特徴抽出を利用した
AR 向けマーカーの作成
提出日: 2012 年 2 月 6 日
指導: 村岡洋一教授
早稲田大学 基幹理工学研究科 情報理工学専攻 学籍番号: 5110B134-4
吉永 浩気
目次
第1章 序論 1
1.1 本研究の背景 . . . 1
1.2 研究目的 . . . 1
1.3 本論文の概要 . . . 2
第2章 関連研究 3 2.1 局所特徴量 . . . 3
第3章 提案手法 6 3.1 利用環境の定義 . . . 6
3.2 SURF-based Line Marker(SLM) . . . 7
3.3 予備実験 . . . 8
第4章 静止画による物体認識実験 10 4.1 システム概要 . . . 10
4.2 実験概要 . . . 12
4.3 データサイズの評価 . . . 13
4.4 速度評価 . . . 14
4.5 精度評価 . . . 14
第5章 同一画像内における直線の傾きによるフィルタリング 18 5.1 同一画像内における直線の傾き分布 . . . 19
5.2 フィルタリングの概要 . . . 20
5.3 評価実験 . . . 22
第6章 動画による物体認識実験 25
6.1 システム概要 . . . 25
6.2 実験概要 . . . 26
6.3 速度評価 . . . 27
6.4 精度評価 . . . 30
第7章 総括 32 7.1 最終結果 . . . 32
7.2 Future Work . . . 32
参考文献 33
図目次
1.1 マーカーを利用した拡張現実 . . . 2
2.1 特徴量を記述する対象領域 . . . 4
2.2 128次元の特徴量 . . . 4
2.3 SIFT特徴量 . . . 5
3.1 検出される同一直線部分 . . . 6
3.2 SURF-based Line Marker (SLM) . . . 7
3.3 ユークリッド距離の測定結果 . . . 9
4.1 観光ガイドシステムのフロー . . . 11
4.2 データベースへの登録に用いた12個の『門』の画像 . . . 12
4.3 評価実験用の画像例 . . . 13
4.4 正解・不正解時の得票数の分布 . . . 16
4.5 有効・無効とすべき得票数の分布 . . . 17
5.1 SLMに適切な直線と不適切な直線 . . . 19
5.2 直線の傾きの分布1[radian] . . . 20
5.3 直線の傾きの分布2[radian] . . . 20
5.4 直線の傾きの分布3[radian] . . . 20
5.5 フィルタリング結果の例 . . . 21
5.6 フィルタリングを含めたシステムフロー. . . 22
5.7 フィルタリングを行った場合の正答率 . . . 23
6.1 動画入力でのシステム概要 . . . 26
6.2 認識対象 . . . 27 6.3 閾値毎の有効回答取得率 . . . 28 6.4 動画入力における平均回答時間と予測必要回答数 . . . 30
表目次
2.1 SIFTとSURFの比較 . . . 5
4.1 データサイズの比較 . . . 14
4.2 特徴点の検出と物体認識の所要時間 . . . 14
4.3 正答率の比較 . . . 15
4.4 得票数の閾値毎の正答率と回答・正解拒絶率 . . . 17
5.1 画像1枚当たりの所要時間[s] . . . 23
6.1 動画入力における認識の平均所要時間[s] . . . 27
6.2 二重投票制が正解終了するまでの平均所要回数[回] . . . 29
6.3 最終回とを得るのに必要な回答数[回] . . . 30
第 1 章
序論
1.1 本研究の背景
2009年9月24日,「セカイカメラ」というiPhone用アプリケーションが公開され,4日 間で10万ダウンロードを記録した.これをきっかけに「拡張現実(Augmented Reality)」 の存在がより知られるようになった.それに伴い,今度はこの人目を集める「拡張現実」の 広告への利用が現れ始めた.それは新聞の紙面上[1][2]であったり,野球中継のバックネッ ト[3]であったりする.他にもこの拡張現実というのは携帯電話のカメラやWebカメラな どのデバイスを通さないと見えないので,景観を損ねることもない.その為,京都などの景 観維持に厳しい地域でも,これまでとは異なるより自由度の高い広告が可能となる.
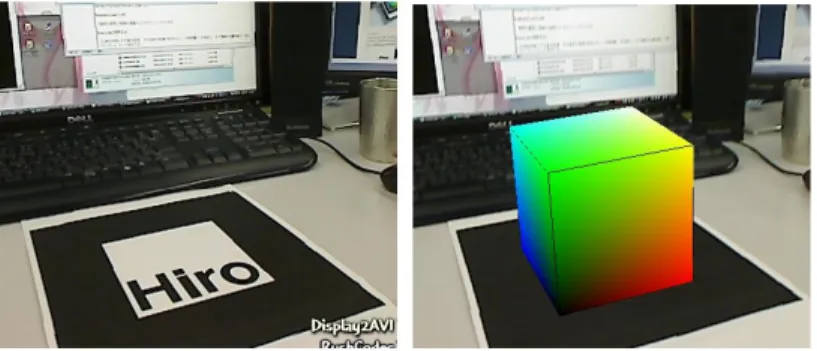
そして今現在使われている広告に用いられている拡張現実の殆どが,図1.1の様な四角 形の位置を基準に描画しており,これを「マーカー」と呼んでいる.これを利用することで ARの情報表示の際の位置が正確で,なおかつ対象物が何であるかの判別を容易にした。
ただしこのマーカーを利用するには事前に設置しておくことが不可欠で,場合によっては 景観を損ねてしまいかねないものでもあった.
