卒業研究論文
鉄道ネットワークを用いた 職住分布の同時形成モデルの構築
01D8103011i
円地 隆之中央大学理工学部情報工学科 田口研究室
2005
年3
月概要
本研究では
,
労働者の居住地・就業地の選択行動を「都市の地代」,
「収穫逓増の効果」,
「通勤費用」の観点から記述する
.
都市の地代,
収穫逓増の効果は,
居住地分布・就業地分布 により内生的に定まる効用関数として取り入れる.
特に,
収穫逓増の効果は,
企業のコミュ ニケーション活動により説明する.
さらに,
鉄道を利用する通勤行動に着目し,
鉄道ネット ワークにより定まる通勤費用を用いる.
そして,
ランダム効用理論に基づく職住分布の同 時形成モデルを用いて,
都市の均衡職住分布を解として与える関数方程式を導く.
数値計 算を行うことにより,
本モデルは都心の形成,
副都心の形成,
居住地のドーナツ化現象を再 現することが可能であることを示す.
キーワード
:
ランダム効用理論,
職住分布,
均衡,
同時形成モデル,
鉄道ネットワーク,
都心,
副都心目 次
第
1
章 序論1
第
2
章 ロジットモデル3
2.1
ランダム効用理論. . . . 3
2.2
ロジットモデル. . . . 4
第
3
章 職住分布の同時形成7 3.1
職住分布の同時形成モデル. . . . 7
3.1.1
職住分布. . . . 7
3.1.2
職住選択行動の前提. . . . 8
3.1.3
基本モデル. . . . 8
3.2
土地利用モデルに基づく労働者の職住選択行動. . . . 9
3.2.1
労働者と企業の立地行動. . . . 9
3.2.2
労働者の職住選択行動. . . . 14
3.3
鉄道ネットワーク上の職住分布. . . . 15
3.3.1
ネットワーク型都市空間の定義. . . . 15
3.3.2
鉄道ネットワークを用いた労働者の職住選択行動. . . . 16
3.4
鉄道ネットワークを用いた職住分布の同時形成モデルの構築. . . . 17
3.4.1
鉄道ネットワークを用いた職住分布の同時形成モデル. . . . 17
3.4.2
反復計算による解法. . . . 18
第
4
章 数値実験20 4.1
準備. . . . 20
4.2
結果. . . . 25
4.2.1
モデルの再現性. . . . 31
第
5
章 結論33
謝辞
34
参考文献
35
図 目 次
3.1 F (φ)
のグラフ. . . . 11
3.2 φ ∗
のグラフ. . . . 11
3.3 exp( − τ w | y | )
のグラフ. . . . 12
3.4 m(x)
のグラフ. . . . 13
3.5 A(x)
のグラフ(τ w = 0.1, C A = 1) . . . . 13
3.6 A(x)
のグラフ(τ w = 0.5, C A = 1) . . . . 13
3.7 A(x)
のグラフ(τ w = 0.1, C A = 2) . . . . 13
4.1
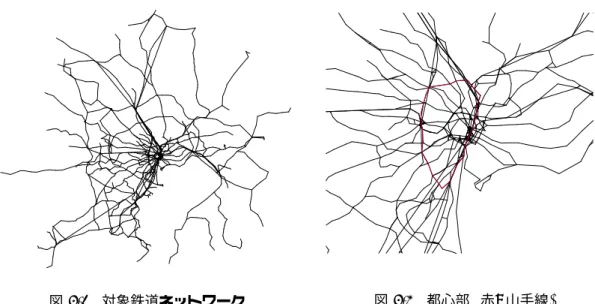
対象領域. . . . 20
4.2
対象鉄道ネットワーク. . . . 21
4.3
都心部(
赤:
山手線) . . . . 21
4.4
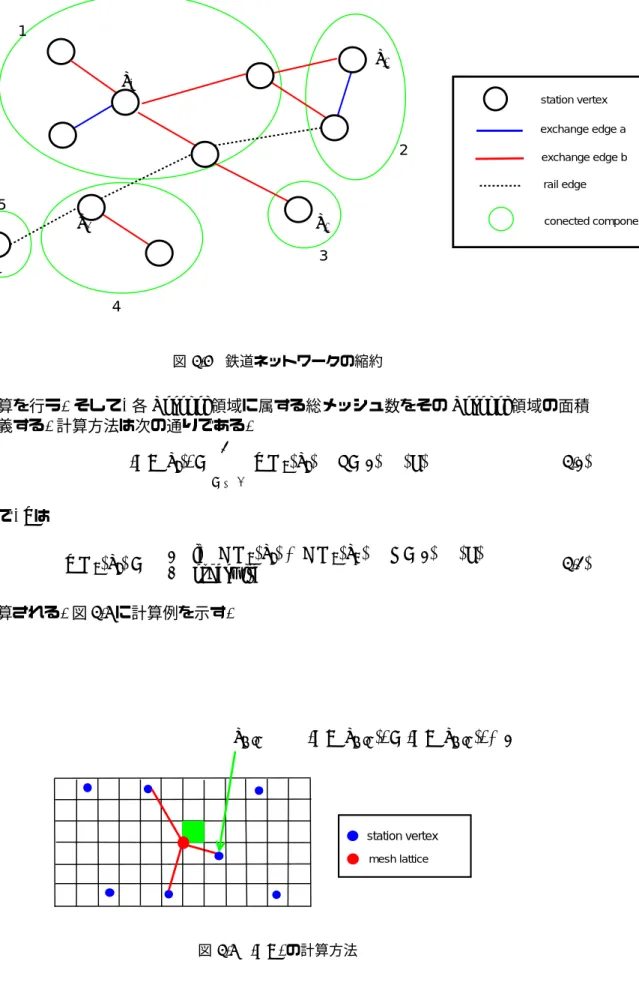
鉄道ネットワークの構造. . . . 22
4.5
鉄道ネットワークの縮約. . . . 23
4.6 | V R |
の計算方法. . . . 23
4.7
代表駅の位置. . . . 24
4.8
モデルによる居住地分布(
左)
と就業地分布(
右)
の立体図. . . . 25
4.9
モデルによる居住地分布(
左)
と就業地分布(
右)
