Speaker-Adaptive Speech Synthesis Based on Eigenvoice Conversion and Language-Dependent Prosodic Conversion in Speech-to-Speech Translation
4
0
0
全文
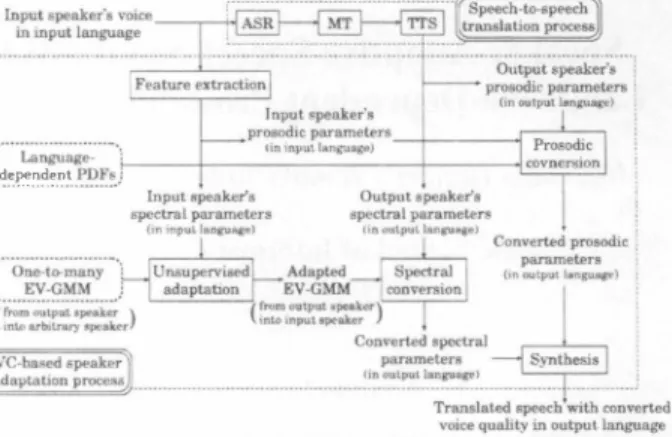
(2) ,. where the mean veclorμ�;.'( l') (ω) is w出巴n as I X,l 'lt...\. ' (切). 1 1 _ r �( n μ �� ) _= rI J.L�;) r-'":' . I リ),� , I . (2) }切+ b;: } (O)J l μ�� � でJ (切) IJ - ILB��. ln one-to-manyEVC, the target mean vcctor of the mth mix- ,(両日平 tw'e component is represented as a lin巴ar combination of :..d�!"'���.�t..p.J)�:�J a bias vector b}�) (0) and時間sentative vectors B江) ) whe向山number of represc脚. d (外. [bV(1),. tive vectors. J.. The J-dimensional weight vector凹 = 10 an arbitr町larget speaker while山e parameter sel of theEV-GMM入(E\') is ti巴d over dif ferent target speakers.. [ω( 1),. is. 川(J)l' is adapted. 2.2. Training. Figure 1:. The ticd parameter set of山巴EV-GMM is trained in advance using the multiple parallel data sets consisting of the single source sp巴aker and many pre-sto陀d target speak ers Let X t and y;s) be the feature vec川of th巴 source spe山r and that th 品 。f the s'" pre-stor巴d target speaker at frame t. NOl only the tied par釦leler set 入( E川but also a sel of lh巴 weight vectors WLS {ω1,・ ,ωS} adapted 10 individual pre-stored町get sp巴akers are optimized as fol1ows:. ,. 3. Cross-Liogual Speech Syothesis ßased 00 VC io Speech-to-Speech Traoslatioo. =. 切. E 入. y. x、 ''』ts、 P 日出 九 s 日出 s m m E W可λ f〈t a 一 一. ,WI:S. 今、J ,, 、、,B,. { ^主 同 ) A ). To enable maximum a posteriori (MAP) 巴stimation in the adaptation process, a prior p.dJ. of the weight veClor is mod巴l巴d by a Gaussian distribution as fol1ows:. P(ω叫|休入必>.lw加川山刈)人υ,汗7う)=N川(ωりi川μμJ川(加川叩叫) ?fff7「ρ一→-1I;lw加山叫)) ,. 付. wher'陀e7 I路s a hyperト-pa訂ra創m】巴飢t巴町r.Am】odel pa訂rame臥ter set 入 (叫) con ). s剖IS抗叫tin】 goぱf t出h巴 mean vectωorμ( 凶叫) and t山h 巴 c∞ovana加n】にcωe matrix. I;( 日. is estimated using a set of the weighl vectors optimized for in dividual pre-stored targel speakers inEq. (3). 2.3. Unsuperviscd adaptation. TheEV-GMM is adapted 10 an arbitrary target s peaker by cs timating the optimum w巴ight vector for given speech samples of the凶get sp巴aker in a completely unsup巴円IS巴d mann巴f,l.e., using neiÙler parallel data nor linguistic infonnation. For a tim巴 S叫uence of Ùl巴 given target feature vectors y � y ト the MAP eSlimation of lhe weighl veCLOr is performed as follows:. ,・ ' ,. ûl. There are two main approaches to develop speaker-adaptive speech synthesis in speech-to-speech translation: one is to synthesize voices of the output languag巴 uttered by the input speaker as回ly as possible (e.g., presenting Japan巴se accent巴d English if出e input speaker'sEnglish is accented): and the other is to synthesize voices of the input spe誌巴r in the OUtpllt lan guag巴 as flllently