1.2 研究目的
ではマーカーを使わない拡張現実にはどういったものがあるのか.最も一般的な例とし て用いられているのが「GPSによる位置情報」であるが,これは現在では最も環境が良い 状態でも数メートルの誤差が生じるので,ルート案内など以外の用途での利用は難しい[4].
図1.1 マーカーを利用した拡張現実
そこに登場したのが「Parallel Tracking and Mapping for Small AR Workspaces(PTAM)」 というオープンソースである [5]. この PTAM では「Simultaneous Localisation and
Mapping(SLAM)」という技術用いて, 背景を利用することで初めての場所であっても
マーカーレスの拡張現実の実現を可能としている.本研究ではこのPTAMの手法と同様 にして,背景から検出された特徴量を利用し,新たなマーカーを作り出すことでARの広 告媒体としての汎用性の追求すると同時に,特に観光地での利用を想定したシステムの作 成を目的とする.
1.3 本論文の概要
本研究では拡張現実の為のSURF 特徴量[6]による直線マーカー作成と,そのマーカー を利用したAR 観光ガイドシステムについて述べる.街の景観保護の条例がある京都の様 な観光地では,お店の案内などの情報を自由に掲示出来ない.しかし,特徴量を利用した マーカーによる拡張現実であれば景観を損なわず,思い通りの情報表示が可能となる.そ して本システムの情報表示の舞台となるのは寺・神社・お店といった建築物だ.そして殆 どの建築物には直線部分が存在している.それをハフ変換によって検出し,周辺の特徴量 に注目することで計算コストとデータサイズを抑えるを手法をここでは提案する.
第 2 章
関連研究
2.1 局所特徴量
物体認識において一般的に用いられており,本研究でも用いている局所特徴量.この特 徴量の内,本研究と特に関係の深いSIFTとSURFについてここで説明する.
2.1.1 Scale-Invariant Feature Transform(SIFT)
SIFT[7]の処理は,特徴点(キーポイント)検出(Detection)と特徴量記述(Descriptor) の2段階から構成されており,以下の(1)と(2)がDetection,(3)と(4)がDescriptionに 相当する[8].
(1) スケールと特徴点の検出 (2) キーポイントのローカライズ (3) オリエンテーションの算出 (4) 特徴量の記述
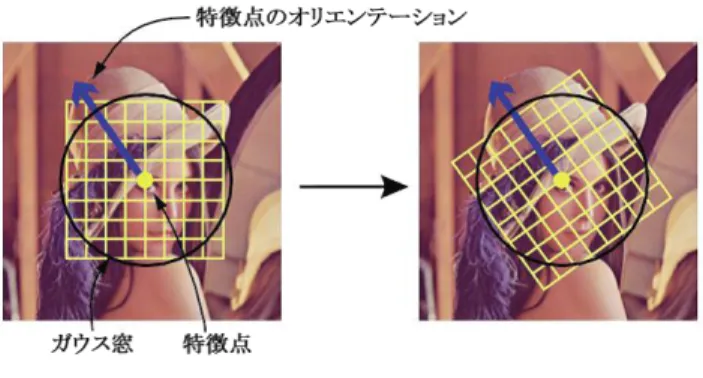
Detectionでは (1)でGaussianで平滑化 (ぼかす)した画像を利用して極値点を検出 し,(2)ではエッジ上の点など特徴点として向かない点を削除する.Descriptionでは,特徴 点周囲の輝度勾配から最も変化が大きいオリエンテーションを算出する(3).算出された オリエンテーションを基に図2.1の様に対象領域を回転させ,図2.2の様な4×4×8方 向=128次元の特徴量の記述を行う.
常にこのオリエンテーションに合わせて特徴記述を行う為,回転に不変な特徴量となる. また128次元の各特徴ベクトルの長さはベクトルの総和で正規化されているので,照明変 化や回転・拡大縮小などの変化に対して影響が少ない特徴量となる.こうしてSIFT特徴
図2.1 特徴量を記述する対象領域
図2.2 128次元の特徴量
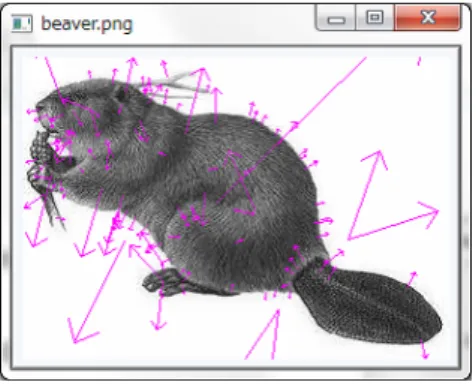
量は検出・記述され,図2.3の様な特徴点が検出される.
モバイル端末などでSIFTをリアルタイムで利用する際には,[9]の様に計算コストを いかにして削減するかが不可欠となってくる.
2.1.2 Speeded up robust features(SURF)
SIFT を改良し, 大きく高速化を図ったのがこの SURF だ. 図 2.2 でも紹介した様 に,SIFTでは4×4×8の128次元であったのに対して,SURFは同様に周辺領域を4× 4で分割し,各領域内を8方向ではなく4方向へと減らした64次元の特徴量をもつ.これ に加えて表2.1の様な点でSIFTを高速化しているのがSURFの主な特徴である.
