DEIM Forum 2016 G6-5
ページの階層構造に基づく具体度・詳細度を考慮した手順情報の検索
下野
普也
†山本
岳洋
††田中
克己
†††
京都大学工学部情報学科
〒 606–8501 京都府京都市左京区吉田本町
††
京都大学大学院情報学研究科
〒 606–8501 京都府京都市左京区吉田本町
E-mail:
†{
shimono,tyamamot,tanaka
}
@dl.kuis.kyoto-u.ac.jp
あらまし 「ギターを上達する」「ダイエットする」「美味しいトーストを焼く」といった行動をとりたいと思った際,
その行動を達成するための手順や方法を検索することがしばしば必要になる.このような手順や方法の検索を本研究
ではハウツー検索と呼ぶ.現在のハウツー検索は,通常の検索エンジンを用いて行うことができるが,検索結果とし
て得られた手順ページの具体度が揃っていないという問題がある.本研究では,手順ページの情報源である wikiHow
を対象として,手順ページの具体度を計算する手法を提案する.提案手法では,手順ページの具体度を,複数のステッ
プと呼ばれるサブ手順の具体度から求める.その際に,ステップ間の詳細化関係という関係を導入し,詳細化関係と
具体度を再帰的に求める手法を提案する.実験の結果,詳細化関係を再帰的に求めることで,詳細化関係の精度は,F
値で 0.188 となり,また,詳細関係の精度向上に合わせて,具体度による手順ページランキングの精度も 0.84 に向上
した.
キーワード
1.
は じ め に
Web検索エンジンが発達するにつれて,ある目的を達成する ための方法や手順を検索することが広く行われるようになって きている.本研究では,このような方法や手順のことを記述し たWebページを手順ページ,その構成要素をステップと呼び, 手順ページの検索をハウツー検索と呼ぶ.ハウツー検索の例と して,「ギターを上達する方法を探す」「ダイエットする方法を探 す」「美味しいトーストを焼くための手順を探す」などがあげら れる.中村らが2006年に行った,1,000人を対象としたWeb 検索の目的を調査したアンケートによると,1,000人中575人 が「方法・手段」を探すためによくWeb検索を利用すると回 答している[?].また,近年ではwikiHow(注 1) やnanapi(注 2) に 代表される,手順ページをまとめたウェブサイトも登場し利用 されている.このように,ハウツー検索は人々にとって重要な 検索の一つとなっていると考えられる. しかし,一般的なウェブ検索と異なり,現状のハウツー検索 においては,いくつか問題点が存在すると考えている.たとえ ば,人々が自由に手順ページをまとめて公開できるwikiHowで は,ユーザは検索クエリを投入することでクエリと関連度の高 い手順ページが検索結果として得られるが,以下に挙げる問題 点が存在する. • 検索結果の具体性が揃っていない点: 例えば,ギターの上 達に関する手順ページには,「ギターの練習方法」のような, 曖昧なステップしか含まれていないものもあれば,「ギター ソロの音の取り方」のような,具体的な手順ページも存在 する.どのような手順ページをユーザが求めるかは,ユー (注 1):http://www.wikihow.com/ (注 2):https://nanapi.jp/ ザの知識に依存すると考えられる.しかし,既存のランキ ングはこうした手順ページの具体性を考慮していないため, 検索結果にこれらの異なるユーザ向けのページが混在して おり,ユーザが欲しい手順ページを手に入れるに苦労する ことが多い. • あるステップのより詳細なステップの検索が困難な点: 例 えば,「コードの練習方法」というステップを閲覧している 時に,そのステップの記述が曖昧であると「Fコードの練 習方法」や「コードの簡単な覚え方」といった,さらに詳 細な情報が欲しくなるときがある.しかし,現状ではユー ザはこうしたより詳細なステップを得るためには,その都 度検索する必要がある.さらに,こうした詳細なステップ は手順ページの一部に記載されていることもりあり,手順 ページのタイトルからでは発見が難しい場合がある. 前者の問題点を解決するため,本研究では手順ページの具体 性に着目し,手順ページの具体度を計算する手法を提案する. 手順ページの具体性とは,「その情報だけを見て,ユーザが具体 的に何をすればよいかがわかるか」を表しており,これを表す 尺度を本研究では具体度と定義する.具体度が高い手順ページ は,そのページを見れば何をすればわかるが,ある事柄に特化 したページが多く,予備知識がないとこれを理解することがで きない事もあり,専門的であると言える.逆に具体度が低い手 順ページは,そのページだけを見ても具体的に何をすればよい かはわからないが,物事の全体を見渡したりするのに有用であ る場合が多く,ある事柄に関して知識を有さない初心者向けで あると言える. 具体度による手順ページのランキングが可能となれば,ユー ザの知識に合わせて,ユーザが求める具体度の手順ページを検 索することが容易になると考えられる. また,後者の問題点を解決するため,ステップ間の詳細化関係を推定する手法を提案する.