の断面図. . . . 25
4.10 C A
を増加させたときの居住地分布(
左)
と就業地分布(
右)
の立体図. . . . 26
4.11 C A
を増加させたときの居住地分布(
左)
と就業地分布(
右)
の断面図. . . . 26
4.12 τ w
を減少させたときの居住地分布(
左)
と就業地分布(
右)
の立体図. . . . . 27
4.13 τ w
を減少させたときの居住地分布(
左)
と就業地分布(
右)
の断面図. . . . . 27
4.14 C R h
を増加させたときの居住地分布(
左)
と就業地分布(
右)
の立体図. . . . 28
4.15 C R h
を増加させたときの居住地分布(
左)
と就業地分布(
右)
の断面図. . . . 28
4.16 C d
を増加させたときの居住地分布(
左)
と就業地分布(
右)
の立体図. . . . . 29
4.17 C d
を増加させたときの居住地分布(
左)
と就業地分布(
右)
の断面図. . . . . 29
4.18 C d
を増加させ, C R h
を減少さたときの居住地分布(
左)
と就業地分布(
右)
の 立体図. . . . 30
4.19 C d
を増加させ, C R h
を減少させたときの居住地分布(
左)
と就業地分布(
右)
の断面図. . . . 30
4.20
実データの居住地分布(
左),
就業地分布(
右)
の立体図. . . . 31
4.21
実データの居住地分布(
左),
就業地分布(
右)
の断面図. . . . 31
4.22
モデルによる居住地分布(
左下),
就業地分布(
右下)
と実データの居住地分 布(
左上),
就業地分布(
右上),
相関係数0.54 . . . . 32
第 1 章 序論
人々の活動の大部分は移動を伴う
.
そのような活動を考えるとき,
距離という概念は重 要な要素となる.
距離により,
人々の活動を記述し,
その活動を距離の次元から分析するこ とは興味ある問題である.
本研究では特に,
人々の「住む」,
「通勤する」,
「働く」という 日常の活動に焦点を当てる.
人々は都市において
,
居住地・就業地を選択する.
そして,
居住地・就業地間を通勤する.
通勤距離は人々の選択に抵抗として働く.
就業地を固定した場合,
この抵抗の影響により,
人々の居住地は就業地の周辺地域に集中することになる.
しかし,
居住地には面積が必要 である.
そのため,
集中地域では,
土地の需要過剰となる.
このとき,
土地の価値(
地代)
と いう効果により,
人々の集中は抑えられることになる.
一方,
人々の居住地を固定した場 合,
就業地は居住地の周辺地域に存在することが望ましい.
しかし,
収穫逓増(increasing
returns)
の効果により,
就業地はある地域に集積1
することになる[6].
したがって,
距離,
地代
,
収穫逓増の概念により,
人々の選択を記述する必要がある.
距離と地代により
,
人々の立地を分析する研究は土地利用モデルとして,
特に地理経済 学や都市経済学で行われている[5].
古典的な土地利用モデルは,
都心の存在を前提した単 一中心的なモデルである.
この前提のもとで,
都心の周りの土地利用がどのようになるか を通勤と地代のトレードオフ問題として解析している.
しかし,
現実の大都市圏は単一中 心的ではない.
つまり,
都心,
副都心が存在する.
この都心,
副都心の存在を説明する試みとして
Fujita
のモデル[7]
がある.
このモデルは企業間に距離逓減的な外部経済を仮定し,
都心
,
副都心の存在を説明している.
重要な点は,
企業の集積を企業間のコミュニケーショ ン活動により説明している点である.