本研究ではデータサイズの縮小と計算コストの削減の為,64次元のSURF特徴量を用 いる.
図2.3 SIFT特徴量
表2.1 SIFTとSURFの比較
SIFT SURF
特徴量の次元数 4×4×8 = 128 4×4×4 = 64
特徴量の表現 勾配のヒストグラム Haar waveletの1次応答の総和 特徴点の検出 LoG Hessian行列の行列値
検出の近似手法 DoG 矩形フィルタ
第 3 章
提案手法
3.1 利用環境の定義
第1章でも述べた通り,本研究における提案手法は寺社を中心とした伝統的な日本の建 築物を認識対象としている.これらの建築物1つ1つは,その殆どが直線によって構成さ れている.この直線をハフ変換によって検出し,各直線の周辺のSURF特徴量の集合を1 セットとしたマーカーを作成するが,この際日照時間中での利用を想定している.これは 一般的な寺社の参拝時間での利用を目的としている為だ.
また,対象を矩形ではなく直線によって限定した主な理由として挙げられるのが,直線 が矩形に比べてより安定して検出が可能であるという点だ.その為,図3.1の様な異なるア ングルから対象物を撮影した場合でも,共通した直線部分が容易に検出可能となり,より 素早く確実な物体認識を行える.
図3.1 検出される同一直線部分
この様に, 本研究ではSURFの検出・記述アルゴリズムそのものを改善するのではな く,対象領域を直線周囲に限定することでSURF に掛る時間を短縮すると取り扱うデー タサイズの縮小を実現している.加えてSIFT特徴量を用いた物体認識の主な手法である Bag-of-keypoints[10]の様に,多くの画像による事前学習を用いずに,1枚の画像で登録し たデータによる認識を行うことも特色の1つである.
3.2 SURF-based Line Marker ( SLM )
この論文では「SURF-based Line Marker」という名前の通り,SURF をベースとした 直線のマーカーを作成し,これを実際に利用したシステムを作成してゆく.
図3.2 SURF-based Line Marker (SLM)
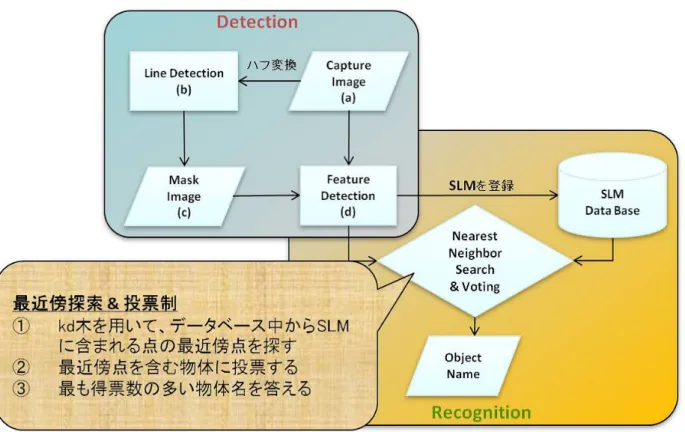
このSLMは大きくの分けて以下の4つのステップによって構成される.
• (a)画像のキャプチャ
• (b)ハフ変換による直線検出
を検出し,(c)でその直線を長軸とした楕円を描いたマスク画像を作成する.このマスク画 像によって指定された領域での(d)のSURFの検出と記述を行っている.
そして(c)で描いた1つの楕円に含まれるSURF特徴量の集合をマーカーとして用い ているのがこのSLMだ.なおマスク画像をの楕円の短半径は 4×log(長半径)としてい る.これは極端に長い直線をマーカーとして用いる際,検出される特徴点の数が指数的に増 加するのを防ぐことを目的としている.
3.3 予備実験
SLMでは直線の周囲,つまりエッジ周辺に存在する特徴量を利用している.しかし,エッ ジ周辺の特徴量は一般的に認識に用いるにはあまり向いていないとされている.そこでこ のSLMで物体認識が行えるかを確認する為の予備実験を行う.
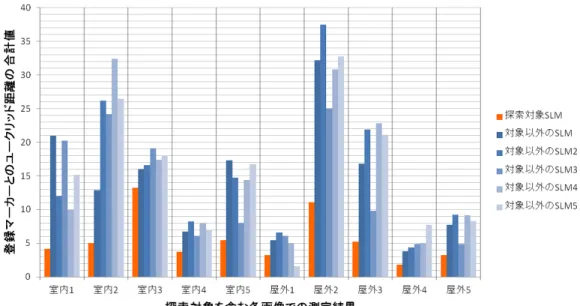
この実験では予め探索対象としてSLMを各回1つ登録しておき,対象を含んだ風景を 撮影した画像中に存在する全ての直線のSLMと登録しておいたSLMとのユークリッド 距離を測定する.画像中の全てのSLMで探索対象とのユークリッド距離が最も小さな値 を示せば, その物体が何であるかを正確に認識することが可能であるといえる.この実験 を10回行った結果を図3.3に示す.
10 回の実験で 9 回正解の探索対象が最小のユークリッド距離を示した. これによ り,SLMが物体の認識に用いることが充分に可能であると言えることが証明された.
図3.3 ユークリッド距離の測定結果
第 4 章
静止画による物体認識実験
4.1 システム概要
前章ではSLMによる物体認識が充分に可能であることを証明した.この章では実際に SLMを用いて物体認識を行う『観光ガイドシステム』の概要を説明する.