具体度の低いステップに対して, それに含まれる情報が他の手順ページ中の複数のステップに よって,より詳細な説明が為されている場合がある.このよう な手順ページの部分集合は,元のステップを詳細化していると 定義し,この手順間の関係を詳細化関係と呼ぶ.手順間の詳細 化関係を求めることで,より具体的な情報をユーザに提示する ことが可能である. 本研究では,手順ページの具体度およびステップ間の詳細化 関係を求めるため,両者を相互再帰的に求める手法を提案する. 本研究では,手順ページの具体度とステップ間の詳細化関係は 互いに依存していると考える.手順ページの具体度はそこに含 まれるステップの具体度によって決まる.ここで,ある具体的 なステップを詳細化しているステップ集合は,元のステップよ りも高い具体度を持つと考えられる.また,あるステップ集合 が別のステップを詳細化するためには,そのステップ集合は詳 細化されるステップよりも具体度は高い必要がある.このよう に,具体度と詳細化関係は互いに依存しており,両者を再帰的 に計算することで,精度良く両者を計算することができると考 えられる. 提案手法はまず,与えられた手順ページ集合から,手順間の 粗い詳細化関係を求める.具体的には,ステップ間の順序関係 とテキストの類似性のみに基づき,再現率を重視した詳細化関 係を求める.次に,得られた詳細化関係を基に,ステップ間の 詳細化関係を表した詳細化関係グラフを作成し,グラフの深さ を基準とするスコア付与アルゴリズムを適用することでステッ プの具体度を求める.その後,得られたステップの具体度を基 に,詳細化関係グラフ中の不要なエッジを発見し,エッジを除 去することで詳細化関係グラフを修正し,再度ステップの具体 度を求める.このプロセスを繰り返しグラフを修正していく ことで,各ステップの具体度および詳細化関係を得ることがで きる. 提案手法により,「ギターの上達」に関するwikiHow中の16 ページ,304ステップに対して詳細化関係と手順ページの具体度 を求めたところ,詳細化関係の精度は,最大でF値が0.188と なり,その時の手順ページの具体度によるランキングはnDCG で0.84となった.また,これらの評価値は,両者とも粗い詳細 化関係から求めた評価値よりも高くなっており,提案手法によ る詳細化関係の精度の向上と,精度の良い詳細化関係を抽出す れば良い具体度が求まることが確認された. 本稿の構成は以下の通りである.2節ではハウツー検索に関 する研究について述べる.3節では,本研究で求める具体度と 詳細化関係について述べ,両者の関係を整理する.4節では提 案手法について詳細に述べる.5節で,実験と評価について述 べる.6節で,まとめと今後の課題について述べる.
2.
関 連 研 究
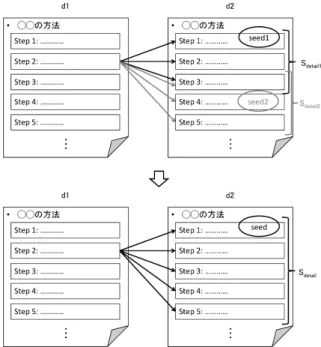
近年,さまざまな研究者がハウツー検索に関連した研究を 行っている.野中らは,手順ページを見やすさでランキングす る手法を提案している[?].野中らは,Web上に存在する,ある 方法を説明するページは,各手順をまとめたリスト形式で記述 されることが多いことに着目し,手順ページをそこで記述され るステップの系列として表現している.本研究で扱うwikiHow においても,1つのページがステップと呼ばれる複数の手順で 記述されており,我々も野本らと同様に,手順ページは複数の ステップで構成されると考える.さらに,湯本らは手順ページ を階層化する手法を提案している[?].湯本らは「肉じゃがの作 り方」といったレシピに関する情報を手順ページとみなし,手 順ページの詳しさに着目し,同じ事柄について記述している手 順ページを階層構造化している.本研究と湯本らの研究は,手 順ページの階層化に着目するという点で目的が同じである.一 方で,湯本らの研究は手順ページと手順ページ間の関係に対し て階層関係を発見しているのに対して,我々は手順ページに含 まれるステップと,別の手順ページに出現するステップ集合間 の関係に対して,詳細化関係を求めているという点で彼らの研 究とは異なる. また,今回は手順情報の知識源を対象として研究を行うが, Web上から手順情報を抽出する研究も活発に行われている.湯 本らは,手順表現や経過表現およびページの構造を用いて手順 情報の掲載部分を抽出する手法を提案している[?].さらに同氏 は,手順情報を動作と対象のペアでモデル化し,文末表現に注 目して手順を説明する文のみを抽出しそれらの文に対して,動 作と対象を抽出する手法も提案している[?]. 北口らは,Web上でのハウツー検索を支援するためのクエリ 変換手法を提案している[?].北口らは,「ゴルフ 上達」のよう な,名詞と動作で表されるクエリを対象にし,「スライス 修正」 や「レッスン 受講」のようなより具体的なクエリをWeb検索 結果から抽出する.また,Yamamotoらは検索連動型広告を用 いて,与えられたクエリのサブタスクを表すクエリをクエリの クラスタリングによって求める手法を提案している[?].