって実行時間を計測し、
T b comm(p, j)を算出する。例えば、図3.1でVIの基礎パラメータを得る場合、L5 の実行時間を計測し、T b comm(p, VI )を求める。
3.2.3 各ブロック実行回数の取得
次に、PU台数がp台時のブロック実行回数を求める方法を述べる。尚、ブロッ ク実行回数の取得には、1台のPUがあればよい。簡易実行を実現するために、プ ログラムのループ部分のループ回数を削減しているため、各ブロックの基礎パラ メータを取得する時と、実際にプログラムを実行する時とでは実行回数が異なる。
そのため、基礎パラメータ取得時のブロック実行回数と、実際にプログラムを実 行する時のブロック実行回数の両方を取得する必要がある。
• Np comp(p, i):予測の際に計算ブロックiを実行する回数
• Nr comp(p, i):計算ブロックiの実際の実行回数
• Np comm(p, j):予測の際に通信ブロックjを実行する回数
• Nr comm(p, j);通信ブロックjの実際の実行回数
また、各ブロック実行回数の取得の際には、取得のための処理時間を削減する ために、対象となるMPIプログラムに以下の方法を適用する。
(1) プログラム中の全てのループに対して、ブロック実行回数に依存する変数の 計算文のみを残し、他の実行文をコメントアウトする。
(2) MPI 通信関数も、(1) のブロック実行回数に依存する通信以外はコメントア
ウトする。
以上の方法で作成したプログラムを実行し、各ブロックの実行回数を取得する。
3.3 各ブロックの実行時間予測手法
本節では、3.2で述べた方法により取得したパラメータを使用して、実行時間を 予測する手法を説明する。
3.3.1 計算ブロック予測
計算ブロックを予測するには、3.2.1で得られたT b comp(p, i)、及び3.2.3で得 られたNp comp(p, i)とNr comp(p, i)を用いて、PU台数がp台時のブロックiの 実行時間T comp(p, i)を式(3.1)により計算をする。
T comp(p, i) = T b comp(p, i)
Nr comp(p, i) ×Np comp(p, i) (3.1)
3.3.2 通信ブロック予測
通信ブロックを予測するには、3.2.2で得られたT b comm(p, j)、及び3.2.3で得 られたNp comm(p, j)とNr comm(p, j)を用いて、PU台数がp台時のブロックj の実行時間T comm(p, j)を式(3.2)により計算をする。
T comm(p, j) = T b comm(p, j)
Nr comm(p, j)×Np comm(p, j) (3.2)
3.3.3 全実行時間予測
PU台数がp台時におけるプログラム全体の実行時間T All(p)は、3.3.1及び3.3.2 で述べた方法により得られる、計算ブロックの予測実行時間T comp(p, i)と、通 信ブロックの予測実行時間T comm(p, j)を用いて、式(3.3)のように予測する。
T All(p) =
N
i=1T comp(p, i) +
M
j=1T comm(p, j) (3.3)
3.4 提案手法
本節では、前節までに述べてきた簡易実行による実行時間予測手法の、通信の 予測を改良した手法について説明する。
MPIプログラムを実行する際、通信にかかる時間はネットワークの性能や負荷 に大きく左右される。PU数が多くなり、あらゆるPUが通信をし始めると、ネッ トワークコンテンションが発生する確率が増えてくる。コンテンションが発生す ると、通常の通信よりも時間がかかるため、頻繁に発生すれば通信時間に大きく 影響してくる。コンテンションの発生率が分かれば、予測の精度を向上させるこ とができるが、コンテンションがいつ発生するかを予測するのは困難である。し たがって、予測には通信を複数回行い、十分なデータを取得する必要がある。
MPIプログラムでは、MPI Barrier()などの同期通信関数を呼び出した直後の通 信で、コンテンションによる通信の遅延が大きくなることが分かった。128PU使 用時に、MPI Allreduce()関数を呼び出した時の通信の遅延の様子を図3.2に示し、
また、同期通信関数の影響を受ける通信を図3.3に示す。PU数にもよるが、通常 の通信の10倍以上の時間がかかる。そこで、同期通信関数を呼び出した直後の通 信(1ループ目の通信)と、2ループ目以降の通信を区別して計測することにした。
通信を区別して計測するために、簡易実行による実行時間予測手法の一部を改 良する必要がある。そこで、3.4.1で基礎パラメータの取得の変更点、3.4.2で通信 ブロック予測の変更点を述べる。他の項目に関しては、前節までに述べた方法を 利用する。