図 4.1 の検出 (Detection) 部分は先述の図 3.2 と同様のものなので, ここでは認識
(Recognition)部分について説明を行う. 認識のステップは『最近傍探索』による『投票
制』によって構成されており,本システムではこれによってデータベース中に登録された SLMからクエリーSLMに該当する物体名を返す様になっている.
4.1.1 最近傍探索
予備実験でユークリッド距離を測定した際にも行っており,クエリーSLM中に含まれ ている内の1つの特徴量と,データーベース中に登録されたいずれかのSLMに含まれる 内の1つの特徴量から,最もユークリッド距離が近いペアを作る上で最近傍探索を利用し ている.
予備実験では線形探索を行っていたが,これでは登録しているSLMの数に比例して所 要時間が長くなってしまい,結果として数多くの名所が存在し,多数のデータを登録する 必要がある観光地での利用に相応しくない.そこでリアルタイムでの利用を実現する為に, より高速な探索方法として『kd木』を用いることにした.kd 木を用いた探索では一般に数 十次元の値ならば高速化が可能で,本研究では64次元のSURF をで扱っているので充分 に利用可能だ[11].これによりこれまでの線形探索によって行っていた場合に比べ,kd 木
図4.1 観光ガイドシステムのフロー
では89.6 %の時間を短縮することが出来た.
4.1.2 投票制
前章ではクエリーSLMとデータベース中のSLMとの『ユークリッド距離の合計』を 1つずつ算出して用いてきたが,今回『投票制』による認識に変更した.ユークリッド距離 の合計では,クエリー画像中のSLMとデータベースに登録されたSLM から最も類似度 の高い点どうしのペアを作り,各ユークリッド距離を合計した値により認識を行ってきた. この手法では登録されている物体毎に合計値を算出する為,データ数に比例して認識に要 する時間が線形的に増加してしまう.
これに対して投票制ではクエリーのSLMに含まれる特徴量の最近傍値をデータベース 中から探索し,その特徴量を所有する物体に投票する.この手法の長所は,登録された物体 数によって所要時間が大幅に変化しない点で,多くの観光スポットの登録を想定している
ここでは投票制による認識の有効性の確認と共に,色彩や形状の似通った建築物が数多 く存在する寺社であってもシステムの利用が本当に可能であるかを確認する為の実験を行 う.この実験では以下の図4.2の様な画像から寺社の『門』12 個をデータベースに登録し ておく.
図4.2 データベースへの登録に用いた12個の『門』の画像
これに対して図4.3の様に,様々なアングルから撮影した異なる時間帯・季節の58枚の 画像での識別を行った.また,より実際の利用環境に近いものとして他の観光客が写りこ んでいるものや,日が暮れる直前の明るさのものも含まれている.
SLMを用いる場合との比較対象として,図4.2の画像の全領域(All area)から得られる 特徴量全てで1セットのマーカーとしてデータベースに登録したものを利用する.つまり 認識の際は本システムと同じく最近傍探索と投票制によって対象物体を識別するが,検出 部分については常に画像中の全領域を用いることとなる.
図4.3 評価実験用の画像例
4.3 データサイズの評価
このシステムにおいて作成されたデータベースのサイズを表4.1に示す.全領域を利用 した12個の寺社のデータベースのサイズは15.5MBなのに対して,SLMを用いて同物体 を登録したデータベースのサイズは991kBとなっており,約93.5%のサイズダウンを実 現している.実際のサービスならば少なくともこの5〜10倍のデータを登録する必要があ ることを考えると,この手法は全領域を用いる場合と比較して適切なサイズへと抑えるこ とが出来たといえる.
比較 93.5% OFF
4.4 速度評価
まず特徴点の検出(Detection) と認識システム全体(Detection&Recognition)におけ る所要時間を測定する.実験では58枚全ての識別を行った際の所要時間(All Time)を測 定し,その結果から1枚の静止画あたりの平均の所要時間を算出した.
表4.2 特徴点の検出と物体認識の所要時間
Detection Detection&Recognition
All area SLM All area SLM
All Time 42.75 19.84 62.47 38.51
Av. Time 0.737 0.342 1.077 0.664
53.6% OFF 38.3% OFF
表4.2ではその特徴点の検出と認識システム全体の所要時間を表している.全領域を扱 う時と比べ,SLMでは検出時間が58.6%,認識システム全体での時間が38.3%と大きく 短縮するのに成功していることが確認出来る.これにより,SLMによる高速化が可能であ ることが実証された.
4.5 精度評価
精度ではシステム正答率によって評価を行う.速度評価の時と同じく図4.3の様な58枚 の評価用画像を用い,システムが回答した物体名と正解とを比較すことでその正誤を判別 し,正答した回数をカウントすることで最終的な正答率を算出している.
この結果,表4.3の様に全領域を用いたい場合の正答率は50.88%なのに対し,SLMを
用い場合では正答率が34.92%となった.利用する情報量を減らしたことによってある程 度の精度低下は予想されていたが,これでは全くもって実用性がないという結論となって しまう.以下の項ではこの結果に対する考察とその対策について述べてゆく.