こうし た研究は,ハウツー検索におけるクエリを対象とした研究であ り,我々の研究はハウツー検索における文書を扱った研究であ るといえる.ハウツー検索における文書のランキングを扱った 研究として,加藤らの研究がある[?].加藤らは,Web検索エ ンジンを用いた手順ページの検索を対象にし,タスクの汎化と 特化関係を利用することでより適合する文書を上位にランキン グする手法を提案している.タスクの汎化と特化関係をランキ ングに用いる加藤らの考え方は,本研究におけるステップ間の 類似度を考える際に有用となると考えられる. また,グラフの深さに応じて具体度を計算する方法には田中 らの手法があげられる[?].田中らは,Webページの具体度を 評価するにあたって,WordNetにおいて下位語が多く存在す る語は曖昧であるという尺度を設けていた.これは本研究にお ける具体度の低いステップの判定基準と類似している.さらに クエリからis-a関係の木を作成し,ノード間の関係を考慮して 検索意図を階層的に分類するYinらの手法とも類似する[?]. その他にも,リンクされる頻度を考慮するという点では関 連研究に白川らの研究が挙げられる[?].白川らは,Wikipedia データ上でリンクされる頻度を考慮することによって異義語の 判定を行うという手法を提案しており,この手法は湯本らの手 順ページ階層化[?]でも応用されている.図 1 手順ページとステップの関係
3.
概 念 説 明
3. 1 ステップと手順ページ まず本研究で扱う手順ページとステップについて説明する. 手順情報はそれ自体が手順のリストで構成されていると考え られる[?].そこで本研究では,ある目的を達成するための一連 の行動をまとめた文書を手順ページと呼び.手順ページに含ま れる,1つ1つの手順のことをステップと呼ぶ.本研究では,手 順ページはそのページに含まれるステップの集合として表され る(図??).このような構造を持つ文書は,レシピやハウツー情 報を扱ったサイトに多く存在し,本研究が対象とするwikiHow も同様の構造を持っている. またステップは手順の概略を表した「タイトル」と,手順の 内容を記述した「本文」,を含む要素で構成されていることが 多い.本研究で扱うwikiHowについても,ステップはタイト ルと本文から構成され,ステップ間の類似度を計算する際に用 いられる. 3. 2 具 体 度 本研究では,具体度とは,あるステップや手順ページに対し て付与される,その情報がどれだけ具体的かを表したスコアと 定義する.ここで,あるステップまた手順ページが具体的であ るとは,「その情報だけを見て,ユーザが具体的にどのような 行動を取れば良いかがわかる」として定義される.たとえば, ギターの上達に関するステップとして,“ギターのコード練習” というステップと“Cコードの練習”というステップがあった 場合,後者のステップの方が,ユーザは具体的に何をすれば良 いのか分かる場合が多く,従って,高い具体度となると考えら れる. また,本研究では,手順ページの具体度は,そこに含まれる ステップの具体度によって定まると考える.従って,ある手順 ページdiの具体度を求めるためには,手順ページに含まれる 各ステップsij∈ diの具体度を求めれば良い. 3. 3 詳細化関係 あるステップsiと,あるステップ集合Sj={sj1, . . . sjk}が 与えられたとき,ステップsiで記述されている方法の一部もし くは全てが,ステップ集合Sjでより詳細に記述されているとき, 「siとSjは詳細化関係にある」と定義し,「Sjはsiを詳細化して いる」と記述する.例えば,si=“ギターのコード練習”に対し て,ステップ集合Sj={“Fコードの練習”, “Gコードの練習”} は,Sjはsiを詳細化していると言える. この詳細化関係を手順ページ集合から抽出することができれ ば,例えばユーザが“ギターのコード練習”に関するステップ を閲覧しているときに,システムが自動的に“Fコードの練習” と“Gコードの練習”に関するステップを推薦することが可能 となる. また,詳細化関係にあるステップ集合は要素のステップ同士 が類似していると考えられる.さらに,互いに類似するステッ プは同一手順ページ中では散在せずに,連続して偏在している と考えられるため,あるステップは,他の手順ページ中の連続 したステップの集合により詳細化されている,と定義する. 3. 4 具体度と詳細化関係の相互依存性 具体度と詳細化関係を求めるため,本研究ではそれぞれ以下 の様な仮定をおいた. • 具体度が高いステップは,具体的なステップから多く詳細 化されている • あるステップ集合Sjがステップsiを詳細化するとき,Sj 中の各ステップsjl∈ Sjはsiよりも具体的である. 前者の仮定は,ステップの具体度を求めるためにはステップ間 の詳細化関係を,また,後者の仮定は,ステップ間の詳細化関 係を求めるためにはステップの具体度を必要としていることを 表している.従って,本研究では具体度と詳細化関係を再帰的 に求める手法を提案する.4.