一方
,
人々の居住地・就業地の空間的分布と,
その間に発生する通勤交通の関係を工学 的に予測する研究も行われている.
交通計画の分野では,
ネットワーク利用者均衡モデル の分布配分統合モデルによる需要予測モデルがある.
このモデルは,
発生量,
集中量を固 定・変動とするかで,
片側制約,
両側制約問題に分けることができる.
片側制約問題として,
Oppenheim[8]
は目的地での混雑を考慮した分布配分統合モデルを提案している. D. Boyce
and L. Mattson[2]
は,
居住地の立地を住宅供給の問題と関連させ, bilevel programing
に より定式化している.
両側制約問題としては, Wilson
により提案されたエントロピーモデ ルがある.
また,
地域科学の分野では,
経済理論に基ずく空間相互作用モデルの研究が行わ れている[4].
ネットワーク利用者均衡モデルや空間相互作用モデルは居住地・就業地間の交通に焦点 を当てている
.
一方で,
これらのモデルと相補的な関係にある居住地・就業地を同時に決 定するモデルも存在する.
本間[3]
は(1)
居住地・就業地の通勤, (2)
就業地同士の取引, (3)
混雑による負の効果の3
つの点を考慮した上で居住地分布,
就業地分布の同時形成をモデ ル化している.
本間
[3]
のモデルは,
人々の選択行動に関して経済理論との整合性という点で課題がある.
そこで,
本研究では, Fujita
のモデル[7]
に基づき,
同時形成モデルの再構築を行う.
この モデルは地代と通勤のトレードオフによる居住地のドーナツ化現象の再現,
コミュニケー ション活動による就業地の集積の再現を試みる.
そのために,
このモデルを東京都市圏へ1
集積とは,
循環的論理による,
経済活動の集まり(
クラスター)
をあらわす言葉である.
適用する
.
その際,
通勤距離は鉄道ネットワークを用いた距離を利用することで東京都市 圏の特徴を取り入れる.
本論文の構成を以下に示す
.
第
2
章では,
本研究の基礎理論となるロジットモデルを述べる.
ロジットモデルにより,
人々の選択行動を確率的に記述することができる.
第
3
章では,
本研究で提案する職住分布の同時形成モデルを述べる.
このモデルは,
都 市における居住地分布,
就業地分布を同時に決定するモデルである.
このモデルを導くた めの準備として,
居住地と就業地のペアを表す量として,
職住同時分布を定義する.
また,
このモデルにより決定される居住地分布と就業地分布の意味を明確にするために,
均衡と いう概念を用いる.
そして,
同時形成の基礎となる方程式を述べる.
次に,
経済理論に基づ き,
人々の選択行動を記述する.
ここでは,
地代,
コミュニケーション活動による収益をも とに,
人々の効用関数を定めることが本題となる.
後半部では,
鉄道通勤を考慮した,
職住 分布の同時形成モデルを提案する.
このモデルは鉄道網を利用する通勤行動に着目し,
駅 周辺の職住活動により定まる効用関数を定める.
そして,
通勤における駅の利用を土地利 用の観点から再現する.
第
4
章では,
東京都市圏を対象にモデルを適用する.
現実の居住地分布,
就業地分布の再 現は難しいが,
本モデルは,
大都市の特徴である,
都心,
副都心の形成や,
居住地が都心の 周辺地域に分散するドーナツ化現象を再現することが可能であることを示す.
第
5
章では論文のまとめと今後の課題を述べる.
第 2 章 ロジットモデル
本研究では
,
人々の選択行動を表すためにロジットモデルを用いる.
人々の選択肢を効 用という尺度により計量化し,
人々の選択行動を数理的に表す.
効用は,
確定的でなく,
確 率的に変動すると考えることで,
より現実的な行動を記述することができると考えられる.
そのための基礎理論がランダム効用理論である.
ロジットモデルは効用の確率分布を特定 することにより,
人々の選択行動を確率的に表すモデルである.
2.1
節では,
人々の選択行動を確率的に表すための基礎理論となるランダム効用理論の概 要を説明する.
そして, 2.2
節では,
ランダム効用理論より導かれる,
ロジットモデルを説 明する.
ロジットモデルは人々の選択行動を確率的に表すことができ,
また,
その計算方法 も単純である.
なお,
本章で述べるロジットモデルの導出は土木学会[1]
を参考にした.
2.1
ランダム効用理論個人
n
の選択可能な選択肢集合をC n
とし,
その中に含まれている選択肢j
を選択する ことによって得られる効用をU j n
とする.
ランダム効用理論では,
この効用が確率的に変 動すると仮定する.
選択行動の分析において,
この仮定は次の理由で,
効用を非確率的とす る場合よりも妥当と考えられる.
第一に,
個人の行動は,
必ずしも常に合理的選択行動に厳 密に従うとは限らない.