表4.3 正答率の比較 全領域 SLM 正答率[%] 50.88 32.77
比較 18.11%DOWN
4.5.1 得票数の分布
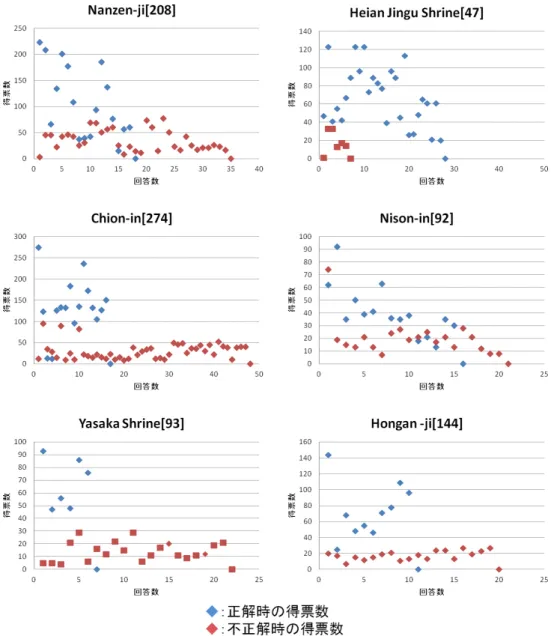
図4.4は実験時の得票数を回答された物体名ごとにまとめたものだ.横軸は回答の回数・
縦軸が得票数となっており,青は正解・赤は不正解時の得票数を示している.また,各表の 上部の物体名の横の数字は,データベースに登録されているその物体のSLMに含まれて いる64次元の特徴量の数を表している.
この図4.4では,12個ある『門』の内で特に回答回数が多い6個を掲載している.この6 つの物体に登録されている特徴量の数は最小で47個,最大で274個と大きな差があるに も関わらず,その正解・不正解の分布には同じ傾向が見受けられる.いずれの場合において も,不正解の得票数はそれぞれの登録されている特徴量の数に対して一定の割合の部分に 集中し,それより上の部分に正解の得票数は集中している.これを利用し,登録されている 特徴量の数に対する得票数の割合に閾値を設けることでより認証精度を向上させることが 可能であると考えられる.
4.5.2 得票数の閾値 v の設定
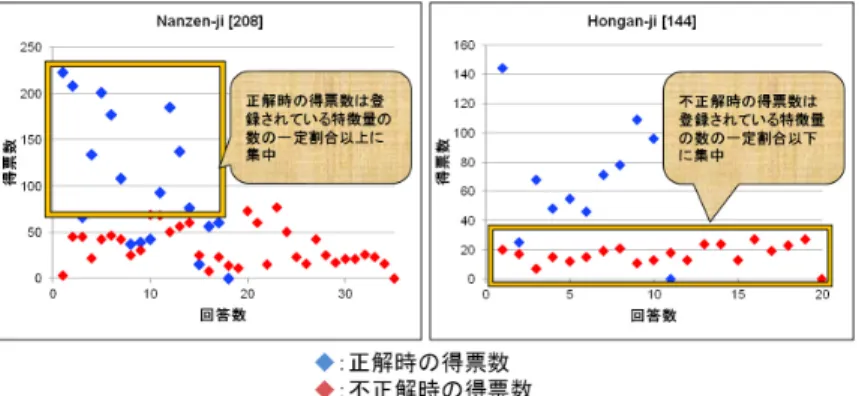
図4.4の内の2つを抜粋したものが図4.5だ.これからも確認出来るように,データベー ス中に存在する特徴量の数に関係なく,常にその数の一定の割合を境界にして正解・不正 解時の分布が広がっている.このことから,得票数に閾値を設ける際には絶対的な閾値で はなく,相対的な閾値を設定する必要があることが考えられる.この「v以上の得票」とい う閾値vを実際に設定し,改めて実験した結果を以下に示す.
%にまで達し,全領域と比べても27.22%向上した.
図4.4 正解・不正解時の得票数の分布
図4.5 有効・無効とすべき得票数の分布
表4.4 得票数の閾値毎の正答率と回答・正解拒絶率
正答率 回答拒絶率 正解拒絶率
All area 50.88% - -
SLM 32.77% - -
SLM + v=1/5 55.84% 48.40% 12.06% SLM + v=1/4 63.35% 58.38% 19.54% SLM + v=1/3 70.88% 65.72% 25.86% SLM + v=1/2 78.10% 80.23% 52.87%
その一方で正解・不正解を問わず,vの値を上げると回答の拒絶率も大幅に増加してい る.つまり,回答を無効とする確率が急激に上昇していることが伺える.特に1/2以上の得 票を要する場合には正答率が高い反面,回答全体の拒絶率が80%を超えており,結果とし て回答を得られないケースが過度に増加してしまった.この実験では静止画を用いており, 実際の端末上で利用する際にはカメラで撮影した画像を利用することになる.その為,回答 が拒絶され続けると何度も写真を撮り直す必要が生じ,実用的ではないと考えられる.こ の点を踏まえ,第6章では動画を入力とすることで撮り直しの手間を省くと共に,得票数 の閾値と所要時間の関係について考察を行う.
第 5 章
同一画像内における直線の傾きによ るフィルタリング
第4章まででは,1枚の画像から検出された全ての直線をSLMとして用いてきた.しか し,検出される直線の中にはSLMとして用いるのに不適切な直線も存在している.
その例としてまず挙げられるのが図5.1の(a)-3の様な直線である.これは確率的ハフ 変換によって誤検出されたノイズの様な存在で,対象物と関係ない部分や直線でない部分 に現れてくる.