提 案 手 法
本研究では,具体度と詳細化関係を再帰的に計算する手法を 提案する.まず,提案手法の流れについて説明し,その後詳細 について述べる. 4. 1 提案手法の概要 提案手法の基本的な考え方は,まず,詳細化関係集合を簡潔 な手法で求め,その後得られた詳細化関係に基づき各ステップ の具体度を計算することで,はじめに得た詳細化関係から不要 なものを削除するという考えである.これは,ステップの具体 度を,詳細関係を利用せずに直接求めることは困難であるが, 詳細関係集合は具体度を直接用いなくとも,テキスト間の類似 度を利用することである程度の精度で求めることができるので はないかという考えに基づいている. しかし,単なるテキスト類似度だけでは,どちらがより具体 的なステップかが分からないため,本来詳細化関係ではないス テップ間についても,詳細化関係であると判定してしまう可能 性がある.つまり,ステップ間のテキスト類似度を用いること で,再現率は高いが適合率の低い詳細化関係集合を得ることが できる.このようにして求めた精度の低い詳細化関係集合を用 いて,各ステップの具体度を計算することで,本来詳細化関係 と判定すべきではない関係が発見することができ,適合率を向 上することができると考えられる. 提案手法では以下のような流れに従い具体度と詳細化関係を 求める.(1) システムは手順ページ集合D = {d1, d2, . . . , dn}を受け 取る.ここで,nはシステムに入力される手順ページ数を 表す. (2) すべての手順ページdi∈ Dに含まれる各ステップsにつ いて,詳細化関係集合を発見する.全てのステップs∈ S について得られた詳細化関係集合をマージすることで,詳 細化関係集合R0 ={r 1, . . . rm}を得る.ここで,Sは手 順ページ集合Dに含まれる全ステップ集合,mは得られ た詳細化関係の数を表す. (3) 得られた詳細化関係集合R0に基づき,詳細化関係木集合 TR0={tR10, . . . tR 0 n }を構築し,この木に基づき,各ステッ プsの仮具体度C0 s(s)を計算する. (4) ステップの仮具体度を基に,各詳細化関係ri ∈ R0の詳 細度MR0(ri)を求める.minri∈R0M R0 (ri)が閾値以下な ら,詳細化関係集合R0からriを除去することでR1を得 る.更新された詳細化関係R1から構築された木TR1を元 に,再び各ステップの具体度を計算する. (5) 3. 4. を削除するべき詳細化関係riが無くなるまで繰り返 し実行することで,詳細化関係集合R∗を得る. (6) R∗から構築された詳細化関係木集合TR∗ から,各ステッ プsの具体度Cs∗を求める. (7) 各ステップの具体度Cs∗に基づき,手順ページd∈ Dの具 体度Cd(d)を計算する. 以降,それぞれの工程について詳しく述べる. 4. 2 シード手順の発見 システムは手順ページ集合Dを受け取ったのち,まず,各ス テップsに対して詳細化関係集合を発見する.しかし,詳細化 関係は手順と手順集合の関係であるため,全ての手順集合に対 して可能な詳細化関係を列挙し,一つ一つテキスト類似度に基 づいて正しい詳細化関係であるかを判定することは計算量の点 で効率が悪い.そこで,本研究では,シード手順という考えを 導入し,あるステップに対してシード手順をまず求め,そこか ら詳細化関係集合を求める. ある詳細化される手順sdetailedを詳細化するステップ集合 Sdetailがあるとき,Sdetailは同じ手順ページ中に連続して出現 している.従って,あるステップsdetailedに対して,非常に類 似するステップsjが存在するとき,sjの前後のステップがも しsdetailedやsjと類似していれば,それらはsdetailedを詳細 化していると考えられる.このように,まずステップsdetailed と非常に類似するステップを求め,それを基に詳細関係を発見 することで,計算量を削減することができると考えられる.こ のとき,ステップsjをsdetailedのシード手順sseedと呼ぶ. シード手順sseedの発見するために,詳細元となるステップ sdetailedとの類似度を用いる.類似度にはtf-idf値によるコサ イン類似度を利用する.本研究では,ステップのtf-idf値を計 算する際に,ステップ中に出現する名詞,動詞,形容詞の最上 級形を用いた.名詞だけではなく,動詞と形容詞の最上級形を 用いた理由は,ステップは動作を表すため動詞が重要であるこ と,wikiHowにおいては“at least”や“lowest”といった,手 順の性質を表すのに最上級形がよく用いられているためであ 図 2 シード手順の発見 る.具体的には,ある単語tiのステップsjにおける出現回数 をn(i, j),ステップsj中におけるすべての単語の出現回数の 和を∑knk,j,入力手順ページ集合に含まれる総ステップ集合 をS,S中の単語tiを含むステップをSti と置くと,ステップ
sjにおける単語tiのtf-idf値tfidfi,jは以下の式で定義される.