正しい情報が得られたとしても,
それに対する知覚がそれぞれの 行動時点で同じでないかもしれない.
第二に,
情報の不完全性の問題があり,
利用可能な選 択肢の範囲やその特性について,
十分な情報がないケースも多い.
第三に,
具体的な理論の 適用の場面では,
効用に関する選択肢のもつ特性,
個人の社会経済属性,
その他の要因の中 には測定困難なものや,
複雑すぎて関数の中にとり入れにくいものなどが存在する.
さら に,
データについての測定誤差の問題などがある.
ランダム効用理論では
U i n
を確率変数とし,
これを変動しない部分(
確定項) V i n
と,
確 率的に変動する部分(
変動項) ² n i
に分け,
その線形性を仮定して次のように表す.
U i n = V i n + ² n i (2.1)
このとき
,
効用最大化理論によると,
個人n
が選択肢i
を選択する確率P i n
は, P i n = Prob { U i n ≥ U j n ; i 6 = j, j ∈ C n }
= Prob { V i n + ² n i ≥ V j n + ² n j ; i 6 = j, j ∈ C n } (2.2)
となる.
ただし, P i n
は0 ≤ P i n ≤ 1, X
i ∈ C n
P i n = 1
を満たす.
ここで
,
確定項と確率項の性質を述べる.
まず,
効用の測定スケールが移動し,
定数項V 0
が加わっても選択確率は変化しない
.
すなわち,
P i n = Prob { V i n + ² n i ≥ V j n + ² n j ; i 6 = j, j ∈ C n }
= Prob { V 0 + V i n + ² n i ≥ V 0 + V j n + ² n j ; i 6 = j, j ∈ C n } . (2.3)
また
,
測定のスケールをα(> 0)
倍しても,
選択確率は変化しない,
すなわち, P i n = Prob { V i n + ² n i ≥ V j n + ² n j ; i 6 = j, j ∈ C n }
= Prob { αV i n + α² n i ≥ αV j n + α² n j ; i 6 = j, j ∈ C n } . (2.4)
(2.3)
式の性質を用いれば,
確率項の平均値は一般にどのような定数をとっても構わないことになる
.
また(2.4)
式の性質より確率項の変動を任意のスケールα (> 0)
で固定することにより確定項のスケールも固定され
,
その中に含まれるパラメータのスケールが固定さ れたことになる.
選択肢が
3
以上の多項選択問題を選択肢が2
だけの単純な2
項選択問題として扱うこと ができる.
選択集合C n
の中から選択肢i
が選択される条件,
U i n ≥ U j n , i 6 = j, j ∈ C n (2.5)
は
,
次のように表すことができる.
U i n ≥ max
i 6 =j,j ∈ C n U j n (2.6)
この表現は
,
選択肢集合C n
の中のi
以外のすべての選択肢j
からあるひとつの合成選択 肢をつくり,
その効用をj
の中で最大の効用を与える選択肢の効用で代表していると考え ることができる.
もし, U i n
がこの合成選択肢の効用を上回れば,
選択肢i
が選ばれること になる.
すなわち,
P i n = Prob { U i n ≥ max U j n ; i 6 = j, j ∈ C n }
= Prob { V i n + ² n i ≥ max
i6=j, j ∈C n (V j n + ² n j ) } . (2.7)
以上の準備をした上で,
確率項²
にガンベル分布を仮定して,
ロジットモデルを導出する.
ここで,
個人n
の選択肢集合C n
に含まれる選択肢はJ n
個とし,
選択肢はj = 1, 2, . . . , J n
で表すことにする.
2.2
ロジットモデルガンベル分布は
,
次式のような分布関数で表されるものである.
F(²) = exp { exp[ − ² − λ(² − η)] } , λ > 0 (2.8) F(²)
を²
で微分すると,
確率密度関数は次のようになる.
f (²) = λ exp[ − ² − λ(² − η)] exp { exp[ − ² − λ(² − η)] } (2.9)
このようにガンベル分布が使われる理由は,
誤差項として一般的に使われる正規分布に 近似しており,
正規分布と比べて分析上の操作性が高いことにある.
また,
ランダム効用理 論における変動項には,
測定不能特性による効用分も含まれていると考えられることから,
効用最大化の行動の中で誤差項に含まれている効用に関してもその最大値を考慮してみる と,
最大値の分布を表わす極値分布を用いることは意味がある.
このパラメータ
(η, λ)
をもつガンベル分布は次のような性質をもっている. 1.
モードM (²) = η
2.
平均値E(²) = η + γ/λ
3.
分散V ar(²) = π 2 /6λ 2
4. ²
がパラメータ(η, λ)
のガンベル分布の確率変数の場合, α² + V
もパラメータ(αη + V, λ/α)
のガンベル分布となる.
ここでα(> 0), V
はともに定数である.