次に挙げられるのが(a)-2・(b)-2の様な直線だ.これらは(a)-3とは異なり,正確に対 象物の直線部分を検出した結果のものだが,(a)と(b)とではその周辺の背景,特に右半分 が大きく変化してしまっている.この様な直線をSLMとして利用した場合,SURFの利点 である撮影角度の変化への頑強さが損なわれてしまい,結果として正しい認証が出来なく なってしまう.
これら2つの直線に対して(a)-1・(b)-1の様な直線はその周辺の背景が大きく変化する ことない為,結果として正しい結果を容易に得られると考えられる.同時に,建築物の直線 部分は縦よりも横の直線の方が検出されやすい傾向が強く,同一画像内であれば基本的に
(a)-1・(b)-1と同程度の傾きをもつ直線が最も多く検出される.この点を利用した直線の
傾きによるフィルタリングを本章では行ってゆく.
図5.1 SLMに適切な直線と不適切な直線
5.1 同一画像内における直線の傾き分布
フィルタリングを行うにあたり,まず始めにその同一画像内で実際にどの様にして直線 の傾きが分布しているかを見てゆく.
以下の図 5.2〜5.4 のグラフでは縦軸が直線の傾き [radian],横軸は同一画像内の直線 の本数[本]を表している.青色は「対象物であり SLMとして適切な直線」の傾き,緑色 は「対象物ではあるがSLMに不適切な直線」の傾き,赤は「対象物以外の直線」の傾き を-π/2〜π/2の範囲で示している.なお,これら 3つの色の傾きは,それぞれ図5.1におけ る(a)−1・(b)−1,(a)−2・(b)−2,(a)−3に相当する.
これら3つの図に共通していえる点は,青色の「対象物でありSLMとして適切な直線」
の傾きが他の2色ものものよりも安定して同程度の値をとっていることだ.これに加え,
「建築物の直線部分は縦よりも横の直線の方が検出されやすい傾向が強く」と述べた通り の分布になっており,その中央に青が分布している.
以上の点を踏まえてフィルタリングを行うことで,図5.5の様に必要な直線のみをSLM に利用する.その結果,特徴検出を行う対象領域を減らすことが可能となり,速度の向上が 期待出来るようになる.同時に,これまで利用していたSLMに不適切な直線を除去するこ とが出来るので精度の向上が期待される.
図5.2 直線の傾きの分布1[radian]
図5.3 直線の傾きの分布2[radian]
図5.4 直線の傾きの分布3[radian]
5.2 フィルタリングの概要
フィルタリングの機能を追加するにあたり,図4.1を一部変更して図5.6の様なシステ ムを作成した.ここで実際に用いるフィルタリングは,
図5.5 フィルタリング結果の例
• 1次フィルタ:-0.2〜0.2[rad]の直線以外は除去
• 2次フィルタ:中央値±α(α=0.02, 0.05, 0.1)以外の直線を除去 の二重構造をとっている.
まず1次フィルタでは,建物の横線のみを利用するように範囲を限定している.一般的 にカメラで写真を撮影する際,対象物の主要な横線部分の傾きはこの範囲内に収束し,なお かつ建物の縦線部分をSLMの候補から除外している.また,誤って検出された直線の傾き はこの範囲外であることが多く,それらの直線をノイズとしてキャンセルする役割も担っ ている.
これに対し, 同一画像内において特に主要な直線部分は1次フィルタの-0.2〜0.2[rad]
の中でも更に分布が偏ってくる.2次フィルタでは,1次フィルタを通過した直線の傾きの 中央値を軸に±αの範囲を指定することで,真に有効な直線のみを利用する為のものであ る.なお平均値ではなく中央値を利用しているのは,SLMとして不適切な傾きの分布が適 切な傾きと比べて大小いずれかに偏る傾向があるからだ.加えて,適切な傾きをもつ直線 の本数は不適切なもののそれよりも多いことが殆どなので,結果として中央値を利用する ことが不適切な傾きの値を除外する上で有効となっている.
図5.6 フィルタリングを含めたシステムフロー
5.3 評価実験
第4章での評価実験に用いた58枚の画像を用いて,図5.6のシステムにおけるフィルタ リングの効果について検証してゆく.
5.3.1 速度評価
先述した通り,フィルタリングを行うことで余計な直線を除去することで,特徴検出に 用いるマスク画像の領域を更に減らすことが出来た.その結果を表5.1で,システム全体で の画像1枚当たりの平均所要時間を用いて表した.なお,得票数の閾値は速度に対して影 響を与えないのでここでは省略する.
全領域を用いるでは1.077[s],フィルタリングなしのSLMでは0.64[s]だったのに対し, フィルタリングを行った場合は0.521〜0.563[s]と全体的に短縮されていることが確認出 来る.単体で用いた場合と比較すると最大で 21.4%,全領域を用いた場合の半分以下の 51.6%短縮を達成した.
表5.1 画像1枚当たりの所要時間[s]
所要時間 比較:全領域 比較:SLM
All area 1.077 - -
SLM 0.664 38.3%OFF -
SLM:α=0.02 0.521 51.6%OFF 21.4%OFF SLM:α=0.05 0.547 49.2%OFF 17.6%OFF SLM:α=0.1 0.563 47.7%OFF 15.1%OFF
5.3.2 精度評価
今度はフィルタリングによる精度の変化についての検証を行う.