tfidfi,j= tfi,j· idfi
tfi,j= ni,j ∑ knk,j idfi= log |S| |s : s ∋ ti| いま,ステップsiとsjの類似度を上記のtf-idf値を用いたコサ イン類似度で定義すると,sim(si, sj) >= θ1となる時,siはsjの シード手順であると言う(図??).また,sim(si, sj) = sim(sj, si) であるため,siがsjのシード手順であるならば,同時にsjは siのシード手順である. siのシード手順はsiを含まない全手順ページに対して,0個 以上存在する.つまり,siのシード手順が,ある手順ページd 中に複数個存在する場合もある. 4. 3 詳細化手順集合の発見 本節では,詳細化ステップ集合Sdetailの発見方法について述 べる. ??節で述べた詳細化関係の定義より,Sdetailの要素はシード 手順sseed の前後に存在している.そこで,sseed の前後のス テップs′seedを1つ1つ取り出して,Sdetialに含まれるかを判 定する基準については以下の2点があげられる. • s′
seedがSdetailに追加されるとsdetailedに含まれる単語の 被覆度が大きくなる • s′ seedとSdetailが類似している 以上2件の要件のどちらかを満たす時,s′seed∈ Sdetailとする. これを実際に求めるアルゴリズムを以下で定義する. まず被覆度について形式化する.ステップsiに含まれる「名 詞」「動詞」「形容詞(最上級)」の集合をTiとすると,s1がs2 の単語をどれだけ被覆しているかは,以下の式で表される. cover(s1, s2) = T1∩ T2 T2 ま た ス テップ 集 合 S = {s1. . . sn}中 の 単 語 集 合 TS = T1∪ T2∪ . . . Tnがs2の単語をどれだけ被覆しているかは, cover(S, s2) = TS∩ T2 TS
図 3 詳細化関係の発見
と書ける.
したがって,s′seedをSdetailに追加することで増加する被覆 度は,s′seed追加後の詳細化ステップ集合をSdetail′ とおくと,次 式で表される.