図 3.2: コンテンションによる通信の遅延
図 3.3: 同期通信関数と通信ブロック
3.4.1 基礎パラメータの取得
従来の通信ブロックの基礎パラメータは、3.2.2で述べたように、T b comm(p, j) のみである。しかし、T b comm(p, j)のみでは、同期通信関数を呼び出した直後の 通信(1ループ目の通信)と2ループ目以降の通信を区別できない。そこで、通信 ブロック基礎パラメータを以下のように2つに分ける。
(1) T b comm1st(p, j):通信ブロックjの1ループ目の基礎パラメータ (2) T b comm2to(p, j):通信ブロックjの2ループ目以降の基礎パラメータ
(ただし、1≤j ≤M 、
Mは通信ブロックの個数であり、pは実行PU 台数である。)
また、計算ブロックの予測は従来の方法で行うため、改良は加えない。
3.4.2 通信ブロック予測
ここでは、3.4.1で取得した基礎パラメータを元にした、通信ブロックの予測方 法を述べる。
従来は、式(3.2)を使ってT comm(p, j)を予測をしていたが、これを式(3.4)に 改める。
T comm(p, j) = T b comm1st(p, j) + T b comm2to(p, j)
Nr comm(p, j)−1×Np comm(p, j)−1 (3.4)
第 4 章 姫野ベンチマークを用いた提 案手法の評価
本章では、第3章で説明した簡易実行による実行時間予測手法、及び提案手法 の検証を行い、評価結果を示し考察を行う。手法の検証には、姫野ベンチマーク
[14]を用いて2〜128台のPUの実行時間予測を行った。これより、4.1で予測対象
プラットフォーム及びプログラムについて述べ、4.2で予測結果を示すと共に考察 を行う。最後に、4.3で本章のまとめを行う。
4.1 予測対象プラットフォームと予測対象プログラム
本節では、4.1.1で予測対象プラットフォームを示し、4.1.2で予測対象プログラ ムの概要を示す。
4.1.1 実行環境
実行環境
本稿で予測に用いたプラットフォームを表4.1に示す。
表 4.1: 予測対象プラットフォーム
項目 スペック
Node 128
CPU Intel Pentium4
Clock 2.4GHz
HDD 240GB (120GB×2) 7200rpm Memory 1GB (512MB×2) SDRAM
L2 Cache 512KB
Network 1000BaseT Ethernet
Network Switch NETGEAR Gigabit Switch GS524Tモデル(TOP)
NETGEAR Gigabit Switch GS516Tモデル(内部)
OS RedHat Linux 7.3
Compiler gcc 2.95.3 Compiler Option -O3
また、予測対象プラットフォームのネットワーク構成を図4.1に示す。
図 4.1: ネットワーク構成
MPICH
MPIプログラムの実行には、すべてMPICH[12] ver1.2.6を使用した。MPICH は、Argonne National Laboratoryで開発されたフリーのソフトウェアであり、MPI 規格の実装の一つである。
MPICHはC言語、Fortranに対応した並列計算用ライブラリである。MPICH
は、既存のコンパイラと併せて利用することでMPIプログラムのコンパイル・実 行を実現する。今回はコンパイラとしてgccを、他のノードにおけるプログラムの 実行命令としてrshを用いた。MPICHは、make時のオプションにより、プロセ スの起動にrshでなくsshを指定することも可能である。
また、MPI-1に動的プロセス生成や、並列IOなどの拡張を行ったMPI-2を完全 にサポートするMPICH2もリリースされている。現在の最新バージョンは、2004 年9月にリリースされたver1.0である。
フリーのMPI実装系として他にはLAM[13]がある。MPICHとの相違点は通信 の方式にあり、MPICHが通信毎にソケットコネクションの確率を行うのに対し、
LAMはプログラムの実行時にホスト上にデーモンを起動させ通信を行う。
4.1.2 姫野ベンチマーク
姫野ベンチマーク[14]は、情報基盤センター・センター長の姫野龍太郎氏によっ て、非圧縮流体解析コードの性能評価のために実装されたものである。内容は、ポ アッソン方程式解法をヤコビの反復法で解く場合に 主要なループの処理速度を計 るものである。コードが非常に短く、簡単にコンパイル・実行できるので、即座に 速度を求めることができる。