図5.7 フィルタリングを行った場合の正答率
全領域を用いた場合の正答率は50.88 %と,図 5.7のグラフの最下部にあたる数値で あった.そしてSLMを単体で用いた場合, その精度は得票数の閾値v に応じて55.84〜
以上より,速度と精度の両面においてフィルタリングは有効であったことが確認出来た.
第 6 章
動画による物体認識実験
6.1 システム概要
前章までは静止画を用いて実験を行ってきたが,閾値を上げること正答率が上がる反面, 回答拒絶率も飛躍的に増大してしまった.実際に屋外での携帯端末での利用場面を考える と,拒絶される毎に幾度も写真を撮り直すのは現実的ではない.従って入力を静止画でな く動画に変更し,連続的にクエリー画像を取得することを可能にした.これに伴い,前章ま で用いてきた図4.1のシステムを一部変更し,図6.1の様なシステムを作成した.このシス テムではこれまでの各SLMが示す物体名を回答する為に用いていた投票制に加え,更に その回答で同一の物体名の回答を複数得るまで投票を行う『二重投票制』を採用している.
6.1.1 二重投票制
これまでの『投票制』はSLM毎に物体名を回答する為のものであったのに対し,今度は その回答を票とし,この『二重投票制』で既定の回数だけ得票した物体名を最終的に回答 する様にしている.これは閾値を高くすることで回答が拒絶される可能性が高くなってし まったことへの解決として動画入力を行うことに加え,同一回答が複数待つことでその認 証の精度の向上にも役立つと考えられるからだ.なお,この最終回答に必要な最大得票数 mを,先の閾値vとαとのいくつかの組み合わせで検証する.
図6.1 動画入力でのシステム概要
6.2 実験概要
ここでは今まで用いてきたデータベースに新たに図6.2の様な対象物のSLMを登録し て動画入力による識別実験を行う.今回はこの画像を紙面に印刷し,それを手に持ったカ メラによって動画を撮影する.これは実際の利用場面においても手ぶれが発生することを 考慮したものだ.なお実験では図5.7で精度の高かった得票数の閾値v とフィルタリング の閾値αの組み合わせを選び,二重投票制による最終回答を20回得られるまで続け,その 間の所要時間と正解数を測定する.
図6.2 認識対象
6.3 速度評価
最終回答を20回得られるまでの所要時間を測定し,これをもとに算出した最終回答の 平均所要時間は表6.1の様になった.
表6.1 動画入力における認識の平均所要時間[s]
(v, α) (1/2, 0.05) (1/2, 0.1) (1/3, 0.05) (1/4, 0.05) (1/4, 0.1) (1/5, 0.02)
m = 2 1.021545 1.397 0.755245 0.62051 0.55701 0.437539
m = 3 1.275075 1.47472 0.83896 0.83174 0.918565 0.63741
m = 4 2.0996 2.23919 1.406905 1.082545 1.0169 0.939715
m = 5 2.583505 2.60213 1.467355 1.4411 1.48879 1.181305
動画での認識は最も遅いのが(v, α, m)=(1/2, 0.1, 5) の時で2.60213[s]だった.これ に対して最速は(1/5, 0.02, 2)の時で0.437539[s]で,複数回の回答を得るために複数の画 像を処理していることを考えると,この値は第5章の表5.1でのα=0.02の際の所要時間
0.521[s]を大きく上回る速さを示す結果となった.これは動画入力では微妙な手ぶれなど
の影響で,静止画を直接利用する際よりも検出される直線部分が激減したことが原因だと 考えられる.これによってマスクの領域も激減し, 結果として特徴量の検出についての所 要時間が大幅に削減されたことが現れたものだと考えられる.
要とされる回答数を計算し,その数値と表6.1の値との傾向の比較検証を行う.この必要な 回答数は,1次投票での得票数が閾値を上回っている『有効回答を得るまでの平均所要回答 数』と,その有効回答で行われる『二重投票制が正解で終了するまでの平均所要回数』を 乗じた数値によって算出する.
有効回答を得るまでの平均所要回答数
ここでは閾値を設けることで生じた回答拒絶率が実際に回答を得る上でどの程度の影響 を与えているかの考察を行う.有効な回答を得られる確率と回答回数の関係を閾値毎に以 下の様な6.1式を用いて定義した.
有効回答取得率 = (1−( r
100)n)×100(r:回答拒絶率n:回答回数) (6.1) いくつかの(v,α)の組み合わせの回答拒絶率を用いた計算結果を,以下の図6.3に示す.
図6.3 閾値毎の有効回答取得率
閾値vが1/5・1/4・1/3の場合,それぞれの有効回答取得率が90%を超えるのが3回・
4回・5回と大きな差が開いていないことが伺える.それに対して閾値が1/2の場合は,90
%を超えるのに9回の回答が必要となり,1/3の場合の倍に近い回答回数を求められてい る.この時点で閾値を1/2とするのは不適切に考えられるが,一方でその有効回答の正答 率が高く,他と比べてmの値が小さいくても充分に信頼できる結果を得られる可能性が ある.
二重投票制が正解で終了するまでの平均所要回数
次に二重投票制での閾値mと図5.7の正答率を用いて,最終回答が正解で終了する確率 を計算する.これは先述の有効回答までの平均所要回答数が「二重投票に1票入れるの必 要な1次投票の回答数」なのに対し,こちらは「2つ目の投票結果が充分に信頼出来る結 果で終わることが出来る回答数」を表している.この最終回答が正解で終了する確率は以 下の式によって定義する.
n回目までの正解終了確率=
∑n k=1
(k−1)!