δcover(s′seed, Sdetail) =
cover(Sdetail′ , sdetailed) cover(Sdetail, sdetailed)
− 1
この被覆度と,??節で定義した類似度を用いて,詳細化ス
テップ集合を求めるアルゴリズムを以下に示す. (1) sseedをSdetailとし,sm= sM = sseedとする
(2) δcover(sM +1, Sdetail) >= θ2またはsim(sM, sM +1) >= θ3を 満たすとき,sM +1をSdetailの要素とし,sM = sM +1に
更新する.これを前式を満たす限り繰り返す
(3) δcover(sm−1, Sdetail) >= θ2またはsim(sm, sm−1) >= θ3を 満たすとき,sm−1をSdetailの要素とし,sm= sm−1に 更新する.これを前式を満たす限り繰り返す (4) sm |= sM ならば,ri= (sseed, Sdetail)とする. (4)は,詳細化は複数のステップにより行われるべきで,単一 のステップによる詳細化は提案手法では詳細化と定義せず棄却 することを意味する. 図??に詳細化関係の例を示す. これで基本的な詳細化ステップ集合の求め方は終わりだが, ある手順のシード手順が同手順ページ中に複数存在する場合を 考える. 仮定によれば,ある手順を詳細化するステップは連続して存 在しているので,同手順ページ中に複数の詳細化ステップが存 在することは仮定に反する.そこで,以下では複数詳細化ス テップをマージする方法を提案する.同手順ページに複数の詳 細化ステップが存在する場合,以下の2パターンが考えられる のでそれぞれについてマージの方法を述べる. • 詳細化ステップ集合の範囲が重なっている場合: 詳細化ス テップ集合をすべて正しいものとし,要素の和集合を新た な詳細化ステップ集合とする.このマージ方法の実際の例 を図??に示す. • 詳細化ステップ集合の範囲が重なっていない場合: 詳細化 ステップ集合は1つ以外間違っているとし,各シード手順 と詳細元の類似度を比較する.最も高いものを正しい詳細 化集合とし,それ以外を棄却する.このマージ方法の実際 の例を図??に示す. これを定式化すると次のようになる. (1) sjkのdi中における詳細化関係をRjk0 ={ri10, r0i2. . . r0in} 図 4 詳細化ステップ集合の範囲が重なっている場合のマージ例 図 5 詳細化ステップ集合の範囲が重なっていない場合のマージ例 とし.rip0 中の詳細化ステップ集合をSp0とおく. (2) Sp0に含まれるステップのindexの最小・最大をspm,s p M と する. (3) R0 jk中から2つの詳細化関係r0i1, ri20 を取り出す. (4) s1m<= s2M, s 2 m<= s1M またはs 2 m<= s1M), s 1 m<= s2M を満たす 時,r0i1, ri20 を棄却し,新たな詳細化関係r0xを作成する. (5) sxm= min(s1m, s2m), sxM = max(s1M, s2M)となるようにS0x にステップを格納する.またシード手順と詳細元手順の類 似度は高い方を設定する. (6) 4で定義した条件式を満たすものが存在する限り,3から5 の作業を繰り返す (7) R0jkの要素が2つ以上ある場合,シード手順と詳細元手順
の類似度が最も高い詳細化関係以外を棄却する. 以上の作業により,ある手順の詳細化関係ステップ集合は, 手順ページ毎に必ず1また0個となるように設定できた. 4. 4 仮具体度の計算 前節の手法により,与えられた手順ページ集合から詳細化関 係集合R0を得ることができた.しかし,これらはテキスト類 似度のみに基づいて得られており,本来は詳細化関係ではない ものも多く含むと考えられる.そこで,詳細化関係集合をもと に各ステップの仮具体度を計算し,詳細化関係内の手順間の具 体度をみることで,得られた詳細化関係が正しいかどうかを評 価する. ステップの具体度を求めるにあたり,本研究では以下の仮定 をおいた. • 具体度が高いステップに詳細化されているステップほど具 体度が高い 上記の仮定に基づいてステップの具体度を求めるため,本研 究では以下のアルゴリズムに従って各ステップの具体度を計算 する. (1) 空の詳細化関係木集合T0= ϕを用意する. (2) 全てのステップsi∈ Sに対して,以下を実行する. (a) ステップsiを根とし,詳細化関係集合R0中に,siが 詳細化元,sjが詳細化先となっているような詳細化関 係があれば,sjをsiの子とする詳細化関係木t0i を作 成する.また,sjに対しても同様のことを行い,sjを 詳細化元,skが詳細化先となるような詳細化関係があ れば,skをsjの子としてtiに追加する.この手続き を幅優先で再帰的に行うことで木にステップを追加し ていく.この時,閉路あるいは子が複数の親を持つよ うなエッジが木に追加される場合は,そのエッジを削 除する.これは,手続きを幅優先で行うことで決定的 に行うことができる. (b) 得られた詳細化関係木t0 i をT0に追加する. (3) 全ての木tl∈ T0の各ノードsに対して,根を1とするそ のノードの深さを求める. (4) 各ノードに付与された深さの平均値をそのノード(ステッ プ)の仮具体度する.