as native speakers. The use of bilingllal data would be 巴ssential in the fonner approach but it is not always necessary in the latter approach. In this paper, we focus on the latter approach and propose a novel approach based on VC techniques without any bilingual data. A basic idea is to gener ale the input speはぜs voices in the outpUl language by properly lTIixing voices of various native speakers of the output 1釦guage Figure 1 shows th巴 propos飢1 framework. First the input speaker's voice is translated into a text in出e output language by ASR and MT, and then speech pararneters such as spec 凶1 and prosodic p紅白lleters 紅e generated by τTS. After that, spectral parameters are converted with one-to-manyEVC and prosodic parameters are converted based on language-dependent proba bility distribution functions (PDFs). This proposed fr加nework has nice portability since it is straightforwardly applied 10 any speech-to-speech translation system, If the TTS system gener ates only speech wavefonns, a speech analysis process is nec essary to extract speech par創neters from the generated OUtpllt waveform. In曲目paper, HMM-based spe巴ch synÙlesis is used as the TTS system. Thanks to its parametric speech synthe sis framework, sp田ch parameters generated from the translated text are avail a ble 10 be lIsed in one-LO-many EVC wi出Olll any. =組、Eぺ'1! P(ωIY�,'・・,Yト入) =叫ザ P(凹|入( 叫),7) n P(Y;I入山川),. Proposed speaker-adaptive speech s)'lIIhesis frame. workfor speech-to-speech translatiol1 system.. specch. analysis process. 3.1. Spectral COl1version Based 011 One・to・Mal1yEVC. (5). The output speaker of a speech-to-speech translation system is as the source speaker 加d the inpllt sp巴aker of Ùle system (i.e" a us巴r) is used as the target spe法巴r LO be adapted in one to-manyEVC. First one-to-manyEV-G恥1M is adapt氏1 into the mput spe泊三er lIsing only hislher voic沼s input 10 the system. The spec汀al param巴ter sequence generated by the TTS is convert巴d with the adaptedEV-GMM so as to exhibit the input speaker"s voice quality. An excitation par創lleter such as aperiodic com ponents may also be converted in Ùle same manner using an otherEV-GMM develop巴d for such a parameter. To train theEV-GMMs, it is necessary to use multiple par allel data set� consisting of the speak巴r modeled by the TTS used. This adaptation process works reasonably well even if llsing only one or two utterances since th巴 nllmber of adaptive pa rameters (i,ι, the number of dimensions of the weight vector) is smal1 enough 2.4. CODvcrsion. 8ased on the adapted EV-GMM, the source featllre vectors are converted into the target feature vectors. The maximum likelihood estimation method consid巴ring dynamic featllres and global variance [7) is adopted in this pap巴r. 2770. -98-.