(m−1)!(k−m)!(1−p)k−mpm(n:回答回数, p:正答率)
(6.2) この6.2式を用いて実際に閾値毎にmの値を変更して計算し,正解終了確率が90%を 超えた時の回答回数nを以下の表6.2に示す.
表6.2 二重投票制が正解終了するまでの平均所要回数[回]
(v, α) (1/2, 0.05) (1/2, 0.1) (1/3, 0.05) (1/4, 0.05) (1/4, 0.1) (1/5, 0.02)
m = 2 4 4 5 5 5 6
m = 3 6 6 6 7 7 8
m = 4 7 7 8 9 9 10
m = 5 8 9 9 11 11 12
最終回答を得るのに必要な回答数
以上の数値を利用して算出した最終回とを得るのに必要な回答数を表6.3にまとめた.
m = 2 36 36 25 20 20 18
m = 3 54 54 30 28 28 24
m = 4 63 63 40 36 36 30
m = 5 72 81 45 44 44 36
実測値との比較
表6.1と表6.3の値の傾向を比較する為,図6.4の様に可視化した.これより実測値での 平均所要時間と最終回答に必要な回答数の傾向が一致していることが確認出来,測定値が 適切であったと考えることが出来る.
図6.4 動画入力における平均回答時間と予測必要回答数
6.4 精度評価
この実験では(v,αm)の組み合わせに依らず,全ての最終回答で正解の物体名を回答 した.その一方で,値の組合せ表6.3の右上に近付く程に,途中の回答に正解以外のものも
含まれる頻度が高くなっていた.その為,実験回数を20回より多くした場合には不正解と なる可能性がわずかだが存在する.
第 7 章
総括
7.1 最終結果
SLMを用いることでそのデータベースのサイズは93.5%削減に成功した.静止画では 1枚当たりの所要時間は0.52[s]で,精度は84.0%に達し,全領域を用いた場合に比べて2 倍以上の速さを実現すると同時に精度は33.12%もの向上を果たした.また動画入力によ る実験では0.44〜2.60[s]と実用面で充分な時間での認識を達成し,精度は静止画における 精度を上回る結果となった.以上の成果より,このSURF-based Line Markerは携帯端末 上での動作を視野に入れる上で有効な手法でだといえるだろう.
7.2 Future Work
今回は観光支援を目的とすると為, データベースに予め適切なSLMを選別して登録し ておいた. しかし, それ以外の用途でユーザが自由にデータを登録可能にするには, データ ベースとして相応しいかどうかを評価する仕組みが必要であり,AR という情報空間の利 用を本格化するに当たり不可欠でもある部分だ. 今後こういった部分の解決が行われるこ とで, よりARによるサービスの普及が促進されるはずだ.
参考文献
[1] 住 友 商 事 、AR( 拡 張 現 実 )連 動 型 新 聞 広 告 を 展 開, MarkeZine ニ ュ ー ス http://markezine.jp/article/detail/8849
[2] 博 報 堂 が 展 開 す る AR 広 告「 テ ノ ヒ ラ ア ド 」っ て 何 だ ?, ITmedia ニ ュ ー ス http://www.itmedia.co.jp/news/articles/0912/04/news015.html
[3] AR(拡張現実), 朝日新聞社広告局
http://adv.asahi.com/modules/keyword/index.php/content0023.html
[4] 武 部 健 一: 位 置 情 報 利 用 は GPS の 精 度 に 依 存, 日 経 コ ミ ュ ニ ケ ー シ ョ ン http://itpro.nikkeibp.co.jp/article/COLUMN/20081215/321495/
[5] Georg Klein, David Murray: Parallel Tracking and Mapping for Small AR Workspaces. IEEE Computer Society Washington, DC, USA, 2007.
[6] H. Bay, T. Tuytelaars, and L. V. Gool: Speeded up robust features, In Proc.
ECCV 2006, 2006.
[7] Lowe. D:Object recognition from local scale-invariant features”. Proceedings of the International Conference on Computer Vision. 2. pp. 1150–1157.
[8] 藤吉弘亘:Gradient ベースの特徴抽出 -SIFT と HOG-, 情報処理学会 研究報告
CVIM 160, pp. 211-224, 2007.
[9] D. Wagner, G. Reitmayr, A. Mulloni, T. Drummond, D. Schmalstieg: Pose Track- ing from Natural Features on Mobile Phones.ISMAR ’08: Proceedings of the 7th IEEE/ACM International Symposium on Mixed and Augmented Reality.
[10] G. Csurka, C. Bray, C. Dance, and L. Fan:Visual categorization with bags of keypoints. Proc. of ECCV Workshop on Statistical Learning in Computer Vision, pp. 59.74(2004).
[11] 3日で作る高速特定物体認識システム (7)最近傍探索の高速化
謝辞
本修士論文の作成にあたって、たくさんの方々に大変お世話になりました。
まず、お忙しいところ時間を割いて頂き、的確な御指導をして下さった村岡洋一教授に 深く感謝致します。またご指導だけでなく、本論文作成にあたり必要となる書物や快適な 研究環境をご用意して下さり、大変助かりました。
多くの学生への指導でお忙しい中、研究テーマの決定や論文作成にあたって幅広い範囲 に渡ってご相談にのって下さった秋岡明香先生に感謝致します。
そして最後になりますが、この1年間の研究生活を支えて下さった家族と仲間に深く感 謝致します。