すなわち,ある木tl中のあるノード siの深さをdi,lとすると,ステップsiの仮具体度Cs0iは, Cs0i = 1 k ∑ t0 l∈T0di,lとして求められる.ここで,kはス テップsiを含む木の数を表す. たとえば,上記のアルゴリズムを図??で表す詳細化関係集 合に対して適用すると,この図のステップiの仮具体度は, C0 si= (2 + 1)/2 = 1.5と計算される.このように,上記アルゴ リズムは,詳細化されているステップを詳細化しているステッ プに対して,より高い具体度を付与することができる. 4. 5 不要な詳細化関係の削除 前節の手法により,詳細化関係集合中に出現する全ステップ に対して仮具体度が求まった.本節では,得られた仮具体度に 基づいて,現在得られている詳細化関係集合から不要な詳細化 関係を発見し削除する手法について述べる. ??節で述べたように,あるステップ集合Sjがステップsiを 図 6 詳細化関係木集合の例 詳細化するとき,Sjはsiよりも具体的であると考えられる. そこで,仮具体度を用いて,R0中の各詳細化関係ri= (si, Sj) に対して,詳細化先のステップ集合Sjが詳細化元のステップ siよりもどの程度具体的か計算する尺度として,詳細度Mr0i を以下の式で定義する. Mr0i = ∑ s∈SjC 0 s C0 si 詳細度Mr0i は詳細化先の各ステップの具体度が詳細化元のス テップの具体度よりも大きいほど高い値をとる. 全ての詳細化関係r∈ R0i に対して詳細度Mr0iを計算し,最 も低い詳細度(すなわち,minri∈RM 0 ri)が閾値θ4を下回って いれば,その詳細化関係を詳細化関係集合R0から削除しR1 を得る.得られたR1を元に,??節および本節で述べた手法を 閾値θ4を下回る詳細化関係がなくなるまで繰り返し適用して いくことで,詳細化関係集合R∗を得ることができる.最後に, R∗に基づいて各ステップsiの具体度Cs∗iを求めることで,詳 細化関係集合とステップの具体度を求めることができる. 4. 6 手順ページの具体度の計算 最後に,得られたステップの具体度に基づいて,手順ページ の具体度を計算する.本研究では,手順ページdの具体度Cd を,d中に含まれる各ステップの具体度の平均値として求めた. 具体的には,手順ページdの具体度Cdは,d中の具体度が定 義されているステップ集合Sdとそのステップ数ndを用いて Cd= 1 nd ∑ s∈Sd Cs∗ として計算する.なお,本手法は手順ページ中のどのステップ に対しても詳細化関係がないような手順ページに関しては,具 体度を計算することができない.そうした手順ページに対する 具体度の計算は今後の課題である.
5.
実
験
本節では,本研究で行った実験の概要とその結果について述 べる. 5. 1 実 験 設 定 提案手法の有効性を検証するため,「ギターの上達」に関する wikiHow中の16手順ページを人手で用意した.16ページ中に 存在する総ステップ数は304個であった.まず,用意した手順 ページ集合を対象に,著者らが人手で詳細化関係を用意した. また,手順ページの具体度をそれぞれ5段階で評価した.なお, 今回用意した16手順ページ中に存在した詳細化関係は31個で あった.単 語 の 抽 出 お よ び 品 詞 推 定 に は ,Natural Language Toolkit(注 3)を 用 い た .ま た??節 で 用 い た 閾 値 は そ れ ぞ れ , θ1 = 0.2, θ2 = 0.2, θ3 = 0.25と設定し,??節で用いたθ4 には閾値を設定せず,すべての詳細化関係が削除されるまでの, 詳細化関係の精度と手順ページの具体度によるランキング精度 を検証した. 5. 2 評 価 尺 度 得られた詳細化関係の精度評価には以下の尺度を用いた. • 再現率: システムが抽出した詳細化関係集合において,正 解のステップ集合の要素を1つでも含んでいるSdetailの 数をx,人手で用意した全詳細化関係の数をyとして,次 式で再現率Rを定義した. R = x y これは,詳細化関係にあるステップ集合を推薦する際,手 法が取得した詳細化ステップ集合と正解のステップ集合が 完全に一致していなくても要素が1つでも一致していれば 実用上の問題はないという考えに基づいている. • 適 合 率: ま ず,シ ス テ ム が 抽 出 し た あ る 詳 細 化 関 係
ri = (sdetailed, Sdetail)に対する適合率scoreri を定義す
る.いま,zをSdetail中のsdetailedに対する正解詳細化関 係ステップ数とするとき,scoreriを scoreri = z |Sdetail| として求める.システムが抽出した詳細化関係集合Rに対 する適合率Pを,以下の式で計算する. P = ∑ ri∈Rscoreri |R| この適合率は,上記で述べた再現率とトレードオフの関係 になっている. • F 値: 適合率Pと再現率Rの両者を考慮した評価値とし て,F 値を用いた.F 値は以下の式で定義される. F = 2P R R + P 次に,具体度に基づく手順ページのランキングには以下の評 価指標を用いた. • nDCG: 具 体 度 の 評 価 に は nDCG(normalized