(3) system as the singl巴sOllrce speaker and a lot of other sp巴ak C'rs as the pre-defined targ巴t speakers. However. it is laborious work to collect those data sets. To address this issue, we use the synthetic speech to creat巴 th巴 parallel data. There exist speech data of a Jot of speal∞rs with transcriptions available, for in stance, sp巴ech data used in acollstic model training for speech recognition. Because the spe紘er of the TTS syslem is used as the single source spe法er in the proposed framework, it is straightforward to develop the parallel data by generating the single source speaker's voices co汀巴sponding to individual巴:x isting speakers' voices from their transcriptions.. those valu巴s for the input langllage are converted to those for the output language as follows:. 。 =. In the proposed method, the prosodic parameters are gJobally conv巴rted as follows: ,、. (\. r. ) +μ(ν) ). (6). Fl'(y). =町三め=. 川〕仏. σ1. 川匂. (8). where ]1,1 is the number of mixture components‘11m andσ叫are. mean and standard deviation values of the打Z山mixture compo nent, respectively, which are tied over di仔erent languages, and j1(X) is � language-depend巴nt bias tied over different mixture components. Using this GMM for modeling the p.d.f. in each language, the conversion process by Eq. (10) is simplitìed as. 。 =. =. P(X壬x)‘. x -μ( x)+μ( Y). (12). whereμ(入一) andμ(y)創e bias terms for the input language and the output language.. 4. Experimental Evaluations 4.1. Experimental Cond.itions Experimental evaluations on cross-lingual speech synthesis were conducted assuming the spe収h-to-spωch translation among Jap唱nese, English, and Chinese. One female speaker was used in each language as the OUtpllt speaker of eaιh TTS system. In training of one-Io-many EV-GMM of spectral pa r剖neters for each language, 100 speakers (50 male and 50 fe male) w巴re us吋as the pre-defin巴d target speakers. The number of mixture components and the number of rep陀sentallve vec tors of cach EV-GMM werc set to 128 and 99‘respectively. In training of PDFs of prosodic parameters for each language. 326 speakers (163 mal巴 and 163 female) in Japanese, 2印) spe必ぽrs (100 male and 100 female) in EngJish, and 540 spe討(crs (270 male and 270 female) in Chinese were used. To minimize the effect of different spe水ing styles on the pros岨dic parameters, these speakers were sel巴cted ti'om speech corpora of travel con versation. In ∞nversion, 4 speakers (2 male and 2 female) in each language were l1sed as the input speaker (iι, the target spe心ωr to be adapt巴d) not included in the tr釦ning data. Only 2 sentences for each speaker were used in adaplation and 40 sentences for each speaker w釘e used in evaluatio日 th .L__.. _ I_ t"\ A th As a spe氾tral parameter, Ihe 0'" through 24'" mel-c巴戸tral. where x and X show a speaker-dependent pru'ameter vaJue (μ(ν) orσ(ν)) and its random variable in the input lan忠luge, respectJV巴Iy, and y and Y show those in the Olltput language, 陀spectively. The p.d.f.s are given by .fx (:c) for th巴II1put language and .fy (y) for the OlltpUt laJ1guage. In conversion, fìrst we extract the mean and standard deviation values of cach prosαJic pararneter from the giv巴日input speak町、、'oice. Under an assumption that the following 巴quation holds,. P(γ:$ y). σ. = P(Xω=. μ. 