姫野ベンチマークは、表4.2に示す通り、5通りの計算サイズで速度を測定する ことができる。表中のi・j・kは配列のサイズを表しており、姫野ベンチマーク では配列を分割し、複数の計算機に分散させることで、並列に処理を行うことが 可能になっている。どのように分割させるかはコンパイル前に決めることができ、
その分割の仕方によって何台のPUを使うかが決定される。具体的には、配列の 次元ごとの分割数を乗じたものとなる。例えば、配列を2・4・4と分割させると、
必要PU数は32となる。
表 4.2: 姫野ベンチマーク・計算サイズ サイズ i×j×k
XS 32×32×64 S 64×64×128 M 128×128×256
L 256×256×512 XL 512×512×1024
4.2 姫野ベンチマークの予測結果
本節では、簡易実行による実行時間予測手法を用い、2〜128(2・4・8・16・32・
64・128)のPU数における、姫野ベンチマーク計算サイズMの実行時間を予測し
た結果を示し、考察を行う。
まず、図4.2に姫野ベンチマークのプログラム構造を示す。今回の計測は、主 ループ(図4.2中の囲み部分)のループ回数を5000回に固定したものを想定する ことにした。”5000”回に”固定”した理由には2つある。1つは、本稿の手法の対象 が中〜大規模のプログラムを想定しているためである。姫野ベンチマークでは、本 計測の前に予備計測を行い、予備計測の結果を基にして本計測のループ回数を決 定している。しかし、予備計測を元にして計測を行うと、PU数によっては数秒で 処理が終了するため、中〜大規模プログラムを対象とする本稿の手法の趣旨とは ずれる。もう1つの理由は、PU数の違いによる性能を単純に比較できるようにす るためである。PU数に関係なくループ回数を固定すれば、実行時間だけで性能比 較できるため、ピーク性能が分かりやすい。
なお、計算予測は従来の[8]の手法と同じものを、通信予測は3.4で述べた提案 手法を用いて行う。
これより、4.2.1で計算、通信、及び計算と通信を合わせた全実行時間予測の結 果を示す。つづいて、4.2.2で予測の誤差について、4.2.3で予測にかかる時間を考 察する。最後に、4.2.4で岩渕等の手法[8]との比較を行う。
図 4.2: 姫野ベンチマークのプログラム構造
4.2.1 実行時間予測
計算時間予測
簡易実行による実行時間予測手法では、短時間での計測を実現するために、プ ログラム中のループ部分のループ回数を削減する。今回の測定対象プログラムで ある姫野ベンチマークでは、図4.2の主ループ部分のループ回数を削減した。ルー プ回数を削減するということは、予測時に計算ブロック・通信ブロックの実行回 数が削減されるということである。そこで、どの程度計算ブロックを実行すれば 十分な精度が得られるかを検証するために、ループ回数と計算ブロック予測実行 時間の関係を調べた。主ループのループ回数を5・10・50・100・500回と変え、計 算ブロックの実行時間の予測結果を図4.3に示す。実験は各回数とも10回ずつ行 い、すべての予測データを図にプロットした。また、実際の実行時間と比較する ために、実際の実行時間の範囲を2つの線で囲まれた部分で定義する。
通信時間予測
計算予測と同様に、どの程度通信ブロックを実行すれば十分な精度が得られる かを検証するために、ループ回数と通信ブロック予測実行時間の関係を調べた。主 ループのループ回数を5・10・50・100・500回と変え、通信ブロックの実行時間の 予測結果を図4.4に示す。
全実行時間予測
計算ブロックと通信ブロックを合わせた全実行時間の予測を行う。図4.5にルー プ回数と予測実行時間の関係を示す。
0 100 200 300 400 500 600 700 800 900 1000
Real 5 10 50 100 500
time(second)
# of loop(time)
0 100 200 300 400 500 600
Real 5 10 50 100 500
time(second)
# of loop(time)
(a)2PU時 (b)4PU時
0 50 100 150 200 250
Real 5 10 50 100 500
time(second)
# of loop(time)
0 20 40 60 80 100 120 140
Real 5 10 50 100 500
time(second)
# of loop(time)
(c)8PU時 (d)16PU時
0 10 20 30 40 50 60
Real 5 10 50 100 500
time(second)
# of loop(time)
0 5 10 15 20 25 30
Real 5 10 50 100 500
time(second)
# of loop(time)
(e)32PU時 (f)64PU時
0 2 4 6 8 10 12 14 16
Real 5 10 50 100 500
time(second)
# of loop(time) (g)128PU時
図 4.3: ループ回数と計算ブロック予測実行時間の関係
0 20 40 60 80 100 120 140 160
Real 5 10 50 100 500
time(second)
# of loop(time)
0 20 40 60 80 100 120 140 160
Real 5 10 50 100 500
time(second)
# of loop(time)
(a)2PU時 (b)4PU時
0 10 20 30 40 50 60 70 80
Real 5 10 50 100 500
time(second)
# of loop(time)
0 10 20 30 40 50 60 70
Real 5 10 50 100 500
time(second)
# of loop(time)
(c)8PU時 (d)16PU時
0 10 20 30 40 50 60
Real 5 10 50 100 500
time(second)
# of loop(time)
0 5 10 15 20 25 30 35 40 45
Real 5 10 50 100 500
time(second)
# of loop(time)
(e)32PU時 (f)64PU時
0 20 40 60 80 100 120 140
Real 5 10 50 100 500
time(second)
# of loop(time) (g)128PU時
図 4.4: ループ回数と通信ブロック予測実行時間の関係
0 200 400 600 800 1000 1200
Real 5 10 50 100 500
time(second)
# of loop(time)
0 100 200 300 400 500 600
Real 5 10 50 100 500
time(second)
# of loop(time)
(a)2PU時 (b)4PU時
0 50 100 150 200 250 300 350
Real 5 10 50 100 500
time(second)
# of loop(time)
0 20 40 60 80 100 120 140 160 180
Real 5 10 50 100 500
time(second)
# of loop(time)
(c)8PU時 (d)16PU時
0 20 40 60 80 100 120
500 100 50 10 5 Real
time(second)
# of loop(time)
0 10 20 30 40 50 60 70
Real 5 10 50 100 500
time(second)
# of loop(time)
(e)32PU時 (f)64PU時
0 20 40 60 80 100 120 140 160
Real 5 10 50 100 500
time(second)
# of loop(time) (g)128PU時
図 4.5: ループ回数と全予測実行時間の関係
4.2.2 予測誤差
図4.3・4.4・4.5から分かるように、ループ回数を多くするとデータのバラつき
が減っていくことが読み取れる。本稿では、データのバラつき具合を実際の実行 時間に対する誤差と考える。そこで、どの程度バラつきがあるのかを計算する(偏 差Dを求める)ために、式(4.1)を用いる。なお、標準偏差を求める式を参考にし ているが、通常の標準偏差とは違い、実際の実行時間のデータ範囲からのズレを 求めることとする。つまり、すべての予測データが実際の実行時間のデータ範囲 に入っている場合は、偏差Dは0と考える。
また、偏差Dが実際の実行時間と比べてどの程度差があるのかを誤差eとして、
eを求める式を式(4.2)に示す。
D =
1
N
N i=1
di2 (4.1)
di =
⎧⎪
⎪⎨
⎪⎪
⎩
xi−max (ifxi > max)
0 (ifmin≤xi ≤max) xi−min (ifxi < min)
e = D
min + D
max
× 1
2 ×100 [%] (4.2)
(ただし、Nはデータ数、min・maxはそれぞれ実測時 のデータの最小値・最大値を示す))
表4.3・4.4・4.5は、それぞれ計算・通信・全実行時間予測の偏差と誤差を表した