Dis-counted Cumulative Gain)を用いて行う.手順ページ
diの前項で定めた5段階評価値をG[i]とし,提案手法が 算出した具体度の高い順番にランキングされた手順ページ 系列D′= [d′1, d′2. . . d′n]に対して,DCGは次のように計 算される. DCG = ∑n i=1G[i] log2(i + 1) これに対して,理想的な順番(実際に具体度の高い順番) に並べたときのDCGの値をiDCGとしてiDCGでDCG を正規化した値 nDCG = DCG iDCG を評価値として手順ページの具体度を評価する. (注 3):http://www.nltk.org/ 図 7 不要な詳細化関係の削除による再現率・適合率・F 値の変遷 図 8 具体度に基づく手順ページランキングの精度 5. 3 実 験 結 果 まず,詳細化関係の精度について述べる.図??は具体度に基 づく不要な詳細化関係の削除を行うことで,システムが抽出し た詳細化関係の精度がどのように変化したのかを表す図である. 図中のx軸は横軸は詳細化関係を削除した回数,また,y軸の 赤線は再現率,青線は適合率,黒線はF値を表している.図?? では詳細化関係が0個になるまでの変遷を表している.図??の 左端の再現率を見ると,??節,??節の手法で取得した詳細化関 係の再現率は0.4程度であることが確認できる.また,不要な 詳細化関係を削除していくことで,適合率が上昇していること も分かる.不要な詳細化関係を削除することで,再現率も減少 してしまうものの,詳細関係の削除を行っていくことでF値も 向上していることが分かる. 次に具体度に基づく手順ページのランキングの評価結果を 図??に示す.図中のx軸は詳細化関係を削除した回数.y軸は nDCGを表す.図??より,詳細化関係の削除を行うことで,ラ ンキングの精度が向上していることが分かる.具体的には,詳 細化関係を始めて抽出した際(x軸の左端)のnDCGが0.77 なのに対して,詳細化関係のF値が最大となった削除回数時の ランキングは,0.84であることが分かる.このことは,精度の 高い詳細化関係を抽出することで,手順ページの具体度の推定 精度も向上するということを示唆している.
5. 4 考 察 最後に,今回の実験から得られた結果について考察を行う. 図??にあるように,詳細化関係の削除により詳細化関係の抽出 精度は向上しているものの,その精度は最大でもF値で0.188 と高い精度とは言えない結果となった.提案手法の性質上,不 要な詳細化関係の削除により再現率はが向上することはないた め,??節,??節で詳細化関係を取得する手法を改善する必要が ある.改善の方法として挙げられるのは,ステップ間の類似度 判定の手法である.本研究における提案手法では,ハウツー検 索であるということを考慮して,通常の検索とは違い,名詞だ けでなく行動に関わる動詞なども注目して類似度を計算した. しかし,より高精度に詳細化関係を抽出するためには,品詞だ けではない情報を利用して類似度を計算する必要があると考え られる. また,本研究の実験では,詳細化関係の削除を停止する閾値 を設定せずに,実験結果の評価を行った.しかし,実際に本提 案手法をシステムに適用するためには,具体的な閾値を設定す る必要がある.そのためには正解データのみではなく,多くの 学習データからこの値を上手く設定する必要がある. 不要な詳細化関係の削除による,具体度に基づく手順ページ のランキングは一定の効果を示すことができたと考えている. 例えば「ギターの練習方法」という手順ページは具体度が低い ことが予想されるが,類似度だけでは詳細化されるステップも するステップも多く持ってしまうため,削除を行う前では3位 にランキングされていた.しかし,詳細化関係の削除を行うこ とで,F値が最大となった時点では13位にランキングされ,ラ ンキングの精度が向上したということが分かった.さらに「ギ ター譜の読み方」といったページ具体度の高いページも提案手 法によりランキングが9位から1位に向上したことも確認でき た.一方で,「ギターのスケールの学び方」という具体度が高い ページがF 値最大の時点で最下位にランキングされることも あった.この手順ページは,F値が最大値になる直前までは上 位にランキングされており,削除回数が170前後でnDCGの 値が急激に落ちているのはこれが原因だと考えられる.このよ うに,間違った削除を行ってしまうタイミング見極めるために も,閾値の設定は必要であると考えられる.
![図 1 手順ページとステップの関係 3. 概 念 説 明 3. 1 ステップと手順ページ まず本研究で扱う手順ページとステップについて説明する. 手順情報はそれ自体が手順のリストで構成されていると考え られる [?] .そこで本研究では,ある目的を達成するための一連 の行動をまとめた文書を手順ページと呼び.手順ページに含ま れる, 1 つ 1 つの手順のことをステップと呼ぶ.本研究では,手 順ページはそのページに含まれるステップの集合として表され る ( 図 ??) .このような構造を持つ文書は,レシピやハ](https://thumb-ap.123doks.com/thumbv2/123deta/8191637.1277303/3.892.81.394.65.292/ステップステップステップについてステップ順ページ含まれる.webp)