仁 1二. Fx(x). μ. where p(.r.) and þ(ν) are a prosodic parameter of the source speaker (i. e.. the TTS Olltput speaker) and that converted 10 Ihe target sp巴aker (i.e., th巴 input speaker of th巴 translation syト tem), resp巴ctively. Pru'ameters of出is conversion function in clud巴mean values of th巴 prosodic parameters for th巴 source and tru'get speakers,μ(r.) andμ(ω. and standard deviation val ues for those sp巴akers,σ(x) andσ(11) The par副11eters for Ihe source sp巴紘er,μ(x) andσ(x)‘are easiJy e.xtracted in advance using a large number of synthetic voices from the TTS system or spe巴ch data used in voice building of the TTS system. The parru11elers for the target sp巴心,er,μω) andσ(ω, ru'e exlracted frolTl utterances input 10 the translation system Although the above process assumes that the parrun巴ters for the target speaker are the San1e even if a language is different, this assumption does not always hold. Nrunely, the prosodic pa rameters would depend on not only individual speakers bllt also individual languages: e.g., the standard deviation value of Fo would be larger in a tonal language such as Chinese or Japanese than that in a non-tonal language such as English. To consider the 巴tTect of each langllage on th巴 prosodic pa rameters, we propose a prosodic conversion m巴thod bas巴d on language-dependent PDFs of thos巴 par創11巴t巴rs. A speech cor pllS including a lot of speakers in the input language and that 111由巳OUlput language are separately used 10 extract language dependent features of the prosodic parameters. First, the mean and standard deviation values.μ(Y) and σ(ν) are calclllated speaker by speaker. Then,【he PDF of each param巴ter for each language is drawn using the calculat巴d parameter values of all speakers in th巴 same language as follows:. x. vb /'ats\ M M 一 1 乞同 M 一 一 z v i f J. σ(".). ' 、1』1'. σ(y). In this paper, we use log-scaled Fo as the prosodic param eter and its mean and standard deviation values are converted using language-dependent PDFs. I In the proposed method. we need to use speech data in cluding a lot of speak巴rs in each language but we don't have to use bilingual data. It is easy to白nd those speech data available rath巴r than to develop bilingual data. However. the resulting PDF is strongJy affected by the number of available samples (i.e., th巴 number of speakers) in each language. To alleviate the overfitting 巴ffect, the p.d.f. in each language is modeled by the following constrained GMM,. ability Distribution Functions (PDFs). _ (y). (10). Finally, the prosodic parameters generated from出e TTS sys tem are globally converted using the conversion function b y Eq. (6) with the parameter values converted in向. (10) asμ( y) and. 3.2. Prosodic Conversion with Language-Dependent Prob. 戸(ν) = L p(z)-14(占) r. F↓-11( F x(x)).. coefficients were used. As a prosodic parameter, log-scaled Fo was used in the global conversion and its mean and stan dard deviation values were used as parameters convert吋 with I We also tried convelting a dllration parameler but we did not自nd. (9). any Slgl1l品cant improvements in naturalness. 2771. -99-. 01' the印nverted speech.
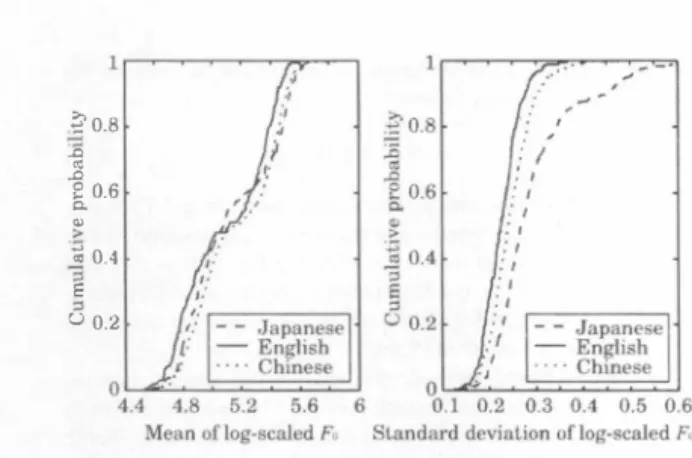