ものである。また、表4.3・4.4・4.5の予測誤差の部分を図に表したものが図4.6・
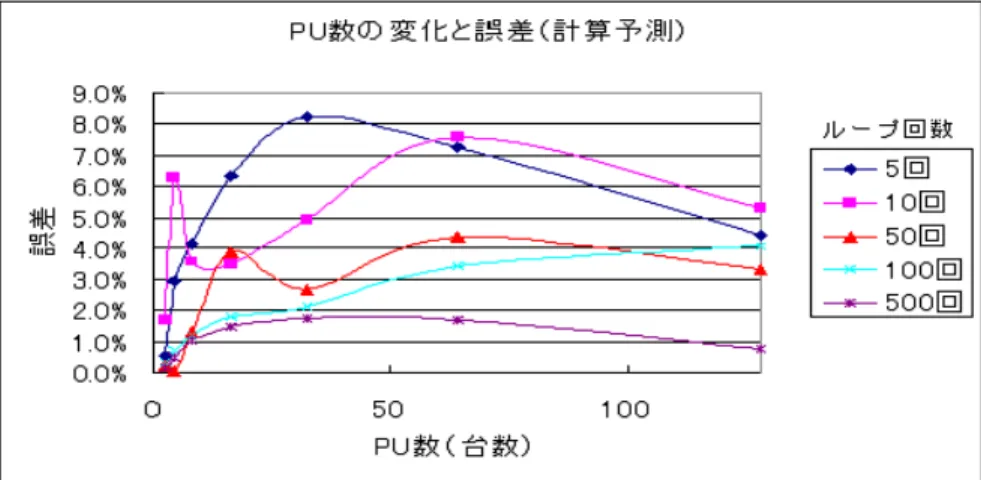
4.7・4.8であり、予測誤差をPU数の変化に着目して図示したものが、図4.9・4.10・ 4.11である。
計算予測に関しては、すべてのPU数において、ループ回数を5回まで(実測時
の1/1000回)削減しても誤差を9%以内に抑えることができた。また、ループ回
数を500回(実測時の1/10回)にすると、誤差を2%以内にすることができた。
通信予測に関しては、計算予測に比べて、誤差が安定するまでに必要なループ 回数は多くなっている。しかし、ループ回数を100回にすれば、128PU使用時を 除いて誤差を12%以内、500回にすれば、すべてのPU数において誤差を11%以内 にすることができた。
最後に、計算と通信を合わせた全実行時間予測の誤差について考察する。PU数 が少ない場合は計算部分の比率が高いため、通信の誤差が大きくても、全体の誤 差自体はループ回数を削減しても小さくなる。64PU使用時まではループ回数を5 回まで削減しても、誤差を8%以内に抑えることができた。しかし、128PU使用時 は図3.2に示すようなコンテンションの発生が頻繁に起きるため、通信全体の予測 をするために必要なループ回数を十分に取らなければならない。そのため、ルー
プ回数が少ない場合、通信予測の誤差が大きくなるため、全体の予測誤差も大き くなっている。ただし、ループ回数を500回とした時は、予測の誤差は4.69%であ り、予測に必要なループ回数が100〜500回の間にあることが分かる。
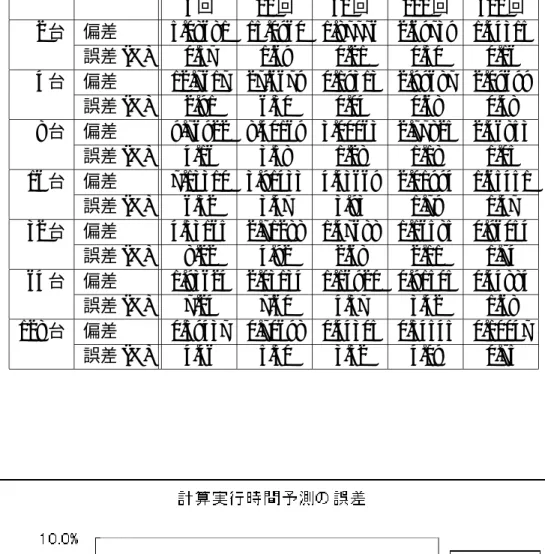
表 4.3: 計算実行時間予測の偏差と誤差
5回 10回 50回 100回 500回
2台 偏差 5.08681 15.0960 1.87776 2.69739 1.44315 誤差(%) 0.57 1.69 0.21 0.30 0.16 4台 偏差 12.7617 27.6679 0.19313 2.99687 2.09699
誤差(%) 2.91 6.30 0.04 0.68 0.48 8台 偏差 9.76922 8.40169 3.00063 2.77825 2.46853
誤差(%) 4.16 3.58 1.28 1.18 1.05 16台 偏差 7.13310 3.91433 4.43669 2.01994 1.65451
誤差(%) 6.32 3.47 3.93 1.79 1.47 32台 偏差 4.53165 2.71288 1.47688 1.16585 0.96054
誤差(%) 8.22 4.92 2.68 2.11 1.74 64台 偏差 1.93624 2.03134 1.16920 0.91505 0.44884
誤差(%) 7.24 7.60 4.37 3.42 1.68 128台 偏差 0.59437 0.70698 0.44305 0.54545 0.10047
誤差(%) 4.46 5.30 3.32 4.09 0.75
図 4.6: 計算実行時間予測の予測誤差
表 4.4: 通信実行時間予測の偏差と誤差
5回 10回 50回 100回 500回
2台 偏差 2.17607 26.3408 0.59488 1.86242 1.40127 誤差(%) 4.72 57.1 1.29 4.04 3.04 4台 偏差 2.46625 27.5381 0.24534 2.04991 0.34642
誤差(%) 4.53 50.5 0.45 3.76 0.64 8台 偏差 3.60570 3.21607 5.86786 2.52205 2.98574
誤差(%) 6.61 5.89 10.7 4.62 5.47 16台 偏差 8.81068 2.01831 0.48330 0.02873 1.56799
誤差(%) 24.29 5.56 1.33 0.08 4.32
32台 偏差 5.29496 0.72201 7.02592 3.56834 3.28357
誤差(%) 17.13 2.34 22.7 11.5 10.6
64台 偏差 1.09375 0.67328 1.80067 1.96385 0 誤差(%) 3.35 2.06 5.51 6.01 0.00 128台 偏差 12.1490 33.0984 9.07918 9.56668 1.83211
誤差(%) 42.2 115 31.5 33.2 6.37
図 4.7: 通信実行時間予測の予測誤差
表 4.5: 全実行時間予測の偏差と誤差
5回 10回 50回 100回 500回
2台 偏差 4.33282 37.4875 1.17945 2.28388 0.94044 誤差(%) 0.46 4.02 0.13 0.24 0.10 4台 偏差 10.9831 37.0733 0.05240 2.01429 0.73053
誤差(%) 2.22 7.48 0.01 0.41 0.15 8台 偏差 5.35476 7.59344 4.82002 0.62729 1.66383
誤差(%) 1.85 2.63 1.67 0.22 0.58 16台 偏差 7.27174 2.23896 3.86426 0.15647 0.14167
誤差(%) 4.87 1.50 2.59 0.10 0.09 32台 偏差 4.82746 2.23569 6.40027 2.68745 2.71293
誤差(%) 5.60 2.59 7.42 3.12 3.15 64台 偏差 1.84788 1.95455 1.50323 1.61573 0
誤差(%) 3.10 3.28 2.52 2.71 0.00 128台 偏差 12.1990 33.0057 9.05389 9.45989 1.97364
誤差(%) 28.9 78.3 21.4 22.4 4.69
図 4.8: 全実行時間予測の予測誤差
図 4.9: PU数の変化と予測誤差(計算)
図 4.10: PU数の変化と予測誤差(通信)
図 4.11: PU数の変化と予測誤差(全体)
4.2.3 予測にかかる時間
表4.6、図4.12に実際の実行時間と予測にかかる時間の比較を示す。ループ回数
を5回に抑えれば、どのPU数でも1/1000の時間、ループ回数を500回にすれば 1/10の時間で予測をすることが可能である。
表 4.6: 予測にかかる時間(平均)
実測 5回 10回 50回 100回 500回 2台 940.645 0.94070 1.91937 9.40154 18.7790 93.9317 4台 499.280 0.50495 1.03376 5.00765 9.92809 49.8534 8台 289.006 0.28807 0.58263 2.90837 5.79708 29.1536 16台 147.984 0.21609 0.33636 1.51526 3.01145 14.8693 32台 85.8311 0.25321 0.32131 1.08824 1.91384 8.85372 64台 58.5906 0.34351 0.39398 0.86666 1.47755 5.98996 128台 41.4924 0.41222 0.44392 0.83306 1.19258 4.30539 合計 2062.83 2.95876 5.03133 21.6207 42.0996 206.957
単位(秒)
図 4.12: 全PU数における実際の実行時間と予測にかかる時間の比較
4.2.4 岩渕等の手法との比較
ここでは、本稿で参照した[8]の手法との比較を行う。[8]の手法と提案手法の違 いは、通信予測の計算方法の違いである。
予測実行時間
図4.13に[8]の手法を用いたループ回数と通信ブロック予測実行時間の関係、図 4.14に[8]の手法を用いたループ回数と予測実行時間の関係を示す。
予測誤差・予測にかかる時間
表4.7・4.8にそれぞれ[8]の手法を用いた通信予測の偏差と誤差、全実行時間予
測の偏差と誤差を示す。また、図4.15・4.15にそれぞれ[8]の手法を用いた通信予 測の誤差、全実行時間予測の誤差を示す。8PU使用時までは、誤差は提案手法と 変わりないが、16PU以上を使用すると、ループ回数を多くしないと誤差が大きく なることが分かる。PU数が多い場合、通信が占める比重は高くなるので、結果的 に全実行時間に影響を与えることになる。
また、[8]の手法では静的にループ回数を決めているため、PU数に関わらず予 測時のループ回数は一定である。そのため今回の実験の場合、一番誤差が大きい PU数128台使用時を想定してループ回数を決めなければならない。
しかし、提案手法を用いて、さらに各PU数で各々ループ回数を決めることが できれば、予測にかかる時間を短縮することができる。例えば、予測誤差5%以内 を目安に考えると、提案手法では8.51秒で予測できるのに対して、[8]の手法では ループ回数を500回にする必要があり、予測に207秒かかる(実際の実行時間は 2062秒)。また、予測誤差45%以内を目安に考えても、提案手法では3.38秒で予 測できるのに対して、[8]の手法ではループ回数を100回にする必要があり、予測 に42.1秒かかる。
0 20 40 60 80 100 120 140 160
Real 5 10 50 100 500
time(second)
# of loop(time)
0 20 40 60 80 100 120 140 160
Real 5 10 50 100 500
time(second)
# of loop(time)
(a)2PU時 (b)4PU時
0 10 20 30 40 50 60 70 80
Real 5 10 50 100 500
time(second)
# of loop(time)
0 50 100 150 200 250
Real 5 10 50 100 500
time(second)
# of loop(time)
(c)8PU時 (d)16PU時
0 50 100 150 200 250 300
Real 5 10 50 100 500
time(second)
# of loop(time)
0 50 100 150 200 250 300 350 400
Real 5 10 50 100 500
time(second)
# of loop(time)
(e)32PU時 (f)64PU時
0 50 100 150 200 250 300 350 400 450 500
Real 5 10 50 100 500
time(second)
# of loop(time) (g)128PU時
図 4.13: ループ回数と通信ブロック予測実行時間の関係([8]の手法)
0 200 400 600 800 1000 1200
Real 5 10 50 100 500
time(second)
# of loop(time)
0 100 200 300 400 500 600
Real 5 10 50 100 500
time(second)
# of loop(time)
(a)2PU時 (b)4PU時
0 50 100 150 200 250 300 350
Real 5 10 50 100 500
time(second)
# of loop(time)
0 50 100 150 200 250 300 350
Real 5 10 50 100 500
time(second)
# of loop(time)
(c)8PU時 (d)16PU時
0 50 100 150 200 250 300 350
Real 5 10 50 100 500
time(second)
# of loop(time)
0 50 100 150 200 250 300 350 400 450
Real 5 10 50 100 500
time(second)
# of loop(time)
(e)32PU時 (f)64PU時
0 50 100 150 200 250 300 350 400 450 500
Real 5 10 50 100 500
time(second)
# of loop(time) (g)128PU時
図 4.14: ループ回数と予測実行時間の関係([8]の手法)
表 4.7: 通信実行時間予測の偏差と誤差
5回 10回 50回 100回 500回
2台 偏差 1.84296 24.3962 0.58712 1.87362 1.41430
誤差(%) 4.00 52.91 1.27 4.06 3.07
4台 偏差 3.27568 24.8792 0.25513 2.02626 0.34380
誤差(%) 6.02 45.69 0.47 3.72 0.63
8台 偏差 5.40179 4.28101 5.97060 2.56013 2.98309
誤差(%) 9.90 7.85 10.94 4.69 5.47
16台 偏差 86.8965 21.1869 5.01907 3.70235 1.89447 誤差(%) 239.58 58.41 13.84 10.21 5.22 32台 偏差 175.190 78.6910 23.7561 9.99637 4.00415
誤差(%) 566.63 254.52 76.84 32.33 12.95 64台 偏差 286.058 137.705 25.0675 12.2160 0
誤差(%) 874.96 421.20 76.67 37.36 0.00 128台 偏差 371.181 181.727 40.8601 18.2936 1.67580
誤差(%) 1290.20 631.67 142.03 63.59 5.82
図 4.15: 通信実行時間予測の予測誤差
表 4.8: 全実行時間予測の偏差と誤差
5回 10回 50回 100回 500回
2台 偏差 4.33500 35.3548 1.04252 2.28551 0.93903 誤差(%) 0.46 3.79 0.11 0.24 0.10 4台 偏差 12.0082 35.1240 0.06218 1.99205 0.73109
誤差(%) 2.42 7.09 0.01 0.40 0.15 8台 偏差 6.45143 7.23777 4.87321 0.62067 1.66076
誤差(%) 2.23 2.50 1.69 0.21 0.57 16台 偏差 86.0853 17.1514 7.85954 0.59051 0.23796
誤差(%) 57.71 11.50 5.27 0.40 0.16
32台 偏差 170.364 76.3360 22.1052 8.55722 3.33138 誤差(%) 197.52 88.50 25.63 9.92 3.86 64台 偏差 283.982 136.570 23.9348 11.3988 0
誤差(%) 476.22 229.02 40.14 19.12 0.00 128台 偏差 370.606 181.402 40.6100 18.3988 1.77054
誤差(%) 879.74 430.61 96.40 43.68 4.20
図 4.16: 全実行時間予測の予測誤差
4.3 まとめ
本節では、第4章で見てきた結果についてのまとめを行う。
[8]の簡易実行による実行時間予測手法、及び通信予測の効率化手法について、
姫野ベンチマークを用いてその有効性を検証してきた。その結果、以下のことが 分かった。
• 計算ブロックを含むループのループ回数を1/1000に削減しても、計算ブロッ クの予測誤差を9%以内に抑えることができた。
• さらに、計算ブロックを含むループのループ回数を1/10にすると、計算ブ ロックの予測誤差を2%以内に抑えることができた。
• 同期通信関数呼び出し直後の通信(1ループ目の通信)を、2ループ目以降 の通信と区別することで、予測に必要な通信回数を削減することができた。
• 実際の実行時間の1/1000〜1/10の時間で、実行時間を予測することができた。
第 5 章 おわりに
本稿では、並列プログラムの簡易実行による実行時間予測手法、及び通信予測 の効率化手法について述べた。そして、本手法を姫野ベンチマークに適用し、実 行時間予測を行った。評価対象はサイズMに限って測定をした。結果は、実際の 実行時間に比べて1/100の時間で、予測の誤差5%以内で予測をすることが実現で きた。また、従来の簡易実行手法に比べて、誤差5%以内の予測をするのにかかる 時間が1/20となり、予測の効率化を実現できた。姫野ベンチマークは単純なルー プ構造で構成されているが、そのようなプログラムに対して、簡易実行による実 行時間予測手法が有効であることが示すことができた。
今後の課題として3つ取り上げる。1つは、今回姫野ベンチマークのみしか実験 を行うことができなかったので、他の多くのプログラムへ適用することである。2 つ目は、ループ部分のループ回数削減を動的に決められるようにすることである。
そして3つ目は、プログラムの自動化である。現在はすべて手動でソースプログ ラムを修正しているので、将来的にはすべて自動で予測を完了することが目標で ある。
謝辞
本研究を進めるにあたり、数々のご指導をいただいた山名早人助教授に感謝いた します。また、岩渕先輩をはじめ、山名研究室の諸先輩方にも様々なアドバイス をいただき、非常に参考になりました。この場を借りて厚く御礼申し上げます。
![図 2.1: EXCIT と INSPIRE によるシミュレーションの流れ([1] より抜粋) 処理の流れは以下の通りである。 (1) オリジナルの並列プログラム (Prog#0〜Prog#3 に分割) を EXCIT に通して、 計算区間計測用コード Prog”#0、及び通信トレースファイル生成用コード Prog’#0〜Prog’#3 を得る。 (2) Prog”#0 を実行することで並列プログラムの計算時間を求める。 (3) Prog’#0〜Prog’#3 を個別に実行し、プログラム毎に通信トレースファ](https://thumb-ap.123doks.com/thumbv2/123deta/9785053.1868385/8.918.207.681.82.381/シミュレーションオリジナルトレースファイルトレースファ.webp)
![図 2.2: 部分実行と線形補完によるタスクの実行時間の推定( [9] より抜粋)](https://thumb-ap.123doks.com/thumbv2/123deta/9785053.1868385/12.918.221.682.99.272/図22部分実行と線形補完によるタスクの実行時間の推定より抜粋.webp)