5. ² 1 , ² 2
がそれぞれパラメータ(η 1 , λ), (η 2 , λ)
をもつ独立のガンベル分布に従うとき,
² ∗ = ² 1 − ² 2
は次のようなロジステック分布となる.
F (² ∗ ) = 1
1 + exp[λ(η 1 − η 2 − ² ∗ )] (2.10) 6. (² 1 , ² 2 , . . . , ² J )
がそれぞれパラメータ(η 1 , λ), (η 2 , λ), . . . , (η J , λ)
をもつJ
個の独立 のガンベル分布に従うとき, max(² 1 , ² 2 , . . . , ² J )
もパラメータ(log P J j=1 /λ, λ)
のガ ンベル分布となる.
ロジットモデルは
,
変動項² n j , j = 1, 2, . . . , J n
が独立の同一なガンベル分布に従うと仮定 したときの,
個人の選択確率を計算することができる.
ガンベル分布のパラメータを(0, λ)
と便宜上仮定すると,
性質4.
よりU j n = V j n + ² n j
はパラメータ(V j n , λ)
のガンベル分布と なる.
さらに選択肢1
を選ぶ確率は次のようになる.
P 1 n = Prob { U 1 n ≥ U j n ; j = 2, 3, . . . , J n }
= Prob { V 1 n + ² n 1 ≥ V j n + ² n j ; j = 2, 3, . . . , J n }
= Prob { V 1 n + ² n 1 ≥ max
j=2,3,...,J n V j n + ² n j ) } . (2.11)
ここで, ˆ U n
をU ˆ n = max
j=2,3,...,J n (V j n + ² n j ) (2.12)
と定義すると, ˆ U n
は性質6.
より(log P J j=2 n exp λV j n /λ, λ)
のガンベル分布となる.
さらに
, ˆ U n = ˆ V n + ˆ ² n , ˆ V n = P J j=2 n exp λV j n /λ
とおくと, ˆ ² n
はパラメータ(0, λ)
のガン ベル分布となる.
したがって
,
P 1 n = Prob { V 1 n + ² n 1 ≥ V ˆ n + ˆ ² n }
= Prob { ( ˆ V n + ˆ ² n ) − (V 1 n + ² n 1 ) ≤ 0 } (2.13)
ここで, 2
つの独立したガンベル分布の確率変数の差がロジステック分布となるという性 質5.
を用いると,
P 1 n = 1
1 + exp[λ( ˆ V n − V 1 n )]
= exp(λV 1 n ) exp[λ(V 1 n + ˆ V n )]
= exp(λV 1 n )
exp { λ[V 1 n + exp(log P J j=2 n exp λV j n )] }
= exp(λV 1 n ) P J n
j=1 exp(λV j n ) (2.14)
となる
. (2.14)
式が多項ロジットモデルである.
ロジットモデルを一般的な形で示す
.
なお,
パラメータ(η, λ)
をもつガンベル分布を(η, λ)-
ガンベル分布と表す.
ある個人の選択肢の集合はJ
個の要素からなるものとし,
これを
C = { 1, 2, . . . , J } (2.15)
で表すものとする
.
そして,
ある個人の選択肢i
を選択する効用がU i = V i + ² i (2.16)
と表されるとし
, ² 1 , ² 2 , . . . , ² J
が同一の(0, λ)-
ガンベル分布に従うとする.
このとき,
選択 肢i
を選択する確率P i
はP i = exp(λV i ) P J
j=1 exp(λV j ) (2.17)
となる
.
第 3 章 職住分布の同時形成
本研究では
,
都市に存在する「人」は,
居住地と就業地のペアを唯一もつ「労働者」であ ると想定し,
居住地と就業地の総数は総労働者数N
であるとする.
そして「住」とは労働 者の居住地,
「職」とは労働者の就業地を指すものとし,
通勤交通は「住」を起点,
「職」を終点とする交通をいうものとする
.
ここで
,
都市の構成要素を表す言葉を定義する.
まず,
居住地分布,
就業地分布のペアを 職住分布と呼ぶ.
職住分布の領域として, 2
次元に広がる空間を考える.
これを2
次元ユー クリッド空間S
で表す.
空間S
の「距離」はユークリッド距離d(p, q) (p, q ∈ S)
により 定義される.
3.1
節では職住分布の同時形成モデルを述べる.
居住地と就業地のペアを表す量として,
職住同時分布を定義する.
次に,
労働者の職住選択行動の前提を述べる.
この前提により,
安定な職住分布として,
均衡という概念を定義する.
そして,
均衡職住分布を与える関数方 程式を導出する. 3.2
節では,
ロジットモデルの効用関数を都市経済学の土地利用モデルに 基づき定める.
地代と通勤費用のトレードオフ,
コミュニケーション活動による就業地の 収益を効用関数に取り入れた定式化を行う. 3.3
節では,
鉄道網による通勤行動に着目し,
鉄道ネットワーク上の通勤距離を用いた労働者の職住選択行動を定める.
そして, 3.4
節で は,
鉄道ネットワークを用いた職住分布の同時形成モデルとその解法を述べる.
3.1
職住分布の同時形成モデル労働者の職住選択行動をランダム効用最大化という形で定式化する
.
そして,
ロジット モデルを用いて,
労働者の居住地,
就業地の選択確率を計算する.
この選択確率により,
都 市における,
居住地と就業地のペアの量を確率的に計算することができる.
このペアの量 を表すために職住同時分布を定義する.
職住分布は職住同時分布の周辺分布として与えられる
.
さらに,
ランダム効用関数の確 定項を職住分布の関数として定めることにより,
職住分布に関する関数方程式を導くこと ができる.
労働者の選択行動に前提を定めることにより,
この関数方程式の解として与え られる職住分布は均衡状態を表している.
3.1.1
職住分布職住同時分布は職住間の通勤交通量である
[10].
これは,
居住地,
就業地のペアを表す量 と考えられる.
都市の空間S
で,
居住地p h ∈ S
を起点とし,
就業地p w ∈ S
を終点とする 通勤交通量をf hw (p h , p w )
と表す.
この密度関数f hw : S × S → R + (3.1)
を職住同時分布と呼ぶ
. (3.1)
式の周辺分布として,
居住地分布f h : S → R + ,
就業地分布f w : S → R +
はf h (p h ) = Z
S
f hw (p h , p w )dp w , (3.2)
f w (p w ) = Z
S
f hw (p h , p w )dp h (3.3)
と与えられる
.
都市に居住する人がすべて一定の労働時間で働くとするならば,
居住地分 布f h
は夜間人口を表し,
就業地分布f w
は昼間人口を表す.
3.1.2
職住選択行動の前提本研究では
,
労働者の職住選択行動に関して,
以下の前提をおく.
(a)
労働者の職住選択は所与の効用関数を最大化する形で合理的に行われる. (b)
すべての労働者の職住選択は同時に行われる.
(c)
労働者は他の労働者の選択を考慮しない.
すべての労働者が前提
(a)
に基づき居住地,
就業地を選択する.
このとき,
居住地,
就業 地はある地域に集中する.
なぜなら,
ある労働者にとって効用の高い居住地・就業地はすべ ての労働者にとって効用の高い居住地・就業地となるからである.
前提(b) , (c)
により,
労働者はそのような集中が起こることを考慮しない.
しかし,
居住地と就業地の集中はそ の地域に地代の上昇や混雑度などの非効用を生じさせる.
その結果,
労働者には,
他の居住 地,
就業地を選択する動機が生じる.
都市において,
そのような職住分布は安定ではない.
そこで,
労働者の職住選択行動の均衡状態を表す居住地分布,
就業地分布を示すことが有 用となる.
定義
3.1
すべての労働者が,
与えられた職住分布のもとで,
他の居住地,
就業地を選択す る動機がなくなるとき,
その職住分布は均衡状態であると定義し,
このときの職住分布を 均衡職住分布と呼ぶ.
3.1.3
基本モデル労働者の職住選択行動は
,
ランダム効用関数U (p h , p w ) = V (p h , p w , f h , f w ) + ² (3.4)
を最大化するという形で定式化される.
ここで, ²
は(0, λ)-
ガンベル分布にしたがうランダ ム効用の変動項である. V
は,
所与の居住地分布f h ,
就業地分布f w
の関数として定義され るランダム効用の確定項である. (3.4)
式より,
ロジットモデルを用いて,
労働者の職住選 択行動に基づく職住同時分布を求めることができる.
居住地p h ,
就業地p w
を選択する確 率はロジットモデルよりp(p h , p w ) = exp[λV (p h , p w , f h , f w )]
R
S
R
S exp[λV (p, q, f h , f w )]dpdq (3.5)
となる. f hw (p h , p w )
は選択確率p(p h , p w )
に所与の総労働者数N
を乗じてf hw (p h , p w ) = N exp[λV (p h , p w , f h , f w )]
R
S
R
S exp[λV (p, q, f h , f w )]dpdq (3.6)
となる.
(3.6)
式より, (3.2)
式, (3.3)
式と同様に,
職住分布( ˆ f h , f ˆ w )
はf ˆ h (p h ) =
Z
S
f hw (p h , p w )dp w , (3.7)
f ˆ w (p w ) = Z
S
f hw (p h , p w )dp h (3.8)
と計算できる
. ( ˆ f h , f ˆ w )
は,
与えられた職住分布(f h , f w )
のもとで,
職住選択行動(3.4)
に 基づき労働者が行動をしたときの結果を表している. (f h , f w )
が( ˆ f h , f ˆ w )
と異なるとき,
職住分布(f h , f w )
は,
労働者に他の選択をする動機を生じさせるものであるといえる.
定 義3.1
により, (f h , f w )
が均衡状態となるためには, (f h , f w )
と( ˆ f h , f ˆ w )
は等しくなること が必要である.
したがって,
均衡職住分布(f h ∗ , f w ∗ )
は次の関数方程式(3.9)
f h (p h ) = Z
S
f hw (p h , p w )dp w f w (p w ) =
Z
S
f hw (p h , p w )dp h (3.9)
f hw (p h , p w ) = N exp[λV (p h , p w , f h , f w )]
R
S
R
S exp[λV (p, q, f h , f w )]dpdq
の解として与えられる.
3.2
土地利用モデルに基づく労働者の職住選択行動都市経済学の土地利用モデルに基づく労働者の職住選択行動を定式化する
.
都市の土地 利用をミクロ経済の枠組みで分析するモデルが,
都市経済学の土地利用モデルである.
土 地利用モデルの立地行動を単純化することにより,
労働者の職住選択行動を定式化する.
3.2.1
節では, Fujita and Thisse[7]
により定式化された労働者と企業の立地を説明する.
この
Fujita and Thisse[7]
のモデルは,
企業間のコミュニケーションによる外部経済を仮定することで
,
都市の形成を労働者と企業の立地から分析している. 3.2.2
節では,
労働者と 企業の立地を単純化することにより,
労働者の職住選択行動をランダム効用を最大化する 形で表す.
3.2.1
労働者と企業の立地行動都市の空間
S
において,
労働者は居住地と就業地,
企業は産業地を選択する.
労働者の 居住地・就業地選択行動,
企業の産業地選択行動を立地行動と呼ぶ.
ここで,
地点p h ∈ S
を居住地, p w ∈ S
を就業地と選択するときの通勤費用はT (p h , p w )
とする.
労働者と企業 の立地行動は土地市場と労働市場において相互に作用する.
労働者は賃金を得るために就 業地を選択し,
企業に雇われる.
企業は生産活動を行うために産業地を選択し,
雇用者を雇 い,
賃金を支払う.
この労働市場の空間的な需要と供給の関係により,
賃金は地点p ∈ S
の 関数W (p)
として定まる.
また,
労働者と企業は,
土地を使用するために,
土地市場で労働 者と企業の土地の購入競争が起こる.
この競争によって地代は地点p ∈ S
の関数R(p)
と して定まる.
労働者の効用関数を
U (z, s)
で表す. z
は土地以外の財(
合成財)
の量, s
は土地の量であ る.
簡単のために労働者の土地の量はS h
と固定する.
また,
合成財は単位価格1
で購入で きるものとする.
労働者は効用関数U (z, s)
を予算制約z + R(p h )S h + T (p h , p w ) = W (p w ) (3.10)
のもとで最大化する形に定式化される.
さらに,
土地のサイズS h
を固定したので,
労働者 の立地行動は合成財の消費量z(p h , p w ) = W (p w ) − R(p h )S h − T (p h , p w ) (3.11)
を最大化する形に定式化される
.
企業の立地行動は生産活動による利益を最大化するものとして定式化される
.
ここで,
企業の生産活動に関して以下の前提をおく.
(a)
生産活動には土地S w
と労働力L f
を使用する. (b)
コミュニケーション活動により企業の収益は定まる.
(c)
コミュニケーション活動はface-to-face
の活動である.
また,
この活動には費用が 伴う.
(d)
企業は都市に存在するすべての企業とコミュニケーション活動を行う.
ここで
,
企業p
は地点p ∈ S
で活動する企業を指すものとする.
企業p
から企業q
への コミュニケーション活動量をφ(p, q)
とする.
前提(b)
より, φ(p, q)
の関数F [φ(p, q)]
で 収益が与えられるとする.
そして前提(d)
より, m(q)
を地点q ∈ S
の企業の密度としたと きの企業p
の収益関数pQ(p)
は,
pQ(p) = Z
S { F[φ(p, q)] } m(q)dq (3.12)
となる
.
生産活動には,
前提(a)
により地代と労働賃金の費用と,
前提(c)
によりコミュニ ケーション活動の費用がかかる.
地代と労働賃金の費用はR(p)S w + W (p)L f (3.13)
となる
.
企業p
から企業q
への単位コミュニケーション活動において,
企業p
はc 1 (p, q)
の費用を負担する.
また,
企業q
は費用c 2
を負担する. c 1 (p, q)
は移動による費用, c 2
はコ ミュニケーションに対応するための費用である.
企業p
のコミュニケーション活動による費用は
Z
S
[c 1 (p, q)φ(p, q) + c 2 φ(q, p)]m(q)dq (3.14)
となる.
以上より,
企業p
の利益関数π(p)
はπ(p) = pQ(p) − R S [c 1 (p, q)φ(p, q) + c 2 φ(q, p)]m(q)dq − R(p)S w − W (p)L f
= Z
S { F [φ(p, q)] − [c 1 (p, q)φ(p, q) + c 2 φ(q, p)] } m(q)dq − R(p)S w − W (p)L f (3.15)
となる.
各企業は
,
企業の空間分布m
が与えられたとき,
利益を最大化する産業地p
とコミュニ ケーション活動量を選択する.
(3.15)
式のF [φ(p, q)] − c 1 (p, q)φ(p, q)
を最大化するφ(p, q)
を選択することにより,
企 業p
から企業q
への最適なコミュニケーション活動量φ ∗ (p, q)
を,
企業の空間分布に関係 なく決定することができる. c 1 (p, q) = c 1 (q, p)
ならば,
最適なコミュニケーション活動量 はすべての企業のペアで等しくなる.
すなわち,
企業p,
企業q
のペアで定まる最適なコ ミュニケーション活動量はφ ∗ (p, q) = φ ∗ (q, p)
となる.
(3.15)
式をφ ∗
を用いて表す.
ローカルアクセスビリティa(p, q)
をa(p, q) = F[φ ∗ (p, q)] − [c 1 (p, q) + c 2 ]φ(p, q) ∗ (3.16)
と定義し,
集約アクセスビリティA(p)
をA(p) = Z
S
a(p, q)m(q)dq (3.17)
と定義すると
,
利益関数π(p)
はπ(p) = A(p) − R(p)S w − W (p)L f (3.18)
となる
.
ローカルアクセスビリティa(p, q)
は企業p
が地点q
で活動する企業とのコミュニ ケーション活動による得られる収益,
集約アクセスビリティA(p)
は企業p
が行うコミュニ ケーション活動により得られる収益を集約したものである.
Fujita and Thisse[7]
では,
関数F
としてエントロピータイプを提案している. F [φ] =
( − φ log φ for φ ≤ 1/e
1/e for φ > 1/e (3.19)
図
3.1
にF (φ)
のグラフを示す. F(φ)
はコミュニケーション活動量φ
に関する増加関数 である.
このとき, F [φ] − c 1 φ + c 2
を最大化するφ ∗
はexp( − c 1 − 1)
となる.
図3.2
は企 業が行うコミュニケーション活動が,
移動費用c 1
とともに指数的に減少することを表して いる.
0 0.1 0.2 0.3 0.4 0.5
0 0.2 0.4 0.6 0.8 1
F(φ)
φ
図
3.1 F (φ)
のグラフ0 0.1 0.2 0.3 0.4 0.5
0 1 2 3 4 5
φ*
c1
図
3.2 φ ∗
のグラフ ローカルアクセスビリティa(p, q)
は, (3.16)
式よりa(p, q) = F [φ ∗ (p, q)] − c 1 (p, q)φ ∗ (p, q) − c 2
= 1 − c 2
e exp[ − c 1 (p, q)] (3.20)
となる
.
ここで,
単位直線距離当たりのコミュニケーション活動費用をτ w
とすると, c 1 (p, q) = τ w d(p, q)
となる. (1 − c 2 )/e
をC A
とすると,
集約アクセスビリティA(p)
は(3.17)
式より,
A(p) = C A
Z
exp[ − τ w d(p, q)]m(q)dq (3.21)
となる.
集約アクセスビリティ
A(p)
の性質を一次元の空間X
で説明する. X, m(x)
が与えられ たとき, (3.21)
式は,
A(x) = C A Z
X
exp( − τ w | x − y | )m(y)dy (3.22)
となる
.
この(3.22)
式における被積分関数は,
地点x
から,
地点y
への距離により定まる重み関数
exp( − τ w | x − y | )
を,
その地点の企業数m(y)
に掛けあわせるという形になってい る.
そして, A(x)
は,
空間上のすべての地点y
について足し合わせることで,
地点x
の収益 を表している.
重み関数は地点間の距離に関して
,
指数的に減少するコミュニケーション活動量を表し ている.
そして,
その減衰率がτ w
で表される.
地点x ∈ X
を固定すると重み関数はその地 点を中心に左右に指数的に減少する関数として表現することができる.
図3.3
に, x = 0
と したときの重み関数exp( − τ w | y | )
を示す(τ w = 0.1, τ w = 0.5).
この図は,
地点0 ∈ X
の企 業が行うコミュニケーション活動を空間的に表していると解釈することができる.
0 0.2 0.4 0.6 0.8 1 1.2
-10 -5 0 5 10
exp(−τ|y|)
y
0.1 0.5
図
![図 3.1 に F (φ) のグラフを示す . F(φ) はコミュニケーション活動量 φ に関する増加関数 である . このとき , F [φ] − c 1 φ + c 2 を最大化する φ ∗ は exp( − c 1 − 1) となる](https://thumb-ap.123doks.com/thumbv2/123deta/7158736.2363413/15.892.308.570.474.985/φグラフ示すFコミュニケーションに関する−+∗.webp)