(4) |. nυ nu O4 aq nbnu nenυ @ 。晶 帽 』 出 ケ ロ 唱 同 E ヨョ4 hg ] dF [ E E S E 8 5 h a @ よ. を0.8. .0 '" 」コ. 8. ι ω 〉. 0.6. 言0.4 ロ 2 Ü. l. 日95%∞nfid阻回国出rval -庄三--士、 100r一ーで=コ c:コEVC+PC 亡コw/o VC. 100. 11. EコEVC+PC 11 ・・・EVC+LDPC H. T咽1酒圏r刊1 咽咽1 ‘,.. - 圃圃圃 E. ご酒_ ,. _ 11. 1. 1. E{. .+ ..........iF 801� ... . .・・EVC+LDPC. ;詰詮;?6併 s c:t ø碕. . ..j;i: .r. ... 空軍1 2B40 ;調t ロ1・・・・ T r- ・・・" I =1・・・ 1 L ・・ E 比 . _ 11 _ I _�・・ 1 � II�� 20胤 |週間Itr1. 0.2. ‘-e o:s ロ. 週1-. -. 4L_・司I .ム圃圃E111 L:園圃I JPNJPN. ENG ENG CHN .CHN. nllt-..・・・IL!.! JPN- JPN- ENG ENG CHN .CHN Lan忠坦喜e pa町. Language p副r. Figure 3:. Results oIsulり.ιtive e\'(/!ulltions. STRAIGHT [13) was uscd as a. to-spωch translation. In the proposcd techniques, spectral pa. Prefcrence tcsts (XAB tcsts) of convcrsion accuracy for. and prosodic paramet巴rs are globally converted considering di f. language-dcpcndcnt PDFs.. speech analysislsynLhesis method. Th巴 shirt length wa� 5 ms. ramelers are converted with one-to-many eigenvoice conv巴rSlOn. spcakcr individuality and naturalness were conducted sepa rately.. ferences of Lheir probability distribution functiol1s bctwccn dir. In the preference test of conversion accuracy for. ferent languages. Experimental results havc demonstratcd thm. speaker individuality, 1) thc output voice without VC (w/o. th巴proposcd tcchniques arc cffcctive for dcvcloping spcakcr. VC). 2) the output voice converted with one-to-many EVC. adaptive sp巴ech synthesis in speωh-to-speech translation.. and global prosodic conversion without considering languagc. Acknowledgment:. dependcnt differences (EVC+PC), and 3) the output voice con. Th日research wa� suppo'1cd. Granl-in・Aid for Yo川ng. vertcd with one-to-many EVC and global prosoclic conversion. in. part by MEXT. (A) and MIC SCOPE. 6. References. using language-dcpendent PDFs (EVC+LDPC) werc compared. [IJ S. Nakamura, K. Markov. H. Nakaiwa, G. Kikui, H. Kawai.. with cach other. Jn the preference test of naturalncss, the lat. suhir官、J.-S. Zhang, H. Yamamoto, E.. tcr two methods (EVC+PC and EVC+LDPC) werc compared. Sumita,. 1'. Jit. and S. YamamOlO. .. Thc ATR multilingllal speech-to-speech tran,lalion sy stem IEEE. wiLh each oth己r. After vocoded speech of the input speaker (in. T町lIl.l". ASLP. vol.14. nO.2. pp.36 5-376、2006. the input language) was presentα1 as a reference, a pair of th巴. 121. OUlpUI voices (in thc Olttput language) by different two metlト. H. 7""n, K. Tokud礼and A.W. ßlack. Statislical parametric spccch ぉyn山csis. Speech. ods was present巴d to listeners. In lhe Iìrst preferencc test, the listeners evaluatcd which voice sounded more similar to the ref. Cοmm/ll.;cal;on.. vo1.51 , nO.11. pp.1039-10かL. 2009 [3J. erence in tenns 01' spe泊三巴1・indivitluality. In Ihe other prefercnce. S. King, K. 1'okuda. H. Zen, 剖ld J. Yamagishi.. Unsupcrvised. adaptation for HMM-based speech synthe出s,. test, the list巴ners evaluated which voice sound己d more natural. 141. as the outpul language voice. Th巴se tests were performed sep. Proc. INTER. SPEECH. pp.18 6ゅー1872 , ßri.bane. Australia. 2008. Y.-N. Chen. Y. Jiao,. Y.. Qian, and F.K. Soong.. for cross-Ianguage speaker adaplation in. arately for each output language by the listeners whos巴 nat.ve. 'ITS.. Stale mapping. Pro<・ofICASSP.. pp.4273-4276, 2009 151. languagcs wcrc thc same as thc output language. The nUlllbcr of listeners fur each languag巴was 10.. M. Gi恥on and W. ßyrne.. Un刈perv円cd intralingual and cros:-.. lingual気peakcr adaptation f()r H MM-based 'pcech 'y nthc two-pass deci別on (rc(' con叫ructlo明. 持 I � usmg. IEEF:. Trans. ASLP, vol.l9,. no.4, pp.895-904, 2011. 4.2. Experimental Results. 16J. Thc PDF of cach paramctcr is shown in Figure 2. It can bc. Y.. Stylianou. O. Capp丘and E. MOlllines. Continuous probabilis. tic transform for 刊Ice印n\'ersion. IEEE. Tra/ls.. o. SAP, v l.6 ,. pp.I3I-1 42 . 1998. obscrvcd that thc PDFs of Ihe Fu mean valu巴 are simil出to. no.2,. 17J T. Toda. A.W. ßlack, and K. Tokuda. VoicピCυnver�ion ba�eù. each other among di仔erent language� but the PDF, of the F.J standa.rd 氏、riation values are quite differcnt especially belw民n. maximum likeliho肌1 estimation. 01' speclral. 01. paran官官r trajcctory. IEEE TranふASLP, vol.15司nO.8, pp.2222-2235 , 2ぽ17.. Japancse and thc othcr two languagcs. In the prefercncc tests, these PDFs wcre model巴:d by the constraincd GMMs. The nUIll. 18J. M. Abe. K. Shikano, and H. Kuwabara. Statistical analy引s of bilingual sp四ker・s speech for cross.language刊Ice convcrslon. 1. AcousI. Soc. Am. , \'01.90司no.1 , pp.7<,>-82 .1991. ber 01' mixture components was set to 2 for the Jミu mean value antl set to 1 for the Fo standard deviation valu巴 Figure. Scicntists. 19J. M. Mashimo. T. 1'oda. H. Kawanami. K. ShikaJlo. alld N. Camp. bell. Cross-Ianguage 、明ice conversion evalu3lion using bilingual. 3 shows pr巴ference �cores on conversion accuracy い0]. fOI・speaker individuality and Lhose on the naturalness. The one to-many EVC effectively generates synthetic spe巴ch of which voice qualily is引milar to the input気pcaker ovcr all languagc. databases. IP幻journal, vol.43, no.7, pp.�177-2185. July 2002. D. Eno. A. Moreno, and A. ßOllafo.川te.INCA砧Igorithm for lrain. 川g voice conversion �y叫em, from nonparallel Tr.α/1.1'. ASLP. Vυ1.18 . nO.5 . pp.944-953. 2010. c orpora.. IEEE. [11J T. Toda. Y. Ohtani, and K. Shikano. One-to-many and maJly tO-()(lC vQlce conv町sion based on eigenvoices. Proc. ICASSP.. pairs. Furthcrmorc, thc languagc-dcpcndcnt prosodic convcr sion yields significant improvelllents in naLuralness of th巴ι.on. pp.12 49ー1252, Hωwaii. USA, Apr. 2007. vcrtωspeech in the language pairs of which PDFs of FtJ standard deviations are quile di仔el巴nt frolll each other (iι. 112J. M. Charli<r.. Y.. Ohtani‘T. Tod3. A. Moinet. and 1'. Dutoit. Cross. language voice conversion ba問d on eigenvoices.. Japancse-English and Japanese-Chinese). ProιINTER. SPEECH, pp.1635-1638、Brighton司UK, Sep. 2創)9 [13J. S. Conclusions. H. Kawahara.. 1.. Masuda-KaLSuse, and A.de Che\'cignc'.. Re. structuring .pcech reprcscnt剖ions using �t pilch-aùapti叩llll1C freqllency smoothing and an instantaneolls-frequcncy-ba,叫ん cxu'action: possible role of a 悶petitive strllctllrc in sound;,.. In lhis papcr_ we havc proposcd nov己1 voice conversion tech. CοmmumcωfOf1,、唱1.27, nO.3-4. pp.187-2日7.1999. niques to conu'ol voice quaJity 01' tran�lated specch in >P巴巴ch-. 2772. -100-. Speeι、h.
(5)
図
関連したドキュメント
Today Iʼm going to make a speech about my dream... )in
In this thesis, I intend to examine how freedom of speech has been legally protected in consideration of fundamental human rights, and how the double standards in the
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
patient with apraxia of speech -A preliminary case report-, Annual Bulletin, RILP, Univ.. J.: Apraxia of speech in patients with Broca's aphasia ; A
This paper presents a data adaptive approach for the analysis of climate variability using bivariate empirical mode decomposition BEMD.. The time series of climate factors:
While conducting an experiment regarding fetal move- ments as a result of Pulsed Wave Doppler (PWD) ultrasound, [8] we encountered the severe artifacts in the acquired image2.
Japanese Phonic Syllables「ki」[kj i] and「chi」[tɕi] Assessment of Speech Perception in those with Articulation Disorder Ako Imamura (NPO Kotori Corporation) The purpose of
3) Ruscello DM: An examination of nonspeech oral motor exercises for children with velopharyungeal inadequacy, Semin Speech Lang,. 29:
